import gzip
import os
from dataclasses import dataclass
from typing import List
import psycopg
# ====== 连接串(按你的环境改)======
# 例:本机连 docker 映射端口
# PG_DSN = "host=127.0.0.1 port=55432 dbname=postgres user=postgres password=123456"
PG_DSN = os.getenv(
"PG_DSN",
"host=192.168.152.134 port=55434 dbname=postgres user=postgres password=123456"
)
SCHEMA = "imdb"
@dataclass
class CopyJob:
table: str
columns: List[str]
gz_path: str
DDL_SQL = f"""
CREATE SCHEMA IF NOT EXISTS {SCHEMA};
DROP TABLE IF EXISTS {SCHEMA}.title_basics;
CREATE TABLE {SCHEMA}.title_basics (
tconst text PRIMARY KEY,
titleType text,
primaryTitle text,
originalTitle text,
isAdult int,
startYear int,
endYear int,
runtimeMinutes int,
genres text
);
DROP TABLE IF EXISTS {SCHEMA}.name_basics;
CREATE TABLE {SCHEMA}.name_basics (
nconst text PRIMARY KEY,
primaryName text,
birthYear int,
deathYear int,
primaryProfession text,
knownForTitles text
);
DROP TABLE IF EXISTS {SCHEMA}.title_principals;
CREATE TABLE {SCHEMA}.title_principals (
tconst text,
ordering int,
nconst text,
category text,
job text,
characters text
);
CREATE INDEX IF NOT EXISTS idx_principals_tconst ON {SCHEMA}.title_principals(tconst);
CREATE INDEX IF NOT EXISTS idx_principals_nconst ON {SCHEMA}.title_principals(nconst);
CREATE INDEX IF NOT EXISTS idx_principals_cat ON {SCHEMA}.title_principals(category);
"""
def run_ddl(conn: psycopg.Connection) -> None:
with conn.cursor() as cur:
cur.execute(DDL_SQL)
conn.commit()
def copy_tsv_gz(conn: psycopg.Connection, job: CopyJob) -> None:
"""
使用 COPY FROM STDIN 导入 .tsv.gz
- HEADER true:跳过首行表头
- NULL '\\N':IMDb 空值标记
- DELIMITER E'\t':TSV
"""
full_table = f"{SCHEMA}.{job.table}"
cols = ", ".join(job.columns)
copy_sql = f"""
COPY {full_table} ({cols})
FROM STDIN
WITH (
FORMAT csv,
DELIMITER E'\\t',
HEADER true,
NULL '\\N',
QUOTE E'\\b'
);
""".strip()
print(f"[COPY] {job.gz_path} -> {full_table}")
# gzip.open(..., 'rt'):文本模式,返回 str,COPY 直接可读
with gzip.open(job.gz_path, "rt", encoding="utf-8", errors="replace", newline="") as f:
with conn.cursor() as cur:
with cur.copy(copy_sql) as cp:
for line in f:
cp.write(line)
conn.commit()
print(f"[OK] {job.table}")
def quick_check(conn: psycopg.Connection) -> None:
sql = f"""
SELECT
(SELECT count(*) FROM {SCHEMA}.title_basics) AS titles,
(SELECT count(*) FROM {SCHEMA}.name_basics) AS names,
(SELECT count(*) FROM {SCHEMA}.title_principals) AS principals;
"""
with conn.cursor() as cur:
cur.execute(sql)
row = cur.fetchone()
print("[COUNT]", row)
def main():
# ====== 改成你的实际文件路径 ======
jobs = [
CopyJob(
table="title_basics",
columns=["tconst", "titleType", "primaryTitle", "originalTitle", "isAdult", "startYear", "endYear", "runtimeMinutes", "genres"],
gz_path="title.basics.tsv.gz",
),
CopyJob(
table="name_basics",
columns=["nconst", "primaryName", "birthYear", "deathYear", "primaryProfession", "knownForTitles"],
gz_path="name.basics.tsv.gz",
),
CopyJob(
table="title_principals",
columns=["tconst", "ordering", "nconst", "category", "job", "characters"],
gz_path="title.principals.tsv.gz",
),
]
with psycopg.connect(PG_DSN) as conn:
# 1) 建表(如果你已经建好,可以注释掉)
run_ddl(conn)
# 2) 导入
for job in jobs:
copy_tsv_gz(conn, job)
# 3) 校验
quick_check(conn)
if __name__ == "__main__":
main()
import json
import os
import time
import psycopg
from psycopg.rows import dict_row
from tqdm import tqdm
# ==========================
# 配置
# ==========================
DSN = os.getenv(
"PG_DSN",
"host=192.168.152.134 port=55434 dbname=postgres user=postgres password=123456"
)
GRAPH = "imdb_graph"
BATCH_PERSON = int(os.getenv("BATCH_PERSON", "5000"))
BATCH_TITLE = int(os.getenv("BATCH_TITLE", "5000"))
BATCH_EDGE = int(os.getenv("BATCH_EDGE", "5000"))
RETRY = int(os.getenv("RETRY", "3"))
SYNC_COMMIT_OFF = os.getenv("SYNC_COMMIT_OFF", "true").lower() in ("1", "true", "yes", "y")
# 只跑某阶段:PERSON / TITLE / EDGE / ALL
RUN_STAGE = os.getenv("RUN_STAGE", "ALL").upper()
# 可选:只导 actor/actress 的边(small 表你本来就筛过了,这里保守保留开关)
ONLY_ACTORS = os.getenv("ONLY_ACTORS", "true").lower() in ("1", "true", "yes", "y")
# ==========================
# 固定 Cypher
# ==========================
SQL_PERSON_CYPHER = f"""
SELECT 1
FROM cypher('{GRAPH}', $$
UNWIND $rows AS row
MERGE (p:Person {{nconst: row.nconst}})
SET p.primaryname = row.primaryname,
p.birthyear = row.birthyear,
p.deathyear = row.deathyear,
p.primaryprofession = row.primaryprofession,
p.knownfortitles = row.knownfortitles
RETURN 1
$$, %s::agtype) AS (x agtype);
"""
SQL_TITLE_CYPHER = f"""
SELECT 1
FROM cypher('{GRAPH}', $$
UNWIND $rows AS row
MERGE (t:Title {{tconst: row.tconst}})
SET t.titletype = row.titletype,
t.primarytitle = row.primarytitle,
t.originaltitle = row.originaltitle,
t.isadult = row.isadult,
t.startyear = row.startyear,
t.endyear = row.endyear,
t.runtimeminutes = row.runtimeminutes,
t.genres = row.genres
RETURN 1
$$, %s::agtype) AS (x agtype);
"""
SQL_EDGE_CYPHER = f"""
SELECT 1
FROM cypher('{GRAPH}', $$
UNWIND $rows AS row
MATCH (p:Person {{nconst: row.nconst}})
MATCH (t:Title {{tconst: row.tconst}})
MERGE (p)-[r:WORKED_ON {{category: row.category, ordering: row.ordering}}]->(t)
SET r.job = row.job,
r.characters = row.characters
RETURN 1
$$, %s::agtype) AS (x agtype);
"""
# ==========================
# small_* 取数 SQL(单线程 keyset)
# ==========================
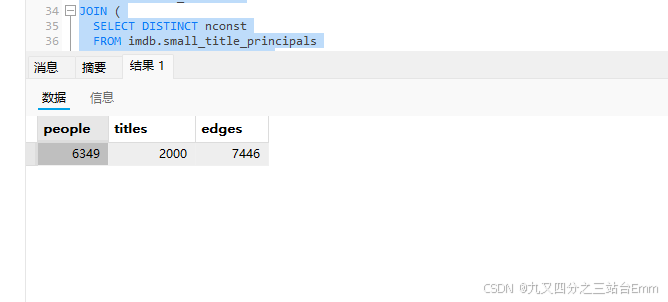
SQL_TOTAL_PERSON = "SELECT count(*) AS total FROM imdb.small_name_basics;"
SQL_TOTAL_TITLE = "SELECT count(*) AS total FROM imdb.small_title_basics;"
SQL_TOTAL_EDGE = "SELECT count(*) AS total FROM imdb.small_title_principals;"
SQL_SELECT_PERSON = """
SELECT nconst, primaryname, birthyear, deathyear, primaryprofession, knownfortitles
FROM imdb.small_name_basics
WHERE nconst > %s
ORDER BY nconst
LIMIT %s
"""
SQL_SELECT_TITLE = """
SELECT tconst, titletype, primarytitle, originaltitle, isadult, startyear, endyear, runtimeminutes, genres
FROM imdb.small_title_basics
WHERE tconst > %s
ORDER BY tconst
LIMIT %s
"""
SQL_SELECT_EDGE = f"""
SELECT tconst, nconst, ordering, category, job, characters
FROM imdb.small_title_principals
WHERE (tconst, nconst, ordering) > (%s, %s, %s)
{"AND category IN ('actor','actress')" if ONLY_ACTORS else ""}
ORDER BY tconst, nconst, ordering
LIMIT %s
"""
def make_payload(rows) -> str:
return json.dumps({"rows": rows}, ensure_ascii=False)
def init_session(cur):
cur.execute("SET search_path = ag_catalog, imdb, public;")
if SYNC_COMMIT_OFF:
cur.execute("SET synchronous_commit = off;")
def fetch_total(cur, sql_total: str) -> int:
cur.execute(sql_total)
return int(cur.fetchone()["total"])
def exec_with_retry(cur, conn, sql_cypher: str, payload: str):
last_err = None
for attempt in range(1, RETRY + 1):
try:
cur.execute(sql_cypher, (payload,))
conn.commit()
return
except Exception as e:
conn.rollback()
last_err = e
time.sleep(min(0.5 * attempt, 2.0))
raise last_err
def load_people(cur, conn):
total = fetch_total(cur, SQL_TOTAL_PERSON)
last = ""
done = 0
t0 = time.time()
with tqdm(total=total, desc="Person (single)", unit="rows", dynamic_ncols=True) as pbar:
while True:
cur.execute(SQL_SELECT_PERSON, (last, BATCH_PERSON))
batch = cur.fetchall()
if not batch:
break
rows = [dict(r) for r in batch]
exec_with_retry(cur, conn, SQL_PERSON_CYPHER, make_payload(rows))
last = rows[-1]["nconst"]
done += len(rows)
pbar.update(len(rows))
elapsed = time.time() - t0
print(f"[Person single] DONE {done}/{total} elapsed={elapsed:.1f}s rate={done/elapsed:.0f} rows/s")
def load_titles(cur, conn):
total = fetch_total(cur, SQL_TOTAL_TITLE)
last = ""
done = 0
t0 = time.time()
with tqdm(total=total, desc="Title (single)", unit="rows", dynamic_ncols=True) as pbar:
while True:
cur.execute(SQL_SELECT_TITLE, (last, BATCH_TITLE))
batch = cur.fetchall()
if not batch:
break
rows = [dict(r) for r in batch]
exec_with_retry(cur, conn, SQL_TITLE_CYPHER, make_payload(rows))
last = rows[-1]["tconst"]
done += len(rows)
pbar.update(len(rows))
elapsed = time.time() - t0
print(f"[Title single] DONE {done}/{total} elapsed={elapsed:.1f}s rate={done/elapsed:.0f} rows/s")
def load_edges(cur, conn):
total = fetch_total(cur, SQL_TOTAL_EDGE)
last_t, last_n, last_o = "", "", -1
done = 0
t0 = time.time()
with tqdm(total=total, desc="Edge (single)", unit="rows", dynamic_ncols=True) as pbar:
while True:
cur.execute(SQL_SELECT_EDGE, (last_t, last_n, last_o, BATCH_EDGE))
batch = cur.fetchall()
if not batch:
break
rows = [dict(r) for r in batch]
exec_with_retry(cur, conn, SQL_EDGE_CYPHER, make_payload(rows))
last_t = rows[-1]["tconst"]
last_n = rows[-1]["nconst"]
last_o = rows[-1]["ordering"]
done += len(rows)
pbar.update(len(rows))
elapsed = time.time() - t0
print(f"[Edge single] DONE {done}/{total} elapsed={elapsed:.1f}s rate={done/elapsed:.0f} rows/s")
def main():
with psycopg.connect(DSN, row_factory=dict_row) as conn:
with conn.cursor() as cur:
init_session(cur)
print("== small single-thread loader ==")
print(f"RUN_STAGE={RUN_STAGE} sync_commit_off={SYNC_COMMIT_OFF} retry={RETRY}")
print(f"BATCH person={BATCH_PERSON} title={BATCH_TITLE} edge={BATCH_EDGE}")
print(f"ONLY_ACTORS={ONLY_ACTORS}")
if RUN_STAGE in ("PERSON", "ALL"):
load_people(cur, conn)
if RUN_STAGE in ("TITLE", "ALL"):
load_titles(cur, conn)
if RUN_STAGE in ("EDGE", "ALL"):
load_edges(cur, conn)
print("== done ==")
if __name__ == "__main__":
main()