目录
[1.1 MySQL更新操作的底层原理](#1.1 MySQL更新操作的底层原理)
[1.2 多表更新的锁机制分析](#1.2 多表更新的锁机制分析)
[2.1 标准SQL:2003语法](#2.1 标准SQL:2003语法)
[2.2 MySQL特有的多表更新](#2.2 MySQL特有的多表更新)
[2.3 更新顺序的优化器决策](#2.3 更新顺序的优化器决策)
[3.1 层次化数据更新](#3.1 层次化数据更新)
[3.2 图数据更新(邻接关系)](#3.2 图数据更新(邻接关系))
[4.1 执行计划深度分析](#4.1 执行计划深度分析)
[4.2 批量更新策略对比](#4.2 批量更新策略对比)
[4.3 索引设计策略](#4.3 索引设计策略)
[5.1 避免死锁的模式](#5.1 避免死锁的模式)
[5.2 乐观锁与版本控制](#5.2 乐观锁与版本控制)
[6.1 性能监控视图](#6.1 性能监控视图)
[6.2 执行计划缓存分析](#6.2 执行计划缓存分析)
[7.1 更新策略选择总结](#7.1 更新策略选择总结)
[7.2 完整的安全更新流程](#7.2 完整的安全更新流程)
[8.1 MySQL 8.0新特性](#8.1 MySQL 8.0新特性)
[8.2 与应用程序集成模式](#8.2 与应用程序集成模式)

作为后端程序员来说涉及到数据库更新操作,单表直接更新相信大家都可以轻松搞定,但针对复杂的业务常见,有时候需要基于另一张或者几张表表的数据来更新目标表时,许多程序员会面临挑战。是选择低效的循环查询与更新,还是冒险使用可能导致全表扫描或意外数据覆盖的UPDATE...JOIN?多表联合更新操作能高效实现复杂的数据同步与业务规则;但如果使用不当,则可能引发性能瓶颈、死锁甚至数据不一致。今天给来给大家分享一下关于MySQL多表更新JOIN操作相关的实战经验,希望对大家能有所帮助!
一、多表更新技术原理介绍
1.1 MySQL更新操作的底层原理
在深入多表更新之前,有必要理解MySQL单表更新的执行流程:
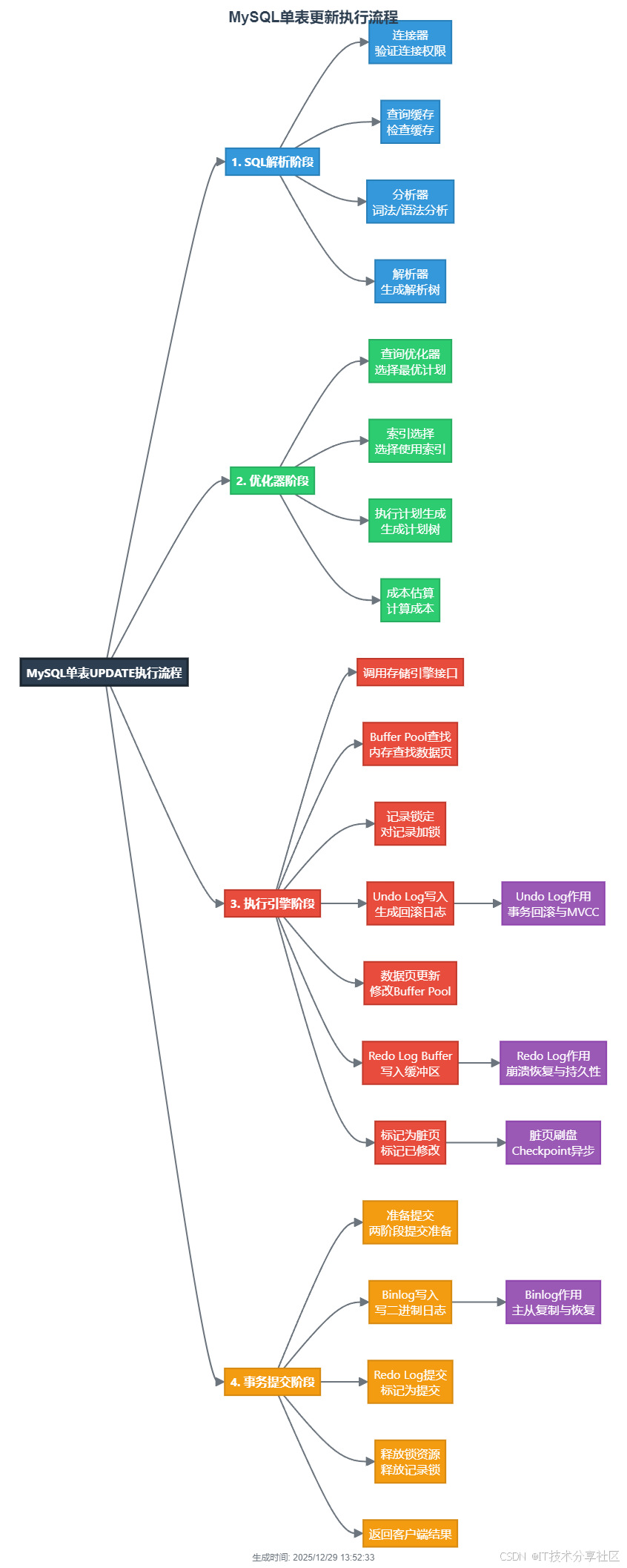
-- 简化的更新过程
1. 解析器(Parser): 解析SQL语句,生成解析树
2. 优化器(Optimizer): 生成执行计划,选择最优索引
3. 执行引擎(Storage Engine):
- 在Buffer Pool中查找数据页
- 写入Undo Log(用于回滚)
- 更新数据页(置为脏页)
- 写入Redo Log(用于崩溃恢复)
4. 提交阶段:
- 写入Binlog(用于主从复制)
- 刷新脏页到磁盘多表更新在此基础上引入了连接处理的复杂性。MySQL采用以下两种主要算法:
嵌套循环连接(Nested Loop Join)
sql
// 伪代码表示执行逻辑
for each row in table1 {
for each row in table2 {
if (join_condition_matches) {
update_target_row();
}
}
}块嵌套循环连接(Block Nested Loop Join)
sql
// 伪代码表示执行逻辑
for each row in table1 {
for each row in table2 {
if (join_condition_matches) {
update_target_row();
}
}
}1.2 多表更新的锁机制分析
多表更新涉及复杂的锁管理,理解这一点对避免死锁至关重要:
sql
-- 查看当前锁信息(需要performance_schema)
SELECT
r.trx_id AS waiting_trx_id,
r.trx_mysql_thread_id AS waiting_thread,
r.trx_query AS waiting_query,
b.trx_id AS blocking_trx_id,
b.trx_mysql_thread_id AS blocking_thread,
b.trx_query AS blocking_query
FROM information_schema.innodb_lock_waits w
INNER JOIN information_schema.innodb_trx b
ON b.trx_id = w.blocking_trx_id
INNER JOIN information_schema.innodb_trx r
ON r.trx_id = w.requesting_trx_id;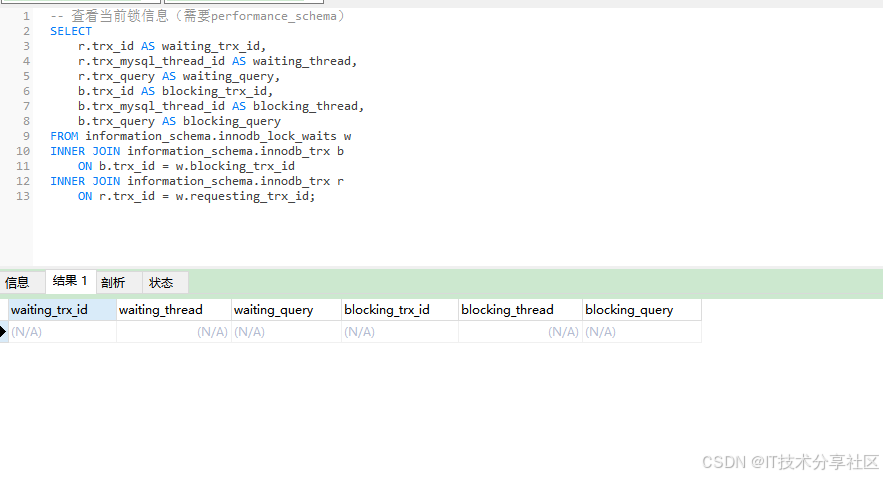
锁升级路径:
-
意向锁(Intention Locks):表级锁,表明稍后将需要行锁
-
记录锁(Record Locks):锁定索引记录
-
间隙锁(Gap Locks):锁定索引记录间的间隙
-
临键锁(Next-Key Locks):记录锁+间隙锁
多表更新时,MySQL按照表在FROM子句中出现的顺序依次加锁,但优化器可能重排序。
二、多表更新语法介绍
2.1 标准SQL:2003语法
sql
-- ANSI标准语法
UPDATE target_table
SET column = value
FROM table1
