🍋🍋AI学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
一、为什么需要多模态检索增强生成?
随着大语言模型(LLMs)的快速发展,像 GPT-4 和 LLaMA 这样的模型在许多自然语言处理任务中展现了强大的能力。然而,这些模型常常面临"幻觉"问题,即生成不可靠或不准确的回答。为了解决这一问题,检索增强生成(RAG)技术应运而生。RAG 通过将外部知识与大语言模型结合,显著减少了幻觉现象。
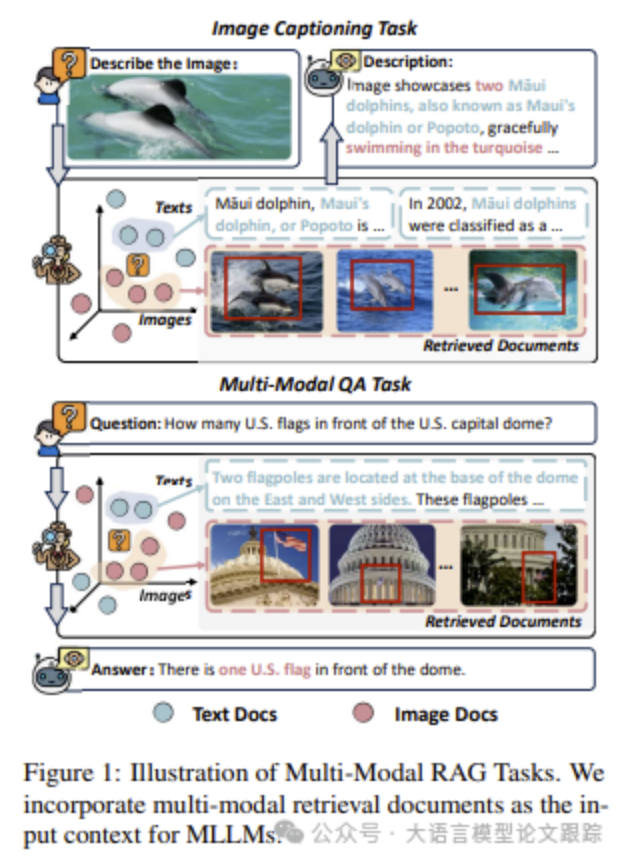
然而,现有的 RAG 方法主要依赖于文本检索,忽略了多模态数据(如图像和文本结合)在提供更丰富、更全面信息方面的潜力。多模态数据能够为模型提供更全面的上下文,从而生成更准确的回答。因此,研究多模态检索增强生成(Multi-Modal RAG)变得尤为重要。
Agentic RAG 已从概念走向标准化架构 。最新系统普遍采用"规划-检索-验证-反思"四阶段工作流:用户查询首先由规划器拆解为子任务(如"查政策 + 算费用 + 生成建议"),每个子任务交由专用检索 Agent 执行,结果经验证器(Verifier)自动校验(如比对权威文档或执行逻辑规则),若置信度不足则触发反思机制生成新查询重新检索。微软在 2025 年 10 月开源的 GraphRAG 2.0 引入动态子图裁剪,仅加载与当前任务相关的知识子图,将 70B 模型下的多跳推理延迟降低 60%;而阿里 RAGFlow 则在 11 月推出 Memory-Augmented RAG,将用户历史交互自动聚类为长期记忆节点,嵌入知识图谱,实现跨会话上下文感知。
二、什么是M²RAG和MM-RAIT
M2RAG(Multimodal Retrieval-Augmented Generation)基准是一个专门设计用于评估多模态大语言模型(MLLMs)在检索增强生成任务中表现的综合性基准。

