说明
前两项目需要用到RediSearch提高检索速度,然后网上搜索了好多文章,也问了AI,但是结果不尽人意,最终还是根据网络文章整理,一点点修复,处理除了最终版本
首先SpringBoot整合RediSearch有两种,第一种是jedis的,第二种是Lettuce写的
然后我这里整合的是jedis,首先我最开始使用的Lettuce,不过各种异常报错,因为我其他代码使用了
StringRedisTemplate 然后StringRedisTemplate 是基于Lettuce,所以我更倾向于Lettuce,而且Lettuce是线程安全,不过总是有问题,所以最终选择了jedis,不过jedis同样也是一堆错误,大致错误都是依赖包版本各种冲突
然后最开始使用的是老版本的jedis.sendCommand,他返回的是文档数据,还是一堆问题,后来查询高版本,可以解决这个问题
正文
依赖版本:
php
springboot:2.1.5.RELEASE (这里本来用的高版本,但是和连接池冲突,然后就改回了2.1.5)
jredisearch:2.2.0
jedis:4.3.0 这里使用4.3.0,返回的结果是map数据,方便使用,低版本不是,只是文档
pool2:2.12.0 创建连接池使用整体依赖:
xml
<!-- redis 这里排除pool2,是防止版本冲突 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jredisearch</artifactId>
<version>2.2.0</version>
<!-- 排除包内引用的jedis, 包内引用的是3.7.0,但是无法连接redis7的redisearch,在下面单独引用 jedis -->
<exclusions>
<exclusion>
<artifactId>jedis</artifactId>
<groupId>redis.clients</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- jedis 不能太高,也不能提低,不然一堆错误 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.12.0</version>
</dependency>开始整合
- 由于RediSearch一堆问题(win没找到,说要自己编译,linux安装又麻烦,所以直接使用docker里整合好的)
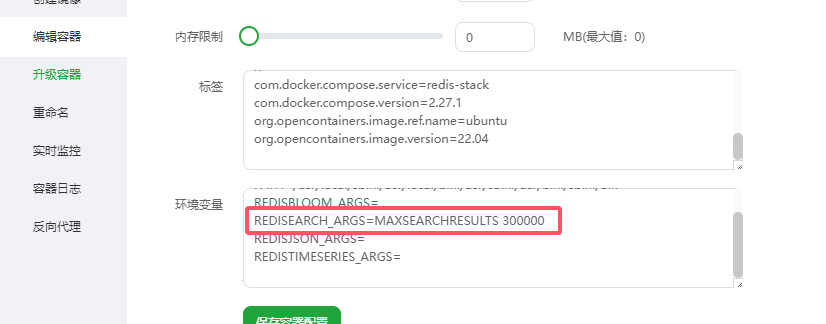
- 宝塔安装比较容易,应用商店直接安装就行了,都是一键搞定,然后,安装好后需要注意,必须先编辑容器,环境变量里需要修改查询上线,不然数据量查询默认10000
xml
REDISEARCH_ARGS=MAXSEARCHRESULTS 300000如果修改后远程连接不上,可以重新安装,然后在docker页面里重新编辑
- 接下来开始上代码
java
spring.redis.host=127.0.0.1 #(远程填写ip,部署时修改成127.0.0.1就可以了)
spring.redis.port=6378 #(对了上面因为是用的docker容器,所以端口根据情况做映射,所以不用6379)
spring.redis.password=密码- 连接池配置
java
package com.reptile.util.redis.redisearch;
import java.net.URI;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import redis.clients.jedis.Connection;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.UnifiedJedis;
import redis.clients.jedis.JedisPooled;
@Configuration
public class RedisConfig {
@Value("${spring.redis.host:127.0.0.1}")
private String host;
@Value("${spring.redis.port:6378}")
private int port;
@Value("${spring.redis.password:密码}")
private String password;
@Bean
public UnifiedJedis redisSearchClient() {
// 1. 池配置
GenericObjectPoolConfig<Connection> poolCfg = new GenericObjectPoolConfig<>();
poolCfg.setMaxTotal(128);
poolCfg.setMaxIdle(64);
poolCfg.setMinIdle(16);
poolCfg.setMaxWaitMillis(5000);
// 2. 组装 URI(db 默认 0)
String uri = String.format("redis://:%s@%s:%d/0", password, host, port);
// 3. 带池配置的构造器
return new JedisPooled(poolCfg, URI.create(uri));
}
}上面这个配置就可以满足并发使用了
-
注意下面代码非完整代码,主要是创建索引和基础查询,由于里面带了我自己项目的代码封装,所以你们不能直接复制使用,需要自己处理一下
java
package com.reptile.util.redis.redisearch;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.alibaba.fastjson.JSON;
import redis.clients.jedis.UnifiedJedis;
import redis.clients.jedis.search.Document;
import redis.clients.jedis.search.IndexDefinition;
import redis.clients.jedis.search.IndexOptions;
import redis.clients.jedis.search.Query;
import redis.clients.jedis.search.Schema;
import redis.clients.jedis.search.SearchResult;
@Component
public class RediSearchUtils {
@Autowired
private UnifiedJedis redisSearchClient;
//创建索引
public void IndexD() {
// 1. 存在就删
try {
redisSearchClient.ftDropIndex("gmshow"); // 索引立即删除
} catch (Exception ignore) {
// 索引不存在会抛异常,忽略即可
System.out.println("索引存在,删除失败");
}
// 2. 重新创建
Schema schema = new Schema()
.addTagField("id")......;
//其他索引自己需要搞的注意
//下面提供几个常用的索引格式
//.addTagField("id")这种加进来的只能用@名称:{id} 等于检索,就是数据库里的=,不能用模糊查询
//.addNumericField("time") 这是数字,可以用来排序
// .addTextField("director", 3.0) 这是文本,3.0代表权重,可以使用@名称:*关键词* 模糊查询
IndexDefinition def = new IndexDefinition(IndexDefinition.Type.HASH)
.setPrefixes("vod_show:");//这是redis存入的前缀
redisSearchClient.ftCreate("gmshow",
IndexOptions.defaultOptions().setDefinition(def),
schema);
System.out.println("创建成功");
}
//检索数据
public Pages byMovie(参数...) {
.....
//开始拼接参数
qsql = "@title:*关键词*";
Query q = new Query(qsql)
.setSortBy(os, false) //这是排序,填写字段名称就可以了 false代表倒序
.limit((page-1)*limit, limit);
// 2. 执行搜索
SearchResult sr = redisSearchClient.ftSearch("gmshow", q);
long totalResults = sr.getTotalResults();
// System.out.println("总条数:"+totalResults);
// 3. 拿结果
List<Document> docs = sr.getDocuments();
docs.forEach(d -> System.out.println(JSON.toJSONString(d.getProperties())));
//d.getProperties() 这个就是最终要的数据
return pagess;
}
}上面的代码完整包含了使用,不过需要自己根据项目整理
创建索引只需要调用一次就可以了,后续不需要
ps:补充一下塞入数据
java
# item 是数据拿出来的数据,下面是塞入redis中,这不是唯一的方法,还有一种是jedis自带的
Map<String,String> redisMap = new HashMap<>(item.size());
item.forEach((k,v) -> redisMap.put(k, String.valueOf(v)));
stringRedisTemplate.opsForHash().putAll("vod_show:" + vid, redisMap);