【论文阅读】VGGT: Visual Geometry Grounded Transformer
- 论文所属团队与时间所属团队:
- 问题背景
- [3 解决方案(VGGT 模型)](#3 解决方案(VGGT 模型))
-
- [3.1 模型设计](#3.1 模型设计)
-
- [3.1.1 Backbone](#3.1.1 Backbone)
- [3.1.2 多任务解耦预测头](#3.1.2 多任务解耦预测头)
- [3.2 Loss设计](#3.2 Loss设计)
- [4 结论](#4 结论)
论文所属团队与时间所属团队:
组织: 牛津大学 Visual Geometry Group (VGG) 与 Meta AI
作者: Jianyuan Wang、Nikita Karaev、Andrea Vedaldi(计算机视觉大牛)等
发布时间:2025
问题背景
在 3D 计算机视觉领域,长期以来存在以下几个核心痛点:
- 任务碎片化:过去的研究往往将 3D 任务拆分为独立的问题,如单独研究相机估计(Camera Calibration)、深度估计(Depth Estimation)或点追踪(Point Tracking),缺乏一个能理解全局几何的统一模型。
- 对优化算法的依赖:传统的 3D 重建(如 SfM 或 SLAM)依赖于复杂的后期优化(如捆绑调整 Bundle Adjustment),这些算法运行缓慢且对初始值敏感。
- 架构复杂度高:现有的模型往往针对特定任务手动设计了复杂的几何先验(Inductive Biases),难以利用大规模数据进行简单的端到端扩展。
3 解决方案(VGGT 模型)
3.1 模型设计
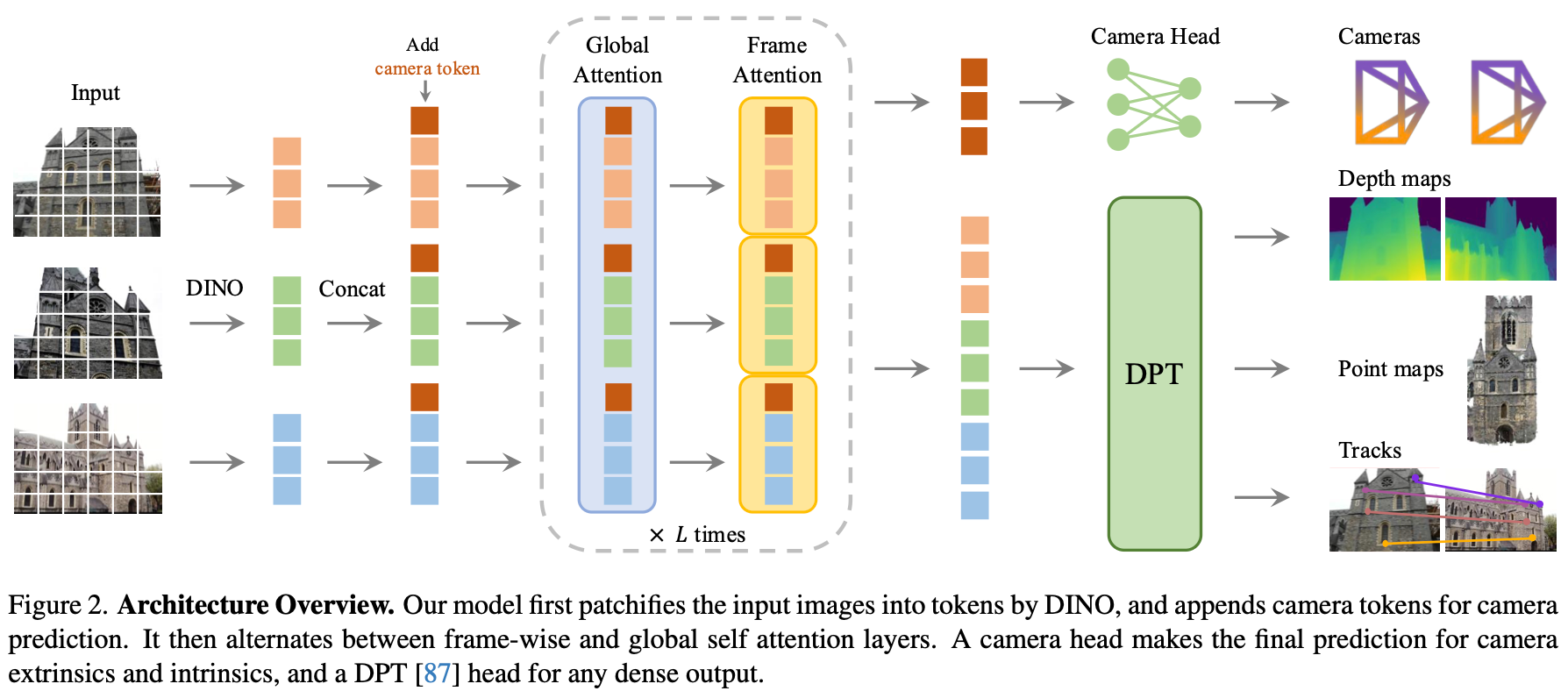
3.1.1 Backbone
输入编码 (Tokenization):模型接收 N N N 张图像作为输入。每张图像被切割成固定大小的补丁(Patches),并加上位置编码(Positional Encoding)和视角编码(View Encoding),以便让模型知道某个 Token 属于哪张图的哪个位置。
骨干网络 (Transformer Backbone):采用类似于 ViT(Vision Transformer)的架构。所有图像的 Token 会一起送入模型,通过自注意力机制(Self-Attention)实现跨视图的通信。这意味着模型在这一阶段就已经在隐式地进行"特征匹配"和"三角测量"了。
3.1.2 多任务解耦预测头
尽管骨干网络是统一的,但为了输出不同的 3D 属性,VGGT 在顶层设计了专门的"预测头":
- 相机外参头 (Camera Head):通过对全局 Token 进行池化或使用特殊的 CLS Token,直接回归出每张图像相对于第一张参考图的旋转四元数 q q q 和平移向量 t t t。相机内参头 (Intrinsics Head):预测焦距 f f f(通常表现为 FoV)和主点位置。这使得模型能够处理从不同设备拍摄、甚至经过剪裁的照片。
- 稠密几何头 (Point & Depth Head):这是一个像素级的预测分支。对于输入的每一个补丁,模型输出其对应的 3D 点图 (Point Map)。深度图 (Depth Map) 则可以从点图中导出,或者由专门的层进行精细化预测。点追踪头 (Point Tracking Head):预测特定点在 3D 空间随时间或视角变化的轨迹。
