前言
在数据库支撑的业务系统中,性能瓶颈就像路上的堵点,直接拉低用户体验、影响业务正常运转。金仓数据库(KingbaseES)作为企业级解决方案,性能优化涉及SQL语句、索引设计、执行计划、资源配置等多个维度。下面我们就从SQL精调、执行计划优化、多核CPU利用等场景,给各位带来全景性能优化指南。

文章目录
- 前言
- 一、SQL语句精调:从源头减少性能损耗
-
- [1.1 基础语法优化技巧](#1.1 基础语法优化技巧)
- [1.2 逻辑优化规则应用](#1.2 逻辑优化规则应用)
- [1.3 实操代码示例](#1.3 实操代码示例)
- 二、执行计划优化:让优化器选对最优路径
-
- [2.1 统计信息精准维护](#2.1 统计信息精准维护)
- [2.2 执行计划分析与干预](#2.2 执行计划分析与干预)
- 三、多核CPU高效利用:并行查询释放硬件潜力
-
- [3.1 并行查询启用条件](#3.1 并行查询启用条件)
- [3.2 并行查询优化场景](#3.2 并行查询优化场景)
- [3.3 注意事项与实操代码](#3.3 注意事项与实操代码)
- 四、性能参数调优:适配硬件与业务场景
-
- [4.1 核心参数配置](#4.1 核心参数配置)
- 五、监控与持续优化:构建闭环调优体系
-
- [5.1 SQL监控工具](#5.1 SQL监控工具)
- [5.2 持续优化流程](#5.2 持续优化流程)
- [5.3 实操代码示例](#5.3 实操代码示例)
- 结语
- 附录:更多金仓干货看这里
一、SQL语句精调:从源头减少性能损耗
SQL语句是数据库的"沟通语言",低效SQL往往是性能问题的罪魁祸首。优化SQL不用搞复杂,遵循"简洁、精准、避坑"三大原则,从语法到逻辑逐步优化就行。
1.1 基础语法优化技巧
- 避免全表扫描踩坑 :查询时别用
SELECT *,只查需要的字段;大表查询如果没有重复数据,用UNION ALL替代UNION,省去去重排序的额外开销,速度能快不少。 - 消除隐式类型转换 :查询条件里字段类型和传入值要一致,比如
WHERE id = '100'得改成WHERE id = 100,不然索引会失效,相当于白建了。 - 优化子查询与连接 :像
WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.id=t1.id)这样的相关子查询,改成JOIN查询更高效,减少逐行执行的开销;多表连接一定要写清楚连接条件,避免出现笛卡尔积,数据量会暴增。
1.2 逻辑优化规则应用
借助金仓的kdb_rbo插件,能进一步提升SQL执行效率,这些规则不用手动写,开启插件就自动生效:
- 优化
