| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | RECAP |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | A VLA that Learns from Experience |
| 4 | 创新点 | 1:优势调节 1:优势调节 作者没有改变 VLA(视觉-语言-动作)模型的底层逻辑,而是改变了它的输入方式 。在训练阶段,机器人尝试过很多次,有成功也有失败,当机器人看到图片并且做了一个正确的动作,就给这个数据加上一个postive的标签。在推理阶段,在模型预测动作之前,插入了一个文本标签:"Advantage: positive" 或 "Advantage: negative" (摄像头画面 + 任务:做咖啡 + 文本标签:优势:正向)。这种设计让模型学会了关联"动作"与"结果好坏"。在推理(执行)时,只要强行输入 positive 标签,模型就会自动开启"学霸模式",只输出那些能导致成功的动作。 相比传统的强化学习,这种方法不需要复杂的数学梯度计算,对大模型极其友好且稳定。 2:异构数据 传统的机器人学习要么只用专家演示,要么只用自主探索,RECAP 首次证明了将三种截然不同的数据融合在一起的巨大威力。专家演示 (Demonstrations): 提供基础的"怎么做"的知识。 自主尝试 (Autonomous Experience): 机器人自己乱试,提供大量的"反面教材",让模型知道什么动作会导致失败。 专家干预 (Interventions): 在机器人出错时人类出手纠正。这部分数据被视为"救命药",专门教机器人如何从错误状态中恢复。 3:离散分布价值函数 为了让 RL 训练不崩溃,作者在价值函数(Critic)上做了工程优化,将价值预测从"回归问题"转变为"分类问题"。它将任务的回报(Return)切分成 201 个"桶"(Bins)。模型不是预测一个分数,而是预测得分落在哪个桶里的概率。 这种 Distributional RL(分布强化学习) 极大地提高了大规模 VLA 模型在真实世界中训练的鲁棒性,有效避免了预测分数大幅波动导致的模型发散。 4:从"模仿"到"优化" 证明了 RL 可以显著提升 VLA 的吞吐量 ,之前的模型大多只能"模仿"人类,而人类操作机器人往往很慢。RECAP 通过 RL 的奖励机制(每多走一步扣一分),逼迫机器人学会了**"抄近路"**。在咖啡任务和折衣服任务中,机器人动作的流畅度和速度翻倍,证明了 RL 是让机器人从"实验室玩具"走向"工厂劳动力"的必经之路。 |
| 5 | 引用量 | 把复杂的强化学习转化成了一个"带标签的监督学习"问题,将强化学习带入真实世界的vla训练。 通过给大模型增加一个'学霸标签'(优势调节),RECAP 成功地让机器人在真实世界中,利用人类的偶尔点拨和自己的反复试错,实现了从'笨拙模仿'到'高效专家'的跨越。 |
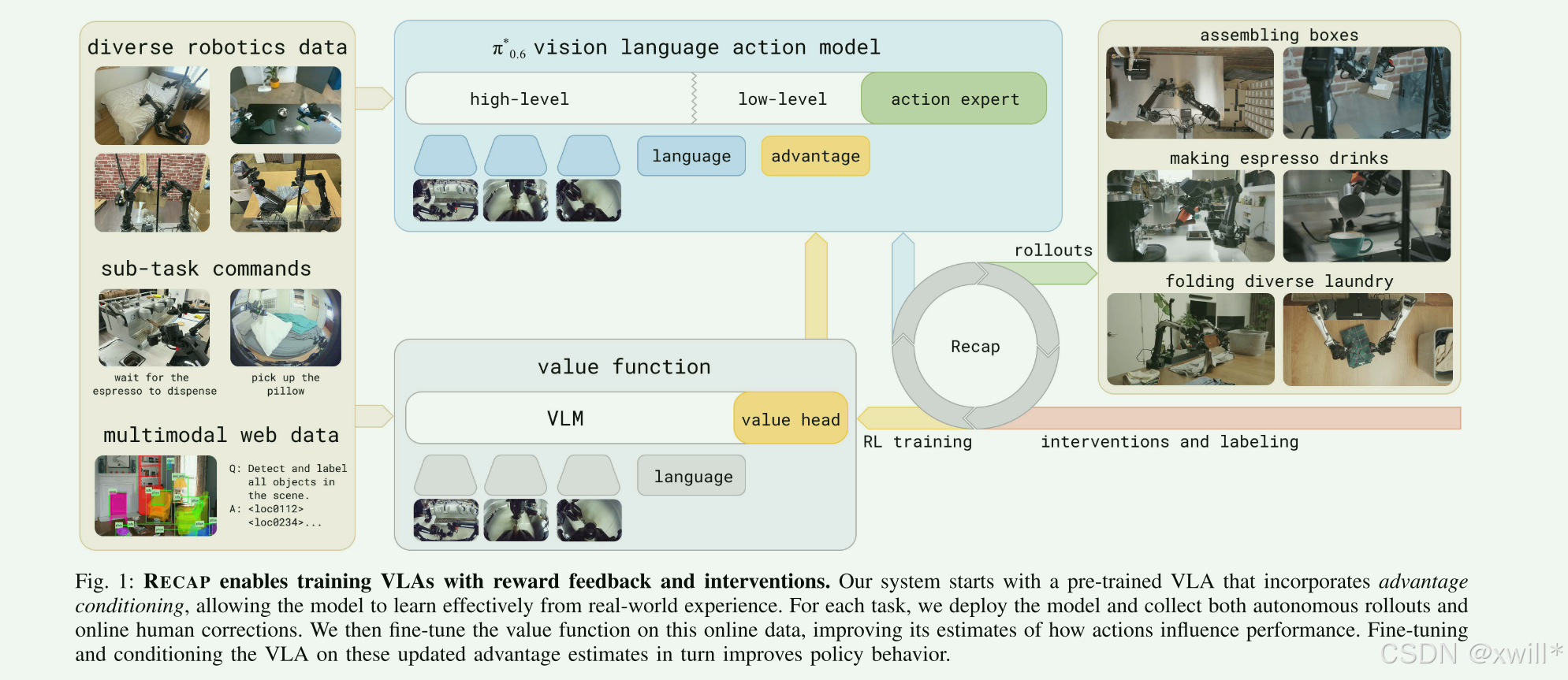
一:提出问题
这篇论文的核心在于解决**具身智能机器人如何"越用越聪明"**的问题。目前的 VLA 模型大多依赖模仿学习(BC),即单纯模仿人类的动作,但通过这篇论文提出的 RECAP 方法,机器人可以通过"练习"和"纠错"来进化。其主要是如何混合使用三种不同质量的数据集来训练机器人。
-
演示数据 (Demonstrations): 传统的完美人类操作数据。
-
在线自主数据 (On-policy Data): 机器人自己尝试做任务时产生的数据(可能有成功,也有失败)。
-
专家干预数据 (Interventions): 这是最关键的一点。当机器人在自主尝试过程中犯错时,人类专家通过远程操作"接管"并修正它的动作。RECAP 将这种修正视为极其宝贵的学习信号。
"**优势条件化" (Advantage Conditioning) :**简单来说,这是告诉模型:"这就叫做得好,那叫做得差"。模型不仅仅学习"动作",还学习评估每个动作的"优势"(Advantage)。
单纯靠模仿人类,机器人的上限就是人类的操作水平。但如果通过练习(RL),机器人可以"超越人类远程操作的速度和稳定性"。本文提出了 RECAP,这是一种能够让 VLA 模型在训练流程的各个阶段(从预训练一直到基于自主执行数据的训练)都能融合奖励反馈的方法。
RECAP 的工作流:
-
预训练 (Pre-training): 先用离线 RL 练一个底子很好的通用模型。
-
微调 (Finetuning): 针对具体任务(如叠衣服)用演示数据微调。
-
自主练习 (Autonomous Execution): 机器人自己去试。(也是从另一个角度解决了大模型难以进行RL的情况)
-
反馈机制:
-
稀疏奖励 (Sparse Reward): 做完了告诉它"成功"还是"失败"。
-
专家干预 (Interventions): 就像学车时教练帮你扶方向盘,这被视为极其高质量的纠错信号。
-
π0.6∗模型: 它是在 π0.6(基础版)上改的。核心改动是加入了 Advantage Conditioning(优势条件化)。模型在输入时,多接收一个信号,告诉它"我要你做一个高优势(成功率高)的动作"。因为模型在训练时见过"高优势动作"和"低优势动作",推理时我们只要强制要求它输出"高优势动作",它就能表现得更好。
二:解决方案
2.1 预备知识
大多数经典算法(如 AWR, CRR)得出的最优策略公式是带有指数项的:exp(A/β)。本文引入了一个结论,最优策略 = 原策略 ×"这个动作能改进结果的概率" 。也就是说,作者不直接引用指数,而是采用改进概率 p (I ∣A )。与其计算复杂的指数权重,不如把问题简化为一个"这个动作比原来好的概率有多大"的问题。
-
计算动作的优势 A。
-
如果 A 很高,说明这个动作改进的概率很大。
-
训练新模型 π**θ 时,让它尽可能模仿这些高改进概率的动作(即最小化 KL 散度)。
只要能算准优势 A ,并且让模型去模仿那些 A 比较高的动作 (这就是公式最后的 minK**L 的含义),数学上就能保证新模型 π ^ 一定比老模型 πref 强。这就是为什么机器人在家里自己练几天(收集数据、算优势、重训练),就能越做越好的原因。
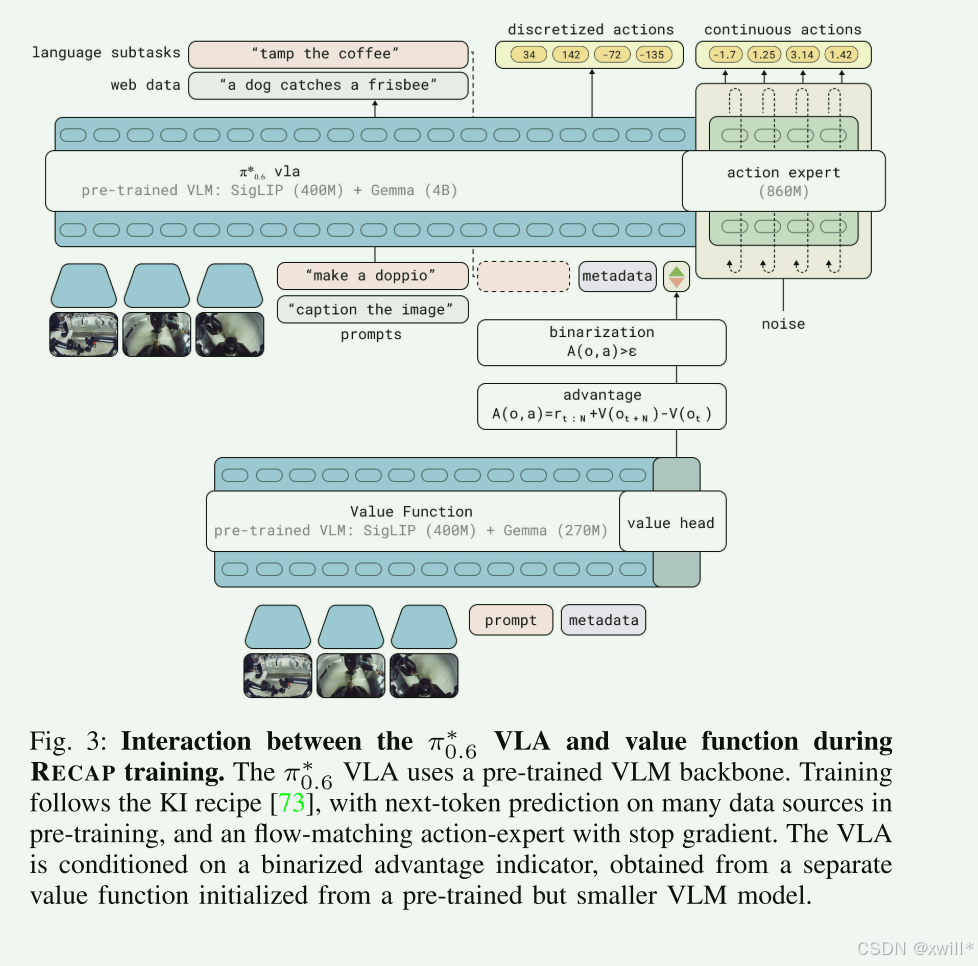
2.2RL WITH EXPERIENCE AND CORRECTIONS VIA ADVANTAGE-CONDITIONED POLICIES (RECAP)
1.价值函数(充当裁判员的角色)
传统的价值函数通常是一个回归问题,输入状态,直接输出一个分数(比如预测你会得 85 分)。RECAP 不直接输出一个分数,而是输出一个概率分布 (直方图)。比如:它会说"有 10% 的概率得 0 分,80% 的概率得 100 分"。直接预测分数的回归(Regression)在深度学习中往往不稳定。而预测概率分布本质上是一个分类问题(这里分成了 201 个类别/桶),使用交叉熵损失函数,训练起来极其稳定。在机器人任务中,结果往往是双峰的------要么成功(满分),要么失败(零分)。用平均值(比如 50 分)来代表这种状态是不准确的,分布函数能准确表达这种"要么成要么败"的不确定性。
蒙特卡洛方法就是"事后诸葛亮"。机器人做完一整套动作(比如倒了一杯咖啡),我们看到了结果(成功了,回报是 1;或者洒了,回报是 0)。然后我们拿着这个最终结果,回过头去告诉刚才经历的每一个状态:"你当时那个状态,最终导致了成功/失败"。
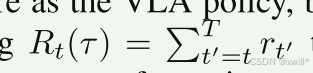
这个公式就是指从当前时刻一直加到最后的总分。虽然这种方法没有偏差,但是方差比较大,数据利用率很低。具有训练稳定的特点,在理论上不是最优的(Less optimal),但在工程上它简单、好用,而且效果已经比单纯的模仿学习好得多了。但是存在必须等任务结束才能算分,数据利用率稍低的问题。
为了让巨大的 VLA 模型能进行强化学习,作者放弃了复杂的、容易不稳定的 Q-learning,转而使用将"价值预测"转化为"多分类问题"**的蒙特卡洛方法。虽然这听起来不那么"先进",但在数万小时的真实机器人数据上,这种方法的鲁棒性(Reliability)才是成功的关键。
2.通过优势调节进行策略提取
当拥有价值函数之后,需要一种方法来训练一个改进的策略,这个过程就叫测量提取。以前的方法(加权法),如果机器人做错了,这个数据的权重就设为 0。这意味着模型根本没见过错误 。结果是:机器人一旦在现实中犯了一点小错,它不知道该怎么挽救,因为它只学过完美的路线。RECAP 的调节法:它把所有动作都喂给模型,但打上标签。模型学会了区分好坏。更重要的是,它学会了错误动作会导致什么后果,从而在逻辑上更"懂"这个任务。
CFG 本来是图像生成(如 DALL-E 或 Stable Diffusion)中用来控制图片内容的技巧。 RECAP 中 :训练时:模型同时学习"普通动作"和"好动作(优势动作)"。推理时(Runtime) :研究者给模型下死命令------"请假设 *I*=1(我要最好的动作)来进行输出"。从而模型会自动从它庞大的记忆库中,提取出那些被标注为"高优势"的动作模式来执行。
现在的顶尖机器人模型(如 RT-Slot 或 π 系列)不再是简单的分类器,而是生成式模型。传统的强化学习(如 PPO)需要计算 log**P (a )。对于 Diffusion 这种复杂的生成过程,这个值极难计算。RECAP 的优势 :它本质上还是监督学习(Supervised Learning) 。它只是在输入端多加了一个 I 变量。无论你的动作生成架构多复杂(是扩散模型还是流匹配),只要能做监督学习,就能用 RECAP。
RECAP 不通过"删掉差生"来进步,而是通过"给差生和优等生贴标签"来进步。训练结束后,我们只让"优等生模式"下的机器人出来干活。这种方法不仅稳定,而且能兼容最先进的 AI 架构(如流匹配)。
3.方法总结

上边的算法伪代码展示了完整的方法概述,本文的方法完全由三个子程序定义,1,通过自主尝试(Autonomous Rollouts) 收集数据(可选专家的纠正性干预);2.根据公式 (1) 训练价值函数 ;3.根据公式 (3) 训练策略。
其实也就是,第一步,让机器人自己去实战,然后第二部让机器人对自己做的实战的所有的动作进行复盘打分。最后就是进行自我进化,策略网络拿着带分数的动作重新学习。如此经过训练回答道比人类演示更好的效果。
普通的 VLA 模型输入是 (图像, 语言指令)。 π ∗0.6 的核心改动是在输入端增加了一个"开关"位------*I**t*(优势指示符)。
-
训练时 :给模型喂数据时,如果这个动作好,I**t 设为 1;不好,设为 0。
-
部署时 :人为地把 I**t 恒定设为 1。这就像是给模型下了一个暗示:"假装你现在是世界冠军,请给出你认为最正确的动作。"
为什么要用VLM初始化价值函数?论文提到的价值函数(打分员)也是由 VLM(视觉语言模型)初始化的。这非常聪明:打分员必须先看懂什么是"折好的衣服",什么是"弄乱的衣服"。VLM 已经具备了常识,用它来做价值评估的基础,比从零开始训练一个评估器要快得多,也准得多。
3.1*π*0.6 模型
模型能够达到比较好的效果,总的来说有一下的特点:
1.知识隔离训练:如果你让一个模型同时学"说话(语义推理)"和"动手动脚(精确控制)",这两者需要的特征空间是不一样的。混在一起训练,精确控制往往会干扰语义逻辑。知识隔离就像在模型内部打了一道"防火墙"。模型主体学常识和逻辑,而专门的"动作专家"学控制。通过梯度截断,动作专家怎么折腾都不会把主体模型的逻辑带偏。
2.分块动作与高频控制:模型不是一次只输出一个动作指令(如"向左移 1 厘米"),而是一次输出一串序列(比如未来 10 步的动作)。这串动作以每秒 50 次的速度执行。这保证了机器人动作的流畅性,不会像老式机器人那样一顿一顿的。
3.分层推理:模型先输入图片,然后生成文字子任务最后执行动作。这个文字 ℓ^ 充当了"思维链"。它让动作专家知道,接下来的这串动作是为了"走向咖啡机"服务的。这种分层让模型在处理长距离、复杂任务时极其稳定。
4.流匹配:能学习非常复杂的动作分布。它能让机器人学会"绕过障碍物"这种带有曲线轨迹的平滑动作,而不是生硬的直线。
3.2 From π0.6 to π∗ 0.6 with advantage conditioning
作者没有修改复杂的神经网络底层结构,而是直接利用了大模型(Gemma 3)强大的语言理解能力 。在模型准备输出动作之前,强行在它的"思维链"里插一句话。这就像是在考试前,你在考生的耳边小声说:"接下来的这道题,请按满分作文的标准写。"因为模型在训练时见过什么是"Positive(正向)"动作,什么是"Negative(负向)"动作,当你给它这个 Prompt 时,它内部的神经元权重会自动转向那些高分的、成功的动作模式。
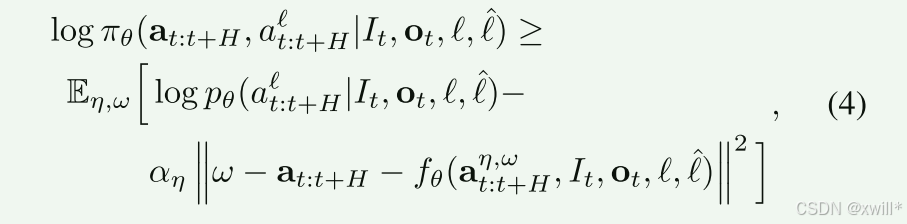
公式4的核心就是解决机器人动作的平滑度,系统会给成功的动作轨迹添加一点随机噪声,模型的目标是学会如何"拨乱反正",即把带噪声的乱动作还原成那个"优势为正"的精准动作。这让机器人不仅学会了"做什么",还学会了在动作发生轻微偏移(受到干扰)时,如何顺滑地回到正确轨道上。训练时,有时给"Advantage"标签,有时不给。通过对比"有标签输出"和"无标签输出"的差异,我们可以放大 这种差异。比如:如果有标签比无标签在某个方向上多移了 1 厘米,我们就让它在这个方向上再多移 0.5 厘米。这种"推力"能让模型表现出超越数据集中最高水平的极致性能。
3.3Reward definition and value function training
通常我们训练机器人,可能想给它细致的奖励:比如"离杯子近了给 1 分"。但这太难调优了。 RECAP 用的逻辑叫 "Distance-to-Success"(距离成功的距离) :在这种机制下,机器人为了让总分最高(也就是让减分最少),它必须学会用最少的步数、最快的速度去完成任务 。这自动解决了机器人动作拖泥带水的问题。如果机器人把杯子摔碎了,或者任务超时了,它会得到一个巨大的负分(−Cfai**l )。这确保了在计算"优势值(Advantage)"时,任何导致失败的动作都会被标记为 "Advantage: negative"。模型通过对比"快要成功(高分)"和"彻底失败(极低分)"的画面,能极其敏锐地学会避开那些危险动作。
跨任务归一化:作者根据任务的最大长度进行缩放,让所有任务的分数都落在 0 到 −1 之间。这样,一个通用的价值函数就能同时评价几百种不同的任务。
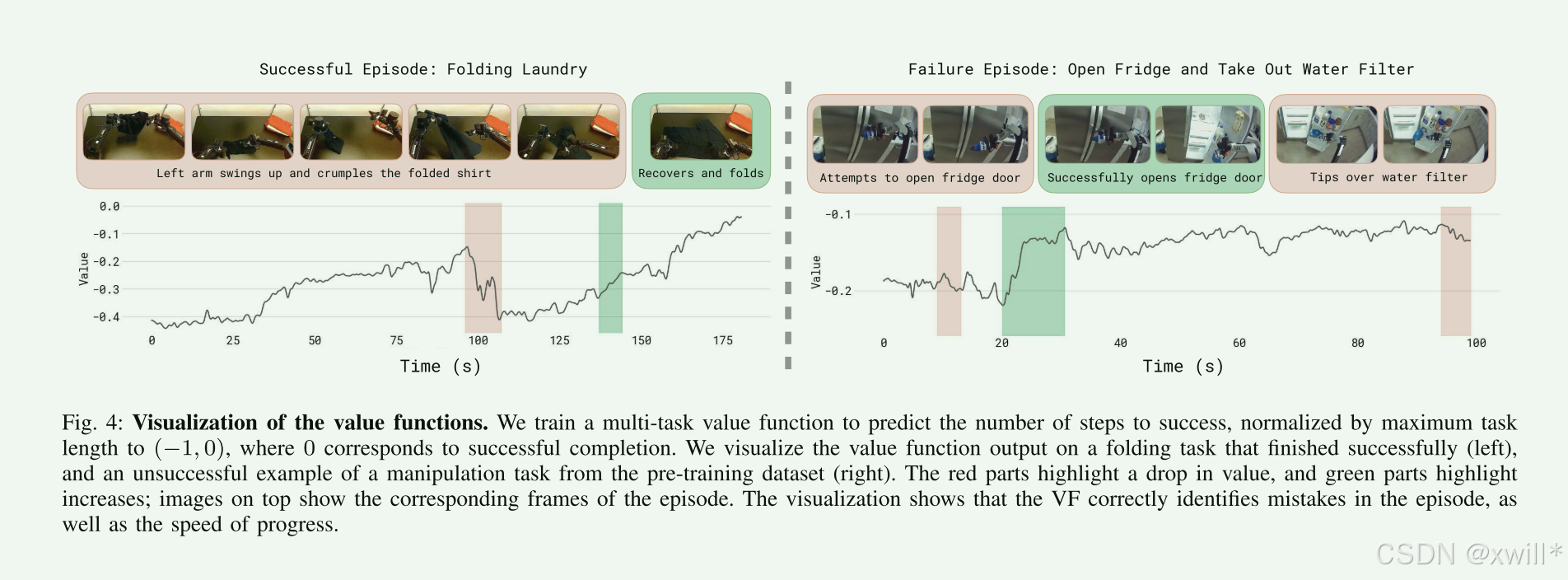
如上图所示,在成功案例中 ,随着机器人越来越接近目标,价值曲线会稳定上升 (从 −1.0 慢慢爬向 0)。而在失败案例中 :一旦机器人做了一个错误动作(比如把衣服扯飞了),价值曲线会断崖式下跌。这证明了价值函数真的看懂了任务进度。
3.4Pre-training, data collection, and learning from experience
模型在预训练阶段 使用的数据混合比例很大程度上遵循了 π0.5 的配方,包含来自互联网的视觉语言数据、子任务预测 ℓ^ 以及来自多种不同机器人的低级动作预测。
作者没有把标准定得太高(比如只取前 5% 的动作)。他们设定 30% 分位数为阈值。在数据非常杂乱的机器人任务中,这种相对宽松的阈值能保证模型有足够多的"正面教材"可以学习,同时又能过滤掉那些明显的失误和废动作。
如果机器人犯了错(比如手卡住了),人接管并修好它。这段数据告诉机器人:"如果你处于这种尴尬的境地,你应该这样自救。"人提供的纠正动作被强制标为 I**t=True。这赋予了人类动作极高的权重。单纯的自主探索很难学到如何从罕见的严重错误中恢复,人类的"神来之笔"能帮机器人快速跨越这些难点。
通常 RL 是"练完一轮,在这一轮的基础上接着练"。每次更新都回过头去,从最原始的预训练模型开始微调。持续在特定任务上微调会导致"灾难性遗忘"(模型变得只会在这个咖啡机前做咖啡,却忘了怎么走路或说话)。从预训练检查点开始,能确保模型在变强的同时,依然保留着 Gemma 3 带来的通用逻辑和感知能力。
即使只迭代一次(收集一轮数据,更新一次模型),效果也会有质的飞跃。这证明了 RECAP 的学习效率极高,不需要像传统强化学习那样在模拟器里跑几亿次。
三:实验
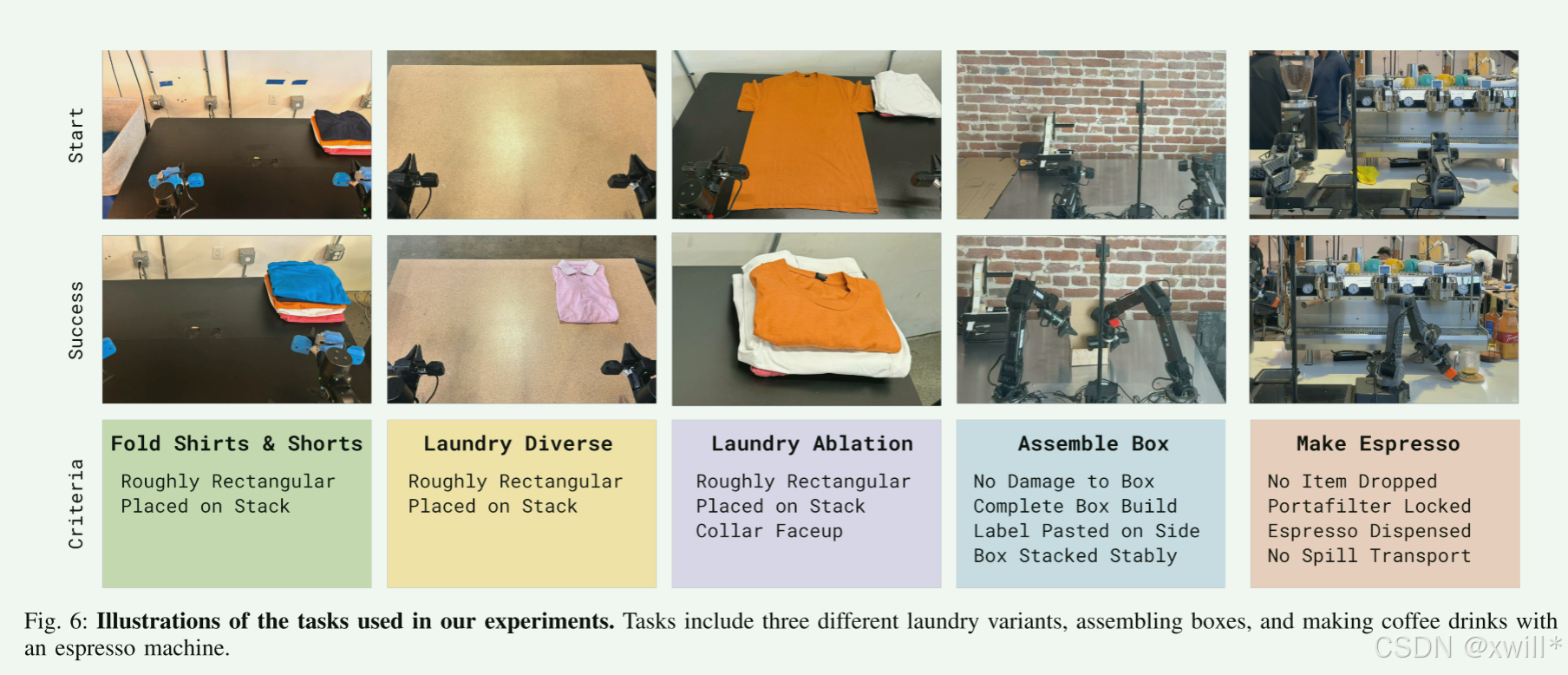
在实验评估中,使用 RECAP 在一系列现实任务上训练 π0.6 模型:制作浓缩咖啡、折叠多样化的衣物以及组装纸箱。每个任务都包含多个步骤,持续时间在 5 到 15 分钟不等,涉及复杂的操控行为(受限的强力操作、倾倒液体、操作布料和纸板等),并要求快速执行以保证高吞吐量。我们在图 5 中展示了实验中使用的机器人平台。
四:总结
在机器人研究中,通常只看"成功率"。但作者强调了吞吐量 (单位时间内完成的任务量)。如果机器人做一杯咖啡需要半小时,就算 100% 成功也没用。而RECAP通过 RL,机器人不仅学会了"做对",还学会了"抄近路"和"加速"。它优化了动作的轨迹,去掉了冗余的停顿。这是模仿学习很难达到的------因为它学的是人类,而人类在操作机器人时往往是缓慢且犹豫的。
论文提到了 DAgger(Dataset Aggregation)。这是一种经典的算法思想,也就是让机器人自己跑,人坐在一旁看。机器人快闯祸时,人接手纠正。它把 DAgger 的"纠错能力"和 RL 的"性能优化能力"完美结合了。人负责保底(不让机器人把咖啡机拆了),RL 负责冲刺(让机器人做得比人还快)。
作者坦诚地提出了三个尚未解决的痛点,这也是目前机器人领域最前沿的研究课题:
-
奖励自动标注:现在还要人点"成功"或"失败"。未来的趋势是用另一个 AI(比如视觉大模型)来自动当裁判。
-
场景自动重置:机器人弄乱了桌子,现在还得人去整理好。如果机器人能学会自己把桌子收拾干净再练下一轮,那就能实现"24小时不间断自学"。