3.2 Loss设计
- 总损失函数 (Total Loss)VGGT 的优化目标是将所有预测属性与真值(Ground Truth, GT)进行比对。总损失公式可以简化表示为: L t o t a l = λ g L c a m + λ P L p o i n t + λ D L d e p t h + λ T L t r a c k \mathcal{L}{total} = \lambda_g \mathcal{L}{cam} + \lambda_P \mathcal{L}{point} + \lambda_D \mathcal{L}{depth} + \lambda_T \mathcal{L}_{track} Ltotal=λgLcam+λPLpoint+λDLdepth+λTLtrack通过这种方式,模型在训练时被迫同时学习几何的一致性和相机的精确位姿 111。
- 各子任务 Loss 详细设计
-
相机损失 ( L c a m \mathcal{L}_{cam} Lcam):
-
旋转误差:计算预测四元数 q ^ \hat{q} q^ 与真值 q q q 之间的差异。
-
平移误差:计算预测平移向量 t ^ \hat{t} t^ 与真值 t t t 之间的欧式距离
-
焦距误差:针对 FoV 参数 f f f 进行监督。
-
注:所有位姿预测均以第一张图为参考系 。
-
-
点图损失 ( L p o i n t \mathcal{L}_{point} Lpoint):
- 定义:点图是将每个像素投射到 3D 空间后的坐标图
- 计算:采用预测点云 P ^ \hat{P} P^ 与 GT 点云 P P P 之间的 L 2 L_2 L2 距离。为了处理尺度不确定性,模型在计算 Loss 前会对 3D 点进行归一化处理(通常基于场景的平均距离)
-
深度损失 ( L d e p t h \mathcal{L}_{depth} Ldepth):
- 定义:预测每个像素的线性深度值
- 计算:通常使用预测深度与 GT 深度之间的 尺度不变损失 (Scale-invariant Loss) 或简单的回归损失。这有助于模型在单视图和多视图下都能准确感知物体的远近
-
点追踪损失 ( L t r a c k \mathcal{L}_{track} Ltrack):
- 逻辑:对于给定的查询点,模型预测其在所有其他帧中的 2D 位置
- 计算:计算预测坐标与真值坐标之间的距离。如果某点在某些帧中不可见(被遮挡),相应的 Loss 会被掩码(Mask)掉或进行特殊处理 。
4 结论
- 效率极高:VGGT 是一个前馈式(Feed-forward)模型,在不到 1 秒的时间内即可完成传统方法需要数分钟甚至更久才能完成的重建任务。
- 性能卓越:在多个任务(相机估计、多视图深度估计、点追踪等)上达到了 SOTA(当前最佳)水平。令人惊讶的是,这种纯神经网络的直接预测效果,往往优于经过复杂后期优化的传统方法。
- 通用性强:它证明了通过大数据训练,Transformer 能够学习到一种通用的"视觉几何表征",为未来构建 3D 世界的基础模型(Foundation Models)提供了重要方向。