论文题目:大型图的归纳表示学习
会议:NIPS2017
摘要:大型图中节点的低维嵌入已经被证明在各种预测任务中非常有用,从内容推荐到识别蛋白质功能。然而,大多数现有的方法要求在训练嵌入时图中的所有节点都存在;这些先前的方法本质上是转导的,不能自然地推广到看不见的节点。在这里,我们提出GraphSAGE,一个通用的归纳框架,利用节点特征信息(例如,文本属性)有效地为以前未见过的数据生成节点嵌入。我们不是为每个节点训练单独的嵌入,而是学习一个函数,该函数通过从节点的局部邻域中采样和聚合特征来生成嵌入。我们的算法在三个归纳节点分类基准上优于强基线:我们基于引用和Reddit帖子数据对进化信息图中不可见节点的类别进行分类,并且我们表明我们的算法使用蛋白质-蛋白质相互作用的多图数据集推广到完全不可见的图。
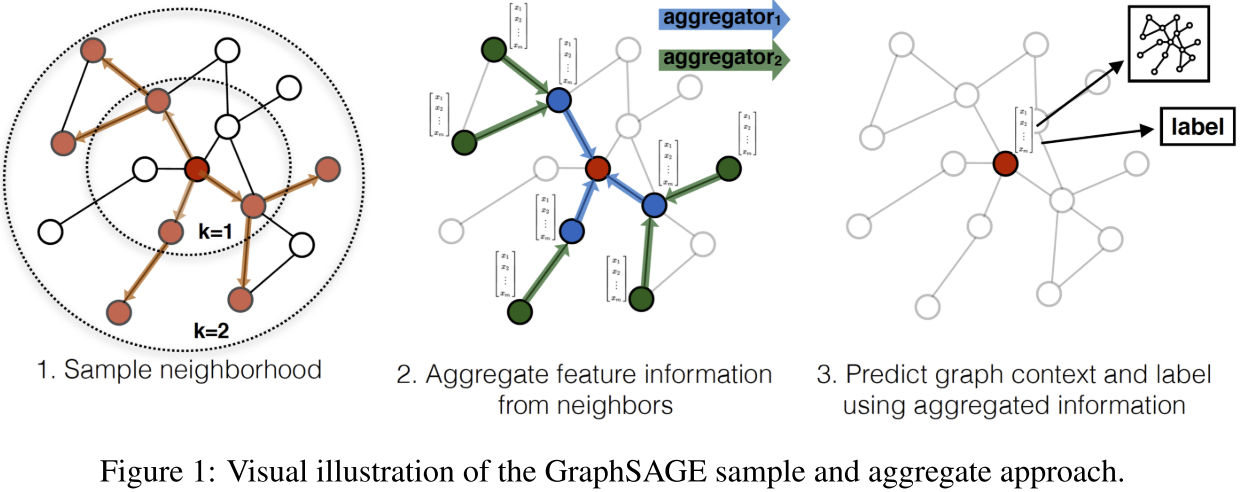
GraphSAGE - 让图神经网络真正"见多识广"
你有没有想过,当你的社交网络每天都有成千上万的新用户加入时,如何让机器学习模型快速理解这些新用户?传统的图神经网络方法在这个问题上显得力不从心。今天,我们来深入探讨一篇来自Stanford的经典论文:GraphSAGE,看看它如何优雅地解决这个难题。
问题:传统方法的"记忆力"陷阱
想象你正在为YouTube构建一个推荐系统。每天都有数百万新视频上传、新用户注册。如果你使用传统的节点嵌入方法(如DeepWalk或node2vec),会遇到什么问题?
传统方法的工作方式
传统方法会为图中的每个节点学习一个独立的嵌入向量。就像给每个学生分配一个学号,这些方法通过优化让"关系密切"的节点有相似的嵌入。
听起来不错?但问题来了:
- 新节点怎么办? 当新用户加入时,模型必须重新训练才能为新节点生成嵌入
- 计算成本爆炸 论文实验显示,DeepWalk处理新节点的速度比GraphSAGE慢100-500倍!
- 无法跨图迁移 在不同图上训练的嵌入空间可能完全不对齐(想象两个坐标系任意旋转)
这就是所谓的**直推式学习(Transductive Learning)**的局限------只能在训练时见过的节点上工作。
解决方案:学会"举一反三"
GraphSAGE的核心洞察非常优雅:与其记住每个节点,不如学会如何从邻居那里提取信息。
核心思想:从记忆到泛化
传统方法:
节点A → 嵌入向量[0.2, 0.5, 0.8, ...] (死记硬背)GraphSAGE方法:
节点A + 邻居特征 → 聚合函数 → 嵌入向量 (举一反三)这就像从"背答案"变成"学方法"------只要掌握了方法,见到新题也能解决。
算法详解:三步走策略
第一步:采样邻居
GraphSAGE不是查看所有邻居(可能成千上万个),而是均匀采样固定数量的邻居。比如:
- 第1层:采样25个邻居
- 第2层:每个邻居再采样10个邻居
这样做的好处:
- ✅ 计算量可控
- ✅ 可以并行化
- ✅ 对大规模图友好
第二步:聚合信息
这是GraphSAGE最精彩的部分!论文提出了三种聚合器:
1. Mean聚合器(最简单)
h_neighbor = mean({邻居1的特征, 邻居2的特征, ...})
h_new = σ(W · [h_self || h_neighbor]) # ||表示拼接这类似GCN的做法,简单但有效。
2. LSTM聚合器(最灵活)
虽然LSTM本来是为序列设计的,但GraphSAGE巧妙地将其用于无序集合:
- 随机排列邻居顺序
- 喂给LSTM处理
- 获得更强的表达能力
3. Pooling聚合器(性能最佳)
# 每个邻居独立通过一个神经网络
transformed = [MLP(邻居1), MLP(邻居2), ...]
# 逐元素取最大值
h_neighbor = element_wise_max(transformed)这个设计很聪明:
- MLP提取每个邻居的不同特征
- Max-pooling捕捉邻域的多样性
- 保持排列不变性(无论邻居顺序如何)
第三步:多层传播
GraphSAGE会进行K层(通常K=2)迭代:
- 第1层:收集1跳邻居的信息
- 第2层:收集2跳邻居的信息
- ...
每一层都在"扩大视野",让节点看到更远的邻域。
训练策略:有监督 vs 无监督
无监督训练(类似Word2Vec)
目标:让图上相近的节点有相似的嵌入
损失函数 = -log(σ(z_u · z_v)) (正样本:图上相邻)
- Σ log(σ(-z_u · z_neg)) (负样本:随机节点)有监督训练
如果有标签(如节点类别),可以直接用交叉熵损失端到端训练。
实验表明,有监督版本通常比无监督版本提升10-20个百分点。
实验亮点
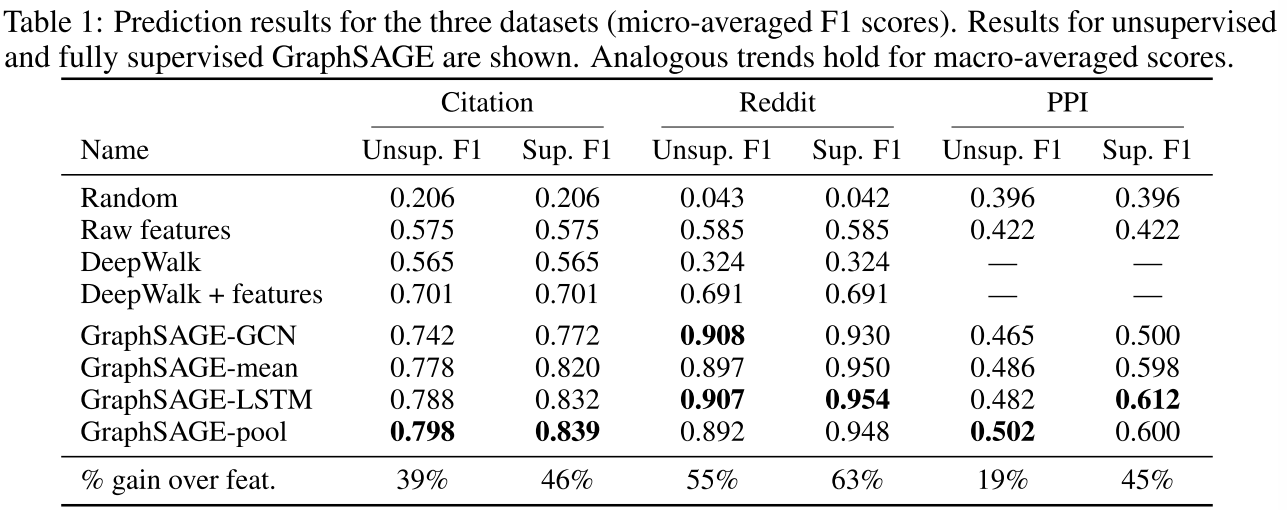
战场1:学术论文分类(Citation Network)
- 数据:30万篇生物学论文(2000-2005)
- 任务:只用2000-2004年数据训练,预测2005年新论文的学科
- 结果 :
- 原始特征:57.5% F1
- DeepWalk+特征:70.1%
- GraphSAGE-pool:79.8% ✨
提升39%! 而且测试速度快100倍。
战场2:Reddit社区预测
- 数据:23万个Reddit帖子
- 任务:用前20天数据训练,预测后10天新帖子的所属社区
- 结果 :
- 原始特征:58.5%
- DeepWalk+特征:69.1%
- GraphSAGE-LSTM:90.7% ✨
提升55%! 这个任务特别能体现归纳学习的价值。
战场3:蛋白质功能预测(跨图泛化)
这是最难的测试!
- 训练:20个人体组织的PPI图
- 测试:2个全新的PPI图(训练时从未见过)
- 结果 :
- 原始特征:42.2%
- GraphSAGE-LSTM:61.2% ✨
提升45%! 证明GraphSAGE真的学到了可迁移的"知识"。
理论保证:不只是黑盒
论文还提供了理论分析,证明GraphSAGE可以学习图结构信息。

定理1 :如果每个节点有唯一的特征,GraphSAGE可以以任意精度近似节点的聚类系数 。【**论文表述:**定理1指出,对于任何图,存在一个算法1的参数设置,如果每个节点的特征是不同的(并且如果模型足够高维),那么它可以将该图中的聚类系数近似为任意精度。】

聚类系数衡量的是"你的朋友之间是否也是朋友"------这是一个纯结构性指标!
这个定理告诉我们:即使GraphSAGE是基于特征的,它也能捕捉到图的拓扑结构。
为什么Pooling聚合器最强?
论文的证明依赖于Pooling聚合器的两个关键性质:
- 万能逼近能力:MLP可以学习任意复杂的函数
- 排列不变性:Max操作保证输出不依赖邻居顺序
这解释了为什么实验中Pooling和LSTM通常表现最好。
实践建议
如果你想在自己的项目中使用GraphSAGE,这里是一些经验:
超参数设置
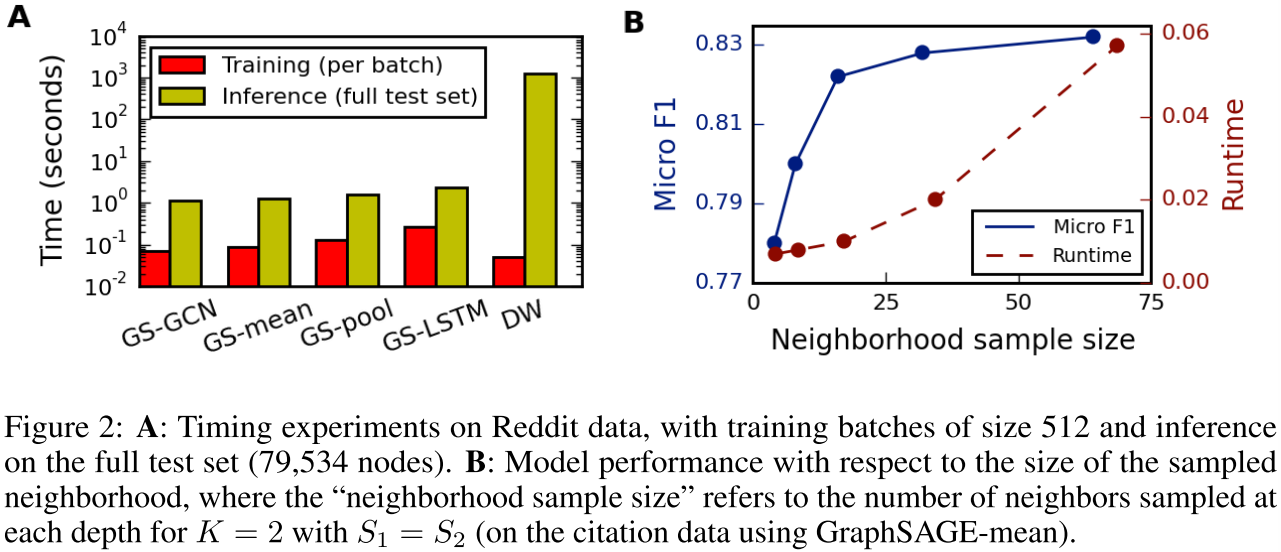
- 深度K:K=2通常足够,K=3提升很小但计算慢10-100倍
- 采样大小:S1=25, S2=10是个好起点
- 聚合器选择 :
- 性能要求高 → Pooling或LSTM
- 速度要求高 → Mean(快2倍)
- 简单任务 → GCN变体
特征工程
- 有特征:文本用Word2Vec/GloVe,图像用CNN特征
- 无特征:用节点度、PageRank等结构特征
- 特征很重要:实验显示特征质量直接影响最终效果
训练技巧
- 小数据集(<10万节点)→ 有监督训练
- 大数据集 → 先无监督预训练,再有监督微调
- 使用邻域采样控制内存和速度
总结:为什么GraphSAGE重要?
GraphSAGE解决了图神经网络的一个根本性问题:如何从固定图泛化到动态、开放世界。
核心创新:
- ✅ 归纳学习:可以处理全新节点和图
- ✅ 高效可扩展:通过邻域采样控制计算
- ✅ 灵活聚合器:适配不同任务需求
- ✅ 理论保证:能学习结构和特征
实际价值:
- 🚀 推荐系统中处理新用户/物品
- 🧬 生物信息学中的跨物种迁移
- 📱 社交网络中的实时分析
- 🏭 任何需要处理演化图的场景
如果你在做图相关的机器学习项目,GraphSAGE绝对值得一试!