文章目录
-
- 一、什么是PyTorch
- 二、什么是CUDA
- 三、为什么要用GPU跑任务
-
-
- [1. CPU与GPU的核心架构差异](#1. CPU与GPU的核心架构差异)
- [2. 任务特性与GPU架构的高度匹配](#2. 任务特性与GPU架构的高度匹配)
- [3. 实际效果:数量级的速度提升](#3. 实际效果:数量级的速度提升)
-
- 四、GPU配置全流程
-
-
- 1.安装anaconda
- 2.创建conda虚拟环境
- 3.安装pytorch
- [4.安装Vs Code开发IDE & 验证GPU是否启用](#4.安装Vs Code开发IDE & 验证GPU是否启用)
-
一、什么是PyTorch
PyTorch是一款开源的深度学习框架,由Facebook的人工智能研究团队开发并维护,目前是全球深度学习领域最主流的框架之一。
它的核心定位是为科研人员和工程师提供灵活、高效的工具,用于构建、训练和部署各种深度学习模型,如图像分类、自然语言处理、语音识别等。PyTorch的核心优势在于支持动态计算图,使用时实时构建计算流程,便于调试和灵活设计复杂模型,同时兼具易用性和高性能。
二、什么是CUDA
CUDA 的全称是Compute Unified Device Architecture(统一计算设备架构),它并非硬件,而是NVIDIA公司推出的一套并行计算平台和编程模型。
简单来说,CUDA的核心作用是:打破了NVIDIA GPU原本仅用于图形渲染,如游戏、图像编辑的限制,为开发者提供了一套编程接口,让开发者能够直接利用GPU的并行计算能力,来加速各类通用的科学计算、工程计算任务,而非仅图形任务。
需要注意的是:CUDA是NVIDIA专属的技术,AMD显卡有对应的OpenCL等替代方案,但生态成熟度远低于CUDA,而PyTorch等深度学习框架,正是通过调用CUDA接口,实现对NVIDIA GPU硬件资源的利用,从而完成模型的加速计算。
三、为什么要用GPU跑任务
用GPU跑任务,尤其是深度学习、大规模数据计算等任务的核心原因,是CPU和GPU的硬件架构差异 ,以及任务特性与GPU架构的高度匹配,具体拆解如下:
1. CPU与GPU的核心架构差异
| 特性 | CPU(中央处理器) | GPU(图形处理器) |
|---|---|---|
| 核心数量 | 少(通常2-64核,主流消费级4-16核) | 极多(成百上千个流处理器/核心,如NVIDIA A100有5496个CUDA核心) |
| 缓存大小 | 大(便于快速读取少量关键数据) | 小(仅能缓存少量高频数据) |
| 设计定位 | 擅长串行计算(复杂单任务逻辑处理,如操作系统调度、办公软件运行) | 擅长并行计算(大量简单任务同时执行,如重复的矩阵运算、数据遍历) |
| 计算效率 | 单核心计算能力强,多任务串行高效 | 单核心计算能力弱,多任务并行效率极高 |
2. 任务特性与GPU架构的高度匹配
我们日常用GPU加速的任务,如深度学习训练/推理、3D渲染、大数据分析、科学模拟等,都具备一个核心特征:包含大量可并行化的简单重复运算。
以深度学习任务为例,模型训练过程中需要频繁进行矩阵乘法、卷积运算、梯度下降迭代等操作:
- 这些运算本质上是大量相同的简单计算,如矩阵中每个元素的乘法和加法,可以被拆分到GPU的上千个核心中同时执行;
- 例如:一个1000×1000的矩阵乘法,CPU需要逐个元素串行计算,而GPU可以同时启动数千个核心,并行处理数百组元素的计算,瞬间完成任务。
3. 实际效果:数量级的速度提升
正是由于上述架构差异和任务匹配度,GPU跑这类密集型计算任务的速度,远超CPU:
- 比如训练一个简单的图像分类模型,CPU可能需要数天甚至数周,而入门级NVIDIA GPU比如RTX 3060可能只需几小时,高端专业GPU甚至只需几十分钟;
- 即使是轻量的模型推理任务,GPU的速度也能比CPU快10倍以上,满足实时性需求,如视频实时目标检测。
四、GPU配置全流程
1.安装anaconda
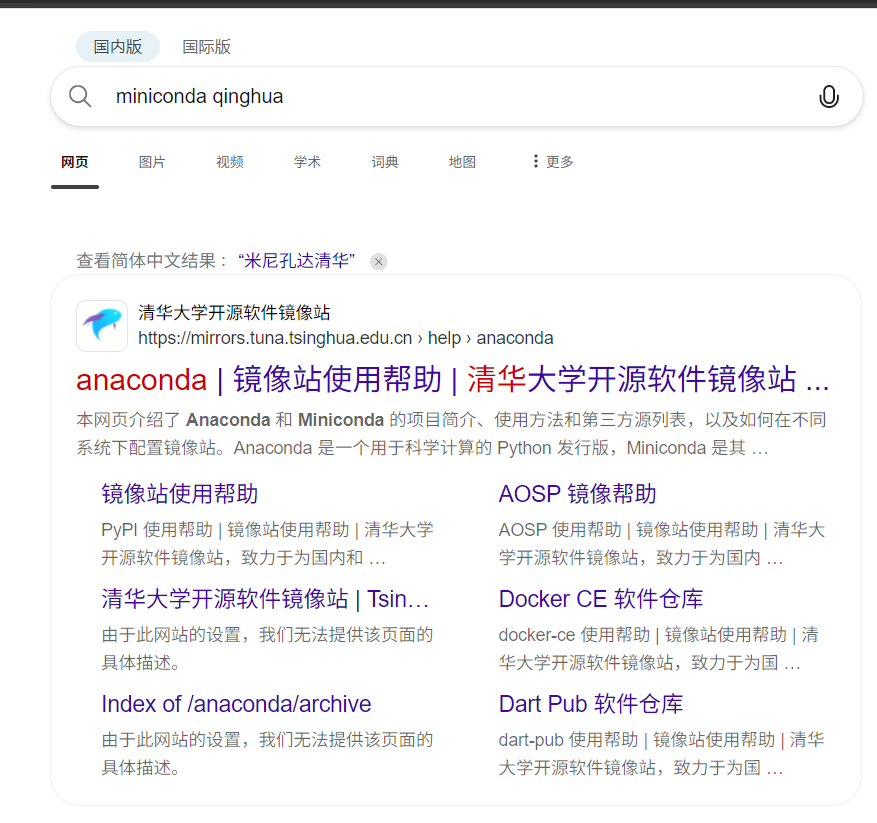
首先进入浏览器输入:miniconda qinghua 进入清华镜像中,选择对应的py版本即可,不过一般要选择3.9版本以上
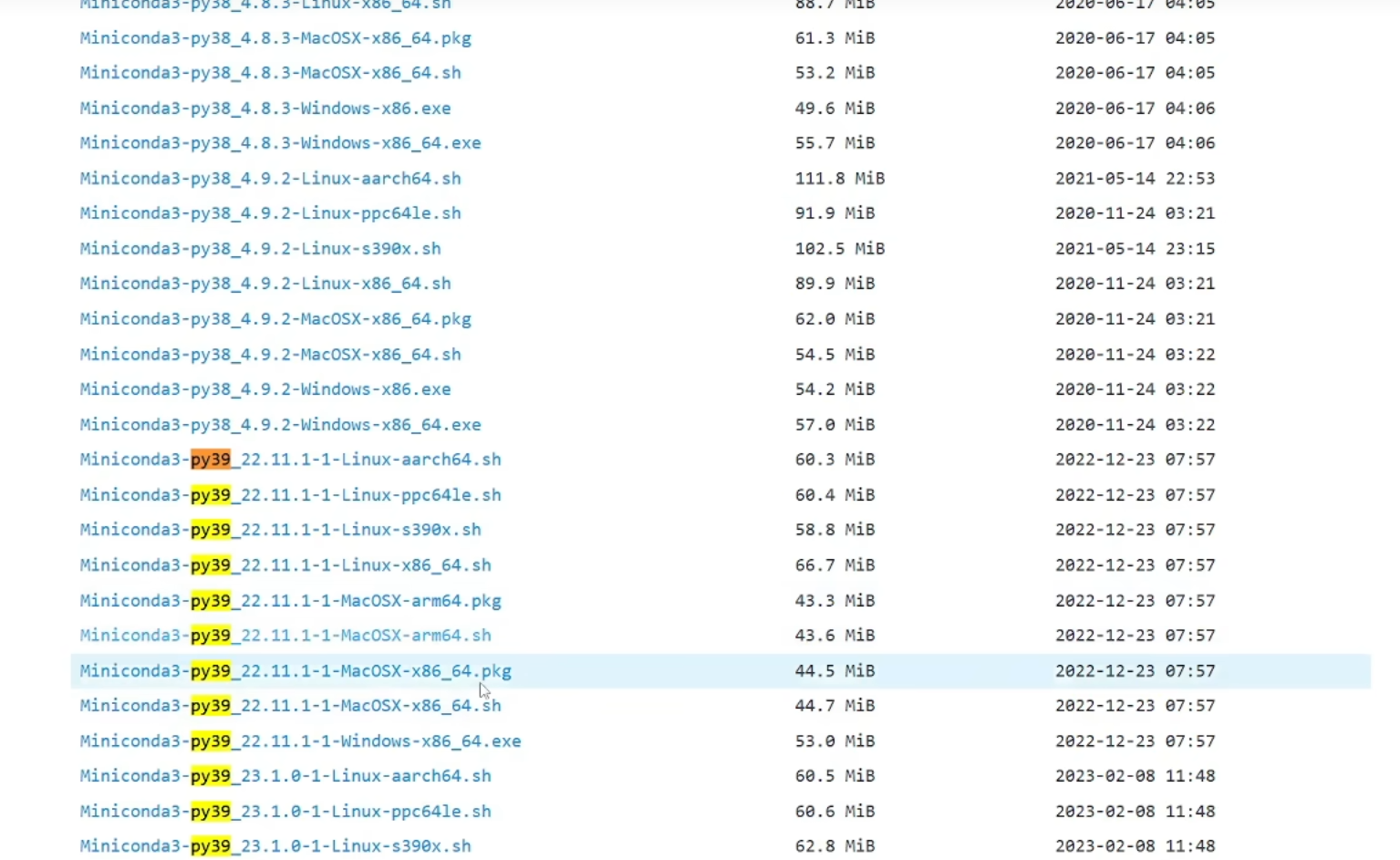
