常用接口
- insertone/insertMany
- updateOne/updateMany/upsert/replaceOne
- deleteOne/deleteMany
查询
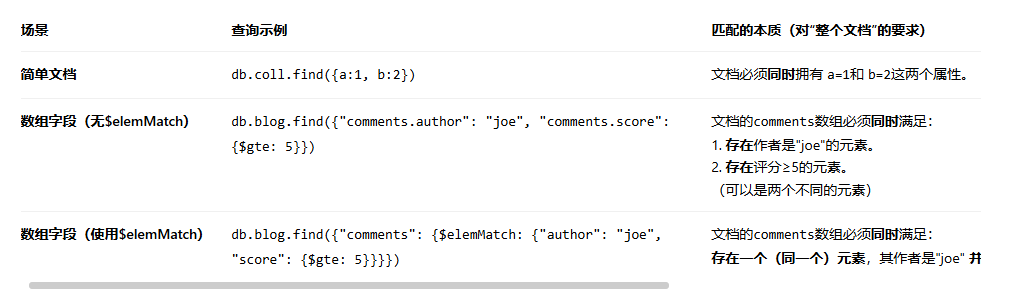
MongoDB查询匹配的本质确实是:查询条件作用于"整个文档"的层面,只要"整个被查询的文档"满足查询条件中的所有要求,它就会被返回。
复合索引创建原则
1、第一个键优先使用等值字段
2、第二字段使用排序字段
3、第三个字段使用多值字段
疑惑点:为何这样的顺序设计复合索引性能往往较好,带着这个问题,尝试从他的原理去分析
原理:
只有在尽量小的范围内查询结果,那么查询的性能才能更好。所以复合索引创建原则就是为了实现的这个目标,总结的一般性原则。
我将用一个例子来说明我对于这个原则的理解:
假设有一个用户集合(users),包含以下字段:
city:用户所在城市(字符串类型,等值过滤字段)。
age:用户年龄(数值类型,范围过滤字段)。
username:用户名(字符串类型,排序字段)。
查询需求:查找城市为"New York"、年龄大于20岁的用户,并按用户名升序排序。
假设数据库中有New York、HongKong、Beijing三个城市,每个城市都有100000个记录
javascript
db.users.find({ city: "New York", age: { $gt: 20 } }).sort({ username: 1 })如果按照原则设计索引,那么如下创建
javascript
db.users.createIndex({city:1, username:1, age:1})那么查询过程如下:
- city是等值过滤字段,精准匹配New York相关记录,就不需要遍历其余200000个其他城市的记录,一下子缩小了三分之二的查询数量。
- 由于创建的索引是按照升序构造的,而我们的查询也是根据用户名进行升序排序,那么避免mongo进行内存排序
- 由于 age是索引最后一个字段,过滤仅需检查每个匹配项的 age值,而不会破坏索引的顺序性。
这个过程的优势:
-
减少键扫描量:等值字段 city将扫描范围缩小到城市为"New York"的子集,避免全索引扫描。
-
消除排序成本:索引内排序避免内存排序(SORT阶段),降低CPU和内存开销。
-
高效范围过滤:范围查询在匹配子集内进行,不会导致索引跳跃。
错误设计
创建索引:{ age: 1, city: 1, username: 1 }
同样是进行:查找城市为"New York"、年龄大于20岁的用户,并按用户名升序排序。
查询过程:
- 索引首先按 age排序,但 age: {$gt: 20}是范围条件,因此MongoDB需扫描所有年龄大于20的索引项(从21到无穷大),无法快速定位匹配项。那么会产生很多无效的查询,例如city=Beijing和city=HongKong的文档都会被扫描
- 索引按city排序,但查询需按 username排序,因此MongoDB无法直接使用索引顺序。它必须在内存中对结果进行排序(SORT阶段)。
该设计带来的代价:
- 如果结果集大,可能触发32MB内存限制,导致错误或性能下降。
- 范围查询在索引前端进行,导致扫描键数量远高于返回文档数(如扫描10万键返回100文档)。
- 内存排序复杂度为O(n log n),而索引排序为O(n),数据量越大性能差异越显著。
总结
-
等值字段优先:尽快缩小扫描范围,提升索引选择性。例如,city等值过滤直接定位城市子集。
-
排序字段次之:利用索引有序性避免内存排序。例如,username在索引中维护顺序。
-
范围字段最后:防止范围查询中断索引连续性。例如,age范围过滤在匹配子集内进行。
-
通用性:该原则适用于大多数多条件查询,尤其是结合过滤和排序的场景。
-
实践过程中,建议使用explain验证查询语句执行情况。
索引桶
概念:索引桶是MongoDB中索引存储的基本单位。在MongoDB的底层存储引擎中,索引被组织为多个固定大小的存储单元,这些单元就是索引桶。每个索引桶包含一定数量的索引条目,这些条目按照索引键的顺序排列。
特点:
-
固定大小:每个索引桶有固定的大小限制。(通常为4KB或16KB,具体取决于存储引擎配置)
-
顺序存储:索引桶内的条目按照索引键的顺序排列,便于范围查询。
-
B树结构:索引桶通过B树(或B+树)结构组织,支持高效的查找、插入和删除操作。
工作原理
索引条目的存储方式
-
每个索引桶包含多个索引条目,每个条目由以下部分组成:
-
索引键值:文档中对应字段的值
-
文档指针:指向实际文档位置的引用(记录ID)
-
元数据:如时间戳、版本信息等
索引桶的分裂与合并
-
当索引桶已满时,MongoDB会执行桶分裂操作:
-
桶分裂:将过满的索引桶分成两个新桶,重新分配索引条目
-
平衡操作:通过B树的自平衡特性维持查询效率
-
空间回收:删除大量数据后,相邻的空桶可能会合并
索引遍历过程
查询时,MongoDB按以下步骤使用索引桶:
-
从根节点开始,沿B树结构向下遍历
-
在适当的索引桶中二分查找目标键值
-
找到匹配的索引条目后,通过文档指针定位实际文档
限制和约束
大小限制
-
条目大小限制:在MongoDB 4.2之前,索引条目必须小于1024字节,4.2之后取消了这个限制,如果一个文档的字段由于大小限制不能被索引,那么 MongoDB 就不会返回任何类型的错误或警告。这意味着大小超过 8KB 的键不会受到唯一索引的约束:比如,你可以插入多个相同的 8KB 字符串。
-
总索引大小:单个集合的索引总大小不能超过RAM限制
-
桶数量限制:过多桶会导致B树层级过深,影响查询性能
特殊键类型的限制
-
数组字段:每个数组元素生成独立的索引条目,可能造成桶分裂
-
大字符串:超过索引桶大小限制的键值无法被索引
-
地理空间数据:使用特殊的GeoHash编码,占用更多桶空间
索引桶与唯一约束
创建唯一索引时,MongoDB需要确保:
-
每个索引键值在桶中唯一
-
插入重复键时会检查所有相关桶
-
唯一索引的桶分裂操作需要额外的一致性检查
索引类型
唯一索引
地理空间索引
用途:支持基于地理位置的高效查询(如邻近点查询、地理范围搜索)。
类型:
2dsphere:处理球面几何(地球表面)的查询。
2d:适用于平面坐标(如游戏地图)。
复合地理空间索引:可与其他字段(如时间戳)组合以优化复杂查询。
全文搜索索引
功能:支持文本内容的语义搜索(如关键词匹配、相关性排序)。
多语言支持:通过指定语言选项(如default_language)支持不同语言的词干分析。
固定集合(Capped Collections)
特点:
固定大小,写入新数据时会覆盖最旧的数据(循环写入)。
支持高性能写入和顺序读取(如日志存储)。
可追加游标(Tailable Cursors):实时监控新插入的数据,类似tail -f命令。
TTL索引(Time-To-Live)
用途:自动删除过期数据(如会话信息、临时缓存)。
机制:基于时间字段(如createdAt)和expireAfterSeconds参数设置生命周期。
GridFS文件存储
设计原理:将大文件分割为多个块(chunk),存储为独立文档。
结构:
fs.files:存储文件元数据(如文件名、大小)。
fs.chunks:存储二进制数据块。