系列文章目录
- 第一章 【大数据环境安装指南】 JDK安装
- 第二章 【大数据环境安装指南】 Python安装
- 第三章 【大数据环境安装指南】VMware虚拟机静态IP及多IP配置
- 第四章 【大数据环境安装指南】 Flume图文安装教程
- 第五章 【大数据环境安装指南】ZooKeeper搭建Hadoop高可用集群教程
文章目录
- 系列文章目录
- 前言
- [一、Flink 核心定义与设计理念](#一、Flink 核心定义与设计理念)
-
- [1.1 Flink vs Spark(核心区别,新手易混淆)](#1.1 Flink vs Spark(核心区别,新手易混淆))
- [1.2 部署模式(按需选择)](#1.2 部署模式(按需选择))
- [1.3 核心版本兼容性(官方推荐):](#1.3 核心版本兼容性(官方推荐):)
- [二、Standalone Cluster(独立集群)部署](#二、Standalone Cluster(独立集群)部署)
-
- [2.1 Standalone 集群核心概念](#2.1 Standalone 集群核心概念)
- [2.2 部署前准备](#2.2 部署前准备)
-
- [2.2.1 集群规划(示例:3 节点集群)](#2.2.1 集群规划(示例:3 节点集群))
- [2.2.2 环境要求(所有节点)](#2.2.2 环境要求(所有节点))
- [2.2.3 下载并解压 Flink 安装包(所有节点)](#2.2.3 下载并解压 Flink 安装包(所有节点))
- [2.3 Standalone 集群配置(主节点 node1 操作)](#2.3 Standalone 集群配置(主节点 node1 操作))
-
- [2.3.1 修改集群节点配置](#2.3.1 修改集群节点配置)
- [2.3.2 指定从节点列表](#2.3.2 指定从节点列表)
- [2.3.3 同步配置到所有从节点](#2.3.3 同步配置到所有从节点)
- [三、启动与停止 Standalone 集群](#三、启动与停止 Standalone 集群)
-
- [3.1 启动集群(主节点 node1 执行)](#3.1 启动集群(主节点 node1 执行))
- [3.2 停止集群(主节点 node1 执行)](#3.2 停止集群(主节点 node1 执行))
前言
部署环境:
- 操作系统:Centos 7、Rocky 9 、Kylin V11
- Hadoop版本:3.4.2
- Zookeeper版本:3.8.4
- Flink版本:1.17.2
- jdk版本:8
Apache Flink作为大数据领域主流的流批一体化计算框架,Flink 的核心优势是低延迟实时流处理,同时兼顾批处理能力,是构建实时数据管道、实时分析、实时风控等场景的核心工具
一、Flink 核心定义与设计理念
Apache Flink 是一款分布式、高性能、容错的流批一体化开源计算框架,核心设计理念是:
- 一切皆流:批处理本质是 "有界流",流处理是 "无界流",Flink 从底层将两者统一,而非像 Spark 那样 "批优先、流模拟";
- 状态化计算:针对流处理场景,内置完善的状态管理机制,支持复杂的有状态计算(如窗口聚合、实时关联);
- 端到端一致性:通过 Checkpoint(分布式快照)、Savepoint(持久化快照)和连接器适配,实现数据从输入到输出的 "精确一次(Exactly-Once)" 处理。
1.1 Flink vs Spark(核心区别,新手易混淆)
| 维度 | Flink | Spark |
|---|---|---|
| 核心定位 | 流优先,流批一体 | 批优先,微批模拟流(Spark Streaming) |
| 实时性 | 纯流处理,毫秒级延迟 | 微批处理,秒级延迟(Structured Streaming 优化后仍不如 Flink) |
| 状态管理 | 内置完善的状态存储 / 恢复 | 依赖外部存储(如 Redis) |
| 容错机制 | Checkpoint(基于 Chandy-Lamport) | RDD 血缘 + Checkpoint |
| 适用场景 | 实时计算(风控、实时大屏、监控) | 批处理(数仓、离线分析)+ 准实时计算 |
1.2 部署模式(按需选择)
| 部署模式 | 适用场景 | 特点 |
|---|---|---|
| Standalone | 测试 / 小规模生产集群 | 部署简单,无依赖第三方集群 |
| YARN | 已有 Hadoop YARN 集群 | 资源动态调度,适配大数据生态 |
| Kubernetes | 云原生环境、容器化部署 | 弹性扩缩容,适合云平台 |
1.3 核心版本兼容性(官方推荐):
| Flink 版本 | 支持的 JDK 版本 | 支持的 Hadoop 版本 | 关键说明 |
|---|---|---|---|
| Flink 1.12.x | JDK 8(推荐)、JDK 11(实验性) | Hadoop 2.7+、3.1+ | 最后支持 JDK 8 独占的版本 |
| Flink 1.13.x | JDK 8、JDK 11(正式支持) | Hadoop 2.7+、3.1+ | 开始全面支持 JDK 11 |
| Flink 1.14.x - 1.16.x | JDK 8、JDK 11 | Hadoop 2.7+、3.3+ | 兼容 Hadoop 3.3 最新版本 |
| Flink 1.17.x - 1.19.x | JDK 8、JDK 11、JDK 17(实验性) | Hadoop 2.7+、3.3+ | 开始支持 JDK 17,推荐生产用 JDK 8/11 |
| Hadoop 2.7+、3.3+ | JDK 8、JDK 11、JDK 17(正式支持) | Hadoop 3.1+、3.4+ | 逐步放弃 Hadoop 2.x 支持,主推 JDK 11/17 |
二、Standalone Cluster(独立集群)部署
2.1 Standalone 集群核心概念
Flink Standalone 集群是纯 Flink 自身的主从集群,不依赖 YARN/K8s 等外部资源调度器,由 JobManager(主节点)和 TaskManager(从节点)组成:
- 主节点(JobManager):1 台,负责集群管理、作业调度、Checkpoint 协调;
- 从节点(TaskManager):至少 1 台(推荐多台),负责执行具体的计算任务;
- 核心特点:部署简单、无外部依赖,但资源无法动态调度,需手动规划节点和资源。
2.2 部署前准备
2.2.1 集群规划(示例:3 节点集群)
| 节点 IP / 主机名 | 角色 | 说明 |
|---|---|---|
| node1 | JobManager + TaskManager | 主节点 + 1 个工作节点 |
| node2 | TaskManager | 工作节点 1 |
| node3 | TaskManager | 工作节点 2 |
2.2.2 环境要求(所有节点)
bash
# 1. 安装Java 8/11
java -version # 验证版本,输出openjdk 8/11
# 2. 配置免密登录(主节点node1免密访问所有从节点)
# 在node1执行:
ssh-keygen -t rsa # 一路回车,生成密钥
ssh-copy-id node2 # 免密登录node2
ssh-copy-id node3 # 免密登录node3
# 3. 关闭防火墙/SELinux(测试环境,生产需开放指定端口)
systemctl stop firewalld
systemctl disable firewalld
setenforce 0 # 临时关闭SELinux2.2.3 下载并解压 Flink 安装包(所有节点)
Flink 官网地址:https://flink.apache.org/
- 下载Flink 1.17.2(适配Scala 2.12)
bash
wget https://archive.apache.org/dist/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz- 解压到指定目录
bash
tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /usr/local/app/- 配置环境变量(所有节点)
bash
sudo echo "export FLINK_HOME=/usr/local/app/flink-1.17.2" >> /etc/profile
sudo echo "export PATH=\$FLINK_HOME/bin:\$PATH" >> /etc/profile
source /etc/profile
2.3 Standalone 集群配置(主节点 node1 操作)
2.3.1 修改集群节点配置
编辑$FLINK_HOME/conf/flink-conf.yaml(核心配置):
yaml
# 1. 指定JobManager节点(主节点主机名/IP)
jobmanager.rpc.address: node1
# 2. JobManager内存配置(默认1024m,按需调整)
jobmanager.memory.process.size: 1024m
# 3. TaskManager内存配置(默认1024m)
taskmanager.memory.process.size: 2048m
# 4. 每个TaskManager的Slot数(推荐等于CPU核数,测试环境设2)
taskmanager.numberOfTaskSlots: 2
# 5. 集群默认并行度
parallelism.default: 4
# 将Web UI端口改为8083,避免端口冲突
rest.port: 8083
# 正确配置(对外可访问)
rest.address: 0.0.0.02.3.2 指定从节点列表
编辑$FLINK_HOME/conf/workers,添加所有 TaskManager 节点:
bash
node1
node2
node3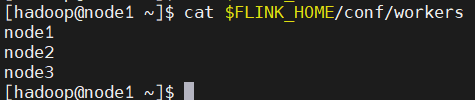
2.3.3 同步配置到所有从节点
bash
# 将配置文件同步到node2、node3
scp $FLINK_HOME/conf/flink-conf.yaml node2:$FLINK_HOME/conf/
scp $FLINK_HOME/conf/workers node2:$FLINK_HOME/conf/
scp $FLINK_HOME/conf/flink-conf.yaml node3:$FLINK_HOME/conf/
scp $FLINK_HOME/conf/workers node3:$FLINK_HOME/conf/三、启动与停止 Standalone 集群
3.1 启动集群(主节点 node1 执行)
bash
# 启动集群(自动启动JobManager和所有TaskManager)
cd $FLINK_HOME/bin/
./start-cluster.sh
# 验证启动状态:
# 1. 查看进程(node1能看到JobManagerRunner,所有节点能看到TaskManagerRunner)
jps
# 预期输出(node1):
# JobManagerRunner
# TaskManagerRunner
# 预期输出(node2/node3):
# TaskManagerRunner
# 2. 访问Flink Web UI(默认端口8081)
http://node1:8083
# 页面能看到"Task Managers"列表包含node1/node2/node3,状态为"Running"即启动成功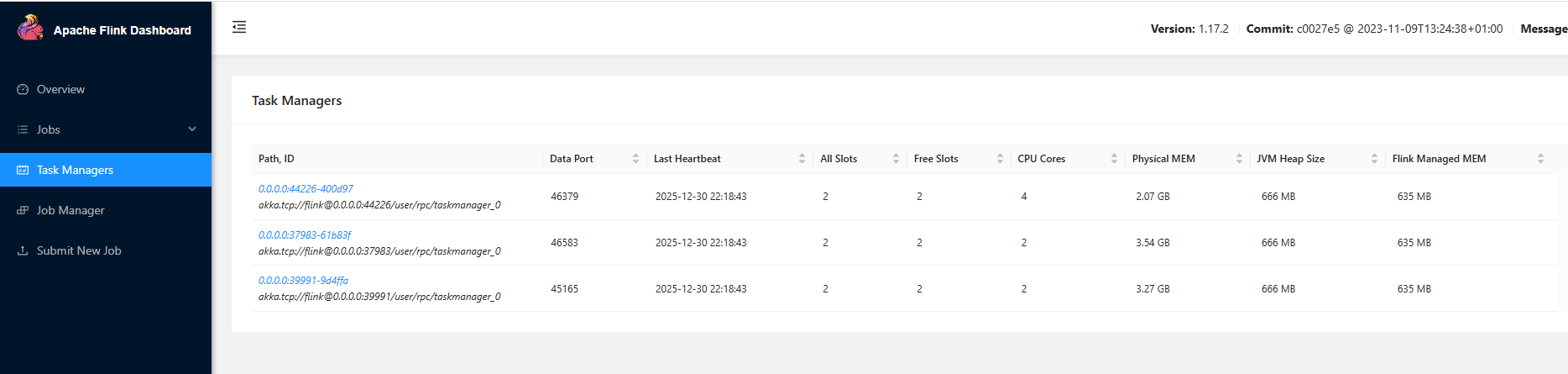
3.2 停止集群(主节点 node1 执行)
bash
# 停止整个集群
$FLINK_HOME/bin/stop-cluster.sh
# 单独停止JobManager/TaskManager(可选)
$FLINK_HOME/bin/stop-jobmanager.sh # 停止主节点
$FLINK_HOME/bin/stop-taskmanager.sh # 停止工作节点