count(distinct):通过kdb_rbo.attribute_distinct_value_threshold参数控制阈值(默认0.1),高基数列的去重计数性能会明显提升; - 谓词下推与条件化简:优化器会自动把WHERE/JOIN-ON条件推到数据源层面,减少中间结果集大小,省资源又省时间;
- 外连接自动转内连接:当WHERE子句满足"空值拒绝条件"时,优化器会自动把外连接转成内连接,降低连接开销。
1.3 实操代码示例
sql
-- 优化前:子查询效率低
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.id=t1.id);
-- 优化后:改写为JOIN查询
SELECT t1.* FROM t1 JOIN t2 ON t1.id=t2.id;
-- 优化前:UNION去重开销大
SELECT id FROM t1 UNION SELECT id FROM t2;
-- 优化后:无重复数据用UNION ALL
SELECT id FROM t1 UNION ALL SELECT id FROM t2;二、执行计划优化:让优化器选对最优路径
执行计划是SQL的"执行蓝图",优化器全靠它找最优路径,而执行计划的好坏,又依赖准确的统计信息。所以核心就是"让统计信息精准,让执行计划合理"。
2.1 统计信息精准维护
- 自动收集配置 :开启
autovacuum进程,默认就会自动收集,但可以微调参数让它更适配业务:autovacuum_analyze_threshold=50、autovacuum_analyze_scale_factor=0.1,表数据变动超过这个阈值,就会自动触发ANALYZE更新统计信息。 - 主动收集时机 :装载大量数据后、创建索引后、批量更新/删除数据后,手动执行
ANALYZE table_name(column1, column2),精准更新关键列的统计信息,避免优化器"误判"。 - 扩展统计信息 :多列关联查询(比如
WHERE a=1 AND b=1),单列表统计信息不准,就创建扩展统计:CREATE STATISTICS stts(dependencies) ON a,b FROM t,解决多条件选择率估算偏差。
2.2 执行计划分析与干预
- 查看执行计划 :用
EXPLAIN ANALYZE能看到实际执行情况,对比预估行数和实际行数,就能判断统计信息准不准;线上想捕获慢查询的执行计划,就启用auto_explain插件,设置auto_explain.log_min_duration=1000,自动记录执行时间超过1秒的SQL计划。 - 常见问题优化 :
- 统计信息不准:执行
