认识URL
URL 的全称是Uniform Resource Locator(统一资源定位符),就是我们常说的 "网址",用来唯一标识互联网上某个资源(比如网页、图片、文件)的地址。
就像我们搜索"C++"然后浏览器上方会出现一个很长的字符串
https://www.bing.com/search?pglt=297&q=C%2B%2B&cvid=9aa566933b0d465faa30f0daf1382ce0&gs_lcrp=EgRlZGdlKgYIABBFGDkyBggAEEUYOTIGCAEQABhAMgYIAhAAGEAyBggDEAAYQDIGCAQQRRhBMgYIBRBFGD0yBggGEEUYPDIGCAcQRRhBMgYICBBFGEHSAQgyMzc1ajBqMagCALACAA&FORM=ANNTA1&PC=U531&mkt=zh-CNURL 的编码方式与反编码
URL 里有一些字符是 **"特殊字符"(比如+、?、/、&),这些字符已经被 URL 赋予了特定含义(比如?用来分隔网址和参数,&用来分隔多个参数)。如果你的内容里本身包含这些特殊字符(比如搜索关键词是C++),就需要把这些字符转义成 "%+ 十六进制"** 的格式,这个过程就是urlencode;反过来把%XY转成原字符,就是urldecode。
为什么要编码?
核心原因是避免特殊字符 "混淆 URL 的结构"。比如:
- 假设你要搜索
a?b&c,如果不编码,URL 会变成https://xxx/search?q=a?b&c------ 此时 URL 会把?和&当成自己的分隔符,误以为参数是q=a?b和c,而不是你要搜索的a?b&c; - 编码后,
?会变成%3F,&变成%26,URL 就变成https://xxx/search?q=a%3Fb%26c,服务器就能正确识别你要搜索的内容了。
以截图的"C++"为例
先把要转义的字符(比如+)转成ASCII 码的十六进制 :+的 ASCII 码是 43,对应的十六进制是2B。在十六进制前面加%,得到%2B。
所以截图里的C++会被编码成C%2B%2B,最终 URL 里的参数就是q=C%2B%2B。
编码表
| 原字符 | ASCII 码 | 十六进制 | urlencode 结果 | 说明 |
|---|---|---|---|---|
+ |
43 | 2B | %2B |
空格的替代符 / 加号本身 |
| (空格) | 32 | 20 | %20(或+) |
URL 中常用+替代空格 |
? |
63 | 3F | %3F |
分隔 URL 和参数 |
& |
38 | 26 | %26 |
分隔多个参数 |
= |
61 | 3D | %3D |
参数名和参数值的分隔符 |
/ |
47 | 2F | %2F |
路径分隔符 |
# |
35 | 23 | %23 |
锚点(页面内定位) |
% |
37 | 25 | %25 |
编码的前缀符(需转义) |
: |
58 | 3A | %3A |
协议分隔符(如https://) |
" |
34 | 22 | %22 |
双引号 |
' |
39 | 27 | %27 |
单引号 |
( |
40 | 28 | %28 |
左括号 |
) |
41 | 29 | %29 |
右括号 |
[ |
91 | 5B | %5B |
左方括号 |
] |
93 | 5D | %5D |
右方括号 |
URL的组成
https://www.bing.com/search?pglt=297&q=C%2B%2B&cvid=9aa566933b0d465faa30f0daf1382ce0&gs_lcrp=EgRlZGdlKgYIABBFGDkyBggAEEUYOTIGCAEQABhAMgYIAhAAGEAyBggDEAAYQDIGCAQQRRhBMgYIBRBFGD0yBggGEEUYPDIGCAcQRRhBMgYICBBFGEHSAQgyMzc1ajBqMagCALACAA&FORM=ANNTA1&PC=U531&mkt=zh-CN| 部分 | 内容示例 | 作用 |
|---|---|---|
| 协议(Scheme) | https:// |
规定访问资源的方式(这里是加密的 HTTP) |
| 域名(Host) | www.bing.com |
资源所在的服务器地址 |
| 路径(Path) | /search |
服务器上的具体资源路径(这里是 Bing 的搜索功能) |
| 查询参数(Query) | ?pglt=297&q=C%2B%2B&...&mkt=zh-CN |
传递给服务器的参数(?开头,&分隔多个参数,=分隔参数名和值) |
HTTP协议
HTTP 的全称是 HyperText Transfer Protocol(超文本传输协议),是一种客户端(比如浏览器)和服务器之间传输数据的规则------ 你打开网页、刷图片、加载视频,基本都是通过 HTTP(或加密的 HTTPS)来完成数据交换的。
HTTP 基于什么?
