目录
[二、核心思想:"伪造者" 与 "鉴别师" 的博弈](#二、核心思想:“伪造者” 与 “鉴别师” 的博弈)
[三、GAN 的基本结构](#三、GAN 的基本结构)
[1. 生成器(Generator)](#1. 生成器(Generator))
[2. 判别器(Discriminator)](#2. 判别器(Discriminator))
[四、数学目标:最小 - 最大博弈](#四、数学目标:最小 - 最大博弈)
[步骤 1:训练判别器(提升鉴别能力)](#步骤 1:训练判别器(提升鉴别能力))
[步骤 2:训练生成器(提升造假能力)](#步骤 2:训练生成器(提升造假能力))
[七、经典 GAN 变体](#七、经典 GAN 变体)
一、引言
生成对抗网络(Generative Adversarial Networks,简称 GAN)是 2014 年由 Ian Goodfellow 等学者提出的生成式机器学习模型,核心思想是通过 "两个网络的对抗博弈" 来学习真实数据的分布,最终让模型具备生成与真实数据高度相似的新样本的能力。
二、核心思想:"伪造者" 与 "鉴别师" 的博弈
GAN 的设计灵感源于现实中的 "对抗场景":
- 把生成器(Generator) 类比为 "伪造者":目标是生成以假乱真的 "假样本"(比如伪造的画作、图片);
- 把判别器(Discriminator) 类比为 "鉴别师":目标是区分输入样本是 "真实样本"(来自真实数据)还是 "生成样本"(伪造者的作品)。
两者通过交替训练、互相提升:伪造者不断优化造假技巧,鉴别师不断提升鉴别能力,最终达到 "伪造者生成的样本足以以假乱真,鉴别师无法区分真假" 的平衡状态 ------ 此时生成器学到了真实数据的分布。
三、GAN 的基本结构
GAN 由生成器(G) 和判别器(D) 两个独立的神经网络组成:
1. 生成器(Generator)
- 输入:低维随机噪声(通常是服从正态分布的向量,记为z);
- 功能:将随机噪声映射为与真实数据同维度的 "生成样本"(记为G(z));
- 输出:与真实数据格式一致的样本(比如 MNIST 手写数字是 28×28 的图像,生成器输出就是 28×28 的矩阵);
- 常用结构:全连接网络、卷积神经网络(如 DCGAN 中用转置卷积生成图像)。
2. 判别器(Discriminator)
- 输入:样本(可以是 "真实样本"x,也可以是生成器输出的 "生成样本"G(z));
- 功能:输出该样本是 "真实样本" 的概率(通常通过 Sigmoid 函数映射到 0~1 之间);
- 目标:对真实样本输出高概率(接近 1),对生成样本输出低概率(接近 0);
- 常用结构:全连接网络、卷积神经网络(如 DCGAN 中用卷积层提取特征)。
四、数学目标:最小 - 最大博弈
GAN 的训练目标是一个最小 - 最大优化问题,核心目标函数为:
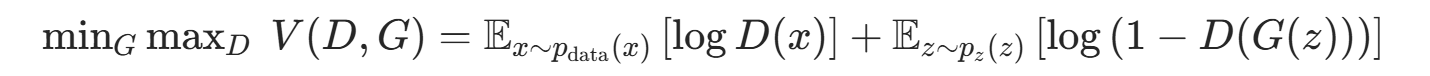
- 对判别器D :要最大化目标函数V(D,G)------ 让真实样本的logD(x)尽可能大(真实样本被判定为 "真" 的概率高),让生成样本的log(1−D(G(z)))尽可能大(生成样本被判定为 "假" 的概率高);
- 对生成器G :要最小化目标函数V(D,G)------ 让生成样本的log(1−D(G(z)))尽可能小(生成样本被判定为 "真" 的概率高,骗过判别器)。
当判别器达到最优状态 时,目标函数会转化为 "真实数据分布" 与 "生成数据分布
" 之间的JS 散度(Jensen-Shannon Divergence)------ 这意味着 GAN 的本质是让生成分布尽可能接近真实分布(JS 散度越小,分布越相似)。
五、训练流程(交替梯度下降)
GAN 的训练是交替优化生成器和判别器的过程,每一轮训练包含两步:
步骤 1:训练判别器(提升鉴别能力)
- 从真实数据集中采样m个真实样本
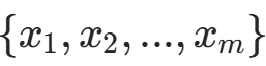 ;
