一、内存管理的基石:为什么需要 GC
以前我写过 Redis 之整数集合,里面提到了这个数据结构的定义和内存申请及初始化。
c
// intset.h
typedef struct intset {
uint32_t encoding; /* 编码 */
uint32_t length; /* 数组 contents 长度 */
int8_t contents[]; /* 柔性数组,存储集合的整数数组 */
} intset;
c
// intset.c
/* Create an empty intset. */
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}其中 intsetNew 函数作用是
- 手动调用 zmalloc 向堆申请一块内存
- 初始化结构体字段
- 返回指针
此时,一个 intset "诞生" 了。
但问题也随之而来:它什么时候"被回收呢"?
当一个 SET 被删除、覆盖或过期时,Redis 会沿着对象引用链一路向下,最终在释放 SET 对象时,调用:
c
zfree(o->ptr); // o->ptr 正是 intset一次 zfree,这块连续内存被完整回收,生命周期宣告结束。
这在 C 世界里,是"理所当然"的事情。
对 Redis 而言,这样的设计非常合理:
- 内存申请是显式的
- 内存释放是确定的
- 生命周期完全可控
- 不存在"我以为它还活着,其实已经被回收"的情况
但代价也同样明显:
- 每一个对象的释放路径,都必须被人工正确地设计
- 一旦某个分支漏掉 zfree,就是内存泄漏
- 一旦释放过早,就是悬垂指针与未定义行为
在 Redis 这种对内存模型极度克制、工程经验极其成熟的项目中,这套模式可以被严格执行。
但在更复杂的业务系统中,这种"全靠人记住"的内存管理方式,很快就会变成灾难。
正是因为 C 语言世界中这种手动管理内存生命周期的复杂性,才催生了垃圾回收(Garbage Collection)机制。
GC 的核心问题,其实只有一个:对象什么时候可以被安全地回收?
与 Redis 的 intset 不同,在具备 GC 的语言里:
- 你仍然"创建对象"
- 但你不再显式地"销毁对象"
- 对象的回收时机,从程序员的责任,转移到了运行时系统
代价是:
- 运行时更复杂
- 需要额外的标记、扫描、暂停或并发机制
收益是:
- 极大降低了系统级 bug 的可能性
- 程序员可以把注意力从"内存的生死"转移到"业务的正确性"
二、常见垃圾回收算法概览
1. 标记-清除(Mark-Sweep)
先标记出所有存活对象,标记完后统一回收掉没有被标记的对象。
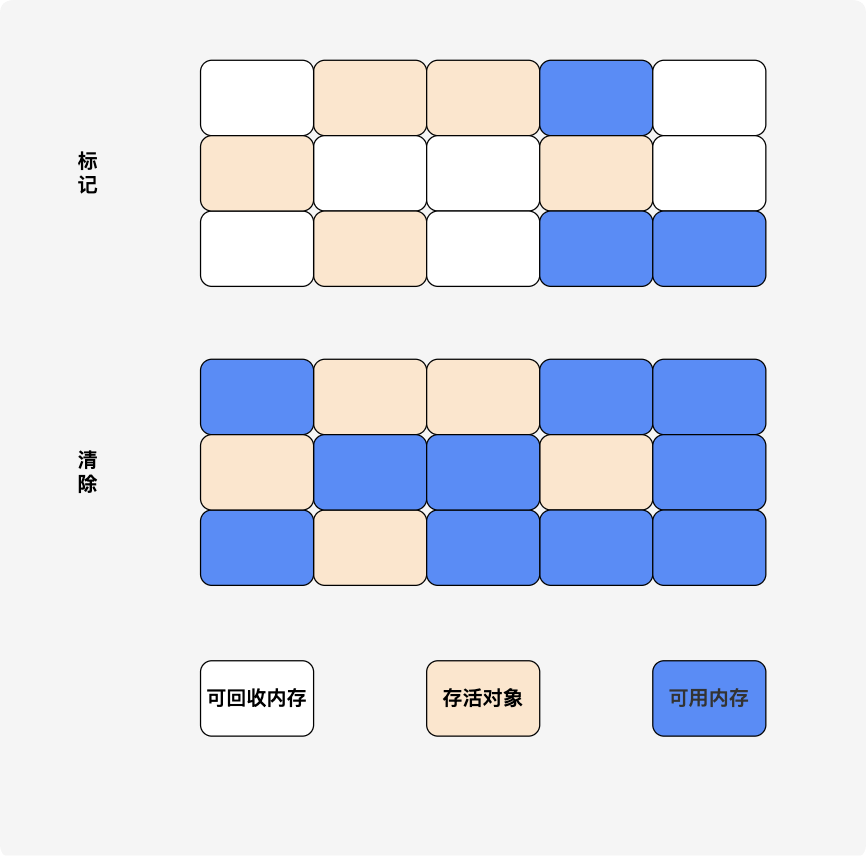
缺点:标记和清除的效率都不高;会产生大量不连续的内存碎片。
2. 标记压缩 (Mark-Compact)
