文章目录
- Python
-
- 第一章:Python介绍
-
- [1.1 概述](#1.1 概述)
- [1.2 环境部署](#1.2 环境部署)
- [1.3 开发工具](#1.3 开发工具)
- [1.4 Python模块](#1.4 Python模块)
-
- [1.4.1 安装模块](#1.4.1 安装模块)
- [1.4.2 pip镜像源设置](#1.4.2 pip镜像源设置)
- 第二章:Python基础
-
- [2.1 代码格式](#2.1 代码格式)
- [2.2 标识符和关键字](#2.2 标识符和关键字)
- [2.3 变量和数据类型](#2.3 变量和数据类型)
- [2.4 课堂练习](#2.4 课堂练习)
-
- [2.4.1 打印购物票](#2.4.1 打印购物票)
- [2.4.2 蚂蚁森林](#2.4.2 蚂蚁森林)
- [2.5 数字类型](#2.5 数字类型)
-
- [2.5.1 整型](#2.5.1 整型)
- [2.5.2 浮点类型](#2.5.2 浮点类型)
- [2.5.3 复数类型](#2.5.3 复数类型)
- [2.5.4 布尔类型](#2.5.4 布尔类型)
- [2.5.5 数字类型转换](#2.5.5 数字类型转换)
- [2.6 运算符](#2.6 运算符)
-
- [2.6.1 算数运算符](#2.6.1 算数运算符)
- [2.6.2 赋值运算符](#2.6.2 赋值运算符)
- [2.6.3 比较运算符](#2.6.3 比较运算符)
- [2.6.4 逻辑运算符](#2.6.4 逻辑运算符)
- [2.6.5 成员运算符](#2.6.5 成员运算符)
- [2.6.6 位运算](#2.6.6 位运算)
- [2.6.7 运算符优先级](#2.6.7 运算符优先级)
- [2.7 总结](#2.7 总结)
- 第三章:流程控制
-
- [3.1 条件语句](#3.1 条件语句)
-
- [3.1.1 if语句](#3.1.1 if语句)
- [3.1.2 if-else语句](#3.1.2 if-else语句)
- [3.1.3 if-elif-else语句](#3.1.3 if-elif-else语句)
- [3.1.4 if嵌套](#3.1.4 if嵌套)
- [3.2 课堂练习](#3.2 课堂练习)
-
- [3.2.1 猜数字](#3.2.1 猜数字)
- [3.3 循环语句](#3.3 循环语句)
-
- [3.3.1 while语句](#3.3.1 while语句)
- [3.3.2 for语句](#3.3.2 for语句)
- [3.3.3 循环嵌套](#3.3.3 循环嵌套)
- [3.4 实训案例](#3.4 实训案例)
-
- [3.4.1 逢七拍手游戏](#3.4.1 逢七拍手游戏)
- [3.5 跳转语句](#3.5 跳转语句)
-
- [3.5.1 break语句](#3.5.1 break语句)
- [3.5.2 continue 语句](#3.5.2 continue 语句)
- [3.6 本章小结](#3.6 本章小结)
- 第四章:字符串
-
- [4.1 字符串介绍](#4.1 字符串介绍)
- [4.2 格式化字符串](#4.2 格式化字符串)
-
- [4.2.1 使用%格式化字符串](#4.2.1 使用%格式化字符串)
- [4.2.2 使用format()方法格式化字符串](#4.2.2 使用format()方法格式化字符串)
- [4.2.3 使用f-string格式化字符串](#4.2.3 使用f-string格式化字符串)
- [4.3 实训案例](#4.3 实训案例)
-
- [4.3.1 进制转换](#4.3.1 进制转换)
- 4.4字符串的常见操作
- [4.5 实例案例](#4.5 实例案例)
-
- [4.5.1 敏感词替换](#4.5.1 敏感词替换)
- [4.6 本章小结](#4.6 本章小结)
- 第五章:组合数据类型
-
- [5.1 认识组合数据类型](#5.1 认识组合数据类型)
- [5.2 列表](#5.2 列表)
-
- [5.2.1 创建列表](#5.2.1 创建列表)
- [5.2.2 访问列表元素](#5.2.2 访问列表元素)
- [5.2.3 添加元素](#5.2.3 添加元素)
- [5.2.4 元素排序](#5.2.4 元素排序)
- [5.2.5 删除元素](#5.2.5 删除元素)
- [5.2.6 列表推导式](#5.2.6 列表推导式)
- [5.2.7 成绩录入系统](#5.2.7 成绩录入系统)
- [5.3 元组](#5.3 元组)
- [5.4 实例案例](#5.4 实例案例)
-
- [5.4.1 神奇魔方](#5.4.1 神奇魔方)
- [5.5 集合](#5.5 集合)
- [5.6 字典](#5.6 字典)
-
- [5.6.1 创建字典](#5.6.1 创建字典)
- [5.6.2 字典的访问](#5.6.2 字典的访问)
- [5.6.3 字典元素的添加和修改](#5.6.3 字典元素的添加和修改)
- [5.6.4 字典元素的删除](#5.6.4 字典元素的删除)
- [5.6.5 字典推导式](#5.6.5 字典推导式)
- [5.7 实训案例](#5.7 实训案例)
- [5.8 本章小结](#5.8 本章小结)
- [第六章 函数](#第六章 函数)
-
- [6.1 函数概述](#6.1 函数概述)
- [6.2 函数的定义和调用](#6.2 函数的定义和调用)
-
- [6.2.1 定义函数](#6.2.1 定义函数)
- [6.2.2 调用函数](#6.2.2 调用函数)
- [6.3 函数参数传递](#6.3 函数参数传递)
- [6.4 函数的返回值](#6.4 函数的返回值)
- [6.5 变量作用域](#6.5 变量作用域)
-
- [6.5.1 局部变量和全局变量](#6.5.1 局部变量和全局变量)
- [6.5.2 global和nonlocal关键字](#6.5.2 global和nonlocal关键字)
- [6.6 实例案例](#6.6 实例案例)
-
- [6.6.1 角谷猜想](#6.6.1 角谷猜想)
- [6.7 特殊形式的函数](#6.7 特殊形式的函数)
-
- [6.7.1 递归函数](#6.7.1 递归函数)
- [6.7.2 匿名函数](#6.7.2 匿名函数)
- [6.8 项目案例-学生管理系统](#6.8 项目案例-学生管理系统)
- [6.9 本章小结](#6.9 本章小结)
- 第七章:文件与数据格式化
-
- [7.1 文件概述](#7.1 文件概述)
- [7.2 文件的基础操作](#7.2 文件的基础操作)
-
- [7.2.1 文件的打开与关闭](#7.2.1 文件的打开与关闭)
- [7.2.2 文件的读写](#7.2.2 文件的读写)
- [7.2.3 文件的定位读写](#7.2.3 文件的定位读写)
- [7.3 文件与目录管理](#7.3 文件与目录管理)
- [7.4 实训案例](#7.4 实训案例)
-
- [7.4.1 信息安全策略-文件备份](#7.4.1 信息安全策略-文件备份)
- [7.5 数据维度](#7.5 数据维度)
-
- [7.5.1 基于维度的数据分类](#7.5.1 基于维度的数据分类)
- [7.5.2 一维数据和二维数据的存储与读写](#7.5.2 一维数据和二维数据的存储与读写)
- [7.5.3 多维数据的格式化](#7.5.3 多维数据的格式化)
- [7.6 本章小结](#7.6 本章小结)
- 第八章:面向对象
-
- [8.1 面向对象概述](#8.1 面向对象概述)
- [8.2 类的定义与使用](#8.2 类的定义与使用)
-
- [8.2.1 类的定义](#8.2.1 类的定义)
- [8.2.2 对象的创建与使用](#8.2.2 对象的创建与使用)
- [8.3 类的成员](#8.3 类的成员)
-
- [8.3.1 属性](#8.3.1 属性)
- [8.3.2 方法](#8.3.2 方法)
- [8.3.3 私有成员](#8.3.3 私有成员)
- [8.4 特殊方法](#8.4 特殊方法)
-
- [8.4.1 构造方法](#8.4.1 构造方法)
- [8.4.2 析构方法](#8.4.2 析构方法)
- [8.6 封装](#8.6 封装)
- [8.7 继承](#8.7 继承)
-
- [8.7.1 单继承](#8.7.1 单继承)
- [8.7.2 多继承](#8.7.2 多继承)
- [8.7.3 重写](#8.7.3 重写)
- [8.8 多态](#8.8 多态)
- [8.10 实例](#8.10 实例)
- [8.12 本章小结](#8.12 本章小结)
- [第九章 异常](#第九章 异常)
-
- [9.1 异常概述](#9.1 异常概述)
-
- [9.1.1 异常示例](#9.1.1 异常示例)
- [9.1.2 异常类型](#9.1.2 异常类型)
-
- 1)NameError
- 2)IndexError
- [3) AttributeError](#3) AttributeError)
- 4)FileNotFoundError
- [9.2 异常捕获语句](#9.2 异常捕获语句)
-
- [9.2.1 try-except语句捕获异常](#9.2.1 try-except语句捕获异常)
- [9.2.2 异常结构中的else子句](#9.2.2 异常结构中的else子句)
- [9.2.3 异常结构中的finally子句](#9.2.3 异常结构中的finally子句)
- [9.3 抛出异常](#9.3 抛出异常)
- [9.4 自定义异常](#9.4 自定义异常)
- [9.5 本章小结](#9.5 本章小结)
-
- [9.2.2 异常结构中的else子句](#9.2.2 异常结构中的else子句)
- [9.2.3 异常结构中的finally子句](#9.2.3 异常结构中的finally子句)
- [9.3 抛出异常](#9.3 抛出异常)
- [9.4 自定义异常](#9.4 自定义异常)
- [9.5 本章小结](#9.5 本章小结)
Python
第一章:Python介绍
1.1 概述
1.2 环境部署
1.3 开发工具
1.4 Python模块
1.4.1 安装模块
刚才编写的Python程序只有极少的代码,实现的功能非常简单。随着程序复杂度的提高,代码量会同步增长,这时若还是在一个文件中编写代码,代码的维护就会越来越困难。为了保证代码的可维护性,开发人员通常将一些功能性代码放在其他文件中,这样用于存放功能性代码的文件就是模块 。作为一种强大且便捷的编程语言,Python自然支持以模块的形式组织代码。Python内置了一些标准模块 ,Python的使用者也贡献了丰富且强大的第三方模块;标准模块可以直接导入与使用,第三方模块则需先行安装。
Python内置的pip工具(安装Python3.12时会自动安装该工具)可以非常方便地安装Python第三方模块,该工具可在命令行中使用,语法格式如下:
python
pip install 模块名
python
pip install pygame解决超时报错:
原因:国内镜像源未设置,需要配置pip.in
1.4.2 pip镜像源设置
python
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple生成pip.ini文件后,再编辑添加镜像源
bash
[global]
timeout=40
index-url=http://mirrors.aliyun.com/pypi/simple/
extra-index-url=
https://pypi.tuna.tsinghua.edu.cn/simple/
http://pypi.douban.com/simple/
http://pypi.mirrors.ustc.edu.cn/simple/
[install]
trusted-host=
pypi.tuna.tsinghua.edu.cn
mirrors.aliyun.com
pypi.douban.com
pypi.mirrors.ustc.edu.cn检查安装是否成功
bash
pip list第二章:Python基础
2.1 代码格式
可提升代码的可读性,与其他语言不同,Python代码的格式是Python语法的组成之一,不符合格式规范的Python代码无法正常运行。
2.1.1 注释
1)单行注释
以"#"开头,用于说明当前行或之后代码的功能。单行注释既可以单独占一行,也可以位于标识的代码之后,与标识的代码共占一行。
bash
# 单行注释,打印Hello,Python
print("Hello,Python")建议:为了确保注释的可读性,Python官方建议"#"后面先添加一个空格,再添加相应的说明文字;若单行注释与代码共占一行,注释和代码之间至少应有两个空格。
2)多行注释
由三对双引号或单引号包裹的语句,主要用于说明函数或类的功能。因此多行注释也被称为说明文档。
python
...
height = input("请输入您的身高(单位为米):")
print("您的身高:",height)
weight = input("请输入您的体重(单位为公斤):")
print("您的体重:",weight)
bmi = float(weight)/(float(height)*float(height))
print("您的BMI指数:",bmi)
if bmi < 18.5:
print("您的体重过轻!")
if bmi >= 18.5 and bmi <24.9:
print("正常范围,继续保持!")
if bmi >= 24.9 and bmi <29.9:
print("您体重过重!")
if bmi >= 29.9:
print("该减肥了!")
'''2.1.2 缩进
Python代码的缩进可以通过Tab键控制,也可使用空格控制。空格是Python3首选的缩进方法,一般使用4个空格表示一级缩进;**Python3不允许混合使用Tab和空格。**示例如下
python
if True:
print ("True")
else:
print ("False")
print ("False")代码缩进量的不同会导致代码语义的改变,Python语言要求同一代码块的每行代码必须具有相同得缩进量。程序中不允许出现无意义或者不规范的缩进,否则运行时会产生错误。示例如下
python
if True:
print ("True")
else:
print ("False")
print ("hello")上面最后一行代码的缩进量不符合规范,程序在运行后会出现错误,具体如下:
python
File "F:\PycharmProjects\pythonProject1\pycode\mygame.py", line 5
print ("hello")
^
IndentationError: unindent does not match any outer indentation level2.1.3 语句换行
Python官方建议每行代码不超过79个字符,若代码过长应该换行。Python会将圆括号、中括号和大括号中的行进行隐式连接,我们可以根据这个特点实现过长语句的换行显示。
python
string = ("Python是一种面向对象、解释型计算机程序设计语言,"
"由Guido van Rossum于1989年底发明。"
"第一个公开发行版发行于1991年,"
"Python源代码同样遵循GPL(GNU General Public License)协议。")注意:原本由圆括号、中括号和大括号包裹的语句在换行时不需要另外添加圆括号
python
number = ["one","two",
"three","four"]
print(number)2.2 标识符和关键字
在程序中表示一些事物,开发人员需要自定义一些符号和名称,这些符号和名称叫做标识符。 Python中的标识符需要遵守一定的规则。
命名规则:
1)标示符由字母、下划线和数字组成,且数字不能开头。
2)Python中的标识符是区分大小写的。例如,tom和Tom是不同的标识符。
3)Python中的标识符不能使用关键字 。
为了规范命名标识符,关于标识符的命名提以下建议:
1)见名知意。(姓名:name;年龄:age)
2)常量名使用大写的单个单词或由下画线连接的多个单词(ORDER_LIST_LIMIT)。
3)模块名、函数名使用小写的单个单词或由下画线连接的多个单词(low_with_under)。
4)类名使用大写字母开头的单个或多个单词。(Cat,Dog,Person)
关键字是Python已经使用的、不允许开发人员重复定义的标识符。Python3中一共有35个关键字,每个关键字都有不同的作用。
python
import keyword
print(keyword.kwlist)
python
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
获取命令字声明
python
import keyword
print(help("for"))
python
The "for" statement
*******************
The "for" statement is used to iterate over the elements of a sequence
(such as a string, tuple or list) or other iterable object:
for_stmt: "for" target_list "in" starred_expression_list ":" suite
["else" ":" suite]2.3 变量和数据类型
2.3.1 变量
变量:用拉丁字母表示的,值不固定的数据。
程序在运行期间用到的数据会被保存在计算机的内存单元中,为了方便存取内存单元中的数据,Python使用标识符来标识不同的内存单元,如此,标识符与数据建立了联系。
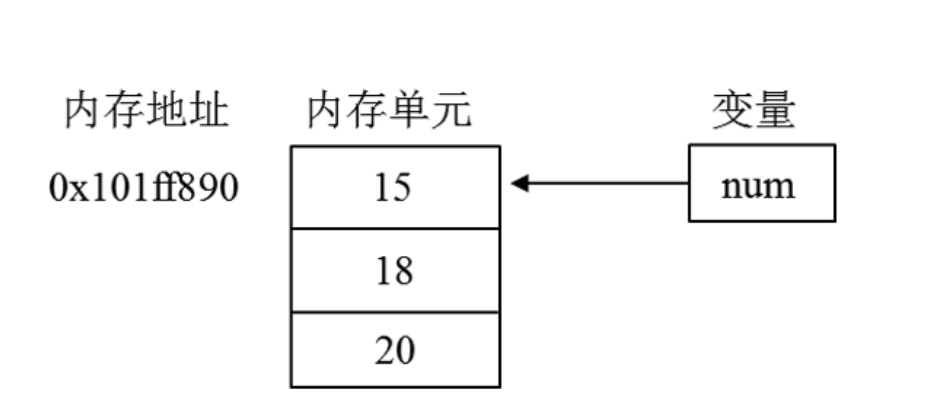
标识内存单元的标识符又称为变量名,Python通过赋值运算符"="将内存单元中存储的数值与变量名建立联系,即定义变量,具体语法格式如下:变量 = 值
将内存单元中存储的数据100与变量名data建立联系,如下所示
python
date = 1002.3.2 数据类型
根据数据存储形式的不同,数据类型分为基础的数字类型和比较复杂的组合类型,其中数字类型又分为整型、浮点型、布尔类型和复数类型;组合类型分为字符串、列表、元组、字典等。

1)数字类型
Python内置的数字类型有整型(int)、浮点型(float)、复数类型(complex)和布尔类型(bool),其中int、float和complex分别对应数学中的整数、小数和复数;bool类型比较特殊,它是int的子类,只有True和False两种取值。
python
整型: 0 101 -239 False True
浮点型: 3.1415 4.2E-10 -2.334E-9
复数类型: 3.12+1.2.3j -1.23-93j
布尔类型: True False2)字符串
字符串是一个由单引号、双引号或者三引号包裹的、有序的字符集合。
python
使用单引号包含: 'Python123¥'
使用双引号包含: "Python3*&%"
使用三引号包含: '''Python s1 ~(())'''3)列表
列表是多个元素的集合,它可以保存任意数量、任意类型的元素,且可以被修改。Python中使用"\[\]"创建列表,列表中的元素以逗号分隔。
python
[1, 2, 'hello']4)元祖
元组与列表的作用相似,它可以保存任意数量与类型的元素,但不可以被修改。Python中使用"()"创建元组,元组中的元素以逗号分隔
python
(1,2,'hello')5)集合
集合与列表和元组类似,也可以保存任意数量、任意类型的元素,不同的是,集合使用"{}"创建,集合中的元素无序且唯一。
python
{'apple', 'orange', 1}6)字典
字典中的元素是"键(Key):值(Value)"形式的键值对,键不能重复。Python中使用"{}"创建字典,字典中的各元素以逗号分隔
python
{"name": "zhangsan", "age": 18}可以使用type()查看数据类型
python
info = {"name": "zhangsan", "age": 18}
print(type(info))
python
<class 'dict'>2.3.3 变量的输入和输出
程序要实现人机交互功能,需能从输入设备接收用户输入的数据,也需要向显示设备输出数据。
1)input函数
input()函数用于接收用户键盘输入的数据,返回一个字符串类型的数据,其语法格式如下所示:
python
input([prompt])prompt表示函数的参数,用于设置接收用户输入时的提示信息。
python
number=input("请输入数字:")
print(type(number))运行结果
python
请输入数字:10
<class 'str'>2)print()函数
print()函数用于向控制台中输出数据,它可以输出任何类型的数据,其语法格式如下所示:
python
print(*objects, sep=' ', end='\n', file=sys.stdout)
python
objects:表示输出的对象。输出多个对象时,对象之间需要用分隔符分隔。
sep:用于设定分隔符,默认使用空格作为分隔。
end:用于设定输出以什么结尾,默认值为换行符\n。
file:表示数据输出的文件对象。代码示例
python
zh_name="张三"
en_name="tom"
info="年龄18岁,毕业于南京大学,兴趣爱好广泛"
print(zh_name,en_name,info,sep="\n")运行结果
python
张三
tom
年龄18岁,毕业于南京大学,兴趣爱好广泛2.4 课堂练习
2.4.1 打印购物票
购物小票又称购物收据,是指消费者购买商品时由商场或其它商业机构给用户留存的销售凭据。购物小票中一般会包含用户购买的商品名称、数量、单价以及总金额等信息。本实例要求编写代码,实现打印购物小票的功能。
2.4.2 蚂蚁森林
蚂蚁森林是支付宝客户端发起"碳账户"的一款公益活动:用户通过步行、地铁出行、在线消费等行为,可在蚂蚁森林中获取能量,当能量到达一定数值后,用户可以在支付宝中申请一颗虚拟的树,申请成功后会收到支付宝发放的一张植树证书。植树证书中包含申请日期、树苗编号等信息。本实例要求编写代码,实现打印植树证书信息的功能。
2.5 数字类型
2.5.1 整型
整数类型(int)简称整型,它用于表示整数。整型常用的计数方式有4种,分别是二进制(以"0B"或"0b"开头)、八进制(以数字"0o"或"0O"开头)、十进制和十六进制(以"0x"或"0X"开头)。
python
0b101 # 二进制
0o5 # 八进制
5 # 十进制
0x5 # 十六进制为了方便使用各进制的数据,Python中内置了用于转换数据进制的函数:bin()、oct()、int()、hex(),关于这些函数的功能说明如下。

代码示例
python
number = 10
bin_num = 0b1010
print("10的二进制:",bin(number))
print("10的八进制:",oct(number))
print("0b1010的十进制",int(bin_num))
print("10的十六进制",hex(number))运行结果
python
10的二进制: 0b1010
10的八进制: 0o12
0b1010的十进制 10
10的十六进制 0xa2.5.2 浮点类型
浮点型(float)用于表示实数,由整数和小数部分(可以是0)组成例如,3.14、0.9等。较大或较小的浮点数可以使用科学计算法表示。
科学计数法会把一个数表示成a与10的n次幂相乘的形式,数学中科学计数法的格式为:
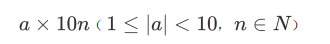
Python程序中使用字母e或E代表底数10
python
-3.14e2 # 即-314
3.14e-3 # 即0.00314Python中的浮点型每个浮点型数据占8个字节(即64位),且遵守IEEE标准。Python中浮点型的取值范围为-1.8e308~1.8e308,若超出这个范围,Python会将值视为无穷大(inf)或无穷小(-inf)。
2.5.3 复数类型
复数由实部和虚部构成,它的一般形式为:real+imagj,其中real为实部,imag为虚部,j为虚部单位。示例如下:
python
complex_one = 1 + 2j # 实部为1,虚部为2
complex_two = 2j # 实部为0,虚部为2代码示例
python
complex_num = 1+2j
print(complex_num.real)
print(complex_num.imag)运行结果
python
1.0
2.02.5.4 布尔类型
布尔类型(bool)是一种特殊的整型,其值True对应整数1,False对应整数0。
python
None。
False。
任何数字类型的0,如0、0.0、0j。
任何空序列,如''''、()、[]。
空字典,如{}。代码示例
python
print(bool(0))
print(bool(''))
print(bool(1))运行结果
python
False
False
True2.5.5 数字类型转换
Python内置了一系列可实现强制类型转换的函数,使用这些函数可以将目标数据转换为指定的类型。数字类型间进行转换的函数有int()、float()、complex()。需要注意的是浮点型数据转换为整型数据后只保留整数部分。

代码示例
python
num_one=2
num_two=2.2
print(int(num_two))
print(float(num_one))
print(complex(num_one))运行结果
python
2
2.0
(2+0j)2.6 运算符
Python运算符是一种特殊的符号,主要用于实现数值之间的运算。根据操作数数量的不同,运算符可分为单目运算符、双目运算符;根据运算符的功能,运算符可分为算术运算符、赋值运算符、比较运算符、逻辑运算符和成员运算符。
2.6.1 算数运算符
Python中的算术运算符包括+、-、*、/、//、%和**。以操作数a = 2,b = 8为例对算术运算符进行使用说明。
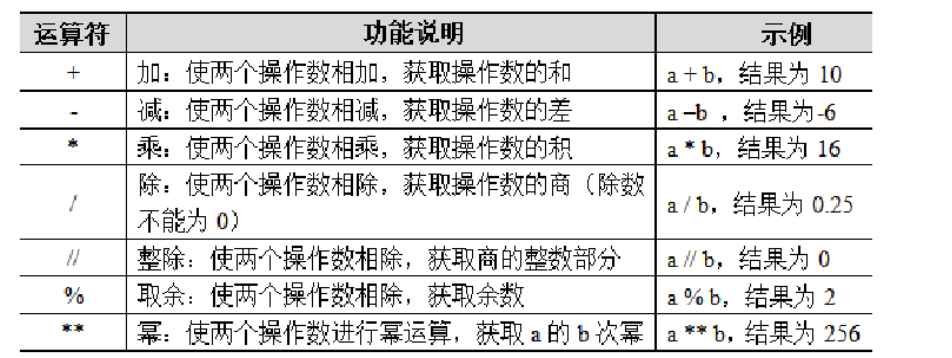
Python中的算术运算符既支持对相同类型的数值进行运算,也支持对不同类型的数值进行混合运算。在混合运算时,Python会强制将数值的类型进行临时类型转换,这些转换遵循如下原则:
python
1:整型与浮点型进行混合运算时,将整型转化为浮点型。
2:其他类型与复数运算时,将其他类型转换为复数类型。代码示例
python
print(10/2.0)
print(10-(3+5j))运行结果
python
5.0
(7-5j)2.6.2 赋值运算符
赋值运算符的作用是将一个表达式或对象赋值给一个左值。左值是指一个能位于赋值运算符左边的表达式,它通常是一个可修改的变量,不能是一个常量。
例如将整数3赋值给变量num
python
num = 3赋值运算符允许同时为多个变量赋值
python
x = y = z = 1 # 变量x、y、z均赋值为1
a, b = 1, 2 # 变量a赋值为1,变量b赋值为2Python中的算术运算符可以与赋值运算符组成复合赋值运算符,赋值运算符同时具备运算和赋值两项功能。以变量num为例, Python复合赋值运算符的功能说明及示例如下表所示:
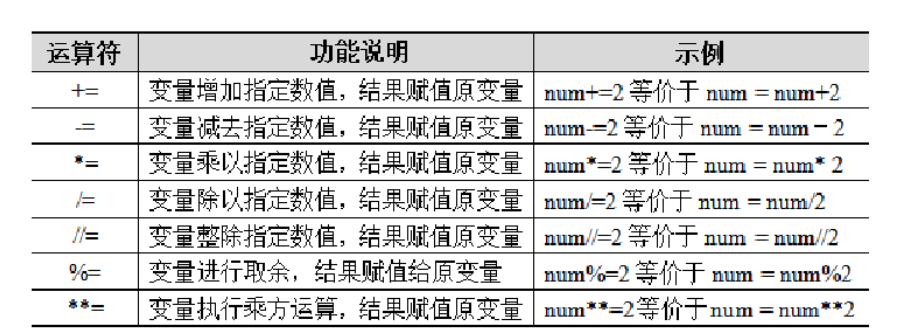
Python3.8中新增了一个赋值运算符------海象运算符":=",该运算符用于在表达式内部为变量赋值,因形似海象的眼睛和长牙而得此命名。
python
num_one = 1
# 使用海象运算符为num_two赋值
result = num_one + (num_two:=2)
print(result)2.6.3 比较运算符
比较运算符也叫关系运算符,用于比较两个数值,判断它们之间的关系。Python中的比较运算符包括==、!=、>、<、>=、<=,它们通常用于布尔测试,测试的结果只能是True或False。以变量x=2,y=3为例,具体如下:
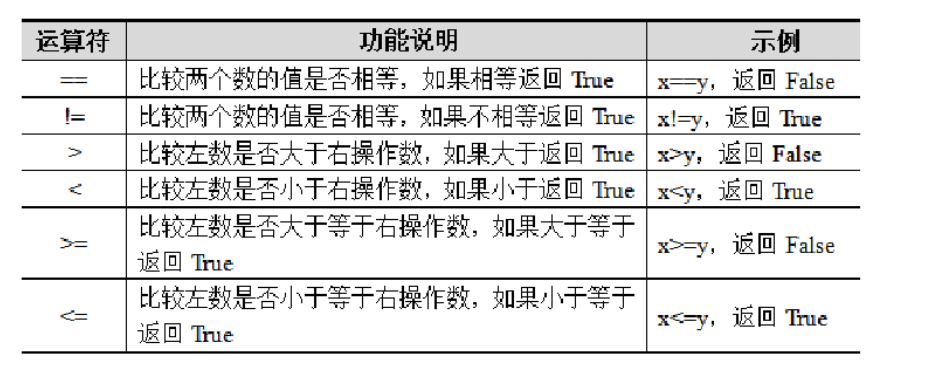
2.6.4 逻辑运算符
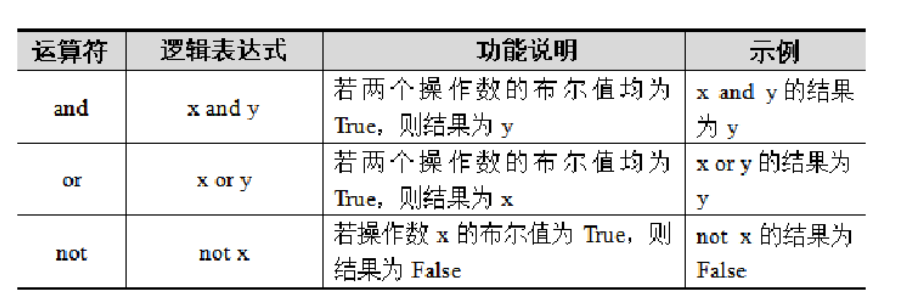
Python中分别使用"or","and","not"这三个关键字作为逻辑运算符,其中or与and为双目运算符,not为单目运算符。以x=10,y=20为例,具体如下:
2.6.5 成员运算符
成员运算符in和not in用于测试给定数据是否存在于序列(如列表、字符串)中,关于它们的介绍如下:
python
in:如果指定元素在序列中返回True,否则返回False。
not in:如果指定元素不在序列中返回True,否则返回False。代码示例
python
x = "Python"
y = 't'
print(y in x)
print(y not in x)运行结果
python
True
False2.6.6 位运算
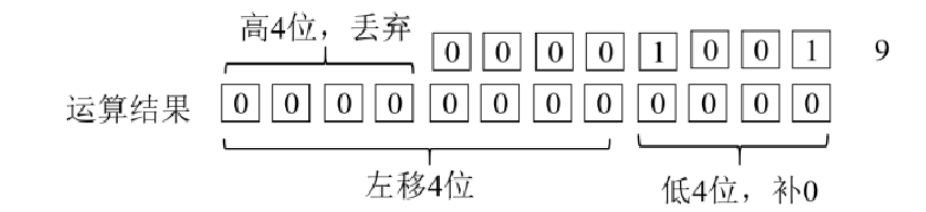
位运算符用于按二进制位进行逻辑运算,操作数必须为整数。下面介绍位运算符的功能,并以a=2,b=3为例进行演示,具体如下:

按位左移(<<)是指将二进制形式操作数的所有位全部左移n位,高位丢弃,低位补0。以十进制9为例,9转为二进制后是00001001,将转换后的二进制数左移4位。
2.6.7 运算符优先级
Python支持使用多个不同的运算符连接简单表达式,实现相对复杂的功能,为了避免含有多个运算符的表达式出现歧义,Python为每种运算符都设定了优先级。Python中运算符的优先级从高到低如下:
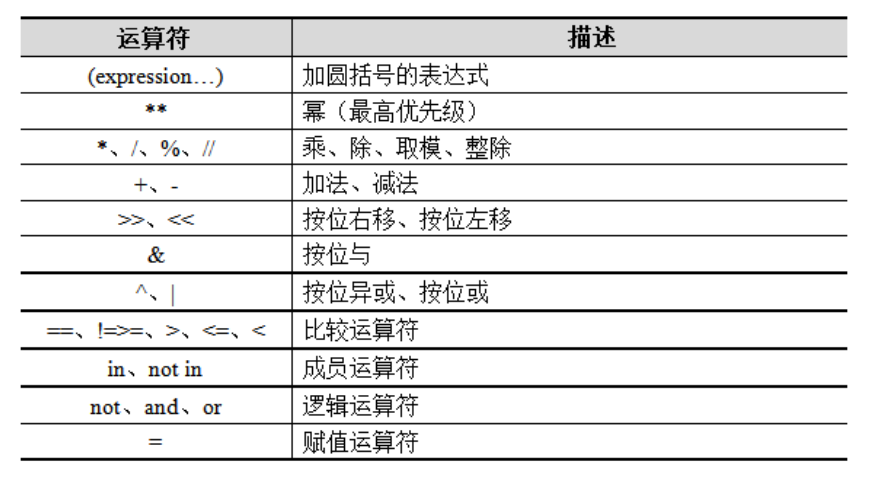
说明:如果表达式中的运算符优先级相同,按从左向右的顺序执行;如果表达式中包含小括号,那么解释器会先执行小括号中的子表达式
代码示例
python
a = 20
b = 2
c = 15
result_01 = (a-b)+c
result_02 = a/b%c
result_03 = c**b*a
print(result_01,result_02,result_03)运行结果
python
33 10.0 45002.7 总结
本章主要介绍了Python基础知识,包括代码格式、标识符和关键字、变量和数据类型、数字类型以及运算符。本章比较简单易学,希望大家在初学Python时,结合实训案例对该部分内容多加练习,为后期深入学习Python打好基础。
第三章:流程控制
程序中的语句默认自上而下顺序执行,但通过一些特定的语句可以更改语句的执行顺序,使之产生跳跃,回溯等,进而实现流程控制。Python中用于实现流程控制的特定语句分为条件语句,循环语句和跳转语句。
3.1 条件语句
现实生活中,大家在12306网站购票时需要先验证身份,验证通过后可进入购票页面,验证失败则需重新验证。在代码编写工作中,大家可以使用条件语句为程序增设条件,使程序产生分支,进而有选择地执行不同的语句。
3.1.1 if语句
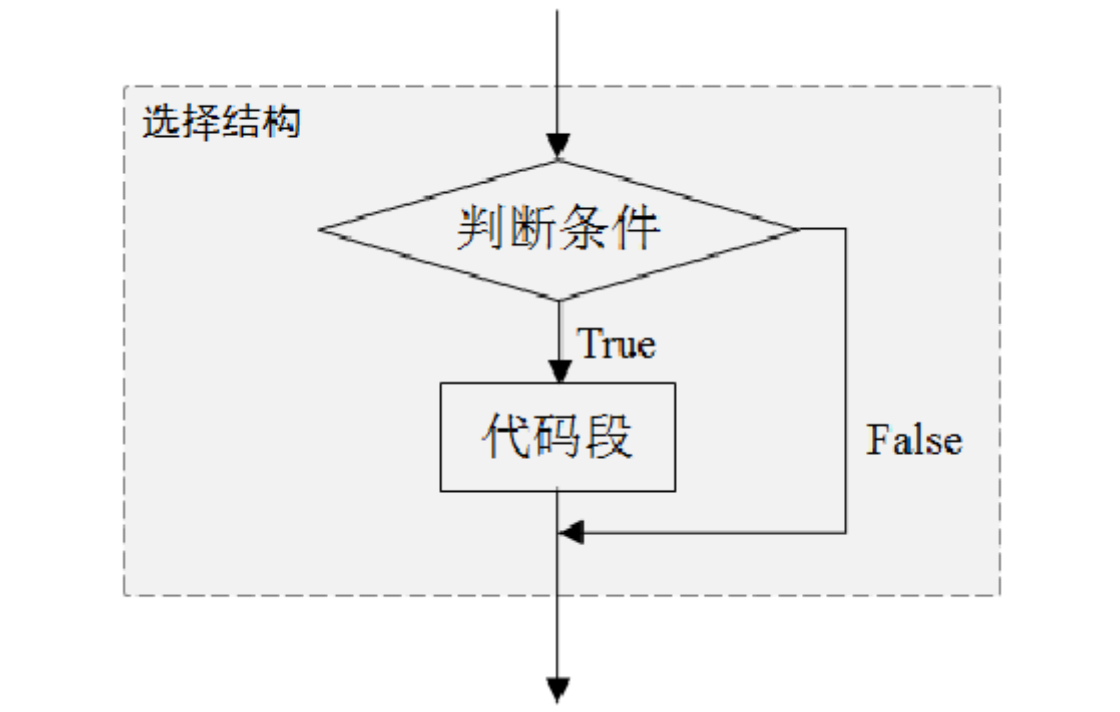
if语句由关键字if、判断条件和冒号组成,if语句和从属于该语句的代码段可组成选择结构。
python
if 条件表达式:
代码块执行if语句时,若if语句的判断条件成立(判断条件的布尔值为True),执行之后的代码段;若if语句的判断条件不成立(判断条件的布尔值为False),跳出选择结构,继续向下执行。
某中学上周进行英语模拟考试,考试成绩不低于60分的学生为"合格",假设小明的考试成绩为88分,输出小明的成绩评估结果。
代码示例
python
score = 88
if score >= 60:
print("考试及格")运行结果
python
考试及格3.1.2 if-else语句
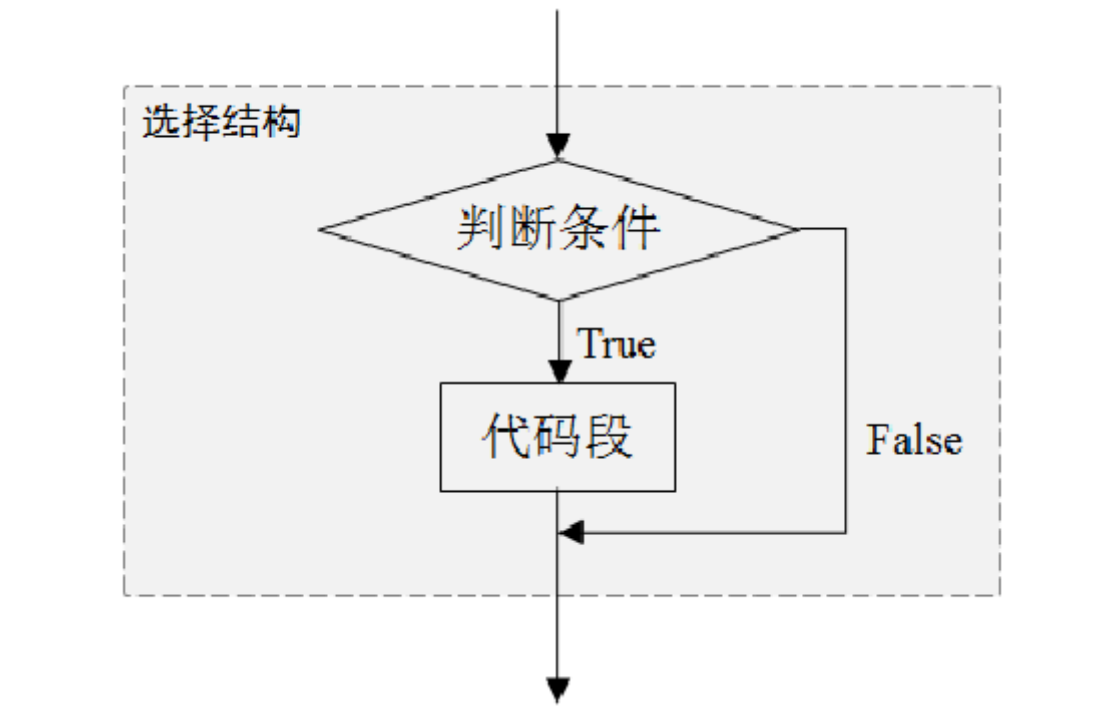
一些场景不仅需要处理满足条件的情况,也需要对不满足条件的情况做特殊处理。因此,Python提供了可以同时处理满足和不满足条件的if-else语句。
python
if 判断条件:
代码块1
else:
代码段2执行if-else语句时,若判断条件成立,执行if语句之后的代码段1;若判断条件不成立,执行else语句之后的代码段2。
代码示例
python
score = 50
if score >= 60:
print("考试及格")
else:
print("考试不及格")运行结果 (可以修改成绩,两次进行结果比较)
python
考试不及格3.1.3 if-elif-else语句
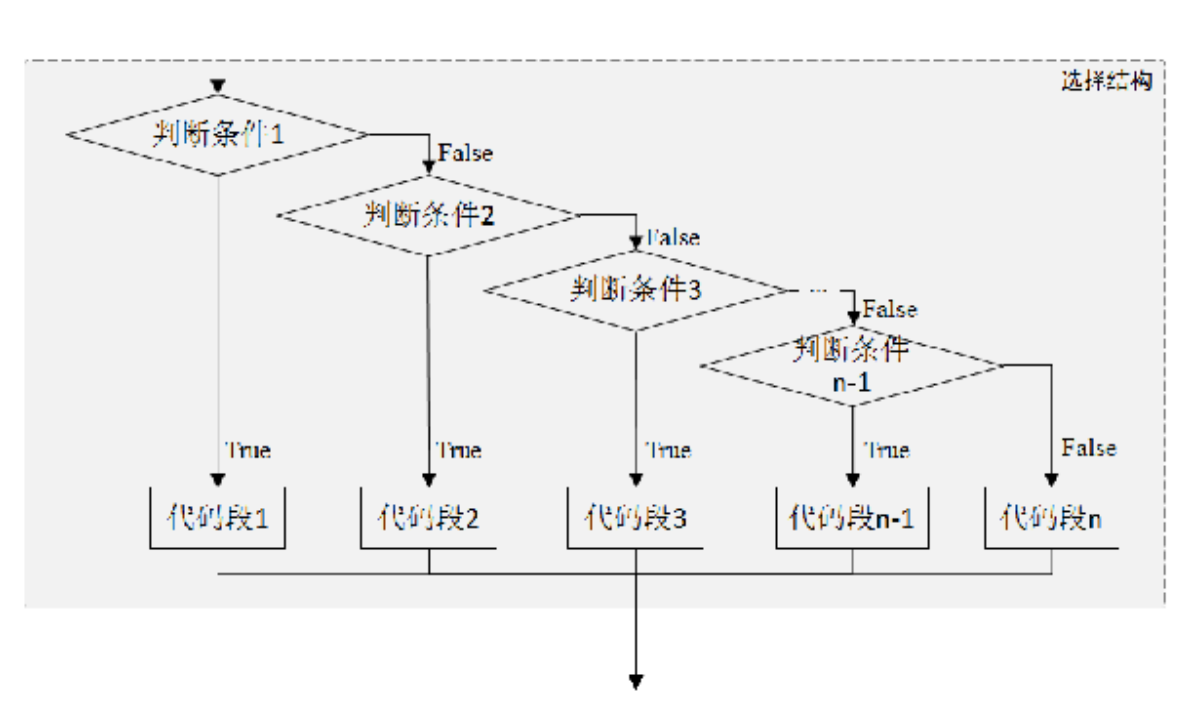
Python除了提供单分支和双分支条件语句外,还提供多分支条件语句if-elif-else。多分支条件语句用于处理单分支和双分支无法处理的情况。
python
if 判断条件1:
代码段1
elif 判断条件2:
代码段2
elif 判断条件3:
代码段3
...
else:
代码段n执行if-elif-else语句时,若if条件成立,执行if语句之后的代码段1;若if条件不成立,判断elif语句的判断条件2:条件2成立则执行elif语句之后的代码段2,否则继续向下执行。以此类推,直至所有的判断条件均不成立,执行else语句之后的代码段。
代码示例
python
score = 84
if score>=85:
print("优秀")
elif 75 <= score <85:
print("良好")
elif 60 <= score <75:
print("合格")
else:
print("不合格")运行结果
python
良好3.1.4 if嵌套
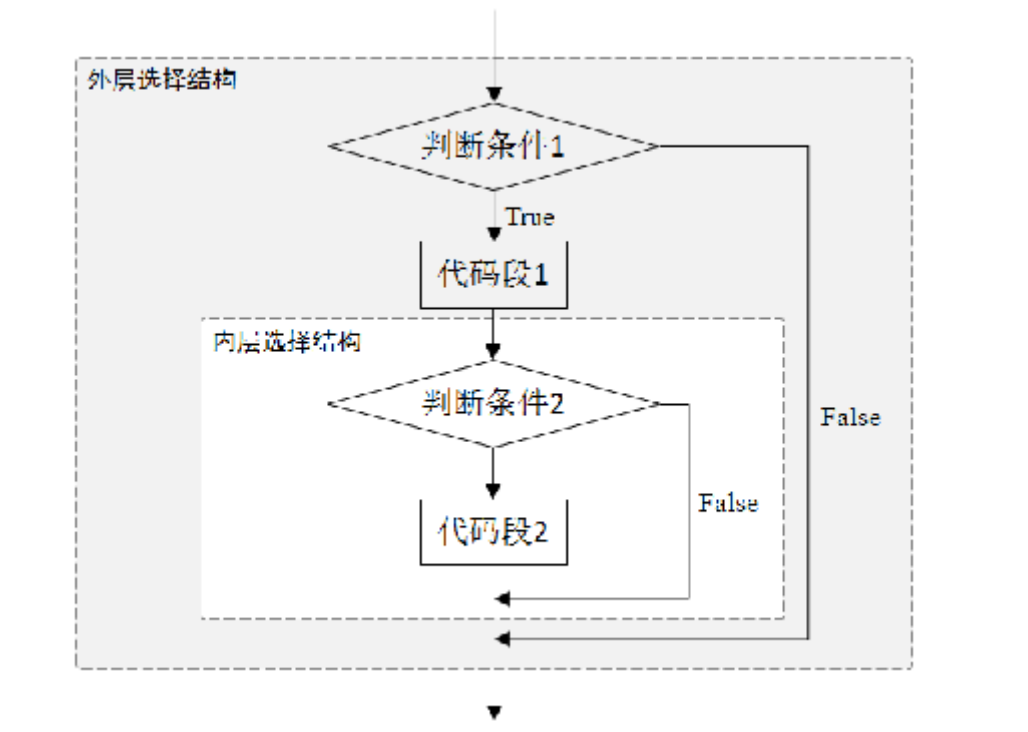
大家在某些火车站乘坐高铁出行时需要历经检票和安检两道程序:检票符合条件后方可进入安检程序,安检符合条件后方可进站乘坐列车。这个场景中虽然涉及两个判断条件,但这两个条件并非选择关系,而是嵌套关系:先判断外层条件,条件满足后才去判断内层条件;两层条件都满足时才执行内层的操作。
Python中通过if嵌套可以实现程序中条件语句的嵌套逻辑。
python
if 判断条件1: # 外层条件
代码段1
if 判断条件2: # 内层条件
代码段2
...执行if嵌套时,若外层判断条件(判断条件1)的值为True,执行代码段1,并对内层判断条件(判断条件2)进行判断:若判断条件2的值为True,则执行代码段2,否则跳出内层条件结构,顺序执行外层条件结构中内层条件结构之后的代码;若外层判断条件的值为False,直接跳过条件语句,既不执行代码段1,也不执行内层的条件结构。
案例:1年有12个月份,每个月的总天数具有一定的规律,1月,3月,5月,7月,8月,10月,12月有31天,4月,6月,9月,11月有30天;2月的情况稍微复杂些,闰年的2月有29天,平年的2月有28天。本示例要求根据年份和月份计算当月的天数。
代码示
python
year= int(input('Enter your year: '))
month = int(input('Enter your month: '))
if month in [1,3,5,7,8,10,12]:
print('月份天数:',31)
elif month in [4,6,9,11]:
print('月份天数',30)
elif month in [2]:
if year%4==0 and year%100!=0 or year%400==0:
print('月份天数 :',29)
else:
print('月份天数:',28)运行结果
python
Enter your year: 2004
Enter your month: 2
月份天数 : 29扩展:isdigit()判断输入的字符串是否是数字,如果是返回True,否则为False
案例:输入成绩判断优秀,良好,合格和不合格,如果输入超出范围的值或者字符,提示输入有误重新输入
python
score = input('请输入成绩:')
if score.isdigit() and 0<=float(score)<=100:
score=float(score)
if score >= 90:
print('优秀')
elif 75<=score<90:
print('良好')
elif 60<=score<75:
print('合格')
else:
print('不合格')
else:
print('输入有误请重新输入!')3.2 课堂练习
3.2.1 猜数字
猜数字由两个人参与,一个人设置一个数字,一个人猜数字,当猜数字的人说出一个数字,由出数字的人告知是否猜中:若猜测的数字大于设置的数字,出数字的人提示"很遗憾,你猜大了";若猜测的数字小于设置的数字时,出数字的人提示"很遗憾,你猜小了";若猜数字的人在规定的次数内猜中设置的数字,出数字的人提示"恭喜,猜数成功"。
本实例要求编写代码,实现遵循上述规则的猜数字程序。
python
import random
count = 0
a = random.randint(1,100)
while True:
b = int(input('请输入1-100的数字:'))
if b > a :
print('猜错了,数值偏大')
count = count + 1
elif b < a :
print('猜错了,数值偏小')
count = count + 1
else:
print('猜对了!')
count = count + 1
break
print('猜数次数:',count)运行结果
python
请输入1-100的数字:30
猜错了,数值偏小
请输入1-100的数字:50
猜错了,数值偏大
请输入1-100的数字:40
猜对了!
