逻辑回归简介
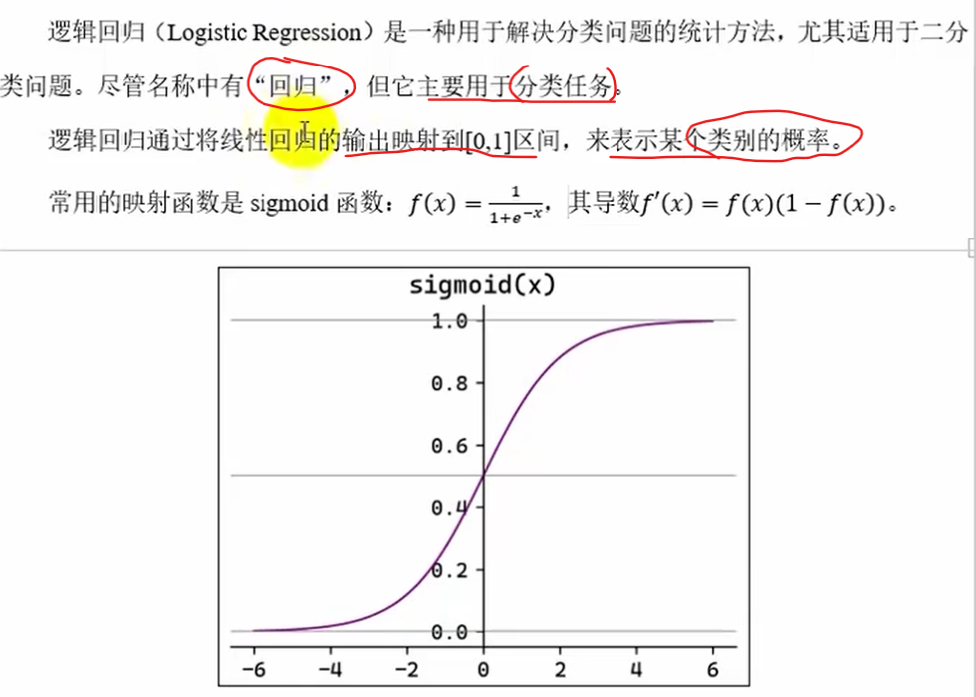
什么是逻辑回归

应用场景

损失函数


最大似然估计MLE:其核心思想是在给定观测数据的前提下,寻找一组参数值,使得这组参数下观测数据出现的概率(即似然函数)最大
式子默认y=1的概率为正概率
损失函数梯度


api使用
LogisticRegression参数说明

from sklearn.linear_model import LogisticRegression
model=LogisticRegression(
solver='sag',
multi_class='multinomial',
max_iter=1000,
class_weight='balanced',
random_state=42,
penalty='l1',
C=1.0 # 正则化系数的倒数
)心脏病预测案例

import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.compose import ColumnTransformer # 引入组合的列转换器
from sklearn.linear_model import LogisticRegression
# 1.加载数据集
dataset=pd.read_csv('../data/heart_disease.csv')
dataset.dropna(inplace=True)
# 2.数据集划分
X=dataset.drop(columns='是否患有心脏病',axis=1)
Y=dataset["是否患有心脏病"]
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
print(x_train.shape,y_train.shape)
# 3.特征工程
# 数值型特征
numerical_features=["年龄","静息血压","胆固醇","最大心率",'运动后的ST下降',"主血管数量"]
# 类别型特征
categorical_features=["胸痛类型","静息心电图结果","峰值ST段的斜率","地中海贫血"]
# 二元特征
binary_features=["性别","空腹血糖","运动性心绞痛"]
# 创建一个列转换器
'''
ColumnTransformer()类中参数是列转换器列表transformers
列表中存放的是三元组(转换的类型,转换方式,要转换的数据列表)
OneHotEncoder()中drop="first"将独热编码的第一列砍掉
转换方式是字符串的话表示不做处理
ColumnTransformer类自带.fit_transform方法
'''
columnTransformer=ColumnTransformer(
transformers=[
('num',StandardScaler(),numerical_features),
('cat',OneHotEncoder(drop="first"),categorical_features),
('bin','passthrough',binary_features)
]
)
# 特征转换
x_train=columnTransformer.fit_transform(x_train)
x_test=columnTransformer.transform(x_test)
# 4.模型定义和训练
model=LogisticRegression()
model.fit(x_train,y_train)
# 5.计算得分,评估模型
print(model.score(x_test,y_test))运行结果:
多分类任务
一对多ovr