标记后将所有存活对象向一端移动,然后清理掉端边界外的内存。
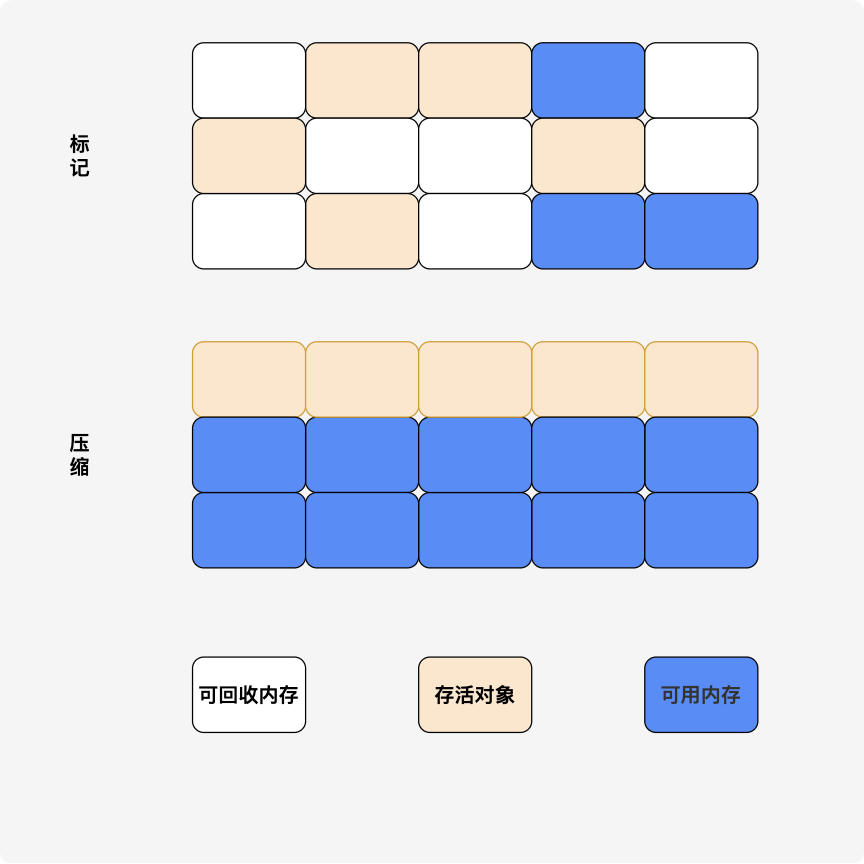
缺点:解决碎片,但复杂度高、耗时多。
3. 半空间复制(Copying GC)
确切说是复制算法,半空间复制是其实现的一种。
将内存分为大小相同的两块,每次使用其中的一块;当一块内存使用完后,就将存活对象复制到另一块,再将原来的一半内存全部回收。
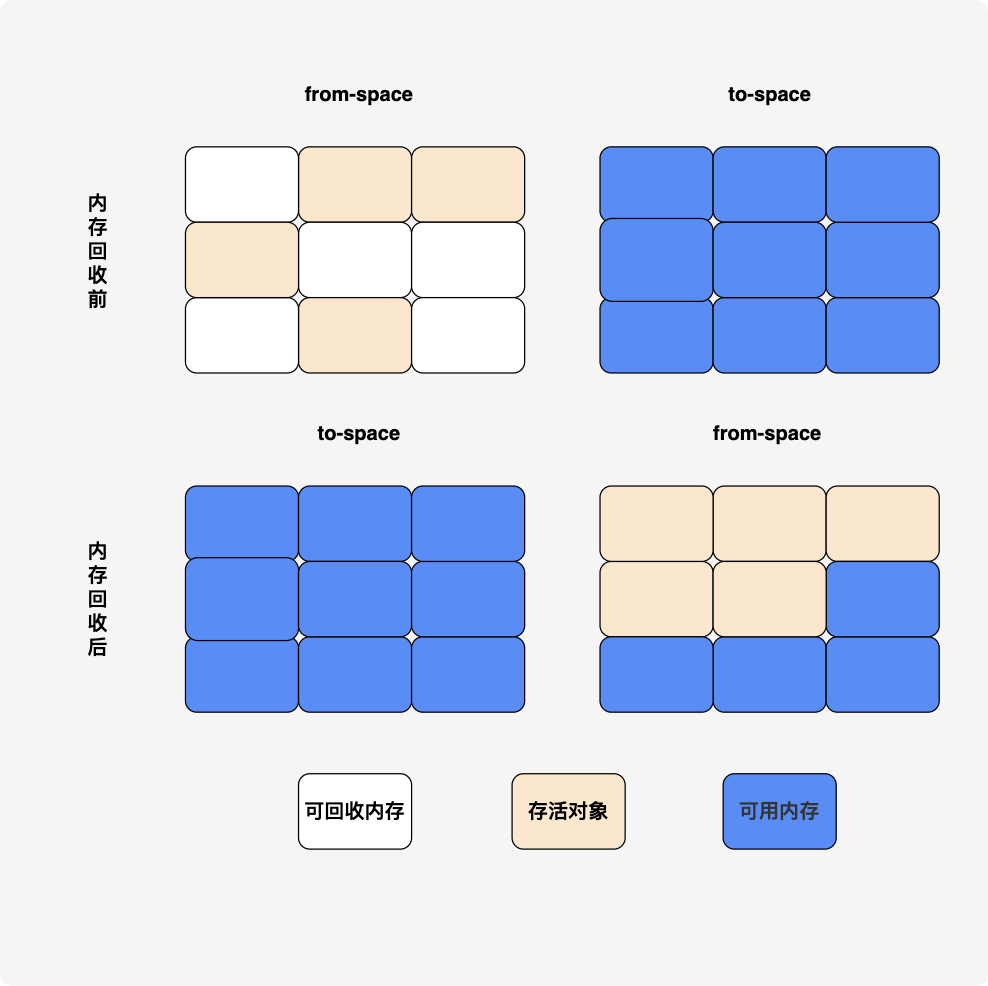
缺点:效率高,但内存利用率仅 50%,不适合内存敏感的服务端程序。
4. 引用计数 (Reference Counting)
规则非常简单:
- 引用 +1
- 删除引用 -1
- 计数为 0 即回收
缺点:实时性好,但无法解决循环引用(PHP 常用)。
5. 分代回收 (Generational)
在 JVM 等系统中:
- 堆被划分为年轻代 / 老年代
- 年轻代频繁回收
- 老年代低频回收
为什么要分代?
- 比如在新生代中,每次收集都会有大量对象死去,所以可以选择"复制"算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集;
- 而老年代的对象存活几率更高,且没有额外的空间对它进行分配担保,所以必须选择"标记-清除"或"标记-整理"算法。
tips:为什么 Go 不做"分代回收"?