猜数次数: 33.3 循环语句
现实生活中存在很多重复的事情,例如,地球一直围绕太阳不停地旋转;月球始终围绕地球旋转;每年都会经历司机的更替;每天都是从白天到黑夜的过程,程序开发中同样可能出现代码的重复执行。Python提供循环语句,使用该语句能以简洁的代码实现重复操作。
3.3.1 while语句
while语句一般用于实现条件循环,该语句由关键字while、循环条件和冒号组成,while语句和从属于该语句的代码段组成循环结构。
python
while 条件表达式:
代码块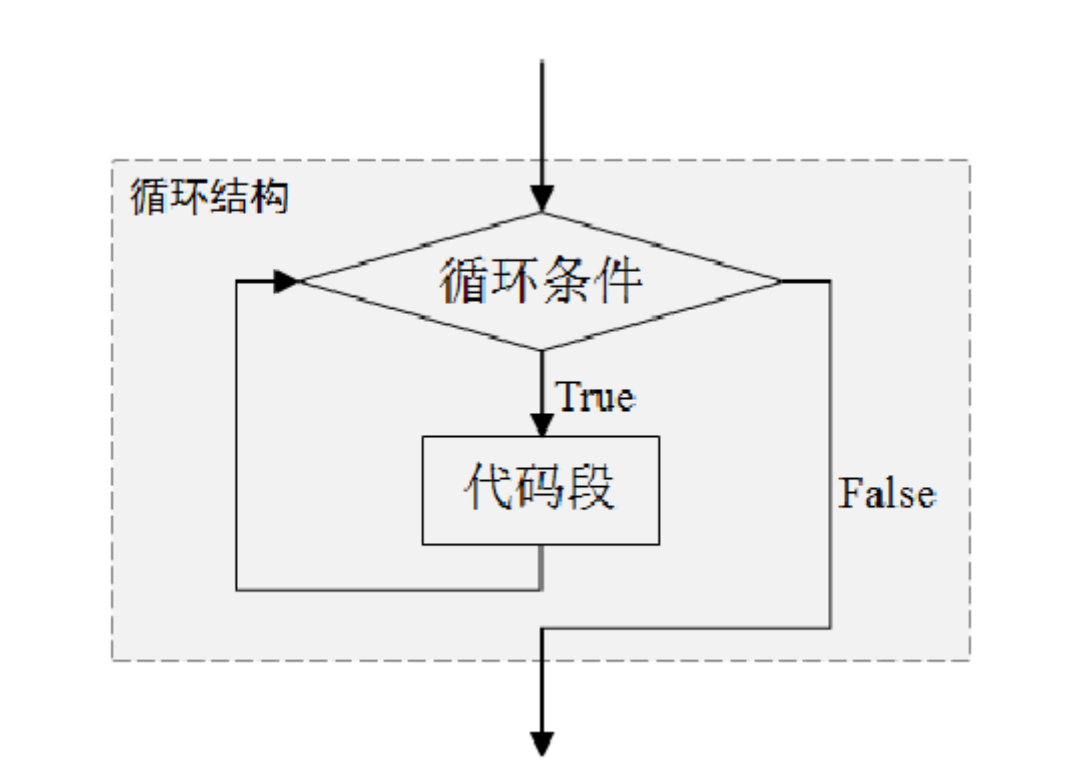
python
i=1
result=0
while i<=10:
result+=i
i+=1
print(result)运行结果
python
55无限循环
python
while True:
print("无限循环")3.3.2 for语句
for语句一般用于实现遍历循环。遍历指逐一访问目标对象中的数据,例如逐个访问字符串中的字符;遍历循环指在循环中完成对目标对象的遍历。
python
for 临时变量 in 目标对象:
代码块案例:使用循环遍历字符串"Python"的每个字符
代码示例
python
for word in "Python":
print(word)运行结果
python
P
y
t
h
o
nfor语句可以与range()函数搭配,range()函数可以生成一个由整数组成的可迭代对象
代码示例
python
for i in range(5):
print(i) 运行结果
python
0
1
2
3
43.3.3 循环嵌套
循环之间可以互相嵌套,进而实现更为复杂的逻辑。循环嵌套按不同的循环语句可以划分为while循环嵌套和for循环嵌套。
1)while循环嵌套
while循环嵌套是指while语句中嵌套了while或for语句。以while语句中嵌套while语句为例,while循环嵌套的语法格式如下:
python
while 循环条件1: # 外层循环
代码段1
while 循环条件2: # 内层循环
代码段2
......执行while循环嵌套时,若外层循环条件1的值为True,则执行代码段1,并对内层循环的循环条件2进行判断,若循环条件2的值为True则执行代码段2,若其值为False则结束内层循环。内层循环执行完毕后继续判断外层循环的循环条件1,如此反复,直至循环条件1的值为False时结束外层循环。
案例:打印"*"组成的直角三角形
python
i=1
while i<6:
j=0
while j<i:
print("*",end='')
j+=1
print()
i+=1运行结果
python
*
**
***
****
*****2)for循环嵌套
for循环嵌套是指for语句中嵌套了while或for语句。以for语句中嵌套for语句为例,for循环嵌套的语法格式如下:
python
for 临时变量 in 目标对象: # 外层循环
代码段1
for 临时变量 in 目标对象: # 内层循环
代码段2
......执行for循环嵌套时,程序首先会访问外层循环中目标对象的首个元素,执行代码段1,访问内层循环目标对象的首个元素、执行代码段2,然后访问内层循环中的下一个元素,执行代码段2,如此往复,直至访问完内层循环的目标对象后结束内层循环,转而继续访问外层循环中的下一个元素,访问完外层循环的目标对象后结束外层循环。因此外层循环每执行一次,都会执行一轮内层循环。
案例:打印"*"组成的直角三角形
python
for i in range(1,6):
for j in range(i):
print('*',end=' ')
print()运行结果
python
*
* *
* * *
* * * *
* * * * * 案例:打印"*"组成的倒直角三角形
python
for i in range(1,6):
for j in range(6-i):
print('*',end=' ')
print()运行结果
python
* * * * *
* * * *
* * *
* *
*案例:打印"*"组成的等腰三角形
python
for i in range(5,0,-1):
for k in range(i):
print(" ",end=" ")
for j in range(2*(6-i)-1):
print('*',end=" ")
print()运行结果
python
*
* * *
* * * * *
* * * * * * *
* * * * * * * * * 案例:打印"*"组成的菱形
python
for i in range(5,0,-1):
for k in range(i):
print(" ",end=" ")
for j in range(2*(6-i)-1):
print('*',end=" ")
print()
for i in range(0,6):
for k in range(i):
print(" ",end=" ")
for j in range(2*(6-i)-1):
print('*',end=" ")
print()运行结果
python
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
* * * * * * * * * * *
* * * * * * * * *
* * * * * * *
* * * * *
* * *
* 3.4 实训案例
3.4.1 逢七拍手游戏
逢7拍手游戏的规则是:从1开始顺序数数,数到有7或者包含7的倍数的时候拍手。本实例要求编写代码,模拟实现逢七拍手游戏,实现输出100以内需要拍手的数字的程序。
python
for i in range(100):
if i % 7 == 0 or '7' in str(i):
print('*', end=' ')
else:
print(i, end=' ')运行结果
python
* 1 2 3 4 5 6 * 8 9 10 11 12 13 * 15 16 * 18 19 20 * 22 23 24 25 26 * * 29 30 31 32 33 34 * 36 * 38 39 40 41 * 43 44 45 46 * 48 * 50 51 52 53 54 55 * * 58 59 60 61 62 * 64 65 66 * 68 69 * * * * * * * * * * 80 81 82 83 * 85 86 * 88 89 90 * 92 93 94 95 96 * * 99
进程已结束,退出代码为 03.5 跳转语句
循环语句在条件满足的情况下会一直执行,但在某些情况下需要跳出循环,例如,实现音乐播放器循环模式的切歌功能等。Python提供了控制循环的跳转语句:break和continue。
3.5.1 break语句
break语句用于结束循环,若循环中使用了break语句,程序执行到break语句时会结束循环;若循环嵌套使用了break语句,程序执行到break语句时会结束本层循环。
案例:在使用for循环遍历字符串'Python'时,遍历到字符'o'就使用break语句结束循环。
示例代码
python
for i in 'python':
if i == 'o':
break
print(i)运行结果
python
p
y
t
h3.5.2 continue 语句
continue语句用于在满足条件的情况下跳出本次循环,该语句通常也与if语句配合使用。
案例:在使用for循环遍历字符串'Python'时,遍历到字符'o'就使用continue语句跳出本次循环。
示例代码
python
for i in 'python':
if i == 'o':
continue
print(i)运行结果
python
p
y
t
h
n3.6 本章小结
本章主要讲解了流程控制的相关知识,包括条件语句、循环语句、跳转语句,并结合众多实训案例演示了如何利用各种语句实现流程控制。
通过本章的学习,希望能掌握程序的执行流程和流程控制语句的用法,为后续的学习打好扎实的基础。
第四章:字符串
在使用浏览器登录网站时需要先输入账户和密码,之后浏览器将账号和密码传递给服务器,服务器把本次输入的密码与之前保存的密码进行对比,两处密码相同则认为本次输入的密码正确,否则认为密码错误,在以上场景中,用户的账号和密码都需要被存储,但用户的信息有字母、数字和字符组成,这些类型就是字符串。
4.1 字符串介绍
字符串是由字母、符号或者数字组成的字符序列。
Python支持使用单引号、双引号和三引号定义字符串,其中单引号和双引号通常用于定义单行字符串,三引号通常用于定义多行字符串。
代码示例
python
print('使用单引号在一行输出')
print("使用双引号在一行输出")
print("""使用三引号
进行多行输出""")运行结果
python
使用单引号在一行输出
使用双引号在一行输出
使用三引号
进行多行输出注意:当字符串中有相同类型引号出现,就需要变更外部的引号类型来避免语法错误
python
print("let's go ")
python
print("""let's go""")除此以外,Python使用反斜杠"\"转义。例如,在字符串中的引号前添加"\",此时Python解释器会将"\"之后的引号视为解释为一个普通字符,而非特殊符号。
python
print('let\'s go')
print('E:\\python\\code')运行结果
python
let's go
E:\python\code扩展:一些普通字符与反斜杠组合后将失去原有意义,产生新的含义。类似这样的由"\"和而成的、具有特殊意义的字符就是转义字符。转移字符通常用于表示一些无法显示的字符,例如空格、回车等。
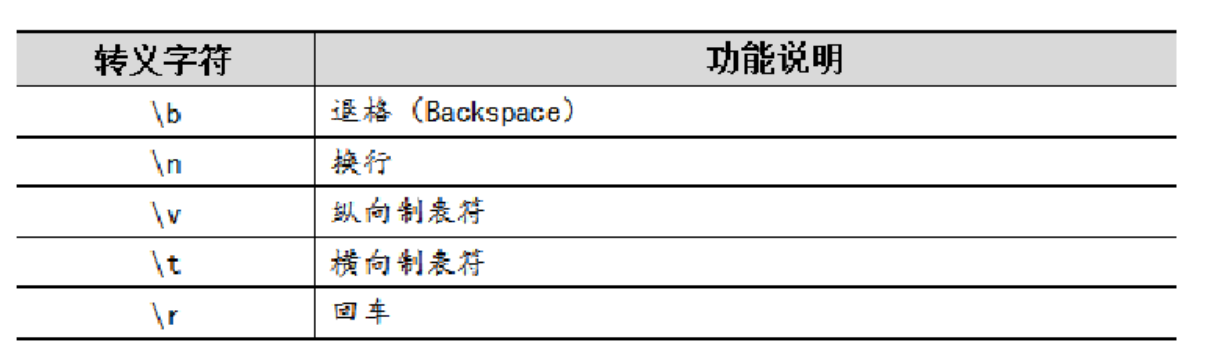
代码示例
python
for i in range(1,10):
for j in range(1,i+1):
print("%d x %d = %d" %(i,j,i*j),end="\t")
print()运行结果
python
1 x 1 = 1
2 x 1 = 2 2 x 2 = 4
3 x 1 = 3 3 x 2 = 6 3 x 3 = 9
4 x 1 = 4 4 x 2 = 8 4 x 3 = 12 4 x 4 = 16
5 x 1 = 5 5 x 2 = 10 5 x 3 = 15 5 x 4 = 20 5 x 5 = 25
6 x 1 = 6 6 x 2 = 12 6 x 3 = 18 6 x 4 = 24 6 x 5 = 30 6 x 6 = 36
7 x 1 = 7 7 x 2 = 14 7 x 3 = 21 7 x 4 = 28 7 x 5 = 35 7 x 6 = 42 7 x 7 = 49
8 x 1 = 8 8 x 2 = 16 8 x 3 = 24 8 x 4 = 32 8 x 5 = 40 8 x 6 = 48 8 x 7 = 56 8 x 8 = 64
9 x 1 = 9 9 x 2 = 18 9 x 3 = 27 9 x 4 = 36 9 x 5 = 45 9 x 6 = 54 9 x 7 = 63 9 x 8 = 72 9 x 9 = 81 在一段字符串中如果包含多个转义字符,但又不希望转义字符产生作用,此时可以使用原始字符串。原始字符串即在字符串开始的引号之前添加r或R,使它成为原始字符串。
python
print(r'转义字符:\n表示转行;\r表示回车;\b表示退格')4.2 格式化字符串
格式化字符串是将制定的字符串转化为想要的格式。Python中有三种格式化字符串的方式:使用%格式化、使用format()方法格式化和使用f-string格式化。
4.2.1 使用%格式化字符串
字符串具有一种特殊的内置操作,它可以使用%进行格式化。
python
format % valuesformat:表示一个字符串,该字符串中包含单个或多个为真实数据占位的格式符;
values:表示单个或多个真实数据;
%:代表执行格式化操作,即将format中的格式符替换为values。
不同的格式符为不同类型的数据预留位置,常见的格式符如下所示。
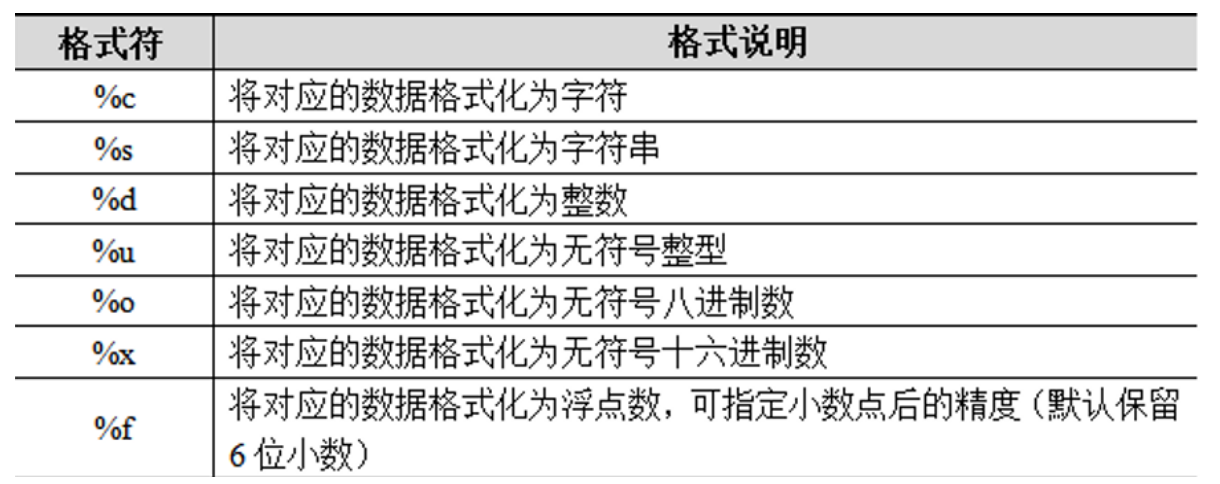
下面使用%对字符串进行格式化,代码示例
python
name = 'dyx'
info = '姓名:%s'
print(info % name)运行结果
python
姓名:dyx注意:如果被替换的数据类型不符合格式符中制定的数据类型,那么程序会出现类型异常错误!