JOIN table2 ON join_condition
WHERE filter_condition;
-- MySQL简化语法 可读性稍弱 不推荐
UPDATE table1, table2
SET table1.column = table2.column
WHERE table1.id = table2.id;2.2 MySQL特有的多表更新
MySQL支持三种形式的多表更新:
形式1:使用逗号分隔(隐式连接)
sql
UPDATE t1, t2, t3
SET t1.col = t2.col,
t2.col2 = t3.col2
WHERE t1.id = t2.id
AND t2.ref_id = t3.id;
-- 注意:缺少WHERE条件会导致笛卡尔积更新!形式2:使用JOIN语法(显式连接)
sql
UPDATE t1
[INNER|LEFT|RIGHT] JOIN t2 ON join_condition
[INNER|LEFT|RIGHT] JOIN t3 ON join_condition
SET t1.col = expression
WHERE filter_condition;形式3:使用派生表
sql
UPDATE t1
SET t1.col = (
SELECT expression
FROM t2
WHERE t2.id = t1.id
[LIMIT 1] -- 注意:查询数据多行返回会报错
)
WHERE EXISTS (
SELECT 1 FROM t2 WHERE t2.id = t1.id
);2.3 更新顺序的优化器决策
MySQL优化器决定多表更新的执行顺序,考虑因素包括:
sql
-- 查看执行计划
EXPLAIN FORMAT=JSON
UPDATE orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
SET o.status = 'processed'
WHERE c.country = 'US';
-- JSON输出中的关键信息
{
"query_block": {
"ordering_operation": {
"using_filesort": false,
"nested_loop": [
{
"table": {
"table_name": "c",
"access_type": "ref",
"possible_keys": ["idx_country"],
"key": "idx_country",
"rows_examined_per_scan": 1000
}
},
{
"table": {
"table_name": "o",
"access_type": "ref",
"join_type": "inner"
}
}
]
}
}
}三、高级多表更新模式
3.1 层次化数据更新
处理树形结构或层级数据:
主要是更新层级的路径和层级
sql
-- 组织架构表更新示例
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(100),
manager_id INT,
department_id INT,
level INT,
path VARCHAR(1000)
);
-- 更新层次路径(使用递归CTE,MySQL 8.0+)
WITH RECURSIVE emp_hierarchy AS (
-- 锚点:顶级管理者
SELECT
emp_id,
emp_name,
CAST(emp_id AS CHAR(1000)) AS path,
0 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归:下属员工
SELECT
e.emp_id,
e.emp_name,
CONCAT(h.path, ' > ', e.emp_id),
h.level + 1
FROM employees e
INNER JOIN emp_hierarchy h ON e.manager_id = h.emp_id
)
UPDATE employees e
JOIN emp_hierarchy h ON e.emp_id = h.emp_id
SET e.path = h.path,
e.level = h.level;
-- 早期版本替代方案(使用存储过程)
DELIMITER //
CREATE PROCEDURE update_employee_hierarchy()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE current_level INT DEFAULT 0;
-- 创建临时表存储中间结果
CREATE TEMPORARY TABLE emp_temp LIKE employees;
-- 初始化:顶级管理者
INSERT INTO emp_temp
SELECT emp_id, emp_name, manager_id, department_id,
0, CAST(emp_id AS CHAR(1000))
FROM employees
WHERE manager_id IS NULL;
WHILE NOT done DO
SET current_level = current_level + 1;
-- 逐级更新