下完成后双击打开,进入安装页面,基本上就是点点点、下一步就可以了,不过需要注意的是安装路径中最好是不要有中文和空格,另外在环境配置页面要勾选中间那个Add...选项,接下来install就可以了。
2.创建conda虚拟环境
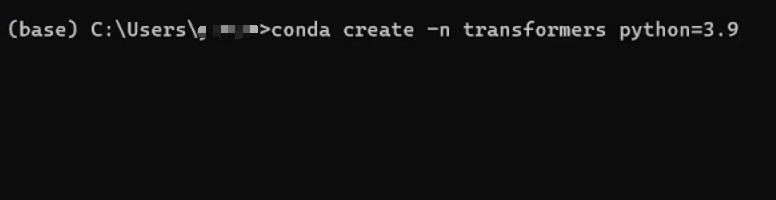
按住win+r打开命令界面后,输入cmd打开终端,输入
matlab
conda create -n 你的环境名称 python=3.9即可创建3.9版本的python虚拟环境
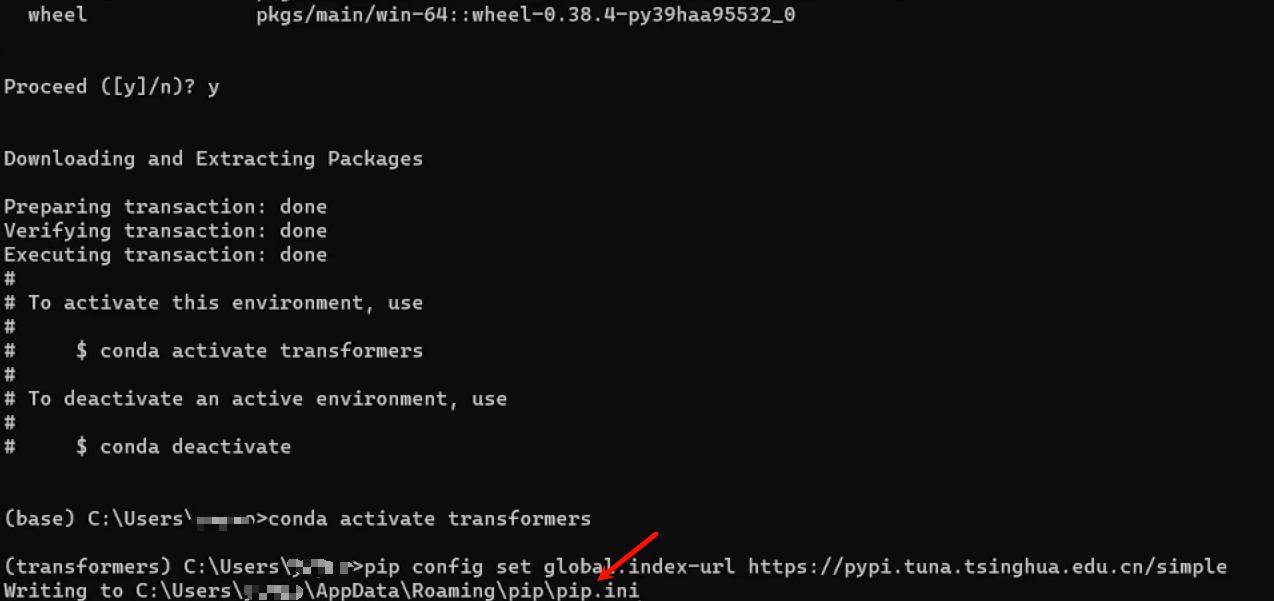
安装好后输入
matlab
conda activate 你的环境名称 进入到虚拟环境中,因为我们的库都会安装到这个环境下面,由于可能不同库版本不一致无法兼容,避免造成主环境崩溃,所以一般会利用虚拟环境进行跑任务。
接下来可以在命令行中输入:
matlab
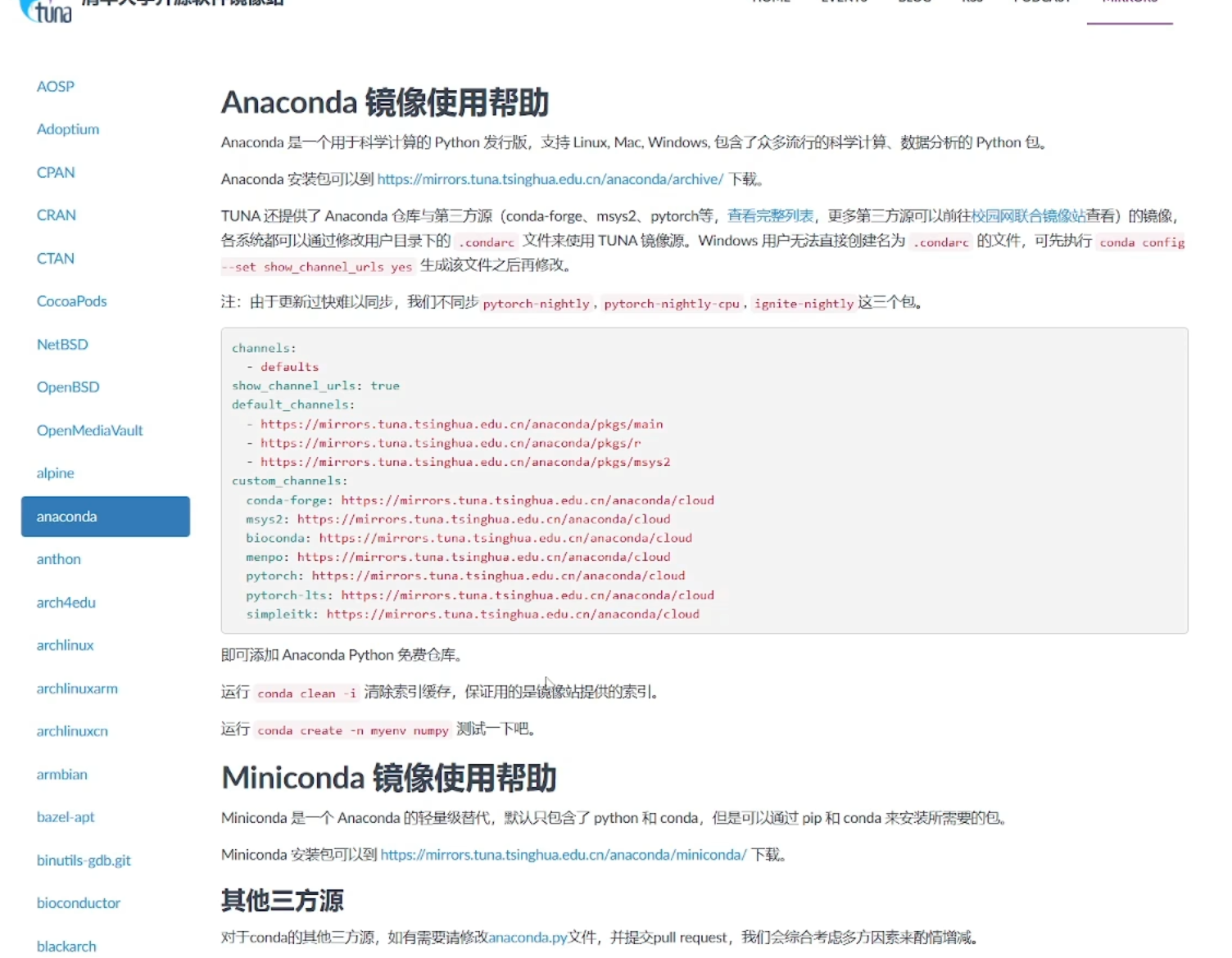
