这篇文章介绍Transformer结构在计算机视觉领域自监督的工作,需要了解
Transformer基础结构:深度学习基础-5 注意力机制和Transformer
基于Transformer的Backbone:计算机视觉Transformer-1 基础结构
知识蒸馏相关知识:模型压缩-知识蒸馏
向量数据库相关知识:大模型应用开发-向量数据库
要确保自己已经了解了以上内容,要不然下面的有些内容会不理解。
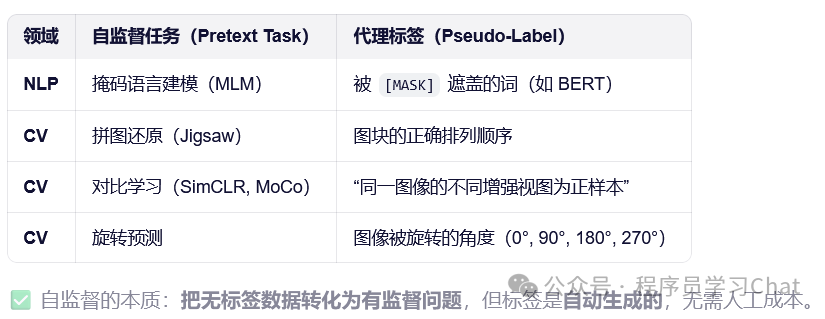
自监督属于无监督学习中的一种,说无监督学习之前先说监督学习,好进行二者的对比。监督学习为每个数据x人工标记标签y,这些(x,y)作为训练数据集训练深度学习模型,y作为一种监督信号引导深度学习模型学习数据集中包含的规律f(x)=y,然后可以利用这个学习到的f(x),对于一个不在训练数据集中的新数据x'做出较为准确的预测y',准确是指要么y'=y,要么二者之间的差距非常小,小到可以忽略,监督学习这种方式致命的弱点就是过度依赖人工标注,深度学习模型的准确性依赖训练数据的规模、数据质量,数据越多越准,那么监督学习需要人工标记的数据也就越来越多,成本会非常高。
无监督学习不需要人工对数据x进行标记,而是让模型自己学习数据集中数据所具有的分布模式p(x),常说的聚类算法就是一种代表性的无监督学习方法,可以看:。
自监督是无监督学习中的一种,无监督方法(如 K-Means)通常直接用于最终任务(比如客户分群),而自监督的目标是预训练一个特征提取器(如 ResNet、BERT),其学到的特征表示可以迁移到各种下游任务中。自监督不依赖人工标记标签,但是会预先定义一个自监督学习任务,根据这个任务可以生成模型要学习的目标,也就是产生了监督信号,一般称这个监督信号为伪标签(pseudo label),和真实人工标记的标签进行区分。举个例子,在自然语言处理中,为了让语言模型学会语言的结构、语义等特征,可以从一句话中随机删除掉一些词语,然后将预测删除掉的词语作为一种自监督训练任务来训练模型,如"我今天早上吃的油条"变为"我今天早mask1吃的油mask2",模型要做的事就是正确预测出mask1='上'、mask2='条',随着模型预测越来越准,反面也说明了模型学会了语言中的结构、语义等信息,事实上现在所说的"大模型预训练"指的就是这个过程,自监督学习过程相当于是一个自己出题,自己答的过程。
自监督预训练方法在NLP领域取得了成功,自然就会想到能否将这种不需要人工标记的学习方法迁移到其它领域,这篇文章介绍的工作就是计算机视觉领域借助Transformer结构进行自监督学习的方法。
一 MAE
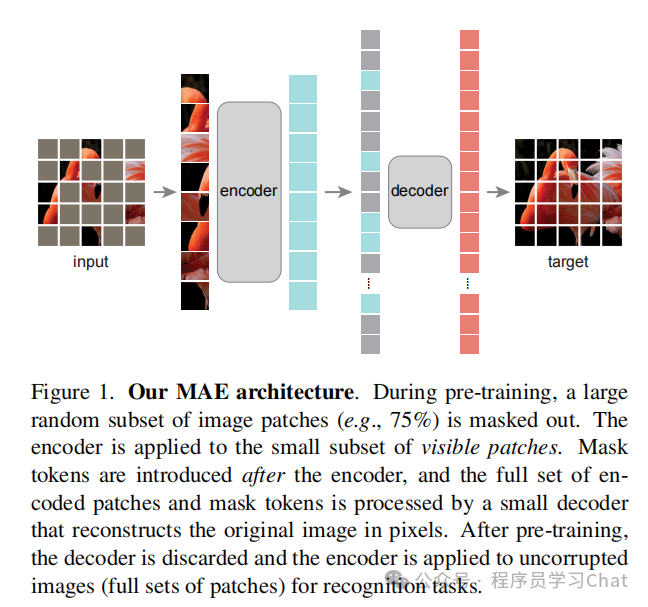
类似自然语言处理中"mask掉词语->预测被mask的词语",MAE将图像进行mask,然后让网络预测、还原出这些被mask掉的部分
那么自然就有以下几个问题:
1.1 怎么mask
自然语言处理中的句子随意mask词语就可以,因为只有一维的结构,图像是一个二维序列,如何对图像mask?
MAE整体结构采用的是ViT,mask方法是按照一定比例移除掉部分patch,作者尝试了以下几种mask方法:

1)Random:随机移除patch
2)Block:移除某个区域范围内的所有patch
3)Grid:按照网格的方式移除patch
实验表明随机移除的方式更好,所以MAE采取的是随机移除patch的mask策略,将未被移除的patch输入到Encoder中进行特征编码
1.2 mask比例是多少
Mask的目的是为了让模型能够学习到图像中具有的高层次语义特征,如果mask比例过小,模型会从邻近patch纹理、边缘的角度恢复被mask的区域,而不是从高层次的语义特征角度去恢复mask区域,也就是mask比例过低会导致模型"偷懒",但是如果mask比例过高,大部分的patch都mask掉,模型又会学习不到高层次的语义特征,因为你给的信息实在有限,作者通过实验发现Mask比例为75%时效果最好

1.3 MAE整体流程
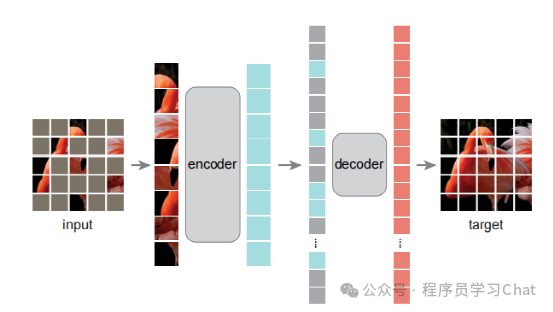
1)输入图像分为固定大小的多个patch,随机mask,也就是按照一定比例移除掉一部分patch
2)将剩余的patch结合位置编码送到encoder中编码高层语义特征,位置编码也是ViT的1D可学习编码向量方式
3)为被mask掉的patch生成一个可学习的编码向量,和encoder的输出按照原来各个patch的位置排列,添加完1D位置编码后输入到decoder中进行整体图像解码
4)decoder解码出整个图像,求每个被mask部分的解码输出和真实图像像素值的均方误差,反向传播训练整个MAE网络
注意decoder中没有以往Transformer中的cross attention,只是根据encoder+mask编码向量解码出原图像,求损失时只求被mask掉patch位置和原图像的损失,使训练更加稳定
1.4 细节问题
自然语言mask预测任务和图像mask预测任务有什么区别?


Encoder只可见图像的部分patch,会不会影响语义特征提取的准确性


二 DINO
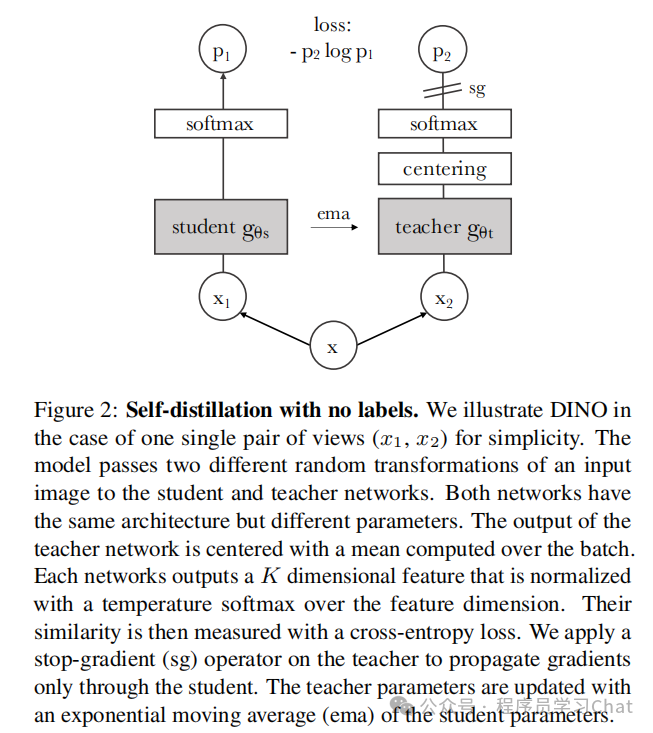
MAE通过复原图像mask的patch块的方式,让Transforer从输入图像中提取高层次的语义特征,这相当于是一种细粒度的语义学习,因为它强迫模型学习不同patch之间的语义差异。DINO利用自蒸馏的方式,让模型学习图像的全局语义信息表示,不对图像进行mask操作,最终模型会通过Transformer的注意力机制+编码结构学习到图像中的"关键物体"这种全局的信息表示,如下图