INSERT INTO emp_temp
SELECT
e.emp_id,
e.emp_name,
e.manager_id,
e.department_id,
current_level,
CONCAT(et.path, ' > ', e.emp_id)
FROM employees e
JOIN emp_temp et ON e.manager_id = et.emp_id
WHERE e.level IS NULL;
-- 检查是否还有未处理的记录
SELECT COUNT(*) INTO done
FROM employees e
WHERE e.level IS NULL;
END WHILE;
-- 批量更新原表
UPDATE employees e
JOIN emp_temp t ON e.emp_id = t.emp_id
SET e.level = t.level,
e.path = t.path;
DROP TEMPORARY TABLE emp_temp;
END//
DELIMITER ;3.2 图数据更新(邻接关系)
sql
-- 社交网络关系更新
CREATE TABLE relationships (
user_id INT,
friend_id INT,
mutual_friends INT,
closeness_score DECIMAL(5,2),
PRIMARY KEY (user_id, friend_id)
);
-- 更新互相关注数量和亲密度
UPDATE relationships r1
JOIN relationships r2 ON r1.user_id = r2.friend_id
AND r1.friend_id = r2.user_id
SET r1.mutual_friends = (
SELECT COUNT(DISTINCT rf.friend_id)
FROM relationships rf
WHERE rf.user_id = r1.user_id
AND rf.friend_id IN (
SELECT rff.friend_id
FROM relationships rff
WHERE rff.user_id = r1.friend_id
)
),
r1.closeness_score = (
0.3 * COALESCE(r1.mutual_friends, 0) +
0.7 * (
SELECT COUNT(*)
FROM interactions i
WHERE (i.user_from = r1.user_id AND i.user_to = r1.friend_id)
OR (i.user_from = r1.friend_id AND i.user_to = r1.user_id)
) / 100.0 -- 标准化
)
WHERE r1.user_id < r1.friend_id; -- 避免重复计算四、性能优化实用技巧
4.1 执行计划深度分析
sql
-- 使用Optimizer Trace分析多表更新
SET optimizer_trace = "enabled=on";
SET optimizer_trace_max_mem_size = 1000000;
-- 执行更新语句
UPDATE large_table lt
JOIN lookup_table lu ON lt.lookup_id = lu.id
JOIN dimension_table dt ON lu.dim_id = dt.id
SET lt.processed = TRUE
WHERE dt.category = 'A'
AND lt.created_at > '2024-01-01';
-- 查看优化器跟踪
SELECT * FROM information_schema.optimizer_trace\G
-- 关键分析点:
-- 1. join_preparation: 连接准备阶段
-- 2. join_optimization: 连接优化决策
-- 3. considered_execution_plans: 考虑的执行计划
-- 4. chosen_execution_plan: 最终选择的计划4.2 批量更新策略对比
策略1:单语句更新(风险较高)
sql
-- 一次性更新所有匹配行
UPDATE big_table bt
JOIN ref_table rt ON bt.ref_id = rt.id
SET bt.status = 'processed'
WHERE rt.batch = '2024Q1';
-- 风险:锁表时间长,undo log膨胀策略2:分页更新(推荐)
sql
-- 使用主键分页
CREATE PROCEDURE batch_update_paginated()
BEGIN
DECLARE batch_size INT DEFAULT 1000;
DECLARE last_id INT DEFAULT 0;
DECLARE max_id INT;
DECLARE rows_updated INT;
SELECT MAX(id) INTO max_id FROM big_table;
WHILE last_id <= max_id DO
START TRANSACTION;
UPDATE big_table bt
