安装模型
ollama run gpt-oss:20b
ollama pull nomic-embed-text代码
# 确保虚拟环境中已安装依赖:
# pip install pypdf python-docx langchain-community chromadb sentence-transformers langchain langchain-core langchain-text-splitters langchain-ollama
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader, Docx2txtLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 修正1:RetrievalQA的正确导入路径(langchain 1.2.0版本)
# 新增:流式输出需要的模块
from langchain_classic.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # 流式输出回调(直接打印)
from langchain_classic.prompts import PromptTemplate # 自定义prompt模板
# 新版本的链构造器
from langchain_classic.chains import create_retrieval_chain
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_core.runnables import RunnablePassthrough
# 1. 加载知识库文档
def load_docs(doc_path):
documents = []
# 分别加载不同类型的文件
import os
from pathlib import Path
path = Path(doc_path)
# 加载PDF文件
pdf_files = list(path.glob("*.pdf"))
if pdf_files:
print(f"找到{len(pdf_files)}个PDF文件")
for pdf_file in pdf_files:
try:
loader = PyPDFLoader(str(pdf_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载PDF文件 {pdf_file} 失败: {e}")
# 加载Word文档
docx_files = list(path.glob("*.docx"))
if docx_files:
print(f"找到{len(docx_files)}个DOCX文件")
for docx_file in docx_files:
try:
loader = Docx2txtLoader(str(docx_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载DOCX文件 {docx_file} 失败: {e}")
# 加载文本文件
txt_files = list(path.glob("*.txt"))
if txt_files:
print(f"找到{len(txt_files)}个TXT文件")
for txt_file in txt_files:
try:
loader = TextLoader(str(txt_file), encoding="utf-8")
documents.extend(loader.load())
except Exception as e:
print(f"加载TXT文件 {txt_file} 失败: {e}")
return documents
# 2. 文档分块
def split_docs(docs):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
return text_splitter.split_documents(docs)
# 3. 初始化Ollama(开启流式支持)
# 对应截图步骤1:使用支持流式的LLM
llm = OllamaLLM(
model="gpt-oss:20b",
base_url="http://127.0.0.1:11434",
streaming=True, # 开启流式输出
callbacks=[StreamingStdOutCallbackHandler()] # 流式输出的回调(直接打印到控制台)
)
embeddings = OllamaEmbeddings(model="nomic-embed-text", base_url="http://127.0.0.1:11434")
# 4. 加载+切分文档(确保docs文件夹有文件)
try:
print("开始加载文档...")
docs = load_docs("docs")
print(f"成功加载{len(docs)}个文档")
split_documents = split_docs(docs)
print(f"✅ 成功加载{len(split_documents)}个文本块")
except Exception as e:
print(f"❌ 文档加载失败:{str(e)}")
import traceback
traceback.print_exc()
exit(1)
# 5. 构建向量库
print("开始构建向量库...")
try:
db = Chroma.from_documents(
documents=split_documents,
embedding=embeddings,
persist_directory="./db/chroma_db"
)
print("✅ 向量库构建成功")
except Exception as e:
print(f"❌ 向量库构建失败:{str(e)}")
import traceback
traceback.print_exc()
exit(1)
# 修正4:新版Chroma无需手动persist(自动保存)
# 6. 使用新版本的API构建链
# 6.1 定义问答prompt模板
prompt = PromptTemplate(
template="""请根据以下上下文回答用户的问题,不知道就说不知道,不要编造:
上下文:
{context}
问题: {input}
回答:""",
input_variables=["context", "input"]
)
# 6.2 创建文档链(使用新的API)
question_answer_chain = create_stuff_documents_chain(
llm=llm,
prompt=prompt
)
# 6.3 创建检索链(使用新的API)
qa_chain = create_retrieval_chain(
retriever=db.as_retriever(search_kwargs={"k": 3}),
combine_docs_chain=question_answer_chain
)
# 8. 流式输出测试
# 对应截图步骤4:使用新的API调用方式
question = "知识库有那一些姓名"
print(f"问题:{question}")
print("模型回答:", end="") # 先打印前缀,避免和流式内容分开
try:
# 新的API调用方式
response = qa_chain.invoke({"input": question})
print(response["answer"])
print("\n✅ 回答完成")
except Exception as e:
print(f"\n❌ 流式输出失败:{str(e)}")
import traceback
traceback.print_exc()流式输出',严格按照知识库,知识库没有,就回答知识库没有该知识
