本章目标
1.程序地址空间回顾
2.虚拟地址
3.进程地址空间(描述)
1.程序地址空间回顾
在语言层面上,我们提及到堆,栈,常量区,静态区,并且会将他们划分到不同的区域.
我们从以下面位低地址,上面位高地址来看的话.
在语言层面上我们的程序地址空间会按照如下划分
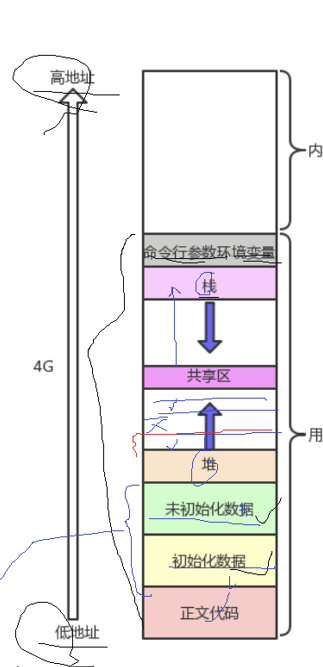
这个图简化了很多,在代码段和全局数据区之间还要一个常量区,在未初始化数据区和初始化数据区之间还存在一个静态区.
一般来说每一个进程这块空间,一般是会给到一个4g的大小,3g作为用户区,1g作为内核区.在这里面我们没见过的共享区这一般数存放动态库的数据和代码的,我们在后面的章节会详细介绍.
我们下面给一段代码详细的验证一下这个过程
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
static int test = 10;
printf("code addr: %p\n", main);
printf("read only string addr: %p\n", str);
printf("init global addr: %p\n", &g_val);
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("uninit global addr: %p\n", &g_unval);
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
//for(int i = 0 ;i < argc; i++)
//{
//printf("argv[%d]: %p\n", i, argv[i]);
//}
//for(int i = 0; env[i]; i++)
//{
//printf("env[%d]: %p\n", i, env[i]);
//}
return 0;
}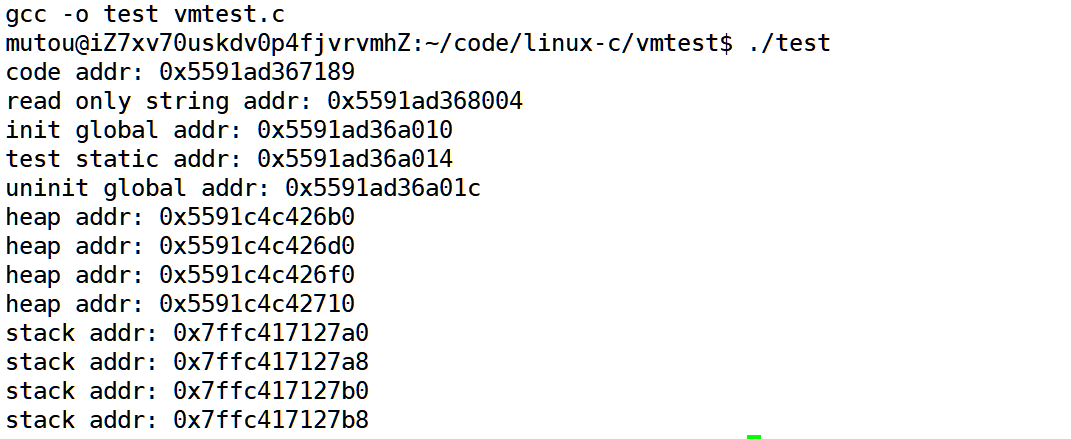
我们从低地址向高地址打我们可以看到从代码段到栈区的地址都是从小到大的.
但是实际上我们的栈是从高地址向低地址生长的,这个说法没有错,但是这个规则实际上应用于全局的栈空间,我们这几个变量的地址是main函数的栈上,对于同一个栈的变量,它应该遵顼从小到大的规则.也就是它是向上增长的.这个规律和我们之前说进程组织的时候讨论Linux对于进程组织的时候是采用一种内嵌式链表的方式方便扩展的时候谈论过这个话题我们一个变量的地址是他开辟一个或多个字节中,最小的那个字节的地址.至于它可以通过这个地址可以向上访问多大的空间,具体要取决于数据类型.
堆,栈,他们两个的地址实际上是相对而生的.
堆从低地址向高地址生长
栈从高地址向低地址生长
但是对于局部的空间的使用,他们都是遵循从小的到大的方式进行使用.
2.虚拟地址
有关于虚拟地址我们之前讨论过,这个问题是出在fork的返回值通过同一个变量可以接受到连个不同的返回值,之前我们说是,当子进程对数据进行修改的时候是会发生写诗拷贝,从而实现了数据的分离的目的.但是我们当时并没有说,这个过程是如何具体实现的.
在今天我们就可以解决这个问题了.
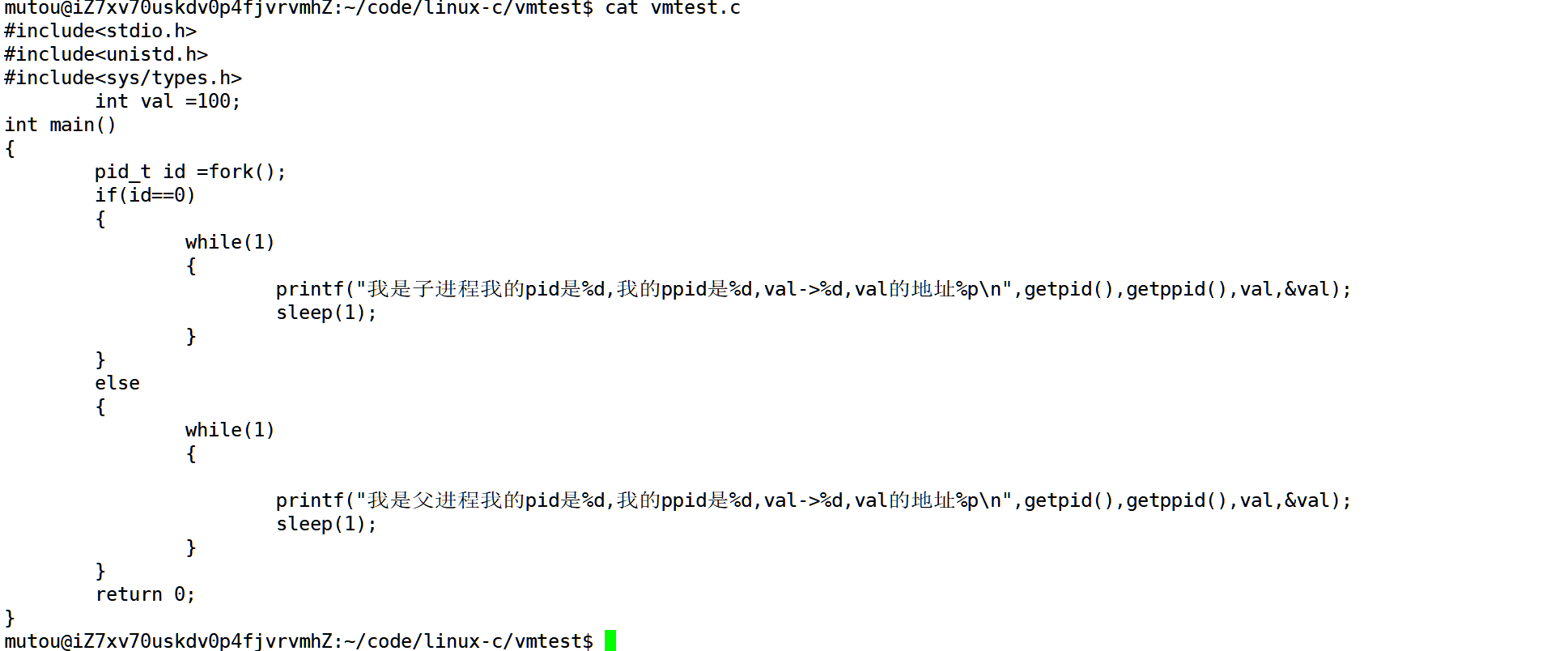

很正常的一段test,我们通过fork的返回值将父子进程进行分流.
我们查看一个全局变量的内容和地址同样正常,父进程会根据自身的task_struct为模板去创建一个子进程.同样它也就一定拿的到父进程的代码和数据.
但是我们进行在子进程让这个值进行自增,它会有什么变化?
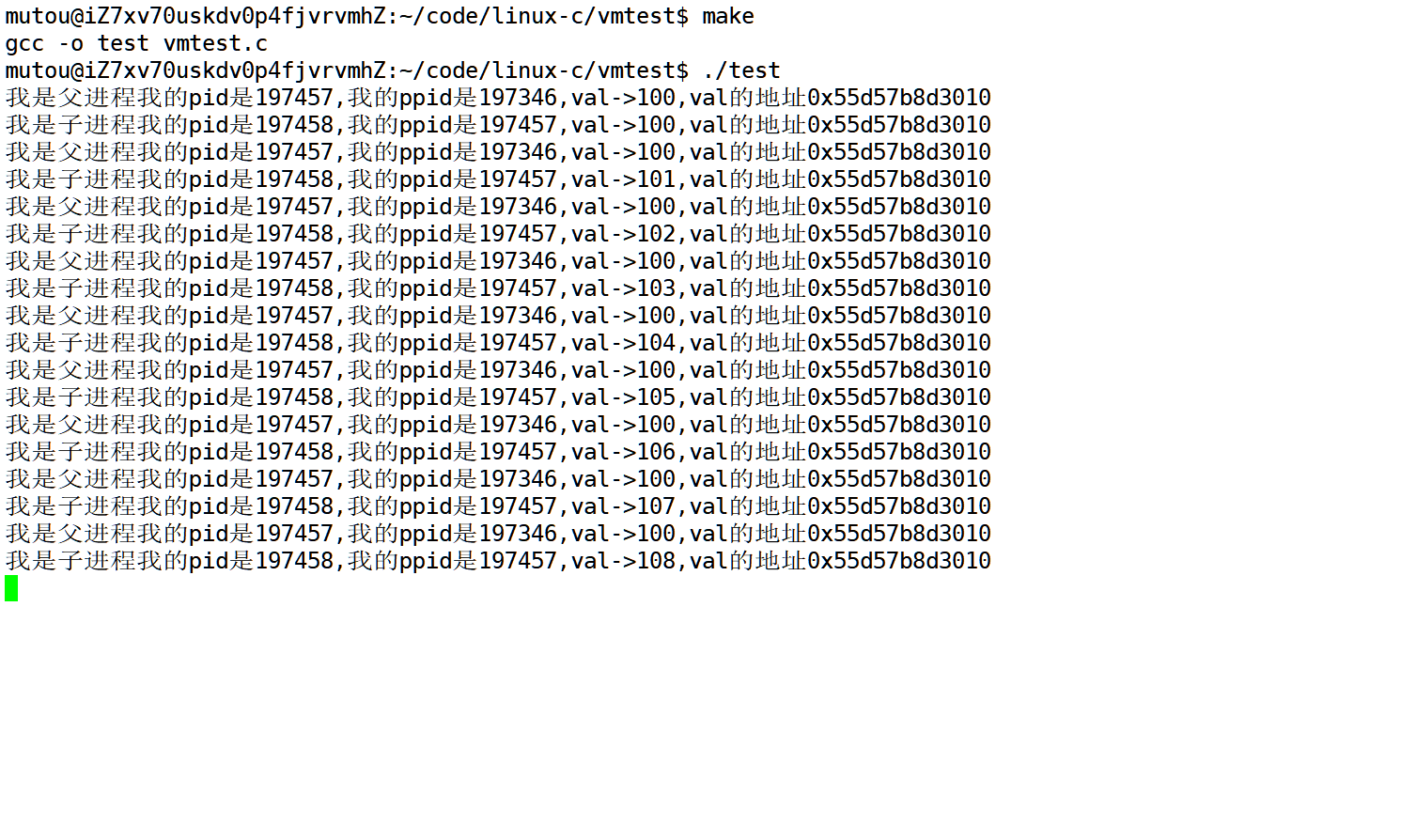
我们可以看到子进程的val变大了,而父进程的val并没有发生改变.
这个现象很好理解,因为数据被修改了.所以发生了进程进行了写时拷贝,实现了数据隔离.
但是这两个进程的val地址没有发生改变?
我们能够得出的第一个结论就是这个地址一定不是物理地址.
因为对同一个物理地址进行修改的话,父子进程一定会相互发生影响.
而这个地址就是我们语言层面的上的指针.这个指针指向内容也一定不是物理地址.
实际上它是虚拟地址,而真正物理地址,我们一般是看不到的.这部分是被我们操作系统所隐藏起来的.
3.进程地址空间(描述)
我们前面所提及的程序地址空间这种说法实际上是不准确的,为了方便我们的进程能够找到操作系统,它实际上还要一部分要作为内核区域.
实际上我们应该叫它进程地址空间,虚拟地址空间,虚拟内存.
我们下面所提及的情况全部都是32位操作系统的情况.对于64位操作系统.我们的进程地址空间他大了.
我们虚拟地址空间实际上一段从0x00000000,到0xffffffff,的一块地址空间,它可以表达的大小是2的32次方,2的十次方是1024kb,32次方实际上是4个g的大小,这4个g的空间会将1个g分给内核,3个g分给用户.
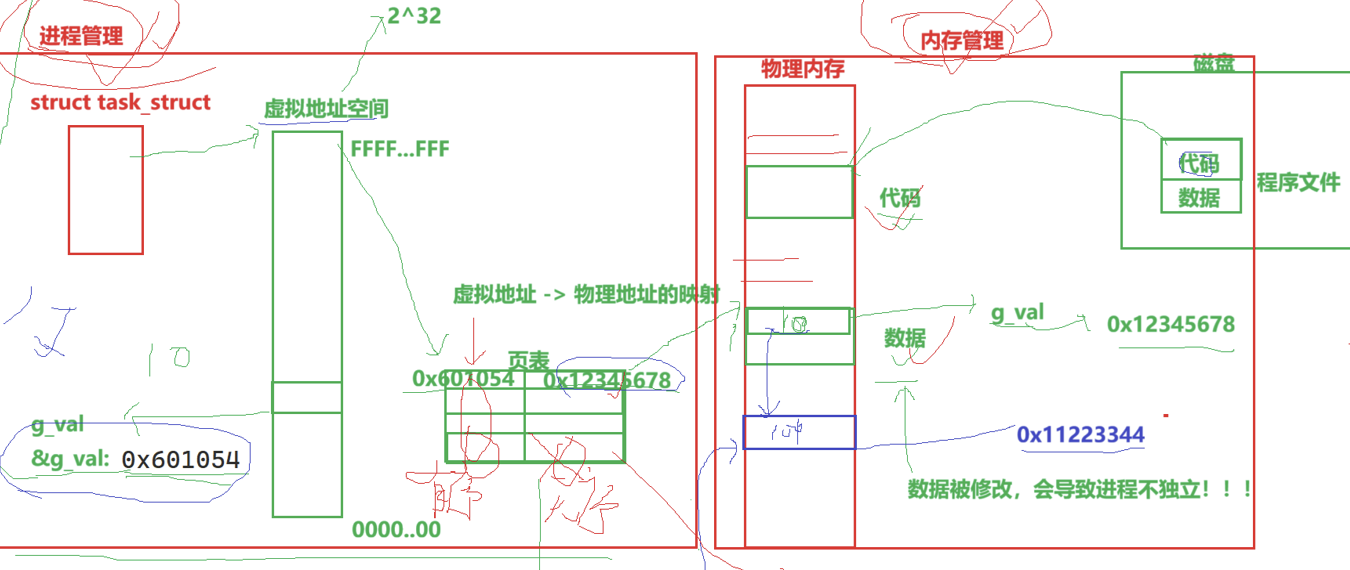
当我们的二进制程序被执行,他会先创建自身的pcb在Linux当中也就是task_struct.
创建出来,当程序的被调用时候,通过一个叫做页表东西将虚拟地址转化为物理地址,然后将自身的代码和数据加载到内存当中.这个虚拟地址是在程序启动前就已经确定了.它的具体实现是在程序编译的时候就已经确定.这个过程当中,物理地址是不确定的,而虚拟地址是确定的.这个东西具体是怎么玩的我们在后面具体介绍页表的时候再说.
当我们创建子进程的时候,我们父进程会以自身为蓝本,创建子进程,子进程自然也就拿到了父进程的虚拟地址空间的大部分东西以及页表.
这个页表现在我们可以简单的理解成
它的左边是虚拟地址,右边是物理地址.
我们子进程自然也就要拿到这个页表,这个变量的虚拟地址,当他进行修改的时候,我们的子进程发现它的页表已经存在了一个物理地址,在这里,为了保证进程间的独立性,也就是要发生写时拷贝.进行数据隔离,在内存中,真正的物理内存中开辟一段空间.并把它的地址重新填回变量的页表的物理地址项,这样我们也就实现了虚拟地址相同,而物理地址不同.也就是出现了这个现象
对于虚拟内存这个系统,始终记住,虚拟地址一开始就已经确定了,而物理地址时根据实际进行分配的.
什么叫做虚拟地址空间
我们在前面大概介绍虚拟到物理的转化,以及为什么同一个地址为什么可以存在两个不同的值.那么我们并没有理解什么是虚拟地址空间.
举个例子,我们的操作系统有16g的物理内存资源,在这个os下面跑着多个进程,在当前os我们假定是32位的,那个一个进程创建task_struct的同时,也要开一个4g大小的空间供该进程使用.然而这是不现实的,我们如果只按4g进行在物理内存当中开辟空间,那么我们在内存里跑的进程实际上并不会多过4个.为了让多个进程同时运行,那么就需要按需分配,这4个g实际上是os给进程画的饼,是它最多能开到4个g,并不是一次性给它4个g的空间.但是对于大量进行都需要虚拟内存,而他们需求量都不同,就需要将他们的信息进行管理.为了管理信息,就需要将其进行描述.对应到操作系统当中就是用结构体将其进行描述.
我们可以看一眼他们在内核当中的结构,这部分的内容一般是存储在task_struct当中的.里里面通过一个指针指向这部分的内容
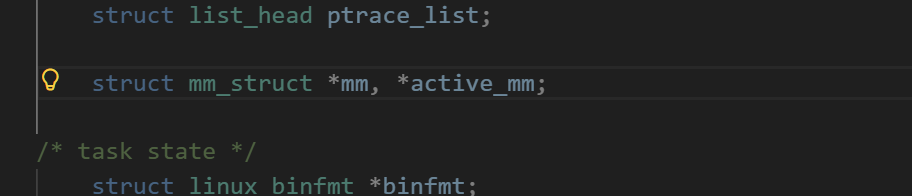
这个结构体的名称就叫做mm_struct,全称可以理解成memory manage struct,也就是内存管理实际上的学名叫做内存描述符
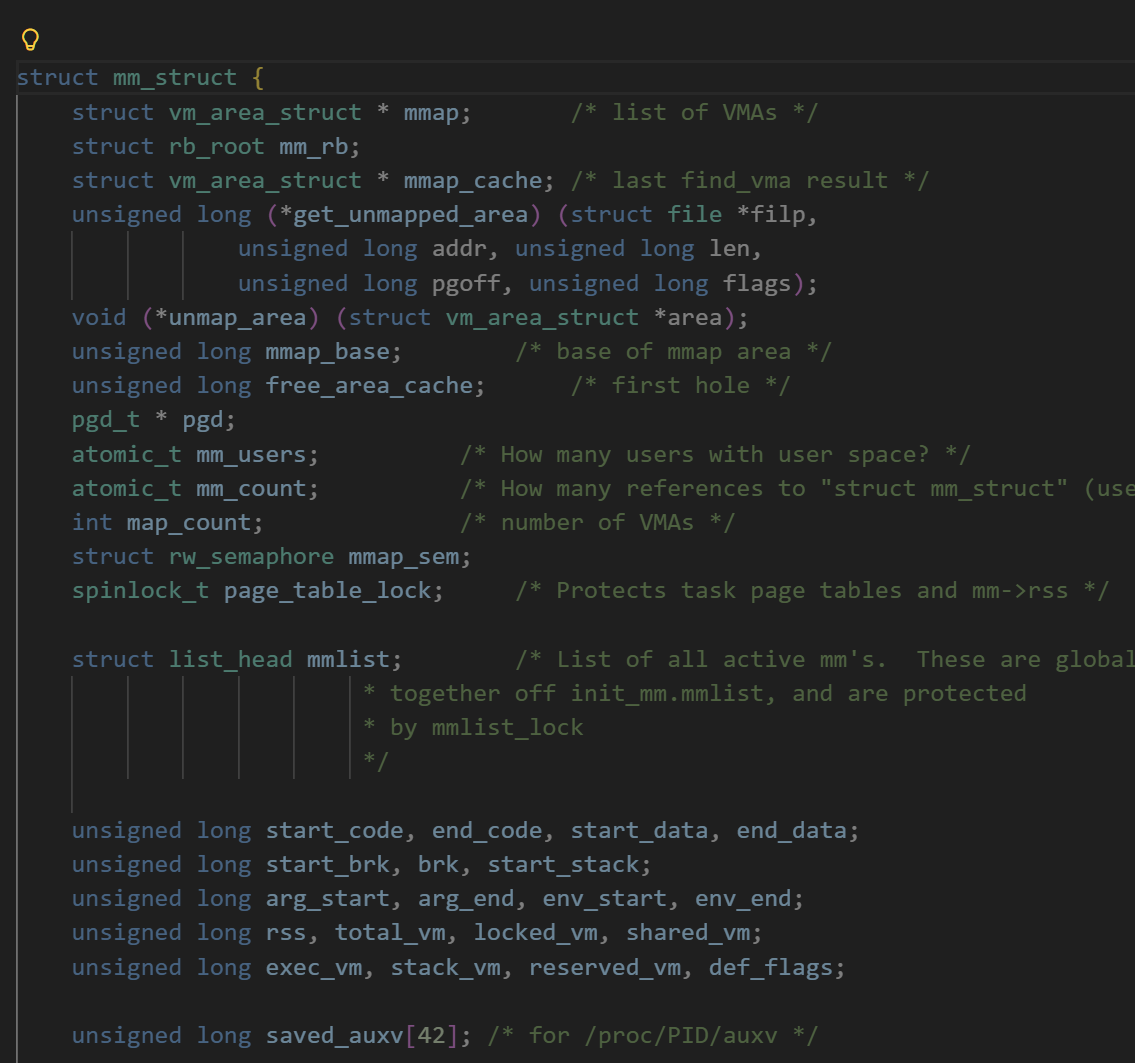
对于一个内核数据结构它最重要的就是描述信息,而对于mm_struct这个结构,它所描述的就是这个虚拟地址空间是如何进行划分的,
如何理解区域划分
对于内存在区域中是如何进行划分的,它是通过一个start和end指针决定的,因为指针的内容是一个地址,我们也可以通过一个无符号长整形变量来进行存储,
我们可以假设我们有一个100个单位的空间,我们只有两个区域进行划分,代码段和数据段.我们给start_code值设为1,end_code的值设为50,start_data的值设为51,end_data的值设为100,在1-50的内容对于代码段来说它可以任意使用,而对于51-100的内容对于数据段,它同样可以任意使用.
我们用两个变量就描述一个区域具体的大小,这样做的好处除了节省内存,它还方便动态进行调整.我们只要给一个空间始末地址就可以调整,举个例子,就是我向给代码段1m的大小,我只要在代码段的起始地址上面+1024就可以得到它的终止地址.
什么是页表,查表的工作由谁来做
根据我们前面介绍,这个问题我们也不难回答,页表实际上就是虚拟地址到物理地址的一个映射机制.而查表的工作并不是由软件实现的.,这个工作是由硬件完成的.
具体到硬件来说,将虚拟地址转化到物理地址这个工作是通过一个MMU的组件来完成的,在当代的计算机当中,它是被集成到cpu当中的,它的全称,memory manage union,内存管理单元,这个查表的工作还要配合cpu当中的cr3寄存器.这个cr3寄存器放着页表的物理地址.
在这里也能够解答三个问题,
为什么常量字符串是只读的
实际上页表不单单是由虚拟地址和物理地址组成的,它还要很多标志位.在这里我们只要介绍两个就可以,其他的雷同

对于一个常量字符串我们一般在填页表的同时会给它的权限为设为r,这个东西一般是类似于位图的结构,只要表示01就可以表示是否存在.因为权限为只读,当我们对一个常量字符串进行修改的时候,一般来说,并不会成功.(可以通过强转的方式实现),会直接报错.
这个底层的原理就是因为只读从虚拟到物理的这个过程,mmu拒绝给你进行转化.
重新理解挂起
在前面我们说过一个进程如果没有被调用的情况下,它的代码和数据可以从内存唤出到磁盘的swap分区当中,当它重新需要被调度的时候再将它从swap分区进行一个换入.
这个过程对应到页表当中就是再页表对应项的是否存在的标志位挂0,如果为0就表示当前地址并不在内存中存在.当它被调度的时候,再重新分配一个物理地址填回到页表当中.
为什么静态变量的生命周期是全局的

对于一个静态变量,全局变量,对于它的作用域是全局的,我们并不难进行理解.
再前面我们进行验证一个静态变量的地址它是它已经初始化的全局数据区和未进行初始化的全局数据区之间的,对于一块虚拟内存来说,堆栈的空间是可能发生改变的.但是对于全局区,代码段,静态区和常量区,这部分是一个进程被创建的时候就已经确定的了.
只要这个进程没dead,它的生命周期就是随着进程的,那对于一个程序来说它就是全局的