ANALYZE VERBOSE table_name强制更新; - 缺少索引:针对过滤条件、连接条件创建合适的索引;
- 连接方式不当:小表连接用嵌套循环(NestLoop),大数据量随机分布用哈希连接(HashJoin),有序数据用归并连接(MergeJoin);
- 内存不足:排序、哈希连接时出现"external merge Disk",说明内存不够,调大
work_mem参数。
- 统计信息不准:执行
- HINT强制干预 :如果优化器选了次优计划,就用HINT手动指定,比如
/*+IndexScan(t1 idx_t1_id)*/强制走索引,/*+HashJoin(t1 t2)*/指定连接方式,/*+Parallel(t1 4)*/启用并行执行。
三、多核CPU高效利用:并行查询释放硬件潜力
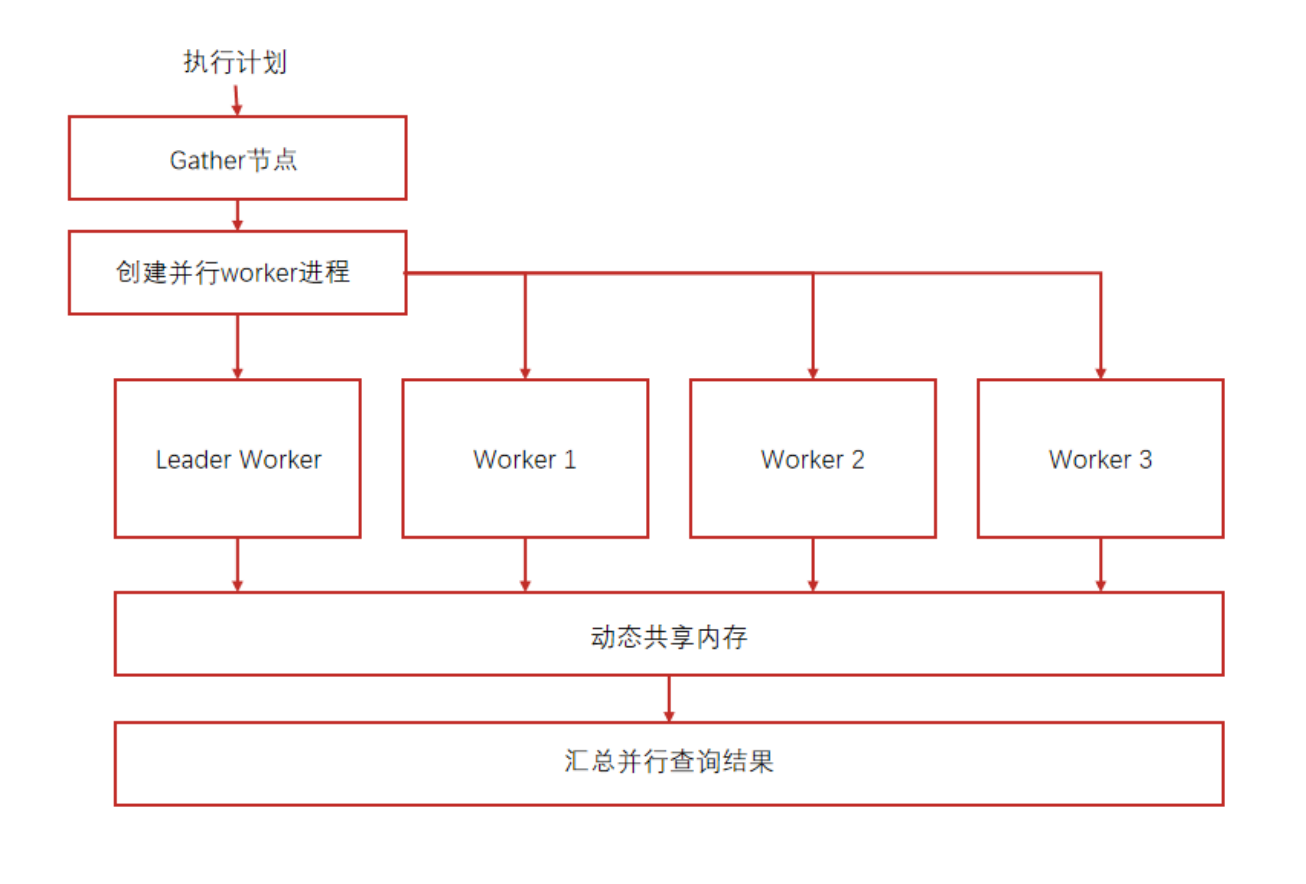
现在服务器都是多核CPU,而KingbaseES 能使用多核 CPU 来加速一个 SQL 语句的执行时间,这种特性被称为并行查询。由于现实条件的限制或因为没有比并行查询计划更快的查询计划存在,很多查询并不能从并行查询获益。但是,对于那些可以从并行查询获益的查询来说,并行查询带来的速度提升是显著的。很多查询在使用并行查询时查询速度比之前快了超过两倍,有些查询是以前的四倍甚至更多的倍数。
3.1 并行查询启用条件
- 参数配置 :关键是设置三个参数,满足
max_parallel_workers_per_gather ≤ max_parallel_workers ≤ max_worker_processes就行。比如服务器是8核CPU,可设置max_worker_processes=8、max_parallel_workers=6、max_parallel_workers_per_gather=4。 - 触发条件 :表存储空间≥
min_parallel_table_scan_size(默认8MB)、索引存储空间≥min_parallel_index_scan_size(默认512KB),优化器会自动评估是否启用并行。
3.2 并行查询优化场景
-
并行全表扫描 :大表过滤条件选择率低时(比如
WHERE age=6),启用并行扫描,多个worker同时读数据,扫描时间直接减半; -
并行连接与聚集 :多表连接、
count()/sum()等聚集操作,多个worker各自处理部分数据,最后汇总结果,效率翻倍; -
并行Append :
UNION ALL场景用/*+ParallelAppend(4)*/hint,多表合并查询速度更快。
3.3 注意事项与实操代码
- 控制并行度:高并发(OLTP)场景,并行进程多了会抢占资源,建议