; - 从噪声分布中采样m个噪声向量
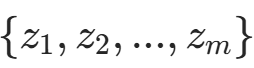 ,通过生成器得到m个生成样本
,通过生成器得到m个生成样本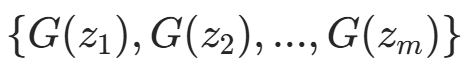 ;
; - 固定生成器参数,计算判别器的损失(真实样本的损失 + 生成样本的损失),通过梯度上升更新判别器参数。
步骤 2:训练生成器(提升造假能力)
- 从噪声分布中采样m个新的噪声向量
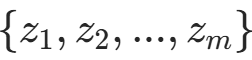 ,通过生成器得到生成样本;
,通过生成器得到生成样本; - 固定判别器参数,计算生成器的损失(让判别器对生成样本输出 "真" 的概率尽可能高),通过梯度下降更新生成器参数。
重复上述两步,直到生成器输出的样本足够逼真(判别器对生成样本的判定概率接近 0.5,无法区分真假)。
六、训练中的经典挑战与改进
原始 GAN 存在一些训练问题,后续研究者提出了大量改进方案:
- 梯度消失:训练初期生成器生成的样本质量差,判别器很容易区分,导致生成器的梯度接近 0,无法有效更新 ------ 改进方案:用 WGAN( Wasserstein GAN)替换 JS 散度为 Wasserstein 距离,缓解梯度消失;
- 模式崩溃:生成器只生成少数几种类型的样本(比如只生成 MNIST 中的 "0"),缺乏多样性 ------ 改进方案:引入多样性约束(如 MGAN)、使用谱归一化;
- 训练不稳定:生成器和判别器的能力容易失衡(比如判别器太强,生成器无法学习)------ 改进方案:DCGAN(规定了卷积层的结构、使用批量归一化)、控制学习率。
七、经典 GAN 变体
GAN 的发展衍生出了大量针对不同场景的变体:
- DCGAN(深度卷积 GAN):用卷积层替代全连接层,是图像生成领域的基础模型;
- WGAN/WGAN-GP:解决原始 GAN 的梯度消失和训练不稳定问题;
- CycleGAN:实现 "无监督图像风格迁移"(比如将马的图片转化为斑马,无需配对数据);
- StyleGAN/StyleGAN2:生成超高分辨率、高真实度的图像(比如人脸生成);
- Text-to-Image GAN:结合文本描述生成对应图像(如 StackGAN)。
八、应用场景
GAN 的生成能力使其在多个领域有广泛应用:
- 图像生成:生成人脸、动漫、艺术作品;
- 图像编辑:风格迁移、图像修复(补全老照片的破损部分)、超分辨率(提升图像清晰度);
- 数据增强:生成新的训练样本(比如医学图像中生成更多病例数据);
- 文本生成:结合 NLP 生成文本(如 GAN 与 Transformer 结合);
- 跨模态生成:从文本、语音等模态生成图像,或反之。
九、生成对抗网络(GAN)的Python代码完整实现
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset, DataLoader
# 配置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# ===================== 1. 定义生成器(Generator) =====================
# 输入:10维随机噪声z | 输出:100维正弦曲线样本(一维序列)
class Generator(nn.Module):
def __init__(self, latent_dim=10, output_dim=100):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 32), # 噪声映射到高维特征
nn.ReLU(),
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, output_dim), # 输出100维正弦曲线序列