JOIN ref_table rt ON bt.ref_id = rt.id
SET bt.status = 'processed'
WHERE bt.id > last_id
AND bt.id <= last_id + batch_size
AND rt.batch = '2024Q1';
SET rows_updated = ROW_COUNT();
-- 记录进度
INSERT INTO update_log
VALUES (NOW(), batch_size, rows_updated);
SET last_id = last_id + batch_size;
-- 短暂提交,释放锁
COMMIT;
-- 控制更新频率
DO SLEEP(0.05);
END WHILE;
END;策略3:分区更新(MySQL 5.7+)
sql
-- 按时间分区
CREATE TABLE orders (
order_id INT,
order_date DATE,
status VARCHAR(20),
PRIMARY KEY (order_id, order_date)
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
-- 分区修剪,只更新特定分区
UPDATE orders
JOIN customers c USING (customer_id)
SET orders.status = 'archived'
WHERE orders.order_date < '2024-01-01'
AND c.country = 'US';
-- 仅扫描p2023分区4.3 索引设计策略
sql
-- 多表更新专用复合索引
CREATE INDEX idx_update_optimized ON orders (
status, -- 更新条件列在前
order_date, -- 范围查询列
customer_id -- 连接列
) INCLUDE (
total_amount, -- 包含列(MySQL 8.0+)
shipping_address -- 避免回表
);
-- 覆盖索引优化
EXPLAIN
UPDATE orders o
JOIN order_items oi ON o.order_id = oi.order_id
SET o.total_items = (
SELECT COUNT(*)
FROM order_items oi2
WHERE oi2.order_id = o.order_id
)
WHERE o.status = 'pending';
-- 如果索引包含(order_id, status),可能使用覆盖索引五、并发控制与锁优化
5.1 避免死锁的模式
sql
-- 死锁示例
-- 事务1:
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 事务2:
UPDATE accounts SET balance = balance - 50 WHERE id = 2;
UPDATE accounts SET balance = balance + 50 WHERE id = 1;
-- 解决方案1:统一更新顺序
CREATE PROCEDURE transfer_funds(
IN from_account INT,
IN to_account INT,
IN amount DECIMAL(10,2)
)
BEGIN
DECLARE first_id INT;
DECLARE second_id INT;
-- 统一按ID排序锁定
IF from_account < to_account THEN
SET first_id = from_account;
SET second_id = to_account;
ELSE
SET first_id = to_account;
SET second_id = from_account;
END IF;
START TRANSACTION;
-- 按顺序加锁
SELECT balance INTO @bal FROM accounts
WHERE id = first_id FOR UPDATE;
SELECT balance INTO @bal FROM accounts
WHERE id = second_id FOR UPDATE;
-- 执行转账
UPDATE accounts SET balance = balance - amount
WHERE id = from_account;
UPDATE accounts SET balance = balance + amount
WHERE id = to_account;
COMMIT;
END;5.2 乐观锁与版本控制
sql
-- 添加版本号列
ALTER TABLE inventory ADD COLUMN version INT DEFAULT 0;
-- 乐观锁更新
UPDATE inventory i
JOIN (
SELECT product_id, warehouse_id, quantity
FROM inventory_changes
WHERE batch_id = 123
) c ON i.product_id = c.product_id