多个格式符进行格式化,代码示例
python
name = 'dyx'
age = 21
info = '姓名:%s,年龄:%d'
print(info % (name, age))运行结果
python
姓名:dyx,年龄:214.2.2 使用format()方法格式化字符串
虽然使用%可以对字符串进行格式化,但是这种方式并不是很直观,一旦开发人员遗漏了替换数据或选择了不匹配的格式符,就会导致字符串格式化失败。为了能更直观、便捷地格式化字符串,Python为字符串提供了一个格式化方法format()。
python
str.format(values)str:表示需要被格式化的字符串,字符串中包含单个或多个为真实数据占位的符号{};
values:表示单个或多个待替换的真实数据,多个数据之间以逗号分隔。
代码示例
python
name = 'dyx'
info = '姓名:{}'
print(info.format(name))运行结果
python
姓名:dyx以上输出结果可以看出,字符串中的{}替换为变量name存储的数据'tom',使用format{}方法格式化字符串时,无须关注替换数据的类型。
字符串中可以包含多个{}符号,字符串被格式化时Python解释器默认会按从左到右的顺序将{}逐个替换为真实的数据。
python
name = 'dyx'
age = 21
info = '姓名:{},年龄:{}'
print(info.format(name, age))运行结果
python
姓名:dyx,年龄:21字符串的{}中可以明确地指定编号,格式化字符串时解释器会按编号取values中相应位置的值替换{},values中元素的索引从0开始。
python
name = 'dyx'
age = 21
info = '姓名:{0},年龄:{1}'
print(info.format(name, age))运行结果
python
姓名:dyx,年龄:21字符串的{}中可以指定名称,字符串在被格式化时Python解释器会按真实数据绑定的名称替换{}中的变量。
python
name = 'dyx'
age = 21
info = '姓名:{a},年龄:{b}'
print(info.format(a=name, b=age))运行结果
python
姓名:dyx,年龄:21字符串中的{}可以指定替换的浮点型数据的精度,浮点型数据在被格式化时会按指定的精度进行替换。
python
r = int(input('请输入圆的半径:'))
import math
pi = math.pi
s = pi * r**2
info = '半径:{a},π:{b:.3},面积:{c:.4}'
print(info.format(a = r,b = pi,c = s))运行结果
python
请输入圆的半径:5
半径:5,π:3.14,面积:78.544.2.3 使用f-string格式化字符串
f-string提供了一种更为简洁的格式化字符串的方式,它在形式上以f或F引领字符串,在字符串中使用"{变量名}"标明被替换的真实数据和其所在位置。
python
f('{变量名}') 或者 F('{变量名}')代码示例
python
name = 'dyx'
age = 21
print(f'姓名:{name} , 年龄:{age}')运行结果
python
姓名:dyx , 年龄:214.3 实训案例
4.3.1 进制转换
十进制是实际应用中最常使用的计数方式,除此之外,还可以采用二进制、八进制或十六进制计数。
本实例要求编写代码,实现将用户输入的十进制整数转换为指定进制的功能。
4.4字符串的常见操作
字符串的操作在实际应用中非常常见,Python内置了很多字符串方法,使用这些方法可以轻松实现字符串的查找,替换,拼接,大小写转换等操作。但需要注意的是,字符串一但创建便不可修改;若对字符串进行修改,就会生成新的字符串。
4.4.1 字符串的查找与替换
1)查找
Python中提供了实现字符串查找操作的find()方法,该方法可查找字符串中是否包含子串,若包含则返回子串首次出现的位置,否则返回-1。
语法格式
python
str.find(sub[, start[, end]])sub:指定要查找的子串。
start:开始索引,默认为0。
end:结束索引,默认为字符串的长度。
代码示例
python
word = 'life is sort , i use python'
print(word)
print(word.find('use'))运行结果
python
life is sort , i use python
172)替换
Python中提供了实现字符串替换操作的replace()方法,该方法可将当前字符串中的指定子串替换成新的子串,并返回替换后的新字符串。
语法格式
python
str.replace(old, new[, count])old:被替换的旧子串。
new:替换旧子串的新子串。
count:表示替换旧字符串的次数。
代码示例
python
word = '八百标兵奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮'
new = word.replace('标兵','战士')
print(new)运行结果
python
八百战士奔北坡,北坡炮兵并排跑。炮兵怕把战士碰,战士怕碰炮兵炮指定替换次数,代码示例
python
word = '八百标兵奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮'
new = word.replace('标兵','战士',1)
print(new)运行结果
python
八百战士奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮4.4.2 字符串的分割与拼接
字符串的分割与拼接功能是处理文本数据时常用的功能。
1)字符串分割
split()方法可以按照指定分隔符对字符串进行分割,该方法会返回由分割后的子串组成的列表。
语法格式
python
str.split(sep=None, maxsplit=-1)sep:分隔符,默认为空字符。
maxsplit:分割次数,默认值为-1,表示不限制分割次数。
代码示例
python
word = '八百标兵奔北坡 北坡炮兵并排跑 炮兵怕把标兵碰 标兵怕碰炮兵炮'
#以空格作为分隔符
print(word.split())
#以'兵'作为分隔符
print(word.split('兵'))
#以'兵'作为分隔符,并分割2次
print(word.split('兵',2))运行结果
python
['八百标兵奔北坡', '北坡炮兵并排跑', '炮兵怕把标兵碰', '标兵怕碰炮兵炮']
['八百标', '奔北坡 北坡炮', '并排跑 炮', '怕把标', '碰 标', '怕碰炮', '炮']
['八百标', '奔北坡 北坡炮', '并排跑 炮兵怕把标兵碰 标兵怕碰炮兵炮']2)字符串拼接
join()方法使用指定的字符连接字符串并生成一个新的字符串。join()方法的语法格式如下。
语法格式
python
str.join(iterable)iterable:表示连接字符串的字符。
使用'-'连接字符串Python中的各个字符,代码示例
python
symbol = '-'
word = 'python'
print(symbol.join(word))运行结果
python
p-y-t-h-o-nPython中还可以使用运算符'+'和'*'连接字符串,代码示例
python
start = 'pyt'
end = 'hon'
print(start + end)
print(end*3)运行结果
python
python
honhonhon4.4.3 删除字符串的指定字符
字符串中可能会包含一些无用的字符(如空格),在处理字符串之前往往需要先删除这些无用的字符。
Python中的strip()、lstrip()和rstrip()方法可以删除字符串中的指定字符。
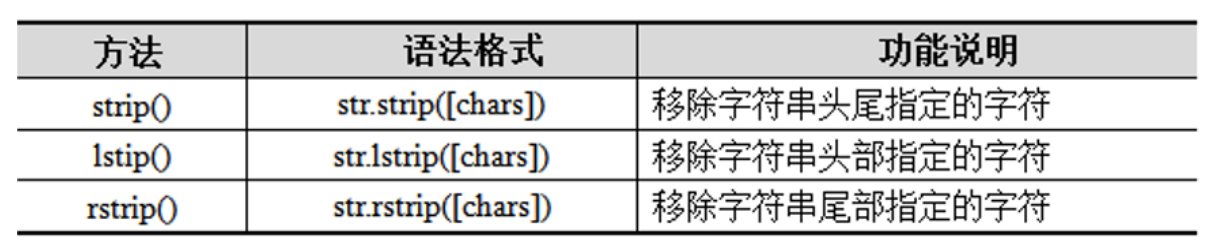
分别移除字符串' 人生苦短,我用Python !'中头部和尾部、头部、尾部的空格,代码示例
python
word = '*life is short, i use python*'
print(word)
#删除字符串头部和尾部*
print(word.strip('*'))
#删除字符串头部*
print(word.lstrip('*'))
#删除字符串尾部*
print(word.rstrip('*'))运行结果
python
*life is short, i use python*
life is short, i use python
life is short, i use python*
*life is short, i use python4.4.4 字符串大小写转换
在特定情况下会对英文单词的大小写形式进行要求,表示特殊简称时全字母大写,如CBA;表示月份、周日、节假日时每个单词首字母大写,如Monday。Python中支持字母大小写转换的方法有upper()、lower()、capitalize()和title()。

对字符串'Life is short. I use Python'进行大小写转换操作,示例代码
python
word = 'life is short, i use python'
#转换成大写字母
print(word.upper())
#转换成小写字母
print(word.lower())
#转换字符串首字母大写
print(word.capitalize())
#转换每个单词首字母大写
print(word.title())运行结果
python
LIFE IS SHORT, I USE PYTHON
life is short, i use python
Life is short, i use python
Life Is Short, I Use Python4.4.5 字符串对其
在使用Word处理文档时可能需要对文档的格式进行调整,如标题居中显示、左对齐、右对齐等。
Python提供了center()、ljust()、rjust()这3个方法来设置字符串的对齐方式。
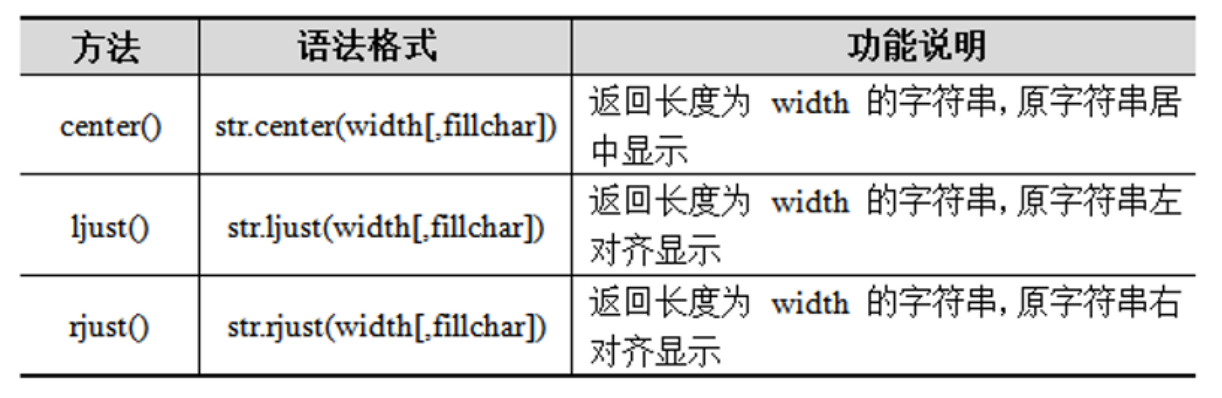
对字符串'hello world'进行对齐操作,代码示例
python
string = 'hello world'
print(len(string))
#居中显示
print(string.center(15,'-'))
#左对齐显示
print(string.ljust(15,'-'))
#右对齐显示
print(string.rjust(15,'-'))运行结果
python
11
--hello world--
hello world----
----hello world4.5 实例案例
4.5.1 敏感词替换
敏感词通常是指带有敏感政治倾向、暴力倾向、不健康色彩的词或不文明的词语,对于文章中出现的敏感词常用的处理方法是使用特殊符号(如"*")对敏感词进行替换。
本实例要求编写代码,实现具有替换敏感词功能的程序。
4.6 本章小结
本章主要讲解了Python字符串的相关知识,包括什么是字符串、格式化字符串、字符串的常见操作,并结合实训案例演示了字符串的使用。
通过本章的学习,希望读者能够掌握字符串的使用。
第五章:组合数据类型
在大数据时代,程序中不仅要处理数字、字符串这些基础数据类型的数据,还需要处理混合数据。为此,Python定义了可以表示混合数据的组合数据类型。使用组合数据类型定义和记录数据,不仅能使数据表示得更为清晰,也能极大简化程序员的开发工作,提升开发效率。
5.1 认识组合数据类型
组合数据类型可将多个相同类型或不同类型的数据组织为一个整体,根据数据组织方式的不同,Python的组合数据类型可分成三类:序列类型、集合类型和映射类型。
1)序列类型
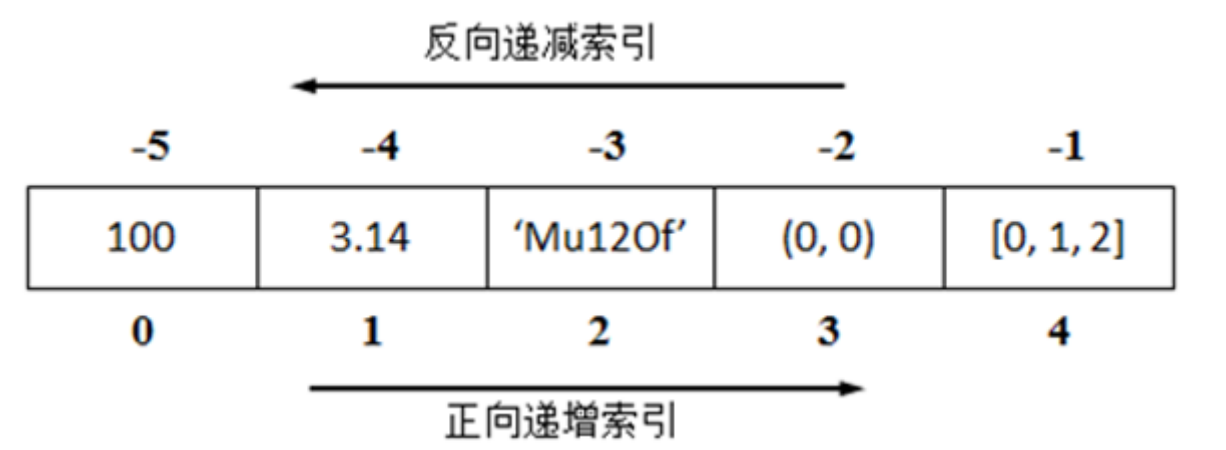
Python中常用的序列类型有字符串(str)、列表(list)和元组(tuple)。
Python中的序列支持双向索引:正向递增索引和反向递减索引。正向递增索引从左向右依次递增,第一个元素的索引为0,第二个元素的索引为1,以此类推;反向递减索引从右向左依次递减,从右数第一个元素的索引为-1,第二个元素的索引为-2,以此类推。
2)集合类型
Python集合具备确定性、互异性和无序性三个特性。
Python要求放入集合中的元素必须是不可变类型,Python中的整型、浮点型、字符串类型和元组属于不可变类型,列表、字典及集合本身都属于可变的数据类型。
-
确定性:给定一个集合,那么任何一个元素是否在集合中就确定了。
-
互异性:集合中的元素互不相同。
-
无序性:集合中的元素没有顺序,顺序不同但元素相同的集合可视为同一集合。
3)映射类型
映射类型以键值对的形式存储元素,键值对中的键与值之间存在映射关系。
字典(dict)是Python唯一的内置映射类型,字典的键必须遵守以下两个原则:
-
每个键只能对应一个值,不允许同一个键在字典中重复出现。
-
字典中的键是不可变类型。
5.2 列表
Python利用内存中的一段连续空间存储列表。列表是Python中最灵活的序列类型,它没有长度限制,可以包含任意元素。开发人员可以自由的对列表中的元素进行各种操作包括访问、添加、排序、删除。
5.2.1 创建列表
Python列表的创建方式非常简单,既可以直接使用中括号"\[\]"创建,也可以使用内置的list()函数快速创建。
1)使用中括号"\[\]"可以创建列表,示例代码如下:
python
list_one = []
print(type(list_one))运行结果
python
<class 'list'>\[\]中包括的是列表元素,列表元素可以是整型、浮点型、字符串等基本类型,也可以是列表、元组、字典等组合类型,还可以是其他自定义类型;列表元素的类型可以相同也可以不同;列表中的元素使用","分隔。
python
list_two = ['p', 'y', 't', 'h', 'o', 'n']2)使用list()函数创建列表
list()函数接收一个可迭代类型的数据,返回一个列表。
python
list_two = list()
print(type(list_two))运行结果
python
<class 'list'>扩展:
-
在Python中,支持通过for...in...语句迭代获取数据的对象就是可迭代对象。
-
我们学习过可迭代的类型有字符串和列表,后续学习的集合、字典、文件也是可迭代类型的对象。
-
使用isinstance()函数可以判断目标是否为可迭代对象,返回True表示为可迭代对象。
python
from collections.abc import Iterable
print(isinstance(range(4),Iterable))运行结果
python
True5.2.2 访问列表元素
列表中的元素可以通过索引或切片这两种方式进行访问,也可以在循环中依次访问。
1)以索引方式访问列表元素
索引就像图书中的目录,阅读时可以借助目录快速定位到书籍的制定内容,访问列表时则可以借助索引快速定位到列表中的元素。
python
list_one = ['python','hello','world','ligth']
print(list_one[0])
print(list_one[1])
print(list_one[-1])运行结果
python
python
hello
ligth2)以切片方式访问列表元素
切片用于截取列表中的部分元素,获取一个新列表。
格式
python
list[起始索引,结束索引,步长]代码示例
python
list_one = [34,67,34,63,82,93,13]
print(list_one[1:4])
print(list_one[1:])
print(list_one[:4])
print(list_one[::2])
print(list_one[1:4:2])运行结果
python
[67, 34, 63]
[67, 34, 63, 82, 93, 13]
[34, 67, 34, 63]
[34, 34, 82, 13]
[67, 63]3)在循环中依次访问列表元素
列表是一个可迭代对象,在for...in...语句中逐个访问列表中的元素。
python
list_one = ['w','o','r','l','d']
for i in list_one:
print(i,end=" ")运行结果
python
w o r l d 扩展:Python的成员运算符in和not in 对列表同样适用,利用in可判断某个元素是否存在于列表,利用not in可以判断某个元素是否不存在列表。
python
list_one = [1,2,3,4,5,6,8]
print(3 in list_one)
print(7 in list_one)
print(1 not in list_one)运行结果
python
True
False
False5.2.3 添加元素
向列表中添加元素是非常常见的一种列表操作,Python提供了append()、extend()和insert()这几个方法向列表末尾、指定位置添加元素。
1)append()方法
在列表末尾添加新的元素
python
list_one = [10,20]
list_one.append(30)
print(list_one)运行结果
python
[10, 20, 30]2)extend()方法
在列表末尾一次性添加另一个列表中的所有元素,即使用新列表扩展原来的列表。
python
list_one = [10,20]
list_two = [30,40,50]
list_one.extend(list_two)
print(list_one)
print(list_two)运行结果
python
[10, 20, 30, 40, 50]
[30, 40, 50]3)insert()方法
按照索引将新元素插入列表的指定位置。
python
list_one = [10,20]
list_one.insert(1,15)
print(list_one)运行结果
python
[10, 15, 20]5.2.4 元素排序
列表的排序是将元素按照某种规定进行排列。列表中常用的排序方法有sort()、reverse()、sorted()。
1)sort()方法
按特定顺序对列表元素排序,语法如下
python
sort(key=None,reverse=False)以上格式中参数key用于指定排序规则,该参数可以是列表支持的函数,默认值为None;参数reverse用于控制列表元素排序的方式,该参数可以取值True或者False,取值为True表示降序排列,取值为False(默认值)表示升序排列,使用sort()方法对列表元素排序后,有序的元素会覆盖原来的列表元素,不产生新列表。
python
list_one = [32,67,34,63,82,93,13]
#升序排列列表中的元素
list_one.sort()
print(list_one)
#降序排列列表中的元素
list_one.sort(reverse=True)
print(list_one)运行结果
python
[13, 32, 34, 63, 67, 82, 93]
[93, 82, 67, 63, 34, 32, 13]2)sorted()方法
按升序排列列表元素,该方法的返回值是升序排列后的新列表,排序操作不会对原列表产生影响。
python
list_one = [32,67,34,63,82,93,13]
list_two = sorted(list_one)
print(list_two)运行结果
python
[13, 32, 34, 63, 67, 82, 93]3)reverse()方法
用于逆置列表,即把原列表中的元素从右至左依次排列存放。
python
list_one = [32,67,34,63,82,93,13]
list_one.reverse()
print(list_one)
list_one.reverse()
print(list_one)运行结果
python
[13, 32, 34, 63, 67, 82, 93]
[93, 82, 67, 63, 34, 32, 13]5.2.5 删除元素
删除列表元素的常用方式有del语句、remove()方法、pop()方法和clear()方法。
1)del语句
用于删除列表中指定位置的元素。
python
list_one = [32,67,34,63,82,93,13]
del list_one[2]
print(list_one)运行结果
python
[32, 67, 63, 82, 93, 13]del也可以删除整个列表
python
list_one = [32,67,34,63,82,93,13]
del list_one
print(list_one)运行结果,出现错误信息,因为已经将列表删除,所以后续在引用变量就会导致报错
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\列表.py", line 76, in <module>
print(list_one)
^^^^^^^^
NameError: name 'list_one' is not defined2)remove()方法
用于移除列表中的某个元素,若列表中有多个匹配的元素,remove()只移除匹配到的第1个元素。
python
list_one = [32,67,34,63,82,93,13]
list_one.remove(63)
print(list_one)运行结果
python
[32, 67, 34, 82, 93, 13]3)pop()方法
用于移除列表中的某个元素,若未指定具体元素,则移除列表中的最后1个元素。
python
list_one = [32,67,34,63,82,93,13]
a = list_one.pop()
print(a)
result = list_one.pop(0)
print(result)
print(list_one)运行结果
python
13
32
[67, 34, 63, 82, 93]4)clear()方法
用于清空列表。
python
list_one = [32,67,34,63,82,93,13]
list_one.clear()
print(list_one)运行结果
python
[]5.2.6 列表推导式
列表推导式是符合Python语法规则的复合表达式,它用于以简洁的方式根据已有的列表构建满足特定需求的列表。
python
[exp for x in list]以上格式由表达式exp和之后的for...in...语句组成。其中,for...in...用于遍历列表(或者其他可迭代对象);exp用于在每层循环中对列表中的元素进行运算。
使用上面的列表推导式可方便的修改列表中的每个元素。例如,将一个列表中每个元素都替换成它的平方。
python
list_one = [1,2,3,4,5]
a =[ i*i for i in list_one]
print(a)
list_one = [1,2,3,4,5]
a =[ i*i for i in list_one if i%2==0]
print(a)运行结果
python
[1, 4, 9, 16, 25]
[4, 16]列表推导式还可以结合if判断语句或for循环嵌套,生成更灵活的列表。
1)带有if语句的列表推导式
在基本列表推导式的for语句之后添加一个if语句,就组成了带有if语句的列表推导式。
python
[exp for x in list if cond]上面格式的功能是:遍历列表,若列表中的元素x符合条件cond,按表达式exp对其进行运算后将其添加到新列表中。
例如上例结果列表中只保留大于4的元素。
python
list_one = [1,2,3,4,5,6,7]
a =[ i*i for i in list_one if i>4]
print(a)运行结果
python
[25, 36, 49]2)嵌套for循环语句的列表推导式
在基本列表推导式的for语句之后添加一个for语句,就实现了列表推导式的循环嵌套。
python
[exp for x in list_1 for y in list_2]以上格式中的for语句按从左至右的顺序分别是外层循环和内层循环。利用此格式可以根据2个列表快速生成一个新的列表。
3)带有if语句和嵌套for循环语句的列表推导式
列表推导式中嵌套的for循环可以有多个,每个循环也都可以与if语句连用(应用场景不多,了解即可)。
python
[exp for x in list_1 [if cond]
for y in list_2 [if cond]
...
for n in list_n [if cond]]5.2.7 成绩录入系统
python
menu="""
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
"""
info = [['刘备',80,88,92],['张飞',86,78,91]]
while True:
#打印菜单
print(menu)
num = int(input('请输入数字:'))
#录入成绩
if num == 1:
#生成子列表,存放数据
list = []
name = input('请输入名字:')
#添加开关变量
doing = True
#判断是否存在
for i in info:
if name == i[0]:
print('已存在,请重新输入!')
doing = False
if doing:
list.append(name)
list.append(int(input('请输入语文成绩:')))
list.append(int(input('请输入数学成绩:')))
list.append(int(input('请输入英语成绩:')))
print('成绩输入完成!!')
#查询成绩
elif num == 2:
print('1.查看所有信息 2.查看个人信息')
num2 = int(input('请输入查看序号:'))
#查看所有成绩,并打印
if num2 == 1:
print('姓名 语文 数学 英语')
for i in info:
for j in i:
print(j, end=' ')
print()
elif num2 == 2:
name = input('请输入查询姓名:')
print('姓名 语文 数学 英语')
for i in info:
if name == i[0]:
for j in i:
print(j, end=' ')
#修改成绩
elif num == 3:
#打印所有人成绩清单
print('姓名 语文 数学 英语')
for i in info:
for j in i:
print(j, end=' ')
print()
name = input('请输入修改姓名:')
print('1.语文 2.数学 3.英语')
num3 = int(input('请输入修改科目:'))
score = int(input('请输入修改成绩:'))
for i in info:
if name == i[0]:
i[num3] = score
print('修改完成!!')
#删除成绩
elif num == 4:
#打印所有信息清单
print('姓名 语文 数学 英语')
for i in info:
for j in i:
print(j, end=' ')
print()
name = input('请输入删除姓名:')
for i in info:
if name == i[0]:
info.remove(i)
print('删除成功!!')
#退出程序
else:
print('退出系统,欢迎下次使用!!')
break运行结果
python
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:2
1.查看所有信息 2.查看个人信息
请输入查看序号:1
姓名 语文 数学 英语
刘备 80 88 92
张飞 86 78 91
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:1
请输入名字:关羽
请输入语文成绩:87
请输入数学成绩:89
请输入英语成绩:90
成绩输入完成!!
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:2
1.查看所有信息 2.查看个人信息
请输入查看序号:1
姓名 语文 数学 英语
刘备 80 88 92
张飞 86 78 91
关羽 87 89 90
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:2
1.查看所有信息 2.查看个人信息
请输入查看序号:2
请输入查询姓名:刘备
姓名 语文 数学 英语
刘备 80 88 92
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:3
姓名 语文 数学 英语
刘备 80 88 92
张飞 86 78 91
关羽 87 89 90
请输入修改姓名:关羽
1.语文 2.数学 3.英语
请输入修改科目:1
请输入修改成绩:70
修改完成!!
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:2
1.查看所有信息 2.查看个人信息
请输入查看序号:2
请输入查询姓名:关羽
姓名 语文 数学 英语
关羽 70 89 90
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:4
姓名 语文 数学 英语
刘备 80 88 92
张飞 86 78 91
关羽 70 89 90
请输入删除姓名:关羽
删除成功!!
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:2
1.查看所有信息 2.查看个人信息
请输入查看序号:1
姓名 语文 数学 英语
刘备 80 88 92
张飞 86 78 91
1.添加成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
请输入数字:5
退出系统,欢迎下次使用!!5.3 元组
元组的表现形式为一组包含在圆括号"()"中、由逗号分隔的元素,元组中元素的个数、类型不受限制。
使用圆括号可以直接创建元组,还可以使用内置函数tuple()构建元组。
python
tuple_one = ()
print(type(tuple_one))
tuple_two = tuple()
print(type(tuple_two))运行结果
python
<class 'tuple'>
<class 'tuple'>
python
t2 = (1,) #包含单个元素的元组
t3 = (1,2,3) #包含多个元素的元组
t4 = (1,'h',('o',2)) #元组嵌套当使用圆括号"()"创建元组时,如果元组中只包含一个元素,那么需要在该元素的后面添加逗号,从而保证Python解释器能够识别其为元组类型。
使用内置函数tuple()也可以创建元组,当函数的参数列表为空时该函数常见空元组,当参数为可迭代对象时该函数创建非空元组。
python
t1 = tuple() #创建空元组
t2 = tuple([1,2,3]) #利用列表创建元组(1,2,3)
t3 = tuple('python') #利用字符串创建元组('p','y','t','h','o','n')
t4 = tuple(range(5)) #利用可迭代对象创建元组(0,1,2,3,4)与列表相同,Python支持通过索引和切片访问元组的元素,也支持在循环中遍历元组。
python
print(t2[1]) #以索引方式访问元组元素
print(t3[2:5]) #以切片方式访问元组元素
for data in t3: #在循环中遍历元组
print(data,end='')运行结果
python
2
('t', 'h', 'o')
python注意:元组是不可变类型,元组中的元素不能修改,即它不支持添加元素,删除元素和排序操作。
5.4 实例案例
5.4.1 神奇魔方
魔方阵又称纵横图,是一种n行n列、由自然数1~n×n组成的方阵,该方阵中的数符合以下规律:
- 方阵中的每个元素都不相等。
- 每行、每列以及主、副对角线上的个元素之和都相等。
本实例要求编写程序,输出一个5行5列的魔方阵。
5.5 集合
Python的集合(set)本身是可变类型,但Python要求放入集合中的元素必须是不可变类型。
集合类型与列表和元组的区别是:集合中的元素无序但必须唯一。
1)创建集合
集合的表现形式为一组包含在大括号"{}"中、由逗号","分隔的元素。使用"{}"可以直接创建集合,使用内置函数set()也可以创建集合。
python
set_one = {}
set_two = {11,22,33,44,55,66,77,88,99}使用内置函数set()也可以创建集合。该函数的参数列表可以为空,此时该函数创建一个空集合。
python
set_one = set()
set_two = {11,22,33,44,55,66,77,88,99}
print(type(set_one))
print(type(set_two))运行结果
python
<class 'set'>
<class 'set'>==注意!==使用{}不能创建空集合(不包含元素的{}创建的是字典变量),空集合只能利用set()函数创建。
若使用set()函数创建非空集合,需为该函数传入可迭代对象。
python
s1 = set([1,2,3]) #传入列表
s2 = set((2,3,4)) #传入元组
s3 = set('python') #传入字符串
s4 = set(range(5)) #传入整数列表
print(s1)
print(s2)
print(s3)
print(s4)运行结果
python
{1, 2, 3}
{2, 3, 4}
{'h', 't', 'o', 'n', 'p', 'y'}
{0, 1, 2, 3, 4}2)集合的常见操作
集合是可变的,集合中的元素可以动态增加或删除。Python提供了一些内置方法来操作集合,常见内置方法如下:
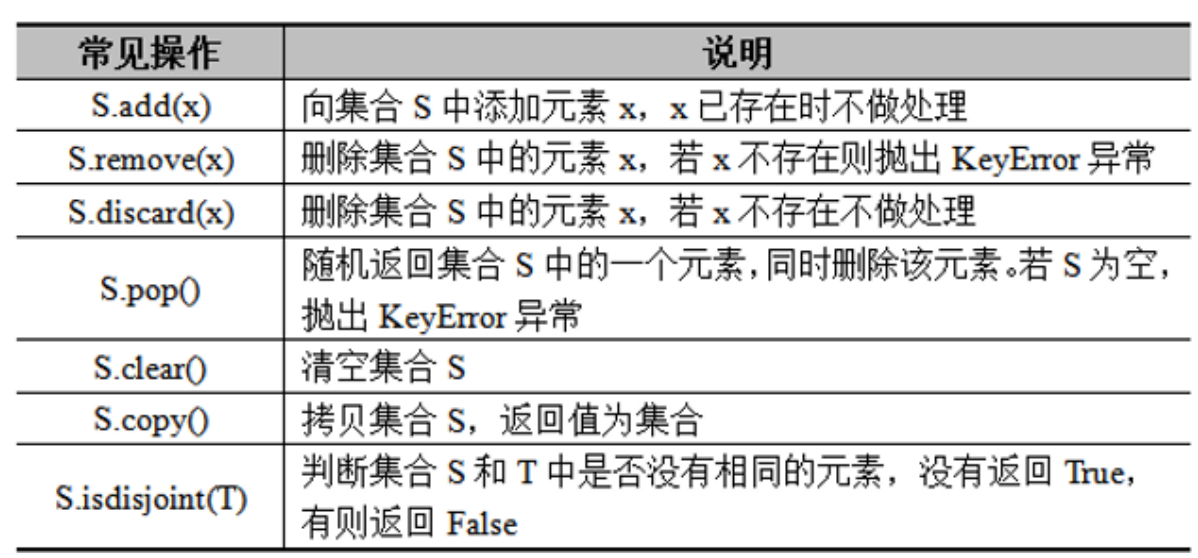
代码示例
python
set_one = {10,20,30,40,50,60,70,80,90,100}
set_one.add(0)
print(set_one)
set_one.remove(10)
print(set_one)
set_one.discard(100)
print(set_one)
result = set_one.pop()
print(set_one)
print(result)
set_two = set_one.copy()
print(set_two)
print(set_one)
set_two = {11,22,33,44,55,66,77,88,99}
print(set_one.isdisjoint(set_two))
python
set_one.clear()
print(set_one)扩展:pop() 是基于HashMap实现的,它总是「删除」集合中的「第一个元素」,由于集合是「无序」的,所以它看起来就像是「随机」删除元素。当集合中的元素是「纯数字」时,集合会按照从小到大的顺序排列元素,「最小」的数值会别排在第一个,所以pop()时,会删除最小的那个元素。
运行结果
python
{0, 100, 70, 40, 10, 80, 50, 20, 90, 60, 30}
{0, 100, 70, 40, 80, 50, 20, 90, 60, 30}
{0, 70, 40, 80, 50, 20, 90, 60, 30}
{70, 40, 80, 50, 20, 90, 60, 30}
0
{70, 40, 80, 50, 20, 90, 60, 30}
{70, 40, 80, 50, 20, 90, 60, 30}
True
python
set()3)集合推导式
集合也可以利用推导式创建,集合推导式的格式与列表推导式相似,区别在于集合推导式外侧为大括号"{}"。
python
{exp for x in set if cond}以上格式中遍历的可以是集合或者其他可迭代对象。利用集合推导式在列表ls的基础上生成只包含偶数元素的集合。
5.6 字典
提到字典这个词相信大家都不会陌生,学生时期碰到不认识的字时,大家都会使用字典的部首表查找对应的汉字。Python中的字典数据与学生使用的字典有类似的功能,它以"键值对"的形式组织数据,利用"键"快速查找"值"。通过"键"查找"值"的过程称为映射,Python中的字典是典型的映射类型。
5.6.1 创建字典
字典的表现形式为一组包含在大括号"{}"中的键值对,每个键值对为一个字典元素,每个元素通过逗号","分隔,每对键值通过":"分隔。
python
{键1:值1, 键2:值2,...,键N:值N}字典的值可以是任意类型,但键不能是列表或字典类型。字典像集合一样使用"{}"包裹元素,它也具备类似集合的特点:字典元素无序,键值必须唯一。
使用"{}"可以直接创建字典。
python
d1 = {} #创建空字典
d2 = {'A':'123','B':'135','C':'680'}
d3 = {'A':123,12:'python'}还可以使用内置函数dict()创建字典。
python
d4 = dict()
d5 = dict({'A':'123','B':'135'})5.6.2 字典的访问
字典的值可通过"键"或内置方法get()访问。
python
字典变量[键]
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
print(dict_one['name'])运行结果
python
dyx字典涉及的数据分为键、值和元素(键值对),除了直接利用键访问值外,Python还提供了内置方法keys()、values()和items()。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict = dict()
print(dict_one.get('name'))
print(dict_one.get('age'))
print(dict_one.get('score'))运行结果
python
dyx
21
[89, 87, 90]字典涉及的数据分为键、值和元素(键值对),除了直接利用键访问值外,python还提供了用于访问字典中所有键、值的元素的内置方法keys()、values()和items()。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
print(dict_one.keys())
print(dict_one.values())
print(dict_one.items())运行结果
python
dict_keys(['name', 'age', 'score'])
dict_values(['dyx', '21', [89, 87, 90]])
dict_items([('name', 'dyx'), ('age', '21'), ('score', [89, 87, 90])])内置方法keys()、values()、items()的返回值都是可迭代对象,利用循环可以遍历这些对象。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
for key,value in dict_one.items():
print(key,value)
print()运行结果
python
name dyx
age 21
score [89, 87, 90]5.6.3 字典元素的添加和修改
字典支持通过为指定的键赋值或使用update()方法添加或修改元素。
1)字典元素的添加
当字典中不存在某个键时,利用一下格式可在字典中新增一个元素。
python
字典变量[键] = 值
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict_one['age']='22'
print(dict_one)
python
dict_one['hobby']='sleep'
print(dict_one)运行结果
python
{'name': 'dyx', 'age': '22', 'score': [89, 87, 90]}
python
{'name': 'dyx', 'age': '21', 'score': [89, 87, 90], 'hobby': 'sleep'}使用update()方法代替以上方式添加元素语句,相同结果
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict_one.update(age = 24)
print(dict_one)运行结果
python
{'name': 'dyx', 'age': 24, 'score': [89, 87, 90]}2)字典元素的修改
修改字典元素的本质是通过键获取值,再重新对元素进行赋值。修改元素的操作与添加元素的操作相同。
python
info = {'stu1':'张三','stu2':'李四','stu3':'王五'}
info.update(stu2='赵六') #使用update()修改
info['stu3'] = '田七' #通过指定键修改
print(info)运行结果
python
{'stu1': '张三', 'stu2': '赵六', 'stu3': '田七'}5.6.4 字典元素的删除
Python支持通过pop()、popitem()和clear()方法删除字典中的元素。
1)pop()方法
pop():根据指定键值删除字典中的指定元素,若删除成功,返回目标元素的值。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict_one.pop('score')
print(dict_one)运行结果
python
{'name': 'dyx', 'age': '21'}2)popitem()方法
popitem():随机删除字典中的元素。实际上popitem()之所以能随机删除元素,是因为字典元素本身无序,没有第1个和最后1个之分。若删除成功,popitem()方法返回被删除的元素。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict_one.popitem()
print(dict_one)运行结果
python
{'name': 'dyx', 'age': '21'}3)clear()方法
clear():清空字典中的元素。
python
dict_one = {'name': 'dyx','age':'21','score':[89,87,90]}
dict_one.clear()
print(dict_one)运行结果
python
{}5.6.5 字典推导式
字典推导式的格式、用法与列表推导式类似,区别在于字典推导式外侧为大括号"{}",且内部需包含键和值两部分。
python
{new_key:new_value for key,value in dict.items()}利用字典推导式可快速交换字典中的键和值
python
old_dic = {'name':'tomc','age':18,'height':180}
new_dic = {value : key for key,value in old_dic.items()}
print(new_dic)运行结果
python
{'tomc': 'name', 18: 'age', 180: 'height'}5.7 实训案例
5.7.1 成绩录入系统改成字典
5.8 本章小结
本章介绍了Python中的组合数据类型 ,然后分别介绍了Python中常用的组合数据类型:列表、元组、集合 和字典 的创建和使用,并结合实例案例帮助大家巩固这些数据类型,最后介绍了组合数据类型与运算符的相关知识。
第六章 函数
在实际开发中,如果有若干段代码的执行逻辑完全相同,那么可以考虑将这些代码抽取成一个函数,这样不仅可以提高代码的重用性,而且条理会更加清晰,可靠更高。
6.1 函数概述
函数是组织好的、实现单一功能或相关联功能的代码段。我们可以将函数视为一段有名字的代码,这类代码可以在需要的地方以"函数名()"的形式调用。
python
print() #输出函数
input() #输入函数函数式编程具有以下优点:
1:将程序模块化,既减少了冗余代码,又让程序结构更为清晰。
2:提高开发人员的编程效率。
3:方便后期的维护与扩展。
6.2 函数的定义和调用
6.2.1 定义函数
在Python中,可以定义个自己想要功能的函数,自定义函数的语法格式如下:

定义一个计算两个数之和的函数。
无参数方式
python
def add():
result = 10 + 20
print(result)
add()运行结果
python
30有参数方式
python
def sub(a,b):
result = a + b
print(result)
sub(11,22)运行结果
python
336.2.2 调用函数
函数在定义完成后不会立刻执行,直到被程序调用时才会执行。
语法格式如下:
python
函数名([参数列表])调用示例:
python
add()
add_modify(10,20)原理图如下:
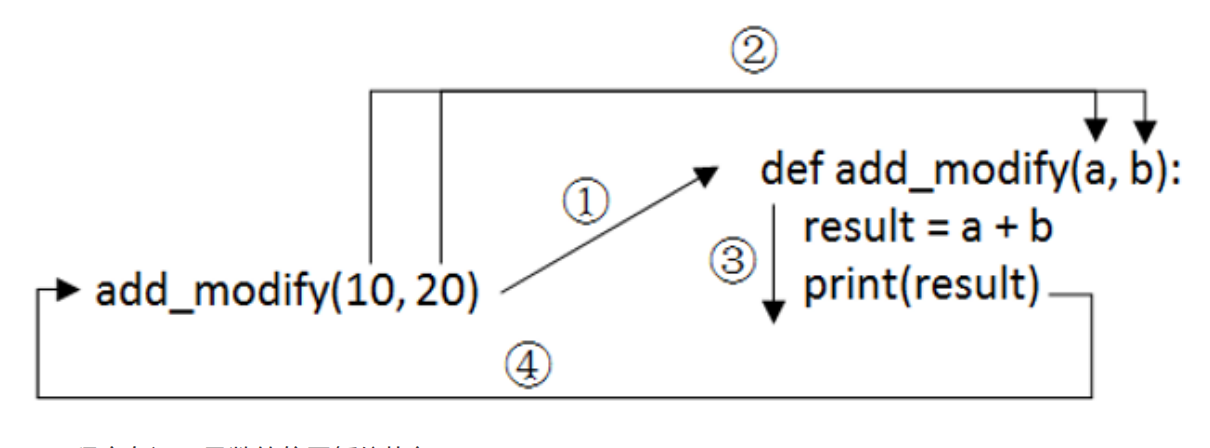
- 程序在调用函数的位置暂停执行。
- 将数据传递给函数参数。
- 执行函数体中的语句。
- 程序回到暂停处继续执行。
嵌套调用:函数内部也可以调用函数,我们称之为嵌套调用,示例代码如下
python
def add():
result = 10 + 20
print(result)
def sub(a,b):
result = a + b
print(result)
add()
sub(11,22)运行结果
python
33
30原理图如下:
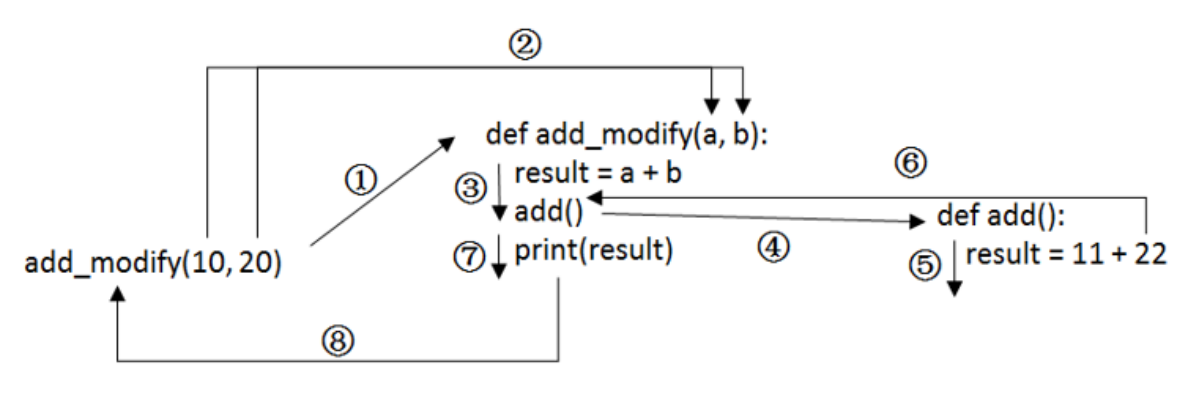
嵌套定义:函数在定义时可以在其内部嵌套定义另外一个函数,此时嵌套的函数称为外层函数,被嵌套的函数称为内层函数。
python
def func(a,b):
result=a+b
def add():
r= 10+20
print(r)
add()
print(result)
func(11,22)运行结果
python
30
33注意:
1)函数外部无法直接调用内层函数
2)只能通过外层函数间接调用内层函数
6.3 函数参数传递
我们通常将定义函数时设置的参数称为形式参数(简称为形参),将调用函数时传入的参数称为实际参数(简称为实参)。函数的参数传递是指将实际参数传递给形式参数的过程。
函数参数的传递可以分为位置参数传递、关键字参数传递、默认参数传递、参数的打包与解包以及混合传递。
6.3.1 位置参数的传递
函数在被调用时会将实参按照相应的位置依次传递给形参,也就是说将第一个实参传递给第一个形参,将第二个实参传递给第二个形参,以此类推。
定义函数比较两数大小,代码示例:
python
def sub(a,b):
result = a + b
print(result)
sub(11,22)运行结果
python
336.3.2 关键字参数的传递
关键字参数的传递是通过"形参=实参"的格式将实参与形参相关联,将实参按照相应的关键字传递给形参。
python
def func(ip,port):
print(f'地址{ip},端口{port}')
func('127.0.0.1',8000)
func(ip='127.0.0.1',port=8000)运行结果
python
地址127.0.0.1,端口8000
地址127.0.0.1,端口8000扩展:无论实参采用位置参数的方式传递,还是关键字参数的方式传递,每个形参都是有名称的,怎么区分用哪种方式传递呢?
python
使用"/"前面的必须为位置参数
使用"*"后面的必须为关键字参数Python从3.8版本开始新增了仅限位置形参的语法,使用符号"/"和"*"来限定部分形参只接收采用位置传递方式的实参。

python
def func(a,/,b,*,c):
print(a,b,c)
func(1, 2, c=3)
func(1, b=2, c=3)运行结果
python
1 2 3
1 2 3总结:b既可以为位置参数,也可以为关键字参数。
6.3.3 默认参数的传递
函数在定义时可以指定形参的默认值,如此在被调用时可以选择是否给带有默认值的形参传值,若没有给带有默认值的形参传值,则直接使用该形参的默认值。
python
def func(ip,port=3306):
print(f'地址{ip},端口{port}')
func(ip='127.0.0.1',port=8000)
func(ip='127.0.0.1')运行结果
python
地址127.0.0.1,端口8000
地址127.0.0.1,端口33066.3.4 参数的打包与解包
1)打包
如果函数在定义时无法确定需要接收多少个数据,那么可以在定义函数时为形参添加"*"或"**":
python
"*" 接收以元组形式打包的多个值
"**" 接收以字典形式打包的多个值元组形式打包代码示例:
python
def func(*args):
print(type(args))
print(args)
func(1,2,3,4)运行结果:
python
<class 'tuple'>
(1, 2, 3, 4)字典形式打包代码示例:
python
def func(**kwargs):
print(type(kwargs))
for item in kwargs.items():
print(item)
print(kwargs)
func(a=1, b=2, c=3)运行结果:
python
<class 'dict'>
('a', 1)
('b', 2)
('c', 3)
{'a': 1, 'b': 2, 'c': 3}总结:
1:虽然函数中添加"*"和"**"的形参可以是符合命名规范的任意名称,但这里建议使用 * args和 * *kwargs。
2:若函数没有接收到任何数据,参数 * args 和 * * kwargs为空,即它们为空元组和空字典。
2)解包
实参是元组 → 可以使用 * 拆分成多个值 → 按位置参数传给形参
实参是字典 → 可以使用 * * 拆分成多个键值对 → 按关键字参数传给形参
python
tuple_one = (1, 2, 3,4)
dict_one = {'a':1,'c':3,'b':2, 'd':4}
def func(a,b,c,d):
print(a,b,c,d)
func(*tuple_one)
func(**dict_one)运行结果
python
1 2 3 4
1 2 3 46.3.5 混合传递
前面介绍的参数传递的方式在定义函数或调用函数时可以混合使用,但是需要遵循一定的规则,具体规则如下。
- 优先按位置参数传递的方式。
- 然后按关键字参数传递的方式。
- 之后按默认参数传递的方式。
- 最后按打包传递的方式。
在定义函数时:
- 带有默认值的参数必须位于普通参数之后。
- 带有 * 标识的参数必须位于带有默认值的参数之后。
- 带有 * * 标识的参数必须位于带有 * 标识的参数之后。
混合参数传递代码示例:
python
def func(a,b,c=33,*args,**kwargs):
print(a,b,c,args,kwargs)
func(1,2)
func(2,3,4)
func(3,4,5,6,e=5)运行结果
python
1 2 33 () {}
2 3 4 () {}
3 4 5 (6,) {'e': 5} 6.4 函数的返回值
函数中的return语句会在函数结束时将数据返回给程序,同时让程序回到函数被调用的位置继续执行。
python
def test(words:str) -> str:
if '翻墙' in words:
tmp = words.replace('翻墙', '技术工具')
return tmp
print(test(input('请输入一段话:')))运行结果
python
请输入一段话:我利用翻墙进行下载镜像
我利用技术工具进行下载镜像如果函数使用return语句返回了多个值,那么这些值将被保存到元组中。
python
def test(a:int, b:int):
result1 = a + b
result2 = a*b
return result1, result2
k,v = test(10,20)
print(f'两数之和:{k}')
print(f'两数之积:{v}')运行结果
python
两数之和:30
两数之积:2006.5 变量作用域
变量并非在程序的任意位置都可以被访问,其访问权限取决于变量定义的位置,其所处的有效范围称为变量的作用域。
6.5.1 局部变量和全局变量
根据作用域的不同,变量可以划分为局部变量和全局变量。
1)局部变量
-
函数内部定义的变量,只能在函数内部被使用
-
函数执行结束之后局部变量会被释放,此时无法再进行访问。
python
def main():
number = 10
print(number)
main()
print(number)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\函数\返回值.py", line 21, in <module>
print(number)
^^^^^^
NameError: name 'number' is not defined
10不同函数内部可以包含同名的局部变量,这些局部变量的关系类似于不同目录下同名文件的关系,它们相互独立,互不影响。
python
def main():
#main局部变量number
number = 10
print(number)
main()
def main2():
#main2局部变量number
number = 20
print(number)
main2()运行结果
python
10
202)全局变量
全局变量可以在整个程序的范围内起作用,可以在程序的任意位置被访问,它不会受到函数范围的影响。
python
num = 10
def test():
print(num)
test()
print(num)运行结果
python
10
10强调:全局变量在函数内部只能被访问,而无法直接修改。
python
sum =100
def test():
sum = sum + 10
print(sum)
test()
print(sum)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\函数\返回值.py", line 39, in <module>
test()
~~~~^^
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\函数\返回值.py", line 37, in test
sum = sum + 10
^^^
UnboundLocalError: cannot access local variable 'sum' where it is not associated with a value报错原因:这是因为函数内部的变量number视为局部变量,而在执行"number+=1"这行代码之前并未声明过局部变量number。
python
sum =100
def test():
global sum
sum = sum + 10
print(sum)
test()
print(sum)运行结果
python
110
110也可以传参
扩展:LEGB原则
LEGB是程序中搜索变量时所遵循的原则,该原则中的每个字母指代一种作用域:
-
L-local:局部作用域。例如,局部变量和形参生效的区域。
-
E-enclosing:嵌套作用域。例如,嵌套定义的函数中外层函数声明的变量生效的区域。
-
G-global:全局作用域。例如,全局变量生效的区域。
-
B-built-in:内置作用域。例如,内置模块声明的变量生效的区域。
Python在搜索变量时会按照"L-E-G-B "这个顺序依次在这四种区域中搜索变量:若搜索到变量则终止搜索,使用搜索到的变量;若搜索完L、E、G、B这四种区域仍无法找到变量,程序将抛出异常。
代码示例:
python
import math
g_number = 10 #g_number,全局作用域为整个程序任意位置
def outer():
e_number = 20 #e_number,嵌套作用域为outer()和inner()范围
def inner():
l_number = 30 #l_number,局部作用域为inner()范围
print(l_number)
print(math.pi) #内置作用域,内置模块中声明
inner()
print(e_number)
outer()
print(g_number)运行结果
python
30
3.141592653589793
20
106.5.2 global和nonlocal关键字
函数内部无法直接修改全局变量或在嵌套函数的外层函数声明的变量,但可以使用global或nonlocal关键字修饰变量以间接修改以上变量。
1)global关键字
使用global关键字可以将局部变量声明为全局变量,其使用方法如下:
python
sum =100
def test():
global sum
sum = sum + 10
print(sum)
test()
print(sum)运行结果
python
110
1102)nonlocal关键字
使用nonlocal关键字可以在局部作用域中修改嵌套作用域中定义的变量,其使用方法如下:
python
def outer():
num =10
def inner():
number = 20
nonlocal num
num += 10
print(num)
inner()
outer()运行结果
python
206.6 实例案例
6.6.1 角谷猜想
角谷猜想又称冰雹猜想,是由日本数学家角谷静夫发现的一种数学现象,具体内容:以一个正整数n为例,如果n为偶数,就将它变为n/2,如果除后变为奇数,则将它乘3加1(即3n+1)。不断重复这样的运算,经过有限步后,必然会得到1。
本实例要求编写代码,计算用户输入的数据按照以上规律经多少次运算后可变为1。

python
def math(a):
count = 0
while True:
if a == 1:
return count
elif a % 2 == 0:
a = a//2
count += 1
else:
a = 3 * a + 1
count += 1
num = int(input('请输入一个数字:'))
print(f'运行{math(num)}次')运行结果
python
请输入一个数字:24
运行10次自己写的
python
def math(a):
count = 0
while a !=1:
if a % 2 == 0:
a = a // 2
count += 1
elif a % 2 == 1:
a = a*3 + 1
count += 1
else:
break
return count
print(math(5))6.7 特殊形式的函数
除了前面按标准定义的函数外,Python还提供了两种具有特殊形式的函数:递归函数和匿名函数。
6.7.1 递归函数
函数在定义时可以直接或间接地调用其他函数。若函数内部调用了自身,则这个函数被称为递归函数。
递归函数在定义时需要满足两个基本条件:一个是递归公式,另一个是边界条件。其中:
-
递归公式是求解原问题或相似的子问题的结构。
-
边界条件是最小化的子问题,也是递归终止的条件。
递归函数的执行可以分为以下两个阶段:
- 递推:递归本次的执行都基于上一次的运算结果。
- 回溯:遇到终止条件时,则沿着递推往回一级一级地把值返回来。
递归函数的一般定义格式如下所示:
python
def 函数名([参数列表]):
if 边界条件:
rerun 结果
else:
return 递归公式递归经典案例:
案例1:阶乘n!:
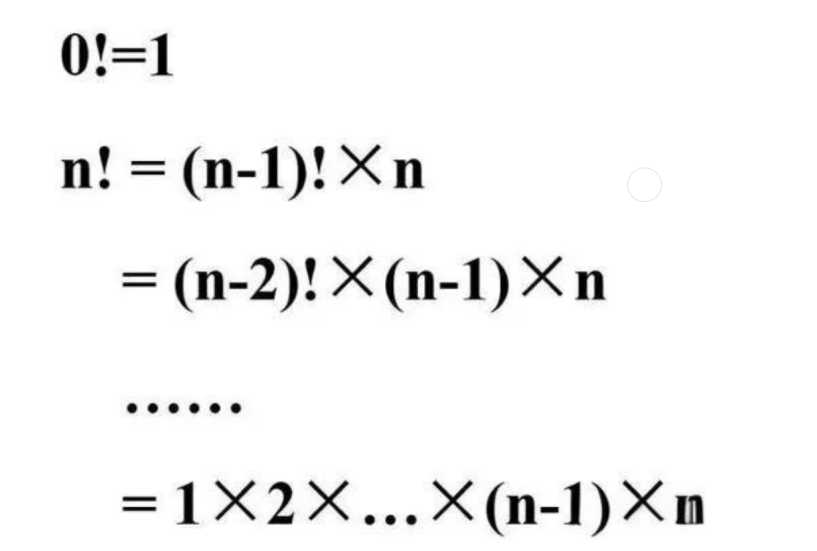
n! = 1 * 2 * 3 * ... * n,可以分为以下两种情况:
- 当n=1时,所得的结果为1。
- 当n>1时,所得的结果为n*(n-1)!。
python
def math(num):
if num == 1:
return 1
else:
return num * math(num - 1)
num = int(input("Enter a number: "))
print(math(num))运行结果
python
Enter a number: 5
120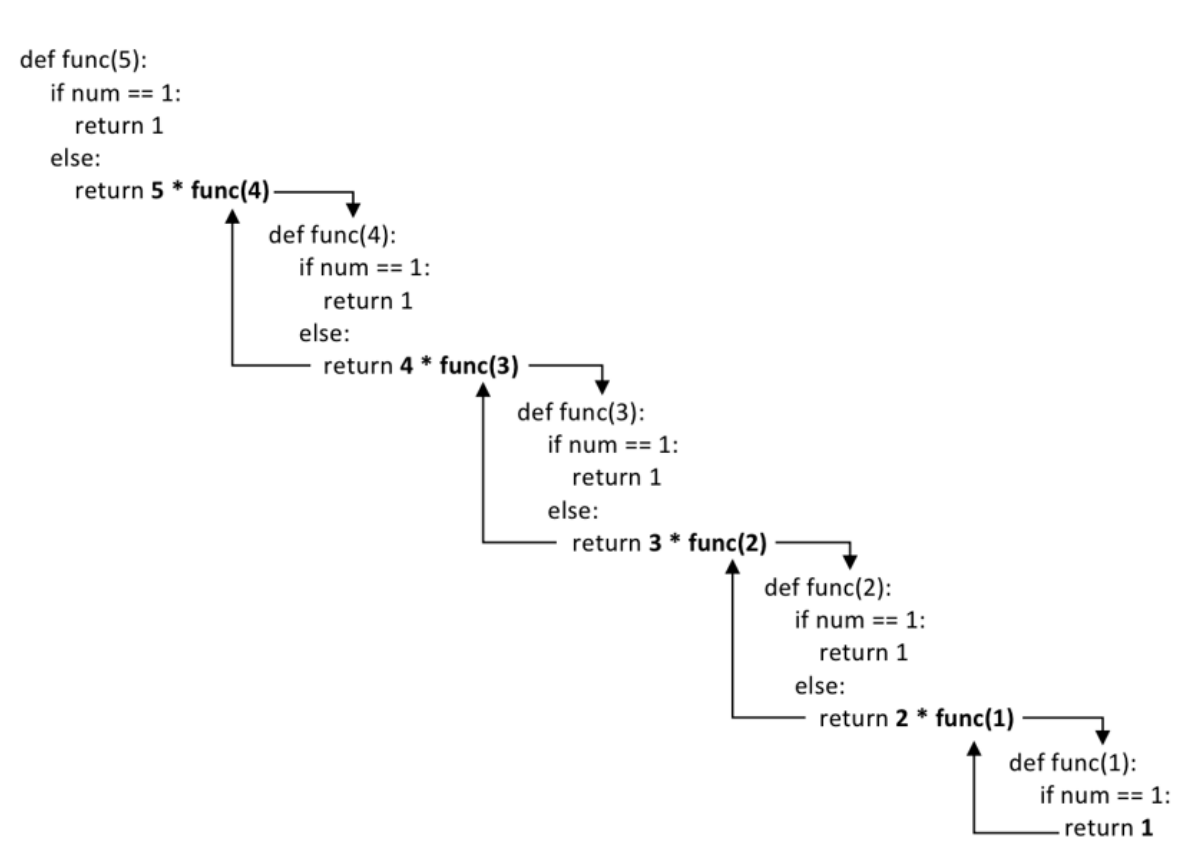
6.7.2 匿名函数
匿名函数是一类无需定义标识符的函数,它与普通函数一样可以在程序的任何位置使用。Python中使用lambda关键字定义匿名函数,它的语法格式如下:
python
lambda <形式参数列表> :<表达式>匿名函数与普通函数的主要区别如下:
-
普通函数在定义时有名称,而匿名函数没有名称;
-
普通函数的函数体中包含有多条语句,而匿名函数的函数体只能是一个表达式;
-
普通函数可以实现比较复杂的功能,而匿名函数可实现的功能比较简单;
-
普通函数能被其他程序使用,而匿名函数不能被其他程序使用。
定义好的匿名函数不能直接使用,最好使用一个变量保存它,以便后期可以随时使用这个函数。
python
#定义匿名函数,并将它返回的函数对象赋值给变量temp
tmp = lambda x: pow(x, 2) #pow()为幂运算函数此时,变量temp可以作为匿名函数的临时名称来调用函数,代码示例:
python
print(tmp(2))运行结果
python
4多参数传递:
python
tmp = lambda x,y : x+y
print(tmp(3,4))运行结果
python
76.8 项目案例-学生管理系统
本案例要求开发一个具有添加、删除、修改、查询学生信息及退出系统功能的简易版的学生管理系统,系统的功能菜单如图所示。
6.9 本章小结
本章主要讲解了函数的相关知识,包括函数概述、函数的定义和调用、函数参数的传递、函数的返回值、变量作用域、特殊形式的函数,此外本章结合实训案例演示了函数的用法。
第七章:文件与数据格式化
程序中使用变量保存运行时产生的临时数据,程序结束后,临时数据随之消失。但一些程序中的数据需要持久保存,例如游戏程序中角色的属性数据,装备数据,物品数据等。那么使用什么方法能够持久保存数据呢?计算机可以使用文件持久地保存数据。本章将从计算机中文件的定义、基本操作、管理方式与数据维度等多个方面对计算机中与数据持久存储相关的知识进行介绍。
7.1 文件概述
文件在计算机中应用广泛,计算机中的文件是以硬盘等外部介质为载体,存储在计算机中的数据的集合,文本文档、图片、程序、音频等都是文件。
类似于程序中使用的变量,计算机中的每个文件也有唯一确定的标识,以便识别和引用文件。
1)文件标识
-
文件标识的意义:找到计算机中唯一确定的文件。
-
文件标识的组成:文件路径、文件名主干、文件扩展名。

- 操作系统以文件为单位对数据进行管理。
2)文件类型
根据数据的逻辑存储结构,人们将计算机中的文件分为文本文件和二进制文件。
-
文本文件:专门存储文本字符数据(使用记事本)。
-
二进制文件:不能直接使用文字处理程序正常读写,必须先了解其结构和序列化规则,再设计正确的反序列化规则,才能正确获取文件信息。
总结:二进制文件和文本文件这两种类型的划分基于数据逻辑存储结构而非物理存储结构,计算机中的数据在物理层面都以二进制形式存储。
扩展:标准文件
Python的sys模块中定义了3个标准文件,分别为:
-
stdin(标准输入文件)。标准输入文件对应输入设备,如键盘。
-
stdout(标准输出文件)。
-
stderr(标准错误文件)。标准输出文件和标准错误文件对应输出设备,如显示器。
在解释器中导入sys模块后,便可对标准文件进行操作。
python
import sys
file = sys.stdout
file.write('hello world')运行结果
python
hello world7.2 文件的基础操作
文件的打开、关闭与读写是文件的基础操作,任何更复杂的文件操作都离不开这些操作。
7.2.1 文件的打开与关闭
将数据写入到文件之前需要先打开文件;数据写入完毕后需要将文件关闭以释放计算机内存。
1)打开文件
内置函数open()用于打开文件,该方法的声明如下:
python
open(file, mode='r', buffering=None)-
file:文件的路径。
-
mode:设置文件的打开模式,取值有r、w、a。
- r:以只读方式打开文件(mode参数的默认值)。
- w:以只写方式打开文件。
- a:以追加方式打开文件。
- b:以二进制形式打开文件。
- +:以更新的方式打开文件(可读可写)
-
buffering:设置访问文件的缓冲方式。取值为0或1。
| 打开模式 | 名称 | 描述 |
|---|---|---|
| r/rb | 只读模式 | 以只读的形式打开文本文件/二进制文件,若文件不存在或无法找到,文件打开失败 |
| w/wb | 只写模式 | 以只写的形式打开文本文件/二进制文件,若文件已存在,则重写文件,否则创建新文件 |
| a/ab | 追加模式 | 以只写的形式打开文本文件/二进制文件,只允许在该文件末尾追加数据,若文件不存在,则创建新文件 |
| r+/rb+ | 读取(更新)模式 | 以读/写的形式打开文本文件/二进制文件,若文件不存在,文件打开失败 |
| w+/wb+ | 写入(更新)模式 | 以读/写的形式打开文本文件/二进制文件,若文件已存在,则重写文件 |
| a+/ab+ | 追加(更新)模式 | 以读/写的形式打开文本/二进制文件,只允许在文件末尾添加数据,若文件不存在,则创建新文件 |
返回值:若open()函数调用成功,返回一个文件对象。
python
file1 = open('d:\\test\\abcd.txt','r')#以只读方式打开f盘的文本文件abcd.txt
print(file1)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\文件\文件输出.py", line 6, in <module>
file1 = open('d:\\test\\abcd.txt','r')
FileNotFoundError: [Errno 2] No such file or directory: 'd:\\test\\abcd.txt'此时abcd.txt 文件不存在,因此出现错误
python
file = open('d:\\damoe1.txt','w')#以只写方式打开f盘的文本文件damoe1.txt,若文件不存在则自动创建新文件
print(file)运行结果
python
<_io.TextIOWrapper name='d:\\damoe1.txt' mode='w' encoding='cp936'>2)关闭文件
Python可通过close()方法关闭文件,也可以使用with语句实现文件的自动关闭。
1:close()方法,是文件对象的内置方法。
python
file.close()
python
file = open('d:\\test\\abc.txt','r')
content = file.read()
print(content)
file.close()
content = file.read()
print(content)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\文件\文件输出.py", line 16, in <module>
content = file.read()
ValueError: I/O operation on closed file.
this is a cloud test
life is short
i study python文件关闭了之后,不能读取
2:with语句,可预定义清理操作,以实现文件的自动关闭。
python
with open("d:\\test\\test.txt",'r') as f:
print('test.txt is closed')运行结果
python
test.txt is closed以上示例中as后的变量f用于接收with语句打开的文件对象。程序中无须再调用close()方法关闭文件,文件对象使用完毕后,with语句会自动关闭文件。
思考:为什么要及时关闭文件?
- 计算机中可打开的文件数量是有限。
- 打开的文件占用系统资源。
- 若程序因异常关闭,可能产生数据丢失。
7.2.2 文件的读写
Python提供了一系列读写文件的方法,包括读取文件的read()、readline()、readlines()方法和写文件的write()、writelines()方法,下面结合这些方法分别介绍如何读写文件。
1)读取文件-read()方法
read()方法可以从指定文件中读取指定字节的数据,其语法格式如下:
python
read(size)size:表示要从文件中读取的数据的长度,单位:字节,如果没有指定size,那么就表示读取文件的全部数据。
读取d盘中abc.txt的数据,代码示例如下
方法一:
python
file = open('d:\\test\\abc.txt','r')
connect = file.read(3)
print(connect)
print('-'*30)
connect = file.read()
print(connect)
file.close()运行结果
python
thi
------------------------------
s is a cloud test
life is short
i study python方法二:
python
with open('d:\\test\\abc.txt','r') as f:
#读取两个字节的数据
print(f.read(4))
#读取剩余的全部数据
print(f.read())2)读取文件-readline()方法
readline()方法可以从指定文件中读取一行数据,其语法格式如下:
python
readline()使用readline()读取f盘中luckycloud.txt文件,代码示例如下
python
with open('d:\\test\\abc.txt','r') as f:
print(f.readline())
print(f.readline())运行结果
python
this is a cloud test
life is short扩展:假如出现如下报错如何解决
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\文件\文件输出.py", line
10, in <module>
print(f.readline())
^^^^^^^^^^^^
UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal
multibyte sequence原因:表示在尝试使用GBK编码解码字节数据时,遇到了一个不合法的字节(0xff),解码器无法继续解码。这通常发生在读取文件时指定了错误的编码,而文件实际上并非GBK编码。
解决方法如下:
当处理文本数据时,经常会遇到各种不同的字符编码。这可能导致乱码和其他问题,因此需要一种方法来准确识别文本的编码。Python中的 chardet 库就是为了解决这个问题而设计的,它可以自动检测文本数据的字符编码。
bash
(.venv) PS C:\Users\86189\PyCharmMiscProject> `pip install chardet`
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting chardet
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/38/6f/f5fbc992a329ee4e0f288c1fe0e2ad9485ed064cac731ed2fe47dcc38cbf/chardet-5.2.0-py3-none-any.whl (199 kB)
Installing collected packages: chardet
Successfully installed chardet-5.2.0
python
#获取文本字符集, 封装函数:传参:文件标识,返回值:字符集
filepath = 'd:\\test\\abc.txt'
import chardet
def file_get_contents(file:str)->str:
with open(file,'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(filepath,mode='r',encoding = file_get_contents(filepath)) as f:
while True:
connect = f.readline()
if connect == '':
break
else:
print(connect)运行结果:默认UTF-16字符集
python
this is a cloud test
life is short
i study python3)readlines()方法
readlines()方法可以一次读取文件中的所有数据,若读取成功,该方法会返回一个列表,文件中的每一行对应列表中的一个元素。语法格式如下:
python
readlines(hint=-1)- hint:单位为字节,用于控制要读取的行数如果行中数据的总大小超出了hint字节,readlines()不会再读取更多的行。
使用readlines()读取f盘中luckycloud.txt文件,代码示例如下
python
filepath = 'd:\\test\\abc.txt'
import chardet
def file_get_contents(file:str)->str:
with open(file,'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(filepath,mode='r',encoding = file_get_contents(filepath)) as f:
print(f.readlines())运行结果
python
['this is a cloud test\n', 'life is short\n', 'i study python']总结:
-
read()(参数缺省时)和readlines()方法都可一次读取文件中的全部数据,但因为计算机的内存是有限的,若文件较大,read()和readlines()的一次读取便会耗尽系统内存,所以这两种操作都不够安全。
-
为了保证读取安全,通常多次调用read()方法,每次读取size字节的数据。
4)写文件-write()方法
write()方法可以将指定字符串写入文件,其语法格式如下:
python
write(data)以上格式中的参数data表示要写入文件的数据,若数据写入成功,write()方法会返回本次写入文件的数据的字节数。
使用write()向luckycloud.txt文件中写入数据,示例代码如下:
python
words = input('写入一段话:')
with open('d:\\test\\demo03.txt', 'w',encoding='utf-8') as f:
size = f.write(words)
print('成功写入;',size,'字节')运行结果,字符串数据成功写入文件。此时打开demo03.txt文件,可在该文件中看到写入的字符串。
python
写入一段话:i use python
成功写入; 12 字节5)writelines()方法
writelines()方法用于将行列表写入文件,其语法格式如下:
python
writelines(lines)-
以上格式中的参数lines表示要写入文件中的数据,该参数可以是一个字符串或者字符串列表。
-
若写入文件的数据在文件中需要换行,需要显式指定换行符。
使用writelines()向luckycloud.txt文件中写入数据,示例代码如下:
python
string = ['Life is short\n','I use python']
with open('d:\\test\\demo.txt','w',encoding='utf-8') as f :
size = f.writelines(string)
print(size)运行代码,若没有输出信息,说明字符串被成功写入文件。
python
None总结:
-
write:将字符串写入文件,适用于单行写入。要求传入的参数必须是字符串类型。如果传入其他类型(如列表),会导致错误。
-
writelines:将字符串按行写入文件,适用于多行写入。可以接受字符串序列(如列表),但序列中的元素必须是字符串类型。如果传入其他类型(如数字),会导致错误。
扩展:字符与编码
文本文件支持多种编码方式,不同编码方式下字符与字节的对应关系不同,常见的编码方式以及字符与字节的对应关系如表所示。
| 编码方式 | 语言 | 字符数 | 字节数 |
|---|---|---|---|
| ASCII | 中文 | 1 | 2 |
| ASCII | 英文 | 1 | 1 |
| UTF-8 | 中文 | 1 | 3 |
| UTF-8 | 英文 | 1 | 1 |
| Unicode | 中文 | 1 | 2 |
| Unicode | 英文 | 1 | 2 |
| GBK | 中文 | 1 | 2 |
| GBK | 英文 | 1 | 1 |
7.2.3 文件的定位读写
read()方法读取了文件luckycloud.txt,结合代码与程序运行结果进行分析,可以发现read()方法第1次读取了2个字符,第2次从第3个字符开始读取了剩余字符。
-
在文件的一次打开与关闭之间进行的读写操作是连续的,程序总是从上次读写的位置继续向下进行读写操作。
-
每个文件对象都有一个称为"文件读写位置"的属性,该属性会记录当前读写的位置。
-
文件读写位置默认为0,即在文件首部。
Python提供了一些获取与修改文件读写位置的方法,以实现文件的定位读写。
-
tell():获取文件当前的读写位置。
-
seek():控制文件的读写位置。
1)tell()方法
tell()方法用于获取文件当前的读写位置,以操作文件abc.txt为例,tell()的用法如下:
python
with open('d:\\test\\abc.txt','r') as f:
#获取文件读写位置
print('首次读写的位置',f.tell())
#利用位置read()方法移动文件读写位置
print(f.read(3))
#再次获取文件读写位置
print('在次读写位置',f.tell())运行结果
python
首次读写的位置 0
thi
在次读写位置 32)seek()方法
Python提供了seek()方法,使用该方法可控制文件的读写位置,实现文件的随机读写。seek()方法的语法格式如下:
python
seek(offset, from)-
offset:表示偏移量,即读写位置需要移动的字节数。
-
from:用于指定文件的读写位置,该参数的取值为0、1、2。
- 0:表示文件开头
- 1:表示使用当前读写位置
- 2:表示文件末尾
seek()方法调用成功后会返回当前读写位置。
python
with open('d:\\test\\abc.txt','rb') as f:
#获取文件读写位置
print('首次读写的位置',f.tell())
#相对文件首部移动5字节
size = f.seek(3,0)
#输出当前文件读写位置
print(size)
print('所在位置:',f.tell())
size = f.seek(4,1)
print('所在位置:',f.tell())运行结果
python
首次读写的位置 0
3
所在位置: 3
所在位置: 7注意:在Python3中,若打开的是文本文件,那么seek()方法只允许相对于文件开头移动文件位置,若在参数from值为1、2的情况下对文本文件进行位移操作,将会产生错误。
python
with open('d:\\test\\abc.txt','r') as f:
print('首次读写的位置', f.tell())
size = f.seek(3,0)
print(size)
size = f.seek(3,1)
print(size)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\文件\文件写入.py", line 38, in <module>
size = f.seek(3,1)
io.UnsupportedOperation: can't do nonzero cur-relative seeks解决:若要相对当前读写位置或文件末尾进行位移操作,需以二进制形式打开文件。
python
with open('d:\\test\\abc.txt','rb') as f:
print('首次读写的位置', f.tell())
size = f.seek(3,0)
print(size)
size = f.seek(3,1)
print(size)运行结果
python
首次读写的位置 0
3
67.3 文件与目录管理
对于用户而言,文件和目录以不同的形式展现,但对计算机而言,目录是文件属性信息集合,它本质上也是一种文件。
os模块中定义了与文件操作相关的函数,利用这些函数可以实现删除文件、文件重命名、创建/删除目录、获取当前目录、更改默认目录与获取目录列表等操作。
1)删除文件-remove()函数
使用os模块的remove()函数可删除文件,该函数要求目标文件存在,语法如下:
python
remomve(文件名)调用remove()函数处理文件,指定的文件会被删除。
python
import os
os.remove('d:\\test\\demo.txt')
print('删除成功')运行结果
python
删除成功2)文件重命名-rename()函数
使用os模块中的rename()函数可以更改文件名,该函数要求目标文件已存在,语法如下:
python
rename(原文件名,新文件名)rename()函数的用法,移动位置
python
import os
os.rename('d:\\test\\demo02.txt','c:\\demo02.txt')运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\文件\文件目录管理.py", line 6, in <module>
os.rename('d:\\test\\demo02.txt','c:\\demo02.txt')
~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'd:\\test\\demo02.txt' -> 'c:\\demo02.txt'不能跨磁盘分区
python
data = []
with open('d:\\test\\abc.txt','r') as f:
data = f.readlines()
print(data)
with open('c:\\abc.txt','w') as f:
f.writelines(data)
print('拷贝完成')重命名
python
import os
os.rename('d:\\test\\demo02.txt','d:\\test\\test.txt')
3)获取当前目录-getcwd()函数
当前目录即是Python当前的工作路径,os模块中的getcwd()函数用于获取当前目录,调用该函数可获取当前工作目录的绝对路径。
python
import os
#获取
print(os.getcwd())
#切换
os.chdir("d:\\")
print(os.getcwd())运行结果
python
C:\Users\86189\PyCharmMiscProject\.venv\练习\文件
d:\4)创建/删除目录-mkdir()/rmdir()
os模块中的mkdir()函数用于创建目录,rmdir()函数用于删除目录,这两个函数的参数都是目录名称。
mkdir()函数用于在当前目录下创建目录,需要注意,待创建的目录不能与已有目录重名,否则将创建失败。
python
import os
os.mkdir('d:\\test\\target')
rmdir()用于删除目录。
python
os.rmdir('d:\\test\\target')
5)获取文件名列表-listdir()函数
实际使用中常常需要先获取指定目录下的所有文件,再对目标文件进行相应操作。os模块中提供了listdir()函数,使用该函数可方便快捷地获取指定目录下所有文件的文件名列表。
python
import os
file = os.listdir('d:\\test')
print(file)运行结果,输出格式为列表类型
python
['abc.txt', 'demo03.txt', 'test.txt']7.4 实训案例
7.4.1 信息安全策略-文件备份
当下是信息时代,信息在当今社会占据的地位不言而喻,信息安全更是当前人类重视的问题之一。人类考虑从传输和存储两方面保障信息的安全,备份是在存储工作中保障信息安全的有效方式。本案例要求编写程序,实现一个具有备份文件与文件夹功能的备份工具。
7.5 数据维度
从广义上看,维度是与事物"有联系"的概念的数量。根据"有联系"的概念的数量,事物可分为不同维度,例如与线有联系的概念为长度,因此线为一维事物;与长方形面积有联系的概念为长度和宽度,因此面积为二维事物;与长方体体积有联系的概念为长度,宽度和高度,因此体积为三维事物。
7.5.1 基于维度的数据分类
根据组织数据时与数据有联系的参数的数量,数据可分为一维数据、二维数据和多维数据。
1)一维数据
具有对等关系的一组线性数据
-
一维列表
-
一维元组
-
集合
2)二维数据
二维数据关联参数的数量为2
-
矩阵
-
二维数组
-
二维列表
-
二维元组
3)多维数据
利用键值对等简单的二元关系展示数据间的复杂结构
- 字典
7.5.2 一维数据和二维数据的存储与读写
程序中与数据相关的操作分为数据的存储与读写,下面我们就一起掌握如何存储与读写不同维度的数据。
1)数据存储
数据通常存储在文件中,为了方便后续的读写操作,数据通常需要按照约定的组织方式进行存储。
一维数据呈线性排列,一般用特殊字符分隔,例如:
-
使用空格分隔:成都 杭州 重庆 武汉 苏州 西安 天津
-
使用逗号分隔:成都,杭州,重庆,武汉,苏州,西安,天津
-
使用&分隔:成都&杭州&重庆&武汉&苏州&西安&天津
一维数据的存储需要注意以下几点:
-
同一文件或同组文件一般使用同一分隔符分隔。
-
分隔数据的分隔符不应出现在数据中。
-
分隔符为英文半角符号,一般不使用中文符号作为分隔符。
二维数据可视为多条一维数据的集合,当二维数据只有一个元素时,这个二维数据就是一维数据。
CSV(Commae-Separeted Values,逗号分隔值)是国际上通用的一二维数据存储格式。
CSV格式规范:
-
以纯文本形式存储表格数据
-
文件的每一行对应表格中的一条数据记录
-
每条记录由一个或多个字段组成
-
字段之间使用逗号(英文、半角)分隔
CSV也称字符分隔值,具体示例如下:
python
姓名,语文,数学,英语,理综
刘备,124,137,145,260
张飞,116,143,139,263
关羽,120,130,148,255
周瑜,115,145,131,240
诸葛亮,123,108,121,235
黄月英,132,100,112,210CSV广泛应用于不同体系结构下网络应用程序之间表格信息的交换中,它本身并无明确格式标准,具体标准一般由传输双方协议决定。
2)数据读取
Windows平台中CSV文件的后缀名为.csv,可通过Office Excel或记事本打开。
Python在程序中读取.csv文件后会以二维列表形式存储其中内容。
python
import chardet
file = 'd:\\test\\info.csv'
def get_encoding(file):
with open(file, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(file, 'r',encoding=get_encoding(file)) as f:
lines = []
for line in f:
line = line.replace('\n','')
lines.append(line.split(','))
print(lines)运行结果:打开文件score.csv后通过对文件对象进行迭代,在循环中逐条获取文件中的记录,根据分隔符","分隔记录,将记录存储到列表lines中,最后在终端打印列表lines。
python
[['姓名', '语文', '数学', '英语', '理综'], ['刘备', '124', '137', '145', '260'], ['张飞', '116', '143', '139', '263'], ['关羽', '120', '130', '148', '255'], ['周瑜', '115', '145', '131', '240'], ['诸葛亮', '123', '108', '121', '235'], ['黄月英', '132', '100', '112', '210']]3)数据写入
将一、二维数据写入文件中,即按照数据的组织形式,在文件中添加新的数据。
在保存学生成绩的文件score.csv中写入每名学生的总分,代码示例如下
python
import chardet
file = 'd:\\test\\info.csv'
def get_encoding(filepath):
#获取样例数据
with open(filepath, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(file, 'r',encoding=get_encoding(file)) as f:
#创建新文件
file_new = open('d:\\test\\count.csv', 'w+')
#数据列表
lines = list()
for line in f:
line = line.replace('\n','')
lines.append(line.split(','))
# print(lines)
lines[0].append('总共')
#跳过第一行标题
for i in range(len(lines)-1):
#索引从一开始
idex = i+1
#成绩总和
sum = 0
for j in range(len(lines[idex])):
if lines[idex][j].isnumeric():
#累加每个人的总成绩
sum += int(lines[idex][j])
#总成绩追加在每个人信息的后面
lines[idex].append(str(sum))
#写入数据
print(lines)
for line in lines:
file_new.write(','.join(line)+'\n')扩展: isnumeric() 方法用于检查字符串是否只包含数字字符。这个方法会返回一个布尔值,如果字符串中的所有字符都是数字,则返回 True ,否则返回 False 。
运行结果,使用Excel打开文件
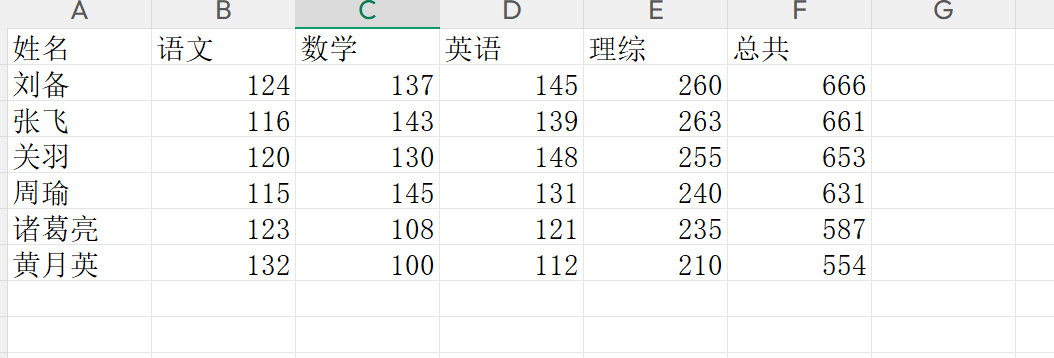
7.5.3 多维数据的格式化
为了直观地表示多维数据,也为了便于组织和操作,三维及以上的多维数据统一采用键值对的形式进行格式化。
网络平台上传递的数据大多是高维数据,JSON是网络中常见的高维数据格式。JSON格式的数据遵循以下语法规则:

-
数据存储在键值对(key:value)中,例如"姓名": "张飞"。
-
数据的字段由逗号分隔,例如"姓名": "张飞", "语文": "116"。
-
一个花括号保存一个JSON对象,例如{"姓名": "张飞", "语文": "116"}。
-
一个方括号保存一个数组,例如{"姓名": "张飞", "语文": "116"}。
python
"班级考试成绩":[
{"姓名": "王小天",
"语文": "124",
"数学": "127",
"英语": "145",
"理综": "259" };
{"姓名": "张大同",
"语文": "116",
"数学": "143",
"英语": "119",
"理综": "273" };
......
]以上数据是一个键值对,它的key为"班级考试成绩",之后跟着以冒号分隔的value。此value本身是一个数组,该数组中存储了多名学生的成绩,通过中括号组织,其中的元素通过分号分隔,分号作为数组元素的学生成绩的每项属性亦为键值对,每项属性通过逗号分隔。
除JSON外,网络平台也会使用XML(可扩展标记语言)、HTML等格式组织多维数据,XML和HTML格式通过标签组织数据。例如,将学生成绩以XML格式存储,示例如下
python
<班级考试成绩>
<姓名>王小天</姓名><语文>124</语文><数学>127<数学/><英语>145<英语/><理综>259<理综/>
<姓名>张大同</姓名><语文>116</语文><数学>143<数学/><英语>119<英语/><理综>273<理综/>
......
</班级考试成绩>对比JSON格式与XML、HTML格式可知,JSON格式组织的多维数据更为直观,且数据属性的key只需存储一次,在网络中进行数据交换时耗费的流量更少
JSON模块------json
利用json模块的dumps()函数和loads()函数可以实现Python对象和JSON数据之间的转换,这两个函数的具体功能如表所示。
| 函数 | 功能 |
|---|---|
| dumps() | 对Python对象进行转码,将其转化为JSON字符串 |
| loads() | 将JSON字符串解析为Python对象 |
Python对象与JSON数据转化时的类型对照表
| Python对象 | JSON数据 |
|---|---|
| dict | object |
| list,tuple | array |
| str,unicode | string |
| int,long,float | number |
| True | true |
| False | false |
| None | null |
1)dumps()函数
使用dumps()函数对Python对象进行转码。
python
import json
pyobj = [[1,2,3],10,3,14,'tom',{'java':98,'python':100},True,False,None]
jsonobj = json.dumps(pyobj)
print(jsonobj)
print(type(jsonobj))运行结果
python
[[1, 2, 3], 10, 3, 14, "tom", {"java": 98, "python": 100}, true, false, null]
<class 'str'>2)loads()函数
使用loads()函数将JSON数据转换为符合Python语法要求的数据类型。
python
import json
pyobj = [[1,2,3],10,3,14,'tom',{'java':98,'python':100},True,False,None]
jsonobj = json.dumps(pyobj)
print(jsonobj)
print(type(jsonobj))
#反序列化操作
new_jsonobj = json.loads(jsonobj)
print(new_jsonobj)运行结果
python
[[1, 2, 3], 10, 3, 14, "tom", {"java": 98, "python": 100}, true, false, null]
<class 'str'>
[[1, 2, 3], 10, 3, 14, 'tom', {'java': 98, 'python': 100}, True, False, None]7.6 本章小结
本章主要介绍了文件与数据格式化相关的知识,包括计算机中文件的定义、文件的基本操作、文件与目录管理、数据维度与数据格式化。通过本章的学习,能了解计算机中文件的意义、熟练地读取和管理文件,并掌握常见的数据组织形式。
第八章:面向对象
面向对象是程序开发领域的重要思想,这种思想模拟了人类认识客观世界的思维方式,将开发中遇到的事物皆看作对象。
8.1 面向对象概述
面向过程:
-
分析解决问题的步骤
-
使用函数实现每个步骤的功能
-
按步骤依次调用函数
面向对象:
-
分析问题,从中提炼出多个对象
-
将不同对象各自的特征和行为进行封装
-
通过控制对象的行为来解决问题。
面向对象编程与面向过程编程是两种不同的编程范式,它们在处理问题的方式上有显著的不同。下面我将通过一个日常生活中的例子 ------"制作一杯咖啡" 来说明这两种编程风格之间的区别。
python
面向过程方式:
假设我们要编写一段程序来描述如何在家里制作一杯简单的美式咖啡。使用面向过程的方法,我们会按照步骤
顺序执行一系列操作:
1)准备好所需的材料:水、咖啡粉。
2)将一定量的水倒入电热水壶中并加热至沸腾。
3)同时,在滤杯中放置一张滤纸,并预热杯子。
4)待水煮沸后稍冷却片刻,使温度降至约 90°C 左右。
5)用量勺取适量咖啡粉放入滤纸内。
6)慢慢地将热水倒在咖啡粉上进行冲泡。
7)等待所有水分过滤完毕,一杯美味的手冲咖啡就完成了!
在这个过程中,我们关注的是完成任务的一系列具体步骤。每个步骤都是独立的任务,按照特定的顺序执行以
达成最终目标。
---------------------------------------------------------------------------------
--------------------------------------------------------
面向对象方式:
如果采用面向对象的方法来看待同样的问题,则会有所不同。首先,我们将识别出几个关键的对象:
咖啡机
水
咖啡粉
杯子
然后为这些对象定义属性和方法。例如:
咖啡机:煮制咖啡的过程;添加原料。
水: 允许设置加热水到特定温度。
咖啡粉: 表示研磨程度。
杯子: 接收冲好的咖啡液。思考:如果想喝茶怎么办?
使用面向过程就需要把过程从头到尾给进行相关调整;使用面向对象只需要把咖啡粉换成茶叶即可。
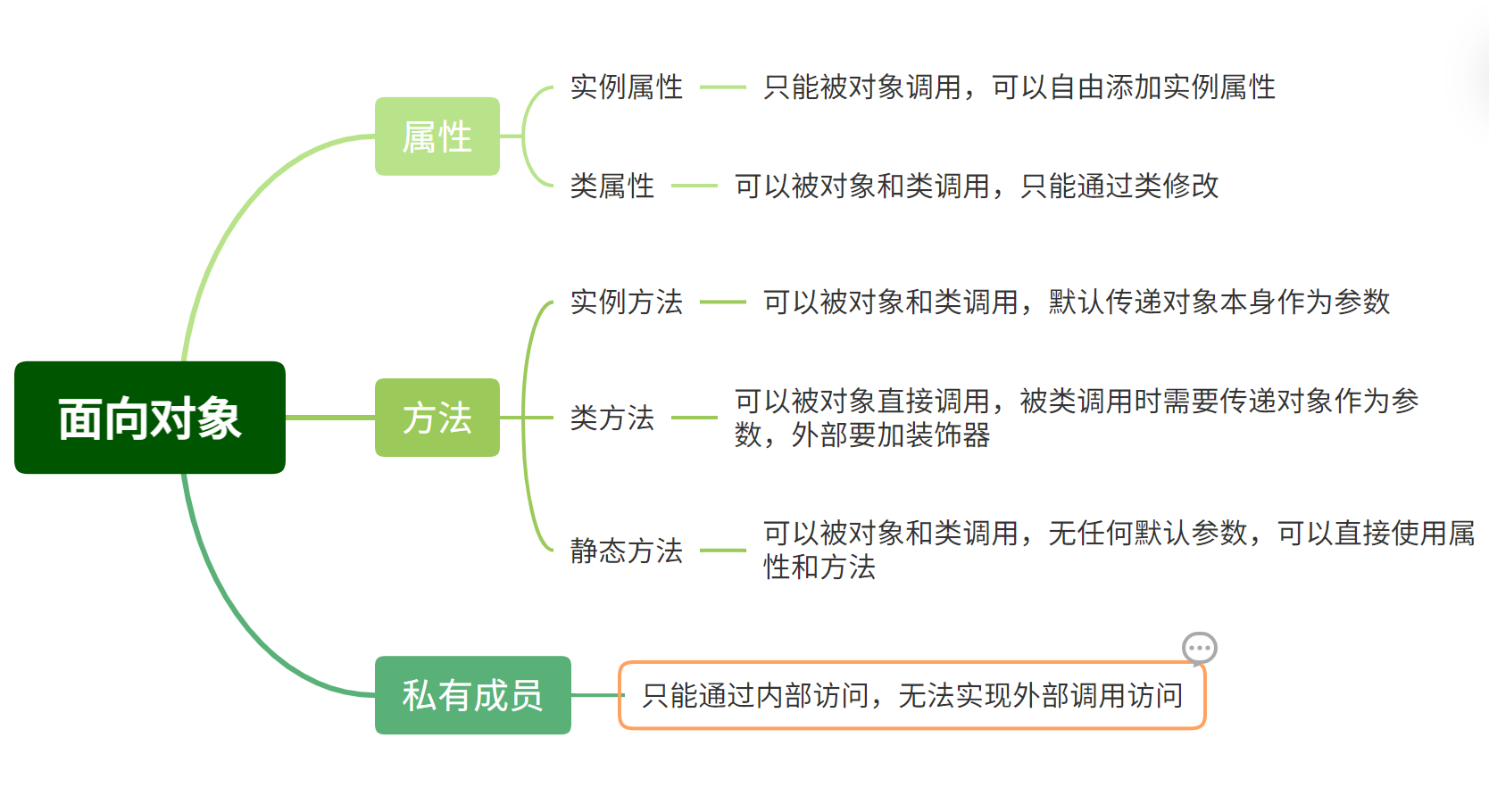
8.2 类的定义与使用
-
面向对象编程有两个非常重要的概念:类和对象。
-
对象映射现实中真实存在的事物,如一本书。
-
具有相同特征和行为的事物的集合统称为类。
-
对象是根据类创建的,一个类可以对应多个对象。
-
类是对象的抽象,对象是类的实例。
8.2.1 类的定义
类是由3部分组成的:
-
类的名称:大驼峰命名法,首字母一般大写,比如Person。
-
类的属性:用于描述事物的特征,比如姓名,性别,身高,体重等(静态描述)。
-
类的方法:用于描述事物的行为,比如吃饭,睡觉,健身,娱乐等(动态描述)。
语法如下:
python
class 类名:
属性名 = 属性值
def 方法名(self):
方法体示例:
python
class Car:
color = '红色'
def drive(self):
return '正在行驶'
car = Car()
print(f'一辆{car.color}的车', car.drive())运行结果
python
一辆红色的车 正在行驶8.2.2 对象的创建与使用
根据类创建对象的语法格式如下:
python
对象名 = 类名() #实例
car = Car()使用对象的本质是访问对象成员:
python
对象名.属性名
car.wheels
对象名.方法名()
car.drive()示例:
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
car = Car()
# 通过对象car修改类属性wheels(类修改影响所有值)
car.color = '蓝'
print('类属性:',Car.color)
print('对象属性',car.color)运行结果
python
类属性: 红色
对象属性 蓝8.3 类的成员
8.3.1 属性
属性按声明的方式可以分为两类:类属性和实例属性。
1)类属性
-
声明在类内部、方法外部的属性。
-
可以通过类或对象进行访问,但只能通过类进行修改。
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
# 创建对象car
car = Car()
car.drive()
# 通过对象car访问类属性
print('对象调用:',car.wheels)
car.name = '问界'
print(car.name)
print(car.drive())
print(Car.drive(car))运行结果
python
对象调用: 4
问界
正在行驶
正在行驶
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
car = Car()
car.drive()
print('类调用:',Car.wheels)运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\面向对象\基础.py", line 21, in <module>
print('类调用:',Car.wheels)
^^^^^^^^^^
AttributeError: type object 'Car' has no attribute 'wheels'2)实例属性
实例属性是在方法内部声明的属性。
Python支持动态添加实例属性。
(1)访问实例属性------只能通过对象访问
python
class Car:
def drive(self):
# 添加实例属性
self.wheels = 4
# 创建对象car
car = Car()
car.drive()
# 通过对象car访问实例属性
print(car.wheels)
# 通过类Car访问实例属性(报错提示:无法访问)
print(Car.wheels) (2)修改实例属性------通过对象修改
python
class Car:
def drive(self):
self.wheels = 4
car = Car()
car.drive()
# 修改实例属性
car.wheels = 3
# 通过对象car访问实例属性
print(car.wheels) (3)动态添加实例属性------类外部使用对象动态添加实例属性
python
class Car:
def drive(self):
self.wheels = 4
car = Car()
car.drive()
car.wheels = 3
print(car.wheels)
# 动态地添加实例属性
car.color = "红色"
print(car.color)8.3.2 方法
Python中的方法按定义方式和用途可以分为三类:实例方法、类方法和静态方法。
1)实例方法
-
形似函数,但它定义在类内部。
-
以self为第一个形参,self参数代表对象本身。
-
只能通过对象调用。
python
class Car:
def drive(self): # 实例方法
print("我是实例方法")
car = Car()
car.drive() # 通过对象调用实例方法
# Car.drive() # 通过类调用实例方法(TypeError报错)2)类方法
-
类方法是定义在类内部
-
使用装饰器@classmethod修饰的方法
-
第一个参数为cls,代表类本身
-
可以通过类和对象调用
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
@classmethod
def stop(cls):
return '刹车,停止'
print(car.stop())
print(Car.stop())运行结果
python
刹车,停止
刹车,停止类方法中可以使用cls访问和修改类属性的值
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
@classmethod
def stop(cls):
cls.wheels = 4
return '刹车,停止
car = car()
car.stop()3)静态方法
-
静态方法是定义在类内部
-
使用装饰器@staticmethod修饰的方法
-
没有任何默认参数
静态方法可以通过类和对象调用,独立于类所存在
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
@staticmethod
def test():
print('静态方法')
car = Car()
car.test()
Car.test()运行结果
python
静态方法
静态方法静态方法内部不能直接访问属性或方法,但可以使用类名访问类属性或调用类方法
python
class Car:
color = '红色'
def drive(self):
self.wheels = 4
return '正在行驶'
@classmethod
def stop(cls):
cls.wheels = 4
return '刹车,停止'
@staticmethod
def test():
print(f'静态方法,车辆是{Car.color}')
car = Car()
car.test()
Car.test()运行结果
python
静态方法,车辆是红色
静态方法,车辆是红色8.3.3 私有成员
类的成员默认是公有成员,可以在类的外部通过类或对象随意地访问,这样显然不够安全。
为了保证类中数据的安全,Python支持将公有成员改为私有成员,在一定程度上限制在类的外部对类成员的访问。
Python通过在类成员的名称前面添加双下画线(__)的方式来表示私有成员,语法格式如下:
-
__属性名
-
__方法名
python
class Car:
__color = '红色'
def __drive(self):
self.wheels = 4
return '正在行驶'
@classmethod
def stop(cls):
return '刹车,停止'
@staticmethod
def test():
print(f'静态方法,车辆是{Car.__color}')
car = Car()
# print(car.color)
# car.drive()
car.test()运行结果
python
静态方法,车辆是红色#的两条命令结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\面向对象\基础.py", line 65, in <module>
print(car.color)
^^^^^^^^^
AttributeError: 'Car' object has no attribute 'color'
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\面向对象\基础.py", line 66, in <module>
car.drive()
^^^^^^^^^
AttributeError: 'Car' object has no attribute 'drive'8.4 特殊方法
类中还包括两个特殊的方法:构造方法和析构方法,这两个方法都是系统内置方法。
8.4.1 构造方法
构造方法指的是init()方法。
创建对象时系统自动调用,从而实现对象的初始化。
每个类默认都有一个init ()方法,可以在类中显式定义init()方法。
init()方法可以分为无参构造方法和有参构造方法。
-
当使用无参构造方法创建对象时,所有对象的属性都有相同的初始值。
pythonclass Car: name = 'BMW' #自动调用 def __init__(self): print('车辆制造完成') self.color = 'red' def drive(self): self.wheels = 4 print('车辆行驶') car = Car() print(f'今天购买一辆{car.name},颜色是{car.color}色') car.drive() print(car.wheels运行结果
python车辆制造完成 今天购买一辆BMW,颜色是red色 车辆行驶 4 -
当使用有参构造方法创建对象时,对象的属性可以有不同的初始值。