nn.Tanh() # 归一化到[-1, 1](匹配正弦值范围)
)
def forward(self, x):
return self.model(x)
# ===================== 2. 定义判别器(Discriminator) =====================
# 输入:100维序列(真实/生成的正弦曲线) | 输出:真假概率(logits)
class Discriminator(nn.Module):
def __init__(self, input_dim=100):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 64), # 输入100维序列
nn.LeakyReLU(0.2), # 避免梯度消失
nn.Linear(64, 32),
nn.LeakyReLU(0.2),
nn.Linear(32, 1) # 输出1维(真假判断)
)
def forward(self, x):
return self.model(x)
# ===================== 3. 超参数与数据准备(无外部数据集) =====================
latent_dim = 10 # 随机噪声维度(简化版,比MNIST的100维更小)
output_dim = 100 # 正弦曲线序列长度(每个样本是100个点的正弦曲线)
batch_size = 32 # 批次大小
lr = 0.0002 # 学习率
epochs = 100 # 训练轮数(一维数据训练更快)
# 生成真实训练数据:正弦曲线(带微小噪声)
def generate_real_data(n_samples):
# 生成n_samples个正弦曲线样本,每个样本100个点
x = np.linspace(0, 2 * np.pi, output_dim) # 0到2π的100个点
data = []
for _ in range(n_samples):
# 随机相位+微小噪声,让真实数据更贴近实际场景
phase = np.random.uniform(0, 2 * np.pi)
noise = np.random.normal(0, 0.05, output_dim)
sin_curve = np.sin(x + phase) + noise
data.append(sin_curve)
# 转换为torch张量(float32,适配GPU)
return torch.tensor(data, dtype=torch.float32)
# 生成1000个真实样本,构建DataLoader
real_data = generate_real_data(1000)
dataset = TensorDataset(real_data) # 仅特征,无标签(GAN无需标签)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# ===================== 4. 初始化模型/损失/优化器 =====================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
generator = Generator(latent_dim, output_dim).to(device)
discriminator = Discriminator(output_dim).to(device)
# 二元交叉熵损失(带Logits)
criterion = nn.BCEWithLogitsLoss()
# Adam优化器(GAN经典选择)
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
# ===================== 5. 对抗训练循环 =====================
# 记录损失变化(用于可视化)
g_losses = []