自监督学习中有个问题:"坍塌"。
自监督的本意是通过自监督训练任务,不借助人工标记标签,自动学习数据中包含的特征信息,但是如果自监督训练任务设计的不好或者自监督模型结构设计的不合理,会出现坍塌的现象,本来一个合格的自监督模型应该对不同的输入产生不同的特征表示输出,但是如果自监督失败,出现坍塌,无论你输入什么到模型中,它都会给你一个相同的特征表示输出




2.1 DINO整体流程
DINO整体基于自蒸馏的策略,自监督训练任务是让学生网络的输出和教师网络的输出尽可能的小。
1)初始化两个一模一样的网络,一个作为学生网络,一个作为教师网络,DINO用的是ViT结构的Transformer
2)对于输入的图像,使用大尺寸的裁剪作为图像的"全局视图"、小尺寸的裁剪作为"局部视图",分别对全局视图、局部视图进行数据增强、分patch、添加位置编码,输入到学生网络、教师网络中,!!!注意,学生网络输入所有视图,但是教师网络只输入全局视图
3)对学生网络cls、教师网络的cls利用FFN(前馈神经网络)再进行变换,教师网络cls向量变换的过程中会注入防坍塌机制,后面详细说,这里只先捋清整体细节
4)求蒸馏损失学生网络根据蒸馏损失进行梯度下降更新
5)教师网络进行指数移动平均更新

论文中的流程示意图如下
论文中的训练伪代码如下:


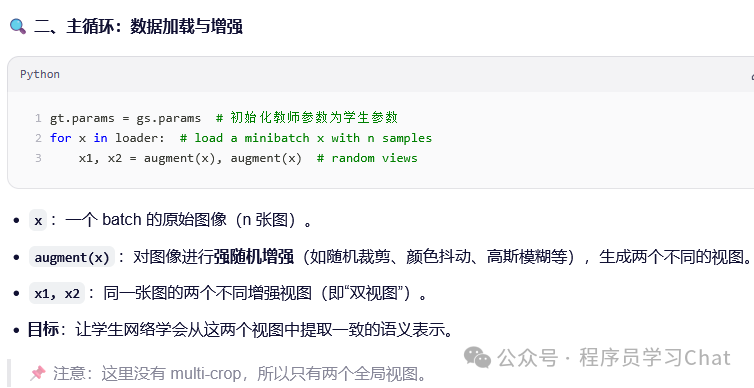






2.2 DINO如何防止坍塌问题
DINO防止坍塌的方法是对于教师网络的输出进行中心化和锐化



2.3 损失函数计算过程










2.4 细节问题







三 DINO V2
DINO V2结合DINO全局建模和MAE细粒度语义提取的思想,在一个超大规模的数据集上进行了训练,语义特征提取能力非常强

3.1 如何构建一个高质量的超大规模数据集
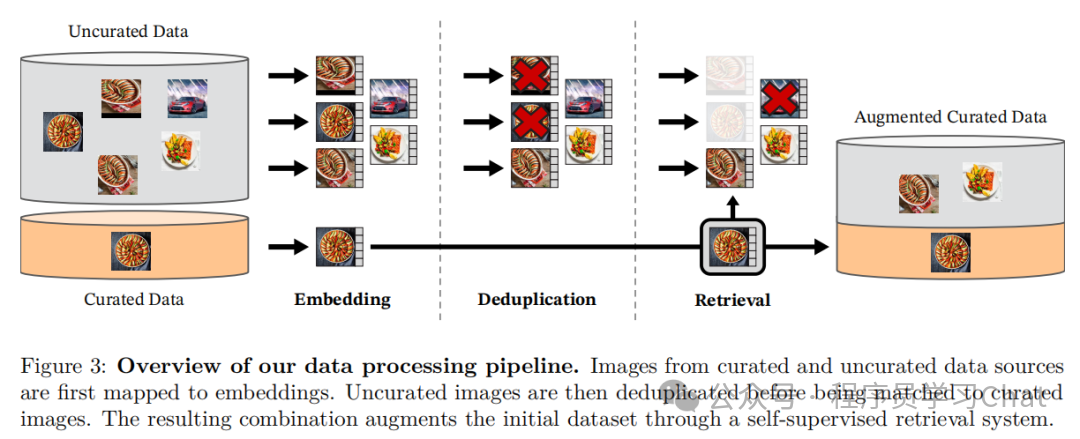
整体利用了向量数据库,通过图像的嵌入向量进行数据清洗,构建高质量数据集




3.3 DINO V2整体流程
通过多任务学习,将DINO、MAE融和到一起

DINO损失


iBOT损失(类似于MAE的一种变体)

