文章目录
- [1、MQ 消息积压](#1、MQ 消息积压)
- 2、常规处理方案
- [3、Rebalance 重平衡](#3、Rebalance 重平衡)
- [4、K8S HPA + KEDA](#4、K8S HPA + KEDA)
1、MQ 消息积压
我所经历经历的多个企业级项目中,偶尔会遇到 MQ 消息积压 相关问题,平时使用最多的 MQ 是 Kafka,消息积压通常指 Consumer Group 的消费速度持续低于 Producer 的生产速度,导致 Lag(滞后量)不断增长,消息在 Topic 的分区中堆积。监控上体现为 Consumer Lag 指标持续上升。
消息积压概括的说,就是生产者的消息推送速度大于消费者消费速度,就导致消息不断挤压在 MQ 当中,这样就会出现消息消费延迟,导致业务上的数据流转出现不实时现象,对于一些实时性的场景是比较忌讳的,对客户的使用体验来说也是不小的打击。
比如说我曾经所在的电商平台推出了红包雨活动,由于该活动的属于典型的短时高并发场景,所以在活动开启这段时间内,会出现瞬间大量消息推送到 MQ 当中,导致 Kafka Lag 直接飚高,并且出现告警。
场景假设:队列中的消息是用于最后红包金额发放到目标账户,那么挤压消息处理延迟就会出现客户金额到账出现了延迟问题。
包括其他某些各种各样消息积压的场景,都会对系统业务造成一定的影响,所以要尽可能的避免 MQ 消息积压现象的发生。针对这种现象我们首先想到的就是:如何加快消费速度
2、常规处理方案
常规的处理流程如下:
- 看监控 -> 确认 Lag 是否在增长,模式是全局还是局部。
- 查资源 -> 检查 Consumer、Broker 的 CPU、内存、磁盘 I/O、网络。
- 调参数 -> 根据情况调整 Consumer 和 Broker 的配置。
- 扩规模 -> 必要时增加分区和 Consumer 实例。
- 审逻辑 -> 分析消费代码是否有性能瓶颈或异常。
- 优架构 -> 长期进行代码优化、架构解耦和容量规划。
一般对于消息积压场景的发生,首先能想到的就是对 MQ 消费者进行横向扩容。大白话来说就是,如果生产者产生消息速度大于消费者,那就多启动几个消费者服务同一个消费者组中,这样对目标 Topic 的分区消息进行更多并发数量的消费处理。
但是这里要注意几个问题点,首先就是消费者数量要 <= 主题分区数量,因为对于消费者组的运行机制来说,如果单分区的消息,在某个时刻,只会被消费者组的一个消费者进行消费,多余的消费者完全处于空闲状态。
也就是说,如果主题有10个分区,那么就不要在该消费者组中启动11个消费者服务,这样就会导致资源浪费,并不会提高消费速度。消费者最大并行度 = 分区数量,可以理解成有多少个分区,就有多少消费并发。
其次,虽然消费者和分区数量保持一致,实现了分区数相同的并发消费。但是在消费者端,也是可以进一步加速消费速度。如果对消息的顺序性要求并不高,完全可以在消费者消费逻辑里面通过线程池异步去进行消费,这样进一步提高了并行度,加快了消费速度,提高了系统吞吐量。
通常在企业中,一般会把 Kafka Topic 的分区数量设置为消费者数量的2倍。例如:你当前运行了3个消费者实例,那么分区数量一般设置为 2 * 3 = 6
3、Rebalance 重平衡
消费者组中消费者增多,一定会发生Kafka Rebalance 现象,该现象概括的说就是将主题分区重新分配给消费者的过程。不只是消费者增加,消费者心跳检测超时session.timeout.ms、消费速度太慢max.poll.interval.ms,分区数变化等等都会引发重平衡现象发生。
Rebalance 偶尔发生不是太大问题,但是频繁发生势必会出现消费重复、乱序等问题,Rebalance发生期间,Kafka 会先"停掉所有消费者",再重新分配分区。这段时间相当于 JVM STW,不会做任何消费处理。重平衡大致的流程如下:
- 暂停所有 consumer 拉取消息
- coordinator 触发 rebalance
- 所有 consumer 重新 JoinGroup
- 选一个 leader consumer
- leader 计算 partition → consumer 分配方案
- coordinator 下发分配结果
