1. SQL Gateway 解决了什么问题
如果只用 SQL Client(embedded),更多是"我在一台机器上交互式跑 SQL"。但一旦进入团队协作和平台化,就会遇到这些诉求:
- 多个用户/系统同时提交 SQL(并发、隔离、会话上下文)
- 用标准协议接入(REST、HiveServer2、JDBC)
- 在 CI/CD 或平台中用 API 方式提交 SQL 脚本
- 统一管理连接、依赖、参数、资源目标集群
SQL Gateway 正是为此设计:可插拔 Endpoint + 统一的 SqlGatewayService 处理器。 (Apache Nightlies)
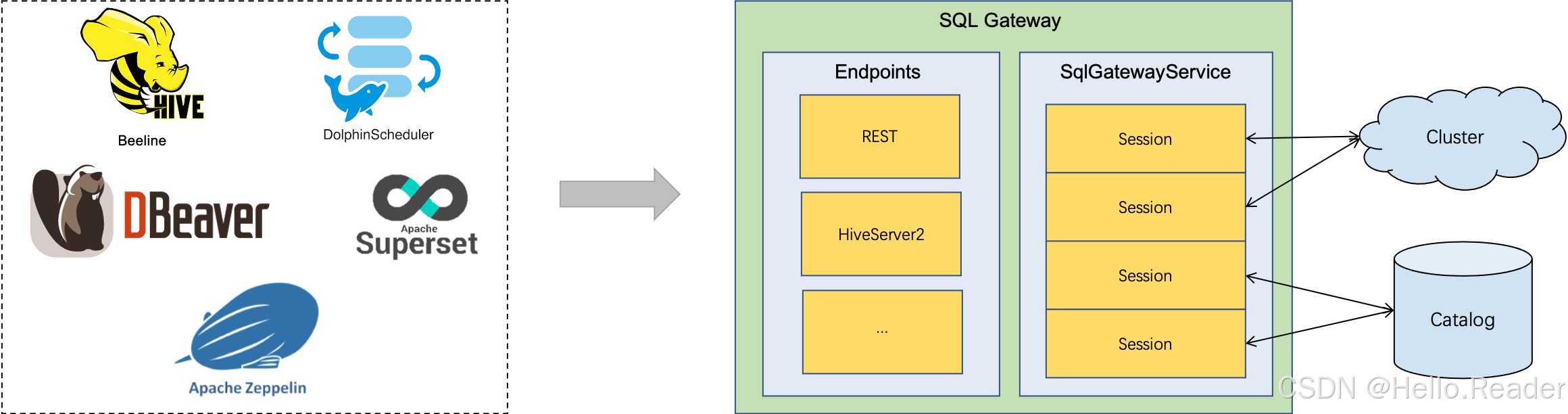
2. 架构速懂:Endpoint + SqlGatewayService + Session/Operation
SQL Gateway 由两部分组成:
- Endpoint:对外入口(比如 REST、HiveServer2)
- SqlGatewayService:真正处理请求的"内核",被不同 Endpoint 复用 (Apache Nightlies)
同时它引入两个关键概念:
- Session(会话):保存用户在交互过程中的上下文(配置、catalog、已加载 jar、变量等),创建后返回
sessionHandle供后续调用使用 (Apache Nightlies) - Operation(操作):每次提交 SQL(查询/DDL/DML)都会生成一个
operationHandle,用于拉取结果或跟踪执行 (Apache Nightlies)
3. 本地 5 分钟跑起来:Cluster + Gateway + 健康检查
1)启动本地 Flink 集群
bash
./bin/start-cluster.sh2)启动 SQL Gateway(REST Endpoint 默认监听 8083)
bash
./bin/sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost3)检查 Gateway 是否可用
bash
curl http://localhost:8083/v1/info能返回产品名和版本信息就说明启动成功。 (Apache Nightlies)
你也可以用 start-foreground 以前台方式启动,便于调试日志。 (Apache Nightlies)
4. REST API 三步走:开 Session → 提交 SQL → 拉取结果
下面是一套最常用的 REST 调用链(非常适合写到脚本或平台后端里)。
Step 1:创建 Session
bash
curl --request POST http://localhost:8083/v1/sessions
# => {"sessionHandle":"..."}Step 2:提交 SQL(示例 SELECT 1)
bash
curl --request POST \
http://localhost:8083/v1/sessions/${sessionHandle}/statements/ \
--data '{"statement":"SELECT 1"}'
# => {"operationHandle":"..."}Step 3:拉取结果(分页/批次)
bash
curl --request GET \
http://localhost:8083/v1/sessions/${sessionHandle}/operations/${operationHandle}/result/0返回体里如果带 nextResultUri,继续 GET 它就能拿下一批结果。 (Apache Nightlies)
5. 关键能力:在请求里指定要提交到哪个 Flink 集群
SQL Gateway 支持客户端在请求体里传 executionConfig,从而指定目标 Flink 集群的 REST 地址与端口(适合一套 Gateway 对多套集群、或平台侧动态路由)。
示例(把作业提交到 jobmanager-host:8081):
bash
curl --request POST \
http://localhost:8083/v1/sessions/${sessionHandle}/statements/ \
--data '{
"executionConfig": {"rest.address":"jobmanager-host","rest.port":8081},
"statement":"SELECT 1"
}'这一点对"统一入口 + 多环境/多集群"非常实用。 (Apache Nightlies)
6. 客户端怎么接:SQL Client / JDBC / Hive 生态
6.1 SQL Client 连接 Gateway(最顺手)
SQL Client 的 gateway 模式就是把 SQL 提交到 SQL Gateway 去执行:
bash
./bin/sql-client.sh gateway --endpoint http://127.0.0.1:8083并且官方明确:SQL Client 从 v2 开始只支持连接 REST Endpoint。 (Apache Nightlies)
6.2 Flink JDBC Driver(给 BI/应用接入)
Flink JDBC Driver 的使用前提就是启动 SQL Gateway 的 REST Endpoint,它相当于 JDBC Server。 (Apache Nightlies)
典型场景:应用用 JDBC 发 SQL,Gateway 统一转成 Flink 作业执行。
6.3 HiveServer2 Endpoint(兼容 Beeline / DBeaver / Superset 等)
SQL Gateway 原生支持 HiveServer2 Endpoint,兼容 HiveServer2 wire protocol,可以用现成的 Hive 客户端工具接入。 (Apache Nightlies)
启用方式:
bash
./bin/sql-gateway.sh start -Dsql-gateway.endpoint.type=hiveserver2或写入 flink-conf.yaml:
yaml
sql-gateway.endpoint.type: hiveserver2CLI 参数优先级高于配置文件。 (Apache Nightlies)
7. 部署 SQL 脚本:Application Mode 一键起作业
SQL Gateway 支持把一段脚本直接以 Application Mode 的方式部署(JobManager 负责编译脚本)。如果脚本里需要 Kafka 等连接器资源,通常要用 ADD JAR 拉取/加载相关 artifact。 (Apache Nightlies)
REST 示例(K8S application):
bash
curl --request POST http://localhost:8083/sessions/${SESSION_HANDLE}/scripts \
--header 'Content-Type: application/json' \
--data-raw '{
"script": "CREATE TEMPORARY TABLE sink(a INT) WITH ( '\''connector'\'' = '\''blackhole'\'' ); INSERT INTO sink VALUES (1),(2),(3);",
"executionConfig": {
"execution.target": "kubernetes-application",
"kubernetes.cluster-id": "'"${CLUSTER_ID}"'",
"kubernetes.container.image.ref": "'"${FLINK_IMAGE_NAME}"'"
}
}'如果你要跑 PyFlink,需要镜像里预装 PyFlink。 (Apache Nightlies)
8. 关键配置与调优:把"服务化"跑稳
SQL Gateway 是常驻服务,最怕两类问题:会话无限增长、线程资源被打满。官方提供了一组核心参数可以控制。 (Arenadata Docs)
会话治理(推荐生产必配)
sql-gateway.session.idle-timeout:会话空闲多久自动关闭(0 表示不关闭)sql-gateway.session.check-interval:检查空闲会话的周期sql-gateway.session.max-num:最大活跃 session 数
吞吐与并发(防止被突发流量压死)
sql-gateway.worker.threads.min/sql-gateway.worker.threads.maxsql-gateway.worker.keepalive-time:空闲 worker 线程回收时间
计划缓存(高频重复查询会很香)
sql-gateway.session.plan-cache.enabledsql-gateway.session.plan-cache.sizesql-gateway.session.plan-cache.ttl(Arenadata Docs)
9. 生产落地建议:平台化时最容易踩的坑
- 入口层建议加反向代理与鉴权:REST Header(Cookie/Token)在企业里很常见,Gateway 本身更适合作为"内网服务",由网关层做认证授权与限流
- 多实例部署:SQL Gateway 本身是服务,前面挂 LB;会话是否需要粘性(sticky)取决于你是否把 session 状态放在实例内存里(通常是)
- 资源隔离:如果你用 session cluster 跑大量互不相干的作业,要提前规划隔离策略(不同队列/不同集群/不同 gateway 实例)
- 依赖管理标准化:把常用 connector/format 的 jar 或 artifact 管理成"白名单",别让用户随意上传导致类冲突与安全风险