d_losses = []
for epoch in range(epochs):
epoch_g_loss = 0.0
epoch_d_loss = 0.0
for batch in dataloader:
# 取出批次数据(batch是元组,第一个元素是特征)
real_samples = batch[0].to(device)
batch_size = real_samples.size(0)
# 标签:真实样本=1,生成样本=0(带轻微标签平滑,提升稳定性)
real_labels = torch.ones(batch_size, 1).to(device) * 0.9 # 标签平滑:1→0.9
fake_labels = torch.zeros(batch_size, 1).to(device) + 0.1 # 标签平滑:0→0.1
# -------------------------- 训练判别器 --------------------------
optimizer_D.zero_grad()
# 1. 训练真实样本:判别器识别真实样本为真
output_real = discriminator(real_samples)
loss_real = criterion(output_real, real_labels)
# 2. 训练生成样本:判别器识别生成样本为假
# 生成随机噪声 → 生成假样本 → 判别器判断
z = torch.randn(batch_size, latent_dim).to(device) # 随机噪声
fake_samples = generator(z)
output_fake = discriminator(fake_samples.detach()) # detach避免训练生成器
loss_fake = criterion(output_fake, fake_labels)
# 判别器总损失
loss_D = loss_real + loss_fake
loss_D.backward()
optimizer_D.step()
# -------------------------- 训练生成器 --------------------------
optimizer_G.zero_grad()
# 生成器目标:让判别器把假样本判为真
output_fake_G = discriminator(fake_samples)
loss_G = criterion(output_fake_G, real_labels) # 标签用1(希望判为真)
loss_G.backward()
optimizer_G.step()
# 累计批次损失
epoch_g_loss += loss_G.item()
epoch_d_loss += loss_D.item()
# 计算每轮平均损失
avg_g_loss = epoch_g_loss / len(dataloader)
avg_d_loss = epoch_d_loss / len(dataloader)
g_losses.append(avg_g_loss)
d_losses.append(avg_d_loss)
# 每10轮打印日志
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch + 1}/{epochs}] | 生成器损失: {avg_g_loss:.4f} | 判别器损失: {avg_d_loss:.4f}")
# ===================== 6. 结果可视化 =====================
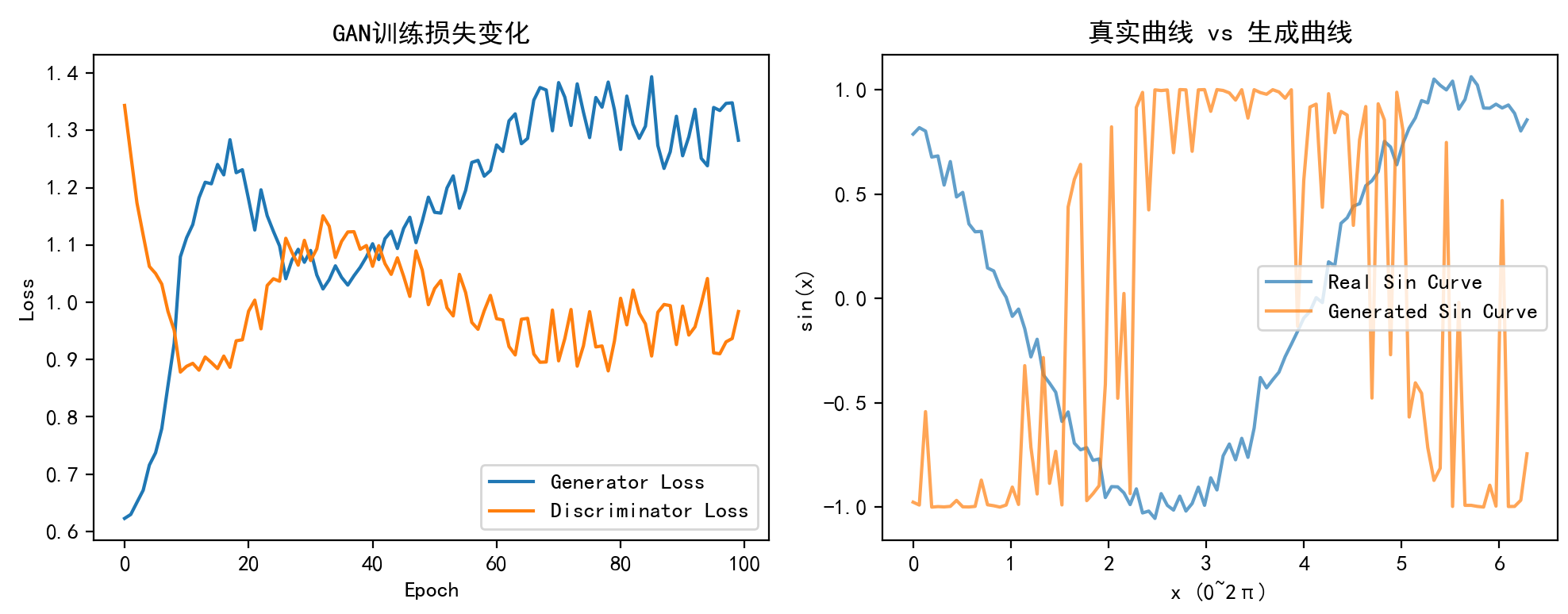
# 6.1 绘制损失变化曲线
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(g_losses, label="Generator Loss")