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple这个是将下载源设置到国内清华镜像源中,能大大提高库的下载速度,出现最下面一行表示设置成功
3.安装pytorch
pytorch安装官方地址:pytorch,有一些注意事项:
1.在一个单独的环境中,能使用pip就尽量使用pip,实在有问题的情况,例如没有合适的编译好的系统版本的安装包,再使用conda进行安装,不要来回混淆。
2.30XX、40XX显卡,要安装cu11以上的版本,否则无法运行。
3.如果只需要训练、简单推理,则无需单独安装CUDA,直接安装pytorch
安装教程可参考pytorch安装,这里就不过多赘述了。
总之就是先查看自己的显卡型号,比如这边的13.0.84的,则可以下载小于13.0.84的版本。然后进入到官网选择自己需要下载的版本,将命令复制到刚刚创建的虚拟环境中即可,建议使用pip命令安装,如果中间有报错可以查看上面的pytorch安装,看看是否能解决。
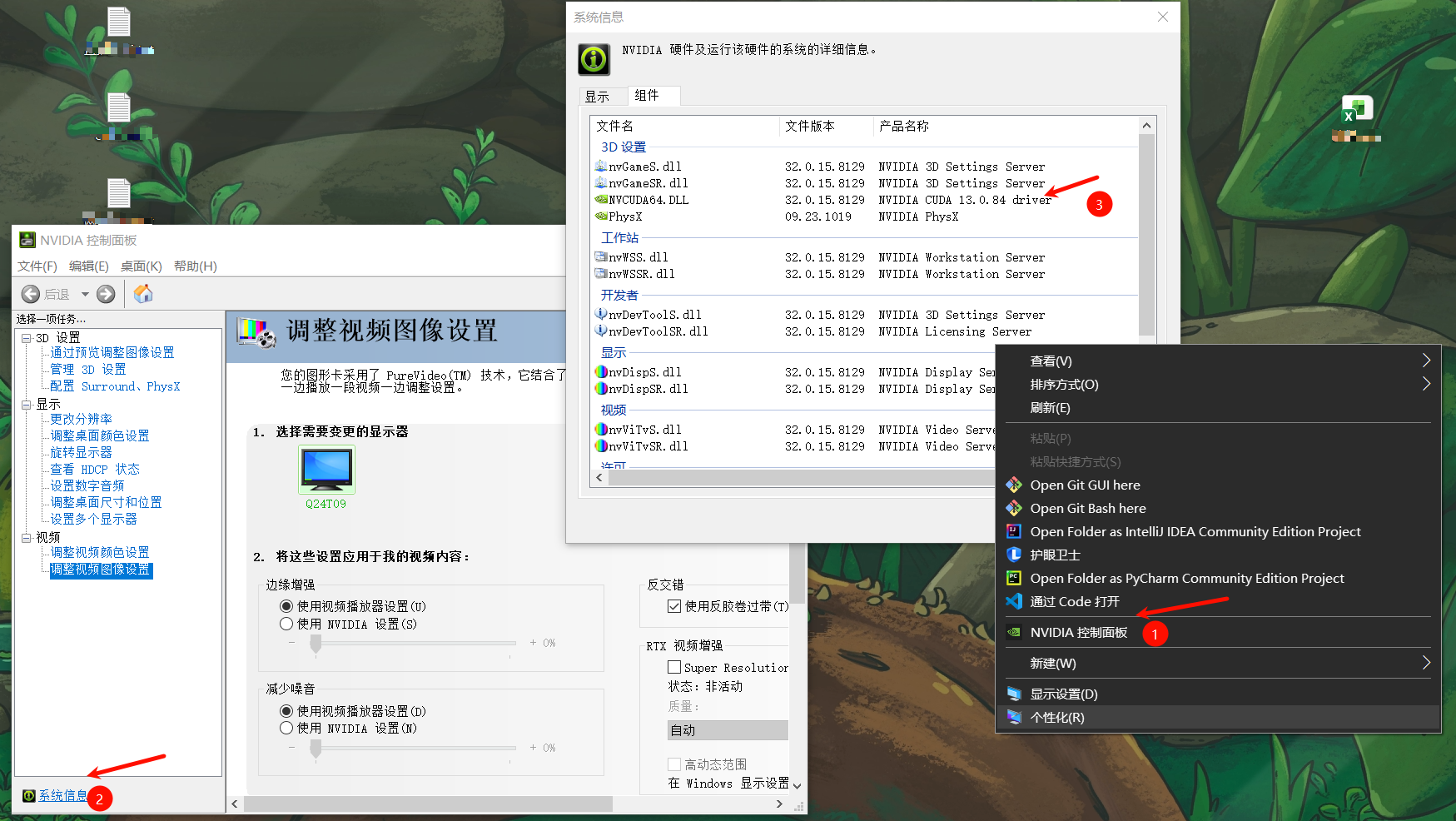

安装完成后,输入查看cuda是否能使用
matlab
python
import torch
torch.cuda.is_available()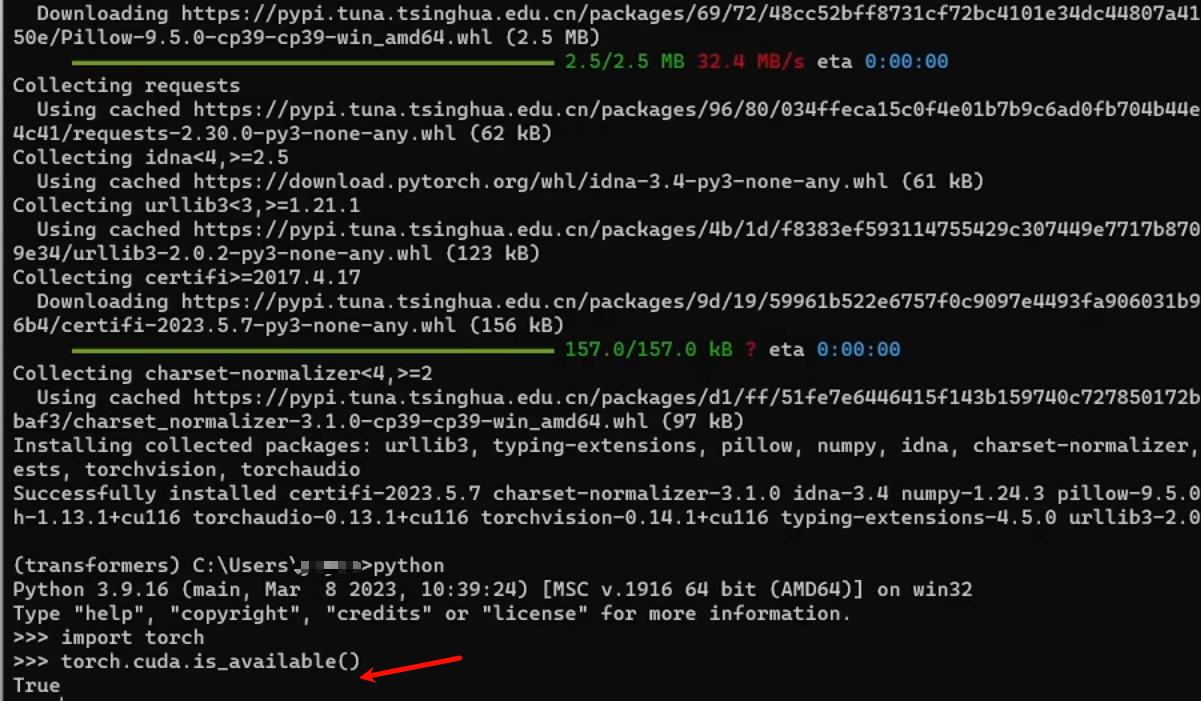
4.安装Vs Code开发IDE & 验证GPU是否启用
也可以按照自己的喜好安装IDE,Vs Code去官网打开下载即可,然后安装python、jupyter、中文插件就行了,基本上就是点点点,这里就不过多赘述了。
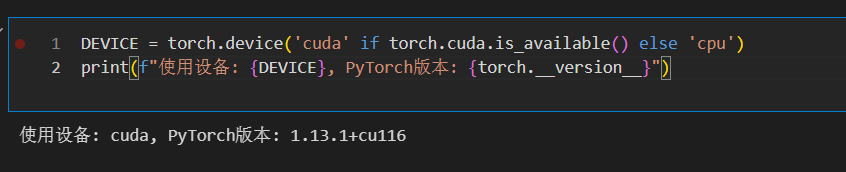
接下来打开vs code,输入以下命令查看是否启用,可以看到已经能够正常的启用gpu了,接下来跑深度学习的任务可以利用GPU并行加速即可。
matlab
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {DEVICE}, PyTorch版本: {torch.__version__}")