# OVR
# 1.直接创建LogisticsRegression模型
model_ovr1=LogisticRegression(multi_class='ovr')
from sklearn.multiclass import OneVsRestClassifier
# 2.创建OneVsRegression模型
model_ovr2=OneVsRestClassifier(LogisticRegression())Softmax回归(多项逻辑回归)

# Softmax逻辑回归
model_softmax=LogisticRegression(multi_class='multinomial') # 不传也行案例:手写数字识别
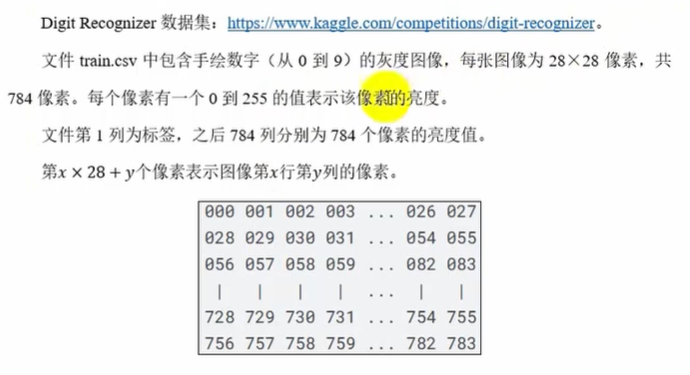
二维图片按照行展开成一维向量了
第一列为标签(0~9类),然后的784列为特征
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, scale
from sklearn.linear_model import LogisticRegression
# 1.加载数据集
dataset=pd.read_csv('../data/train.csv')
# # 测试图像
# digit=dataset.iloc[10,1:].values # 取第10行的第1到末尾列的数据,.values是转化成ndarray
# plt.imshow(digit.reshape(28,28),cmap='gray')# color-map颜色映射:gray灰度图像
# plt.show()
# 2.划分数据集
X=dataset.drop(columns='label',axis=1)
Y=dataset['label']
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
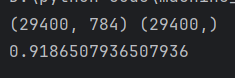
print(x_train.shape,y_train.shape)
# 3.特征工程:归一化
scaler=MinMaxScaler()
x_train=scaler.fit_transform(x_train)
x_test=scaler.transform(x_test)
# 4.定义模型和训练
model=LogisticRegression(max_iter=500) # Softmax多分类
model.fit(x_train,y_train)
# 5.模型评估
score=model.score(x_test,y_test)
print(score)
# 6.测试(预测某个新图像表示的数字)
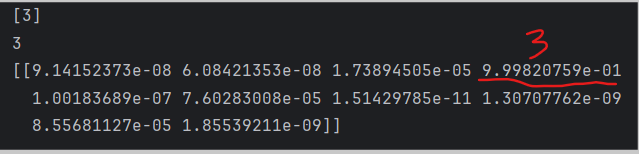
digit=x_test[123,:].reshape(1,-1)
print(model.predict(digit)) # 第123行预测值
print(y_test.iloc[123]) # 第123行的真实值
print(model.predict_proba(digit)) # 打印这个图像各个类的预测概率
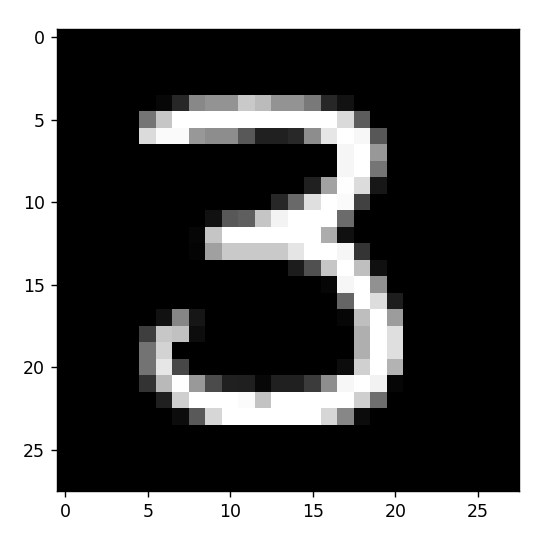
# 画出图像
plt.imshow(digit.reshape(28,28),cmap='gray')
plt.show()运行结果: