文章目录
前言
TCP 是 传输控制协议 的简称,是作为UDP的对立面而设计的,解决了UDP无法满足的关键需求。它提供了一种面向连接的、可靠的通信方式
TCP协议
(1)核心特点
面向连接:
- 通信前必须通过"三次握手"建立可靠的逻辑连接,确保双方通信能力。
- 通信结束后需要通过"四次挥手"有序释放连接
- 优点:提供稳定的通信通道;缺点:增加延迟和开销
可靠传输:
- 保证交付:通过确认应答、超时重传、序列号等机制确保数据可靠到达,丢失会自动重传。
- 保证顺序:每个数据字节都有唯一序列号,接收端按序重组,保证数据流顺序。
- 拥塞控制:通过慢启动、拥塞避免等算法动态调整发送速率,避免网络过载,保障整体网络健康。
面向字节流:
- 发送端和接收端处理的是无边界的数据流,TCP 根据当前窗口和网络状况决定如何分段打包。
- 应用层写入的数据可能被 TCP 拆分成多个报文段发送,也可能将多个小数据合并发送。
- 接收端将数据按序重组为连续的字节流提交给应用层,不保留原始数据报边界。
头部开销大:
- TCP 头部至少 20 字节,包含序列号、确认号、窗口大小、标志位、校验和等丰富控制信息。
- 支持可选项,头部最长可达 60 字节,提供更精细的控制能力。
TCP支持全双工:
- 每个 TCP 连接都维护独立的发送缓冲区和接收缓冲区,允许双向数据同时传输。
- 发送缓冲区存放已发送但未确认的数据(可能重传)和待发送数据,其发送速率受接收方窗口和网络拥塞窗口共同制约。
- 接收缓冲区存放已到达但未被应用层读取的数据(包括乱序到达的数据),并通过窗口通告机制反馈给发送方以实现流量控制。
(2)TCP协议格式
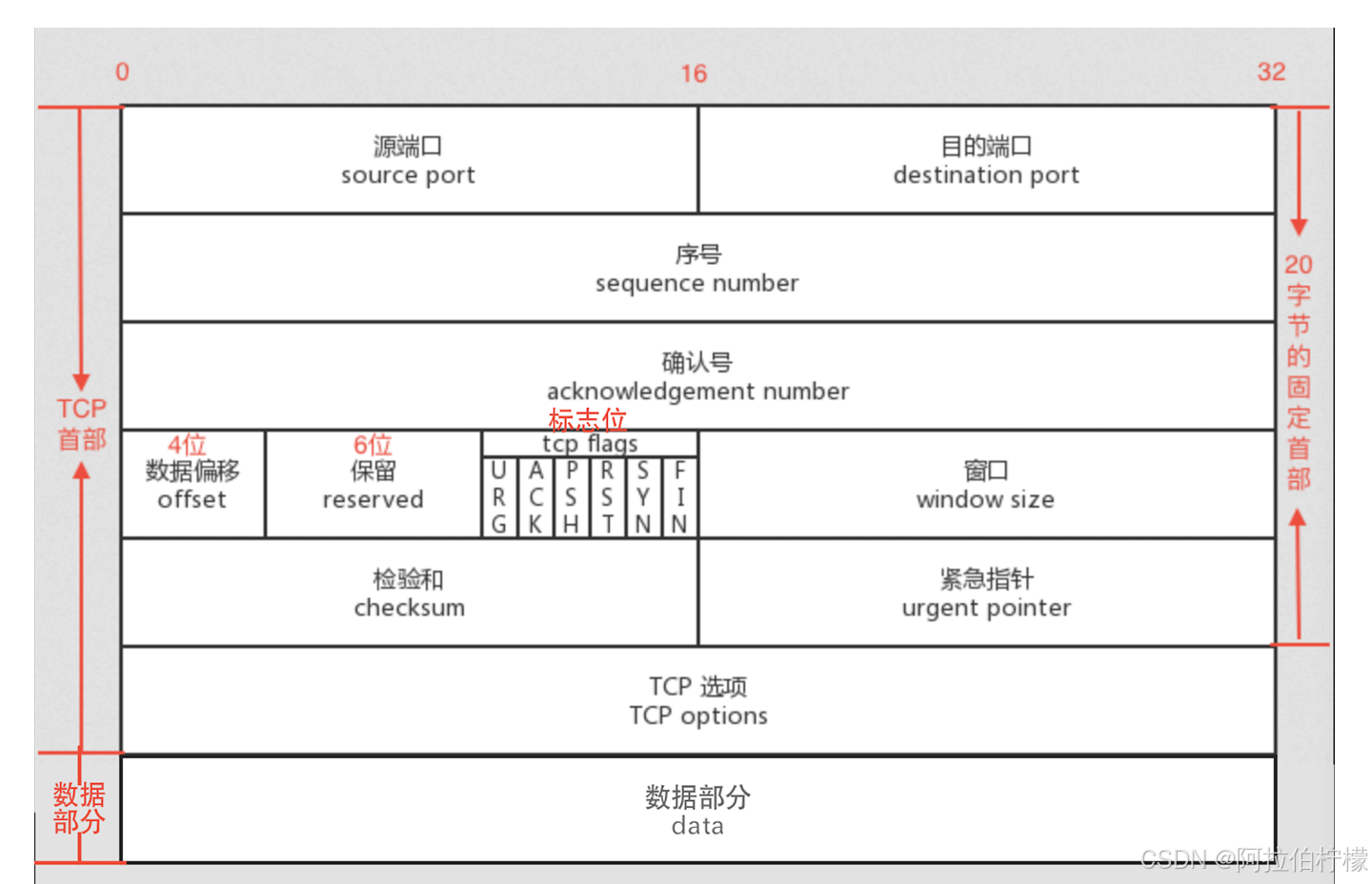