HTTP 是基于 TCP 协议工作的,客户端和服务器先通过 TCP 建立 "可靠的连接"(三次握手),然后在这个连接里传输 HTTP 的请求和响应数据;传输完成后,Tcp连接可能被关闭(HTTP/1.0 默认)或接着复用(HTTP/1.1 的长连接、HTTP/2 的多路复用)。
HTTP 的核心特点
- 无状态:服务器不会记住前后两次请求的关联(比如你第一次登录、第二次访问个人中心,服务器默认不知道这是同一个用户),需要靠 Cookie、Session 等技术来 "维持状态"。
- 基于请求 - 响应:客户端发 "请求",服务器回 "响应",是一对一的交互模式(没有 "主动推送",除非用 WebSocket 等扩展)。
- 灵活可扩展:可以传输任意类型的数据(文本、图片、视频等),只需要在请求头里说明
Content-Type(比如text/html是网页,image/jpeg是图片)。 - 应用层协议:属于 OSI 模型的 "应用层"。
HTTP的无状态、短链接与cookie机制
大前提:正常情况下,如果你访问一个视频网站,那么网站本身肯定要先验证你的 身份,即登陆页面输入账户密码
场景 1:不用 HTTP 长连接 + 不用 Cookie
- 每次页面跳转(比如从登录页→个人中心→视频播放页),都要重新建立 TCP 连接(三次握手);
- 而且每次跳转都要重新输入账号密码登录------ 因为服务器没有任何方式识别 "你就是刚才登录的那个用户",HTTP 无状态的特性会让每一次请求都变成全新的交互。
- 缺点:既浪费 TCP 连接的开销,又要重复登录,体验极差。
场景 2:用 HTTP 长连接 + 不用 Cookie
- 第一次登录后,TCP 连接会被复用,后续页面跳转不用重新建立 TCP 连接(节省握手 / 挥手的开销);
- 但还是要重复登录------HTTP 长连接只是复用了传输通道,协议本身依然无状态,服务器不会因为复用了一个 TCP 连接,就自动记住你的身份。
场景 3:用 HTTP 长连接 + 用 Cookie + Session
- 第一次登录成功后,服务器生成
SessionID,并通过Set-Cookie把SessionID传给浏览器,浏览器保存在本地; - 后续页面跳转时,复用同一个 TCP 连接(不用重新建连接),同时浏览器自动在请求头里带上
Cookie: SessionID=xxx; - 服务器读取
SessionID,查到对应的用户信息,直接识别你的身份 ------不用重复登录。 - 优点:既省了 TCP 连接的开销,又保证了用户体验,这也是绝大多数网站的实际做法。
补充一个关键细节
就算 HTTP 长连接断开了,只要你本地的 Cookie 没过期,下次重新建立 TCP 连接(不管是长连接还是短连接),请求带上 Cookie 就能直接识别身份,依然不用重复登录 ------Cookie 才是 "记住你" 的核心,和 TCP 连接是否保持无关。
HTTP的格式
在 HTTP 协议中,换行符的标准要求是
\r\n(即回车 + 换行),而不是单独的\n(仅换行)。
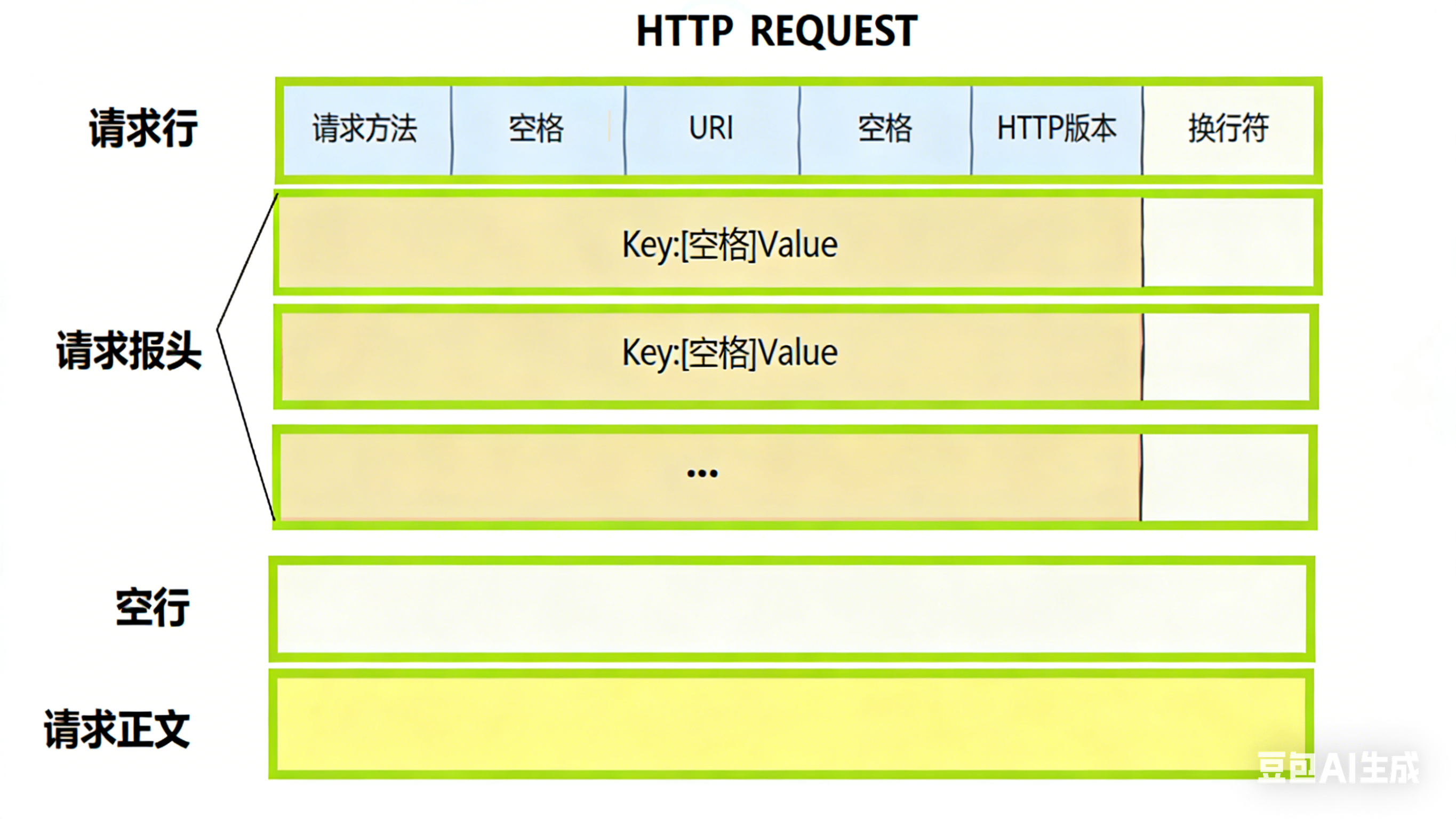
HTTP 请求格式
结构分为 4 部分:请求行 + 请求报头 + 空行 + 请求正文,对应你提供的第一张图:
| 部分 | 格式说明 | 示例 |
|---|---|---|
| 请求行 | 由「请求方法 + 空格 + URI + 空格 + HTTP 版本 + 换行符」组成,是请求的核心指令 | GET /index.html HTTP/1.1(表示用 GET 方法获取/index.html资源,使用 HTTP/1.1) |
| 请求报头 | 由多个「Key: 空格 Value + 换行符」的键值对组成,描述请求的属性(如客户端信息、数据格式等) | Host: www.example.com(指定目标服务器域名)User-Agent: Chrome/120.0.0.0(标识客户端浏览器) |
| 空行 | 单独的换行符,用于分隔 "报头" 和 "正文",是 HTTP 格式的固定分隔标志 | (无实际内容,仅换行) |
| 请求正文 | 可选,存放请求的实际数据(如 POST 提交的表单、上传的文件),若存在则需在报头中用Content-Length标识长度 |
若为 POST 请求提交表单,正文可能是username=test&password=123 |
HTTP 响应格式
结构分为 4 部分:状态行 + 响应报头 + 空行 + 响应正文,对应你提供的第二张图:
| 部分 | 格式说明 | 示例 |
|---|---|---|
| 状态行 | 由「HTTP 版本 + 空格 + 状态码 + 空格 + 状态码描述 + 换行符」组成,告知请求结果 | HTTP/1.1 200 OK(HTTP/1.1 协议,请求成功)HTTP/1.1 404 Not Found(请求资源不存在) |
| 响应报头 | 与请求报头格式一致,描述响应的属性(如服务器信息、返回数据格式等) | Server: Nginx/1.24.0(标识服务器软件)Content-Type: text/html; charset=utf-8(表示正文是 UTF-8 编码的 HTML) |
| 空行 | 同请求格式的空行,分隔报头和正文 | (无实际内容,仅换行) |
| 响应正文 | 存放服务器返回的实际数据(如网页 HTML、图片、接口 JSON 等),长度由报头Content-Length标识 |
若返回网页,正文是完整的 HTML 代码;若返回接口数据,正文可能是{"code":200,"data":"success"} |

HTTP 方法
| 方法 | 说明 | 支持的 HTTP 协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
状态码
| 状态码 | 状态码含义 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时,服务器告诉客户端可以继续上传 |
| 200 | OK | 访问网站首页,服务器返回网页内容 |
| 201 | Created | 发布新文章,服务器返回文章创建成功的信息 |
| 204 | No Content | 删除文章后,服务器返回 "无内容" 表示操作成功 |
| 301 | Moved Permanently | 网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found / See Other | 用户登录成功后,重定向到用户首页 |
| 304 | Not Modified | 浏览器缓存机制,对未修改的资源返回 304 状态码 |
| 400 | Bad Request | 填写表单时,格式不正确导致提交失败 |
| 401 | Unauthorized | 访问需要登录的页面时,未登录或认证失败 |
| 403 | Forbidden | 尝试访问你没有权限查看的页面 |
| 404 | Not Found | 访问不存在的网页链接 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时,代理服务器无法从上游服务器获取有效响应 |
| 503 | Service Unavailable | 服务器维护或过载,暂时无法处理请求 |
HTTP Connection 报头详解
| 取值 | 含义 | 适用 HTTP 版本 |
|---|---|---|
Connection: keep-alive |
开启持久连接(长连接),请求 - 响应完成后保持 TCP 连接,供后续请求复用 | HTTP/1.0(需显式指定)、HTTP/1.1默认就是长连接 |
Connection: close |
关闭连接,请求 - 响应完成后立即断开 TCP 连接(短连接) | 所有版本 |
HTTP/1.0 与 HTTP/1.1 的差异(关键)
| 特性 | HTTP/1.0 协议 | HTTP/1.1 协议 |
|---|---|---|
| 默认连接状态 | 短连接(默认 Connection: close) |
长连接(默认 Connection: keep-alive) |
