3.8 数据同步
redis 中通过 psync 命令,完成数据同步,由redis 服务器在建好同步关系后,自动执行。
bash
PSYNC replicationid offset从节点执行 psync 命令,从主节点处获取数据。
同步按数据多少又分为 全量复制 和 部分复制
3.8.1 replicationid & offset
replicationid 是①主节点启动时生成, ②从节点变为主节点时也会生成。
同一个主节点,每次启动生成的 id 都不同。
主从节点建立关系后,从节点从主节点处获得 replicationid

这里的 master_replid 就是 replicationid。有主从关系的节点的这串字符是一样的。
master_replid2 一般用不上。假若有 主节点 甲 和 从节点 乙。甲乙间通信出现抖动,乙 认为 甲 挂了,乙自己变为主节点了(生成了自己的 replid),此时 replid2 记录的就是 甲 的 replid,后续网络恢复,乙可以根据 replid2 回到 甲的怀抱。、
offset 即偏移量。
主从节点都会维护 偏移量(整数)。
主节点偏移量,表示当前的数据量(主节点会收到很多修改操作命令,每个命令都要占据几个字节,主节点会将这些命令的字节数累加)
从节点偏移量:表示从节点数据同步到了哪里。
主从偏移量一致,说明从节点复制完了。
从节点每秒钟要上报自己的偏移量给主节点。
replicationid 和 offset 共同描述了一个 "数据集合",如果两台机器上的 replicationid 和 offset 都相同,说明这俩个 redis 机器上存的数据一样。
3.8.2 全量复制 & 部分复制
复制多少主要看 offset。 offset 为 -1 时,就是全量数据;如果是具体正整数,则从当前偏移量位置进行获取。
从发送 psync 同步请求,master 有三种返回结果。
- fullresync 全量数据同步
- contineu 增量数据同步
- err 较老版本的 redis 服务器不支持 psync,使用 sync 代替。
全量复制时机:① 主从首次数据同步;② 主节点不方便部分复制时。
部分复制时机:从节点之前已复制过,但因网络抖动或从节点重启,要重新从主节点同步数据,此时看看能不能只同步一部分。
3.8.3 全量复制流程
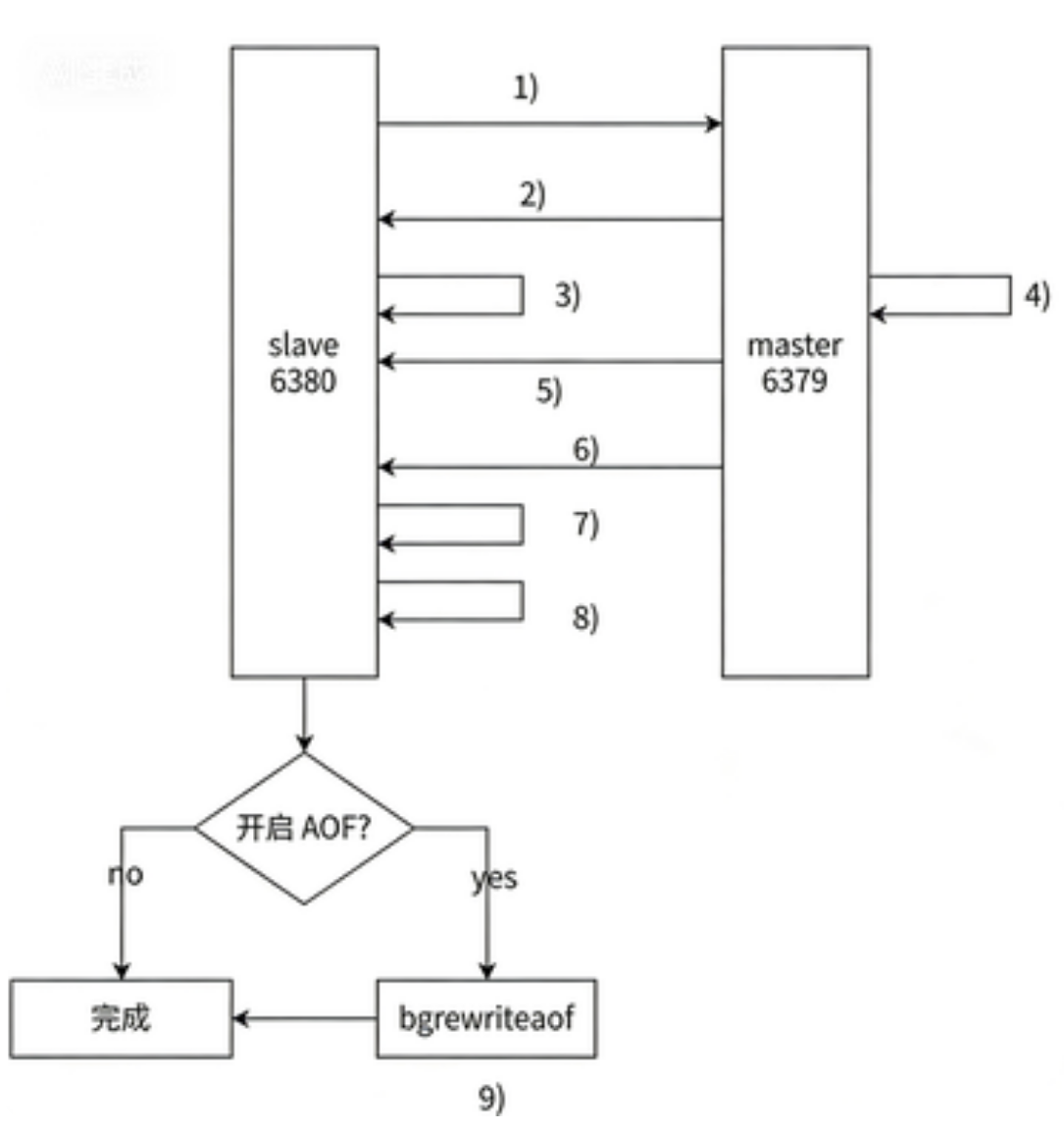
- 从节发送 psync 命令 给主节点,首次复制,没有主节点 replid 和 复制偏移量,所有发送 `psync ? -1``
- 主节点解析命令知道是全量复制,回复 +FULLRESYNC
- 从节点接收主节点的信息并保存
- 主节点执行 bgsave 进行 rdb 文件的持久化
- 主节点将 rdb 文件发给 从节点,从节点将 rdb 文件保存到本地硬盘
