📘 Day 33 实战作业:深度学习 Hello World ------ 手搓神经网络
1. 作业综述
核心目标:
- 环境配置:确认 PyTorch 环境安装成功(这是深度学习的第一道门槛)。
- 数据张量化 :学会将 Numpy 数组转换为 PyTorch 认识的 Tensor (张量)。
- 模型定义 :继承
nn.Module,亲手搭建一个多层感知机 (MLP)。 - 训练循环:理解并实现"前向传播 -> 计算 Loss -> 反向传播 -> 更新参数"的经典四步走。
涉及知识点:
- PyTorch 基础 :
torch.Tensor,nn.Module,nn.Linear,nn.ReLU. - 优化器 :
torch.optim.SGD(随机梯度下降). - 损失函数 :
nn.CrossEntropyLoss(交叉熵).
场景类比:
- sklearn : 像是吃泡面,开水一泡(
fit)就能吃(predict),但口味固定。 - PyTorch: 像是进厨房做菜,你要自己切菜(定义层)、炒菜(前向传播)、尝咸淡(计算 Loss)、加盐(更新参数)。虽然麻烦,但这才是大厨的必经之路。
步骤 1:数据准备 (Numpy to Tensor)
场景描述 :
神经网络对数据非常敏感。
- 数值敏感:必须进行归一化(MinMax 或 Standard),否则梯度会乱飞。
- 类型敏感 :PyTorch 不认识 Numpy 数组,必须转成
Tensor。特征通常是FloatTensor(浮点数),分类标签必须是LongTensor(长整型)。
任务:
- 加载 Iris 数据集并划分训练/测试集。
- 使用
MinMaxScaler进行归一化。 - 关键:将数据转换为 PyTorch 的 Tensor 格式。
py
import torch
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 2. 划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 归一化 (神经网络标准动作)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 4. 转换为 Tensor (关键步骤)
# 特征转为 FloatTensor (32位浮点), 标签转为 LongTensor (64位整型,交叉熵要求)
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.LongTensor(y_train)
X_test_tensor = torch.FloatTensor(X_test)
y_test_tensor = torch.LongTensor(y_test)
print(f"训练集 Tensor 形状: {X_train_tensor.shape}")
print(f"标签 Tensor 类型: {y_train_tensor.dtype}")训练集 Tensor 形状: torch.Size([120, 4])
标签 Tensor 类型: torch.int64步骤 2:搭建神经网络 (Subclassing nn.Module)
场景描述 :
我们要搭建一个简单的 MLP (多层感知机) 来处理 Iris 分类。
输入是 4 个特征,输出是 3 个类别。中间加一层隐藏层(比如 10 个神经元)和激活函数。
PyTorch 建模八股文:
- 定义类,继承
nn.Module。 - 在
__init__里定义有哪些层(零件)。 - 在
forward里定义数据怎么流向(组装)。
任务 :
定义 SimpleMLP 类,包含:输入层(4)->隐藏层(10)->ReLU->输出层(3)。
py
import torch.nn as nn
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__() # 标准起手式
# 定义层 (零件)
# 4 -> 10
self.fc1 = nn.Linear(in_features=4, out_features=10)
# 激活函数
self.relu = nn.ReLU()
# 10 -> 3 (输出层)
self.fc2 = nn.Linear(in_features=10, out_features=3)
def forward(self, x):
# 定义前向传播路径 (组装)
# x -> fc1 -> relu -> fc2 -> output
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
# 注意:这里不需要 Softmax,因为 CrossEntropyLoss 自带了
return out
# 实例化模型
model = SimpleMLP()
print(model)SimpleMLP(
(fc1): Linear(in_features=4, out_features=10, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=10, out_features=3, bias=True)
)步骤 3:训练循环 (The Training Loop)
场景描述 :
这是 PyTorch 最劝退也最核心的部分。
不同于 model.fit() 一键搞定,我们需要手写循环:
- 前向传播: 算出预测值。
- 计算损失: 预测值和真实值差多少?
- 梯度清零: 把上一步的梯度倒掉,别累积。
- 反向传播: 算出每个参数该怎么调。
- 参数更新: 迈出一步 (Step)。
任务:
- 定义损失函数
CrossEntropyLoss和 优化器SGD。 - 编写 1000 轮的训练循环,并记录 Loss 变化。
- 绘制 Loss 曲线。
py
import torch.optim as optim
import matplotlib.pyplot as plt
# 1. 定义 Loss 和 Optimizer
criterion = nn.CrossEntropyLoss()
# 学习率 lr=0.1
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 2. 开始训练
epochs = 1000
loss_history = []
print("🚀 开始训练...")
for epoch in range(epochs):
# --- A. 前向传播 ---
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
# --- B. 反向传播与优化 (核心三件套) ---
optimizer.zero_grad() # 1. 梯度清零
loss.backward() # 2. 反向传播求梯度
optimizer.step() # 3. 更新参数
# 记录 Loss
loss_history.append(loss.item())
if (epoch+1) % 100 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# 3. 可视化训练过程
plt.plot(loss_history)
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
print("✅ 训练完成!")🚀 开始训练...
Epoch [100/1000], Loss: 0.5708
Epoch [200/1000], Loss: 0.3821
Epoch [300/1000], Loss: 0.2937
Epoch [400/1000], Loss: 0.2323
Epoch [500/1000], Loss: 0.1876
Epoch [600/1000], Loss: 0.1555
Epoch [700/1000], Loss: 0.1325
Epoch [800/1000], Loss: 0.1160
Epoch [900/1000], Loss: 0.1040
Epoch [1000/1000], Loss: 0.0951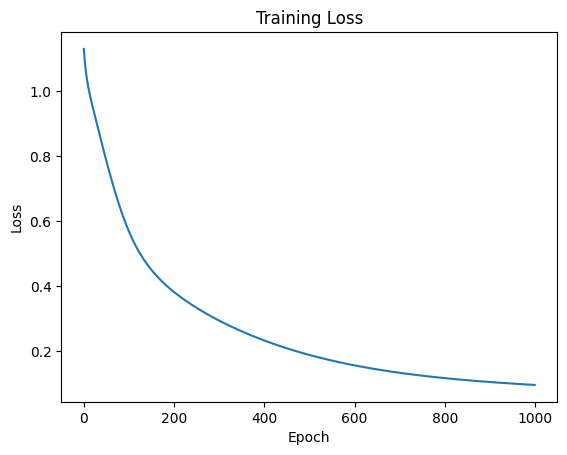
✅ 训练完成!🎓 Day 33 总结:打开"白盒"
恭喜你完成了第一个 PyTorch 神经网络!
今天我们最大的收获是打破了黑盒。
sklearn vs PyTorch 对照表:
| 动作 | sklearn (黑盒) | PyTorch (白盒) |
|---|---|---|
| 定义模型 | clf = MLPClassifier() |
class MyNet(nn.Module): ... |
| 训练 | clf.fit(X, y) |
写 for 循环 (前向+反向+更新) |
| 数据 | Numpy 数组 | torch.Tensor |
虽然代码变多了,但你现在拥有了无限的自由。你可以随意修改层数、随意改变数据流向、随意自定义损失函数。这就是深度学习的魅力。
Next Level :
既然有了模型,怎么评估它的好坏?怎么保存它?明天我们将继续完善这个工程!