人工智能之核心基础 机器学习
第四章 决策树与集成学习基础
文章目录
- [人工智能之核心基础 机器学习](#人工智能之核心基础 机器学习)
- [4.1 决策树原理](#4.1 决策树原理)
- [🌳 什么是决策树?](#🌳 什么是决策树?)
- [🔑 核心组成部分](#🔑 核心组成部分)
- [🔍 如何选择"问什么问题"?------特征选择标准](#🔍 如何选择“问什么问题”?——特征选择标准)
- [1️⃣ 信息增益(ID3算法)](#1️⃣ 信息增益(ID3算法))
- [2️⃣ 信息增益比(C4.5算法)](#2️⃣ 信息增益比(C4.5算法))
- [3️⃣ Gini系数(CART算法,最常用)](#3️⃣ Gini系数(CART算法,最常用))
- [✂️ 剪枝策略:防止过拟合](#✂️ 剪枝策略:防止过拟合)
- [▶ 预剪枝(Pre-pruning)](#▶ 预剪枝(Pre-pruning))
- [▶ 后剪枝(Post-pruning)](#▶ 后剪枝(Post-pruning))
- [🧪 决策树代码实现](#🧪 决策树代码实现)
- [4.2 集成学习思想](#4.2 集成学习思想)
- [🤝 什么是集成学习?](#🤝 什么是集成学习?)
- [✅ 为什么有效?](#✅ 为什么有效?)
- [4.3 随机森林(Random Forest)](#4.3 随机森林(Random Forest))
- [🌲 原理:Bagging + 随机特征](#🌲 原理:Bagging + 随机特征)
- [✅ 优点 vs ❌ 缺点](#✅ 优点 vs ❌ 缺点)
- [🧪 随机森林代码](#🧪 随机森林代码)
- [4.4 梯度提升树入门(XGBoost / LightGBM)](#4.4 梯度提升树入门(XGBoost / LightGBM))
- [🚀 原理:Boosting ------ 串行纠错](#🚀 原理:Boosting —— 串行纠错)
- [🔥 XGBoost vs LightGBM](#🔥 XGBoost vs LightGBM)
- [🧪 XGBoost 快速上手](#🧪 XGBoost 快速上手)
- [4.5 实战案例](#4.5 实战案例)
- [🎯 本章总结](#🎯 本章总结)
- 资料关注
4.1 决策树原理
🌳 什么是决策树?
决策树 就像"20个问题"游戏------通过一系列是/否问题,一步步缩小范围,最终做出判断。
✅ 核心思想 :用树形结构对数据进行分而治之的划分。
🔑 核心组成部分
| 节点类型 | 作用 | 举例 |
|---|---|---|
| 根节点(Root) | 整棵树的起点,第一个判断条件 | "月消费是否 > 500元?" |
| 内部节点(Internal) | 中间判断节点 | "是否经常投诉?" |
| 叶节点(Leaf) | 最终预测结果 | "会流失" / "不会流失" |
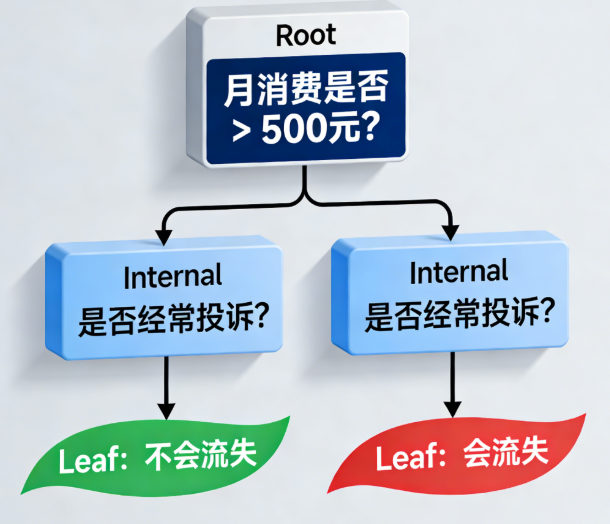
图:一个简单的客户流失预测决策树
🔍 如何选择"问什么问题"?------特征选择标准
目标:每次划分都让子集更"纯净"(同一类样本尽量聚在一起)。
1️⃣ 信息增益(ID3算法)
- 基于信息熵(Entropy):衡量混乱程度
- 信息增益 = 划分前熵 - 划分后加权平均熵
- 选信息增益最大的特征
⚠️ 缺点:偏向取值多的特征(如"用户ID"永远能完美划分,但无意义)
2️⃣ 信息增益比(C4.5算法)
- 对信息增益做归一化,避免偏向多值特征
- 更公平地比较不同特征
3️⃣ Gini系数(CART算法,最常用)
- 衡量"不纯度":Gini越小,越纯净
- 公式: \\text{Gini}(D) = 1 - \\sum_{k=1}\^K p_k\^2
- 选Gini下降最多的划分
💡 通俗理解:
- 熵/Gini 高 → 混乱(比如一半人流失、一半人不流失)
- 熵/Gini 低 → 纯净(比如90%都流失)
我们希望每次提问后,两组人都变得更"整齐"
✂️ 剪枝策略:防止过拟合
决策树容易"学得太细",把噪声也当规律 → 过拟合
▶ 预剪枝(Pre-pruning)
- 在建树过程中提前停止
- 停止条件:
- 树深度达到上限
- 节点样本数太少
- 信息增益/Gini下降小于阈值
✅ 优点:训练快
❌ 缺点:可能"早停",错过更好划分
▶ 后剪枝(Post-pruning)
- 先建完整树,再自底向上合并叶子
- 如果合并后验证集误差不增加,则剪掉分支
✅ 优点:泛化更好
❌ 缺点:训练慢
📌 Scikit-learn 默认使用预剪枝 (通过
max_depth,min_samples_split等参数控制)
🧪 决策树代码实现
python
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# 示例:鸢尾花分类
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树(使用Gini)
clf = DecisionTreeClassifier(
criterion='gini', # 或 'entropy'
max_depth=3, # 预剪枝:最大深度
min_samples_split=10, # 内部节点至少10个样本才分裂
random_state=42
)
clf.fit(X_train, y_train)
# 预测与评估
y_pred = clf.predict(X_test)
print("准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
# 可视化树(简单版)
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=load_iris().feature_names, class_names=load_iris().target_names, filled=True)
plt.show()4.2 集成学习思想
🤝 什么是集成学习?
"三个臭皮匠,顶个诸葛亮"
集成学习 :组合多个弱学习器 (表现略好于随机猜测),形成一个强学习器。
✅ 为什么有效?
| 问题类型 | 单一模型缺陷 | 集成如何解决 |
|---|---|---|
| 高方差(过拟合) | 对训练数据太敏感 | 多模型平均 → 降低方差 |
| 高偏差(欠拟合) | 模型太简单 | 提升法(Boosting)逐步修正错误 |
| 泛化能力差 | 容易受噪声影响 | 多样性 → 更稳健 |
📌 关键 :每个弱学习器要有一定准确性 + 多样性(不能都犯同样错误)
4.3 随机森林(Random Forest)
🌲 原理:Bagging + 随机特征
随机森林 = 多棵决策树投票
两大随机性:
-
样本随机(Bootstrap采样)
- 每棵树从原始数据中有放回地抽取 n n n 个样本(约63%不重复)
- 不同树看到不同数据 → 增加多样性
-
特征随机
- 每次分裂时,只从部分特征 中选最佳划分(默认 总特征数 \sqrt{\text{总特征数}} 总特征数 )
- 防止单一强特征主导所有树
✅ 最终预测:分类用多数投票 ,回归用平均值
✅ 优点 vs ❌ 缺点
| 优点 | 缺点 |
|---|---|
| 几乎不用调参 | 模型不可解释(黑盒) |
| 抗过拟合能力强 | 训练内存和时间开销大 |
| 能处理高维数据 | 对噪声和异常值敏感(但比单棵树好) |
| 自动评估特征重要性 | 无法外推(如预测超出训练范围的值) |
🧪 随机森林代码
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 生成模拟数据(客户流失)
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_redundant=2, n_clusters_per_class=1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 随机森林
rf = RandomForestClassifier(
n_estimators=100, # 树的数量
max_depth=5,
random_state=42,
oob_score=True # 使用袋外样本评估
)
rf.fit(X_train, y_train)
print("测试集准确率:", rf.score(X_test, y_test))
print("袋外误差估计:", 1 - rf.oob_score_)
# 查看特征重要性
importances = rf.feature_importances_
print("前5重要特征:", importances.argsort()[-5:][::-1])4.4 梯度提升树入门(XGBoost / LightGBM)
🚀 原理:Boosting ------ 串行纠错
- Boosting :一棵树接一棵树训练,每棵专注于纠正前一棵的错误
- 梯度提升 :用梯度下降思想优化损失函数
💡 想象老师教学生:
第1次考试错题 → 第2次重点讲这些题 → 第3次再考... 直到全对!
