从海量新闻文本中,如何快速、准确地识别关键人物、言论和行动?PERSIA框架为我们提供了一个全新的视角。
github项目地址:https://github.com/xy200303/PERSIA
1. 引言:突发公共事件分析的挑战
在信息爆炸的时代,突发公共事件(如疫情、自然灾害、安全事故等)相关信息呈现爆发式增长。传统的信息分析方法面临诸多挑战:
- 信息碎片化:事件相关信息分散在不同媒体、不同时间段
- 实体不统一:同一人物、机构在不同报道中的表述各异
- 关系模糊:言论与行动之间的因果关系难以厘清
- 分析滞后:人工分析耗时耗力,难以实时响应
为解决这些问题,我们提出了PERSIA框架(Person-centric Emergency Response Statement and Interaction Analysis Framework),并基于大语言模型和知识图谱技术,构建了一套端到端的智能分析系统。
2. PERSIA框架:人物中心的突发公共事件分析模型
2.1 框架核心思想
PERSIA框架的核心是以人物为中心 ,围绕"谁说了什么"、"谁做了什么"、"产生了什么影响"三个核心问题展开分析。这种设计源于对突发公共事件本质的深刻认识:事件由人物驱动,决策由言论体现,结果由行动塑造。
2.2 四层分析结构
PERSIA框架采用四层递进的分析结构:
第一层:人物识别与关联
核心人物定位(决策者、专家、受影响者等)
人物关系网络构建
第二层:言论抽取与分析
结构化人物言论
言论情境标注(时间、场合、对象、媒体)
第三层:行动追踪与关联
行动类型分类(决策、执行、响应等)
言论→行动关联分析
第四层:因果推理与事件链构建
多级因果链挖掘
时间序列重建2.3 实体标准化体系
为了确保信息的一致性,我们定义了严格的实体标准化体系:
python
# 实体标准化格式(必须严格遵守)
## 1. 机构/组织实体
【格式:[ORG]官方全称(机构类型)】
- 正确示例:[ORG]国家卫生健康委员会(政府机构)
- 错误示例:卫健委、国家卫健委
## 2. 人物实体
【格式:[PERSON]姓名(职位@所属机构)】
- 正确示例:[PERSON]马晓伟(主任@国家卫生健康委员会)
- 错误示例:马晓伟、卫健委主任马晓伟
- **注意**:无需额外标注人物角色,通过职位体现
## 3. 地区/位置实体
【格式:[LOC]标准名称(地区类型)】
- 正确示例:[LOC]湖北省(省级行政区)、[LOC]武汉市(城市)
- 错误示例:湖北、武汉
## 4. 言论实体
【格式:[STATEMENT]内容摘要[言论类型](时间)】
- 正确示例:[STATEMENT]优化疫情防控措施[政策声明](2023-01-08)
- 错误示例:将优化防控措施、政策声明
- **要求**:内容摘要20字以内,时间格式YYYY-MM-DD
## 5. 行动实体
【格式:[ACTION]行动描述[行动类型](时间)】
- 正确示例:[ACTION]实施"乙类乙管"政策[决策](2023-01-08)
- 错误示例:执行乙类乙管、决策行动
- **要求**:行动描述15字以内
## 6. 结果实体
【格式:[OUTCOME]结果描述[结果类型](时间)】
- 正确示例:[OUTCOME]疫情得到有效控制[积极结果](2023-03-15)
- 错误示例:控制疫情、结果
# 关系标签列表(只能使用以下标签)
## 主体关系
BELONGS_TO # 人物属于机构
LEADS # 人物领导机构
COLLABORATES_WITH # 人物间合作
## 言论关系
SAID # 说/表示
ANNOUNCED # 宣布/发布
RESPONDED_TO # 回应/答复
REFUTED # 反驳/否认
SUGGESTED # 建议/提议
QUOTED # 引用/援引
## 行动关系
IMPLEMENTED # 实施/执行
PARTICIPATED_IN # 参与/出席
CONDUCTED # 开展/进行
ISSUED # 印发/下发
INITIATED # 发起/启动
## 因果与影响关系
BASED_ON # 基于/依据
LEAD_TO # 导致/使得
TRIGGERED # 触发/引起
RESULTED_IN # 产生结果
CAUSED_BY # 由...引起
CONTRIBUTED_TO # 促进/促成
FOLLOWED_BY # 随后发生
PRECEDED_BY # 之前发生3. 基于大模型的PERSIA信息抽取
3.1 系统架构
我们构建了基于大语言模型的智能抽取系统,整体架构如下:
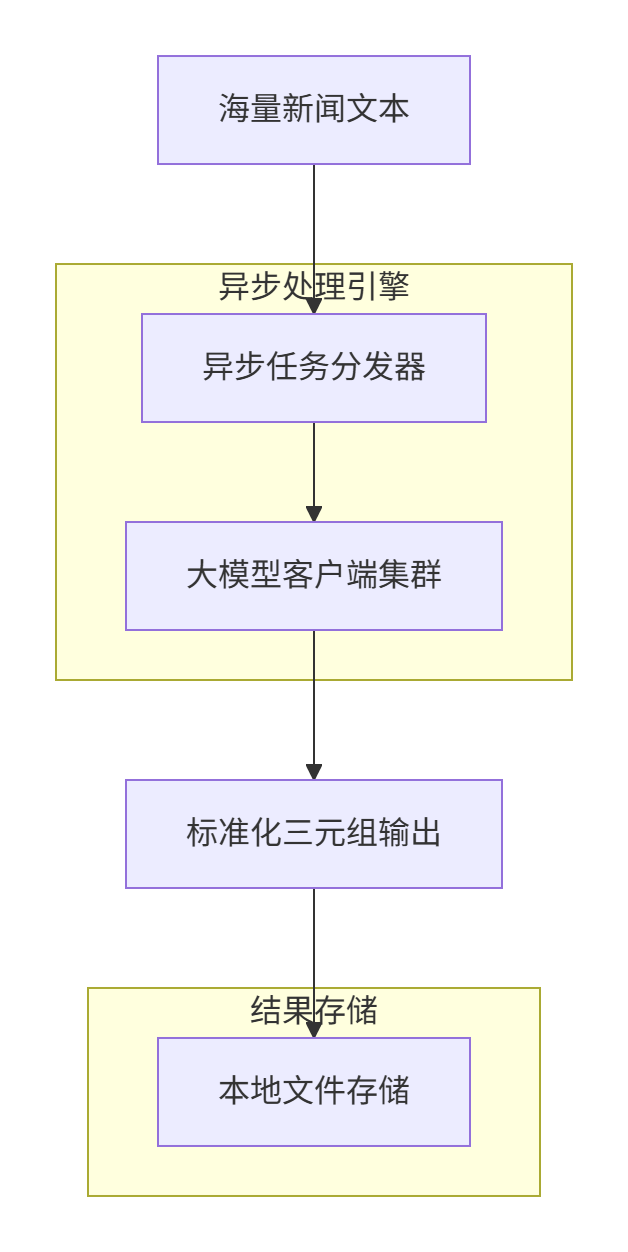
3.2 提示词工程
关键的一步是设计高质量的提示词,引导大模型按照PERSIA框架进行信息抽取:
python
NER_PERSIA_PROMPT= """
# 角色
你是PERSIA框架专家------人物中心化的突发公共事件信息抽取系统。
# 核心约束
1. **标准化输出**:必须严格按照以下标准化格式输出
2. **禁止自创**:不能创建任何未定义的实体类型和关系标签
3. **简洁格式**:去除复杂嵌套格式,使用统一标准格式
# 实体标准化格式(必须严格遵守)
## 1. 机构/组织实体
【格式:[ORG]官方全称(机构类型)】
- 正确示例:[ORG]国家卫生健康委员会(政府机构)
- 错误示例:卫健委、国家卫健委
## 2. 人物实体
【格式:[PERSON]姓名(职位@所属机构)】
- 正确示例:[PERSON]马晓伟(主任@国家卫生健康委员会)
- 错误示例:马晓伟、卫健委主任马晓伟
- **注意**:无需额外标注人物角色,通过职位体现
## 3. 地区/位置实体
【格式:[LOC]标准名称(地区类型)】
- 正确示例:[LOC]湖北省(省级行政区)、[LOC]武汉市(城市)
- 错误示例:湖北、武汉
## 4. 言论实体
【格式:[STATEMENT]内容摘要[言论类型](时间)】
- 正确示例:[STATEMENT]优化疫情防控措施[政策声明](2023-01-08)
- 错误示例:将优化防控措施、政策声明
- **要求**:内容摘要20字以内,时间格式YYYY-MM-DD
## 5. 行动实体
【格式:[ACTION]行动描述[行动类型](时间)】
- 正确示例:[ACTION]实施"乙类乙管"政策[决策](2023-01-08)
- 错误示例:执行乙类乙管、决策行动
- **要求**:行动描述15字以内
## 6. 结果实体
【格式:[OUTCOME]结果描述[结果类型](时间)】
- 正确示例:[OUTCOME]疫情得到有效控制[积极结果](2023-03-15)
- 错误示例:控制疫情、结果
# 关系标签列表(只能使用以下标签)
## 主体关系
BELONGS_TO # 人物属于机构
LEADS # 人物领导机构
COLLABORATES_WITH # 人物间合作
## 言论关系
SAID # 说/表示
ANNOUNCED # 宣布/发布
RESPONDED_TO # 回应/答复
REFUTED # 反驳/否认
SUGGESTED # 建议/提议
QUOTED # 引用/援引
## 行动关系
IMPLEMENTED # 实施/执行
PARTICIPATED_IN # 参与/出席
CONDUCTED # 开展/进行
ISSUED # 印发/下发
INITIATED # 发起/启动
## 因果与影响关系
BASED_ON # 基于/依据
LEAD_TO # 导致/使得
TRIGGERED # 触发/引起
RESULTED_IN # 产生结果
CAUSED_BY # 由...引起
CONTRIBUTED_TO # 促进/促成
FOLLOWED_BY # 随后发生
PRECEDED_BY # 之前发生
# 输出格式
每行一个三元组,严格格式:
[实体类型]实体标准描述 <SEP> 关系标签 <SEP> [实体类型]实体标准描述
**注意**:不要添加任何注释、层级标注或其他文本
# 抽取流程规范
## 第一步:识别所有实体
1. 提取机构实体:[ORG]全称(类型)
2. 提取人物实体:[PERSON]姓名(职位@机构)
