先放一个我目前的工作布局,可能和大家最大的区别是多了一个麦。

0. 先说一次「被迫真香」的经历
真正让我对语音输入改观的,不是在工位上,而是在车上。
有一次我在车上赶一个还没收尾的需求,类似「OAuth 登录这块流程要改一版」这种:
- 旧方案有历史包袱
- 新需求又不断加条件
- 中间还有埋点、埋坑、兼容性一大堆细节
问题在于,当时车已经在路上了:
- 会颠簸,我本来就有点晕车
- 姿势别扭,手伸出去一会儿就酸
- 光线、屏幕角度都不舒服
简单讲------这是一个对「打字」极不友好的环境。
但我不想浪费这段时间,于是只能再一次尝试使用语音输入进行 Vibe Coding:
- 先把当前需求的背景讲了一遍
- 又补了一堆之前踩过的坑和兼容考虑
- 中途不断自我推翻:「不对,这样做登录态会乱掉」「等等,那埋点就对不上了」
如果按照我过去对语音输入的印象,这一大段最后大概率会变成:
- 一堆识别错误的文字
- 一段需要我自己重整的烂帐

结果那次和 AI Agent 协作的表现有点超出预期:
- 它基本听懂了我在说什么
- 把那些犹犹豫豫的念头整理成了几个还算清晰的方案选项
- 顺手帮我列了一份「改版时要注意的坑」清单
我在那辆晃悠的车上,一边说一边看它的回应,突然有一种挺明显的感觉:
它不是在帮我「打字」,而是在帮我「想事情」。
那天结束的时候,我脑子里蹦出一个感觉:「这玩意儿,好像没我想的那么鸡肋。」
等车到地方,下车回到桌前,我又继续用起了语音,同时开始琢磨一件事:
如果在这么恶劣的打字环境下,语音 + AI 还能把这次需求整完,那是不是说明,我以前那套「语音没啥用」「不适合干正经活」的判断,本身就有点问题?
自那以后,我从偶尔用语音输入,到目前级高频使用(还为此升级了下设备),过去了一个多月。
这一个多月「语音」+「AI Coding」的实践让我的认知有了很大变化,这篇关于「语音输入」想来分享三件事:
- 我以前为什么觉得语音输入很鸡肋?
- 最近这波「真香」的底层变化到底在哪?
- 语音在 AI Coding 里适合干什么、不适合干什么?
1. 【成见】以前我为什么瞧不上语音输入
老实讲,我一开始对语音输入的直觉就两个字:鸡肋。
原因也不复杂,基本都是拿自己踩过的坑换来的结论。
1.1 识别不准带来的精神内耗
几年前我试过语音转文字:手机自带的、输入法里的,还有一些小众工具。体验大概都是:
- 说一句话,屏幕上出来一堆奇怪的字
- 专有名词基本全错:React、hook、useState、async/await 之类
- 标点乱飞,逻辑断成一节一节
然后我就得干一件很蠢的事:一边看着屏幕,一边拿回车和删除键当橡皮擦用,去改语音输出的内容。几轮下来,脑子里的结论就是:
修错误的时间 > 直接打字 修错误的情绪消耗 >> 打字
用几次就自然放弃了。

如果稍微理性一点看,过去的语音识别大概是这样的:
