一文总结模型压缩技术:剪枝、量化与蒸馏的原理、实践与工程思考(年度技术复盘)
博客:https://yangdanyang.blog.csdn.net/
创作方向:模型压缩技术年度总结 & 工程实践经验
文章目录
- 一文总结模型压缩技术:剪枝、量化与蒸馏的原理、实践与工程思考(年度技术复盘)
-
- 一、写在前面:为什么模型压缩成为必修课?
- 二、模型压缩全景图:我们在压缩什么?
- 三、剪枝(Pruning):从"全连接"到"结构稀疏"
-
- [3.1 剪枝的核心思想](#3.1 剪枝的核心思想)
- [3.2 剪枝的主要类型](#3.2 剪枝的主要类型)
-
- [1️⃣ 非结构化剪枝(Unstructured Pruning)](#1️⃣ 非结构化剪枝(Unstructured Pruning))
- [2️⃣ 结构化剪枝(Structured Pruning)](#2️⃣ 结构化剪枝(Structured Pruning))
- [3.3 工程实践中的经验总结](#3.3 工程实践中的经验总结)
- 四、量化(Quantization):让模型"轻装上阵"
-
- [4.1 量化在做什么?](#4.1 量化在做什么?)
- [4.2 主流量化方式对比](#4.2 主流量化方式对比)
- [4.3 工程实践中的关键细节](#4.3 工程实践中的关键细节)
- [五、蒸馏(Knowledge Distillation):让小模型"学会思考"](#五、蒸馏(Knowledge Distillation):让小模型“学会思考”)
-
- [5.1 蒸馏的本质](#5.1 蒸馏的本质)
- [5.2 常见蒸馏方式](#5.2 常见蒸馏方式)
- [5.3 蒸馏在大模型时代的价值](#5.3 蒸馏在大模型时代的价值)
- 六、三种技术如何组合?一套实用策略
- 七、年度总结与个人思考
- 八、写在最后
一、写在前面:为什么模型压缩成为必修课?
过去一年,在 大模型与深度学习工程化 的浪潮下,一个现实问题被反复提及:
模型越来越大,但部署环境越来越"苛刻"。
无论是:
- 边缘设备(移动端 / IoT / 嵌入式)
- 高并发在线服务
- 低延迟、低功耗、低成本推理场景
都在逼迫我们重新思考一个问题:
如何在"性能可接受"的前提下,把模型变小、变快、变便宜?
于是,模型压缩(Model Compression) 成为连接"算法理想"和"工程现实"的关键技术。
本文将对 剪枝(Pruning)、量化(Quantization)、蒸馏(Knowledge Distillation) 三大核心技术做一次系统性的年度总结,从:
- 技术原理
- 主流方法
- 实践经验
- 工程取舍
四个维度进行梳理,希望对正在做 模型部署 / 推理优化 / 大模型落地 的你有所帮助。
二、模型压缩全景图:我们在压缩什么?
