一、GPT2训练加速
1.1 使用tensor_core加速
原理:NVIDIA的Tensor Core支持混合精度计算(FP16/FP32),通过Volta/Turing/Ampere架构的GPU(如V100/A100)加速矩阵运算。
Tensor Core 是 NVIDIA Volta 及更新架构(例如 Turing、Ampere、Hopper)GPU 中专门用 于加速矩阵计算的硬件单元。它们旨在高效地执行混合精度浮点运算,特别是 FP16(半精度浮 点数)和 TF32(Tensor Float 32)运算,并累加到 FP32 精度。
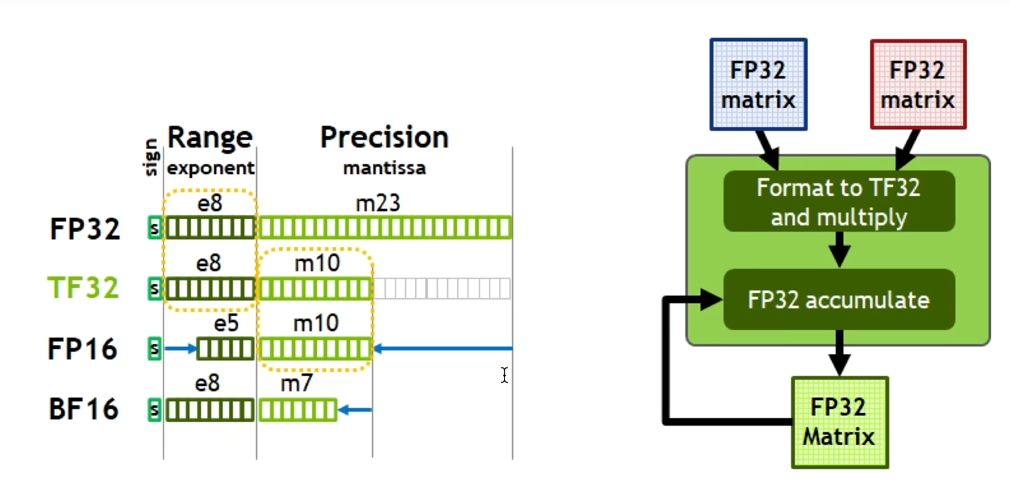
Tensor Core 的工作原理:
传统的 CUDA 核心主要处理标量和向量运算。而 Tensor Core 则专注于矩阵运算,特别是矩阵 乘法累加(Matrix Multiply-Accumulate,MMA)操作。一个 Tensor Core 可以在一个时钟周 期内执行多个 FP16 或 TF32 矩阵的乘法,并将结果累加到 FP32 矩阵上。
例如,在 Volta 架构中,一个 Tensor Core 可以在一个时钟周期内执行一个 4x4 的 FP16 矩阵 乘法,并将结果累加到一个 4x4 的 FP32 矩阵上。这意味着一个 Tensor Core 可以执行 4x4x4=64 次乘法和 4x4=16 次加法。通过并行使用大量的 Tensor Core,GPU 可以显著加速深 度学习模型中的矩阵运算。
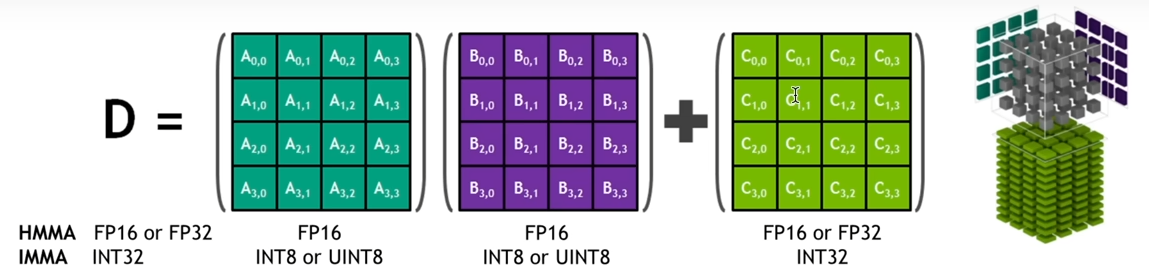
注意:支持 Tensor Core 的 NVIDIA GPU: 只有 Volta 及更新架构的 NVIDIA GPU 才支持 Tensor Core。即20系列显卡以上或者V100以上。
python
#*-=======================tensor_core加速===========================-*
# 设置张量核心算法的精度级别为TF32
torch.set_float32_matmul_precision("high") 加速前
加速后
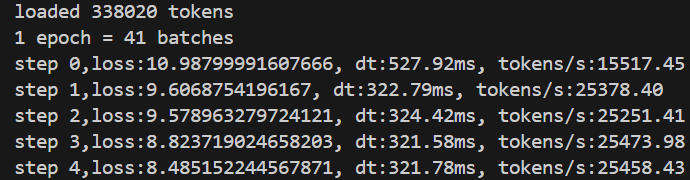
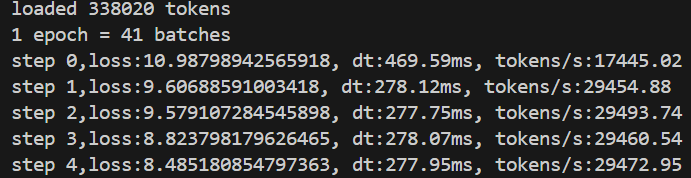
1.2、混合精度
优势:减少显存占用50%,加速计算1.5-3倍。
注意 :可能需调整
GradScaler的init_scale以避免梯度下溢。
python
#*-=======================混合精度============================-*
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
logits, loss = model(x, y)加速前
加速后


1.3、torch_compile**(PyTorch 2.0+)**
介绍:torch.compile --- PyTorch 2.7 documentation
torch.compile是PyTorch2.0引入的一项技术,可以在Linux系统上使用。
在刚开始的版本中未支持Windows,后续PyTorch2.5版本开始, 在 Windows 的 CPU 环境中运行。 要在 Windows 上使用 torch.compile 已正式支持 torch.compile,需要配置 C++ 开 发环境: Accelerate PyTorch* Inference with torch.compile on Windows* CPU
对于Windows的GPU,由于依赖 Triton ,所以目前适配还不是很好。
模式选择:
default:平衡编译时间和速度。
