阔别三年,久违了
Hi,大家好呀。已经很久没在掘金上写文章了,上次发文章,也是三年前的事了。这三年也不是没想过写点什么,但每次打开编辑器,敲几行字又删了...
可能"也许没什么好记录的吧"。哈哈~
今年有些不一样:这一年做的事情,可能是我这几年工作以来比较有"沉淀和进步"的一年。AI的浪潮真正席卷到了我们日常工作的每一个角落。从年初的观望,到年中的All in,再到现在真正落地了一些能力。
所以,25年的最后一天是值得记录下来,给这一年画个完美句号。
当然哈,除了技术方向上的一些唠叨,也开心的聊聊这一年的生活、还有一些零碎的感悟。
如果可以,听首歌,慢慢看。
生活:最大的变化,是角色的转换
在消失的三年中,我成了家。有了一个可爱的女儿"柚柚"。
说实话,当爸爸这件事,比写任何代码都难。代码不行可以重写,bug可以debug,但小朋友的每一个哭声、每一次发烧,我都很局促...
女儿刚出生的那几个月,我经历了人生中最混乱的时期。白天在公司开会、写代码、处理线上问题;晚上回家换尿布、冲奶粉、哄睡觉。有一次凌晨2、3点,女儿发高烧,第一次面临这个问题手忙脚乱,夜里开车带着小孩去医院急诊。那种揪心,着急,相信每个新手爸妈都会和我一样,不知所措。
也分享一些没体验过的时刻:
- 她第一次对着我笑,嘴角弯弯的,眼睛亮亮的;
- 她会用小手抓住我的手指,攥得紧紧的不肯放;
- 她会"啊啊"地跟我"对话",虽然听不懂,但我每次都认真回应。有时候加班回家晚了,她已经睡着了。我就在床边坐一会儿,看着她的小脸,觉得一天的疲惫都消散了,很开心。
成家、当爸爸,这些事情让我更加有动力给她们更好的生活。这对我来说弥足珍贵。
技术:核心三件事