M²RAG 包含四个任务:图像描述、多模态问答、多模态事实验证和图像重排序。这些任务都设置在开放域环境中,要求 RAG 模型从多模态文档集合中检索与查询相关的信息,并将其作为输入上下文用于生成回答。
为了增强 MLLMs 在利用多模态上下文方面的能力,研究者还提出了多模态检索增强指令调优(MMRAIT)方法。MMRAIT 通过在多模态上下文中优化 MLLMs,显著提升了 RAG 系统的性能。实验表明,经过 MMRAIT 训练的模型在零样本和少样本设置下均表现出显著提升。
目前,本项目以开源:https://github.com/NEUIR/M2RAG
多模态 RAG(MM-RAG)完成从"伪多模态"到"原生多模态"的跃迁 。早期方案仅将图像转为文本描述存储,信息损失严重;而 2025 年底的新范式采用统一多向量索引 :文本用 BGE-M3 编码,图像用 SigLIP 或 ColPali 提取 patch-level 向量,视频则通过时序池化生成关键帧向量组,所有模态向量存入支持多向量召回的数据库(如 Infinity 0.8)。查询时,系统自动识别输入模态(如用户上传一张发票图片),并激活对应检索路径------视觉语言模型(VLM)解析图像内容生成结构化查询,再联合文本与图像向量进行混合检索。Google 在 12 月发布的 M-Retriever 进一步引入跨模态对齐损失,在训练阶段强制文本与对应图像区域的向量距离拉近,使电商场景下的图文匹配准确率提升 34%。
RAG 基础设施发生底层重构 。传统 FAISS/Milvus 仅支持单向量,难以应对复杂文档(如含表格、公式、图表的 PDF)。2025 年 Q4 的解决方案是分层混合索引 :文档被 DeepDoc 或 MinerU 解析为语义块(段落)、结构块(表格单元格、公式 LaTeX)和元数据(页码、章节),每类块使用最适合的编码器(如 MathBERT 处理公式),并分别建立稠密向量、稀疏向量(SPLADE)和全文索引(BM25)。查询时,系统根据问题类型动态加权三种召回结果------事实问答侧重稠密向量,关键词定位依赖 BM25,模糊语义匹配则融合稀疏与稠密信号。OpenAI 收购 Rockset 后推出的 Hybrid Search Engine v2 已支持三路召回结果的实时重排序,延迟控制在 50ms 内。
三、多模态RAG测评结果
首先评估了多模态大语言模型(MLLMs)在M2RAG基准测试中的表现。随后,通过消融实验分析了不同模态和数量的检索文档对RAG模型性能的影响。最后,探讨了不同检索模态在RAG模型中的作用,并通过案例研究进一步验证了模型的性能。
3.1 总体性能
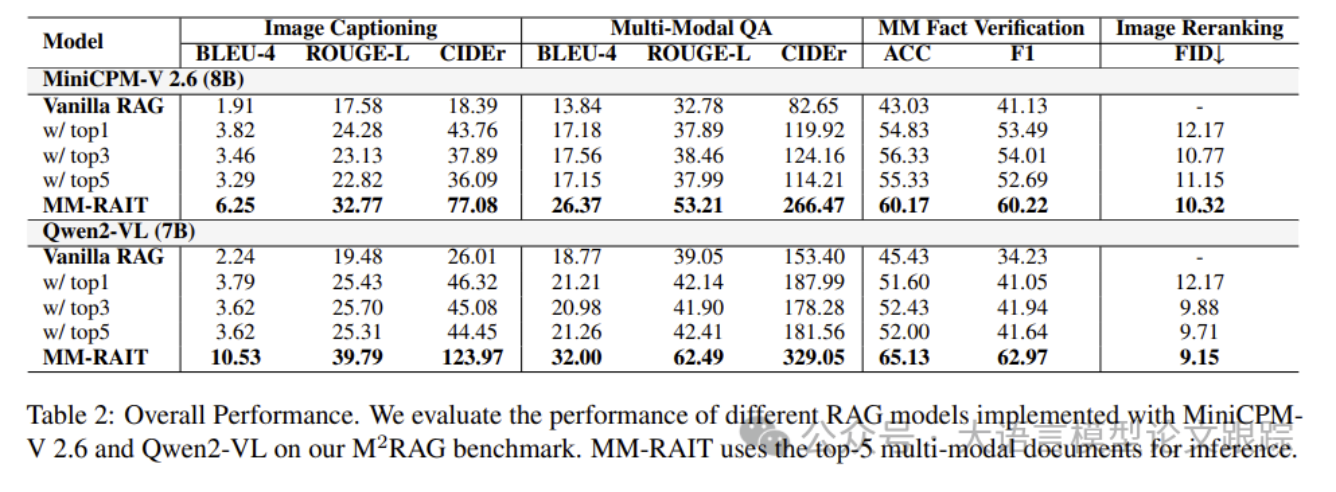
如上表所示,Vanilla RAG模型直接使用检索到的文档来增强LLMs,而MM-RAIT模型则在RAG框架内对MLLMs进行微调。
对于Vanilla RAG模型,随着检索文档数量的增加,性能通常有所提升。然而,当检索到排名靠后的文档时,Vanilla RAG模型在大多数任务上的整体性能相比使用top-1或top-3文档时有所下降。这表明Vanilla LLMs仍然难以充分利用多模态知识来增强MLLMs。
相比之下,经过MM-RAIT训练的MiniCPM-V 2.6和Qwen2-VL在M2RAG基准测试的所有任务中均表现出色。具体而言,MiniCPM-V 2.6在M2RAG的所有任务中平均提升了27%以上,而Qwen2-VL则表现出更大的提升,达到了34%。这些结果表明了MM-RAIT的有效性,展示了其帮助MLLMs更好地利用多模态上下文以提升性能的能力。
3.2 消融实验
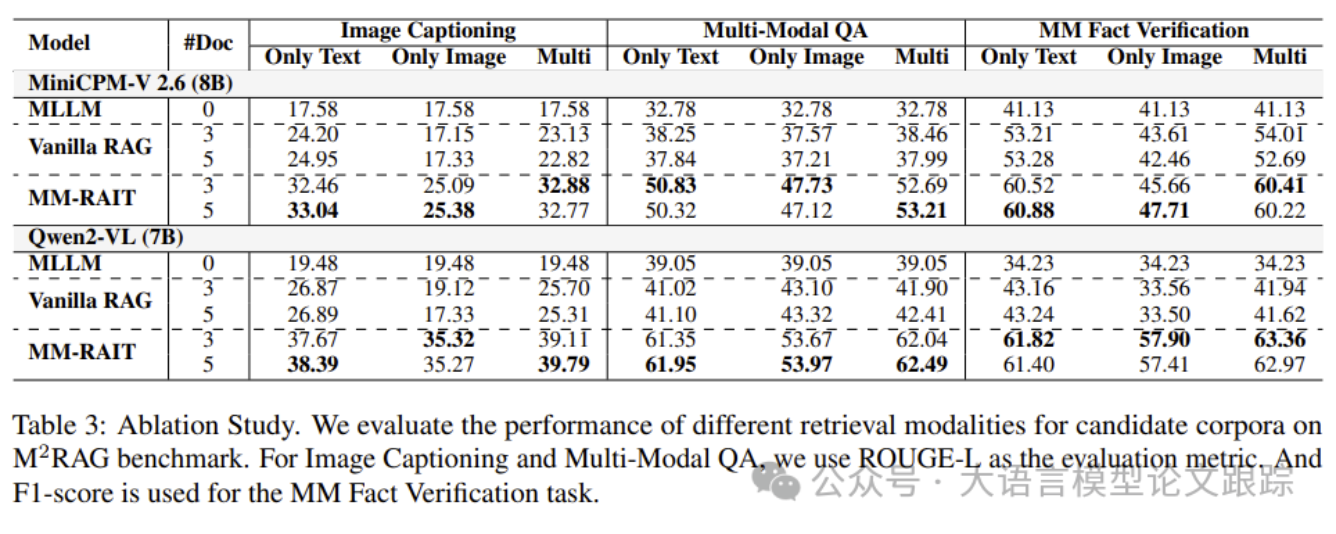
如上表所示,通过消融实验评估了不同模态和数量的检索文档对RAG模型性能的影响。设置了两种评估场景:仅文本(Only Text)和仅图像(Only Image)。
- • 仅文本表示从多模态输入上下文中移除所有图像特征以增强MLLM
- • 仅图像则移除所有文本。
