今天展示的案例是一个基于 Stable Diffusion 3.5 的 ComfyUI 工作流,结合了 ControlNet 的 Canny 边缘检测方法,能够在指定参考图像的约束下生成风格化的新图像。通过加载预训练大模型、文本提示、图像特征提取与条件控制,最终将结果解码并保存。

整个流程不仅实现了文生图与图像控制的结合,也展现了如何利用 ControlNet 在生成中保持结构一致性,从而让生成结果兼具创意与可控性。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode 文本语义嵌入生成](#CLIPTextEncode 文本语义嵌入生成)
- [CLIPTextEncode 负向语义控制](#CLIPTextEncode 负向语义控制)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
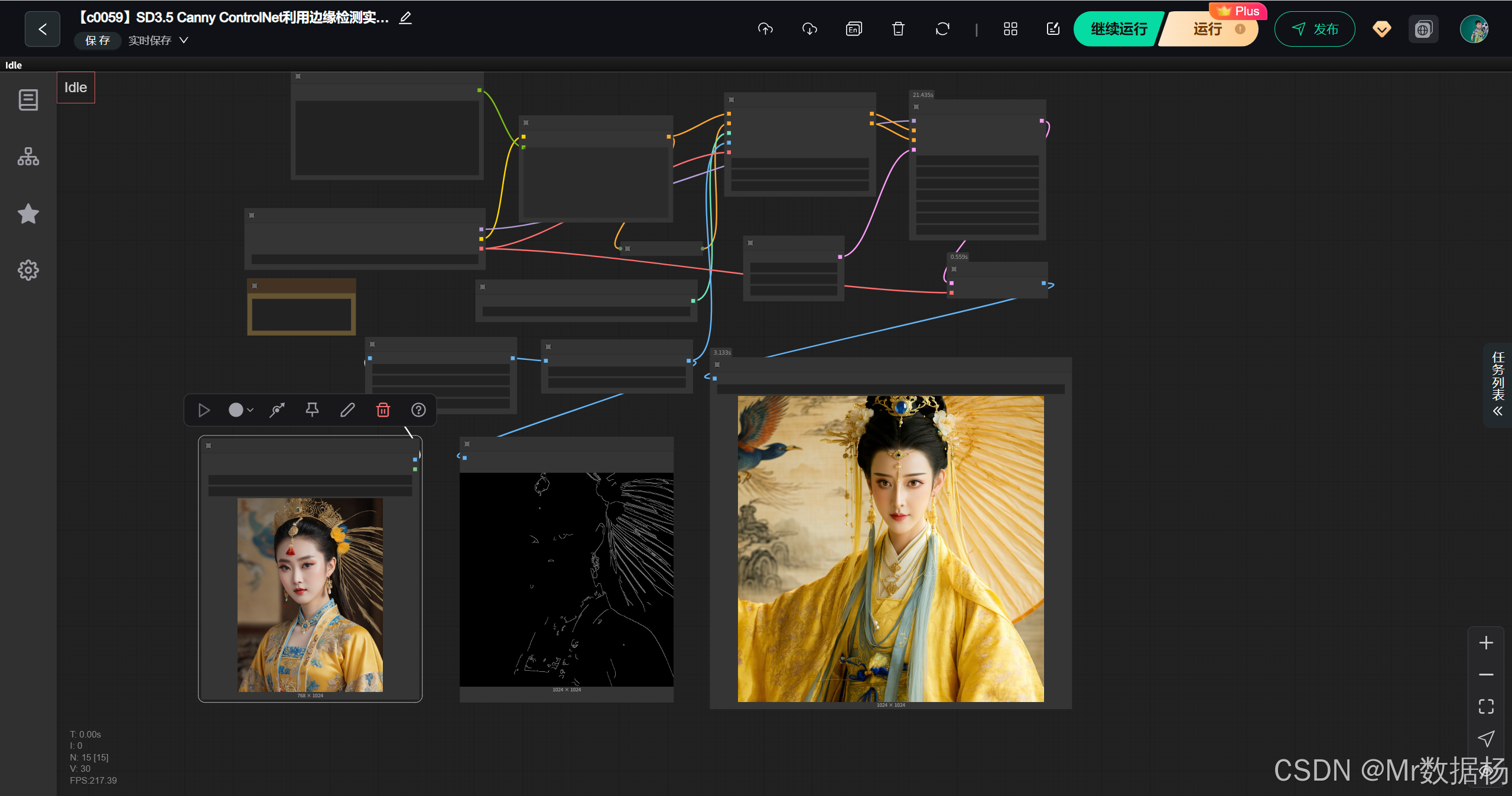
该工作流通过加载 Stable Diffusion 3.5 large fp8 模型作为核心生成引擎,并结合 ControlNet 的 Canny 检测模型,确保输入图像的结构能够得到有效传递。文本提示经过 CLIP 编码后,与 ControlNet 输出的条件控制一起输入采样器,生成潜在空间中的图像结果,再通过 VAE 解码得到最终可视化图像。整个工作流强调在自由度与可控性之间取得平衡,用户既能通过 prompt 控制画面风格,也能依赖参考图像保持清晰的结构细节。
核心模型
在该工作流中,Stable Diffusion 3.5 large fp8 模型承担了主要的生成任务,它具备较高的效率和内存优化效果,适合在显存有限的环境中使用。同时,ControlNet 的 canny 边缘检测模型则作为结构控制器,保证了参考图像的线条信息能影响最终输出。两者配合,使得生成结果在创意与精准性上都能得到兼顾。
| 模型名称 | 说明 |
|---|---|
| sd3.5_large_fp8_scaled.safetensors | Stable Diffusion 3.5 大模型,支持高效的图像生成并具备优化的推理性能 |
| sd3.5_large_controlnet_canny.safetensors | ControlNet Canny 检测模型,用于提取图像边缘特征并在生成时约束画面结构 |
Node节点
工作流的节点设计体现了输入、处理和输出的完整链路。从图像加载、缩放、边缘检测,到文本编码与条件控制,再到采样生成和结果解码,每一个节点都承担了独立但紧密衔接的功能。LoadImage 与 ImageScale 确保输入参考图像具备合适的尺寸,Canny 节点提取边缘特征,CLIPTextEncode 将文本提示转化为条件输入,ControlNetApplyAdvanced 将结构约束与提示信息结合,最终 KSampler 与 VAE 解码器输出高质量图像。PreviewImage 与 SaveImage 节点则提供了效果预览和持久化存储。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入的参考图像,作为结构约束的来源 |
| ImageScale | 调整图像尺寸以匹配模型输入需求 |
| Canny | 提取图像边缘特征,用于 ControlNet 的结构约束 |
| ControlNetLoader | 加载 ControlNet 模型,指定边缘检测权重文件 |
| CLIPTextEncode | 将文本提示转化为向量条件,用于指导生成内容 |
| ConditioningZeroOut | 处理负面提示条件,增强生成画面可控性 |
| ControlNetApplyAdvanced | 将 CLIP 编码与 ControlNet 特征融合,生成增强型条件输入 |
| EmptySD3LatentImage | 创建指定尺寸的潜在图像空间,用于采样生成 |
| KSampler | 基于条件输入进行扩散采样,生成潜在结果 |
| VAEDecode | 将潜在空间解码为可见图像 |
| PreviewImage | 提供生成结果的可视化预览 |
| SaveImage | 将最终图像保存到本地文件夹 |
工作流程
该工作流的执行链路围绕着输入、处理、生成与输出的完整路径展开。参考图像在加载后会被缩放到合适的分辨率,并通过 Canny 算子提取边缘信息,作为结构化的条件输入。与此同时,文本提示被 CLIP 编码器转化为语义向量,再结合负面提示的归零操作,使得生成过程更加精准可控。随后,ControlNet 将边缘特征与文本提示相结合,并与 Stable Diffusion 3.5 模型的潜在空间采样器对接,形成强约束的条件生成。采样结果经过 VAE 解码为可见图像,并通过预览与保存节点实现展示与落地,确保最终生成的作品既能保留输入图像的结构轮廓,又具备高度的风格化表达。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 加载参考图像并调整分辨率,保证与模型兼容 | LoadImage, ImageScale |
| 2 | 特征提取 | 对图像进行 Canny 边缘检测,生成结构约束信息 | Canny |
| 3 | 文本编码 | 将提示词转化为语义向量,结合负面提示优化条件输入 | CLIPTextEncode, ConditioningZeroOut |
| 4 | 条件融合 | 将文本提示与边缘特征通过 ControlNet 融合,形成增强型控制信号 | ControlNetLoader, ControlNetApplyAdvanced |
| 5 | 潜在生成 | 创建潜在图像空间并运行扩散采样,生成潜在结果 | EmptySD3LatentImage, KSampler |
| 6 | 图像解码 | 将潜在结果解码为可见图像,获得最终生成作品 | VAEDecode |
| 7 | 输出与保存 | 在界面中预览结果并将其持久化保存到文件 | PreviewImage, SaveImage |
大模型应用
CLIPTextEncode 文本语义嵌入生成
在 SD3.5 Canny ControlNet 工作流中,CLIPTextEncode 节点负责将用户提供的正向 Prompt 转化为 CLIP 条件嵌入,用于指导生成模型结合 Canny 边缘图像生成目标图像。Prompt 描述直接决定角色、场景、服饰和动作特征,是整个边缘引导生成流程的语义核心。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Positive Prompt) | happy cute anime fox girl with massive fluffy fennec ears and blonde fluffy hair long hair blue eyes wearing a red scarf a pink sweater and blue jeans standing in a beautiful forest with mountains | 将正向 Prompt 转化为 CLIP 嵌入,用于控制图像生成语义、角色特征和场景细节,实现结合 Canny 边缘检测的精确图像生成。 |
CLIPTextEncode 负向语义控制
该节点生成负向条件嵌入,用于抑制生成图像中不希望出现的元素或低质量细节,保证图像干净、自然且符合预期语义。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Negative Prompt) | "" | 将负向 Prompt 转化为 CLIP 嵌入,用于抑制不希望出现的视觉元素或低质量细节,提高图像生成精度和一致性。 |
使用方法
SD3.5 Canny ControlNet 工作流结合边缘检测、ControlNet 条件、正向与负向文本嵌入、潜在空间采样及 VAE 解码,实现高精度可控图像生成。用户提供原图,通过 LoadImage 节点加载,ImageScale 调整大小,Canny 节点生成边缘图,CLIPTextEncode 转化正向和负向 Prompt 为条件嵌入,ControlNetLoader 加载 Canny ControlNet 模型,ControlNetApplyAdvanced 将边缘图与文本嵌入融合输入 UNET 模型。EmptySD3LatentImage 提供潜在图像初始值,KSampler 进行采样,VAEDecode 将潜在图像解码为最终图像,PreviewImage 和 SaveImage 输出。用户可通过调整 Prompt、CFG、ControlNet 强度或输入图像控制生成效果,实现精确、风格统一且与边缘图匹配的图像生成。
| 注意点 | 说明 |
|---|---|
| Prompt 描述清晰 | 确保角色、场景和动作符合预期 |
| 使用负向 Prompt | 避免生成不希望出现的元素或低质量细节 |
| 边缘图质量高 | 边缘检测图越精准,生成图像结构越清晰 |
| ControlNet 强度合理 | 调整边缘控制对生成的影响,平衡自由度与精度 |
| 潜变量尺寸与输出一致 | 确保 VAEDecode 解码后图像比例正确 |
应用场景
该工作流在多种应用中展现了强大的灵活性与可控性。利用 ControlNet 的边缘检测能力,可以让生成的作品在保持结构一致性的前提下展现高度的艺术自由度,非常适合动漫角色重绘、场景扩展以及风格化再创作等任务。在插画设计领域,可以快速将手绘草图转化为精美的数字艺术;在影视分镜中,则能保持人物或场景结构的统一性,同时快速生成多样化的画面风格;在游戏原画创作中,可以用同一参考图像生成多个不同风格的变体,从而提高生产效率。通过这种模式,生成过程不仅满足了创意探索的需求,还能兼顾实际生产的高效与可控。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 动漫角色重绘 | 保持角色形象结构,赋予新的画面风格 | 插画师、同人创作者 | 基于参考图像生成不同风格的角色插画 | 结构不变,风格多样 |
| 场景扩展 | 在保持主体轮廓的同时扩展画面细节 | 影视制作团队 | 从草图生成完整分镜画面 | 快速生成分镜,统一画面基调 |
| 游戏原画创作 | 基于一张草图生成多种变体 | 游戏美术设计师 | 多风格的角色或场景原画 | 批量生成,提升效率 |
| 艺术风格迁移 | 将手绘线稿转化为高质量插画 | 艺术工作室 | 不同风格化的图像成品 | 创意转化效率高 |
| 设计灵感探索 | 在明确结构约束下快速尝试多种风格 | 自由艺术创作者 | 同一场景的多样化表现 | 提供多种灵感选择 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用