| 开启长连接的方式 | 必须在请求头显式添加 Connection: keep-alive |
无需手动添加,默认开启;如需关闭则加 Connection: close |
| 连接复用逻辑 | 仅当请求头带 keep-alive 时,服务器响应头也会返回该字段,才会保持连接 |
默认复用连接,直到空闲超时 / 请求数达上限 / 显式关闭 |
补充细节
-
长连接不是永久连接即便设置了
keep-alive,TCP 连接也不会一直保持:- 服务器会设置空闲超时时间(比如
Keep-Alive: timeout=30),超过时间无新请求则断开; - 服务器也可设置最大请求数(比如
Keep-Alive: max=100),达到上限后断开连接。
- 服务器会设置空闲超时时间(比如
-
与
Keep-Alive报头的关系Keep-Alive是配合Connection: keep-alive的附属字段,用于配置长连接的参数(超时时间、最大请求数)# 请求头 Connection: keep-alive Keep-Alive: timeout=30, max=100 -
请求头 vs 响应头
- 客户端发请求时带
Connection: keep-alive,表示 "希望保持连接"; - 服务器响应时也返回
Connection: keep-alive,表示 "同意保持连接"; - 只要一方返回
Connection: close,连接就会在响应后断开。
- 客户端发请求时带
请求报头
| Header 字段 | 作用说明 | 典型示例 |
|---|---|---|
Content-Type |
标识 Body 的数据类型(媒体类型) | text/html; charset=utf-8、application/json |
Content-Length |
描述 Body 的字节长度,帮助接收方确定数据边界 | 1024(表示 Body 长度为 1024 字节) |
Host |
客户端告知服务器,请求的资源所在的主机域名和端口 | Host: www.example.com:8080 |
User-Agent |
声明客户端的操作系统、浏览器版本等信息,便于服务器适配 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0 |
Referer |
告诉服务器当前页面是从哪个页面跳转而来,可用于防盗链 | Referer: https://www.example.com/index.html |
Location |
搭配 3xx 重定向状态码使用,指定客户端下一步要跳转的 URL | Location: https://www.example.com/home |
Cookie |
在客户端存储少量会话信息,用于维持用户登录状态等 | Cookie: SessionID=abc123; use |
对比get和post
参数传递方式
GET请求通过URL参数传递数据,即将查询字符串附加在URL之后。这种方式使得数据在浏览器地址栏中可见,便于用户分享和收藏,但不适合传递敏感信息。例如,在电商网站搜索商品时,关键词就是通过URL传递的。
POST请求则将数据放在请求体中,以表单形式提交。这种方式使得数据在浏览器地址栏中不可见,增加了数据的安全性,同时不受URL长度限制,适合传递大量数据。例如,在注册新用户或提交评论时,浏览器通常会发送POST请求。
数据大小限制
GET请求由于将参数放在URL中,因此受到URL长度的限制。这个长度限制主要由浏览器和Web服务器决定,不同浏览器和服务器可能有所不同。这限制了GET请求能够传递的数据量。
POST请求则没有这种限制,其数据大小只受到服务器端设置的处理数据大小的限制。因此,POST请求适合传递大量数据,如上传文件或提交复杂表单。
安全性
GET请求的参数暴露在URL上,可能被第三方获取,因此安全性较低。尤其是当传递敏感信息时,如密码、账户信息等,使用GET请求是不安全的。
POST请求的参数在HTTP消息体中,相对更难被获取,因此安全性略高。然而,这并不意味着POST请求完全安全。如果未采取其他安全措施,如使用HTTPS加密通信,数据仍然可能在传输过程中被截获。