- consumer 重新开始消费
这里只是提一嘴,重平衡机制不是本文讨论重点。
4、K8S HPA + KEDA
在正式阐述该方案之前,先提一下另一种企业常用的方案:
就是基于 Promethues 采集 Kafka Lag 指标数据,然后在结合 HPA 做弹性伸缩,这个方案比较适用于公司拥有一套较为完善的 Promethues 监控体系(这套方案之前的公司就这么使用的)
在企业中,有一套比较经典、通用的方案,并不需要运维、研发人员去手动进行消费者实例的扩缩容:
bash
# 不需要在登录到 K8S 集群上进行手动扩容了
kubectl scale deployment kafka-consumer --replicas=10而是采用一套更优雅的方式。就是:结合K8S HPA + KEDA可根据消息积压量、CPU使用率等指标自动扩缩容消费者实例数量。
HPA(Horizontal Pod Autoscaling)是 根据观察到的资源指标(如 CPU、内存使用率)或自定义指标,自动增加或减少 Deployment、StatefulSet 等控制器下的 Pod 副本数量,以实现水平伸缩,但是它并没有办法根据 Kafka 的消息积压相关指标进行弹性操作,所以才有了 KEDA 这种基于事件驱动的方案。
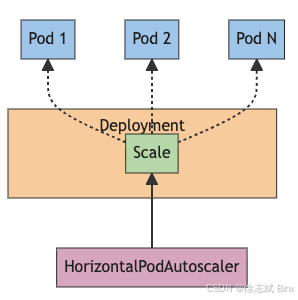
HPA 伪配置如下:
bash
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deploy
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # CPU 使用率阈值 50%
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 70 # 内存使用率阈值 70%
behavior: # 扩缩容行为配置(可选)
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60KEDA (Event-driven Autoscaling)跟 HPA 是一起使用的,KEDA 有 Scalers(伸缩器)这个概念,伸缩器为每一种外部事件源(如 Apache Kafka、RabbitMQ、Prometheus、MySQL 等)提供了对应的 Scaler。Scaler 的职责是去查询外部系统,获取特定的指标(例如,查询 Kafka 特定队列中的消息积压数量)。所以 KEDA 根本就不负责 Pod 伸缩操作,它是一个查询获取外部系统指标数据的组件。
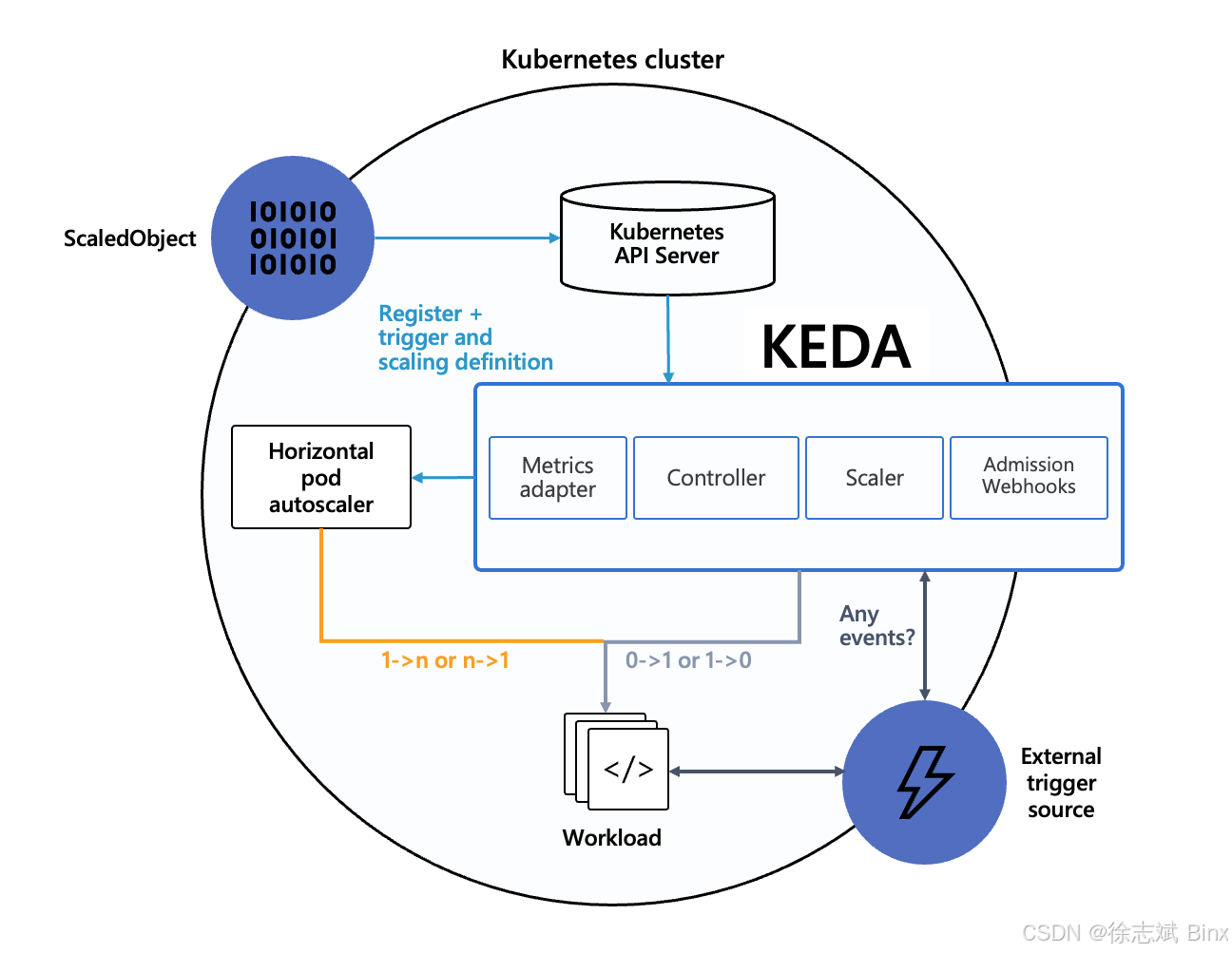
所以针对短时高并发红包雨这类电商活动场景,我们一般会考虑通过 Kafka Lag 数量来判定是否真的需要扩容,当积压量超过10万条或积压时间超过5分钟时,自动触发消费者实例扩容(基于K8s HPA弹性伸缩),伪配置代码如下:只配置KEDA即可,它会创建 HPA。
bash
# KEDA ScaledObject 示例
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-consumer-scaler
spec:
scaleTargetRef:
name: kafka-consumer-deployment
triggers:
- type: kafka
metadata:
bootstrapServers: kafka-broker:9092
consumerGroup: my-consumer-group
topic: my-topic
lagThreshold: '100' # 触发扩容的 Lag 阈值
offsetResetPolicy: latest
activationLagThreshold: '1000' # 激活阈值
scaleToZero: true
authenticationRef:
name: kafka-trigger-auth在实际生产环境中,也不要光依赖 HPA + KEDA 去做弹性伸缩,同样监控也是尤为重要,要去做好 Promethues 指标数据采集、告警,针对大量消息产生提前做好应对和措施。