pythonclass Car: name = 'BMW' #自动调用 def __init__(self,my_color): print('车辆制造完成') self.color = my_color def drive(self): self.wheels = 4 print('车辆行驶') car = Car('蓝') print(f'今天购买一辆{car.name},颜色是{car.color}色') car.drive() print(car.wheels)运行结果
python车辆制造完成 今天购买一辆BMW,颜色是蓝色 车辆行驶 4两个对象
pythonclass Car: name = 'BMW' #自动调用,构造方法 def __init__(self,my_color): print('车辆制造完成') self.color = my_color def drive(self): self.wheels = 4 print('车辆行驶') car = Car('蓝') print(f'今天购买一辆{car.name},颜色是{car.color}色') car2 = Car('红') print(f'今天购买一辆{car2.name},颜色是{car2.color}色')运行结果
python车辆制造完成 今天购买一辆BMW,颜色是蓝色 车辆制造完成 今天购买一辆BMW,颜色是红色
8.4.2 析构方法
析构方法(即del()方法)是销毁对象时系统自动调用的方法。
每个类默认都有一个del()方法,可以显式定义析构方法。
python
class Car:
name = 'BMW'
#自动调用
def __init__(self,my_color):
self.color = my_color
print(f'{self.color}车辆制造完成')
def drive(self):
self.wheels = 4
print('车辆行驶')
def __del__(self):
print(f'{self.color}色的车子被销毁')
car = Car('蓝')
print(f'今天购买一辆{car.name},颜色是{car.color}色')
del car
car2 = Car('红')
print(f'今天购买一辆{car2.name},颜色是{car2.color}色')运行结果
python
蓝车辆制造完成
今天购买一辆BMW,颜色是蓝色
蓝色的车子被销毁
红车辆制造完成
今天购买一辆BMW,颜色是红色
红色的车子被销毁8.6 封装
封装是面向对象的重要特性之一,它的基本思想是对外隐藏类的细节,提供用于访问类成员的公开接口。
如此,类的外部无需知道类的实现细节,只需要使用公开接口便可访问类的内容,这在一定程度上保证了类内数据的安全。
为了契合封装思想,我们在定义类时需要满足以下两点要求。
1.将类属性声明为私有属性。
2.添加两类供外界调用的公有方法,分别用于设置或获取私有属性的值。
python
class Person:
def __init__(self,name):
self.name = name
self.__age = 1
def set_age(self,new_age):
if 0<new_age<= 120:
self.__age = new_age
def get_age(self):
return self.__age
dyx = Person('Dyx')
dyx.set_age(20)
print(f'她的名字是{dyx.name},她的年龄{dyx.get_age()}')运行结果
python
她的名字是Dyx,她的年龄208.7 继承
继承是面向对象的重要特性之一,它主要用于描述类与类之间的关系,在不改变原有类的基础上扩展原有类的功能。
若类与类之间具有继承关系,被继承的类称为父类或基类 ,继承其他类的类称为子类或派生类 ,子类会自动拥有父类的公有成员。
8.7.1 单继承
单继承即子类只继承一个父类。现实生活中,波斯猫、折耳猫、短毛猫都属于猫类,它们之间存在的继承关系即为单继承。
Python中单继承的语法格式如下所示:
python
class 子类名(父类名):-
子类继承父类的同时会自动拥有父类的公有成员。
-
自定义类默认继承基类object。
python
class Cat(object):
def __init__(self,color):
self.color = color
def play(self):
print('喜欢玩毛线球')
class Scofttishfold(Cat):
pass
fold = Scofttishfold('白')
print(f'一只{fold.color}色的猫')
fold.play()运行结果
python
一只白色的猫
喜欢玩毛线球注意:子类不会拥有父类的私有成员,也不能访问父类的私有成员。
python
class Cat(object):
def __init__(self,color):
# 增加私有属性
self.color = color
def play(self):
print('喜欢玩毛线球')
def __test(self):
print('test')
# 定义继承Cat的ScottishFold类
class Scofttishfold(Cat):
pass
fold = Scofttishfold('白')
print(f'一只{fold.color}色的猫')
fold.play()
fold.__test()运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\面向对象\继承.py", line 13, in <module>
fold.__test()
^^^^^^^^^^^
AttributeError: 'Scofttishfold' object has no attribute '__test'8.7.2 多继承
程序中的一个类也可以继承多个类,如此子类具有多个父类,也自动拥有所有父类的公有成员。
Python中多继承的语法格式如下所示:
python
class 子类名(父类名1, 父类名2, ...):创建房车代码示例:
python
# 定义一个表示房屋的类
class House():
def live(self):
print('居住')
# 定义一个表示汽车的类
class Car():
def drive(self):
print('行驶')
# 定义一个表示房车的类
class Truck(House, Car):
pass
tc = Truck()
# 子类对象调用父类House的方法
tc.drive()
# 子类对象调用父类Car的方法
tc.live()运行结果
python
行驶
居住提问:如果House类和Car类中有一个同名的方法,那么子类会调用哪个父类的同名方法呢?
如果子类继承的多个父类是平行关系的类,那么子类先继承哪个类,便会先调用哪个类的方法。
python
class House():
def live(self):
print('居住')
def test(self):
print('房子')
class Car():
def drive(self):
print('行驶')
def test(self):
print('车子')
#相同方法,父类谁在前,用谁
class Truck(House, Car):
pass
tc = Truck()
tc.test()运行结果
python
房子8.7.3 重写
子类会原封不动地继承父类的方法,但子类有时需要按照自己的需求对继承来的方法进行调整,也就是在子类中重写从父类继承来的方法。
在子类中定义与父类方法同名的方法,在方法中按照子类需求重新编写功能代码即可。
python
# 定义一个表示人的类
class Person:
def say_hello(self):
print('hello')
# 定义一个表示中国人的类
class Student(Person):
def say_hello(self):
print('你好')
china = Student()
china.say_hello()运行结果
python
你好子类重写了父类的方法之后,无法直接访问父类的同名方法,但可以使用super()函数间接调用父类中被重写的方法。
python
class Person:
def say_hello(self):
print('hello')
class Student(Person):
def say_hello(self):
#调用父类,对象.调用函数
super().say_hello()
print('你好')
china = Student()
china.say_hello()运行结果
python
你好8.8 多态
多态是面向对象的重要特性之一,它的直接表现即让不同类的同一功能可以通过同一个接口调用,表现出不同的行为。
python
class Dog:
def shout(self):
print('汪')
class Cat:
def shout(self):
print('喵')
def main(a):
a.shout()
dog = Dog()
cat = Cat()
dog.shout()
cat.shout()运行结果
python
汪
喵8.10 实例
python
class Mouse:
def doing(self):
print('拖拽')
class Keybroad:
def doing(self):
print('打字')
class Computer:
def usb1(self,obj):
obj.doing()
def usb2(self,obj):
obj.doing()
computer = Computer()
mouse = Mouse()
keybroad = Keybroad()
computer.usb1(mouse)
computer.usb2(keybroad)运行结果
python
拖拽
打字8.12 本章小结
本章主要讲解了面向对象的相关知识,包括面向对象概述、类的定义和使用、类的成员、特殊方法、封装、继承、多态、运算符重载,并结合众多实训案例演示了面向对象的编程技巧。通过本章的学习,希望能理解面向对象的思想与特性,掌握面向对象的编程技巧,为以后的开发奠定扎实的面向对象编程基础。
第九章 异常
程序开发或运行时可能出现异常,开发人员和运维人员需要辨别程序的异常,明确这些异常是源于程序本身的设计问题,还是由外界环境的变化引起,以便有针对性地处理异常。
程序运行出现异常时,若程序中没有设置异常处理功能,解释器会采用系统的默认方式处理异常,即返回异常信息、终止程序。
9.1 异常概述
异常信息中通常包含异常代码所在行号、异常的类型和异常的描述信息。
9.1.1 异常示例
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\面向对象\多态.py", line 32, in <module>
computer.usb1(mouse)
^^^^^
NameError: name 'mouse' is not defined. Did you mean: 'Mouse'?9.1.2 异常类型
Python程序运行出错时产生的每个异常类型都对应一个类,程序运行时出现的异常大多继承自Exception类,Exception类又继承了异常类的基类BaseException。
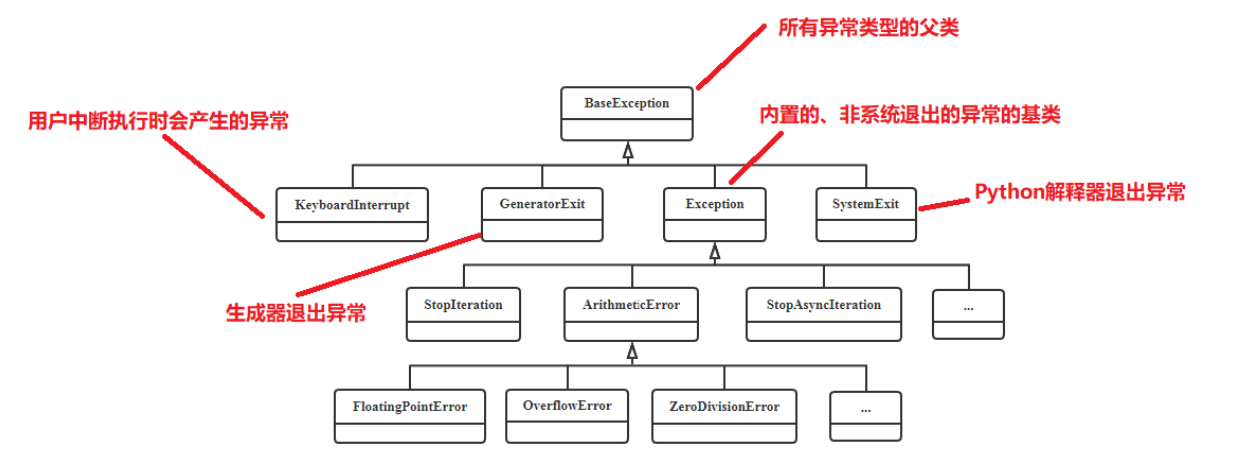
1)NameError
- NameError是程序中使用了未定义的变量时会引发的异常。
- 例如,访问一个未声明过的变量test,代码如下:
python
print(test)
2)IndexError
-
IndexError是程序越界访问时会引发的异常。
-
例如,使用索引0访问空列表num_list,代码如下:
python
num_list = []
num_list[0]
3) AttributeError
AttributeError是使用对象访问不存在的属性时引发的异常。
例如,Car类中动态地添加了两个属性color和brand,使用Car类的对象依次访问color、brand属性及不存在的name属性,代码如下:
python
class Car(object):
pass
car = Car()
car.color = '黑色'
car.brand = '五菱'
car.color
car.brand
car.name运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 57, in <module>
car.name
AttributeError: 'Car' object has no attribute 'name'4)FileNotFoundError
-
FileNotFoundError是未找到指定文件或目录时引发的异常。
-
例如,打开一个本地不存在的文件,代码如下:
python
file = open('test.txt')运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 58, in <module>
file = open('test.txt')
FileNotFoundError: [Errno 2] No such file or directory: 'test.txt'9.2 异常捕获语句
Python既可以直接通过try-except语句实现简单的异常捕获与处理的功能,也可以将try-except语句与else或finally子句组合实现更强大的异常捕获与处理的功能。
9.2.1 try-except语句捕获异常
python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋error
捕获异常后的处理代码try-except语句可以捕获与处理程序的单个、多个或全部异常。
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#单个异常类型
except ZeroDivisionError:
print('出错了')
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#定义error变量输出异常内容
except ZeroDivisionErroras e:
print('出错了',e)如果输入的是字母进行异常捕捉
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#多异常类型
except (ZeroDivisionError,ValueError)as e:
print('出错了',e)使用父类捕捉异常
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
except Exception as e:
print('出错了',e)9.2.2 异常结构中的else子句
else子句可以与try-except语句组合成try-except-else结构,若try监控的代码没有异常,程序会执行else子句后的代码。
python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
else:
未捕获异常后的处理代码如果除法过程没有异常则输出结果
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
result = number1/number2
except Exception as e:
print('出错了',e)
else:
print('结果:',result)9.2.3 异常结构中的finally子句
finally子句可以和try-except一起使用,语法格式如下:
python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
finally:
一定执行的代码-
无论try子句监控的代码是否产生异常,finally子句都会被执行。
-
finally子句多用于预设资源的清理操作,如关闭文件、关闭网络连接。
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
result = number1/number2
except Exception as e:
print('出错了',e)
else:
print('结果:',result)
#无论是否异常,都会执行
finally:
print('程序执行结束!')9.3 抛出异常
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
9.3.1 raise语句抛出异常
使用raise语句可以显式地抛出异常, raise语句的语法格式如下:
python
# 格式1:使用异常类名引发指定的异常
raise 异常类
# 格式2:使用异常类的对象引发指定的异常
raise 异常类对象
# 格式3: 使用刚出现过的异常重新引发异常
raise 1)异常类
python
raise IndexError运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 21, in <module>
raise IndexError
IndexError2)异常对象
python
raise ZeroDivisionError('索引超出')运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 23, in <module>
raise ZeroDivisionError('索引超出')
ZeroDivisionError: 索引超出3)重新引发异常
python
try:
print(5/0)
except ZeroDivisionError as e:
print(e)
raise运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 26, in <module>
print(5/0)
~^~
ZeroDivisionError: division by zero
division by zero4)异常引发异常
如果需要在异常中抛出另外一个异常,可以使用raise-from语句实现。
python
try:
print(5/0)
except Exception as e:
raise IndexError('下标越界') from e运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 32, in <module>
print(5/0)
~^~
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 34, in <module>
raise IndexError('下标越界') from e
IndexError: 下标越界9.3.2 assert语句抛出异常
python
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
assert num2 != 0,'除数不能为0' #assert语句判定num2不等于0
result = num1/num2
print(num1,'/',num2,'=',result)运行结果
python
请输入被除数:10
请输入除数:0
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 38, in <module>
assert num2 != 0,'除数不能为0' #assert语句判定num2不等于0
^^^^^^^^^
AssertionError: 除数不能为09.3.3 异常传递
异常(exceptions)是通过栈(stack)传递的。当函数中发生异常,该异常会被抛出(raised),然后由最内层的函数向外传递,直到被捕获(caught)或者导致程序终止。
python
def inner():
print('inside')
raise ValueError('An error occurred')
def outer():
print('outer')
inner()
try:
outer()
except ValueError as e:
print(e)运行结果
python
outer
inside
An error occurred9.4 自定义异常
有时我们需要自定义异常类,以满足当前程序的需求。自定义异常的方法比较简单,只需要创建一个继承Exception类或Exception子类的类(类名一般以"Error"为结尾)即可。
python
class ShortPwd(Exception):
def __init__(self, length,atleast):
self.length = length
self.atleast = atleast
try:
text = input('请输入密码:')
if len(text) < 3:
raise ShortPwd(len(text),3)
except ShortPwd as e:
print(f'你输入的密码长度:{e.length},密码长度至少{e.atleast}位')运行结果
python
请输入密码:123
python
请输入密码:12
你输入的密码长度:2,密码长度至少3位9.5 本章小结
本章主要讲解了Python异常的相关知识,包括异常概述、异常捕获语句、抛出异常和自定义异常,同时结合实训案例演示了异常的用法。通过本章的学习,希望大家掌握如何处理异常。
ct.venv\练习\异常\基础.py", line 58, in
file = open('test.txt')
FileNotFoundError: Errno 2 No such file or directory: 'test.txt'
### 9.2 异常捕获语句
Python既可以直接通过<font color=red>**try-except**</font>语句实现简单的异常捕获与处理的功能,也可以将try-except语句与<font color=red>**else**</font>或<font color=red>**finally**</font>子句组合实现更强大的异常捕获与处理的功能。
#### 9.2.1 try-except语句捕获异常
```python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋error
捕获异常后的处理代码try-except语句可以捕获与处理程序的单个、多个或全部异常。
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#单个异常类型
except ZeroDivisionError:
print('出错了')
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#定义error变量输出异常内容
except ZeroDivisionErroras e:
print('出错了',e)如果输入的是字母进行异常捕捉
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
#多异常类型
except (ZeroDivisionError,ValueError)as e:
print('出错了',e)使用父类捕捉异常
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
print(number1/number2)
except Exception as e:
print('出错了',e)9.2.2 异常结构中的else子句
else子句可以与try-except语句组合成try-except-else结构,若try监控的代码没有异常,程序会执行else子句后的代码。
python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
else:
未捕获异常后的处理代码如果除法过程没有异常则输出结果
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
result = number1/number2
except Exception as e:
print('出错了',e)
else:
print('结果:',result)9.2.3 异常结构中的finally子句
finally子句可以和try-except一起使用,语法格式如下:
python
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
finally:
一定执行的代码-
无论try子句监控的代码是否产生异常,finally子句都会被执行。
-
finally子句多用于预设资源的清理操作,如关闭文件、关闭网络连接。
python
try:
number1 = int(input("Enter a number: "))
number2 = int(input("Enter another number: "))
result = number1/number2
except Exception as e:
print('出错了',e)
else:
print('结果:',result)
#无论是否异常,都会执行
finally:
print('程序执行结束!')9.3 抛出异常
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
9.3.1 raise语句抛出异常
使用raise语句可以显式地抛出异常, raise语句的语法格式如下:
python
# 格式1:使用异常类名引发指定的异常
raise 异常类
# 格式2:使用异常类的对象引发指定的异常
raise 异常类对象
# 格式3: 使用刚出现过的异常重新引发异常
raise 1)异常类
python
raise IndexError运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 21, in <module>
raise IndexError
IndexError2)异常对象
python
raise ZeroDivisionError('索引超出')运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 23, in <module>
raise ZeroDivisionError('索引超出')
ZeroDivisionError: 索引超出3)重新引发异常
python
try:
print(5/0)
except ZeroDivisionError as e:
print(e)
raise运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 26, in <module>
print(5/0)
~^~
ZeroDivisionError: division by zero
division by zero4)异常引发异常
如果需要在异常中抛出另外一个异常,可以使用raise-from语句实现。
python
try:
print(5/0)
except Exception as e:
raise IndexError('下标越界') from e运行结果
python
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 32, in <module>
print(5/0)
~^~
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 34, in <module>
raise IndexError('下标越界') from e
IndexError: 下标越界9.3.2 assert语句抛出异常
python
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
assert num2 != 0,'除数不能为0' #assert语句判定num2不等于0
result = num1/num2
print(num1,'/',num2,'=',result)运行结果
python
请输入被除数:10
请输入除数:0
Traceback (most recent call last):
File "C:\Users\86189\PyCharmMiscProject\.venv\练习\异常\基础.py", line 38, in <module>
assert num2 != 0,'除数不能为0' #assert语句判定num2不等于0
^^^^^^^^^
AssertionError: 除数不能为09.3.3 异常传递
异常(exceptions)是通过栈(stack)传递的。当函数中发生异常,该异常会被抛出(raised),然后由最内层的函数向外传递,直到被捕获(caught)或者导致程序终止。
python
def inner():
print('inside')
raise ValueError('An error occurred')
def outer():
print('outer')
inner()
try:
outer()
except ValueError as e:
print(e)运行结果
python
outer
inside
An error occurred9.4 自定义异常
有时我们需要自定义异常类,以满足当前程序的需求。自定义异常的方法比较简单,只需要创建一个继承Exception类或Exception子类的类(类名一般以"Error"为结尾)即可。
python
class ShortPwd(Exception):
def __init__(self, length,atleast):
self.length = length
self.atleast = atleast
try:
text = input('请输入密码:')
if len(text) < 3:
raise ShortPwd(len(text),3)
except ShortPwd as e:
print(f'你输入的密码长度:{e.length},密码长度至少{e.atleast}位')运行结果
python
请输入密码:123
python
请输入密码:12
你输入的密码长度:2,密码长度至少3位9.5 本章小结
本章主要讲解了Python异常的相关知识,包括异常概述、异常捕获语句、抛出异常和自定义异常,同时结合实训案例演示了异常的用法。通过本章的学习,希望大家掌握如何处理异常。