UI-INS: ENHANCING GUI GROUNDING WITH MULTIPERSPECTIVE INSTRUCTION-AS-REASONING
摘要
UI-Ins-32B 获得了最佳的接地精度,在 UI-I2E-Bench 上得分 87.3%,在 ScreenSpot-Pro 上得分 57.0%,在 MMBench-GUI L2 上得分 84.9%。此外,我们的模型展示了强大的代理潜力,使用 UI-Ins-7B 作为执行器在 AndroidWorld 上实现了 74.1% 的成功率。
我们关注指令的多样性,并揭示了一个根本性的不匹配:人类可以在多种指令视角中灵活地选择最有效的途径,而目前的模型则以狭隘、固定的风格进行训练。例如,为了表达诸如"关闭窗口"之类的单一意图,人类可能会根据其外观("点击红色X")、功能("关闭文件管理器")、空间位置("右上角的按钮")或高级意图("去掉这个屏幕")来描述相应的UI元素。人类有策略地在这些视角之间切换,为手头的任务选择最有效的描述,如图3所示。我们在第2.1节中的定量分析同样表明,利用指令多样性是提高定位准确性的关键。然而,目前流行的GUI定位模型通常被训练为将单一的指令风格映射到一个动作,在跨不同视角进行推理的能力有限。这种局限性构成了GUI定位任务灵活适应性和稳健解释的关键瓶颈。

1 引言
与先前的工作一致 (Lu et al., 2025; Tang et al., 2025),我们确认自由形式的推理方法通常会降低 GRPO 期间的模型性能 。相反,实验结果表明,我们提出的 Instruction-as-Reasoning 方法始终如一地大幅提高各种基础模型的性能,从而确立了其作为一种高效的对齐推理范式。其次,我们如何缓解 SFT+RL 框架中的策略崩溃 ?我们发现,仅使用坐标作为真实值通过 SFT 微调的模型通常表现出高度一致的响应,导致 RL 中无效的探索和策略崩溃。Phi-Ground (Zhang et al., 2025) 也注意到了这一点。然而,我们的 Instruction-as-Reasoning 框架通过在 SFT 之后灌输多样化的探索能力来缓解这个问题,使模型能够在 RL 期间生成多样化的 rollout,从而避免策略崩溃。最后,UI-Ins 的推理能力是否仅限于训练期间看到的预定义视角?有趣的是,我们观察到,在使用 Instruction-as-Reasoning 进行训练后,该模型不仅学会了选择最佳的推理路径,而且还发展出组合不同推理视角以及从训练中未见过的新指令视角进行推理的新兴能力。
总而言之,我们的贡献如下:
- 对GUI基础指令的系统性调查。我们对GUI基础中的指令进行了系统性分析,揭示了两个关键见解:(1)在主要数据集中,高达23.3%的样本指令存在缺陷;(2)利用指令多样性具有巨大的潜在改进空间,即使不经过训练,也能释放高达76%的相对性能提升。
- 指令即推理范式。在上述见解的基础上,我们提出了指令即推理范式,该范式将指令从静态输入重新定义为动态推理路径。我们通过 SFT+GRPO 训练框架来实现这一点,该框架首先教导模型使用不同的指令视角作为推理路径,然后激励它为任何给定的 GUI 场景选择最佳的分析推理路径。
- 在各种基准测试中均达到 SOTA 性能。我们的 UI-Ins-7B 和 UI-Ins-32B 在五个最著名的 grounding 基准测试中建立了新的 SOTA 性能。值得注意的是,UI-Ins-32B 在 UI-I2E-Bench 上达到了 87.3%,在 ScreenSpot-Pro 上达到了 57.0%,在 MMBench-GUI L2 上达到了 84.9%,显著超过了其最强大的同类产品。此外,我们卓越的 grounding 能力与 GPT-5 作为规划器相结合,在 AndroidWorld 上实现了强大的在线代理性能,成功率达到 74.1%。
- 深入分析。我们的分析为基础提供了额外的见解。我们展示了如何构建推理以增强而非阻碍性能,以及我们的方法如何缓解 SFT+RL 框架中的策略崩溃。此外,我们揭示了我们的方法解锁了涌现的推理能力,使模型能够从新颖的角度进行推理。
2 指示的重要性究竟有多大?
如图2a所示的结果揭示了两个关键的见解。首先,指令的多样性至关重要。从外观、功能和意图角度出发的指令都显著优于原始指令。这表明,即使不进行重新训练,仅仅提供不同的指令视角也可以释放模型中显著的潜在能力。其次,选择最合适的指令视角的能力可以带来更高的性能上限。"组合"条代表了如果模型总是能为每个样本选择表现最佳的视角时的性能,实现了76%的相对改进,远远超过任何单一指令视角。
总而言之,这些结果揭示了利用指令多样性的巨大未开发潜力,包括引入多个指令视角和针对每个实例选择最佳视角。这促使我们开发了一种算法,该算法学习利用不同的指令视角进行推理,并动态选择最佳分析角度。
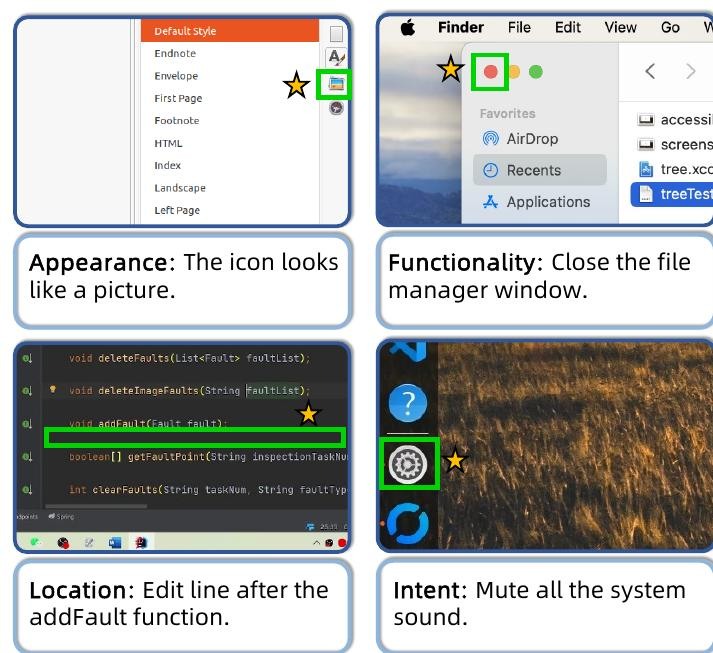
备注:如何设计提示词呢? 可以生成这些描述,但如何根据描述定位?
虽然利用指令多样性很有前景,但其有效性取决于原始指令是否正确这一基础。但这个基础是否有效?为了探究 grounding 数据集的指令质量,我们进行了大规模的人工分析。具体来说,我们检查了来自三个著名数据集的 1,909 个样本,分别是 OS-Atlas (Wu et al., 2024a)、AMEX (Chai et al., 2025) 和 Widget Captioning (Li et al., 2020)。
我们的分析揭示了普遍存在的指令质量问题。如图2b所示,23.3%的指令存在实质性缺陷,包括含糊不清或指向图4中未显示的内容。为了进一步量化此类缺陷的影响,我们使用原始数据集和清理后的版本训练了相同的模型。实验结果如图2c所示:在清理后的数据上训练的模型在多个基准测试中取得了显著且一致的性能提升。换句话说,当用于训练时,有缺陷的指令数据会显著降低下游性能。
示例:grounding 数据集中指令质量的缺陷。左:模糊匹配,一条指令映射到多个 UI 元素。右:不匹配,没有有效的 UI 元素与该指令匹配。
这些发现表明,现有数据集存在指令质量问题,这些问题会积极损害模型性能。因此,数据清理不是可有可无的细节,而是有意义的训练的必要先决条件,尤其是在我们的目标是教导模型利用不同的指令视角进行推理时。