reduce-overhead:减少小batch的开销。
max-autotune:极致优化(编译时间长)。
python
#*-=======================torch_compile===========================-*
model=torch.compile(model)加速前
加速后

1.4、flash attention
python
#*-=======================flash attention============================-*
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)
# att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# att = att.masked_fill(self.bias[:, :, :T, :T] == 0 , float("-inf"))
# att = F.softmax(att, dim=-1)
# y = att @ v # (B, nh, T, T) X (B, nh, T, hs) -> (B, nh, T, hs)加速前
加速后

1.4、加速总结
| 方法 | 显存节省 | 速度提升 | 适用场景 |
|---|---|---|---|
| Tensor Core | 中等 | 1.5x | 矩阵密集运算 |
| 混合精度 | 高 | 2x | 所有GPU训练 |
| torch.compile | 无 | 1.3x | PyTorch 2.0+ |
| Flash Attention | 极高 | 3x | 长序列(>512 tokens) |
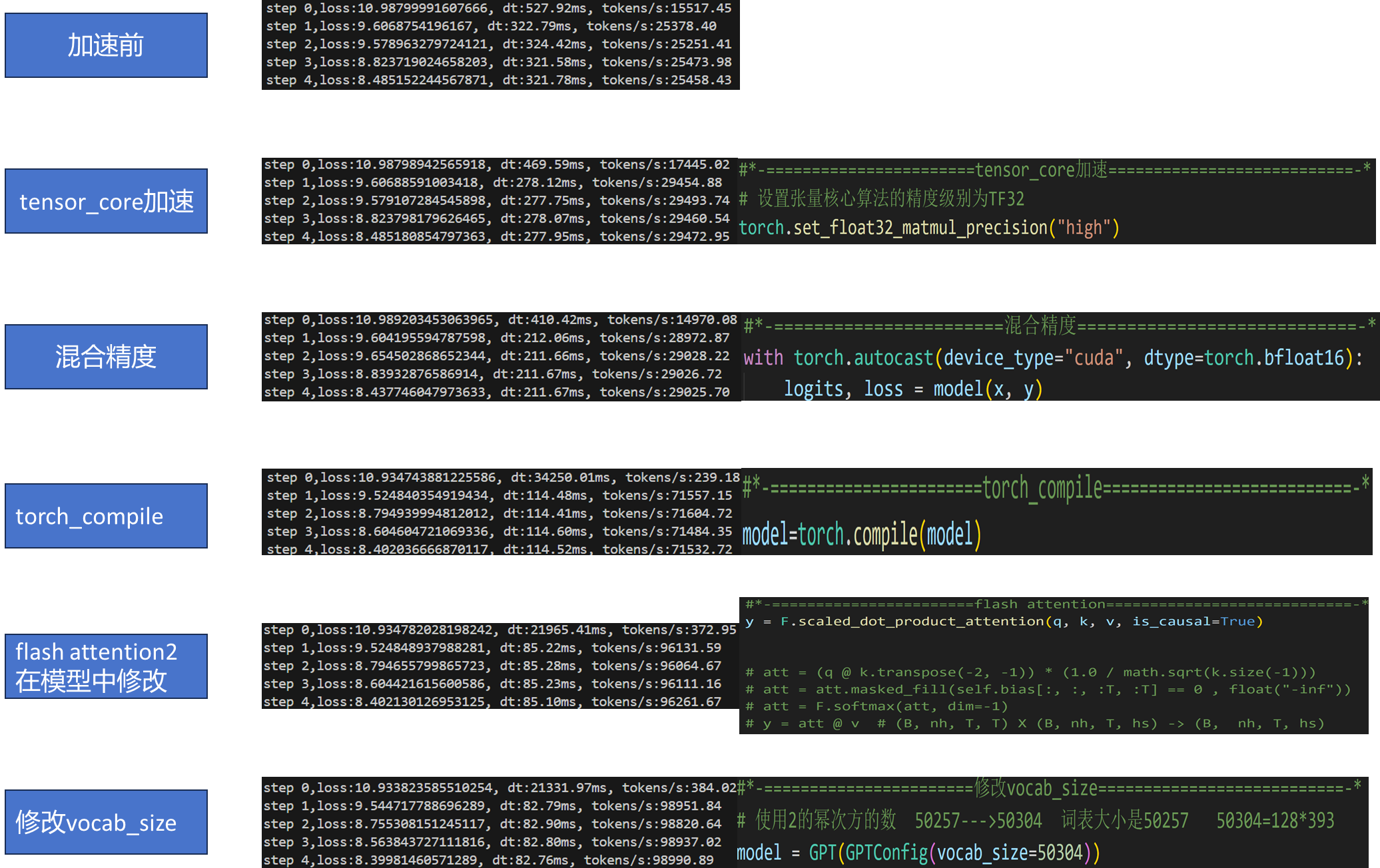
322 --> 277 --> 114 --> 85 --> 82
二、GPT2训练技巧
2.1、梯度裁剪---训练过程操作
python
#*-=======================梯度裁剪===========================-*
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)2.2、学习调度器--余弦退火
python
#*-=======================学习率调度器-1===========================-*
# 实现一个学习率调度器(learning rate scheduler),它根据训练的迭代次数(iteration)动态调整学习率。
# 结合了线性预热(linear warmup)和余弦衰减(cosine decay)两种策略。
max_lr = 6e-4 # 最大学习率
min_lr = max_lr * 0.1 # 最小学习率,是最大学习率的 10%
warmup_steps = 10 # 线性预热的迭代次数
max_steps = 50 # 总的训练迭代次数(或衰减到最小学习率的迭代次数)
def get_lr(it):
"""
根据迭代次数 it 返回当前的学习率。
Args:
it: 当前的迭代次数。
Returns:
当前的学习率。
"""
# 1) 线性预热阶段 (Linear Warmup)
if it < warmup_steps:
# 在 warmup_steps 步内,学习率从 0 线性增加到 max_lr
# it 从 0 开始,所以 (it + 1) 从 1 开始,到 warmup_steps。
# 因此,学习率从 max_lr / warmup_steps 线性增加到 max_lr。
return max_lr * (it + 1) / warmup_steps