今年工作上最大的感受:AI从"能用"到"好用",要走的路很长,做的事很多。
年初那会儿,大模型已经火了快一年,各种Agent框架、RAG方案遍地开花,再加上DeepSeek横空出世带来的冲击,感觉AI的门槛一下子被拉低了:好像谁都能花三天时间搭一个"智能助手"出来。
但真正想把AI落到实际业务里时,会发现:跑通一个demo和做出一个能用的产品,完全是两回事。所以这一年主要做了三件事:搭知识库、建Multi-Agent架构、做上下文工程。
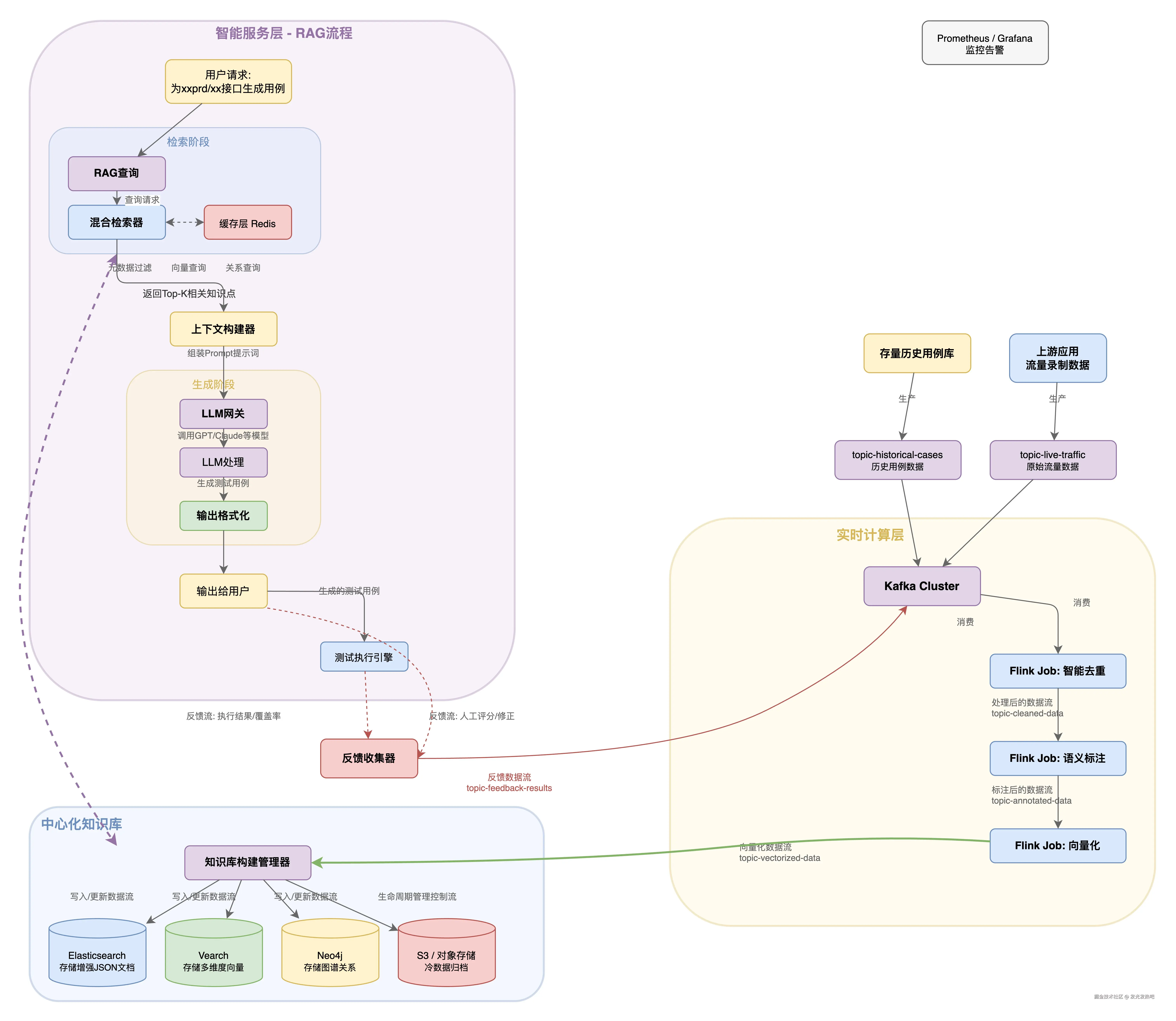
首先是知识库 - 让AI"懂业务"
大模型最大的问题是什么?它什么都知道一点,但对你的业务一无所知。
我涉及的场景是测试领域------需求文档、接口文档、历史测试用例、业务规则......这些知识散落在各个系统里,格式不一,质量参差不齐。直接丢给大模型,它根本理解不了。所以第一件事,是搭建一套企业级的知识库。
核心思路:"先结构化,再向量化":
-
知识入库:把各种来源的文档统一采集,做清洗、去重、脱敏
-
语义增强:不是简单存原文,而是提取实体、关系、关键信息,形成结构化的知识单元
-
多维向量:不同粒度的内容用不同的向量策略------句子级捕捉语义细节,段落级理解上下文,文档级把握整体主题
-
混合检索:向量检索 + 关键词检索 + 规则过滤,多路召回再统一排序
做完这套,AI的回答就不再是泛泛而谈的看似正确的废话了~
这里贴一些图吧:
系统架构
数据处理 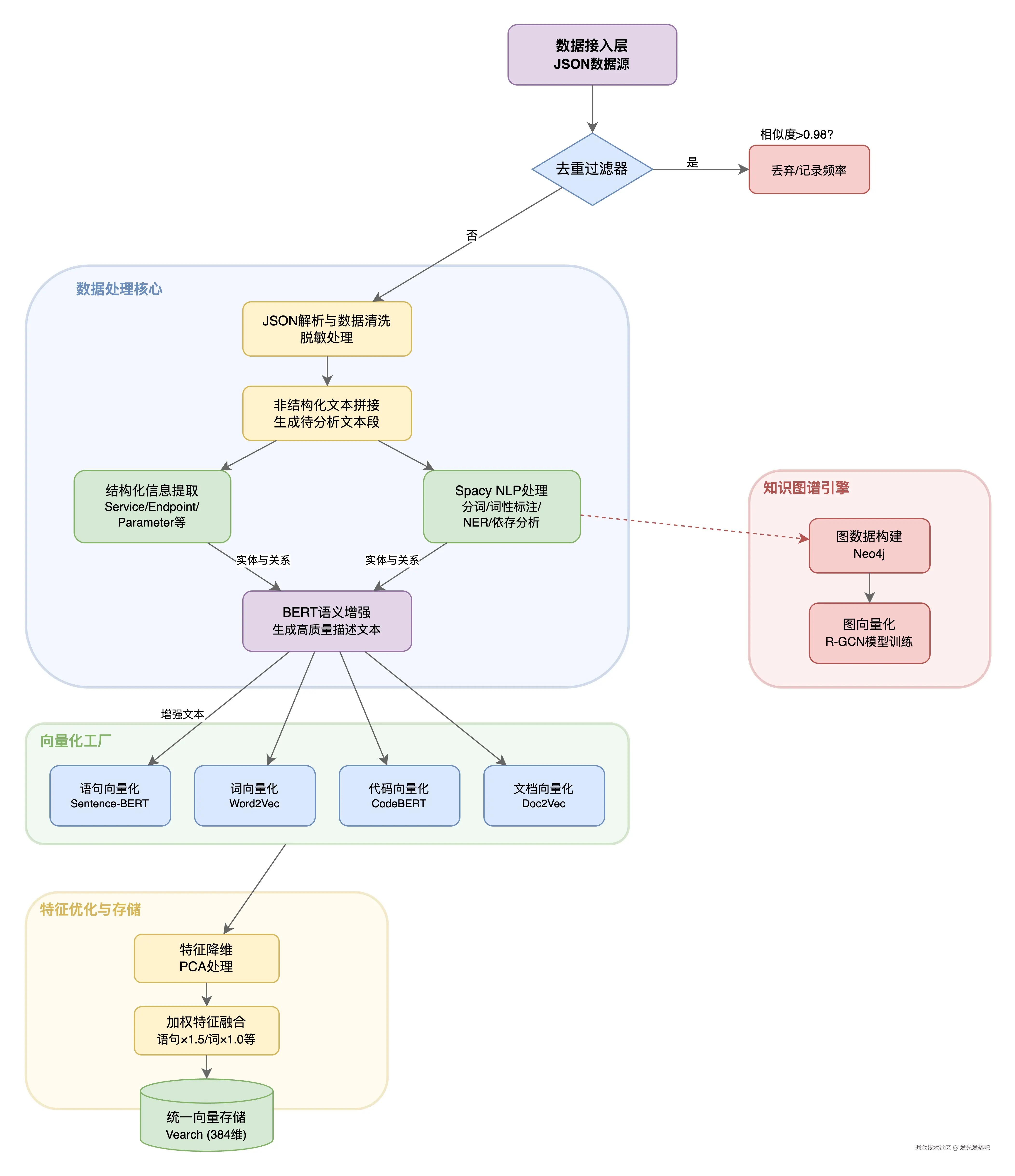
紧接着就是Multi-Agent - 复杂任务规划协作
为什么会需要到 Multi-Agent呢?单个Agent能做的事是有限的。当任务变的比较复杂的时候:比如"读懂一份需求文档,提取测试点,生成测试用例,还要参考历史Case"塞进一个Agent里,prompt是很爆炸的,效果大打折扣。
所以做了Multi-Agent协作架构。核心设计是"理解 + 任务制定 + 分工 + 协作":
-
专业化Agent:文档理解Agent专门做文档解析,用例生成Agent专门做Case设计,知识检索Agent专门做召回。这样就可以保证每个Agent职责单一,能力聚焦
-
调度层:上层有一个统一的masterAgent负责理解用户意图,把任务分发给合适的Agent,再把结果整合起来
-
灵活编排:支持串行、并行、条件分支等多种编排模式,根据场景选择合适的执行策略
-
可观测性:完整的执行链路追踪,每个Agent的输入输出都能看到,调试和优化有据可依
这套架构跑起来之后,复杂任务的完成质量明显提升,而且每个环节都可以单独调优,不会牵一发动全身。
一个体会:Multi-Agent的核心是"让对的Agent在对的节点做对的事"。
同样贴两张图,互相学习(不会放太多,只做简单说明哈):
单Agent与Multi-Agent架构对比 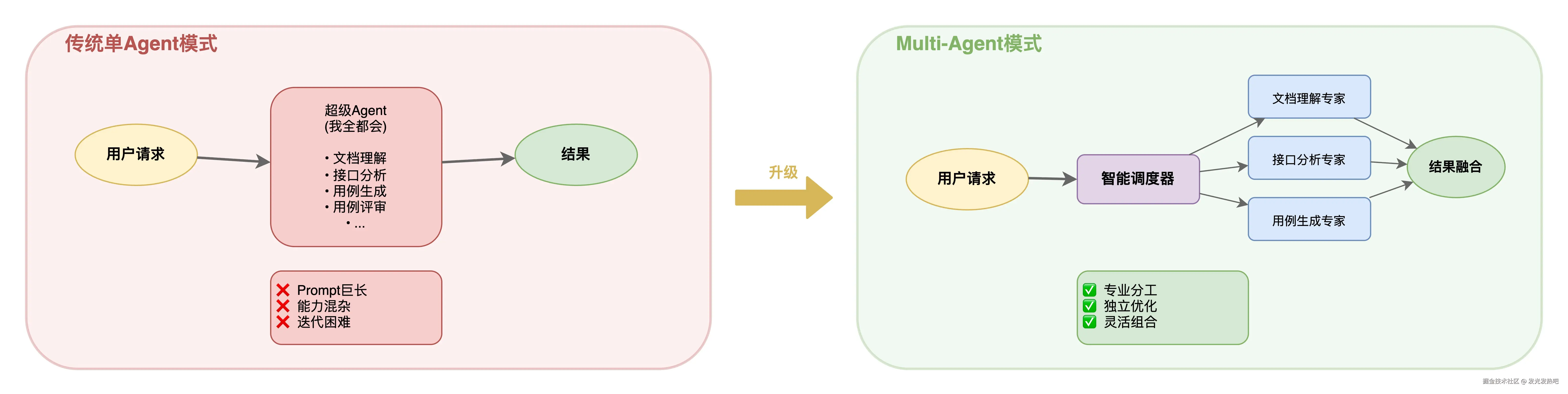
端到端测试工作流 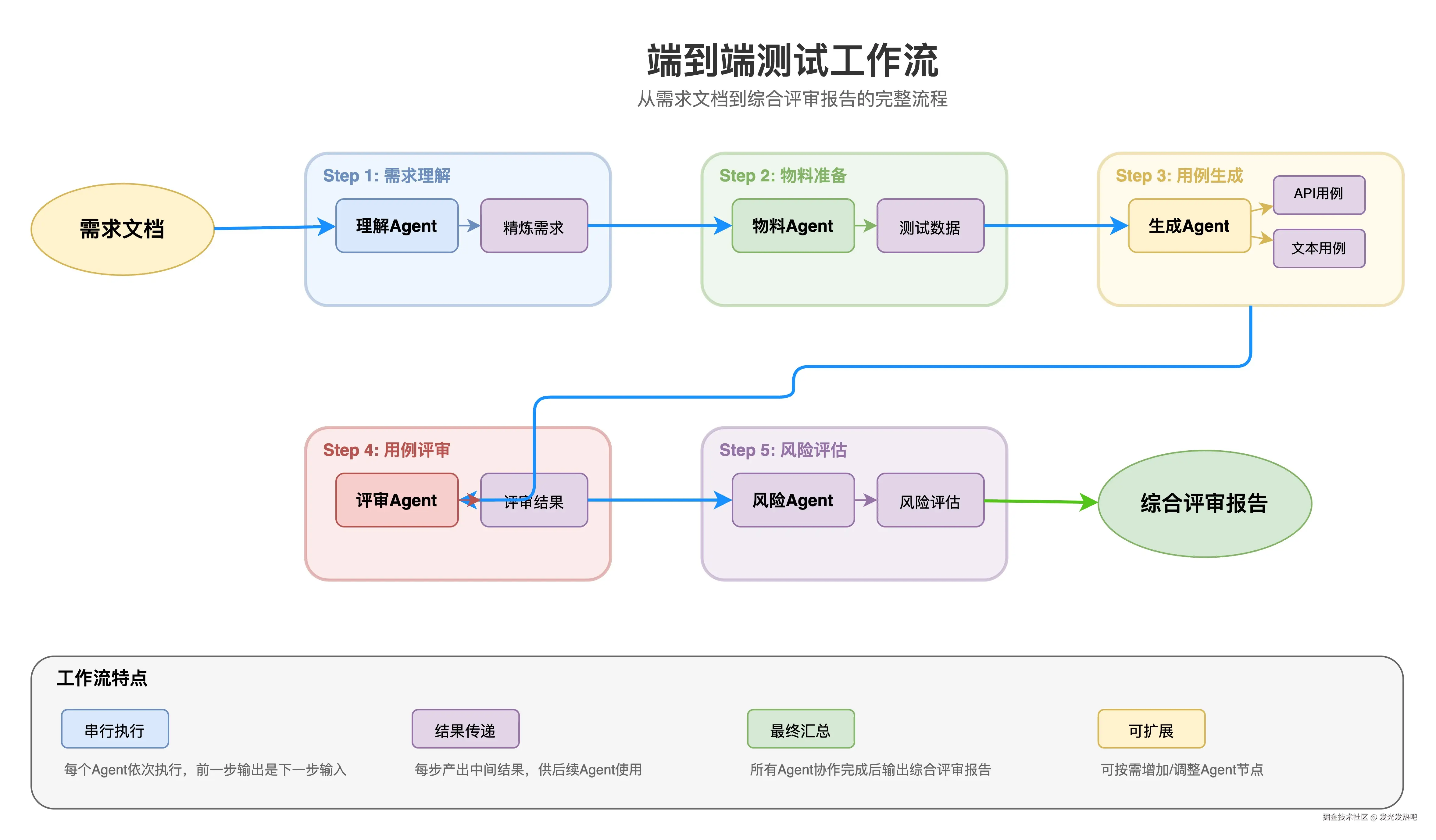
最后上下文工程
今年有个很火的观点:"Prompt Engineering已死,Context Engineering当立"。
技术有时候革新的太快,还沉浸在prompt,知识库等AI领域知识学习的状态中,已经有新东西出来了。为了不掉队,保持学习的低姿态。
看完之后,只有一个感受:有东西!用大模型用得越多,越发现:模型能力是基础,但输出什么样的质量很大程度上取决于:你告诉它什么上下文。
当然,现在上下文也还在初步的尝试,学习使用阶段。目前在上下文工程上做了几件事:
-
上下文压缩:召回内容太多会超token限制,需要智能裁剪:保留最相关的、去掉冗余的、控制在合理长度内
-
上下文增强:不只是塞检索结果,还要补充必要的背景信息、格式要求、few-shot示例,让模型更容易理解任务
-
对话上下文管理:多轮对话中,哪些历史要保留、哪些可以丢弃、怎么做摘要。这是很重要的,因为直接影响对话的连贯性和准确性
目前的一些尝试,浅显体会是:上下文工程的价值可能是当前LLM应用中被低估了的一部分。个人感受:与其花大力气选模型、调Prompt。不如学习如何使用上下文。
思考&体会
做了差不多大半年AI方向,有一些个人的感受:
第一,工程能力很重要。怎么理解呢?
- 刚开始接触大模型的时候,总觉得模型能力是最重要的------选对模型,问题就解决一大半。后来实践久了发现,选模型只是很小的一部分。怎么组织知识、怎么设计上下文、怎么让多个Agent配合起来......这些才是真正决定效果的核心!!!有时候换个更强的模型,可能效果是提升了;但把上下文设计优化一下,效果能提升更多。所以工程能力设计才是核心竞争力。
第二,用户不在乎你的技术多牛,只在乎好不好用。
- 比方说召回率再怎么提升,对于用户而言,并不那么重要。用户根本感知不到这个差异。反倒是把loading时间从5秒压到2秒、把结果从"等半天一次性出来"改成"一边生成一边显示"------用户立刻就觉得"哇,这个可以,牛x"。技术指标是给自己看的,用户体验才是给用户的。从做一个优秀的产品视角做好智能化。