max_parallel_workers_per_gather=2;数据分析(OLAP)场景可适当提高到4-6; - 避免过度并行:小表查询、简单查询启用并行反而浪费资源,优化器会自动评估,不用手动干预。
sql
-- 设置并行参数(kingbase.conf配置)
max_worker_processes = 8;
max_parallel_workers = 6;
max_parallel_workers_per_gather = 4;
-- 手动启用并行查询(HINT)
EXPLAIN ANALYZE /*+Parallel(t1 4)*/ SELECT count(*) FROM t1 WHERE age < 30;
-- UNION ALL场景启用并行Append
EXPLAIN ANALYZE /*+ParallelAppend(4)*/
SELECT * FROM t1 UNION ALL SELECT * FROM t2;四、性能参数调优:适配硬件与业务场景
参数调优就像给数据库"调配置",不用盲目改,根据硬件和业务场景微调,就能充分发挥资源潜力。
4.1 核心参数配置
- 内存参数 :
shared_buffers:数据库共享内存缓冲区,建议设为物理内存的20%-40%,比如16GB内存设为4GB,缓存热点数据减少磁盘IO;work_mem:排序、哈希连接用的内存,默认1MB,排序频繁的场景设为64MB-256MB,避免写临时文件;maintenance_work_mem:创建索引、VACUUM用的内存,默认16MB,创建大索引时设为512MB-1GB,加速索引构建。
- 成本参数 :
random_page_cost:随机页访问成本,默认4.0,用SSD硬盘就设为1.1-1.5,让优化器更倾向选索引扫描;cpu_tuple_cost:CPU处理元组的成本,默认0.01,CPU性能强就设为0.005,性能弱就设为0.02,让优化器更精准评估成本。
- 连接参数 :
geqo_threshold:基因查询优化阈值,默认12,表连接数超过12时启用启发式算法,平衡计划生成时间和质量。
五、监控与持续优化:构建闭环调优体系
性能优化不是"一劳永逸"的,得持续监控、持续调整,构建闭环体系,才能应对业务变化带来的新瓶颈。
5.1 SQL监控工具
启用sys_sqltune插件,通过V$SQL_MONITOR、V$SQL_PLAN_MONITOR视图,实时查看SQL执行状态、资源消耗、执行计划节点详情;还能生成TEXT或HTML格式的监控报告,直观分析SQL瓶颈。
- 生成 TEXT 版监控报告
sql
SELECT DBMS_SQL_MONITOR.REPORT_SQL_MONITOR(type=>'TEXT');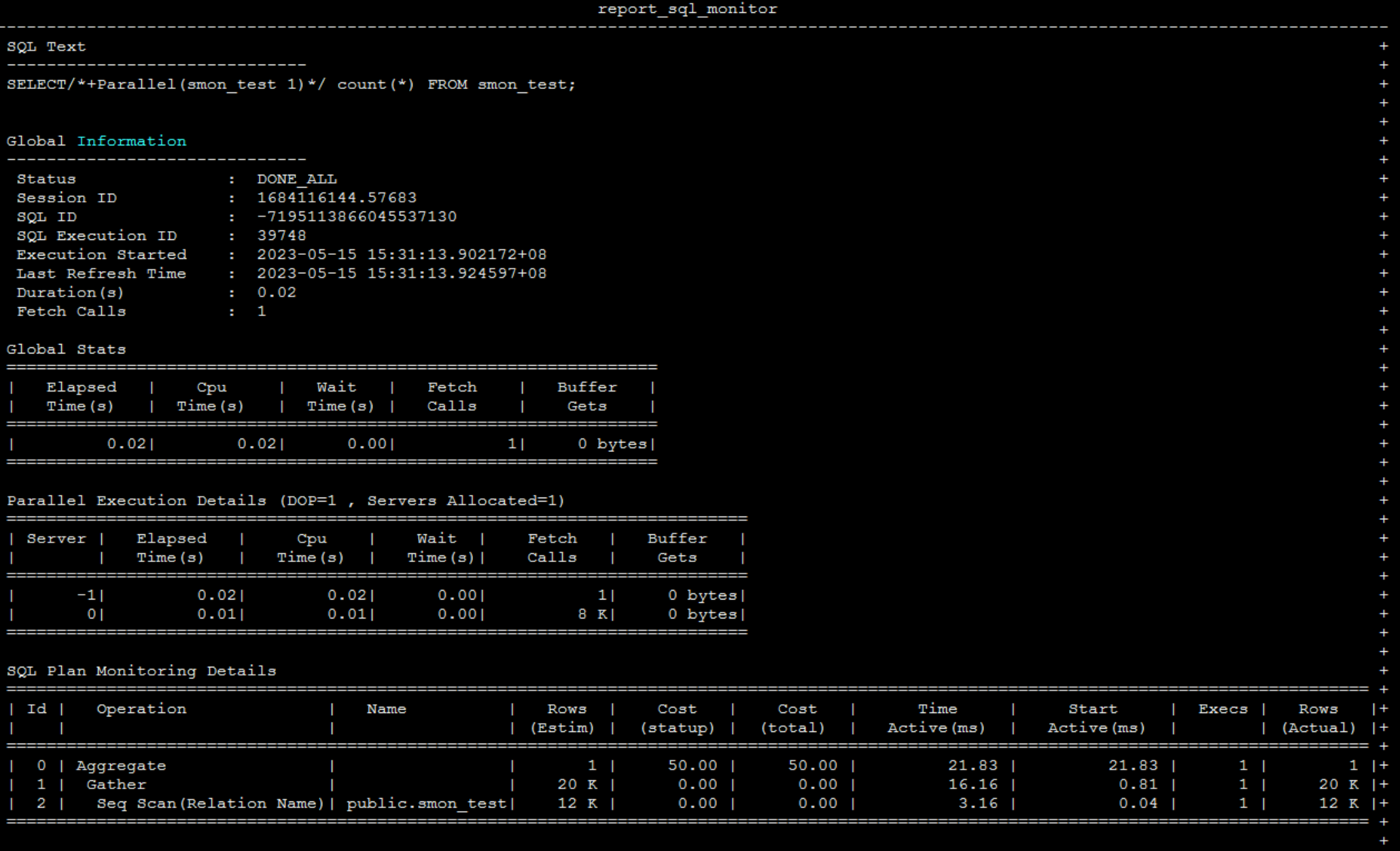