3. 提取言论实体:[STATEMENT]摘要[类型](时间)
4. 提取行动实体:[ACTION]描述[类型](时间)
5. 提取结果实体:[OUTCOME]描述[类型](时间)
## 第二步:建立标准关系
1. 人物与机构:BELONGS_TO/LEADS
2. 人物与言论:SAID/ANNOUNCED/SUGGESTED
3. 言论与行动:LEAD_TO/TRIGGERED
4. 行动与结果:RESULTED_IN
5. 时间顺序:FOLLOWED_BY/PRECEDED_BY
## 第三步:严格格式化输出
- 每行一个三元组
- 使用标准实体格式
- 使用预定义关系标签
- 确保时间信息准确
- 任何行动、言论都必须指明是谁做的,谁说的
# 严格禁止行为
1. 禁止使用简称(必须用全称)
2. 禁止省略职位/机构信息
3. 禁止自创关系标签(只能用预定义标签)
4. 禁止合并多个关系(每行只一个关系)
5. 禁止输出非标准化实体(只能用定义的类型)
6. 禁止添加注释、说明或其他文本
7. 禁止使用复杂嵌套格式(如@场合>对象#媒体)
8. 禁止输出层级标记(如// 第一层)
9. 禁止出现没有主体的事件或者言论实体
# 标准化示例
## 示例1:简单情况
输入:"卫健委表示,将优化防控措施。"
正确输出:
[ORG]国家卫生健康委员会(政府机构) <SEP> SAID <SEP> [STATEMENT]将优化疫情防控措施[政策声明](当日)
错误输出:
卫健委 <SEP> 说 <SEP> 优化防控措施
// 言论层
[PERSON]马晓伟(主任@国家卫生健康委员会)(决策者) <SEP> ANNOUNCED <SEP> [STATEMENT]优化措施[声明]
## 示例2:复杂情况
输入:"钟南山院士建议老年人打疫苗。北京市随即开展了接种工作。"
正确输出:
[PERSON]钟南山(院士@中国工程院) <SEP> SUGGESTED <SEP> [STATEMENT]建议老年人接种疫苗[专家建议](当日)
[STATEMENT]建议老年人接种疫苗[专家建议](当日) <SEP> LEAD_TO <SEP> [ACTION]开展老年人疫苗接种[执行](当日)
[ORG]北京市政府(地方政府) <SEP> CONDUCTED <SEP> [ACTION]开展老年人疫苗接种[执行](当日)
错误输出:
[PERSON]钟南山(院士@中国工程院)(专家) <SEP> 建议 <SEP> [STATEMENT]老年人打疫苗[建议]
[ACTION]接种工作[执行](当日) <SEP> 由 <SEP> [ORG]北京(政府)
## 示例3:完整事件
输入:"2023年1月8日,国家卫健委主任马晓伟宣布实施'乙类乙管'政策。钟南山院士表示支持这一调整。"
正确输出:
[PERSON]马晓伟(主任@国家卫生健康委员会) <SEP> ANNOUNCED <SEP> [STATEMENT]实施"乙类乙管"政策[政策声明](2023-01-08)
[PERSON]钟南山(院士@中国工程院) <SEP> RESPONDED_TO <SEP> [STATEMENT]实施"乙类乙管"政策[政策声明](2023-01-08)
[PERSON]钟南山(院士@中国工程院) <SEP> SAID <SEP> [STATEMENT]支持政策调整[观点表达](2023-01-09)
# 完整处理流程示例
输入文本:"在国务院联防联控机制新闻发布会上,国家卫健委主任马晓伟宣布,自2023年1月8日起对新型冠状病毒感染实施'乙类乙管'。钟南山院士随后表示支持。"
**标准化输出**:
[PERSON]马晓伟(主任@国家卫生健康委员会) <SEP> BELONGS_TO <SEP> [ORG]国家卫生健康委员会(政府机构)
[PERSON]马晓伟(主任@国家卫生健康委员会) <SEP> ANNOUNCED <SEP> [STATEMENT]实施"乙类乙管"政策[政策声明](2023-01-08)
[ORG]国务院联防联控机制(协调机构) <SEP> IMPLEMENTED <SEP> [ACTION]实施"乙类乙管"政策[决策](2023-01-08)
[PERSON]钟南山(院士@中国工程院) <SEP> RESPONDED_TO <SEP> [STATEMENT]实施"乙类乙管"政策[政策声明](2023-01-08)
[PERSON]钟南山(院士@中国工程院) <SEP> SAID <SEP> [STATEMENT]支持"乙类乙管"政策[观点表达](2023-01-09)
[ACTION]实施"乙类乙管"政策[决策](2023-01-08) <SEP> RESULTED_IN <SEP> [OUTCOME]疫情防控措施优化[积极结果](2023-01-20)
# 错误检查清单
在输出前检查:
1. 所有实体是否都是预定义类型?
2. 所有关系标签是否都在列表中?
3. 是否每行只有一个三元组?
4. 是否所有机构都用全称?
5. 是否所有人物都有职位@机构?
6. 是否所有言论都有[类型](时间)?
7. 是否所有行动都有[类型](时间)?
8. 是否没有添加任何注释或说明?
# 最终输出要求
只输出符合以下格式的三元组,每行一个:
[类型]描述 <SEP> 关系 <SEP> [类型]描述
不需要说明、不需要注释、不需要层级标记
严格按照标准化格式
只使用预定义的实体类型和关系标签
现在开始,严格按照标准化要求抽取信息。
"""
"""3.3 异步批量处理
为处理大量新闻文本,我们实现了高效的异步批量处理机制:
python
#利用大模型进行并发抽取,结果保存到./outputs/file,支持断点恢复
CSV_PATH = "./dataset/sentences.csv"
MAX_CONCURRENT = 20 # 最大并发数
OUTPUT_PATH = "./outputs/file"
LOG_DIR = "./logs"
os.makedirs(LOG_DIR,exist_ok=True)
os.makedirs(OUTPUT_PATH, exist_ok=True)
llm_c = LLMClient(system_prompt=NER_PERSIA_PROMPT,max_concurrent_requests=MAX_CONCURRENT,history_max=-1)
async def process_text(id,text,pbar: tqdm = None):
try:
file_path = os.path.join(OUTPUT_PATH,str(id)+".txt")
res=await llm_c.allm_call(text)
with open(file_path,"w",encoding="utf-8") as f:
f.write(res)
if pbar:
pbar.update(1)
pbar.set_postfix_str(f"处理完成: {id}")
return True
except Exception as e:
log_file=os.path.join(LOG_DIR,str(id)+".log")
with open(log_file,"a",encoding="utf-8") as f:
f.write(str(e))
if pbar:
pbar.set_postfix_str(f"处理失败: {id} - {str(e)[:30]}")
return False
async def main():
# 读取csv新闻文件
data = pd.read_csv("./dataset/sentences.csv")
print("数据统计:")
print(f"总行数: {len(data)}")
print(f"唯一文档数: {data['id'].nunique()}")
print("前几个ID:", data['id'].unique()[:5])
# 根据id进行聚合,组成完成的新闻描述
group_data = data.groupby("id")
tasks=[]
print("\n📁 正在准备处理任务...")
pbar = tqdm(total=len(group_data), desc="处理分组")
for index,group in group_data:
file_path = os.path.join(OUTPUT_PATH,str(index)+".txt")
if os.path.exists(file_path):
pbar.update(1)
continue
text = "".join(group["sentence"].tolist())
tasks.append(asyncio.create_task(process_text(index,text,pbar=pbar)))
# 等待所有任务完成
results = await asyncio.gather(*tasks, return_exceptions=True)
pbar.close()
print("\n📊 处理结果统计:")
success=0
for result in results:
if result:
success += 1
print("成功:",success)
if __name__ == "__main__":
asyncio.run(main())4. 三元组解析与知识图谱构建
4.1 三元组解析器
大模型输出的是标准化的文本三元组,我们需要将其解析为结构化数据:
python
import json
import re
from typing import List, Dict, Any
import networkx as nx
import matplotlib.pyplot as plt
from pyvis.network import Network
import pandas as pd
def parse_triples(output_text: str) -> List[Dict]:
"""解析三元组文本为结构化数据"""
triples = []
lines = output_text.strip().split('\n')
for i, line in enumerate(lines):
if '<SEP>' not in line:
continue
parts = line.split(' <SEP> ')
if len(parts) != 3:
continue
head, relation, tail = parts
# 解析实体格式:[TYPE]名称(描述)
head_match = re.match(r'\[(\w+)\](.*?)\((.*?)\)', head)
tail_match = re.match(r'\[(\w+)\](.*?)\((.*?)\)', tail)
if head_match and tail_match:
triple = {
'id': i,
'head': {
'id': f"entity_{i}_head",
'name': head_match.group(2).strip(),
'type': head_match.group(1),
'description': head_match.group(3),
'label': f"{head_match.group(2)} ({head_match.group(1)})"
},
'relation': relation,
'tail': {
'id': f"entity_{i}_tail",
'name': tail_match.group(2).strip(),
'type': tail_match.group(1),
'description': tail_match.group(3),
'label': f"{tail_match.group(2)} ({tail_match.group(1)})"
}
}
triples.append(triple)
return triples4.2 知识图谱构建
基于解析的三元组,我们构建知识图谱网络:
python
import hashlib
from pyvis.network import Network
import webbrowser
def truncate_text(text, max_length=15):
"""截断长文本,添加省略号"""
if len(text) <= max_length:
return text
return text[:max_length] + "..."
def get_entity_hash(name):
return name
"""为实体生成哈希键,确保相同实体得到相同哈希"""
# 对名称进行标准化处理
clean_name = name.strip()
# 生成哈希值(使用MD5,取前8位)
hash_obj = hashlib.md5(clean_name.encode())
hash_hex = hash_obj.hexdigest()
# 返回哈希键
return f"{hash_hex}"
def get_shape_by_type(entity_type):
# 根据类型设置不同形状
if entity_type == 'PERSON':
shape = 'dot'
size = 25
elif entity_type == 'ORG':
shape = 'diamond'
size = 30
elif entity_type == 'LOC':
shape = 'triangle'
size = 30
else: # STATEMENT
shape = 'square'
size = 35
shape="dot"
return shape,size
# 提取[]中的内容
def extract_brackets_content(text):
print(text)
"""提取[]括号中的内容"""
pattern = r'\[(.*?)\]' # 匹配[]中的内容,非贪婪匹配
matches = re.findall(pattern, text)
if len(matches) == 0:
return text
return matches[0]
def build_network(triples):
# 创建网络图
net = Network(height="600px", width="100%", directed=True)
# 节点颜色映射
node_colors = {
'PERSON': '#FF6B6B',
'ORG': '#4ECDC4',
'LOC': '#FFD166',
'STATEMENT': '#95D2B3'
}
# 按名称合并相同实体
# 使用名称作为节点的唯一标识
entity_id_map = {} # 映射:name -> node_id
# 先收集所有实体
all_entities = set()
for item in triples:
head_entity_name = item['head']['name']
tail_entity_name = item['tail']['name']
head_entity_id = item['head']['id']
tail_entity_id = item['tail']['id']
head_entity_type = item['head']['type']
tail_entity_type = item['tail']['type']
if head_entity_name not in all_entities:
all_entities.add(head_entity_name)
entity_id_map[get_entity_hash(head_entity_name)] = head_entity_id
shape,size=get_shape_by_type(head_entity_type)
if head_entity_type=="STATEMENT":
head_entity_name=extract_brackets_content(head_entity_name)
net.add_node(
head_entity_id,
label=head_entity_name,
title=f"{head_entity_name}<br>类型: {head_entity_type}",
color=node_colors.get(head_entity_type, '#CCCCCC'),
shape=shape,
size=size
)
if tail_entity_name not in all_entities:
all_entities.add(tail_entity_name)
entity_id_map[get_entity_hash(tail_entity_name)] = tail_entity_id
shape,size=get_shape_by_type(tail_entity_type)
if tail_entity_type=="STATEMENT":
tail_entity_name=extract_brackets_content(tail_entity_name)
net.add_node(
tail_entity_id,
label=tail_entity_name,
title=f"{tail_entity_name}<br>类型: {tail_entity_type}",
color=node_colors.get(tail_entity_type, '#CCCCCC'),
shape=shape,
size=size
)
# 添加边
for item in triples:
head_name = item['head']['name']
tail_name = item['tail']['name']
head_id = entity_id_map[get_entity_hash(head_name)]
tail_id = entity_id_map[get_entity_hash(tail_name)]
net.add_edge(
head_id,
tail_id,
label=item['relation'],
arrows='to'
)
return net5. 知识图谱可视化
5.1 可视化设计原则
我们设计了多层次的可视化方案:
- 节点编码:不同实体类型使用不同颜色和形状
- 关系可视化:不同类型的关系使用不同线型和颜色
- 时间维度:通过节点大小、颜色深浅表示时间先后
- 重要性排序:通过节点中心性计算,突出关键实体
5.2 交互式可视化实现
使用PyVis库实现交互式知识图谱可视化:
python
#可视化单个数据
net=build_network(triples_list[2])
# 保存HTML文件
net.save_graph("knowledge_graph.html")
# 在浏览器中打开
webbrowser.open("knowledge_graph.html")
print("\n🌐 已在浏览器中打开知识图谱")5.3 可视化效果展示
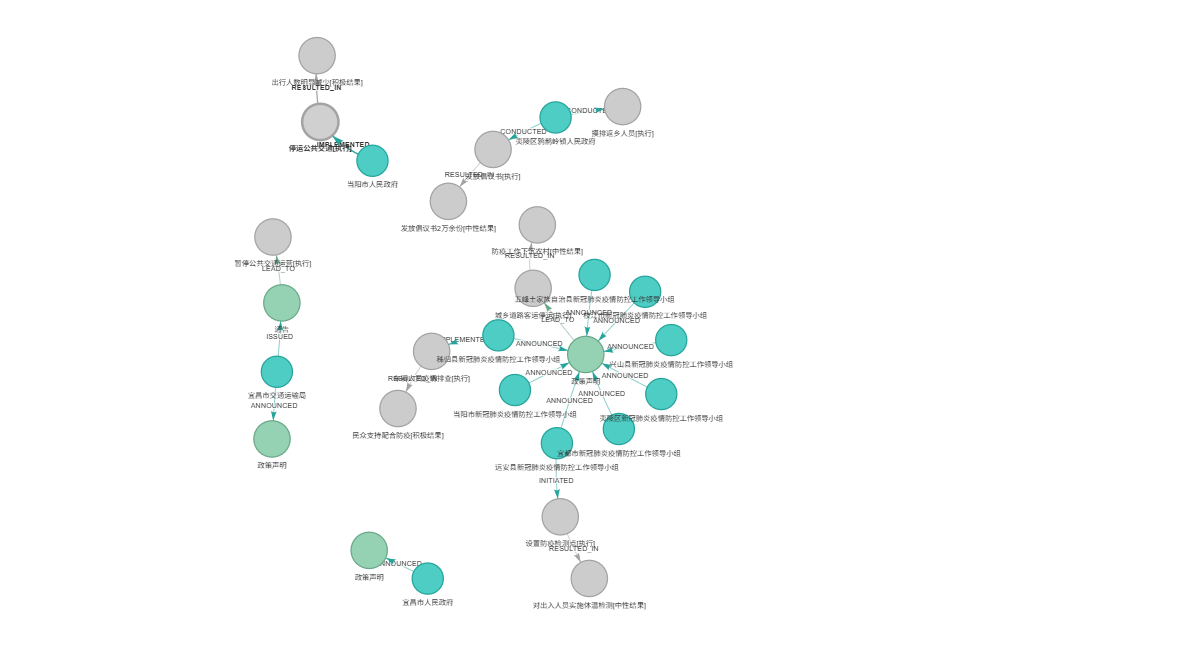
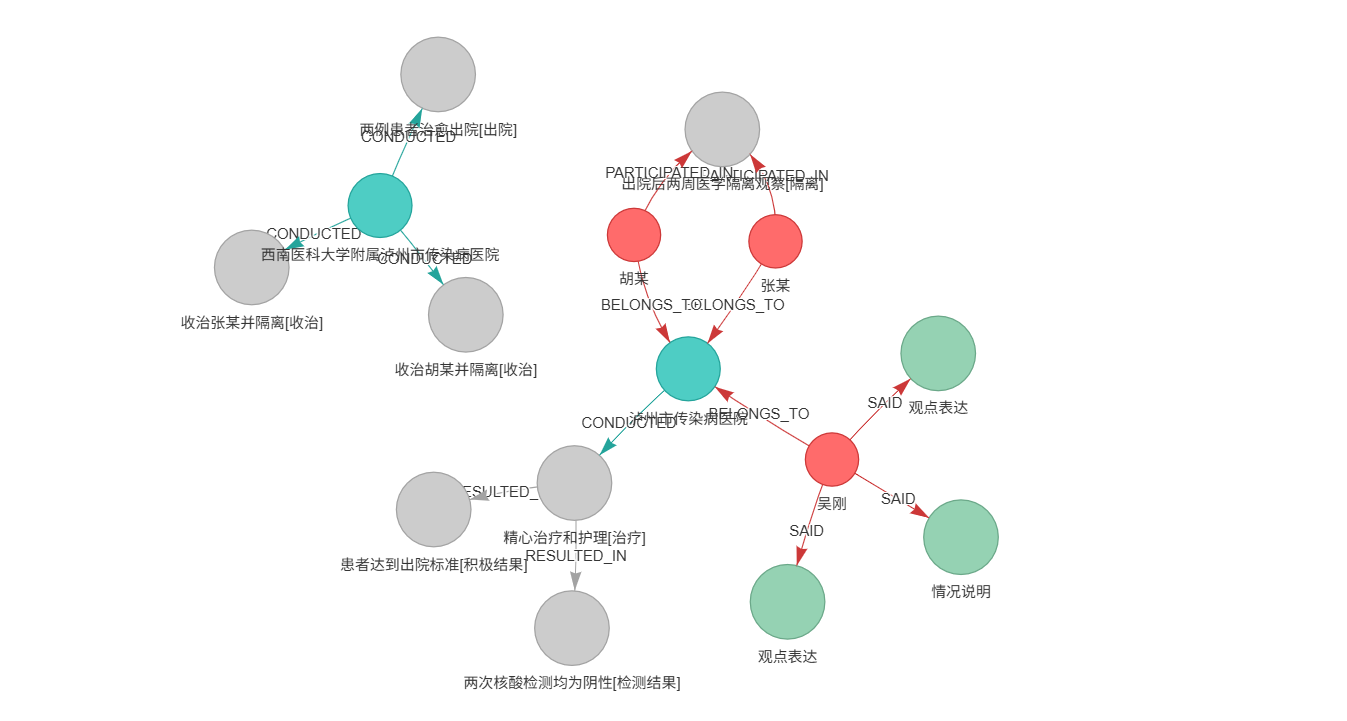
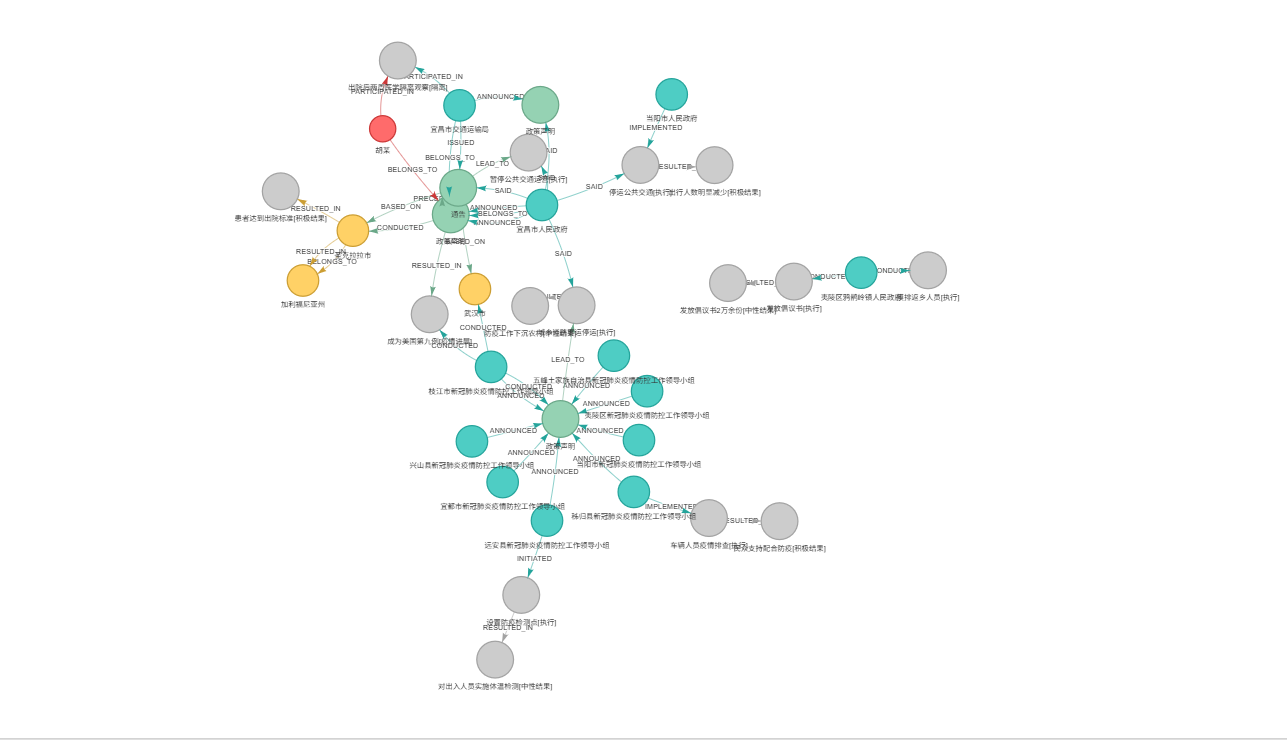
附录:代码资源
完整代码已开源在GitHub:https://github.com/xy200303/PERSIA
核心文件结构
C:.
│ config.yaml
│ examples.py
│ knowledge_graph.html
│ PERSIA实体抽取.py
│ requirements.txt
│ 大模型知识图谱抽取.ipynb
├─.idea
│ │ .gitignore
│ │ misc.xml
│ │ modules.xml
│ │ workspace.xml
│ │ 突发公共事件抽取.iml
│ │
│ └─inspectionProfiles
│ profiles_settings.xml
├─config
│ │ config.py
│ │ __init__.py
│ │
│ └─__pycache__
│ config.cpython-311.pyc
│ __init__.cpython-311.pyc
│
├─dataset
│ sentences.csv
│
├─lib
│ ├─bindings
│ │ utils.js
│ │
│ ├─tom-select
│ │ tom-select.complete.min.js
│ │ tom-select.css
│ │
│ └─vis-9.1.2
│ vis-network.css
│ vis-network.min.js
│
├─llm
│ │ client.py
│ │ __init__.py
│ │
│ └─__pycache__
│ client.cpython-311.pyc
│ __init__.cpython-311.pyc
│
├─logs
├─models
│ │ __init__.py
│ │
│ └─__pycache__
│ __init__.cpython-311.pyc
│
├─outputs
│ └─file
└─prompts
│ __init__.py
│
└─__pycache__
__init__.cpython-311.pyc快速开始
bash
# 安装依赖
pip install -r requirements.txt
# 运行示例
python PERSIA实体抽取.py本博客介绍了PERSIA框架的理论基础、技术实现和应用案例。希望通过这个框架,能够为突发公共事件的分析和理解提供新的工具和思路。欢迎在评论区交流讨论!