第三,别太焦虑,选准方向踏实做。
- 今年AI圈新概念满天飞,每周都有新论文、新框架、新名词。一开始我也是焦虑的,哇,这么多学不过来怎么办...后来慢慢想通了:技术是为场景服务的,不是为了追热点。与其浅尝辄止地追每一个新东西,不如找准几个核心能力,在自己的场景里扎下去,踏踏实实的做,做深做透。反而心里更有底。
最后 "AI真的能提效吗?"
我的答案是:能,但不是你想象的那种"一键生成"。它更像是一个"助手"。能帮你做很多重复性、模式化的工作,但核心的思考、判断、决策,自己决定。
与其焦虑。不如先行 共勉~
愿景
最后聊聊对新一年的期待,共同学习。
技术方向上,我会关注的几个点:
-
知识库:向量检索只是知识库的冰山一角。更完整的知识库应该包括:知识的组织、更新、版本管理、权限控制,以及知识与Agent的深度融合。这块还有很大的能力需要建设。
-
多智能体协作:Agent能根据任务动态组织、能相互学习、能处理冲突。
-
上下文工程:这个词是最近在圈子里很火的概念。核心观点是:对于LLM应用来说,"如何构造输入给模型的上下文"可能比"选择什么模型"更重要。我很认同。
-
Skills技能:让Agent拥有可复用、可组合的"技能"。每次都从头学习,是很笨的。这是Agent能力提升的关键之一。
写在最后
2025年是充实的一年。
技术上,在AI方向有了很多的尝试,落地。学到了很多领域的知识。这是一件很棒的事。我很喜欢。
生活上,我有了家庭和女儿。我是女儿奴,我承认。
2026年,希望能继续保持这个节奏:认真工作,好好生活,捡起写文章的好习惯。
最后的最后,如果你也在做AI方向的工作,欢迎交流。在技术的路上,一起前行~
元旦快乐!