- 输出的是「字面文本」
- 只要错一个词,整句可能就变味了
- 完全不理解语义、不补全、不纠错
- 用户被迫「为机器说话」------刻意放慢、咬字清晰、尽量别说口语
1.2 说话这件事本身「不适合精确表达」
另外一个问题是:以前所有的语音输入工具,都在试图把「说话」当成「打字」的替代品。但我们日常说话,天然是这样的:
- 「那个...就是...那个弹窗...」
- 「不对,我刚刚说的那个逻辑有问题,应该是先 XX 再 XX」
- 「等等,这里应该还有一个边界条件」
而传统软件要的是:
- 精确的指令
- 结构化的输入
- 明确的参数
这俩一对比,问题就很明显了:语音天然是「模糊的」,但传统软件需要「精确的」输入。
所以以前的各种语音工具,为了对接上这些精确输入的软件,都在逼用户做一件反人类的事:
逼自己「像打字一样说话」。

结果就是,本来应该更轻松的语音输入,用起来反而比打字还累。
1.3 说错话的成本太高
最后一个很现实的小问题:撤回成本。
打字时,说错了就:
- Ctrl + Z
- Delete
- 光标回退,改两下
语音就不一样了:
- 你一旦说出口,整句都得重来
- 还要先停下来,等识别结果出来
- 发现不对,再去选中、删除、重说
有一说一,这种「一旦说出口就很难撤回」的感觉,会让人下意识紧张:「那我还是想好再说吧。」一旦进入「想好再说」这个模式,语音输入的速度优势基本也就没了。所以在很长一段时间里,我对语音输入的态度一直是:
在工作里顶多是个玩具,真要干活还是老老实实打字。

2. 【变化】最近这波变化,关键不在「听得更准」
那为什么这次我又真香了?直观感受上,最近这波变化有两个源头:
- 一个是技术本身确实进步了
- 另一个是「我们拿语音来干的事情」变了
这两个叠在一起,才让语音输入从「玩具」逐渐挪到了「主入口」的位置。以下这些都是我实际使用中观察到的,在 thinking 类模型上表现更佳。
2.1 技术这块:从「认字」到「懂你在说啥」
先看下技术面这几年到底进步了什么。
用一个简化版的对比表看一下:
| 维度 | 以前 | 现在 |
|---|---|---|
| 语音识别准确率 | 80-90%? 专业术语更差 | 95%+,对编程术语友好 |
| 延迟 | 明显延迟,容易打断思路 | 接近实时,甚至本地运行 |
单看这张表你会觉得,好像就是「更快更准」了,听上去不错,但似乎还没到「改变使用习惯」的程度。真正改变体验的是另一件事:语音识别后面,多了一层能理解上下文的「理解层」(例如你的下游软件是基于 LLM 的)。
为了方便直观一点,可以脑补成下面这张小图:左边是之前语音工具的链路,右边是现在配合 LLM 之后的链路:
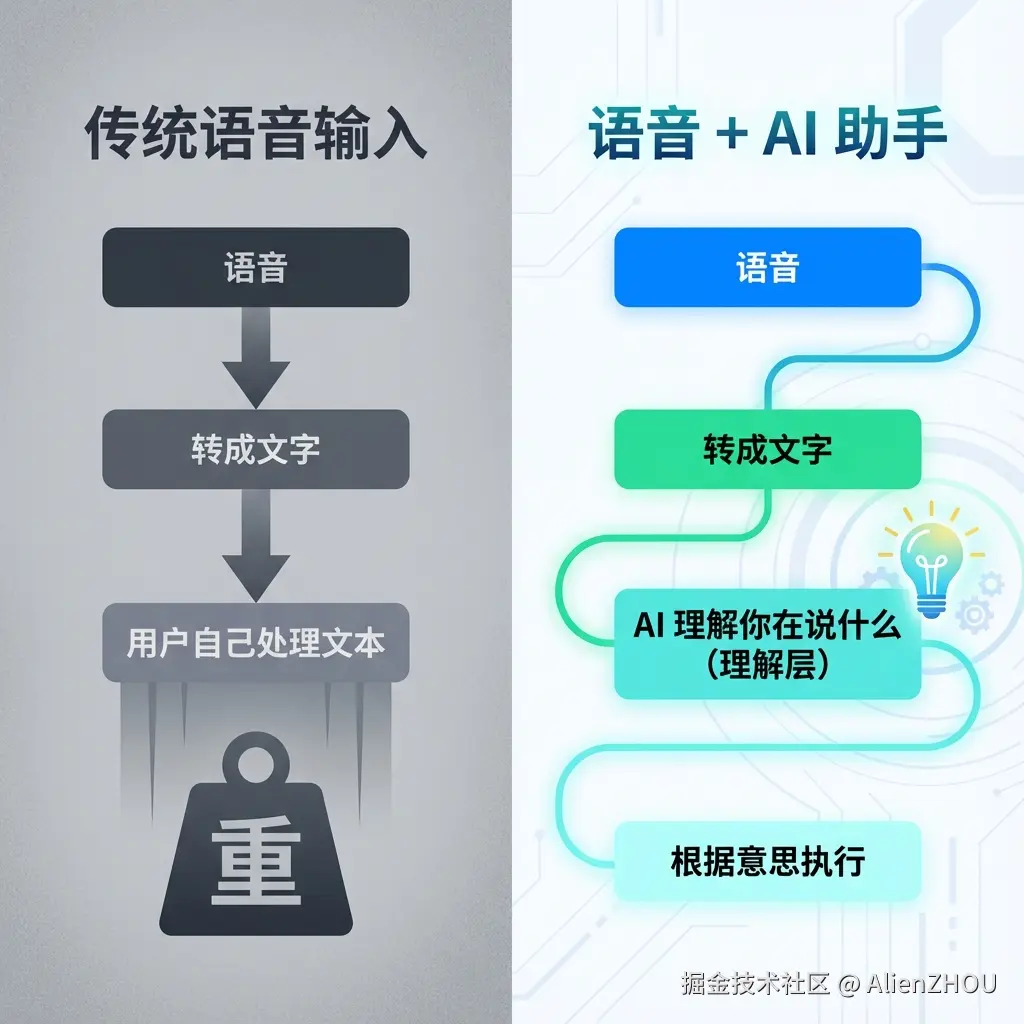
这层「理解」插进来之后,有几个很关键的变化:
- 识别错几个字,不影响结果
- 说话可以口语化、断断续续,也能推出来主要意思
- 从「给精确指令」变成了「表达意图就行」
说白了,
以前语音输入的质量标准是「转录够不够准」,现在更像是「说说你的想法,AI 可以理解」。
2.2 LLM:把你的口水话整理成「可用信息」
刚才说的是「链路结构」的变化,再说点更偏体验的。现在的 AI 会把你那堆口水话当成有用的素材,而不是噪音。一个典型场景:
你对着麦克风说:「嗯......我想要一个函数......不对,应该是一个类......或者说,一个模块,能处理用户认证......」
过去很多系统:
- 会忠实地把这句话转成文本
- 然后把所有的「嗯」「不对」「或者说」也都塞进去
现在的 AI 更像是:「好的,他大概想要一个用户认证模块。」:
- 过滤掉大部分口水话
- 弄清楚你到底「最后倾向哪个方案」
- 同时记住你犹豫过的那几个选项(后面还可能有用)
这个时候,你的「思考过程」就不再是噪音,而是 AI 理解上下文的素材。所以有一个挺重要的视角切换:
语音输入的「输出质量」,不再取决于你说得有多完美,而是取决于后面那个理解你的模型有多能干。
2.3 对话上下文:语音可用性的隐形护栏
还有一条经常被忽略但特别关键的事:对话上下文。
想象一个很日常的情景:
你和同事已经讨论了 20 分钟技术方案,这时候你说:「那这个地方就按刚才说的那个方案来吧。」
你同事大概率事知道你在说什么,因为他有完整的上下文。
但如果一个路过的同时,临时加入你们,他会:
- 不知道「这个地方」是哪里
- 不知道「刚才的那个方案」是哪一个
- 甚至连你们讨论的具体功能都一头雾水
你和 AI 聊天,现在的特点是:
- 它不会「因为"上厕所"错过关键信息」
- 它不会「刚路过」才听到一半
- 它可以随时"回看"之前对话记录
这带来至少三类好处:
-
语义消歧:
- 你说错一个词,它可以根据上下文猜出你真正想说的
- 比如你说成了「Ract」,但之前一直在聊 React 项目,它会自动当成 React
-
专有名词识别:
- 你之前提到过
useAuthStore,后面就算发音糊成一团,它也大概率能对上号
- 你之前提到过
-
思维连续性:
- 「刚才说的那个方案」「那个弹窗」「前面那个接口」这种指代关系,它都能顺着上下文接回来
这也是为什么,在 AI 对话里说「那个」「刚才」「前面那个」比在传统软件里安全得多。
3. 【新生】换个视角看:语音到底在 AI Coding 里擅长什么
上面更多是在讲「为什么现在语音比以前顺手了」。
回到日常工作,我自己这一个多月下来,大概把语音输入在 AI Coding 里焕发出的新的用武之地,归成了这么几类。
3.1 和 AI「讨论」的时候,语音明显更顺
只要是下面这几类事,我现在基本都会先用语音输入:
- 需求还没完全想清楚,只是有一个大概的方向
- 想和 AI 一起推演几种方案的优劣
- 在排查复杂 Bug,需要把现象和怀疑点都说一遍
举个最近的一个真实场景。那阵子我在琢磨 Duet3.0 怎么搞一个「Agent 帮你 Review」的功能,脑子里有很多还没想清楚的问题:
- Agent 到底 review 什么?只看语法 / 代码味道,还是要看需求对齐?
- 人和 Agent 怎么分工?是 Agent 提建议,人拍板,还是 Agent 先改一版?
- 在实际 IDE 里,这个东西应该长成提示气泡、侧边栏,还是一个独立面板?
我一开始是打字和 AI 对话,想把这些问题讲清楚,结果发现特别费劲:「我在想一个 Agent Review 的功能,大概是 Agent 帮我看 PR,然后......」
敲了两段,感觉自己像在写 PRD,而不是在跟一个同事讨论想法。
后来我直接开语音,像在走廊上拉着同事聊一样说:「我最近在想一个事儿:现在大家都在做 Agent Review,但大部分产品巴拉巴拉......我更想要的是那种巴拉巴拉......那人和 Agent 的边界应该怎么划比较自然?是让它直接在 diff 里改,还是只给建议?还有一个问题是,Review 结果要放哪里比较不打断人------是像现在 IDE 的问题列表一样塞一堆 issue,还是更像一个'和 reviewer 聊天'的侧边栏?」
这段话如果让我打字发,我肯定会自觉把很多犹豫、吐槽和半成型的想法删掉,只留下比较「正式」的版本。但语音的时候,我可以把这些真正在意的小勾小角都丢出来。
最后 AI 给我的反馈,也明显不是那种「看起来很正确但有点空」的 checklist,而是:
- 先帮我拆出来几条核心决策:Review 范围、人与 Agent 的分工、UI 呈现位置
- 根据我反复提到的「不要打断人」这点,给出了建议
- 结合我们已有的 Agent 能力体系,提醒我考虑 Review Agent 和其它 Agent 之间的接口设计
这个体验让我感受比较深:
在需要「讲故事」的场景里,语音比打字自然太多,而 AI 又刚好很吃「故事」。
3.2 头脑风暴、列想法的时候,语音很适合作「起手式」
还有一类场景,是我在写文档或设计方案的早期阶段:
- 只是想先把脑子里一堆零碎的点倒出来
- 不追求结构、条理、格式
- 甚至连结论都是模糊的
这时候用语音会变成一种很轻松的输出方式:「我现在脑子里大概有三个方向,第一个是把 XXX 做成一个独立服务,这样好处是 ABC,坏处是 DEF;第二个方向是...」

说完之后,我一般会让 AI 帮我做两件事:
- 把这堆口水话整理成一个比较干净的大纲
- 帮我标出它听到的「担心点」和「决策点」
然后我再回到键盘模式,开始填细节、改措辞。
如果全程打字,我会有很强烈的「写文档」的心理负担。但用语音先说一遍,更像是「口头和同事过一遍想法」,压力小很多。
3.3 精确改代码,老老实实用键盘就好
当然,也有一些场景,我现在语音:
- 精确修改某一行的变量名
- 对现有代码做很细致的重构
这种事情的特点是:我心里已经非常清楚要改什么,关键代码已经在脑子里浮现,就差腾一下。这时候语音+AI 反而会拖后腿:
- 我要先描述位置
- 再描述改动
- AI 再理解一次
- 然后再帮我生成一段严格的改动
往往还不如自己编码来得快、来得可控。
我现在的习惯可以简单概括成:
- 「想问题、聊需求、搞方案」 → 用语音
- 「精确改、收尾」 → 用键盘
两者混着用,体验会好很多。
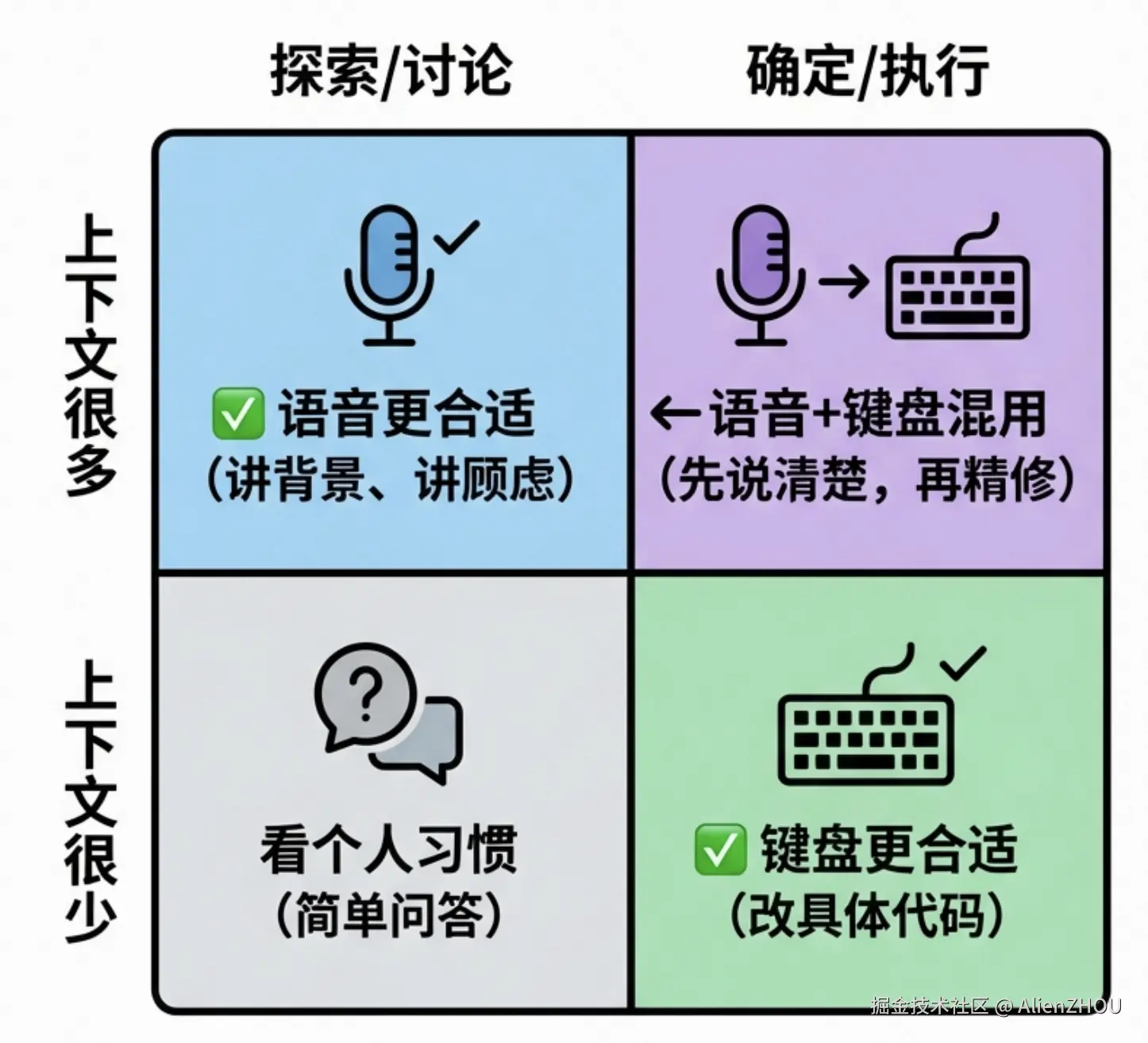
3.4 用一个小矩阵粗暴划一下边界
为了把这种「适合语音 / 适合打字」的界线讲清楚一点,我后来给自己画了一个小矩阵,大概是这样:
4. 【原因】从 Input Method 到 Thought Interface
上面这些更多是从「使用体验」讲的。我也尝试思考了背后可能的原因,如果我要问我自己一个问题:
语音在这波 AI 浪潮里,究竟是个「输入法小功能」,还是一个「新入口形态」?
我自己现在的看法更偏后者。
4.1 两种心智模型的对比
用一个「白板一点」的画法对比传统输入法 (Input Method)和思维界面(Thought Interface),大概就是:
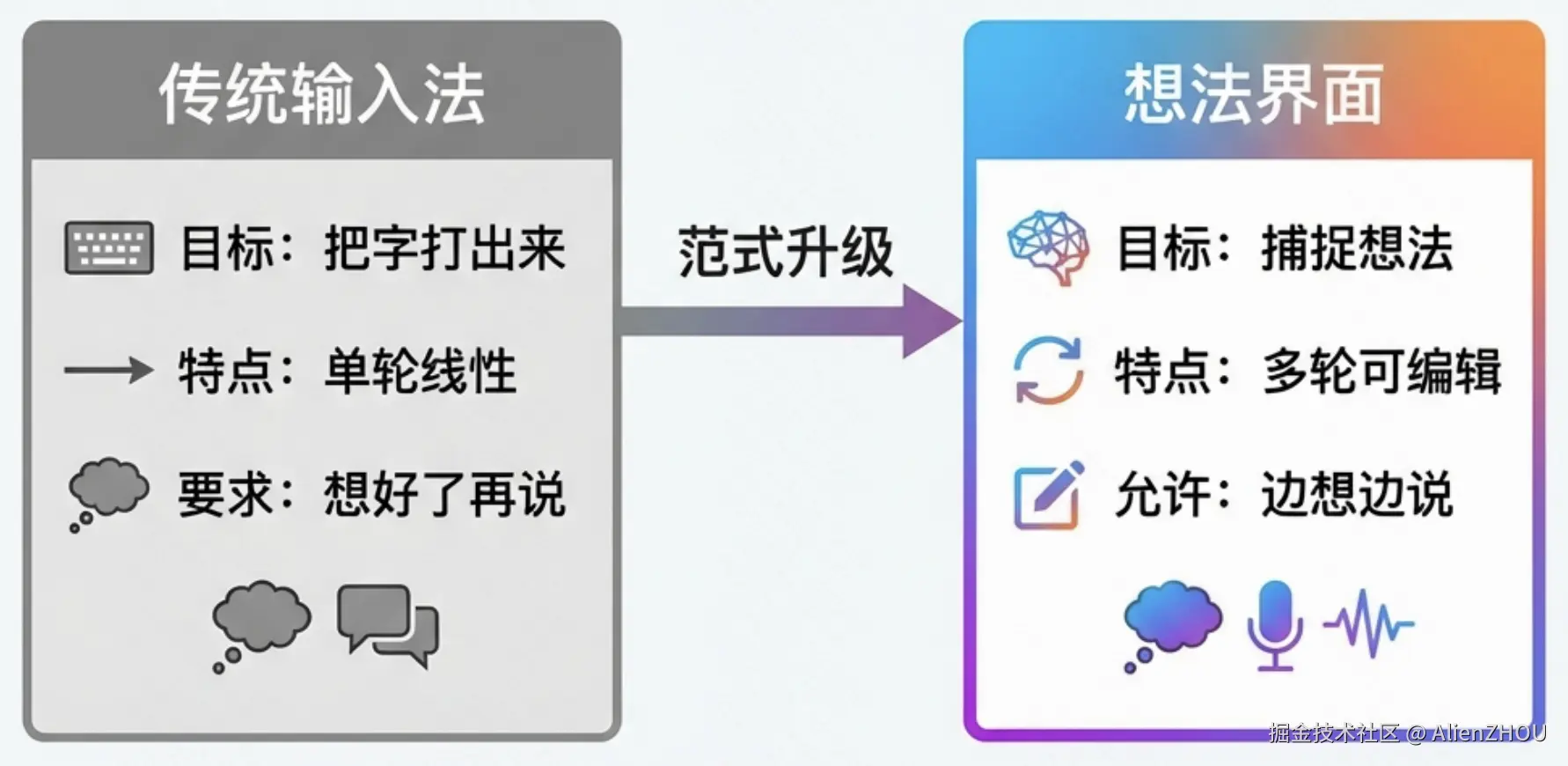
核心差别其实就一句话:
传统输入法要的是「结果」,Thought Interface 不会忽视「过程」。
前者关心你最后敲出来什么字,后者关心你在想什么、怎么想的、犹豫过哪些选项。
4.2 信息带宽:可落地的、能逼近思维速率的输入方式
斯坦福大学 2016 年有个研究,测了下几种输入方式的速度(WPM):
手机打字 : ████░░░░░░░░░░░░ 30 WPM 桌面打字 : █████░░░░░░░░░░░ 39 WPM 语音输入 : ████████████████ 165 WPM
- 语音比打字快 3~5 倍
- 而且短内容优势更明显:
- 50 字以内:快 3.2 倍
- 50-200 字:快 2.7 倍
- 200 字以上:快 2.1 倍
在 AI 场景下,现在整条链路里最慢的那段真的是模型的输出速度么?可不可能是「人怎么把自己的意思说清楚」呢?
当你发现:
- 脑子里已经排好两三种方案,但打字的时候只能一条一条敲
- 想给 AI 讲清楚上下文,结果光组织语言就写了一页纸
那这时候提升「人 → AI」这段的带宽,就比继续优化「AI → 代码」更有价值。
语音目前是少数能明显放大这段带宽的手段。
4.3 认知负担:保持思维连续性
再从「脑子怎么运转」这个角度看一下。
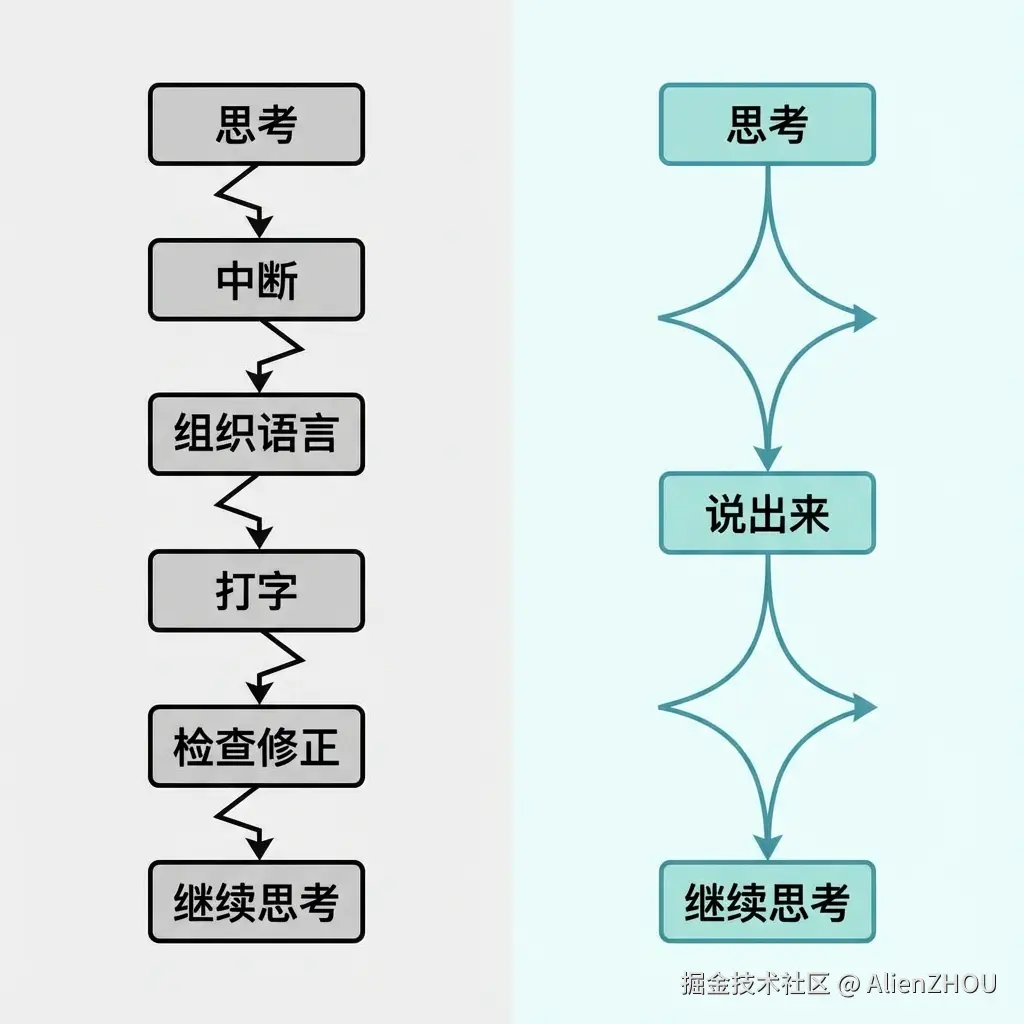
差别在哪?