🔥 XGBoost vs LightGBM
| 特性 | XGBoost | LightGBM |
|---|---|---|
| 分裂方式 | Level-wise(按层) | Leaf-wise(按叶,更快) |
| 处理大特征 | 较慢 | 支持类别特征直方图优化 |
| 内存占用 | 中等 | 更低 |
| 精度 | 极高 | 略快,精度相当 |
✅ 共同优势:
- 自带正则化(防过拟合)
- 支持缺失值
- 提供特征重要性
- Kaggle竞赛常胜将军!
🧪 XGBoost 快速上手
python
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# 使用上面的客户流失数据
xgb = XGBClassifier(
n_estimators=100,
max_depth=4,
learning_rate=0.1,
random_state=42
)
xgb.fit(X_train, y_train)
y_pred_proba = xgb.predict_proba(X_test)[:, 1]
print("AUC:", roc_auc_score(y_test, y_pred_proba))💡 实操要点:
- 调参重点:
n_estimators,max_depth,learning_rate- 用
early_stopping_rounds防止过拟合- 分类不平衡时设
scale_pos_weight
4.5 实战案例
案例1:客户流失预测(电信行业)
目标 :预测用户是否会取消服务
特征 :月费、通话时长、客服投诉次数、合约类型等
模型选择:
- 决策树:可解释性强,业务人员易理解
- 随机森林/XGBoost:精度更高,用于最终部署
python
# 特征重要性分析(业务价值!)
feat_names = ['monthly_charges', 'tenure', 'complaints', 'contract_type']
importances = rf.feature_importances_
plt.barh(feat_names, importances)
plt.title("客户流失关键因素")
plt.show()案例2:商品图像分类(简化版)
目标 :区分T恤、裤子、鞋子(Fashion-MNIST)
方法:
- 将图像像素展平为特征向量
- 用随机森林/XGBoost分类(虽不如CNN,但可作为基线)
python
from tensorflow.keras.datasets import fashion_mnist
(X_train_img, y_train), (X_test_img, y_test) = fashion_mnist.load_data()
X_train_flat = X_train_img.reshape(X_train_img.shape[0], -1) / 255.0
X_test_flat = X_test_img.reshape(X_test_img.shape[0], -1) / 255.0
rf = RandomForestClassifier(n_estimators=50, max_depth=10, random_state=42)
rf.fit(X_train_flat[:5000], y_train[:5000]) # 用部分数据加速
print("准确率:", rf.score(X_test_flat[:1000], y_test[:1000]))🎯 本章总结
| 模型 | 核心思想 | 适用场景 | 关键优势 |
|---|---|---|---|
| 决策树 | if-else规则链 | 需要可解释性 | 直观、无需特征缩放 |
| 随机森林 | 多棵树投票(Bagging) | 通用分类/回归 | 稳定、抗过拟合 |
| XGBoost/LightGBM | 串行纠错(Boosting) | 竞赛/高精度需求 | 精度高、支持多种任务 |
💡 建议:
- 先用决策树理解逻辑
- 再用随机森林获得稳定性能
- 追求极致精度时尝试XGBoost/LightGBM
资料关注
公众号:咚咚王
gitee:https://gitee.com/wy18585051844/ai_learning
《Python编程:从入门到实践》
《利用Python进行数据分析》
《算法导论中文第三版》
《概率论与数理统计(第四版) (盛骤) 》
《程序员的数学》
《线性代数应该这样学第3版》
《微积分和数学分析引论》
《(西瓜书)周志华-机器学习》
《TensorFlow机器学习实战指南》
《Sklearn与TensorFlow机器学习实用指南》
《模式识别(第四版)》
《深度学习 deep learning》伊恩·古德费洛著 花书
《Python深度学习第二版(中文版)【纯文本】 (登封大数据 (Francois Choliet)) (Z-Library)》
《深入浅出神经网络与深度学习+(迈克尔·尼尔森(Michael+Nielsen)》
《自然语言处理综论 第2版》
《Natural-Language-Processing-with-PyTorch》
《计算机视觉-算法与应用(中文版)》
《Learning OpenCV 4》
《AIGC:智能创作时代》杜雨+&+张孜铭
《AIGC原理与实践:零基础学大语言模型、扩散模型和多模态模型》
《从零构建大语言模型(中文版)》
《实战AI大模型》
《AI 3.0》