目录
[二、总体架构:双路召回 + 融合重排 + RAG 生成 + 闭环沉淀](#二、总体架构:双路召回 + 融合重排 + RAG 生成 + 闭环沉淀)
[三. 数据层:切片策略与统一元数据模型(决定上限)](#三. 数据层:切片策略与统一元数据模型(决定上限))
[3.1 文档(片段)类型](#3.1 文档(片段)类型)
[3.2 统一元数据(metadata)建议](#3.2 统一元数据(metadata)建议)
[3.3 日志去噪与规范化(对 BM25/向量都重要)](#3.3 日志去噪与规范化(对 BM25/向量都重要))
[4.1 BM25(Elasticsearch/OpenSearch)------词法精准召回](#4.1 BM25(Elasticsearch/OpenSearch)——词法精准召回)
[4.1.1 Mapping 与 analyzer 实战建议](#4.1.1 Mapping 与 analyzer 实战建议)
[4.1.2 Query 模板(带字段权重与过滤)](#4.1.2 Query 模板(带字段权重与过滤))
[4.2 向量检索(Milvus/pgvector/OpenSearch kNN)------语义召回](#4.2 向量检索(Milvus/pgvector/OpenSearch kNN)——语义召回)
[4.2.1 向量化内容构造(不要直接喂一坨原始日志)](#4.2.1 向量化内容构造(不要直接喂一坨原始日志))
[4.2.2 Metadata 过滤](#4.2.2 Metadata 过滤)
[五、 双路融合:RRF(Reciprocal Rank Fusion)](#五、 双路融合:RRF(Reciprocal Rank Fusion))
[6.1 轻量规则重排(最易落地)](#6.1 轻量规则重排(最易落地))
[6.2 Reranker(可选)](#6.2 Reranker(可选))
[七、RAG 诊断:从"检索结果"到"可执行建议"](#七、RAG 诊断:从“检索结果”到“可执行建议”)
[7.1 证据组织](#7.1 证据组织)
[7.2 输出格式(建议固定 JSON)](#7.2 输出格式(建议固定 JSON))
[8.1 新报错事件化与指纹](#8.1 新报错事件化与指纹)
[8.2 弱命中/无命中时的检索降级策略](#8.2 弱命中/无命中时的检索降级策略)
[8.3 动态现场取证](#8.3 动态现场取证)
[8.4 生成"可验证假设",推动人工确认](#8.4 生成“可验证假设”,推动人工确认)
[8.4 确认后沉淀(最关键)](#8.4 确认后沉淀(最关键))
[十、实战演练:以 ResponseValidationError 为例](#十、实战演练:以 ResponseValidationError 为例)
[9.1 场景重现](#9.1 场景重现)
[9.2 执行流程](#9.2 执行流程)
一、背景与挑战
云计算场景通常包含计算(ECS)、网络(SLB/VPC)、存储(OSS)、中间件(Tengine/MySQL)及 PaaS 平台等数成千上万个微服务。当故障发生时,运维人员面临以下核心挑战:
- 日志异构性强:不同组件日志格式差异巨大,缺乏统一 Schema;
- 新错误高频出现:版本迭代快,超50% 的报错为首次出现;
- 根因定位依赖专家经验:传统关键词搜索无法理解"端口占用"与 "Address already in use" 的语义等价性;
- 需生成可操作建议:仅返回相似日志不够,必须输出排查命令与解决方案。
单一检索技术难以兼顾精确匹配 与语义泛化 。为此设计了一套 "BM25 + 向量检索"双路召回 + LLM 推理 的混合智能诊断架构。
二、总体架构:双路召回 + 融合重排 + RAG 生成 + 闭环沉淀
一条"报错"进入系统后,走如下链路:
- 解析与事件化:从原始日志提取结构化特征
- 双路召回 :
- BM25:强 token 精准召回
- Vector:语义相似召回
- 融合(RRF):合并两路 TopK,得到候选 TopN
- 重排(可选):规则加权或 reranker 精排
- RAG 诊断生成:基于证据生成可验证假设、排查步骤与修复建议
- 闭环入库:人工确认根因后沉淀为知识条目,增量写入两套索引

三. 数据层:切片策略与统一元数据模型(决定上限)
双路召回是否好用,关键在"文档(片段)怎么定义"。
3.1 文档(片段)类型
- 日志片段:异常栈 + 前后 N 行,或同 TraceID/RequestID 时间窗内的上下游日志汇总
- 告警事件:告警规则、触发条件、关键指标快照、关联日志摘要
- 知识库:现象、影响面、根因、处理步骤、验证方式、回滚/规避
- Runbook/SOP:步骤化处置手册、常用命令、判定条件
3.2 统一元数据(metadata)建议
每个片段至少携带:
product / component:产品线与组件名(网关、调度、K8s、DB 等)env / cluster / region:环境(selftest/pre/prod)、集群、机房version:版本号或兼容范围severity:严重等级time:发生/更新时刻tokens:错误码、异常名、表名、ip:port、接口路径、关键类/方法名trace_keys:trace_id/request_id/span_id(若有)
这些 metadata 不只是展示用,更用于检索过滤、融合加权、以及"新报错聚类与去重"。
3.3 日志去噪与规范化(对 BM25/向量都重要)
对原始日志做归一化:
- 替换时间戳、UUID、随机数、内存地址、临时目录等高基数字段为占位符;
- 保留强 token:错误码、异常名、表名、端口、HTTP code、路径;
- 异常栈截断:保留 top frames(如前 10 帧)并提取关键帧指纹。
四、双路索引实现
4.1 BM25(Elasticsearch/OpenSearch)------词法精准召回
BM25 的优势是"看得见、可控、对强 token 极敏感"。在故障诊断中,以下字段往往比自然语言更重要:
NullPointerExceptionACT_RU_JOB、SCOPE_ID_127.0.0.1:443HTTP 502、ORA-xxxx、MySQL 1045- 关键类名/方法名/模块名
4.1.1 Mapping 与 analyzer 实战建议
- 关键字段做
keyword:error_code、exception、table、ip_port、path - 原文做
text:message、stack_trace - 同一字段做 multi-field:既要可分词全文检索,也要可精确匹配/聚合
- 为"异常栈/标识符"配置
whitespace或自定义 tokenizer,避免被中文分词切碎。
4.1.2 Query 模板(带字段权重与过滤)
- 过滤:
product/component/env/version - 查询:
exception/error_code/table/ip_port/path高 boost,message次之
BM25 路的定位是:只要新报错里出现"强 token",BM25 常能直接命中正确案例/Runbook。
4.2 向量检索(Milvus/pgvector/OpenSearch kNN)------语义召回
向量检索解决的是"同一问题不同描述"的问题,例如:
- "连接被拒绝" vs "服务未监听端口"
- "数据库 schema upgrade 失败" vs "Flowable 升级报错"
- "响应体校验失败" vs "ResponseValidationError"
4.2.1 向量化内容构造(不要直接喂一坨原始日志)
推荐构造 embedding_text:
- 标题/摘要(LLM 生成或规则摘要)
- 清洗后的错误描述(clean_text)
- 强 token 拼接(exception/error_code/table/path/ip_port)
- 关键栈帧(top frames)
这样 embedding 更稳定、检索更聚焦。
4.2.2 Metadata 过滤
向量库必须支持基于 metadata 的过滤(如 product=portal、version in [v1,v2]),否则召回会被"语义相似但不相关"的片段污染。
五、 双路融合:RRF(Reciprocal Rank Fusion)
BM25 分数与向量相似度不在一个尺度,直接加权需要大量调参且容易漂移。RRF 用"排名"融合,工程上更稳:
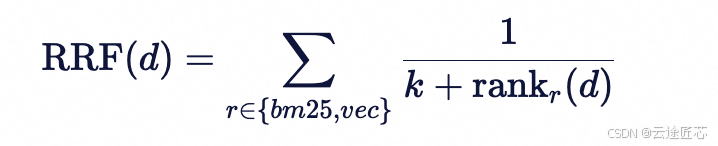
k常取 60- 候选集取两路 TopK 的并集,按 RRF 得分排序取 TopN
RRF 的优点:
- 稳定:不依赖分值归一化
- 强鲁棒:任一路"强命中"都能把正确文档抬上来
- 易解释:可以展示"来自 BM25 第几名 + 向量第几名"
六、重排:把"像"变成"对"
双路融合后得到 TopN(如 30),建议做一层重排以提升最终给 LLM 的证据质量。
6.1 轻量规则重排(最易落地)
- 同
component+x - 同
major version+x - 命中同
error_code/exception/table/ip_port强加分 - 文档过旧或跨版本跨度太大降分
- 文档类型优先级:已闭环工单(根因明确) > Runbook > 原始日志片段
6.2 Reranker(可选)
对 TopN 用 cross-encoder rerank(吞吐较低但质量高),输出 Top10~20 给 RAG。
七、RAG 诊断:从"检索结果"到"可执行建议"
7.1 证据组织
给 LLM 的上下文应包含:
- 新报错的结构化信息(抽取后的 tokens、环境、版本)
- TopK 片段(带 source、时间、版本、处理结论、链接)
- 明确要求:只能基于证据推断,不确定要说明缺失信息
7.2 输出格式(建议固定 JSON)
facts:关键事实提取hypotheses[]:原因列表(概率排序)+evidence_idsverification_steps[]:可执行验证步骤mitigation:短期缓解fix:长期修复missing_info[]:仍需补充的信息
八、新出现报错如何处理:从"未知"到"已知"的闭环机制
"新报错"的本质是:知识库里没有完全相同的指纹,或现有召回证据不足。
8.1 新报错事件化与指纹
生成 fingerprint 用于聚类、去重、追踪:
exception_nameerror_codecomponenttop_stack_frames_hashmajor_version- 可选:
http_code/path/ip_port/table
如果同指纹在短时间大量出现,可直接触发"已知问题候选"流程。
8.2 弱命中/无命中时的检索降级策略
- 放宽过滤:同组件同产品优先,其次跨版本,最后跨产品但同中间件类型
- Query 扩展:
-
- BM25:保留最强 token(错误码/异常名/表名/端口)重查
- 向量:用 LLM 改写为"通用故障描述"再向量检索一次(query rewrite)
- 召回 Runbook 类文档:即使没有同类错误,也能给"同类现象处置步骤"。
8.3 动态现场取证
对于新报错,LLM 可能会给出多个怀疑点。此时,系统演进为 Agent 模式:
- 自动化取证 :如果 LLM 怀疑是磁盘满,系统自动执行
df -h;怀疑是端口未监听,自动执行ss -tulnp。 - 递归诊断:将取证结果再次输入 LLM,形成"报错 -> 假设 -> 取证 -> 结论"的闭环。
8.4 生成"可验证假设",推动人工确认
对新报错不追求一次性定论,而是输出:
- 2~5 条最可能原因(每条明确"为什么"与证据引用)
- 每条的验证动作(查什么日志、看什么指标、执行什么命令)
- 缺失信息清单(TraceID、下游错误码、版本变更等)
8.4 确认后沉淀(最关键)
一旦根因确认:
- 生成标准知识条目:现象→根因→处理→验证→影响范围→防复发
- 增量写入 BM25 索引 与向量库
- 同时把"可规则化"的部分下沉为诊断规则(例如端口拒绝、权限不足、schema upgrade 冲突等)
九、MVP落地路线(工程分阶段)
Phase 1(跑通链路)
- 切片与 metadata 规范
- ES/OpenSearch BM25 索引与查询
- 向量库与 embedding 服务
- 双路并行 + RRF 融合,返回 TopN 证据列表
Phase 2(提升诊断质量)
- 规则重排 / reranker
- RAG 提示词与结构化输出
- 证据引用展示
Phase 3(闭环进化)
- 新报错指纹聚类与去重
- Runbook 自动沉淀与增量索引
- 可规则化故障下沉到自动诊断规则库
十、实战演练:以 ResponseValidationError 为例
9.1 场景重现
在升级测试中,接口 trig_up 突然报出 ResponseValidationError,且历史库中无记录。
9.2 执行流程
- 双路找回 :BM25 匹配到了
FastAPI框架文档,但向量库未找到相似故障单。 - 语义解析 :LLM 识别出报错核心是"返回模型校验失败",原因是期待
Dict却收到了""。 - 代码溯源 :系统读取
/home/admin/manage.py:1830附近的代码片段。 - 逻辑推理 :LLM 发现该处代码在
try...except捕获到业务异常后,默认返回了一个空的 Response 对象,其data字段被赋值为""。 - 输出建议 :
- 根因:触发业务异常,但异常处理函数返回格式不合规。
- 修复 :修改
Response定义,确保data默认为{}。
十一、结论
在云计算智能诊断领域,检索决定了系统的下限,而推理决定了系统的上限。
通过 BM25 + 向量检索 的双路方案,能够构建一个覆盖"已知故障"的强大检索网;而通过 LLM 推理 + 自动化取证,赋予了系统处理"未知异常"的能力。
- BM25 擅长抓住故障诊断中最值钱的"强 token";
- 向量检索擅长跨表述、跨文本形态地找"语义同源问题";
- RRF 让融合变得稳定可控;
- RAG 让结果可解释、可执行;
- 闭环沉淀让系统越用越强,真正适配"新报错不断出现"的现实。