AND i.warehouse_id = c.warehouse_id
SET i.quantity = i.quantity + c.quantity,
i.version = i.version + 1,
i.last_updated = NOW()
WHERE i.version = @expected_version -- 应用程序传入
AND i.quantity + c.quantity >= 0; -- 防止负库存
-- 检查冲突
IF ROW_COUNT() = 0 THEN
-- 版本冲突,需要重试或报错
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Concurrent modification detected';
END IF;六、高级监控与调试
6.1 性能监控视图
sql
-- 实时监控多表更新性能
CREATE VIEW update_performance_monitor AS
SELECT
esh.EVENT_ID,
esh.EVENT_NAME,
esh.TIMER_WAIT / 1000000000 AS duration_sec,
esh.SQL_TEXT,
esh.NESTING_EVENT_ID,
est.THREAD_ID,
est.PROCESSLIST_INFO AS current_query
FROM performance_schema.events_statements_history esh
LEFT JOIN performance_schema.threads est
ON esh.THREAD_ID = est.THREAD_ID
WHERE esh.SQL_TEXT LIKE 'UPDATE%JOIN%'
AND esh.EVENT_NAME = 'statement/sql/update'
ORDER BY esh.TIMER_START DESC
LIMIT 20;
-- 锁等待分析
CREATE VIEW lock_wait_analysis AS
SELECT
r.trx_id AS waiting_trx,
r.trx_state AS waiting_state,
TIMEDIFF(NOW(), r.trx_started) AS waiting_duration,
r.trx_query AS waiting_query,
b.trx_id AS blocking_trx,
b.trx_query AS blocking_query,
l.lock_table AS locked_table,
l.lock_index AS locked_index,
l.lock_type AS lock_type,
l.lock_mode AS lock_mode,
l.lock_data AS lock_data
FROM information_schema.innodb_lock_waits w
JOIN information_schema.innodb_trx b
ON b.trx_id = w.blocking_trx_id
JOIN information_schema.innodb_trx r
ON r.trx_id = w.requesting_trx_id
JOIN information_schema.innodb_locks l
ON w.requested_lock_id = l.lock_id;6.2 执行计划缓存分析
sql
-- 使用Performance Schema分析执行计划
SELECT
sql_text,
digest_text,
count_star AS executions,
avg_timer_wait/1000000000 AS avg_sec,
max_timer_wait/1000000000 AS max_sec,
sum_rows_affected AS total_rows_affected,
sum_created_tmp_tables AS temp_tables_created
FROM performance_schema.events_statements_summary_by_digest
WHERE digest_text LIKE 'UPDATE%JOIN%'
AND count_star > 0
ORDER BY sum_timer_wait DESC
LIMIT 10;
-- 具体查询的详细统计
SELECT
event_name,
timer_wait/1000000000 AS duration_sec,
lock_time/1000000000 AS lock_time_sec,
rows_examined,
rows_affected,
created_tmp_tables,
created_tmp_disk_tables,
select_scan,
no_index_used
FROM performance_schema.events_statements_history_long
WHERE sql_text LIKE '%UPDATE orders JOIN customers%'
ORDER BY timer_start DESC
LIMIT 5;七、生产环境最佳实践
7.1 更新策略选择总结
|---------|----------------|--------------|
| 场景 | 推荐方案 | 注意事项 |
| 小批量实时更新 | 单语句UPDATE+JOIN | 确保WHERE条件有索引 |
| 大批量历史数据 | 分页更新+事务控制 | 监控锁等待,控制批大小 |
| 跨表同步 | 触发器+版本控制 | 注意循环触发,版本冲突 |
| 复杂业务逻辑 | 存储过程+临时表 | 实现幂等性,添加重试机制 |
| 高并发场景 | 乐观锁+队列处理 | 降低锁竞争,异步处理 |
7.2 完整的安全更新流程
sql
-- 安全更新框架
DELIMITER //
CREATE PROCEDURE safe_multi_table_update(
IN update_condition VARCHAR(1000),
IN batch_limit INT
)
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION, SQLWARNING
BEGIN
ROLLBACK;
-- 记录错误
INSERT INTO update_errors
VALUES (NOW(), update_condition, ERROR_MESSAGE());
-- 通知管理员
-- CALL send_alert('Update failed', ERROR_MESSAGE());
RESIGNAL;
END;
-- 1. 验证更新条件
IF NOT is_valid_condition(update_condition) THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Invalid update condition';
END IF;
-- 2. 创建备份
START TRANSACTION;
CREATE TABLE backup_before_update AS
SELECT * FROM target_table
WHERE 1=0; -- 仅复制结构
-- 3. 执行分页更新
SET @offset = 0;
REPEAT
START TRANSACTION;
-- 使用动态SQL构建更新
SET @sql = CONCAT(
'UPDATE target_table t ',
'JOIN related_table r ON t.ref_id = r.id ',
'SET t.status = ''updated'' ',
'WHERE ', update_condition, ' ',
'LIMIT ', batch_limit, ' OFFSET ', @offset
);
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 记录受影响行
SET @rows_affected = ROW_COUNT();
INSERT INTO update_audit
VALUES (NOW(), @rows_affected, update_condition);
COMMIT;
SET @offset = @offset + batch_limit;
-- 控制节奏
IF @rows_affected > 0 THEN
DO SLEEP(0.1);
END IF;
UNTIL @rows_affected = 0 END REPEAT;
-- 4. 验证一致性
CALL verify_data_consistency();
-- 5. 清理临时数据
DROP TABLE backup_before_update;
-- 成功日志
INSERT INTO operation_log
VALUES (NOW(), 'multi_table_update', 'SUCCESS', update_condition);
END//
DELIMITER ;八、未来趋势与扩展
8.1 MySQL 8.0新特性
sql
-- 通用表表达式(CTE)更新
WITH cte_updates AS (
SELECT
o.order_id,
SUM(oi.quantity * oi.unit_price) as new_total
FROM orders o
JOIN order_items oi USING (order_id)
WHERE o.status = 'pending'
GROUP BY o.order_id
)
UPDATE orders o
JOIN cte_updates c ON o.order_id = c.order_id
SET o.total_amount = c.new_total,
o.updated_at = NOW();
-- 窗口函数在更新中的应用
UPDATE orders o
JOIN (
SELECT
order_id,
SUM(total_amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as running_total
FROM orders
) rt ON o.order_id = rt.order_id
SET o.cumulative_total = rt.running_total
WHERE o.order_date > '2024-01-01';
-- JSON字段的跨表更新
UPDATE products p
JOIN product_metadata pm ON p.product_id = pm.product_id
SET p.metadata = JSON_SET(
COALESCE(p.metadata, '{}'),
'$.supplier_info',
JSON_OBJECT(
'name', pm.supplier_name,
'rating', pm.supplier_rating
)
)
WHERE pm.supplier_id IS NOT NULL;8.2 与应用程序集成模式
sql
# Python中使用SQLAlchemy实现安全的多表更新
from sqlalchemy import create_engine, text
from contextlib import contextmanager
import logging
class MultiTableUpdater:
def __init__(self, connection_string):
self.engine = create_engine(connection_string,
pool_size=20, max_overflow=0)
self.logger = logging.getLogger(__name__)
@contextmanager
def safe_update_session(self):
"""安全更新上下文管理器"""
connection = self.engine.connect()
transaction = connection.begin()
try:
yield connection
transaction.commit()
self.logger.info("更新成功提交")
except Exception as e:
transaction.rollback()
self.logger.error(f"更新失败,已回滚: {e}")
raise
finally:
connection.close()
def paginated_update(self, batch_size=1000, max_retries=3):
"""带重试的分页更新"""
for attempt in range(max_retries):
try:
with self.safe_update_session() as conn:
# 使用服务器端游标避免内存溢出
cursor = conn.execute(text("""
SELECT id FROM large_table
WHERE status = 'pending'
ORDER BY id
"""))
while True:
batch = cursor.fetchmany(batch_size)
if not batch:
break
ids = [row[0] for row in batch]
# 执行批量更新
update_stmt = text("""
UPDATE large_table lt
JOIN reference_table rt ON lt.ref_id = rt.id
SET lt.status = 'processed'
WHERE lt.id = ANY(:ids)
AND rt.valid = TRUE
""")
result = conn.execute(update_stmt, {'ids': ids})
self.logger.info(
f"批次 {attempt+1}: 更新了 {result.rowcount} 行"
)
# 短暂暂停,减轻数据库压力
import time
time.sleep(0.05)
break # 成功完成,退出重试循环
except Exception as e:
self.logger.warning(f"尝试 {attempt+1} 失败: {e}")
if attempt == max_retries - 1:
raise
# 指数退避重试
time.sleep(2 ** attempt)
# 使用示例
updater = MultiTableUpdater('mysql://user:pass@localhost/db')
updater.paginated_update(batch_size=500)九、总结
多表联合更新是MySQL中强大但复杂的特性,中级开发者在掌握其基本用法后,应深入理解:
-
执行原理:了解MySQL如何执行多表更新,包括连接算法、锁机制
-
性能优化:掌握索引设计、执行计划分析、分批处理等技巧
-
并发控制:学会避免死锁、处理版本冲突
-
监控调试:使用Performance Schema等工具进行性能分析
-
安全实践:建立完整的备份、验证、回滚机制
随着业务复杂度增加,多表更新的需求会更加频繁。需要建立数据库更新操作规范,包括:
-
所有生产环境更新必须经过评审
-
重大更新操作必须有回滚方案
-
定期review更新SQL的性能模式
-
建立更新操作的监控报警机制
以上内容是关于MySQL多表更新JOIN操作相关的内容分享。大家如果日常有什么问题的话,欢迎评论区沟通交流。