从本质上看,模型压缩主要目标是降低以下成本:
| 维度 | 对应指标 |
|---|---|
| 存储 | 参数量 / 模型体积 |
| 计算 | FLOPs / 推理时延 |
| 能耗 | 功耗 / 服务器成本 |
| 带宽 | 模型传输 / 冷启动 |
对应的核心手段可以抽象为三类:
减少冗余 → 表示压缩 → 知识迁移
也正好对应:
- 剪枝(减少冗余)
- 量化(低精度表示)
- 蒸馏(知识迁移)
三、剪枝(Pruning):从"全连接"到"结构稀疏"
3.1 剪枝的核心思想
并非所有参数都同样重要
大量研究与实践表明:
- 神经网络中存在 显著参数冗余
- 删除部分权重后,模型性能下降并不明显
剪枝的目标就是:
在尽量不损失精度的前提下,删除不重要的参数或结构
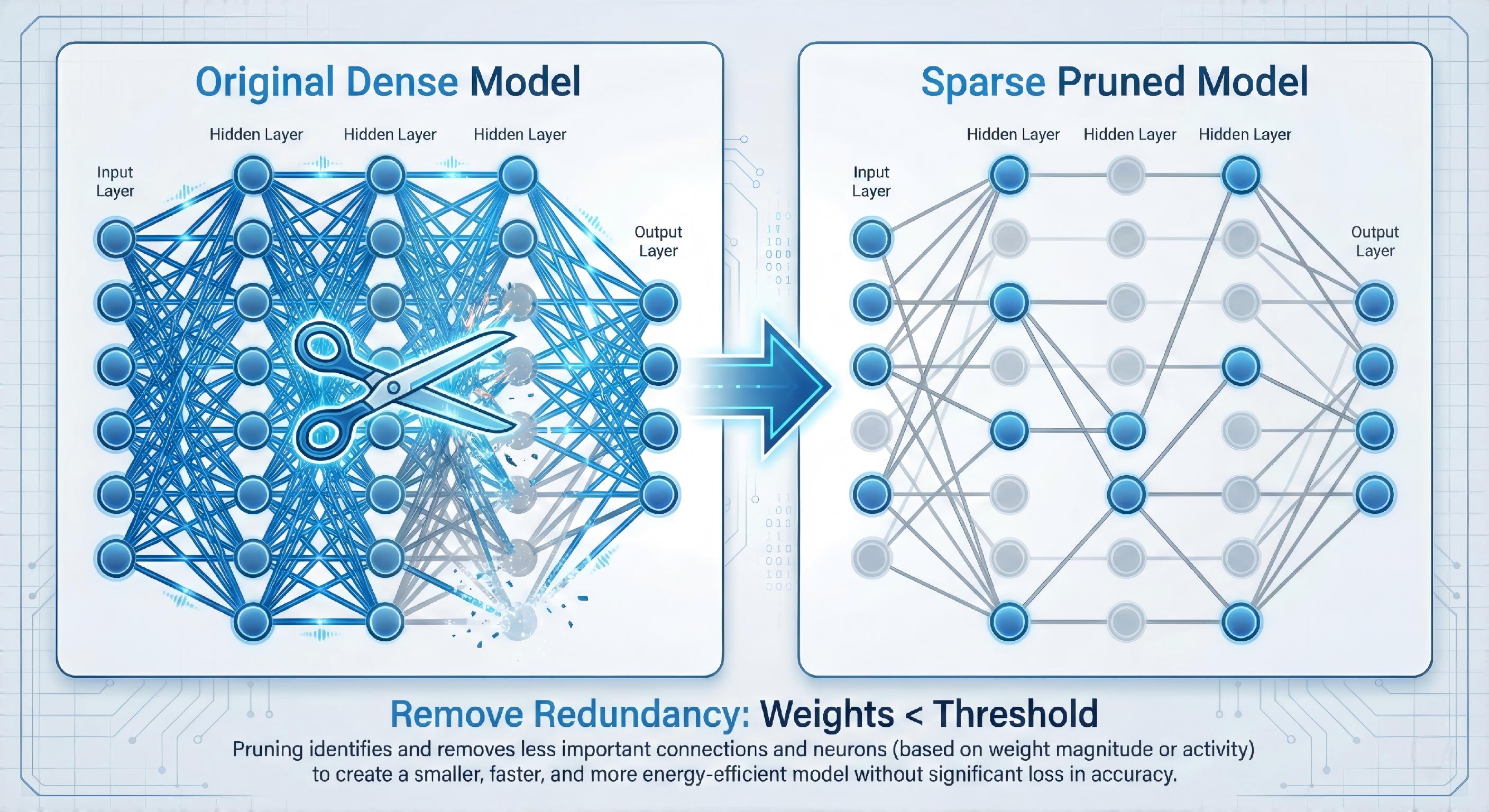
3.2 剪枝的主要类型
1️⃣ 非结构化剪枝(Unstructured Pruning)
-
粒度:单个权重
-
常见方法:
- 基于权重大小(Magnitude-based)
- L1 / L2 正则诱导稀疏
✅ 优点:
- 压缩率高
❌ 缺点: - 稀疏矩阵对硬件不友好
- 实际加速效果有限
2️⃣ 结构化剪枝(Structured Pruning)
-
粒度:
- 通道(Channel)
- 卷积核(Kernel)
- 注意力头(Head)
-
常见于:
- CNN
- Transformer
✅ 优点:
- 真正可加速
- 更适合工程落地
❌ 缺点: - 剪枝策略设计复杂
3.3 工程实践中的经验总结
📌 经验 1:结构化剪枝更适合生产环境
如果目标是 推理加速,优先考虑结构化剪枝。
📌 经验 2:剪枝 ≠ 一次性操作
推荐流程:
- 训练完整模型
- 剪枝
- 微调(Fine-tune)
- 评估
📌 经验 3:Transformer 剪枝要更谨慎
- Attention Head 剪枝
- FFN 中间层维度裁剪
- 层级剪枝(Layer Drop)
四、量化(Quantization):让模型"轻装上阵"
4.1 量化在做什么?
用更低的数值精度表示参数和计算
典型变化:
- FP32 → INT8
- FP16 / BF16
- 混合精度
核心收益:
- 模型体积 ↓
- 内存访问 ↓
- 推理速度 ↑
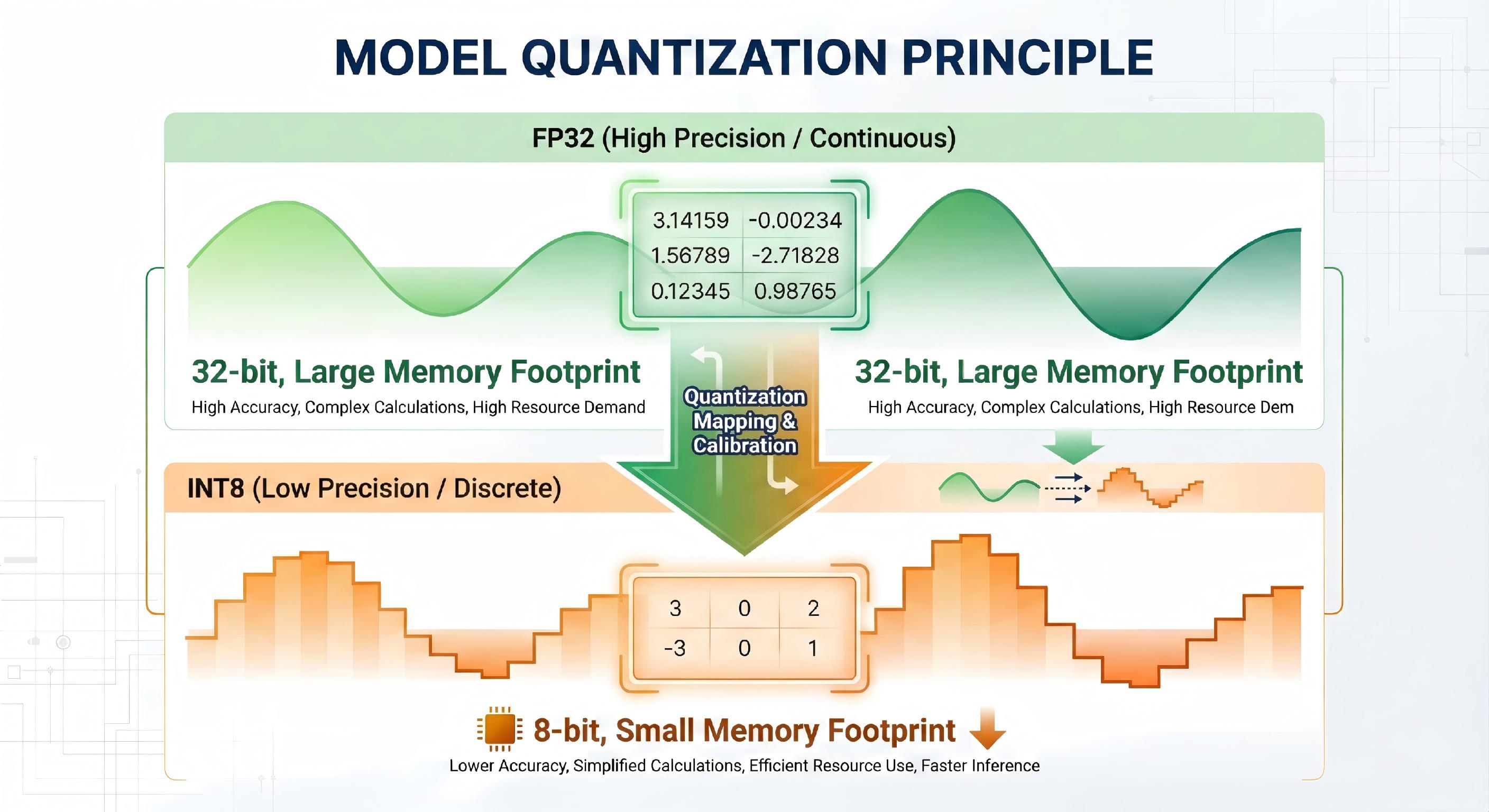
4.2 主流量化方式对比
| 方法 | 是否需重训 | 精度影响 | 工程难度 |
|---|---|---|---|
| PTQ(后训练量化) | ❌ | 中 | ⭐ |
| QAT(量化感知训练) | ✅ | 小 | ⭐⭐⭐ |
| 动态量化 | ❌ | 小 | ⭐⭐ |
4.3 工程实践中的关键细节
📌 经验 1:PTQ 是性价比最高的起点
- 特别适合已有成熟模型
- 配合校准数据即可
📌 经验 2:QAT 是精度敏感场景的首选
- NLP / Transformer 模型更适合 QAT
- 训练成本较高,但收益稳定
📌 经验 3:注意算子支持情况
- 并非所有算子都支持 INT8
- 推理框架(TensorRT / ONNX Runtime)差异明显