- 核心原因:逃逸分析(Escape Analysis)。
- Go 在编译期就通过逃逸分析,将大量短生命周期的对象分配在了栈上。栈随函数调用结束直接销毁,根本不需要 GC 参与。
- 既然"绝大多数对象死于年轻代"的问题已经由栈解决了,堆上的存活对象比例相对较高,分代收益就不再明显。
三、Go GC 的进化史:从 STW 到亚毫秒停顿
Go 1.3 及之前:标记-清除 + 全 STW
- 机制:全过程 STW(Stop The World),标记完了再清除。
- 痛点:程序停顿时间随对象数量线性增长,动辄秒级停顿。
- 1.3 的微调:将 Sweep(清除)移出 STW,改为并发执行,但 Mark(标记)依然全量 STW。
1.3 之前
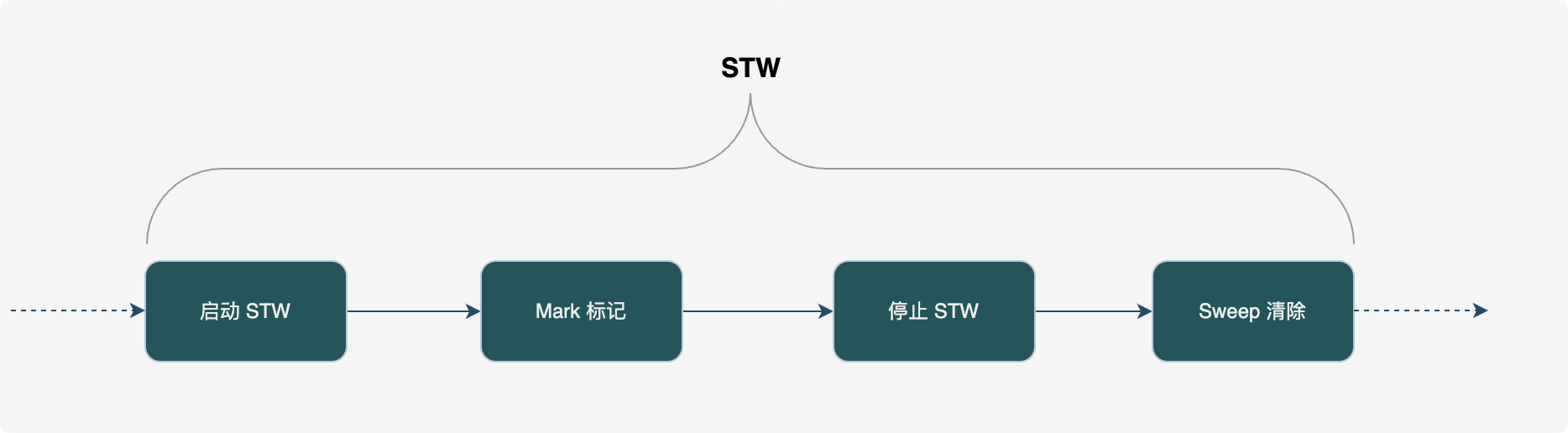
1.3
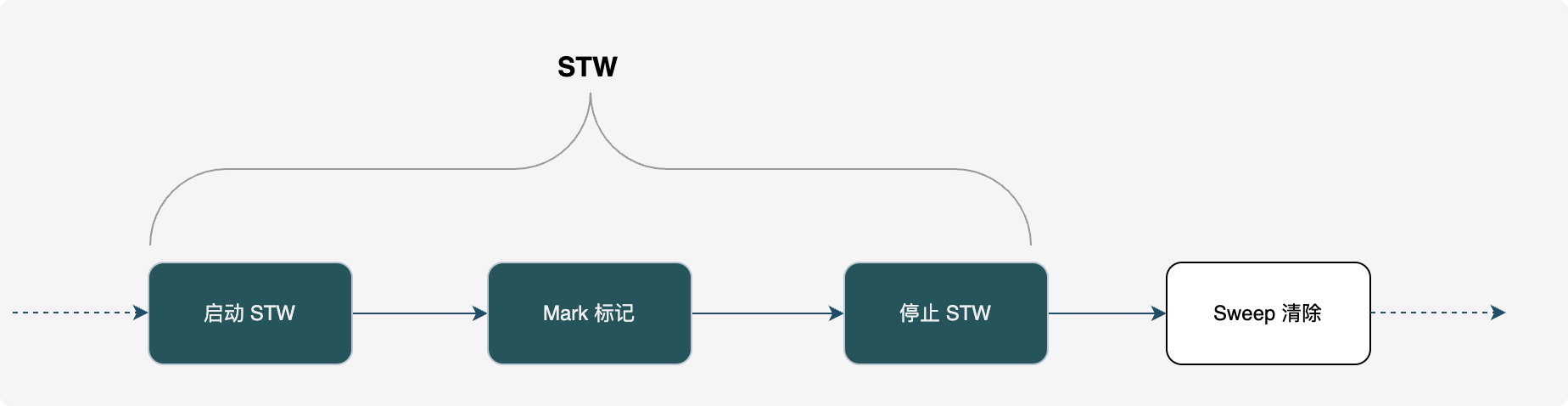
Go v1.5:三色标记法与插入写屏障(重大转折)
三色标记法
颜色定义:
- 白色:潜在垃圾,标记开始时全员白色。
- 灰色:自身存活,但子对象待扫描。
- 黑色:安全对象,自身及子对象均已确认存活。
标记流程
- Root 对象先标记
- 全局变量
- goroutine 栈
- 寄存器
- runtime 内部结构
- finalizer 队列
- 灰 → 扫描 → 黑
- 最终剩余白色对象即垃圾
核心挑战:漏标问题。当黑色对象引用白色对象,且灰色对象断开该白色对象时,白色对象会被误杀。
这正是并发 GC 必须引入写屏障的原因。
屏障机制
由于栈区对象创建、回收频繁,因此屏障机制只针对堆区,栈区没有屏障机制
三色不变性(核心原理):
- 强三色不变性:不允许黑色指向白色。【Go 没有采用这个(代价太高)】
- 弱三色不变性:黑色可以指向白色,但该白色必须有灰色链路保护。
Go 语言中使用两种写屏障技术,分别是 Dijkstra 提出的插入写屏障和 Yuasa 提出的删除写屏障(go v1.8 实现)。
插入写屏障(Dijkstra)
- 在新增引用时触发
- 将被引用对象标记为灰色
优点:
- 实现简单
- 保护新引用关系
缺点:
- 标记结束后必须 STW re-scan 栈,大约需要 10 -100 ms
我来解释下为什么要 re-scan:为了性能,栈上不开启屏障。这导致 GC 结束前无法确认栈上的黑对象是否偷偷引用了堆上的白对象。
场景重现:
- 初始状态 :
- 堆里的 灰色对象 G 引用着 白色对象 W。
- 栈上的 黑色对象 S (已经扫描完了)正准备去引用 W。
- 动作 1(接盘) :栈对象 S 引用了 W(
S.ref = W)。- 1.5 的反应 :因为写入发生在栈上,没有写屏障。此时 S 虽然引用了 W,但 GC 不知道。
- 动作 2(删除) :堆对象 G 断开了对 W 的引用(
G.ref = nil)。- 1.5 的反应 :因为 1.5 并没有删除屏障,所以这个动作也是静默的。
此时的危机:
- 在堆的视角(GC 扫描器的视角)看来,W 已经没有引用路径了,且 W 还是白色的。
- 在实际运行中,S(栈)正死死抓着 W。
- 如果不做任何处理,W 就会被当作垃圾回收掉,导致栈上的 S 变成悬空指针(程序崩溃)。
一句话总结就是:Go 1.5 插入写屏障只保障堆内"黑不指白",栈引用必须靠 STW 扫描修补,否则可能漏标导致悬空指针。
Mark Assist
并发标记虽然好,但有一个致命问题:如果业务协程(Mutator)分配内存的速度极快,而后台 GC 协程扫描得太慢,堆内存依然会由于来不及回收而暴涨。
为此,Go 1.5 引入了 Mark Assist。它建立了一套"债务系统":
- 如果后台标记协程(GC Worker)忙不过来,而业务协程分配内存太快,Go 会强迫业务协程停下手中的活,帮着 GC 去做标记。
- 影响:这解释了为什么有时候 GC 停顿很短,但业务吞吐量却下降了。
Go v1.8:混合写屏障(Hybrid Write Barrier)
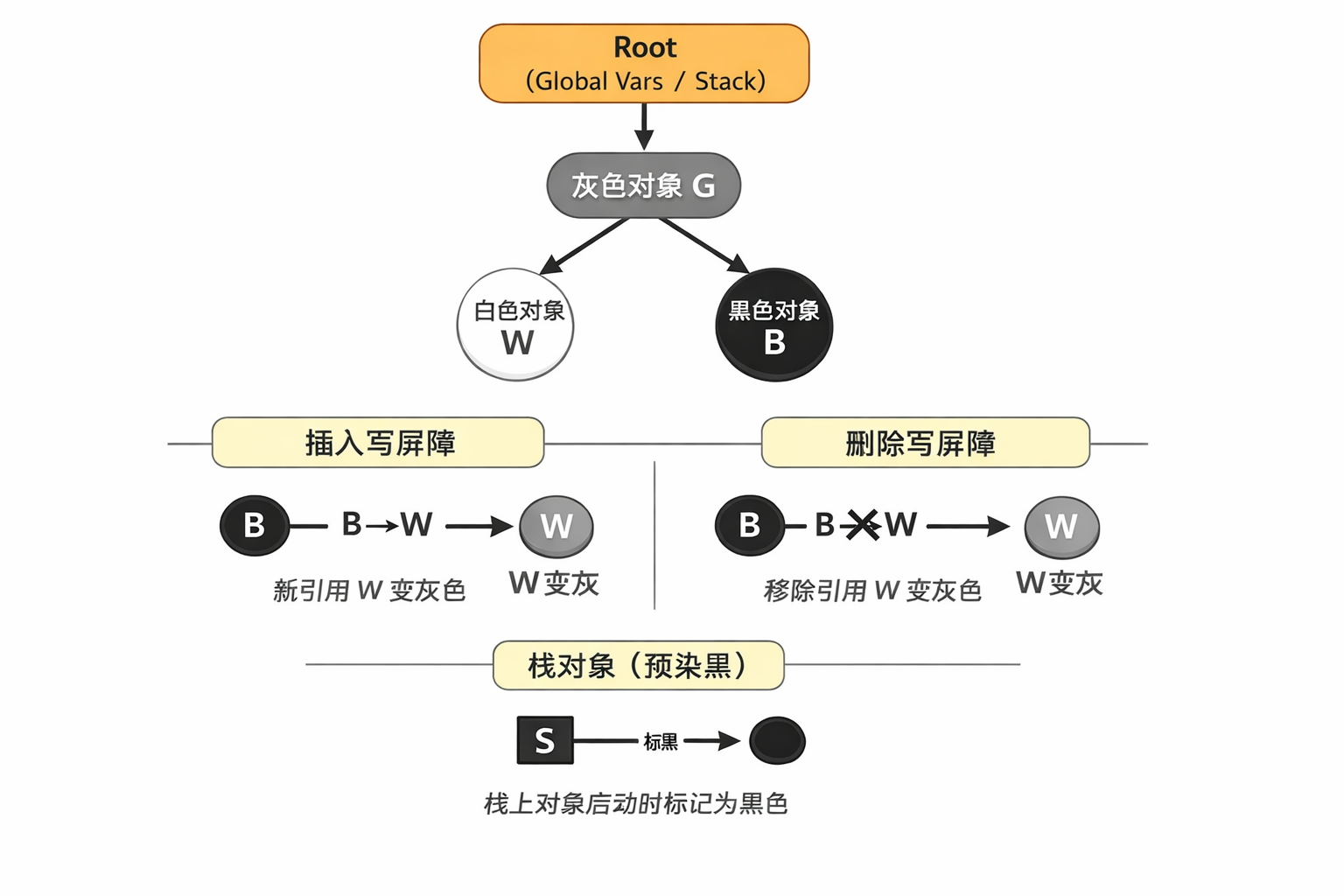
既然 re-scan 太慢,能不能在 GC 期间就把栈"封死"?
为了解决上面的这个短板, 来看看混合屏障的四大金刚规则:
- 栈预染黑(Stack Pre-Painting) :GC 开始时,一次性扫描并将栈上可达对象全部标黑。
- 新对象标黑:GC 期间,栈上新创建的对象直接标黑。
- 插入屏障逻辑:堆上黑指向白,白变灰。
- 删除屏障逻辑:堆上引用断开时,旧值变灰。
如何消除 re-scan
- 1.5 为什么重扫栈? 因为怕"黑栈引用了白堆,且堆上没屏障抓住它"。
- 1.8 为什么不重扫? 因为 1.8 引入了删除屏障。如果一个白色堆对象要被"黑栈"引用,它必然先要从某个"堆引用"中脱离(解引用/删除)。在它脱离堆的一瞬间,删除屏障就会把它染灰。它只要在变动的瞬间"亮了(变灰)",栈上没屏障也无所谓了,它已经安全了。
结果:STW 降至亚毫秒级(< 1ms)。
因此 1.8 之后,STW 停顿几乎只剩下亚毫秒级,极大减少 GC 对低延迟应用的影响。
Go 1.8 之后的 GC 工程化演进
在 1.8 解决了 STW 核心痛点后,后续版本的优化方向转向了 内存归还、调度效率、大内存支持和 CPU 开销控制。
Go 1.12:Scavenger(内存归还)优化
改进: 改进了向操作系统归还物理内存的机制。之前版本由于归还内存过于迟钝,常导致 RSS(实际物理内存占用)居高不下。1.12 引入了更主动的 Scavenger 进程。
Go 1.14:基于信号的异步抢占(STW 的终结者)
在 1.14 之前,如果你的代码里有一个没有任何函数调用的紧凑死循环(例如 for { i++ }),GC 可能会被"卡死"。因为旧版 Go 依靠协程主动让出。1.14 引入了基于 Unix 信号的异步抢占,GC 触发 STW 时可以强制"拍醒"那些沉迷于计算的协程。至此,Go 真正做到了在任何场景下都能保证亚毫秒级的延迟。
Go 1.18:GC Pacer(调步器)重构
改进: 彻底重构了 GC 触发的时机算法。
意义: 以前的 GC 触发比较死板,容易在负载突增时预测失效。1.18 后的 Pacer 更加智能,能根据当前的 CPU 使用率和内存分配速率动态调整 GC 触发点,平衡吞吐量和延迟。
Go 1.19:GOMEMLIMIT(里程碑式改进)
新增: 引入了软内存限制 GOMEMLIMIT 环境变量。
痛点: 以前只能通过 GOGC(百分比)控制。在容器环境(如 K8s)中,如果设置 GOGC=100,当内存接近容器限制时,GC 可能还未触发就导致 OOM。
解决: 现在可以设置 GOMEMLIMIT=2GiB。当内存接近这个值时,GC 会被频繁触发以榨干每一寸空间;如果还不够,它会强制归还内存,有效规避 OOM。
Go 1.19+ 后的最佳实践建议
- 设置方式: 在 K8s 部署时,建议将 GOMEMLIMIT 设置为容器内存限制的 80%~90%(留出一点余量给 CGO 或非堆内存)。
- 例如:容器限制 2GiB,设置 GOMEMLIMIT=1.8GiB。
- GOGC = off: 在极少数超大内存场景下,如果你设置了 GOMEMLIMIT,甚至可以把 GOGC 关掉(off),这样可以最大化利用内存,直到快满时才收割。
Go 1.21:GC 性能调优(减少 40% 尾部延迟)
改进: 优化了 GC 的内部调度逻辑,减少了标记工作对业务代码的影响。
效果: 官方宣称在部分应用中,GC 导致的尾部延迟(Tail Latency)降低了约 40%。
Go 1.23+ / 1.25 展望:Green Tea GC(实验性)
新技术: 社区和官方正在推进 Green Tea GC(基于 Span 的新算法)。
方向: 进一步优化小对象的扫描效率。它通过对象大小分类和批量扫描,试图将 GC 开销再降低 10%~40%。
结语
最后我们来看看 Go GC 关键版本演进总结表吧。
| 版本 | 核心技术演进 | 核心解决痛点 | STW 时间参考 | 备注 |
|---|---|---|---|---|
| Go 1.3 | 并发清理 (Sweep) | 减少了部分 STW 时间 | 数百毫秒级 | 标记过程仍需全量暂停 |
| Go 1.5 | 三色标记 + 插入写屏障 | 实现了并发标记 | 10ms ~ 100ms | 栈上无屏障,需 STW 重扫栈 |
| Go 1.8 | 混合写屏障 (Hybrid WB) | 消除栈重扫 (re-scan) | < 1ms (亚毫秒级) | 奠定现代 Go GC 架构基石 |
| Go 1.12 | Scavenger 归还优化 | 解决物理内存 (RSS) 居高不下 | 极稳定 | 更主动地将内存还给 OS |
| Go 1.14 | 非协作式抢占 (信号) | 解决死循环导致的 GC 卡死 | 极稳定 | 通过 SIGURG 信号强制夺回 CPU |
| Go 1.18 | GC Pacer 算法重构 | 解决复杂负载下触发时机不准 | 极稳定 | 引入控制理论,平滑 GC 压力 |
| Go 1.19 | 软内存限制 (GOMEMLIMIT) | 彻底规避容器环境 OOM | 极稳定 | 开发者最喜爱的生产环境利器 |
| Go 1.21 | GC 内部调度调优 | 降低 P99 尾部延迟 | 极稳定 | 尾部延迟(Tail Latency)减少 40% |
| Go 1.23+ | Green Tea GC (实验性) | 优化小对象扫描开销 | 极稳定 | 持续收割 10%-40% 的 CPU 开销 |