- 打字迫使你频繁从「思考模式」切换到「表达模式」
- 语音几乎不需要显式「切换模式」,嘴可以跟着脑子一起跑
在很多探索性很强的场景里(需求、方案、排查),这种「不断被打断」的感觉会非常明显------你会发现:
- 想问题的时候挺顺
- 一开始写,就容易卡在某一句话、某个词、某个结构上
语音在这里的优势不是神奇地「让你更聪明」,而是很朴素地:
少打断你。
4.4 信息含量:把思考过程也一并传过去
还有一个不那么显眼但很有意思的点,你说这句话的时候:「我想要一个函数......不对,应该是一个类......或者说,一个模块,能处理用户认证。」
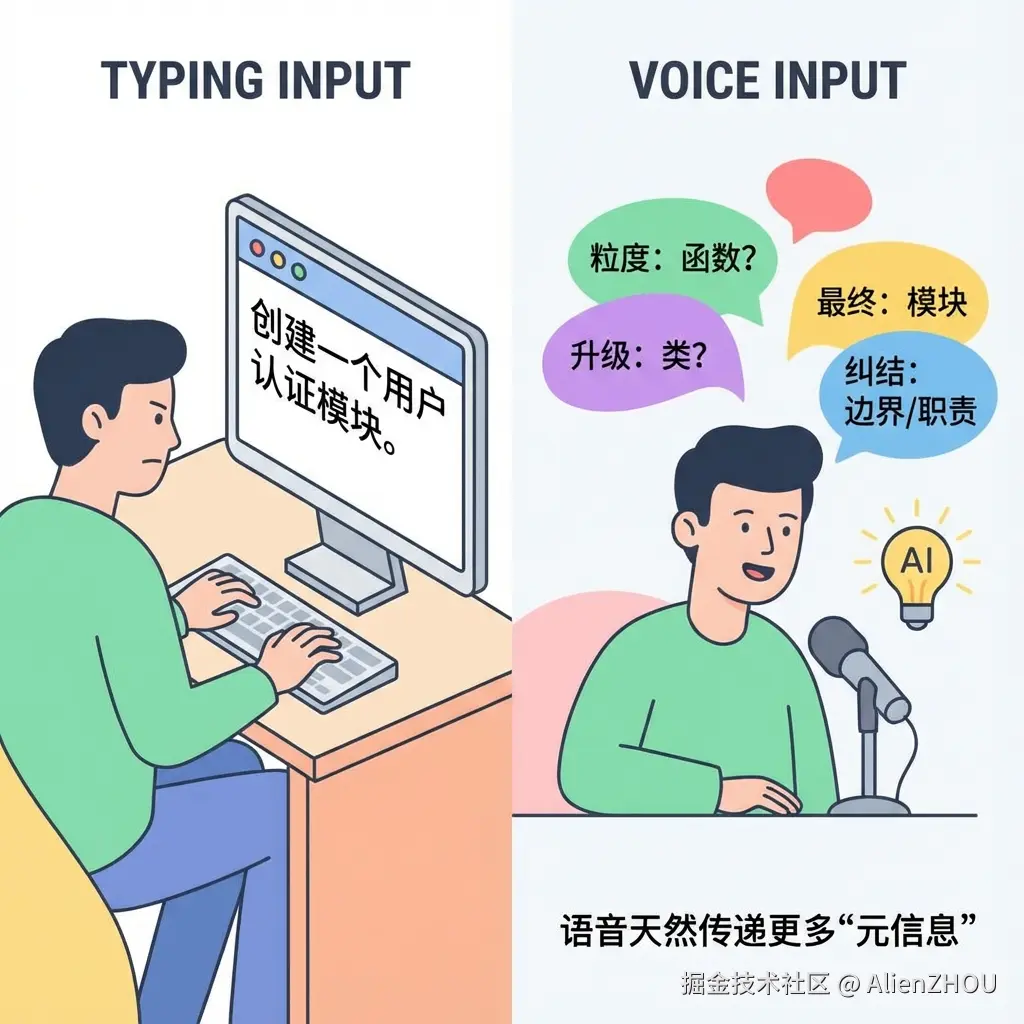
实际上暴露了很多信息:
- 你最开始想的是「函数」这个粒度
- 然后意识到可能需要更重一点的抽象(类)
- 最后把它提升到「模块」的层级
- 说明你对这块的边界、职责是有纠结的
如果你直接打字,只写:「帮我创建一个用户认证模块。」那上面这些「犹豫」和「权衡」就全没了。
大家可能会觉得,这类信息没什么用;但对 AI 来说,这反而是很重要的信号:
- 它能理解你还有顾虑,可能会主动补上一些方案对比
- 它知道你不是要一个 Demo,而是一个真正能挂到系统里的模块
换句话说,
在有理解层的前提下,语音会天然传递更多「元信息」。
5. 【心得】什么时候用语音,什么时候老老实实打字?
讲了这么多,落到实操还是那两个问题:
- 语音到底适合用在哪些场景?
- 打字又在哪些场景更稳?
以下不是什么指南,只是我这一个多月边摸索边实践的心得体会。未来也会随着我使用的深入,继续迭代。
5.1 场景适配:哪里是语音输入的"甜点"
| 场景 | 语音适用度 | 说明 |
|---|---|---|
| 发散性探讨 | ⭐⭐⭐⭐⭐ | 还在想要什么,边聊边想最自然(技术侃大山,需求头脑风暴) |
| 技术方案讨论 | ⭐⭐⭐⭐⭐ | 要来回权衡多个方案,语音更贴近白板讨论(有时真需要再加个白板) |
| 调试排查 | ⭐⭐⭐⭐ | 描述现象、推测原因,语音+其他上下文能把细节说全(虽比打字快,但还是难) |
| 代码审查 | ⭐⭐⭐ | 可以边看边评论,但精确指出具体位置还是键盘更准(有交互提升空间) |
| 精确代码修改 | ⭐⭐ | 语音说位置和改动反而啰嗦,键盘直接改更快(但我习惯后,不排斥语音替代回车键) |
| 正式文档 | ⭐ | 语音适合起稿,但收尾和润色还是键盘舒服 |
我目前的感受:
语音适合「开放/探索性」任务,打字适合「精准/确定性」任务。
5.2 混合用法:别给自己立「全语音」Flag
我自己现在比较稳的一套组合是(60%语音+40%键盘):
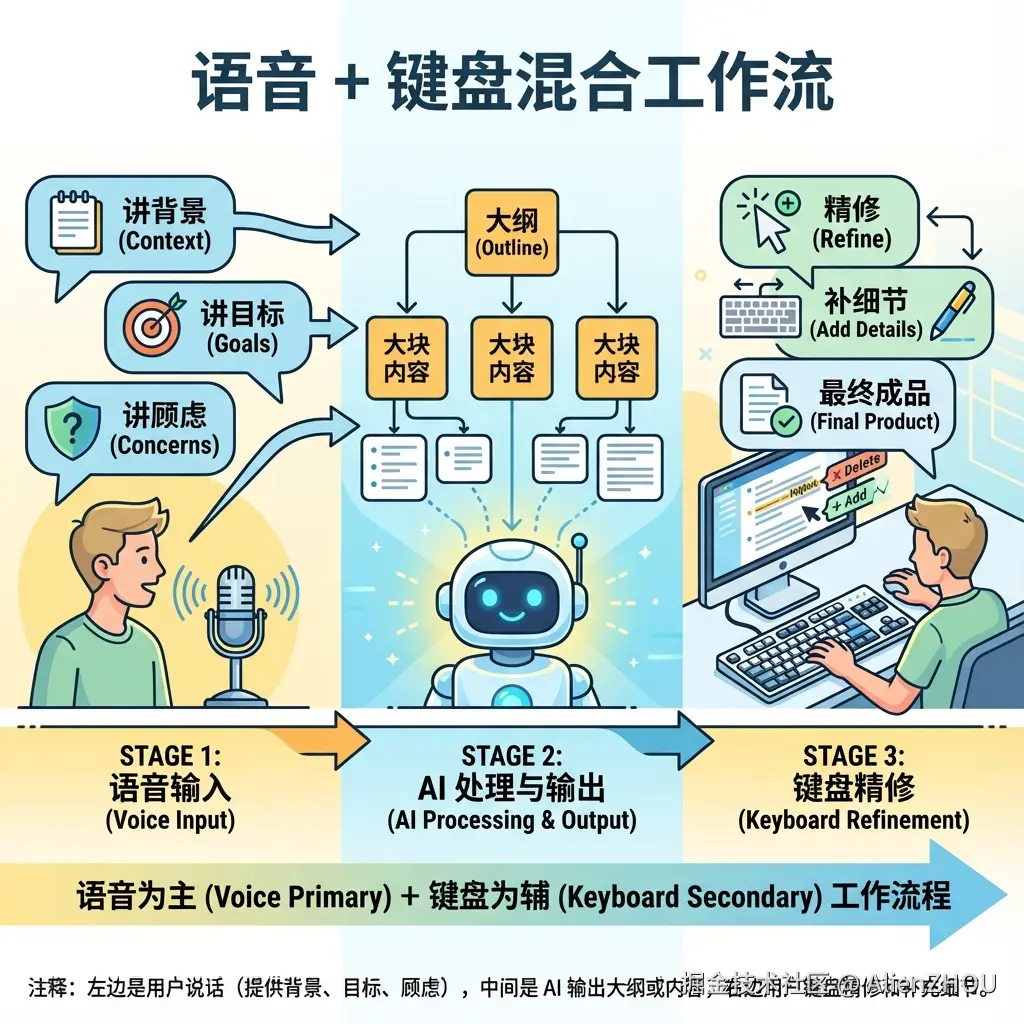
- 语音起手 :
- 跟 AI 讲清楚背景、目标、顾虑
- 把脑子里的零碎想法先「倒出来」
- AI 整理 + 大块实施 :
- 帮我归纳成结构化的大纲或方案,标出重点和需要决策的地方
- 语音指挥 AI 开始大面积实施
- 键盘收尾 :
- 精细修改措辞
- 补充遗漏的细节
6. 【门槛】技术 OK 了,人(心理)还没准备好
技术问题解决了之后,剩下的基本都是心理问题。
6.1 「在工位说话会不会很尴尬」
一开始我也挺别扭的,第一次在开放工位对着屏幕说话,总感觉同事会用一种「你在干嘛」的眼神看我。但现实是:
大家真的没空管你。

绝大多数时候:
- 别人戴着耳机,压根听不见你在说什么
- 工位本来就有各种键盘声、椅子滑动声、讨论声,你那点语音根本淹没在环境噪音里
而且,现在大家早就习惯了视频会议、在线面试、远程沟通等各种「对着屏幕说话」的场景。你在工位小声跟 AI 说两句,别人顶多以为你在开会,很少有人会专门关注你。
6.2 「会不会吵到同事」
这个其实比想象中好解决:
- 麦克风离嘴近一点,小声说就行,现在的麦克风和识别模型对小音量非常友好
- 避开午休或者大家都很安静的时间段
- 实在不放心,就找一个会议室或茶水间试一阵,熟悉了再搬回工位

我现在的做法是:日常工位用一个还不错的麦克风,小声说话就能识别得很好。避开休息时间,工位上小声说话大家基本听不到。
说多了之后,心理门槛会肉眼可见地降低。
6.3 硬件小建议
我是在公司搞了个动圈麦,在家买了个电容麦:
- 动圈麦抗环境噪声比较好
- 电容麦灵敏度高,很小声地说,它也能听清
- 其实蓝牙耳机(比如 AirPods)也能用
总之,硬件这块也不用上来就搞设备,但如果搞麦克风,推荐搭配悬臂。
7. 【工具】如果想用语音,可以从哪里下手
这里简单列一些我自己试过的工具,用的种类不多,大家有更好的也可以分享:
7.1 AI Coding 产品里的语音支持
一般都有语音。之前用过,不少外国产品里中文上不咋行(尤其有的选简体中文后,还会出繁体)。如果你本来就在用这些工具,其实不需要额外上新软件,先试试,看看自己对语音输入的接纳度。
7.1 通用语音输入法
可以让你在 AI Coding 外的其他工具里也使用语音输入。
| 工具 | 简短评价 |
|---|---|
| Typeless | 好。 |
| 闪电说 | 尚可,不如 Typeless 好用。 |
8. 【实操】如果你也想试试,可以从哪里开始
最后收个尾,给一份比较「落地」的起步建议。
8.1 先选一个你真会用起来的场景
别一上来就给自己立 Flag:「以后都用语音写代码」。基本会死在第一个小时。
比较容易成功的切入点有:
- 和 AI 讨论一个你还没想明白的需求
- 用语音把疑惑、担心点全说出来
- 不用管结构,先把自己脑子里的状态「dump」出来
- 排查一个难复现的 Bug
- 把你看到的所有现象用语音描述一遍
- 顺便把你怀疑过但被否掉的方向也讲给 AI 听
要是有一次体验到「原来这场景语音真的更省事」,后面就会很自然地多用一点,不需要强迫自己。我就是经历过两次放弃,又机缘巧合捡起来的。
8.2 接受「可以说得不完整」这件事
有个很重要的小心法:
把语音输入当成「思考过程的录音」,而不是「完美表达的工具」。
比如之前提到的,你完全可以这样说:「我现在有点乱,你帮我先记一下:第一点是 XXX,第二点是 YYY,第三点我还没想清楚,可能和 ZZZ 有关。你先帮我把前两点整理一下,顺便把第三点相关的问题列一下。」
说白了就是:
- 把「想清楚」的压力交给 AI
- 自己负责把脑子里的东西尽量完整地倒出来
我个人目前就是这个状态。这个心态一旦调整过来,语音输入会舒服很多。
8.3 混合使用语音 + 键盘,而不是二选一
前面已经说过一次组合拳,就不重复展开了,核心就是:
不要把语音和键盘当成互斥选项,而是当成一条流程里不同阶段的工具。
9. 【最后】补充一下
我现在也不会把语音输入吹成什么「生产力革命」,它绝对有自己的短板:
- 不太适合精确代码编辑(但我通过自己的一些实践,慢慢规避了)
- 不适合非常安静、对环境要求很高的办公场景(午休时候我就不语音了)
- 偶尔配上 LLM 识别还是会抽风(但真的很少,可能我说的比较长,密度虽低但架不住喷的多)
但对我个人来说,有一个变化挺真实:在需要「和 AI 好好聊一聊」的时候,甚至不知道该怎么组织思路开始的时候,我现在下意识会先点一下语音按钮,而不是直接开始打字。我所有的迷惑与混乱也都会发送给 AI,例如下面是最近我语音发给 AI 的一条消息:
可听化很重要。我可以把沉淀的东西放到 Tools 里整理起来,给一个目录,把几项功能都放一下。方案A,嗷不对,方案 B 可以吧?我不确定,可以试一试
识别有错词、语法不太通、方案选择也在摇摆。但无所谓,结果还是没跑偏。所以如果你最近也觉得:
- 打字跟不上脑子
- 和 AI 对话总是说不清楚背景
- 写方案的时候总是卡在「怎么开头」
那不妨给自己找一个15分钟的碎片时间,挑一个正在做的需求,开个语音,像和一个新人同事交接一样,把这件事「唠一遍」。

效果也许不完美,但如果你哪怕只体验到「好像有那么一点点更轻松了」,这件事就可能就值得继续试下去。