plt.plot(d_losses, label="Discriminator Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("GAN训练损失变化")
# 6.2 对比真实曲线和生成曲线
plt.subplot(1, 2, 2)
# 生成1个假样本
z = torch.randn(1, latent_dim).to(device)
generated_sample = generator(z).detach().cpu().numpy()[0]
# 取1个真实样本
real_sample = real_data[0].numpy()
# 绘制对比
x = np.linspace(0, 2 * np.pi, output_dim)
plt.plot(x, real_sample, label="Real Sin Curve", alpha=0.7)
plt.plot(x, generated_sample, label="Generated Sin Curve", alpha=0.7)
plt.xlabel("x (0~2π)")
plt.ylabel("sin(x)")
plt.legend()
plt.title("真实曲线 vs 生成曲线")
plt.tight_layout()
plt.show()
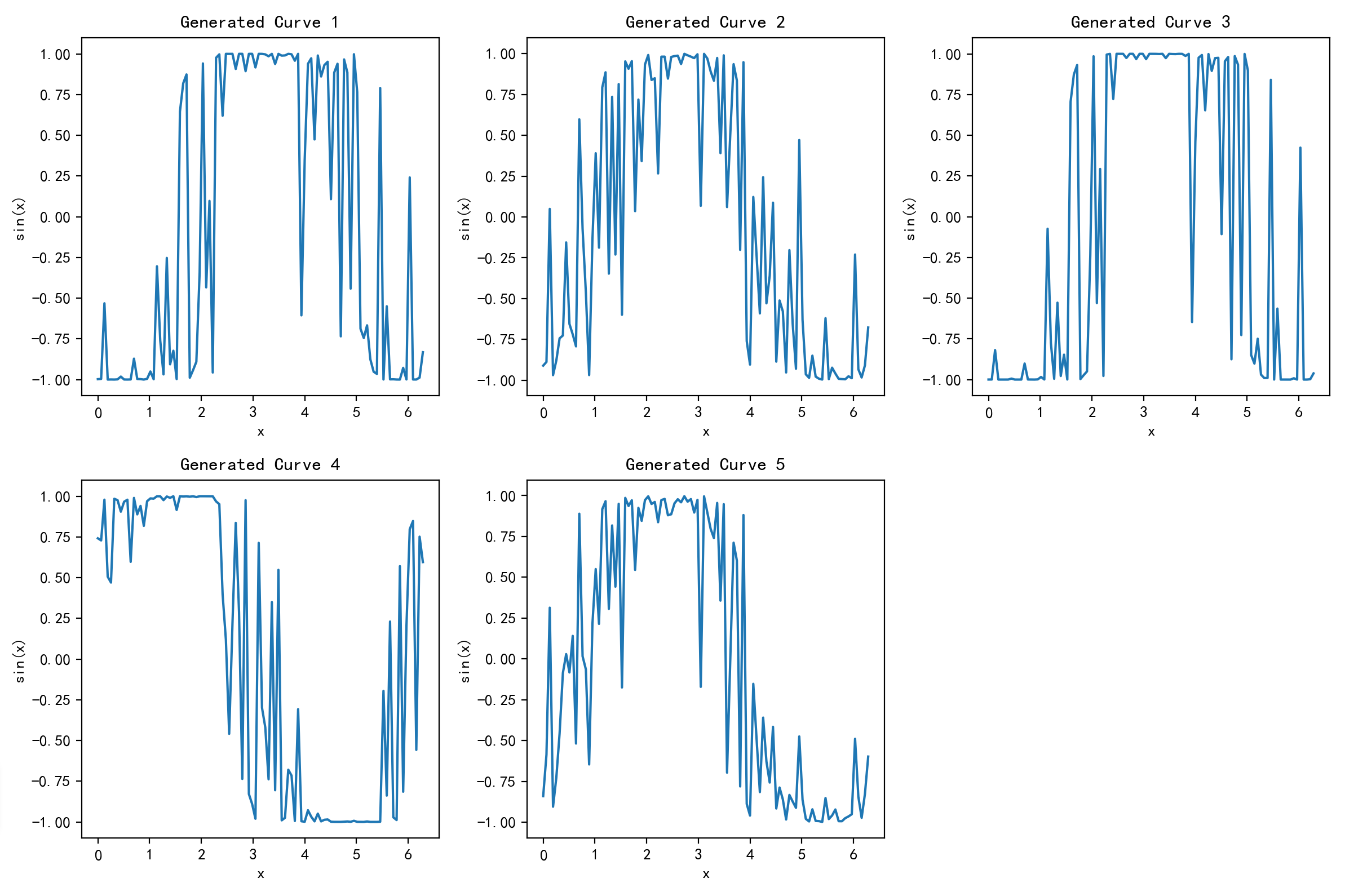
# 6.3 批量生成曲线展示(生成5个不同的正弦曲线)
plt.figure(figsize=(12, 8))
z = torch.randn(5, latent_dim).to(device)
generated_samples = generator(z).detach().cpu().numpy()
x = np.linspace(0, 2 * np.pi, output_dim)
for i in range(5):
plt.subplot(2, 3, i + 1)
plt.plot(x, generated_samples[i])
plt.title(f"Generated Curve {i + 1}")
plt.xlabel("x")
plt.ylabel("sin(x)")
plt.tight_layout()
plt.show()十、程序运行结果展示
Epoch 10/100 | 生成器损失: 1.0794 | 判别器损失: 0.8782
Epoch 20/100 | 生成器损失: 1.2312 | 判别器损失: 0.9345
Epoch 30/100 | 生成器损失: 1.0698 | 判别器损失: 1.1081
Epoch 40/100 | 生成器损失: 1.0791 | 判别器损失: 1.0990
Epoch 50/100 | 生成器损失: 1.1833 | 判别器损失: 0.9957
Epoch 60/100 | 生成器损失: 1.2298 | 判别器损失: 1.0120
Epoch 70/100 | 生成器损失: 1.2993 | 判别器损失: 0.9864
Epoch 80/100 | 生成器损失: 1.3361 | 判别器损失: 0.9323
Epoch 90/100 | 生成器损失: 1.3245 | 判别器损失: 0.9262
Epoch 100/100 | 生成器损失: 1.2827 | 判别器损失: 0.9838
十一、总结
生成对抗网络(GAN)是一种通过生成器与判别器对抗博弈来学习数据分布的深度学习模型。生成器试图生成逼真样本,判别器则负责区分真实与生成样本。本文详细介绍了GAN的核心思想、数学目标、训练流程及常见挑战(如梯度消失、模式崩溃),并列举了DCGAN、WGAN等经典变体。通过Python代码实现了一个生成正弦曲线的简易GAN,展示了训练过程和结果可视化。实验表明,经过100轮训练后,生成器能产生与真实正弦曲线相似的样本,验证了GAN在数据生成任务中的有效性。