- 16位源端口号: 发送方应用程序的端口号
- 16位目的端口号: 接收方应用程序的端口号
- 32位序号: 本报文段所发送数据的第一个字节的编号
- 32位确认序号: 期望收到对方下一个报文段的第一个数据字节的编号
- 4位数据偏移(首部长度): 以4字节为单位 ,最小值为5(20字节),最大值为15(60字节),TCP头部最大长度是15 * 4 = 60字节, UDP报头中16位长度包含的是整个报文的长度 , UDP是面向数据报可以拿到整个数据,而TCP面向字节流,不对数据做解释,只是放到缓冲区中,因此不包含数据大小。
- 6位标志位:
URG: 紧急指针是否有效
ACK: 确认号是否有效
PSH: 提示接收端应用程序立刻从TCP缓冲区把数据读⾛
RST: 对方要求重新建立连接; 我们把携带RST标识的称为复位报文段
SYN: 请求建立连接; 我们把携带SYN标识的称为同步报文段
FIN: 通知对方, 本端要关闭了, 我们称携带FIN标识的为结束报文段 - 16位窗口大小: 接收窗口大小,用于流量控制
- 16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含
TCP首部, 也包含TCP数据部分. - 16位紧急指针: 标识哪部分数据是紧急数据,标识紧急数据在有效载荷中的偏移量
- TCP选项(可变长度) 可选字段,如最大报文段长度(MSS)、窗口扩大因子等
- 数据: TCP报文段承载的应用层数据
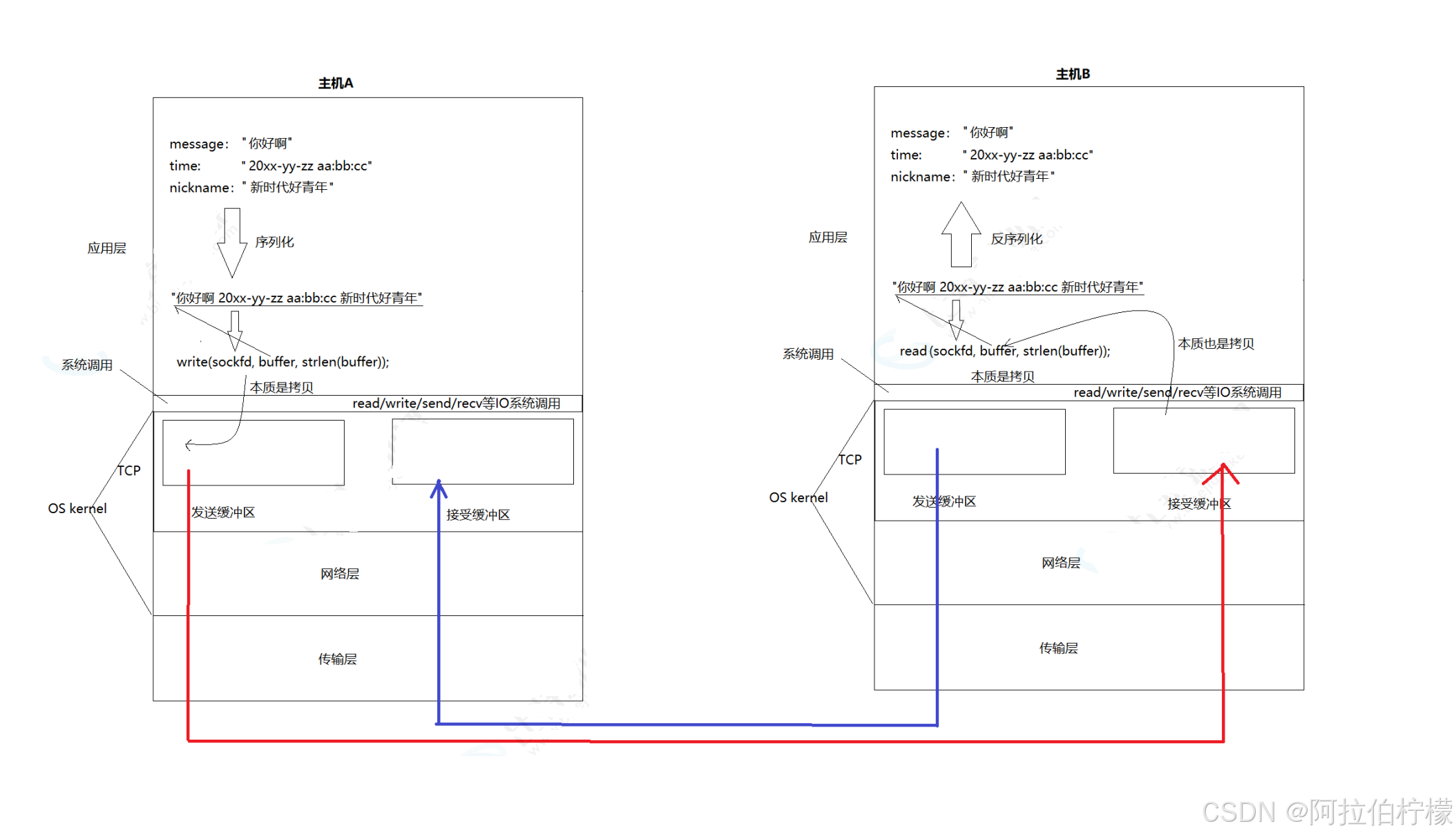
当数据包自底向上传递,传输层收到报文时:
TCP的解包:
先提取20字节固定首部长度 ,然后拿到4位首部长度字段 进而提取到整个报头 ,剩下的TCP有效载荷部分就是TCP的数据了。解包第一步只是提取结构,后续才会详细解析每个字段(序列号、确认序号、标志位等)。
TCP的分用:
先提取目的端口号 ,再查找对应的套接字 ,操作系统维护着一个套接字表,每个套接字绑定到一个特定的端口号。
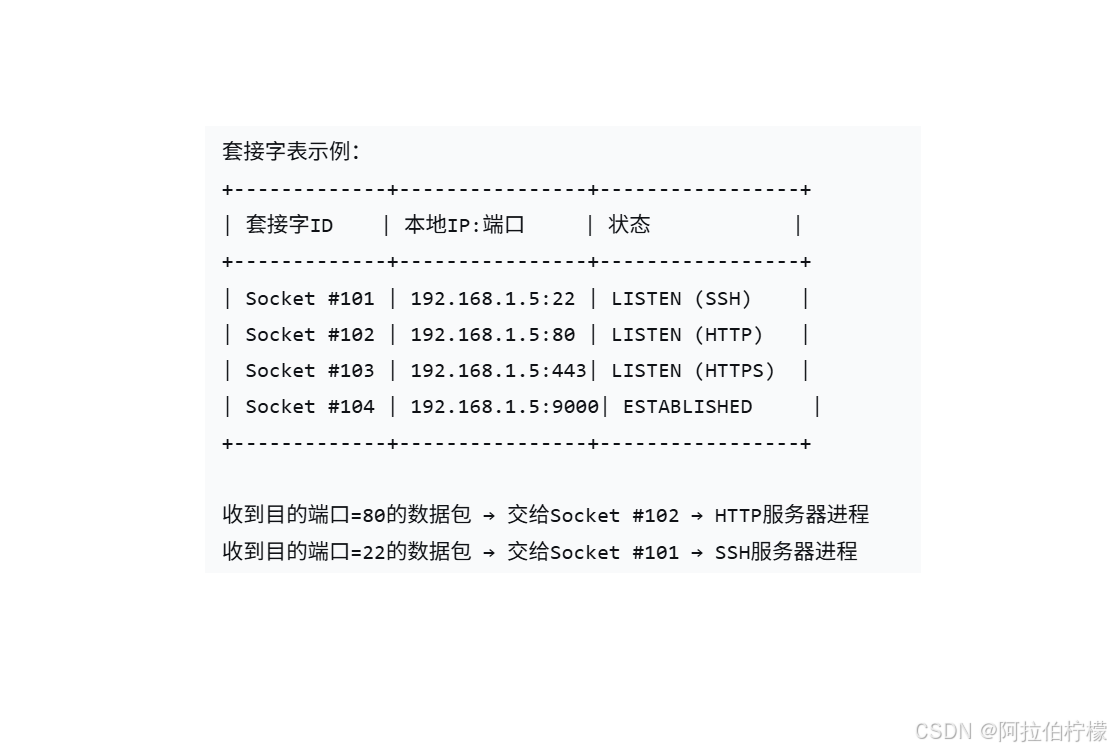
本地进程间通信不涉及数据丢失问题,数据都存在本地进程中,通过内存进行数据交互。
当数据跨网络传输时,就会存在很多问题,协议栈就是为了解决这些问题,而TCP就是其中最重要的一部分
关于TCP的可靠性:
(3)确认应答机制(ACK)

-
让server(接收方)收到报文不是目的,client(发送方)知道server收到报文才是目的 ,
因此需要server接收到数据后对client做一次应答 ,这样才能达成目的,如果client在⼀个特定时间间隔内没有收到server发来的确认应答, 就会进行重发---超时重传机制。当server向client发报文时同理。
-
当长距离通信时,不会有100%的可靠性,因为总会存在一条最新的消息没有应答 。但是对历史报文做到了100%的可靠性 ,这样我们的目的也就达到了,数据一定被对方收到。
-
确认应答至少是一个包含ACK的裸的TCP报头-----这里涉及捎带应答机制。
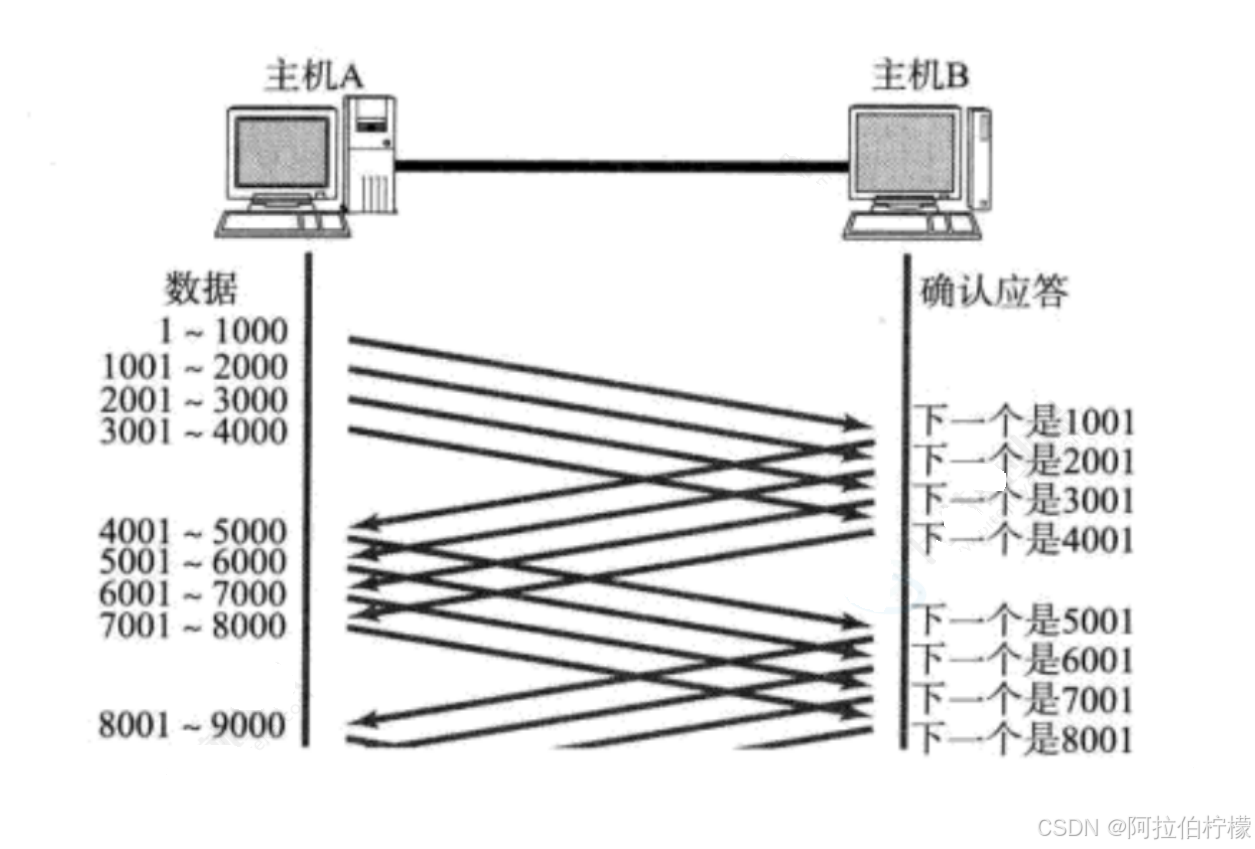
上面的串行化收发消息,效率低下,所以在实际传输过程中,一次性发送多个报文 ,一次性确认多个应答 才是TCP的真实的发送方式,给报文带上序号 ,就可以对其进行区分。