与使用top-3多模态文档的RAG模型相比,Vanilla RAG模型在使用top-5文档时性能通常有所下降,而MM-RAIT虽然缓解了性能下降,但提升有限。表明现有MLLMs在有效利用多模态上下文知识方面仍面临挑战。
此外,进一步移除所有文本或图像特征,以展示不同模态在RAG建模中的作用。对于所有任务,仅文本模型的RAG性能略有下降,表明这些文本是这些RAG模型的主要知识来源。添加图像特征后,RAG性能通常有所提升,表明这些图像特征可以提高RAG模型的性能。尽管不同模态在多模态RAG建模中显示出有效性,但MLLMs仍然难以从这些图像特征中学习到更关键的语义信息以提升RAG性能。
3.3 不同模态RAG场景中MLLMs的有效性
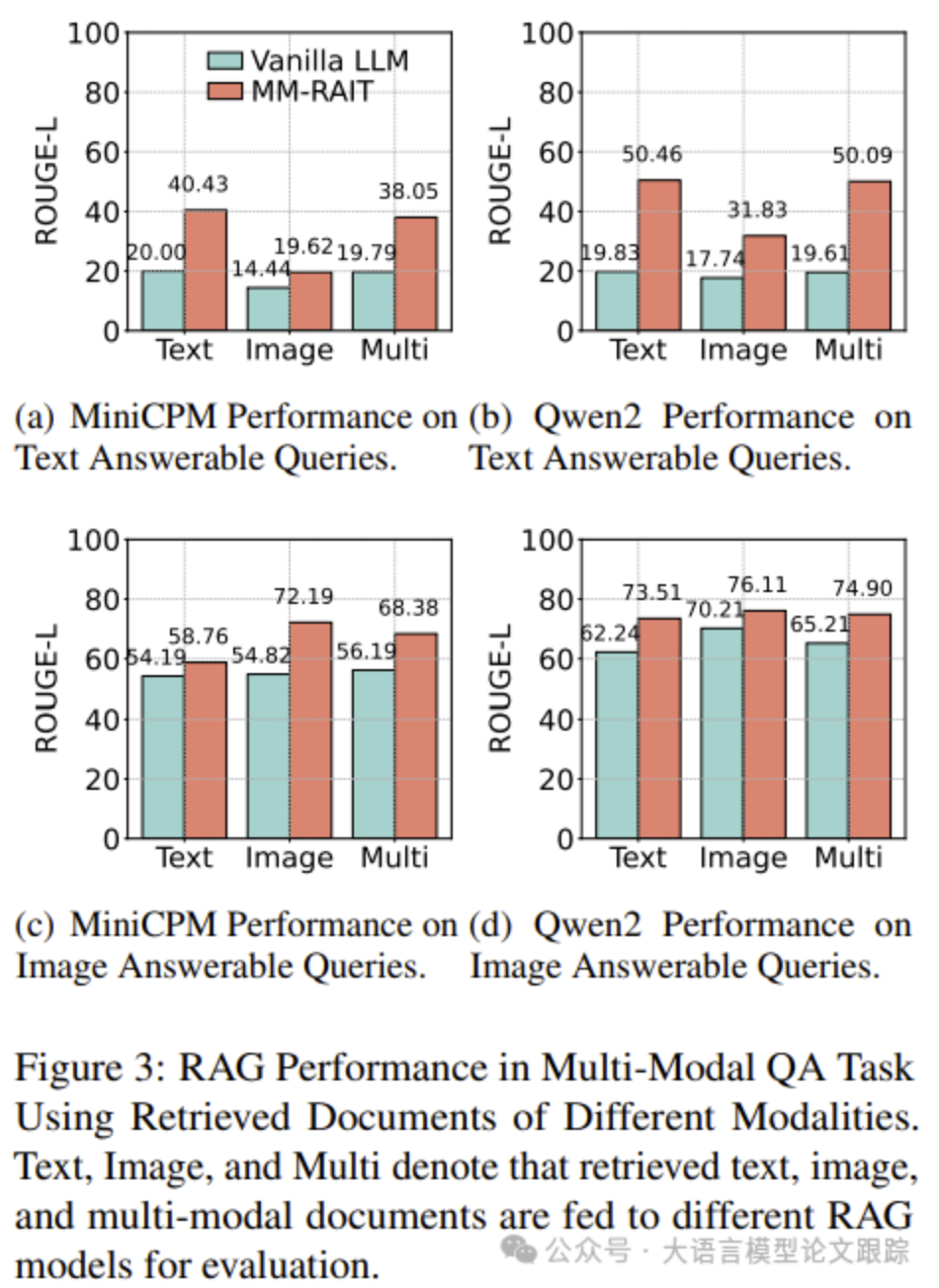
如上图所示,将M2RAG的多模态QA数据集分为两组:图像可回答查询和文本可回答查询。
分别表示可以通过图像或文本文档回答的查询。比较了使用MiniCPM-V和Qwen2-VL实现的Vanilla RAG和MM-RAIT模型。将来自文本、图像和两种模态的top-5文档输入到不同的RAG模型中,以评估QA性能。
图(a)和(b)展示了在文本可回答查询上的RAG性能。使用多模态检索文档的RAG模型与仅使用文本文档的模型表现相当,表明MLLMs能够有效地从文本文档中学习以回答查询。Vanilla RAG模型在使用文本、图像或两种类型的文档时表现差异不大,而MM-RAIT在利用多模态文档时显著提升了性能。
表明MM-RAIT在帮助MLLMs从多模态上下文中学习方面非常有效。有趣的是,Vanilla MLLMs对检索到的上下文似乎不敏感,这可能是因为它们在处理文本可回答查询时严重依赖内部知识。
接下来,评估了在图像可回答查询上的RAG性能,如图(c)和(d)所示。结果表明,使用多模态文档的RAG模型通常优于仅使用文本文档的模型,证实了在检索过程中加入图像文档能够增强MLLMs回答问题的能力。Qwen2-VL的性能差距较小,表明不同的MLLMs对多模态文档的依赖程度不同。