- 从节点清空旧数据
- 从节点加载 rdb 文件
- 主节点将生成 rbd 文件时收到的命令写入缓冲区,从节点保存完 rdb 文件后,主节点将缓冲区内数据发给从节点,从节点执行这些命令,并保持数据一致性
- 从节点如何开启了 aof 持久化,就进行 bgrewrite 操作,得到新的 aof 文件
全量复制,还支持无硬盘模式,即 主节点生成的 rdb 二进制数据,不再保存到 rdb 文件中发给从节点,而是直接通过网络传输给从节点(省下一系列硬盘读写操作);从节点也不再先将rdb 数据写入硬盘,然后从硬盘加载,而是直接加载收到的数据。
虽然有无硬盘模式,但是全量复制操作依然很重,且网络传输是没法省的(一般情况:内存速度 > 硬盘 > 网络),相比于网络传输,硬盘操作算是小的了。
3.8.4 replicationid VS runid
网上一些资料提到 runid 是用来进行复制的,但是不太对。
redis 服务器上这两个 id 都有,虽然这两个的长度相同,格式相似。但 runid 是每个节点都不同,而有主从关系的节点的 replid 是相同的。
前面的命令(摘自官方文档)
bash
PSYNC replicationid offset也明确表明用 replid
runid 用于标识一次 redis 的 "运行",主要用在 redis 哨兵功能的实现,和主从复制没什么关系。
3.8.5 部分复制流程
全量复制开销大,从节点中已有主节点中大部分数据时,就不需要进行全量复制了,应进行部分复制。
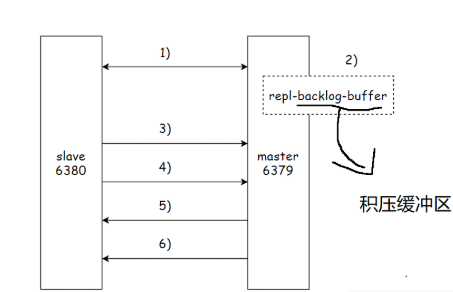
- 主从节点间网络中断超过 timeout 时间,主节点认为从节点挂了终止复制连接
- 断连期间,主节点正常响应命令,但这些命令因网络中断无法发给从节点,命令就会积攒在复制积压缓冲区中
- 主从网络恢复后,从节点重新连上主节点
- 从节点将之前保存的 replicationid 和 offset 作为 psync 参数发给主节点,请求部分复制
- 主节点收到请求后,进行必要的验证,然后根据 offset 在积压缓冲区中找合适的数据,并返回 +CONTINUE 给从节点
- 主节点将从节点需要的数据发给从节点,完成一致性
如果从节点发来的 replicationid 和主节点不一致,说明这个从节点之前在别的主节点手下,就要进行全量复制。
如果相同,说明是自己的,然后看 offset 判定从节点落下的数据,如果缓冲区保存的数据最小 offset 都比从节点的大,那就没办法部分复制了,就要进行全量复制。如果 offset 在缓冲区范围内,就从 offset 开始进行部分复制。
下面箭头指的框,就是 复制积压缓冲区 的设置。
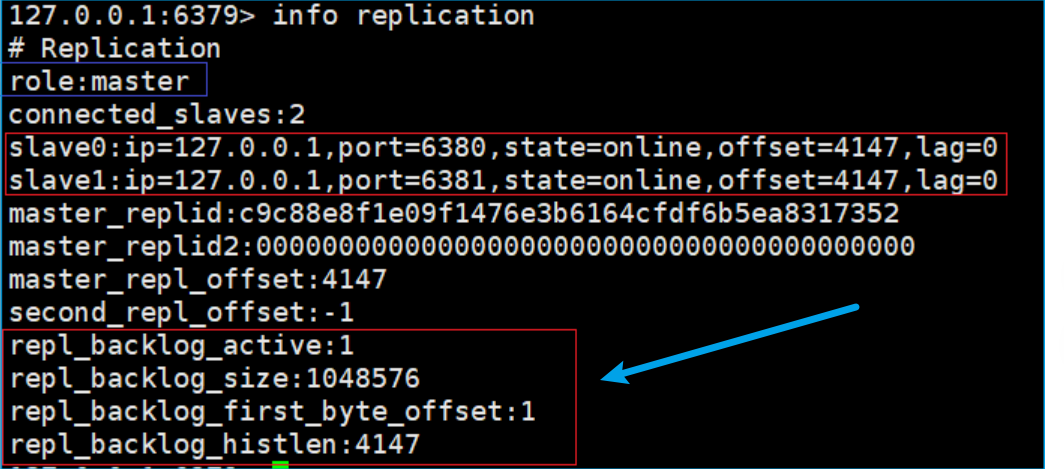
这个缓冲区就是一个内存中的队列,会记录最近一段时间修改的数据,但是总量有限,随时间推移会将之前旧的数据删掉。
bash
repl_backlog_active:1 // 开启复制缓冲区
repl_backlog_size:1048576 // 缓冲区最⼤⻓度
repl_backlog_first_byte_offset:1 // 起始偏移量,计算当前缓冲区可⽤范围
repl_backlog_histlen:4147 // 已保存数据的有效⻓度3.8.6 实时复制
当前主从节点数据已经一致,但后续主节点不断收到修改数据的请求,主节点的数据就会改变,从节点数据也要随之改变。
主从节点之间会建立 TCP 长连接,主节点将自己收到的修改数据的请求,通过该连接发送给从节点,从节点根据这些请求修改内存中的数据。
主节点通过 TCP 发送收到的请求,正常来说,延时较短,但若是多级从节点的树形结构,有很多层,延时就会上升。
实时复制时要求连接处于可用状态,因而引入了心跳包机制。
主节点:默认,每 10 s 给从节点发送一个 ping 命令,从节点收到就返回 pong。
从节点:默认,每 1s 给主节点发起一个特定请求,上报当前自身的复制进度(offset)
3.8.7 主从连接的情况
有两种:
① 从节点主动断开,通过 slaveof no one 命令,这时从节点自动晋升主节点
② 主节点挂了,这时从节点不会晋升主节点,需人工干预,恢复主节点。
但是人工效率不高,还成本高。因而就有了 Redis 哨兵,自动对挂的主节点进行替换。(后面文章会讲)
3.8.8 关停主节点后,主节点无法再启动

之前,修改配置文件时,没有修改工作目录,导致三个 redis-server 共用同一个 aof 文件(虽然,有主从关系,但数据还是有概率不一致的)。
从节点是通过 redis-server 启动的,是 root 用户启动 reids 服务器,生成的 aof 文件也就是 root 用户的文件。
而主节点通过 service redis-server start 命令启动,是通过 redis 这样的用户,来启动的,文件属于 redis 用户。(root 启动 redis 权限太高,一旦redis 被 黑客攻破,后果比较严重)
从上面可以看到 -r--r ,即 root 用户之外的只能读,而redis-server 需要按 可读可写的方式打开 aof 文件。因此,启动失败。
解决方案:将三个 redis 服务器的工作目录区分开(修改配置文件这的 dir 选项)
-
关掉之前的redis 服务器
-
删除之前工作目录下的 aof 文件,或通过 chown (change own)命令修改 aof 文件所属用户

-
给从节点创建新目录,更改从节点配置文件中的工作目录。

- 启动 redis

观察到 aof 文件位置发生变化