# 2) 达到最大迭代次数后,保持最小学习率 (Minimum Learning Rate after Max Steps)
if it > max_steps:
# 超过 max_steps 后,学习率保持在 min_lr
return min_lr
# 3) 余弦衰减阶段 (Cosine Decay)
# 计算衰减比例。
# it 从 warmup_steps + 1 开始,到 max_steps。
# decay_ratio 从 (warmup_steps + 1 - warmup_steps) / (max_steps - warmup_steps) = 1/(max_steps - warmup_steps) 线性增加到 (max_steps - warmup_steps) / (max_steps - warmup_steps) = 1。
decay_ratio = (it - warmup_steps) / (max_steps - warmup_steps)
assert 0 <= decay_ratio <= 1 # 确保衰减比例在 0 到 1 之间,这是一个良好的编程习惯,用于检查代码的正确性
# 计算余弦衰减系数。
# 当 decay_ratio = 0 时,coeff = 0.5 * (1 + cos(0)) = 1。
# 当 decay_ratio = 1 时,coeff = 0.5 * (1 + cos(pi)) = 0。
# 因此,coeff 从 1 线性减小到 0。
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))
# 计算当前学习率。
# 当 coeff = 1 时,学习率为 min_lr + (max_lr - min_lr) = max_lr。
# 当 coeff = 0 时,学习率为 min_lr + 0 = min_lr。
# 因此,学习率从 max_lr 按照余弦曲线衰减到 min_lr。
return min_lr + coeff * (max_lr - min_lr)
python
#*-=======================学习率调度器-2===========================-*
# 确定并设置此迭代的学习率
lr = get_lr(step)
for param_group in optimizer.param_groups:
param_group['lr'] = lr2.3、参数正则化----在模型操作
python
#*-=======================参数正则化-1===========================-*
import inspect
def configure_optimizers(self, weight_decay, learning_rate, device):
# self.named_parameters() 返回模型中所有参数的名称和参数 tensor 的迭代器。
# 第一个 param_dict 存储了所有参数。
# 第二个 param_dict 过滤掉了 requires_grad=False 的参数,即不需要计算梯度的参数。
param_dict = {pn: p for pn, p in self.named_parameters()}
param_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}
# 根据参数的维度进行分组。
# dim() >= 2 的参数通常是权重矩阵(例如全连接层、卷积层、embedding 层),需要进行权重衰减。
# dim() < 2 的参数通常是偏置 (bias) 和 LayerNorm 的参数,不需要进行权重衰减。
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