五、蒸馏(Knowledge Distillation):让小模型"学会思考"
5.1 蒸馏的本质
把大模型的"知识"迁移到小模型中
Teacher → Student
不再只学习 hard label,而是:
- soft label
- 中间特征
- attention 分布
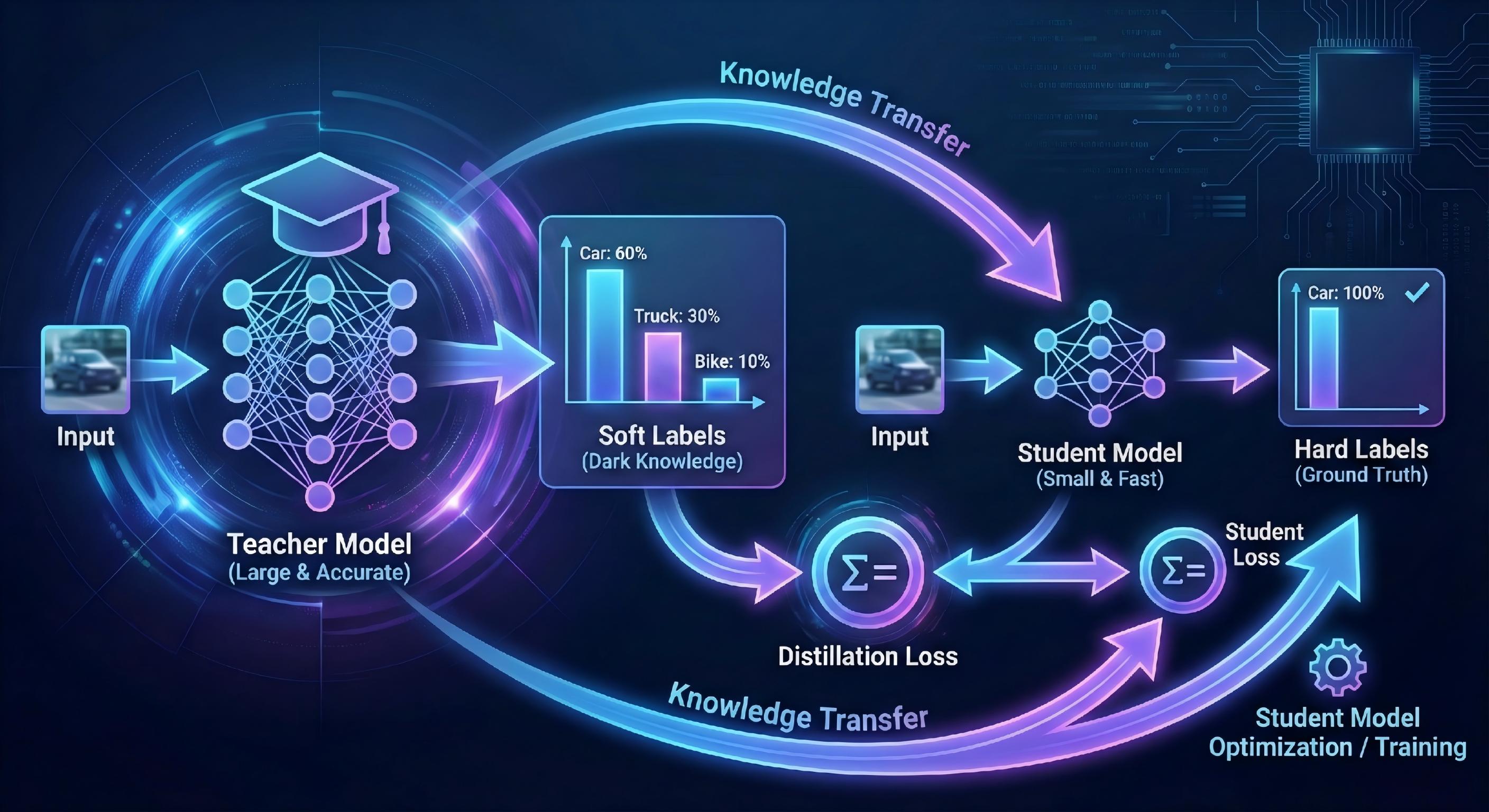
5.2 常见蒸馏方式
- Logits 蒸馏(最常用)
- Feature 蒸馏
- Attention 蒸馏
- 自蒸馏(Self-distillation)
5.3 蒸馏在大模型时代的价值
📌 经验 1:蒸馏是"小模型逆袭"的关键
在同等参数量下:
蒸馏模型 ≫ 从头训练模型
📌 经验 2:蒸馏可以与剪枝、量化叠加
典型组合:
- 先蒸馏 → 再量化
- 大模型蒸馏 + 小模型 QAT
📌 经验 3:蒸馏是成本与效果的平衡器
- 推理成本 ↓
- 性能损失可控
六、三种技术如何组合?一套实用策略
推荐工程组合路径
蒸馏 → 剪枝 → 量化
原因:
- 蒸馏保证性能上限
- 剪枝减少结构冗余
- 量化进一步压缩与加速
不同场景的建议
| 场景 | 推荐方案 |
|---|---|
| 移动端 | 蒸馏 + INT8 |
| 云端高并发 | 结构化剪枝 + 量化 |
| 极致性能 | QAT + TensorRT |
| 快速落地 | PTQ |
七、年度总结与个人思考
回顾这一年在模型压缩方向的学习与实践,我越来越深刻地感受到:
模型压缩不是"妥协",而是工程智慧。
它考验的已经不仅是算法能力,而是:
- 对业务需求的理解
- 对系统瓶颈的判断
- 对成本与收益的权衡
未来,随着:
- 大模型推理成本持续走高
- 边缘 AI 场景不断扩大
模型压缩将从"优化选项"变成"工程标配"。
八、写在最后
希望这篇年度技术总结,能为你在 模型部署、推理优化、工程落地 的道路上提供一份参考。
如果你对:
- Transformer 剪枝
- 大模型蒸馏
- 推理框架优化
感兴趣,欢迎在评论区交流 🤝
也欢迎关注我的博客: