系列文章目录
- 第一章 【大数据环境安装指南】 JDK安装
- 第二章 【大数据环境安装指南】 Python安装
- 第三章 【大数据环境安装指南】VMware虚拟机静态IP及多IP配置
- 第四章 【大数据环境安装指南】Zookeeper单机环境和集群环境搭建
文章目录
- 系列文章目录
- 前言
- 一、前置条件(所有节点必做)
-
- [1.1 基础环境要求:](#1.1 基础环境要求:)
- [1.2 Storm 与 JDK 版本兼容性](#1.2 Storm 与 JDK 版本兼容性)
- [1.3 下载并解压 Storm 安装包:](#1.3 下载并解压 Storm 安装包:)
- [1.4 配置环境变量(所有节点):](#1.4 配置环境变量(所有节点):)
- 二、部署教程
-
- [2.1 集群规划(3 节点示例)](#2.1 集群规划(3 节点示例))
- [2.2 核心配置修改(所有节点)](#2.2 核心配置修改(所有节点))
- 三、启动集群(按节点角色执行)
-
- [3.1 启动 ZooKeeper 集群(先于 Storm,生产必做)](#3.1 启动 ZooKeeper 集群(先于 Storm,生产必做))
- [3.2 启动 Nimbus 主节点(node1)](#3.2 启动 Nimbus 主节点(node1))
- [3.3 启动 Supervisor 从节点(node2、node3)](#3.3 启动 Supervisor 从节点(node2、node3))
- 四、验证集群是否搭建成功
-
- [4.1 查看进程(核心)](#4.1 查看进程(核心))
- [4.2 访问 Storm UI(可视化验证)](#4.2 访问 Storm UI(可视化验证))
前言
操作系统环境 :Centos 7、Rocky 9 、Kylin V11
Storm版本 :2.4.0
JDK版本 :8
Python版本 :3.11
Zookeeper版本:3.8.4
Apache Storm 是开源、分布式、高容错的实时流式计算框架,核心目标是解决「低延迟实时数据处理」问题(毫秒级响应),适用于需要对无限流数据进行实时处理的场景(如实时日志分析、实时监控、实时推荐)。
关键特性:
- 超低延迟:纯事件驱动模型,数据逐条处理,延迟可达毫秒级(对比 Flink 兼顾吞吐量,延迟通常为毫秒 / 秒级);
- 高容错:节点故障时自动重新分配任务,支持 Tuple 重放(At-least-once 语义);
- 水平扩展:通过增加 Supervisor 节点 / Worker 进程线性提升处理能力;
- 多语言支持:核心用 Java 开发,但支持 Java、Python、C++ 等多语言编写业务逻辑;
- 灵活部署:支持 Standalone 集群、YARN/Mesos 集群、本地开发模式。
Storm 与主流流式框架对比:
| 维度 | Apache Storm | Apache Flink | Spark Streaming |
|---|---|---|---|
| 处理模型 | 纯事件驱动(逐条) | 批流统一(微批 + 流) | 微批处理(秒级) |
| 延迟 | 毫秒级(超低) | 毫秒 / 秒级(可配置) | 秒级(较高) |
| 吞吐量 | 较低 | 高 | 中高 |
| 状态管理 | 需手动集成(Redis/ZK) | 内置(RocksDB) | 内置(内存 / 磁盘) |
| 语义支持 | 原生 At-least-once | 原生 Exactly-once | 原生 Exactly-once |
| 窗口支持 | 需手动实现 | 丰富(滚动 / 滑动 / 会话) | 丰富(滚动 / 滑动) |
| 适用场景 | 低延迟实时监控、告警 | 高吞吐有状态计算、批流统一 | 批流一体化、机器学习集成 |
一、前置条件(所有节点必做)
1.1 基础环境要求:
- 至少 3 台服务器(1 台 Nimbus 主节点 + 2 台 Supervisor 从节点,推荐奇数台);
- 所有节点安装 JDK 8(Storm 2.x 推荐 JDK 8,JDK 11 需额外适配);
所有节点关闭防火墙 / 开放必要端口,且能互相 ping 通、SSH 免密登录(核心!); - 所有节点必须已经安装了python
- 可选:搭建 ZooKeeper 集群(Storm 依赖 ZK 做集群协调,生产必须,单机测试可省略)。ZooKeeper 集群搭建教程参考:
【大数据环境安装指南】Zookeeper单机环境和集群环境搭建
1.2 Storm 与 JDK 版本兼容性
| Storm 版本 | 支持的 JDK 版本 | 推荐生产环境使用 | 备注 |
|---|---|---|---|
| Storm 1.x (1.0-1.2) | JDK 7、JDK 8 | JDK 8 | JDK 7 已停止维护,1.2 后逐步弱化对 JDK 7 的支持 |
| Storm 2.0-2.2 | JDK 8 (主要)、JDK 11 (实验性) | JDK 8 | JDK 11 支持不完整,存在部分兼容性问题 |
| Storm 2.3+ (2.3-2.6) | JDK 8、JDK 11 (正式支持) | JDK 8 / JDK 11 | 2.3 起完全兼容 JDK 11,无核心功能限制 |
| Storm 3.0+ | JDK 8、JDK 11、JDK 17 (实验性) | JDK 11 | JDK 17 为实验性支持,暂不建议生产使用 |
注意:Storm 2.x最新的高版本可能不兼容jdk,比如Storm 2.8不兼容jdk 8
1.3 下载并解压 Storm 安装包:
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
bash
# 下载 Storm 2.4.0 稳定版(也可手动下载上传)
wget https://archive.apache.org/dist/storm/apache-storm-2.4.0/apache-storm-2.4.0.tar.gz
# 解压到统一目录
tar -zxvf apache-storm-2.4.0.tar.gz -C /usr/local/app
# 添加软连接
ln -s /usr/local/app/apache-storm-2.4.0 /usr/local/app/storm
# 创建日志/数据目录(所有节点)
mkdir -p /usr/local/app/storm/logs
mkdir -p /usr/local/app/storm/data1.4 配置环境变量(所有节点):
bash
# 编辑 /etc/profile
sudo vim /etc/profile
# 添加以下内容
export STORM_HOME=/usr/local/app/storm
export PATH=$STORM_HOME/bin:$PATH
export JAVA_HOME=/usr/local/jdk8/ # 替换为你的 JDK 路径
# 生效配置
source /etc/profile
# 验证
storm version # 输出 Storm 2.4.0 即正常
二、部署教程
2.1 集群规划(3 节点示例)
以 3 台服务器为例(替换为你的实际 IP / 主机名),角色分配如下:
| 节点 IP | 主机名 | 角色 | 核心端口 |
|---|---|---|---|
| 192.168.3.129 | node1 | Nimbus + UI + ZK | 6627/8080 |
| 192.168.3.130 | node2 | Supervisor + Worker | 6700-6703 |
| 192.168.3.131 | node3 | Supervisor + Worker | 6700-6703 |
2.2 核心配置修改(所有节点)
Storm 核心配置文件为 $STORM_HOME/conf/storm.yaml,所有节点需保持配置一致(除特殊说明)。
1、 编辑 storm.yaml
bash
vim /usr/local/app/storm/conf/storm.yaml2、添加以下配置(关键项必配)
yaml
# 1. 集群唯一标识(自定义)
storm.cluster.mode: "distributed"
# ZK 集群节点(单机 ZK 填单个,集群填所有 ZK 节点)
storm.zookeeper.servers:
- "node1"
- "node2"
- "node3"
storm.zookeeper.port: 2181
# Storm 在 ZK 中的根节点
storm.zookeeper.root: "/storm"
# 2. Nimbus 主节点地址(核心)
nimbus.seeds: ["node1"]
# Nimbus 通信端口
nimbus.thrift.port: 6627
# 监控 Supervisor 频率
nimbus.monitor.freq.secs: 10
# 3. Supervisor 配置(从节点生效)
# 每个 Supervisor 启动的 Worker 端口(可配多个,如 6700-6703)
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
# 监控 Worker 频率
supervisor.monitor.freq.secs: 5
supervisor.worker.start.timeout.secs: 60
supervisor.worker.stop.timeout.secs: 60
# 4. Worker 配置
# 每个 Worker 内存(按需调整)
worker.childopts: "-Xmx1024m"
storm.worker.cleanup.interval.secs: 600
# 5. UI 配置(Nimbus 节点生效)
# Storm UI 端口(默认 8080,避免与 Flink 冲突可改 8084)
ui.port: 8084
# UI 绑定所有网卡,外部可访问
ui.host: "0.0.0.0"
# 6. 日志/数据目录(所有节点)
storm.local.dir: "/usr/local/app/storm/data"
storm.log.dir: "/usr/local/app/storm/logs"
# 7. JVM 配置(优化)
nimbus.childopts: "-Xmx2048m"
supervisor.childopts: "-Xmx2048m"
ui.childopts: "-Xmx1024m"三、启动集群(按节点角色执行)
3.1 启动 ZooKeeper 集群(先于 Storm,生产必做)
- 若未搭建 ZK 集群,可参考 详细搭建教程: 【大数据环境安装指南】Zookeeper单机环境和集群环境搭建
- 若已搭建 ZK 集群,确保所有 ZK 节点启动:
bash
# 在每个 ZK 节点执行
/usr/local/app/zookeeper/bin/zkServer.sh start
# 验证 ZK 状态(有 Leader/Follower 即为正常)
/usr/local/app/zookeeper/bin/zkServer.sh status
3.2 启动 Nimbus 主节点(node1)
bash
# 后台启动 Nimbus
nohup storm nimbus > /usr/local/app/storm/logs/nimbus.log 2>&1 &
# 启动 UI 监控(可选,便于查看集群状态)
nohup storm ui > /usr/local/app/storm/logs/ui.log 2>&1 &
# 启动 Logviewer(查看 Worker 日志,可选)
nohup storm logviewer > /usr/local/app/storm/logs/logviewer.log 2>&1 &
3.3 启动 Supervisor 从节点(node2、node3)
bash
# 在每个 Supervisor 节点后台启动
nohup storm supervisor > /usr/local/app/storm/logs/supervisor.log 2>&1 &
# 启动 Logviewer(可选)
nohup storm logviewer > /usr/local/app/storm/logs/logviewer.log 2>&1 &四、验证集群是否搭建成功
4.1 查看进程(核心)
-
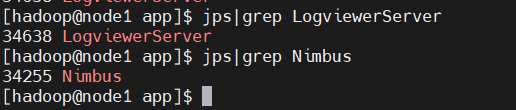
Nimbus 节点:执行 jps,应看到 Nimbus、UI(可选)、Logviewer(可选)进程;
-
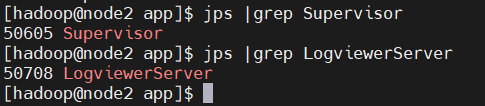
Supervisor 节点:执行 jps,应看到 Supervisor、Logviewer(可选)进程。
4.2 访问 Storm UI(可视化验证)
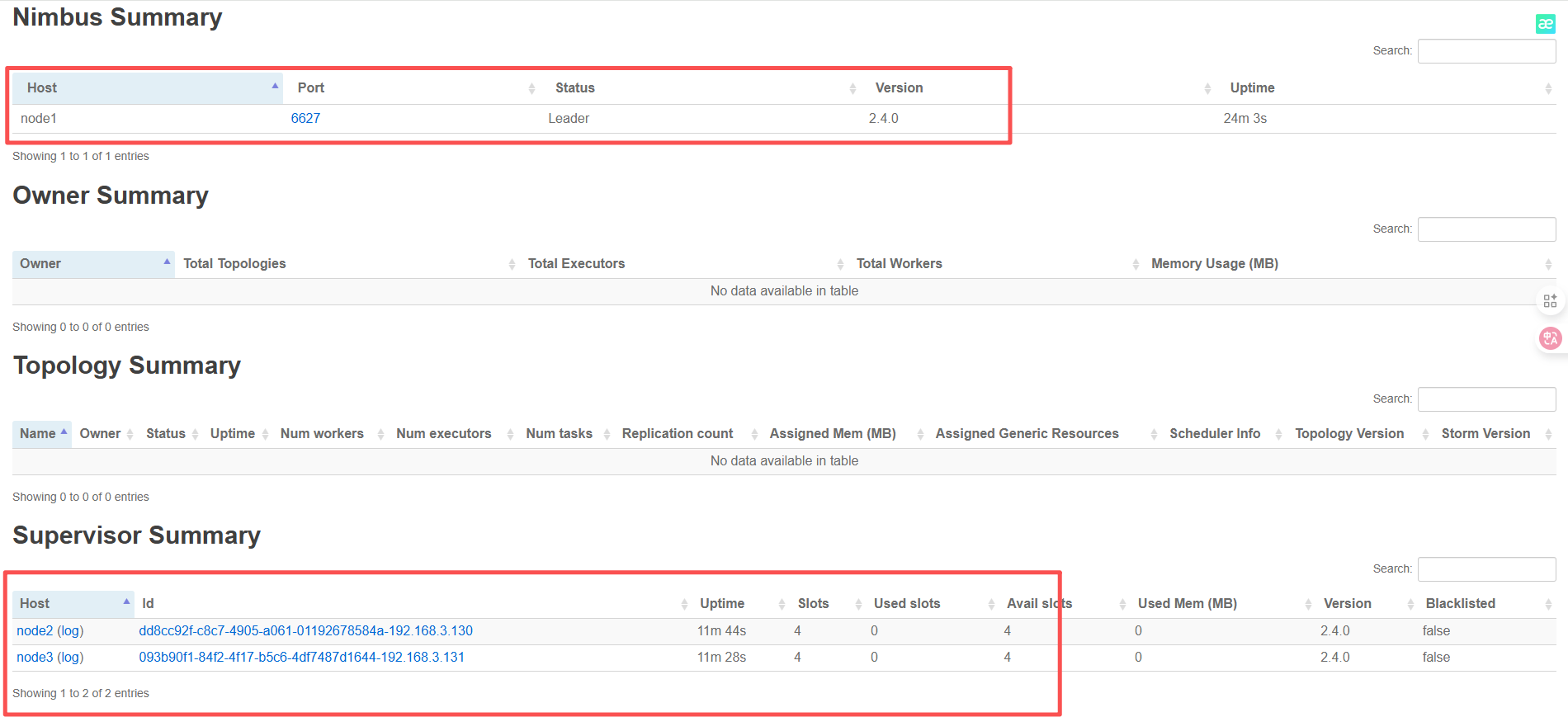
浏览器访问 http://node1:8084(若改了端口则对应调整),正常显示以下内容即为集群就绪:
- 顶部显示 Nimbus Status: ACTIVE;
- Supervisors 列表显示 node1、node2,状态为 UP;
- Slots 列显示配置的端口数(如 4 个 slots)。