# 创建优化器参数组。
# 每个组是一个字典,包含 'params' 和 'weight_decay' 两个键。
# 第一个组包含需要进行权重衰减的参数,其 weight_decay 设置为传入的 weight_decay 值。
# 第二个组包含不需要进行权重衰减的参数,其 weight_decay 设置为 0.0。
optim_groups = [
{'params': decay_params, 'weight_decay': weight_decay},
{'params': nodecay_params, 'weight_decay': 0.0}
]
# 打印需要进行权重衰减和不需要进行权重衰减的参数数量,用于调试和信息展示。numel() 返回 tensor 中元素的总个数。
num_decay_params = sum(p.numel() for p in decay_params)
num_nodecay_params = sum(p.numel() for p in nodecay_params)
print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")
print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")
# 检查 AdamW 是否支持 fused 版本(fused 版本通常在 CUDA 设备上速度更快)。
# fused 是将多个操作合并成一个优化的 CUDA kernel
# inspect.signature() 用于获取函数的签名,parameters 属性返回函数的参数。
fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
use_fused = fused_available and device == "cuda"
print(f"using fused AdamW: {use_fused}")
# 创建 AdamW 优化器。
# optim_groups:参数组,用于分别设置不同参数组的 weight_decay。
# lr:学习率。
# betas:Adam 优化器的 beta 值。
# eps:用于数值稳定性的 epsilon 值。
# fused:是否使用 fused 版本。
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=(0.9, 0.95), eps=1e-8, fused=use_fused)
return optimizer
python
#*-=======================优化器===========================-*
# optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
#*-=======================权重衰减-2===========================-*
optimizer = model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device=device)2.4、梯度累计
python
#*-=======================梯度累计-1===========================-*
total_batch_size= 524288 # 期望的总批量大小,以 token 数量计。这里是 524288,约为 0.5M。GPT-3论文中的数据
B = 8 # 小 batch size,每个 GPU 或设备的本地批量大小。这里是 8
T = 1024 # sequence length
assert total_batch_size % (B * T)== 0, "确保 total batch_size 可以被 B * T 整除。"