# 确保虚拟环境中已安装依赖:
# pip install pypdf python-docx langchain-community chromadb sentence-transformers langchain langchain-core langchain-text-splitters langchain-ollama
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader, Docx2txtLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 核心修复:调整 PromptTemplate 导入路径(适配 LangChain v1.x)
from langchain_core.prompts import PromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
import sys
import traceback
# 1. 加载知识库文档
def load_docs(doc_path):
documents = []
import os
from pathlib import Path
path = Path(doc_path)
# 加载PDF文件
pdf_files = list(path.glob("*.pdf"))
if pdf_files:
print(f"找到{len(pdf_files)}个PDF文件")
for pdf_file in pdf_files:
try:
loader = PyPDFLoader(str(pdf_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载PDF文件 {pdf_file} 失败: {e}")
# 加载Word文档
docx_files = list(path.glob("*.docx"))
if docx_files:
print(f"找到{len(docx_files)}个DOCX文件")
for docx_file in docx_files:
try:
loader = Docx2txtLoader(str(docx_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载DOCX文件 {docx_file} 失败: {e}")
# 加载文本文件
txt_files = list(path.glob("*.txt"))
if txt_files:
print(f"找到{len(txt_files)}个TXT文件")
for txt_file in txt_files:
try:
loader = TextLoader(str(txt_file), encoding="utf-8")
documents.extend(loader.load())
except Exception as e:
print(f"加载TXT文件 {txt_file} 失败: {e}")
return documents
# 2. 文档分块
def split_docs(docs):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""] # 优化中文切分
)
return text_splitter.split_documents(docs)
# 3. 初始化Ollama(开启流式支持)
llm = OllamaLLM(
model="gpt-oss:20b",
base_url="http://127.0.0.1:11434",
streaming=True, # 开启流式输出核心开关
temperature=0.1 # 降低随机性,保证回答准确性
)
embeddings = OllamaEmbeddings(model="nomic-embed-text", base_url="http://127.0.0.1:11434")
# 4. 加载+切分文档
try:
print("开始加载文档...")
docs = load_docs("docs")
print(f"成功加载{len(docs)}个原始文档")
split_documents = split_docs(docs)
print(f"✅ 成功加载{len(split_documents)}个文本块")
except Exception as e:
print(f"❌ 文档加载失败:{str(e)}")
traceback.print_exc()
exit(1)
# 5. 构建向量库
print("开始构建向量库...")
try:
db = Chroma.from_documents(
documents=split_documents,
embedding=embeddings,
persist_directory="./db/chroma_db"
)
print("✅ 向量库构建成功")
except Exception as e:
print(f"❌ 向量库构建失败:{str(e)}")
traceback.print_exc()
exit(1)
# 6. 构建检索问答链
# 6.1 定义问答prompt模板
prompt = PromptTemplate(
template="""请根据以下上下文回答用户的问题,严格基于上下文内容,不知道就说"知识库没有该知识",不要编造任何信息:
上下文:
{context}
问题: {input}
回答:""",
input_variables=["context", "input"]
)
# 6.2 创建文档链
question_answer_chain = create_stuff_documents_chain(
llm=llm,
prompt=prompt
)
# 6.3 创建检索链
qa_chain = create_retrieval_chain(
retriever=db.as_retriever(search_kwargs={"k": 3}), # 检索top3相关文本块
combine_docs_chain=question_answer_chain
)
# 7. 流式输出核心实现
def stream_qa(question):
"""
流式问答实现
:param question: 用户问题
"""
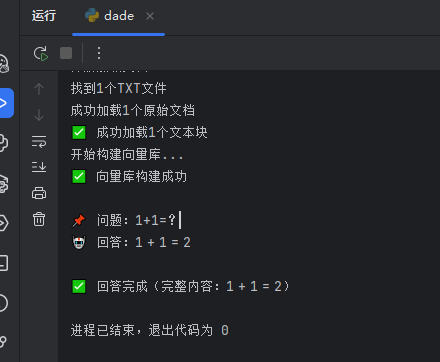
print(f"\n📌 问题:{question}")
print("🤖 回答:", end="", flush=True) # flush=True 立即输出,避免缓冲区延迟
try:
# 核心改动:使用stream方法替代invoke,获取流式响应
stream_response = qa_chain.stream({"input": question})
# 遍历流式响应,逐块输出
full_answer = ""
for chunk in stream_response:
# 提取回答内容(不同阶段的chunk结构不同)
if "answer" in chunk:
answer_chunk = chunk["answer"]
full_answer += answer_chunk
# 逐块打印(sys.stdout.write 比print更灵活)
sys.stdout.write(answer_chunk)
sys.stdout.flush() # 强制刷新输出缓冲区
print(f"\n\n✅ 回答完成(完整内容:{full_answer.strip()})")
return full_answer
except Exception as e:
print(f"\n\n❌ 流式输出失败:{str(e)}")
traceback.print_exc()
return None
# 8. 测试流式输出
if __name__ == "__main__":
# 测试问题(可替换为你知识库中的内容)
test_question = "1+1=?"
# 执行流式问答
stream_qa(test_question)
# 可添加多轮对话示例
# while True:
# user_input = input("\n请输入你的问题(输入q退出):")
# if user_input.lower() == "q":
# print("退出问答")
# break
# stream_qa(user_input)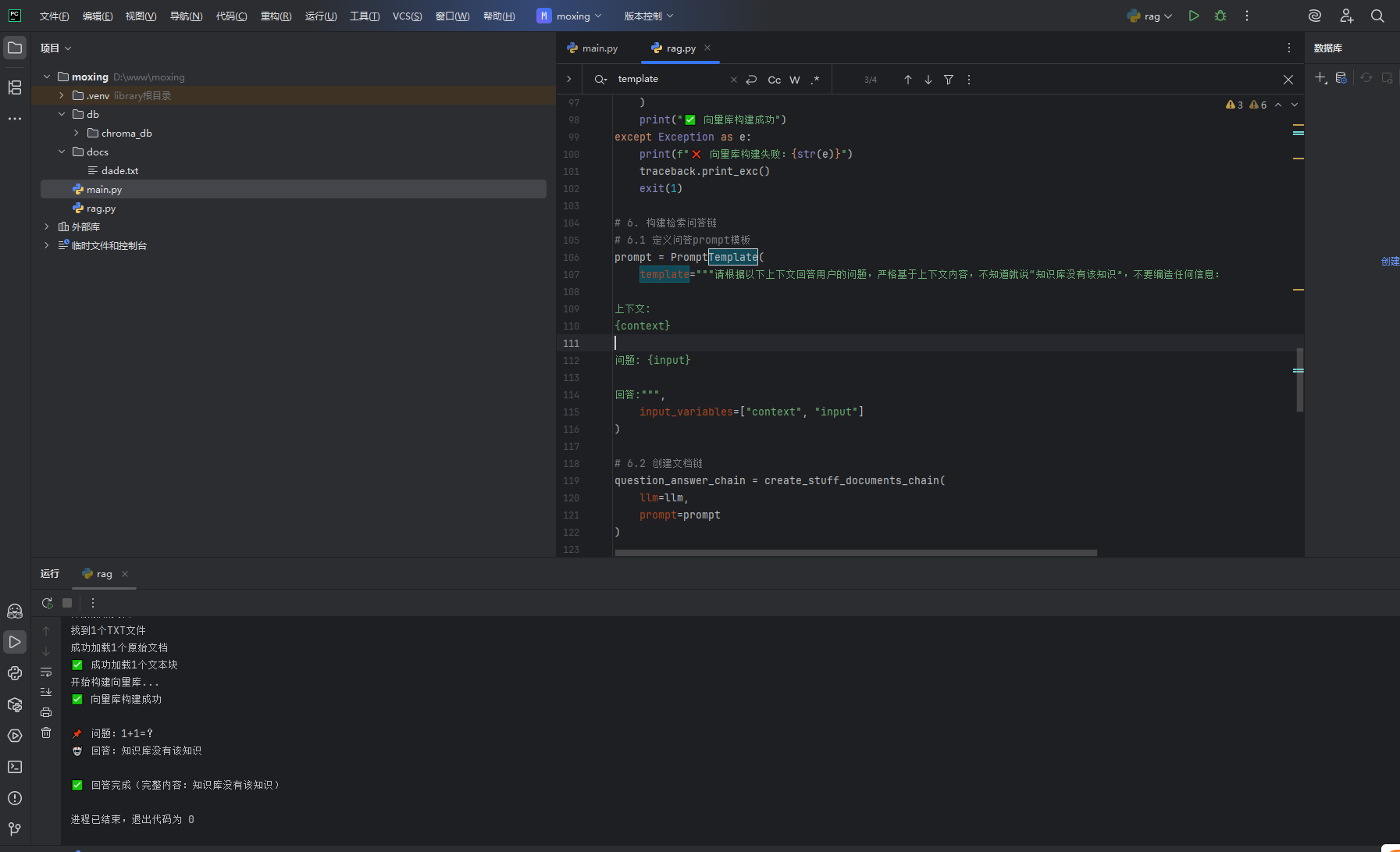
流式输出',知识库没有,按正常回答
# 确保虚拟环境中已安装依赖:
# pip install pypdf python-docx langchain-community chromadb sentence-transformers langchain langchain-core langchain-text-splitters langchain-ollama
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader, Docx2txtLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 核心修复:调整 PromptTemplate 导入路径(适配 LangChain v1.x)
from langchain_core.prompts import PromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
import sys
import traceback
# 1. 加载知识库文档
def load_docs(doc_path):
documents = []
import os
from pathlib import Path
path = Path(doc_path)
# 加载PDF文件
pdf_files = list(path.glob("*.pdf"))
if pdf_files:
print(f"找到{len(pdf_files)}个PDF文件")
for pdf_file in pdf_files:
try:
loader = PyPDFLoader(str(pdf_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载PDF文件 {pdf_file} 失败: {e}")
# 加载Word文档
docx_files = list(path.glob("*.docx"))
if docx_files:
print(f"找到{len(docx_files)}个DOCX文件")
for docx_file in docx_files:
try:
loader = Docx2txtLoader(str(docx_file))
documents.extend(loader.load())
except Exception as e:
print(f"加载DOCX文件 {docx_file} 失败: {e}")
# 加载文本文件
txt_files = list(path.glob("*.txt"))
if txt_files:
print(f"找到{len(txt_files)}个TXT文件")
for txt_file in txt_files:
try:
loader = TextLoader(str(txt_file), encoding="utf-8")
documents.extend(loader.load())
except Exception as e:
print(f"加载TXT文件 {txt_file} 失败: {e}")
return documents
# 2. 文档分块
def split_docs(docs):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""] # 优化中文切分
)
return text_splitter.split_documents(docs)
# 3. 初始化Ollama(开启流式支持)
llm = OllamaLLM(
model="gpt-oss:20b",
base_url="http://127.0.0.1:11434",
streaming=True, # 开启流式输出核心开关
temperature=0.1 # 降低随机性,保证回答准确性
)
embeddings = OllamaEmbeddings(model="nomic-embed-text", base_url="http://127.0.0.1:11434")
# 4. 加载+切分文档
try:
print("开始加载文档...")
docs = load_docs("docs")
print(f"成功加载{len(docs)}个原始文档")
split_documents = split_docs(docs)
print(f"✅ 成功加载{len(split_documents)}个文本块")
except Exception as e:
print(f"❌ 文档加载失败:{str(e)}")
traceback.print_exc()
exit(1)
# 5. 构建向量库
print("开始构建向量库...")
try:
db = Chroma.from_documents(
documents=split_documents,
embedding=embeddings,
persist_directory="./db/chroma_db"
)
print("✅ 向量库构建成功")
except Exception as e:
print(f"❌ 向量库构建失败:{str(e)}")
traceback.print_exc()
exit(1)
# 6. 构建检索问答链
# 6.1 定义问答prompt模板
prompt = PromptTemplate(
template="""请根据以下上下文回答用户的问题。如果有相关上下文,请优先参考上下文内容;如果上下文中没有相关信息,请基于你的知识正常回答问题:
上下文:
{context}
问题: {input}
回答:""",
input_variables=["context", "input"]
)
# 6.2 创建文档链
question_answer_chain = create_stuff_documents_chain(
llm=llm,
prompt=prompt
)
# 6.3 创建检索链
qa_chain = create_retrieval_chain(
retriever=db.as_retriever(search_kwargs={"k": 3}), # 检索top3相关文本块
combine_docs_chain=question_answer_chain
)
# 7. 流式输出核心实现
def stream_qa(question):
"""
流式问答实现
:param question: 用户问题
"""
print(f"\n📌 问题:{question}")
print("🤖 回答:", end="", flush=True) # flush=True 立即输出,避免缓冲区延迟
try:
# 核心改动:使用stream方法替代invoke,获取流式响应
stream_response = qa_chain.stream({"input": question})
# 遍历流式响应,逐块输出
full_answer = ""
for chunk in stream_response:
# 提取回答内容(不同阶段的chunk结构不同)
if "answer" in chunk:
answer_chunk = chunk["answer"]
full_answer += answer_chunk
# 逐块打印(sys.stdout.write 比print更灵活)
sys.stdout.write(answer_chunk)
sys.stdout.flush() # 强制刷新输出缓冲区
print(f"\n\n✅ 回答完成(完整内容:{full_answer.strip()})")
return full_answer
except Exception as e:
print(f"\n\n❌ 流式输出失败:{str(e)}")
traceback.print_exc()
return None
# 8. 测试流式输出
if __name__ == "__main__":
# 测试问题(可替换为你知识库中的内容)
test_question = "1+1=?"
# 执行流式问答
stream_qa(test_question)
# 可添加多轮对话示例
# while True:
# user_input = input("\n请输入你的问题(输入q退出):")
# if user_input.lower() == "q":
# print("退出问答")
# break
# stream_qa(user_input)