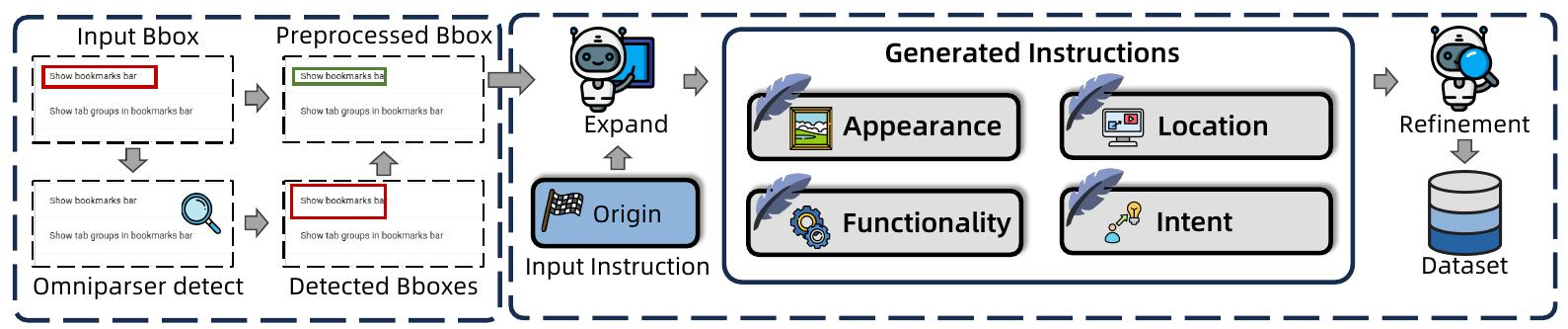
我们的高质量数据处理流程概述。该流程首先预处理真值边界框,然后利用GPT-4.1从不同角度生成指令,最后采用验证阶段来过滤结果,确保指令和真值框之间的精确对齐。
备注:由于我们已经能知道真实的框,最后可以使用验证阶段来过滤即可,这个工作是否已经充分?
3 方法
多视角指令增强。我们流程的核心在于丰富指令的多样性。我们利用 GPT-4.1 (OpenAI, 2025a) 从我们在分析中确定的四个基本分析视角(外观、功能、位置和意图)生成新的指令。对于每个数据实例,模型接收带有突出显示的目标元素的屏幕截图,并被提示创建一组高质量、多样化的措辞。为了减轻 LLM 的幻觉并确保严格的一对一映射,每个生成的指令都经过验证步骤,其中 GPT-4.1 确认它明确地仅指目标元素。这个过程产生了一个高质量、多视角的语料库,专门用于教授复杂的推理。
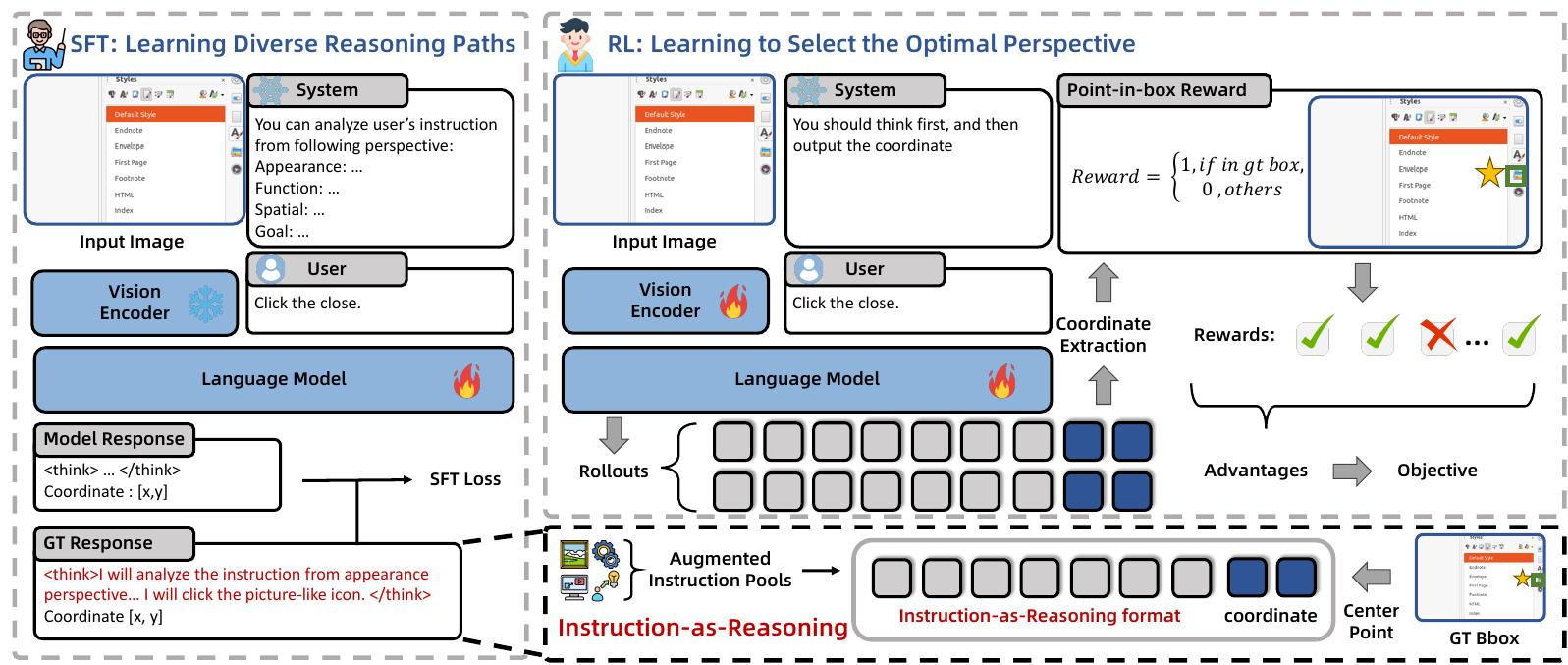
有了这样一个多视角的数据集,我们介绍了使用它的框架。正如第 2.1 节所讨论的,利用不同的指令视角并动态选择最佳分析角度是释放卓越 grounding 性能的关键。如图 6 所示,我们的 Instruction-asReasoning 框架是一种两阶段训练方法,旨在灌输这种能力:(i)SFT 阶段,教导模型使用多视角指令作为显式推理路径;(ii)RL 阶段,训练模型为每个样本使用最佳分析角度。
备注:这张图非常值得借鉴,告诉我们提示词要如何写
SFT阶段的目标是明确地赋予模型执行指令即推理(Instruction-as-Reasoning)的能力:在预测基础坐标点之前,利用不同的指令视角作为分析推理。具体而言,模型首先生成一个中间推理文本,即从一个指令视角重写的指令,作为可操作的推理路径(图 6)。然后输出最终的坐标点。
SFT阶段赋予模型从多个指令角度生成推理的能力。然而,它并没有教导模型在给定的上下文中哪种推理路径是最优的。为了超越这一局限性,并激励模型动态地选择最有效的分析视角,我们引入了一个RL阶段。