5.2 持续优化流程
- 识别高负载语句:通过
sys_stat_statements插件,找到执行频繁、耗时久的TOP SQL; - 分析性能瓶颈:结合执行计划和监控数据,定位是索引缺失、SQL写得不好,还是资源不够;
- 实施优化手段:针对性创建索引、改写SQL、调整参数、启用并行;
- 评估优化效果:用
EXPLAIN ANALYZE对比优化前后的执行时间和资源消耗; - 定期复盘:每季度检查索引使用情况、统计信息准确性、参数配置合理性,适配业务数据增长。
5.3 实操代码示例
sql
-- 启用sys_sqltune插件
CREATE EXTENSION sys_sqltune;
-- 查看TOP SQL
SELECT query, calls, total_time FROM sys_stat_statements ORDER BY total_time DESC LIMIT 10;
-- 生成SQL监控报告(TEXT格式)
SELECT DBMS_SQL_MONITOR.REPORT_SQL_MONITOR(type=>'TEXT');
-- 生成HTML格式监控报告(保存到文件)
SELECT PERF.REPORT_SQL_MONITOR_TO_FILE('sql_monitor_report.html', type=>'HTML');结语
Oracle 迁移 KingbaseES 可别只做 "语法平移"!核心关键是摸透底层逻辑的适配门道,这才是性能不打折的核心。作为深度兼容 Oracle 的国产数据库,KingbaseES 早就不只是复刻语法那么简单 ------ 在优化器智能、资源调度效率、存储性能这些核心硬实力上,已经实现对标甚至反超 Oracle 了。其实迁移后想彻底解决卡顿、执行慢的问题一点都不难:精准同步统计信息、顺着 KingbaseES 的优化器逻辑微调执行计划、重构适配的索引体系、优化资源配置、贴合语法特性做些小适配。把这几点做到位,KingbaseES 就能爆发出不输 Oracle 的性能潜力,稳稳撑起你的业务系统,跑得又快又稳!
附录:更多金仓干货看这里
- 专为企业数字化转型提供全方位知识支持的专业博客平台。涵盖数字化战略规划、数据集成、指标管理、数据可视化应用等各个方面的内容,助力企业数字化转型。
- 金仓社区涵盖了专业论坛、博客分享、学习资源、全站搜索、迁移工具和社区活动等多个板块,为用户提供了丰富的资源和支持。特别值得一提的是,社区还提供了丰富的在线视频课程和认证考试资源,帮助用户全面提升数据库技术能力。
- 金仓社区链接:https://bbs.kingbase.com.cn/