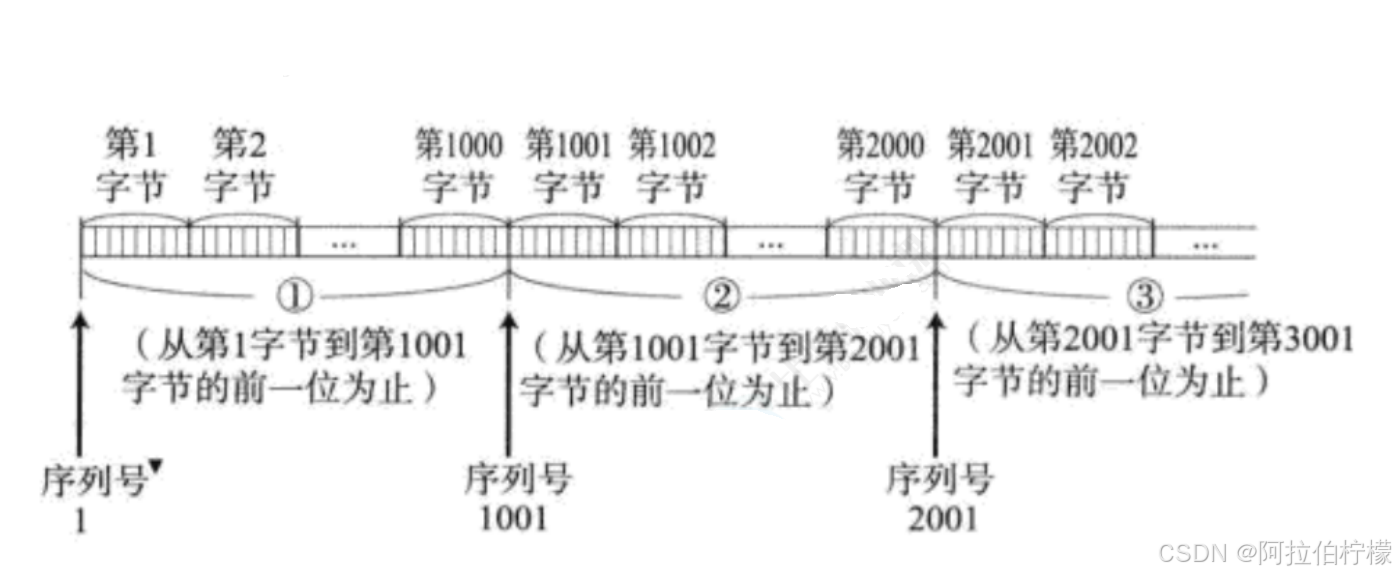
- 可以将缓冲区理解成一个定长数组 ,char outbufferN,数据将其填充并且编号,网络通信就是将A主机的发送缓冲区数组发送到B主机的接收缓冲区数组中,因此TCP是面向字节流。
每⼀个ACK报头都带有对应的确认序号 ,这样就能告诉发送方我接受到哪些信息,下一次你再从哪里开始发送
确认序号 = 序号 + 1 : 表示序号之前的内容我已经全部收到了
序号的意义 :保证报文的按序到达 。
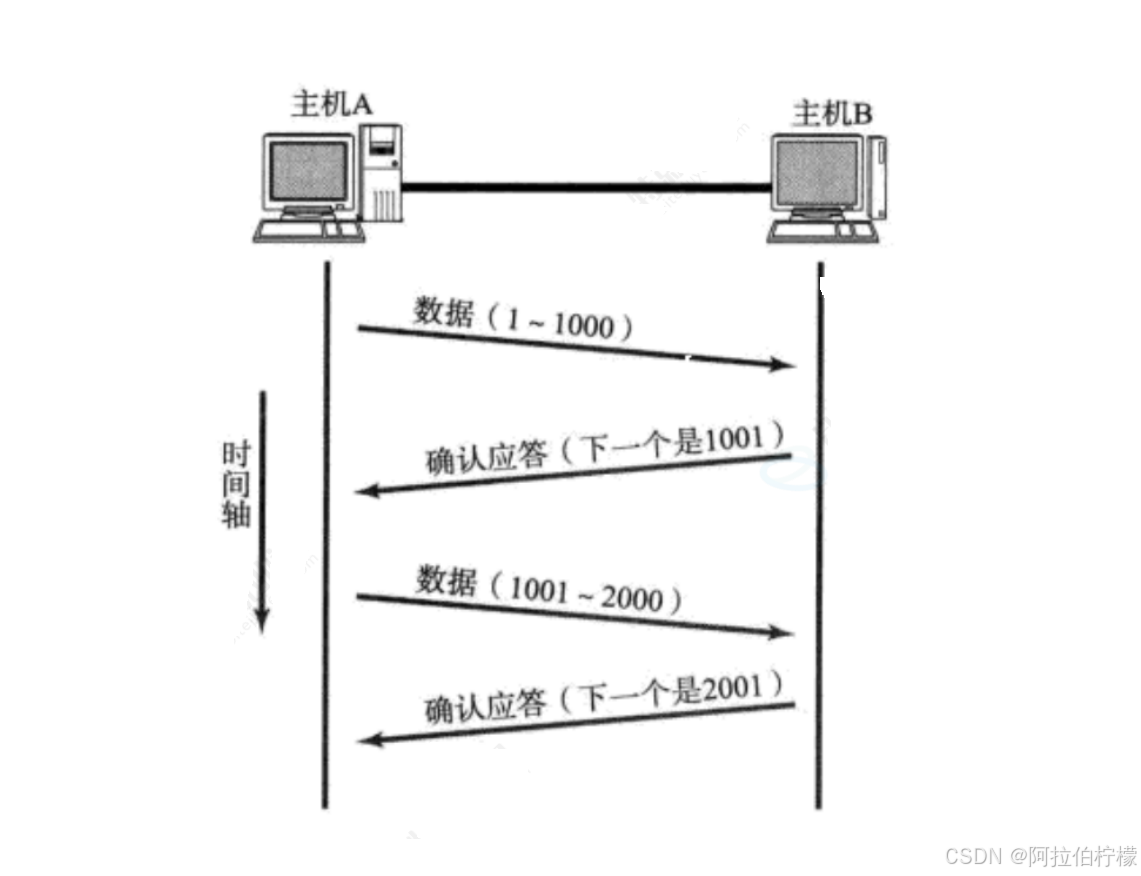
- 确认应答2001的含义是数据2000之前的都收到了
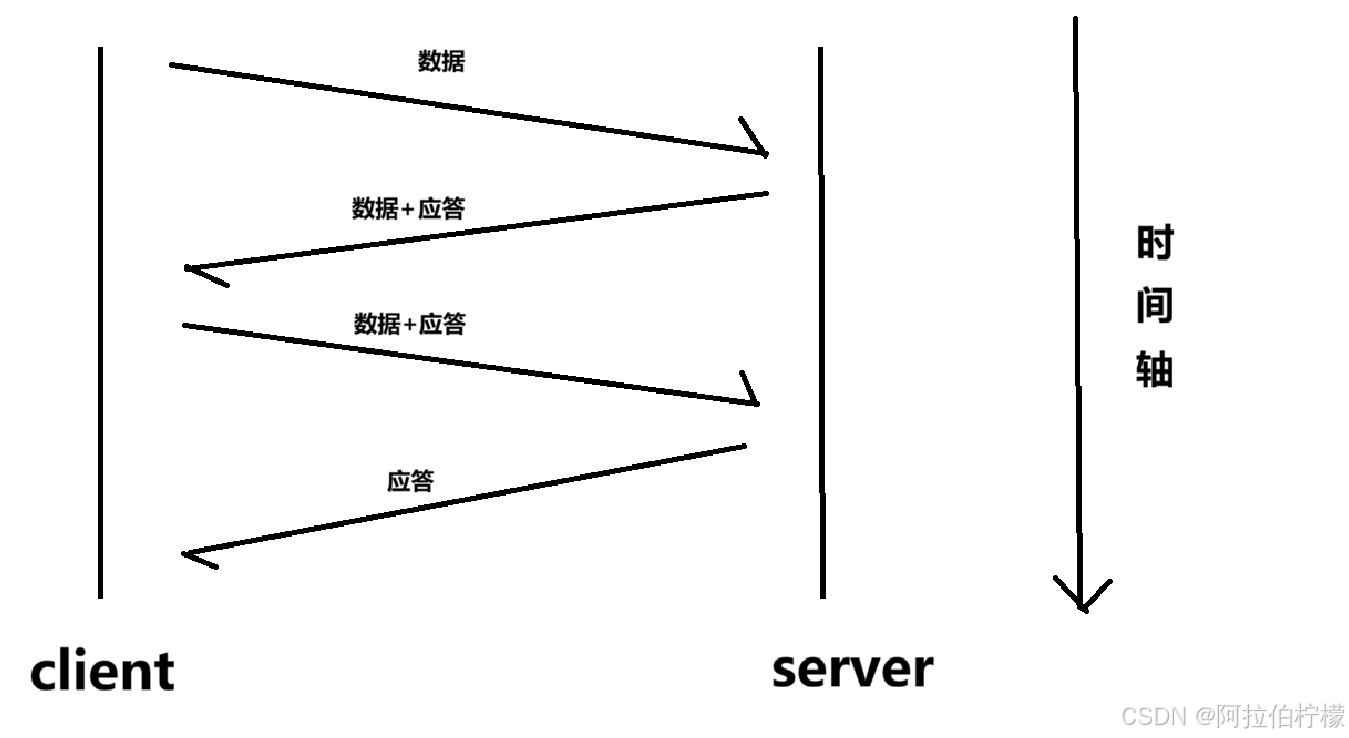
(4)捎带应答机制
为什么在报头中存在两个序号(序号与确认序号) ?
-
TCP是全双工协议,通信双方同时具有发送和接收数据的能力
-
TCP报文在很大概率上,既是应答,也是数据 ,所以报头中序号与确认序号需要同时存在。
(5)超时重传机制
数据丢失的两种情况:
1.数据发送失败:
- 主机A发送数据给B之后, 可能因为网络拥堵等原因, 数据无法到达主机B;
- 如果主机A在⼀个特定时间间隔内没有收到B发来的确认应答, 就会进行重发
2.数据应答失败:
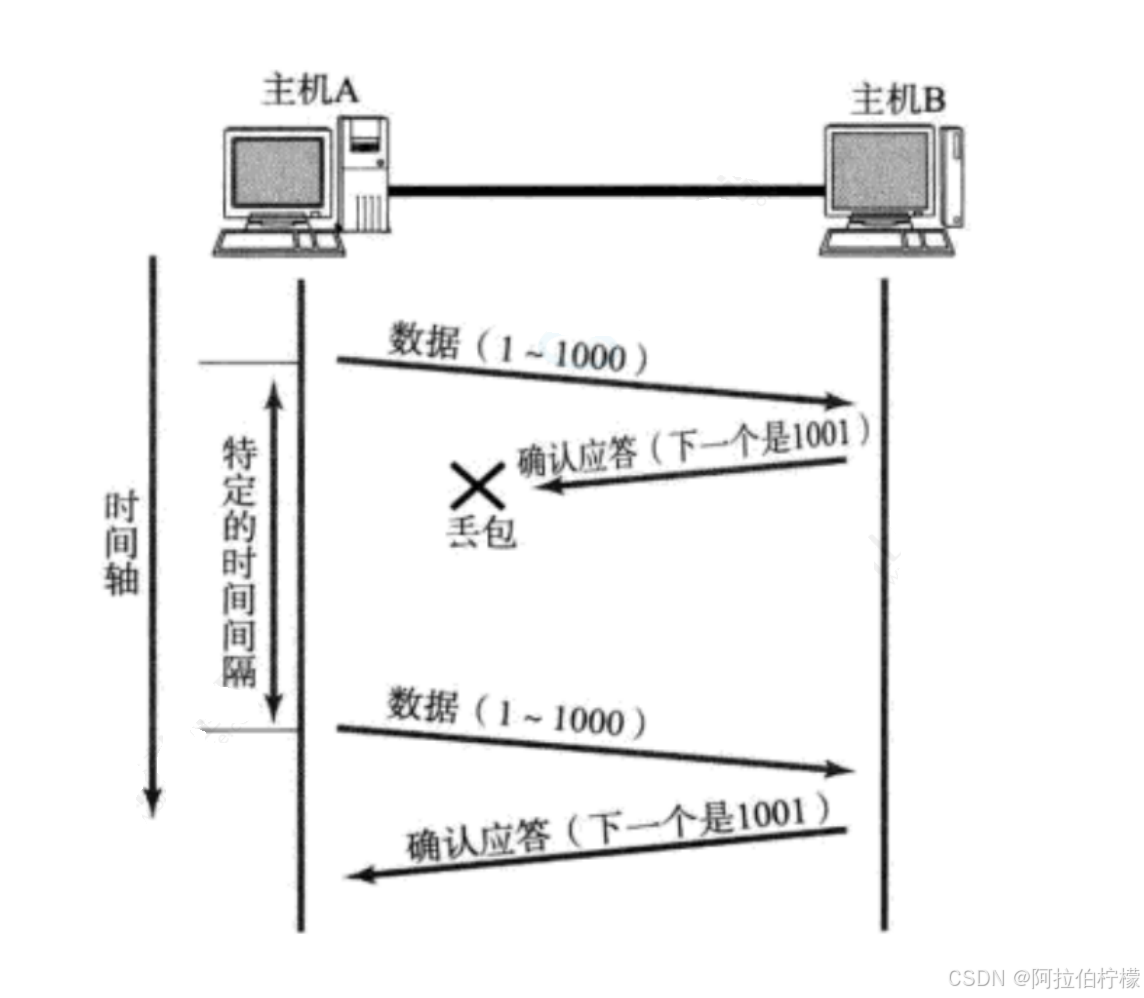
- 主机A未收到B发来的确认应答, 也可能是因为ACK丢失了;
- 因此主机B会收到很多重复数据. 这就要求TCP协议需要能够识别出那些包是重复的包, 并且把重复的丢弃掉.
- 利用序列号就可以达到去重的效果
超时的时间如何确定?
- 最理想的情况下, 找到⼀个最小的时间, 保证 "确认应答⼀定能在这个时间内返回"
- 但是这个时间的⻓短, 随着网络环境的不同, 是有差异的,如果超时时间设的太长, 会影响整体的重传效率,如果超时时间设的太短, 有可能会频繁发送重复的包。
- TCP为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间.
- Linux中(Unix和Windows也是如此), 超时以500ms为⼀个单位进行控制, 每次判定超时重发
的超时时间都是500ms的整数倍。 - 如果重发⼀次之后, 仍然得不到应答, 等待 2500ms 后再进行重传,如果仍然得不到应答, 等待 4 500ms 进行重传. 依次类推, 以指数形式递增 ,累计到⼀定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接