grad_accum_steps = total_batch_size // (B *T) # 梯度累积的步数,计算 total_batch_size 除以 (B * T) 的整数部分。
print(f"total batch size: {total_batch_size}")
# 表示需要累积多少个小批次的梯度才能达到期望的总批量大小。
# 524288 // (8 * 1024) = 64,即需要累积 64 个小批次的梯度才能达到 0.5M 的总批量大小。
# 现在一个step是72毫秒,如果我们累积64个step,那么一个step就是64*72=4608毫秒,约等于5秒
print(f"=> 梯度累计批次的数量: {grad_accum_steps}")
python
#*-=======================梯度累计-2===========================-*
loss_accum = 0.0
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
#*-=======================混合精度============================-*
with torch.autocast(device_type=device, dtype=torch.bfloat16):
logits, loss = model(x, y)
# 如果不将 loss 除以 grad_accum_steps,那么累积的梯度将会是实际梯度的 grad_accum_steps 倍。
loss = loss / grad_accum_steps
loss_accum += loss.detach()
loss.backward()2.5、DDP
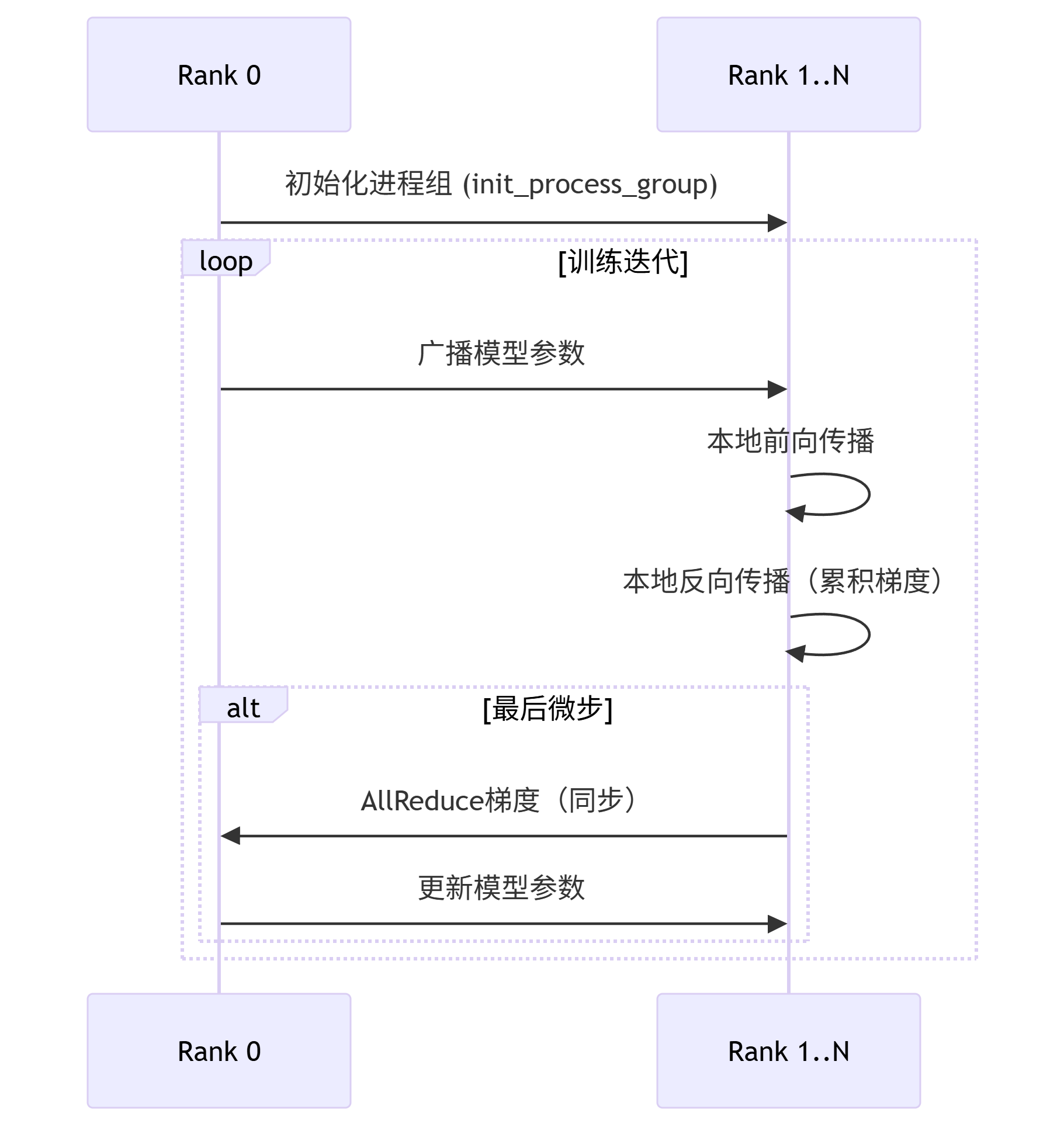
分布式数据并行(DDP)是PyTorch中用于多GPU训练的核心方案,它通过将模型复制到多个GPU上并行处理数据来实现训练加速。在初始化阶段,程序首先通过检查RANK环境变量来判断当前是否处于DDP模式。当检测到DDP模式时,会使用NCCL后端初始化进程组,这是专为NVIDIA GPU设计的高性能通信后端。每个进程会根据分配的本地rank自动绑定到对应的GPU设备,这种设计确保了各进程独立工作在不同GPU上,避免了设备资源冲突。值得注意的是,进程组初始化必须是同步操作,所有进程需要同时调用init_process_group函数才能继续执行后续代码。
在设备配置方面,DDP模式下每个进程会独占一个GPU,这是通过将设备指定为cuda:{ddp_local_rank}来实现的。这种明确的设备绑定策略相比自动选择设备更加可靠,特别是在多节点训练场景下。对于非DDP模式(单GPU或CPU训练),程序提供了自动设备检测逻辑,会按照CUDA GPU、Apple MPS、CPU的优先级顺序选择合适的计算设备。为了便于后续操作,代码中还额外定义了device_type变量来区分设备类型,这在需要根据设备类型执行不同优化时特别有用。
python
# 设置分布式数据并行 (DDP) 环境,如果不是 DDP 运行,则选择可用的设备(CPU、CUDA 或 MPS)。
# simple launch:
# python 15DDP.py
# DDP launch for e.g. 2 GPUs:
# torchrun --standalone --nproc_per_node=2 15DDP.py
import os
import torch
from torch.distributed import init_process_group, destroy_process_group
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 设置 DDP (分布式数据并行)。
# torchrun 命令会设置环境变量 RANK、LOCAL_RANK 和 WORLD_SIZE
ddp = int(os.environ.get('RANK', -1)) != -1 # 判断是否是 DDP 运行。如果设置了 RANK 环境变量,则认为是 DDP 运行。
if ddp:
# # 如果是 DDP 运行,目前需要 CUDA,根据 rank 设置设备
assert torch.cuda.is_available(), "DDP 的运行需要 CUDA"
init_process_group(backend='nccl') # 初始化进程组,使用 nccl 后端(适用于 NVIDIA GPU)
ddp_rank = int(os.environ['RANK']) # 当前进程的全局 rank(在所有进程中的排名)
ddp_local_rank = int(os.environ['LOCAL_RANK']) # 当前进程在当前节点上的本地 rank
ddp_world_size = int(os.environ['WORLD_SIZE']) # 总共有多少个进程
device = f'cuda:{ddp_local_rank}' # 根据本地 rank 设置设备,例如 cuda:0, cuda:1
torch.cuda.set_device(device) # 设置当前进程使用的 GPU 设备
master_process = ddp_rank == 0 # # 判断当前进程是否是 master 进程(rank 为 0 的进程),master 进程负责日志记录、保存检查点等
else:
# 非 DDP 运行(单卡或 CPU 运行)
ddp_rank = 0 # 设置 rank 为 0
ddp_local_rank = 0 # 设置本地rank为0
ddp_world_size = 1 # 设置世界大小为1
master_process = True # 单进程,所以是 master 进程
# 尝试自动检测设备
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
if master_process:
print(f"using device: {device}")
# 设备是CUDA:1等具体执行的设备,添加device_type 标识用来区分运行设备是CPU还是CUDA等
device_type = "cuda" if device.startswith("cuda") else "cpu"模型封装是DDP的核心环节,通过DistributedDataParallel包装原始模型,实现了梯度同步和参数广播的自动化。值得注意的是,DDP封装后的模型会将原始模型保存在module属性中,因此通过raw_model = model.module if ddp else model这种方式可以始终访问到未经封装的原始模型。这种设计在保存检查点或访问模型自定义属性时尤为重要,因为直接操作DDP封装后的模型可能会导致意外行为。在底层实现上,DDP会自动在前向传播时广播模型参数,在反向传播时使用AllReduce操作同步梯度。
python
#*-=======================DDP-1===========================-*
if ddp:
model = DDP(model, device_ids=[ddp_local_rank])
# 当使用 torch.nn.parallel.DistributedDataParallel (DDP) 封装模型时,DDP 会在原始模型 (model) 的外面包装一层,创建一个新的模型对象。
# 这个新的模型对象负责在多个进程之间同步梯度、管理数据分发等。
# 原始模型会被存储在新模型的 module 属性中。因此,如果你想访问原始模型的属性或方法,你需要通过 model.module 来访问。
raw_model = model.module if ddp else model # always contains the "raw" unwrapped model
python
#*-=======================DDP-2===========================-*
optimizer = raw_model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device_type=device)数据加载的分布式处理是通过自定义的DataLoaderLite实现的,它根据process_rank和num_processes参数将数据集划分到不同进程。这种数据并行策略要求每个进程处理不同的数据子集,从而在全局上实现数据的完整覆盖。为了进一步提高训练效率,代码中实现了梯度累积与同步控制的精细管理,通过model.require_backward_grad_sync属性控制在何时执行梯度同步,这使得在保持较大有效batch size的同时,可以使用较小的显存占用进行训练。
python
#*-=======================DDP-3===========================-*
train_loader = DataLoaderLite(B=B, T=T, process_rank=ddp_rank, num_processes=ddp_world_size)
python
#*-=======================DDP-4===========================-*
if ddp:
model.require_backward_grad_sync =(micro_step == grad_accum_steps -1)在训练过程中,损失值的同步是通过dist.all_reduce操作实现的,使用AVG操作符对各个进程计算的损失值求平均,这比简单的求和更能反映模型在全局数据上的表现。为了监控训练效率,代码还计算了tokens_per_sec指标,这个指标考虑了batch size、序列长度、梯度累积步数和GPU数量等因素,能够全面反映系统的整体吞吐量。通过这些精心设计的分布式训练组件,DDP可以在多GPU环境下实现接近线性的加速比,大幅提升模型训练效率。
python
#*-=======================DDP-5===========================-*
if ddp:
dist.all_reduce(loss_accum, op=dist.ReduceOp.AVG)
python
#*-=======================DDP-6===========================-*
tokens_processed = train_loader.B * train_loader.T * grad_accum_steps * ddp_world_size
tokens_per_sec = tokens_processed / dt # 计算每秒训练的token数量在实际部署DDP训练时,开发者需要注意几个关键点:确保数据分片的均匀性以避免负载不均衡;正确处理检查点保存,只需由rank 0进程执行即可;使用torch.profiler等工具进行性能分析,找出可能的瓶颈;注意处理可能出现的死锁问题,特别是在多节点训练环境中。此外,将DDP与其他优化技术如混合精度训练、梯度裁剪等结合使用,可以进一步发挥分布式训练的优势。通过合理配置这些组件,即使是像GPT-2这样的大型语言模型,也能在合理的时间内完成高效训练。