在回答之前,不提供预定义的视角(外观、功能等)的明确列表。这种开放式的指示鼓励模型探索更广泛的推理模式空间,包括综合多个视角,甚至形成全新的视角。然后,该模型学习从强化学习奖励的反馈中选择最佳的分析视角。
通过迭代地应用此过程,该模型学习优先考虑始终能导向正确坐标点的推理路径,从而有效地学习一种最优的、上下文相关的指令视角选择策略。有趣的是,我们发现该模型还学会了结合多个视角,甚至形成了全新的推理视角(第4.5节)。
SFT阶段 我们使用大约28.3万个实例对模型进行单轮微调 。为了教导模型从不同的指令角度进行推理,每个训练实例都是通过从我们定义的四个角度(外观、空间、功能和目标)中随机选择两个不同的指令角度来构建的 。其中一个被指定为指令角度,另一个被指定为推理角度。我们使用256的全局批次大小和5e-6的学习率。
RL阶段:GRPO训练利用3.3万个实例,通过为每个指令视角生成一个样本,扩展到大约10万个训练样本。我们在提示中未指定分析视角,以鼓励探索。我们采用1e-6的学习率和8个rollout。7B模型的批次大小设置为256,32B模型的批次大小设置为128。
备注:意味着系统提示词一样,答案不一样。
4、实验
中间推理步骤是否必要?一个根本问题是,生成中间推理对于我们的方法是否至关重要。为了回答这个问题,我们进行了一项消融研究,完全从SFT和RL阶段移除推理生成,训练模型直接预测坐标。实验结果如表7所示。与我们的方法(第4行)相比,移除推理(第1行)会导致所有基准测试的性能大幅下降,在UI-I2E-Bench上的准确率下降超过10%。这个结果证实了中间推理对于Instruction-asReasoning框架的成功至关重要。
自由式推理和非自由式推理比较
备注:没有证据表明,自由式推理会降低SFT性能。
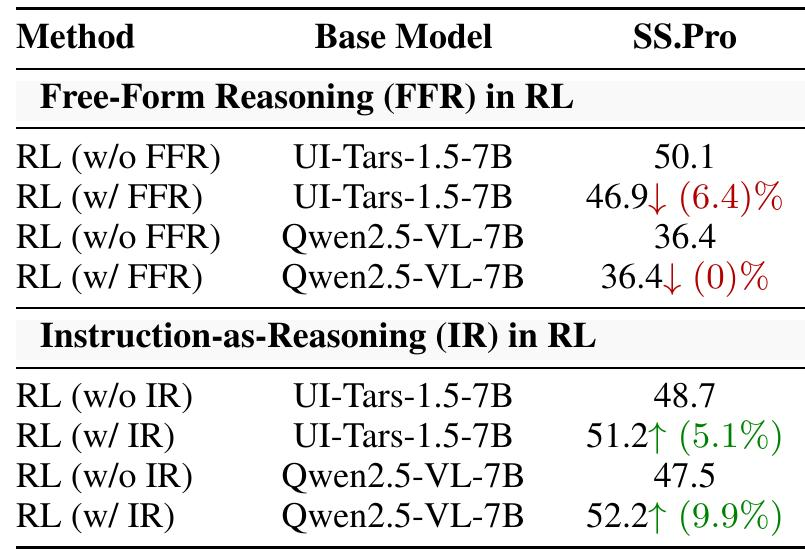
指令即推理(IR)与自由形式推理(FFR)。鉴于推理至关重要,哪种推理方式有效?先前的工作(Lu et al., 2025;Yang et al., 2025;Zhou et al., 2025;Tang et al., 2025)表明,FFR难以优化,甚至可能降低性能。我们在表8中针对我们的IR方法测试了这个假设。如表格顶部所示,应用FFR会降低UI-Tars-1.5-7B和Qwen2.5-VL-7B的性能,证实了先前的发现。例如,它导致UI-Tars-1.5-7B的SS.Pro相对下降6.4%。相比之下,底部部分显示,使用我们的IR方法训练模型可以显著提高准确性。因此,我们可以从实验中得出结论,非结构化的FFR无法改进,而IR是解锁GUI接地的有效推理的关键。
隐藏的益处:稳定SFT+RL。在用于接地的SFT+RL训练中,一个关键的挑战是RL期间的策略崩溃问题。我们在此消融实验中将我们的SFT+RL框架与标准框架进行比较。标准的SFT训练提供了一个较差的策略初始化,通常导致模型在RL期间的性能下降,如表9的上半部分所示。相比之下,我们基于指令即推理的SFT充当了一个强大的探索性预热。通过预训练模型以生成多样化的推理路径,我们赋予它强大的探索能力,从而在RL期间实现了显著的性能提升。这表明我们的SFT阶段不仅教授了推理格式,而且还在RL阶段实现了有效且稳定的策略优化。
6、论文值得借鉴的点
1、领域内的grounding提升可以提高执行能力
2、强化训练中:结构化的推理能提升性能,自由推理会损害性能。没有证据表明非推理SFT比推理SFT差。
3、开源grounding数据错误率达23.3%,会降低下游任务性能
4、仅使用坐标作为真实值通过 SFT 微调的模型通常表现出高度一致的响应,导致 RL 中无效的探索和策略崩溃
**5、**确认自由形式的推理方法通常会降低 GRPO 期间的模型性能。相反,实验结果表明,我们提出的 Instruction-as-Reasoning 方法始终如一地大幅提高各种基础模型的性能,从而确立了其作为一种高效的对齐推理范式
6、指令多样性对性能有显著影响
7、需要检验我们的数据质量错误率是否控制在10%以内,数据过滤工程是否充分。