一篇深入浅出的指南 ------ 带你探秘 Transformer 内部机制与端到端运行流程
直观易懂的 Transformer 系列:自然语言处理篇
这是我的 Transformer 系列文章的第二篇。在第一篇中,我们讲解了 Transformer 的功能作用、应用场景、宏观架构设计,以及它相比其他模型的核心优势。
在本文中,我们将深入探究 Transformer 的底层原理( look under the hood:译为深入探究底层原理) ,详细解析其具体工作机制。我们会了解数据如何以实际的矩阵表示形式与维度 在系统中流转(matrix representations and shapes:译为矩阵表示形式与维度),并搞懂每一个阶段所执行的运算过程。
下面是本系列往期及后续文章的内容速览( a quick summary:译为内容速览)。我贯穿始终的目标,不仅是让大家弄明白事物 "如何运作",更要搞清楚它 "为何要如此运作"。
功能总览
(Transformer 的应用场景、相较循环神经网络的优势、架构组成部分、以及训练与推理阶段的运行机制)
工作原理 ------ 本文详解
(端到端的内部运行流程、数据流转路径与各环节运算过程,含矩阵表示形式)
多头注意力机制
(注意力模块在 Transformer 架构中的底层工作原理)
注意力机制为何能提升性能
(不仅解析注意力机制的功能,更探究其高效运行的深层原因;阐述注意力机制如何捕捉句中词汇间的关联关系)
另外,如果你对自然语言处理(NLP)的各类应用感兴趣,我还写了几篇你可能会喜欢的文章。
束搜索算法(Beam Search 译为束搜索算法)(语音转文字与自然语言处理应用中广泛使用的一种算法,用于提升预测效果)
双语评估替换分数(BLEU)(Bleu Score 标准译法为双语评估替换分数)(双语评估替换分数与词错误率是衡量自然语言处理模型性能的两项核心指标)
架构总览
正如我们在第一部分所了解到的,该架构的核心组成部分包括:
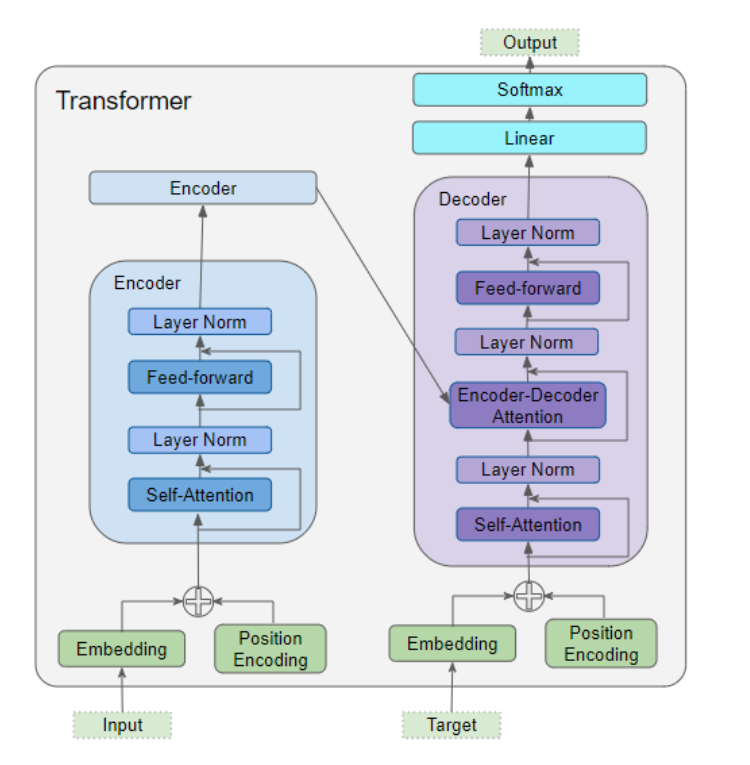
编码器与解码器的共用数据输入模块,包含以下组件:
- 嵌入层
- 位置编码层
编码器堆叠层由若干个编码器组成。每个编码器均包含以下两个模块:
- 多头注意力层
- 前馈神经网络层
解码器堆叠层由若干个解码器组成。每个解码器均包含以下模块:
- 两个多头注意力层
- 前馈神经网络层
输出模块(右上角)------ 用于生成最终输出结果,包含以下模块:
- 线性层
- Softmax 层
要弄清楚每个组件的作用,我们不妨结合一个翻译任务的训练场景,来逐步拆解 Transformer 的工作流程(let's walk through the working of... 译为 "逐步拆解...... 的工作流程",walk through 在技术语境中表示 "逐步讲解、拆解分析",比直译 "走过" 更精准)。我们将选取一组训练样本展开说明,该样本包含一个输入序列(英文句子 You are welcome )和一个目标序列(西班牙语对应表达 De nada)
嵌入与位置编码
与所有自然语言处理(NLP)模型一样,Transformer 模型需要获取每个词汇的两项关键信息 ------ 即词汇本身的语义信息,以及它在序列中的位置信息。
嵌入层负责编码词汇的语义信息。
位置编码层用于表征词汇在序列中的位置信息。
Transformer 采用相加的方式,将这两种编码进行融合。
嵌入层
Transformer 设有两个嵌入层。输入序列会被送入第一个嵌入层,该层被称为输入嵌入层。
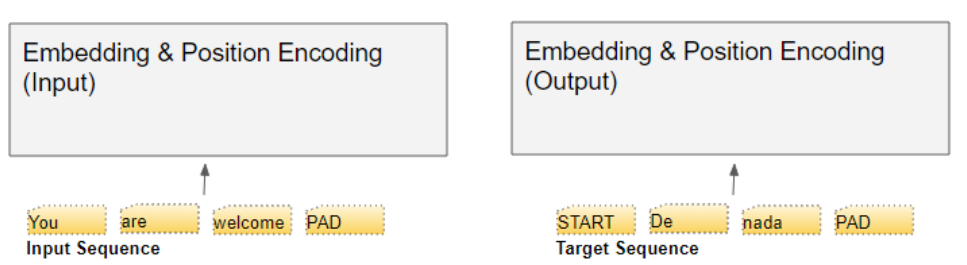
目标序列需先整体右移一位(shifting the targets right by one position 译为整体右移一位) ,并在首个位置插入一个起始标记(Start token) ,之后再送入第二个嵌入层。需要注意的是,在推理阶段 ,我们并没有目标序列可用,此时会像第一部分所讲的那样,以循环的方式将输出序列送入这个第二层。这也是该层被命名为输出嵌入层的原因。
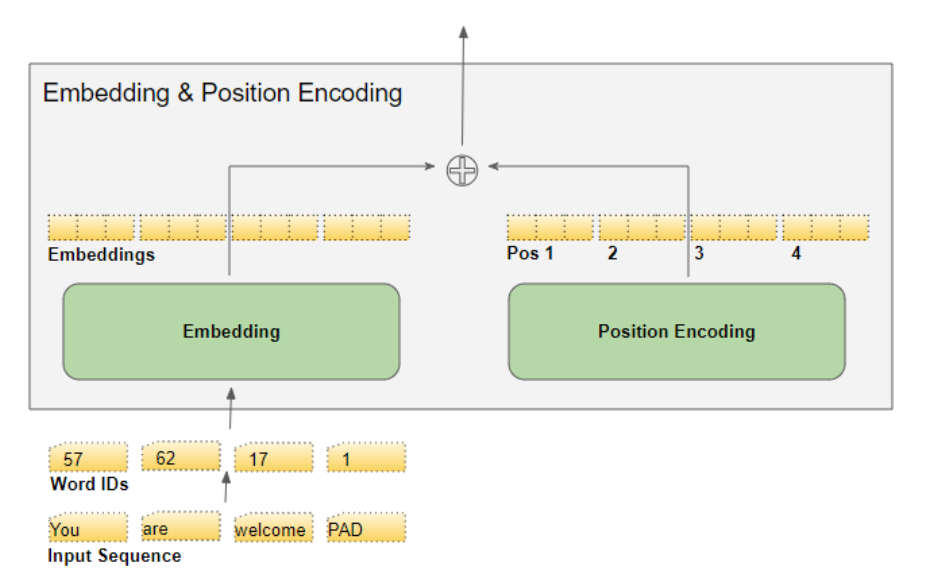
我们会借助词汇表 ,将文本序列映射为数字词标识(word IDs) 。随后,嵌入层会把每个输入词汇映射为一个嵌入向量,该向量是对词汇语义的一种更丰富的表征形式。
位置编码
由于循环神经网络(RNN)采用的是逐词串行输入的循环结构(implements a loop where each word is input sequentially ),因此它会隐式获取每个词汇的位置信息。
然而,Transformer 架构不使用循环神经网络(RNN),且会对序列中的所有词汇执行并行输入 操作。这是它相较于 RNN 架构的一大核心优势,但同时也意味着位置信息会丢失,必须通过独立的方式重新注入。
与嵌入层的设计一致,Transformer 同样设有两个位置编码层。位置编码的计算过程与输入序列本身无关(computed independently of the input sequence 译为 "计算过程与输入序列本身无关") ,其取值为固定值,仅由序列的最大长度决定。例如:
第一项是用于标识首个位置的固定编码(constant code译为固定编码,constant为持续不断地,恒定的)
第二项是用于标识第二个位置的固定编码
以此类推。
这些固定值通过下述公式计算得出,其中
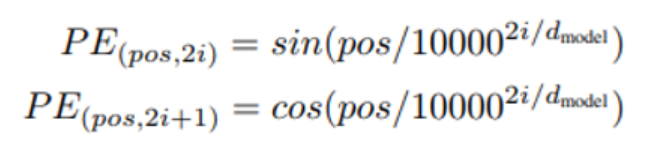
- pos 代表词汇在序列中的位置
- _dmodel 代表编码向量的长度(与嵌入向量长度一致)
- i 代表该向量的索引值
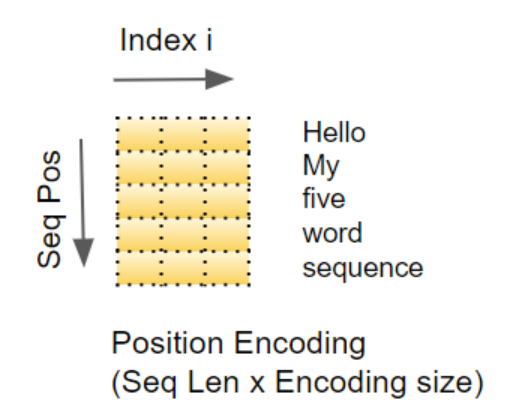
换言之,该方法将正弦曲线与余弦曲线交错组合( interleaves:译为交错组合。 even indexes/odd indexes:译为偶数索引 / 奇数索引) ,向量的所有偶数索引 位置取值为正弦值,所有奇数索引 位置取值为余弦值。举例来说,若我们对一个包含 40 个词汇的序列进行编码,下方即可呈现部分 (词汇位置,编码索引) 组合对应的编码取值。
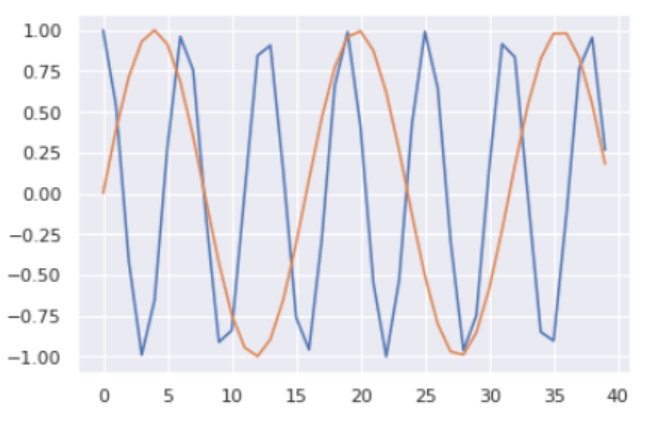
蓝色曲线 展示的是全部 40 个词汇位置 中索引 0 对应的编码取值,橙色曲线 展示的是全部 40 个词汇位置 中索引 1 对应的编码取值(the 0th index/the 1st index 译为索引 0 / 索引 1)。其余索引位置也会呈现出类似的曲线分布。
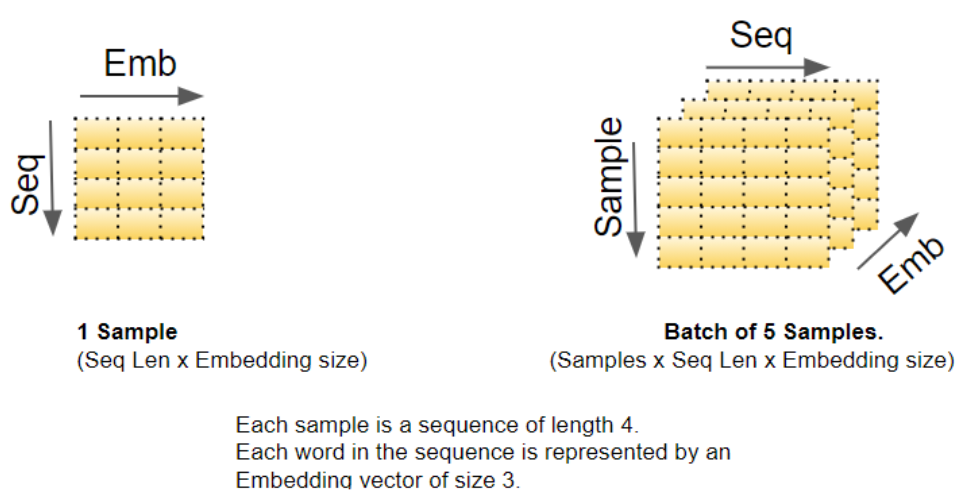
我们知道,深度学习模型会一次性处理一批训练样本 。嵌入层与位置编码层的运算对象,是表征一批序列样本 的矩阵。嵌入层接收一个维度为 (样本数,序列长度) 的词标识矩阵,将矩阵中的每个词标识编码为一个词向量(向量长度等于嵌入维度),最终输出维度为 (样本数,序列长度,嵌入维度) 的矩阵。位置编码层采用的编码维度与嵌入维度完全一致 ,因此它会生成一个维度与之匹配的矩阵,该矩阵可直接与嵌入矩阵执行加法运算。
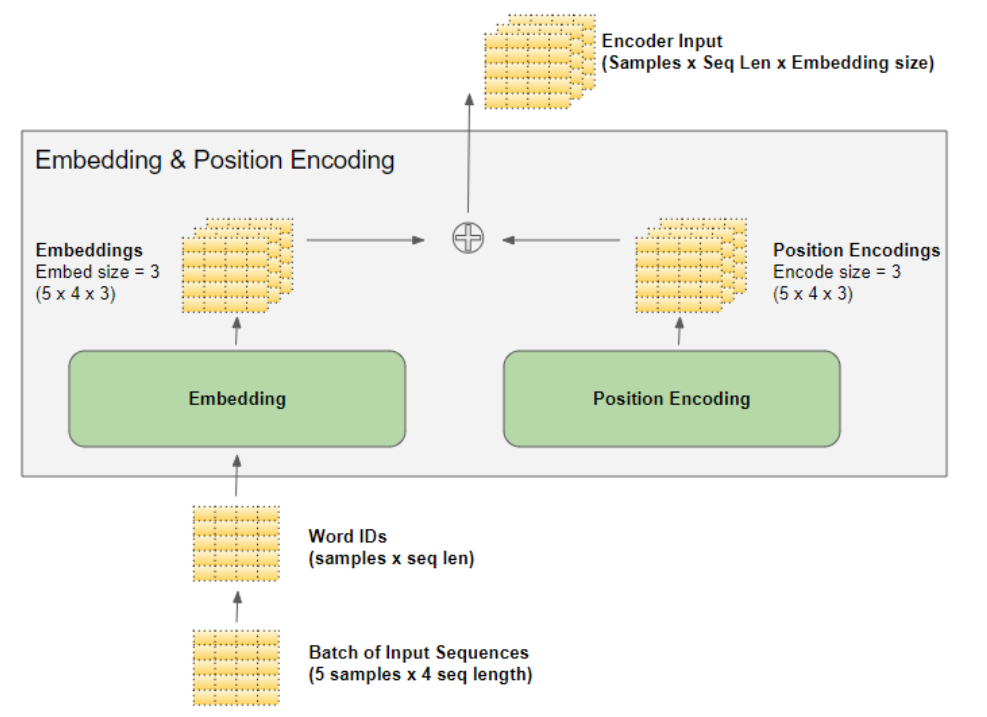
在数据流经编码器堆叠层与解码器堆叠层的整个过程中(as the data flows through... 译为 "在数据流经...... 的整个过程中"),嵌入层和位置编码层输出的维度为 (样本数,序列长度,嵌入维度) 的矩阵形状会始终保持不变,直至被最后的输出层重新调整维度。
输入嵌入层 将其输出传入编码器 。同理,输出嵌入层 的输出会送入解码器。
编码器
编码器堆叠层与解码器堆叠层分别由若干个(通常为 6 个)编码器与解码器串行连接构成。
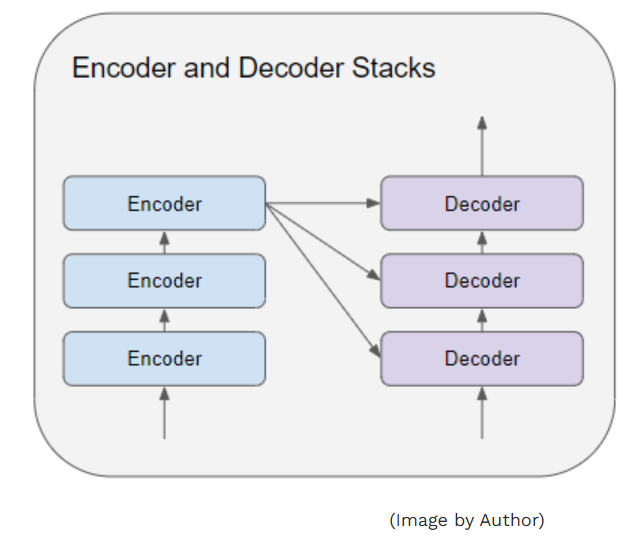
堆叠层中的第一个编码器 接收来自嵌入层与位置编码层的输出数据。堆叠层中的其余编码器则均以前一个编码器的输出作为输入。
编码器会将其输入传入多头自注意力层 。自注意力层的输出随后被送入前馈神经网络层 ,该层再将自身输出向上传递至下一个编码器。
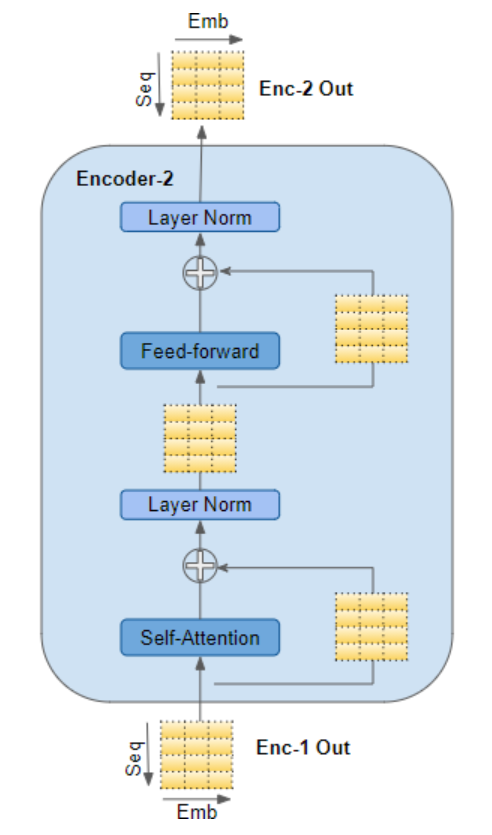
自注意力子层与前馈子层的外围均设有残差跳跃连接( sub-layers → 子层) ,并在连接之后执行层归一化操作。
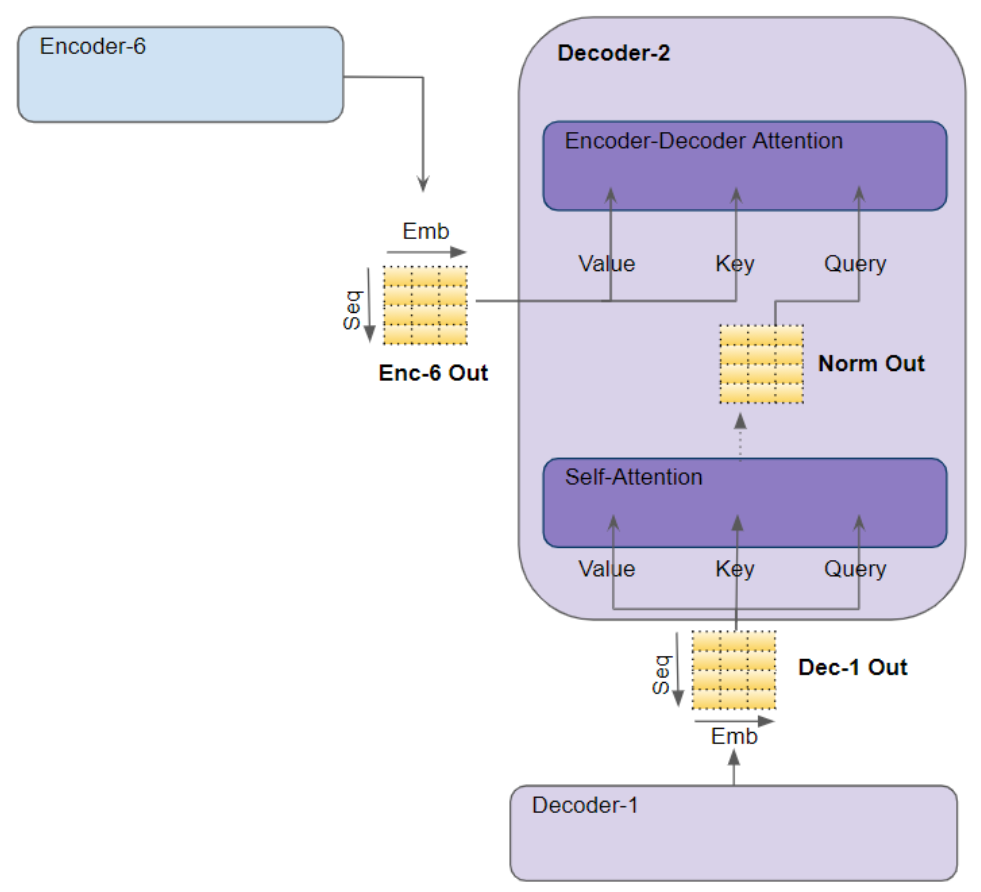
最后一个编码器的输出会被送入解码器堆叠层中的每一个解码器,具体原理如下文所述。
解码器
解码器的结构与编码器极为相似 ,但存在两处差异。
与编码器的机制一致,堆叠层中的第一个解码器接收来自输出嵌入层与位置编码层的输入数据,堆叠层中的其余解码器则均以前一个解码器的输出作为输入。
解码器会将其输入传入多头自注意力层 。该层的工作方式与编码器中的多头自注意力层略有不同 :它仅允许模型关注序列中的前文位置 。这一机制是通过掩码遮挡未来位置实现的,相关细节我们将在后文简述。
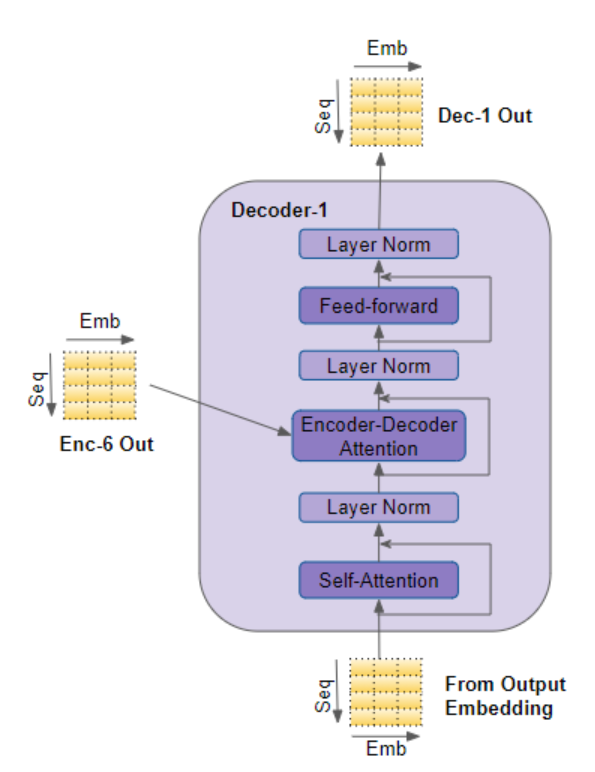
与编码器不同,解码器增设了第二个多头注意力层,该层被称为编码器 - 解码器注意力层。编码器 - 解码器注意力层的工作原理与自注意力层类似,区别在于它会融合两类输入信息 ------ 其下层自注意力层的输出,以及编码器堆叠层的输出。
自注意力层的输出会被送入前馈神经网络层 ,该层随后将自身输出向上传递至下一个解码器。
自注意力层、编码器 - 解码器注意力层以及前馈神经网络层,这三个子层的外围均设有残差跳跃连接 ,并在连接之后执行层归一化操作。
注意力机制
在第一部分中,我们阐述了注意力机制在序列处理任务中至关重要的原因。在 Transformer 架构中,注意力机制被应用于三个位置:
- 编码器中的自注意力机制 ------ 输入序列对其自身进行注意力聚焦
- 解码器中的自注意力机制 ------ 目标序列对其自身进行注意力聚焦
- 解码器中的编码器 - 解码器注意力机制 ------ 目标序列对输入序列进行注意力聚焦
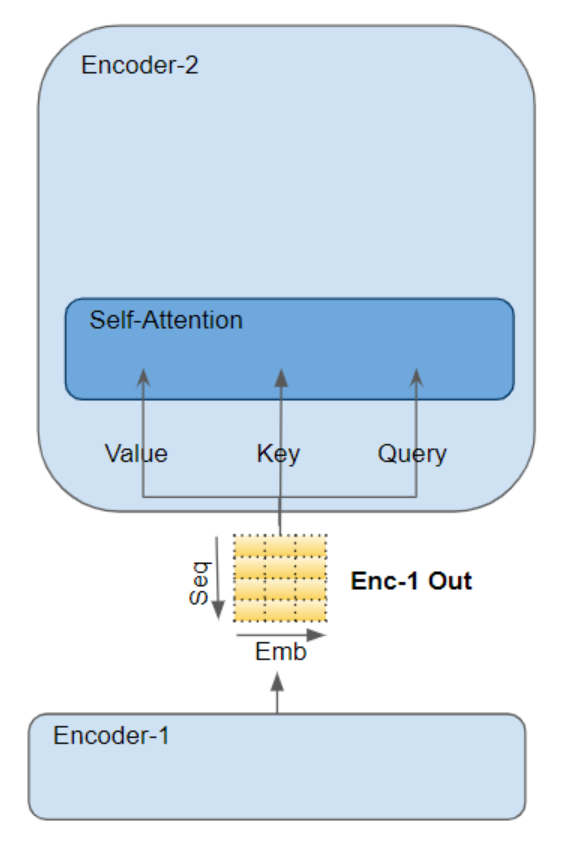
注意力层接收的输入以三个参数形式呈现,这三个参数被称为查询(Query)、键(Key)和值(Value)。
在编码器的自注意力机制中,编码器的输入会被传递至全部三个参数 ------ 查询(Query)、键(Key)和值(Value)
- 在解码器的自注意力机制中,解码器的输入会被传递至全部三个参数 ------ 查询(Query)、键(Key)和值(Value)。
- 在解码器的编码器 - 解码器注意力机制中,编码器堆叠层最后一个编码器的输出会被传递至值(Value)和键(Key)参数;其下层自注意力(及层归一化)模块的输出则会被传递至查询(Query)参数。
多头注意力机制
Transformer 中将每个注意力处理器称为一个注意力头(Attention Head) ,并将其并行重复多次 ------ 这一结构被称为多头注意力机制(Multi-head Attention) 。通过融合多个相似的注意力计算结果,它赋予了注意力机制更强的区分能力。
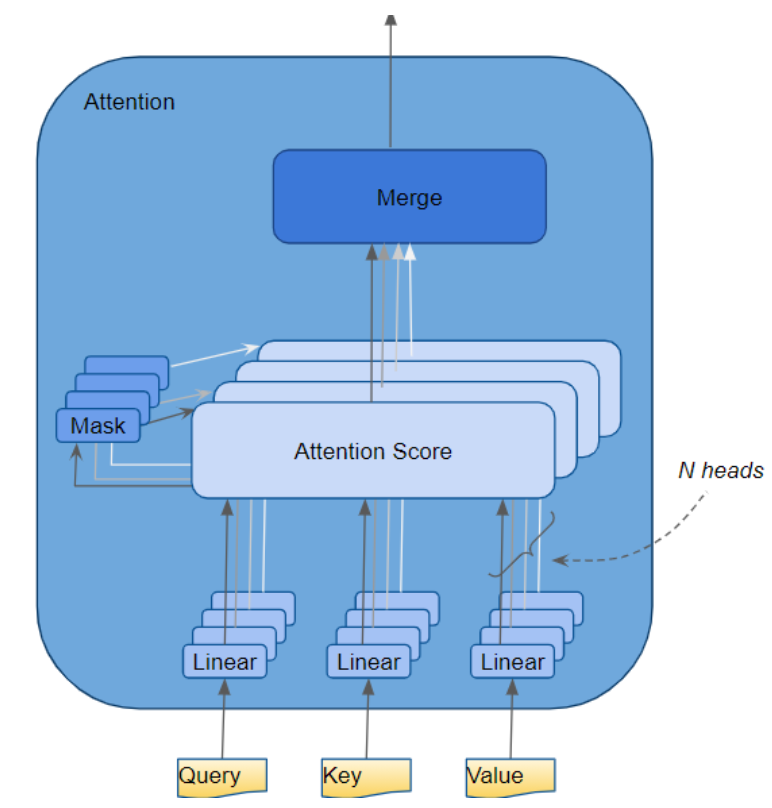
查询(Query)、键(Key)和值(Value)会分别传入独立的线性层 (每个线性层都拥有专属权重),最终生成三个结果,分别对应新的查询(Q)、键(K)和值(V)。随后,这三个结果会通过下方所示的注意力公式 进行融合计算,得到注意力分数(Attention Score)。
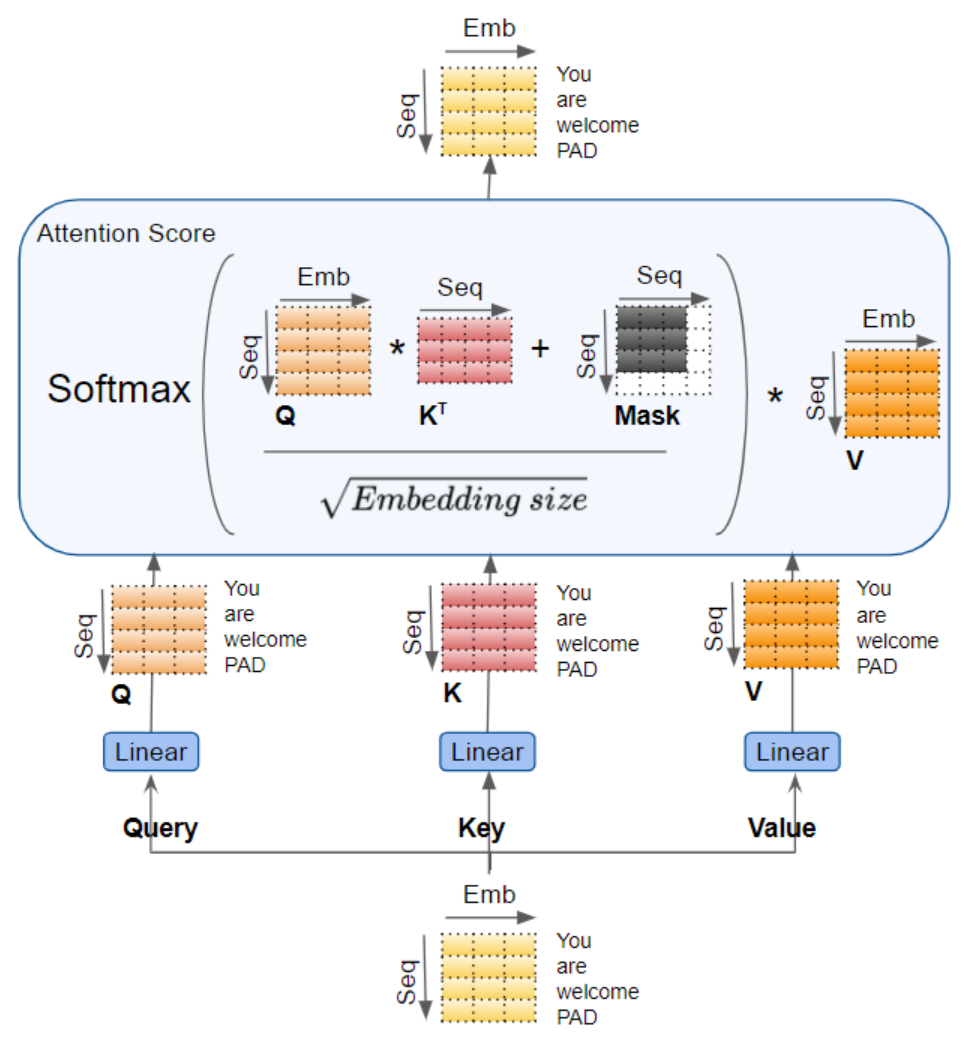
此处需重点理解的核心逻辑是:查询(Q)、键(K)和值(V)均承载着序列中每个词的编码表示 。随后,注意力计算会将序列中的每个词与所有其他词进行关联融合 ,最终使注意力分数(Attention Score)为序列中的每个词编码了一份全局关联权重。
我们前文在讨论解码器时(a little while back 译为 "前文",比直译 "不久前" 更贴合技术文档的上下文衔接逻辑),曾简要提及掩码机制(Masking) ------ 该机制在上方的注意力机制示意图中也有呈现。下面让我们详细了解其工作原理。
注意力掩码(Attention Masks)
在计算注意力分数的过程中,注意力模块会执行一个掩码操作步骤。掩码机制的作用主要有两点:
在编码器自注意力机制和编码器 - 解码器注意力机制中:掩码机制的作用是将输入句子中填充位置(Padding)对应的注意力输出置零 ,以确保填充部分不会对自注意力计算产生任何影响。(注:与大多数自然语言处理(NLP)应用一致,由于输入序列的长度可能各不相同,我们会用填充 Token(Padding Tokens) 对其进行扩展,从而能够向 Transformer 输入固定长度的向量。)
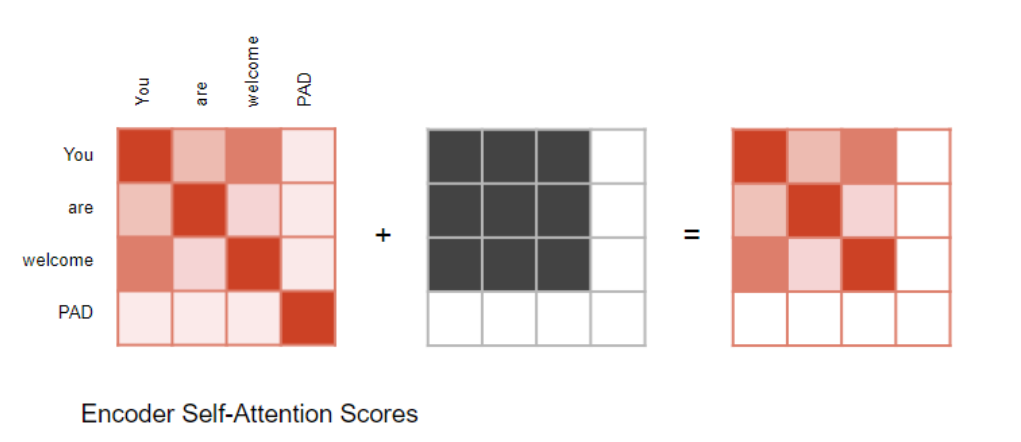
编码器 - 解码器注意力机制的情况与此类似。
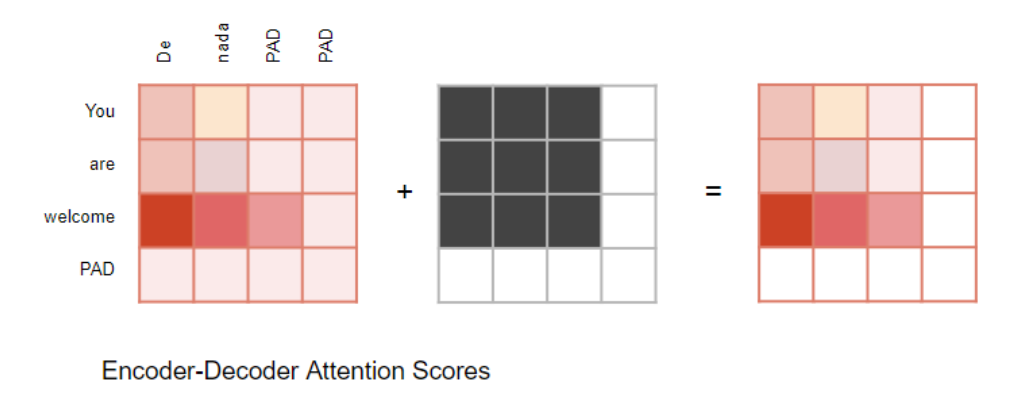
在解码器自注意力机制中:掩码机制的作用是防止解码器在预测下一个词时,提前窥探目标句子中后续的内容( peeking ahead → 提前窥探, the rest of the target sentence → 目标句子中后续的内容)。
解码器会处理源序列中的词,并利用这些词来预测目标序列 中的词。在训练阶段,这一过程通过教师强制(Teacher Forcing) 实现:即将完整的目标序列作为解码器的输入。因此,当预测某个位置的词时,解码器不仅能获取该位置之前 的目标词,还能获取该位置之后 的目标词 ------ 这就导致解码器可能通过利用未来时间步的目标词来 "作弊",即非法获取未到生成时序的信息。
例如,当预测 "第 3 个词" 时,解码器应仅参考目标序列中前 3 个输入词,而不得涉及第 4 个词 "Ketan"。
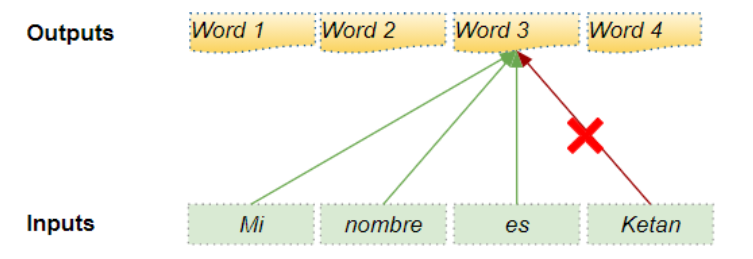
因此,解码器会对序列中后续出现的输入词进行掩码遮挡 ------ 即屏蔽目标序列中当前预测位置之后的所有词。
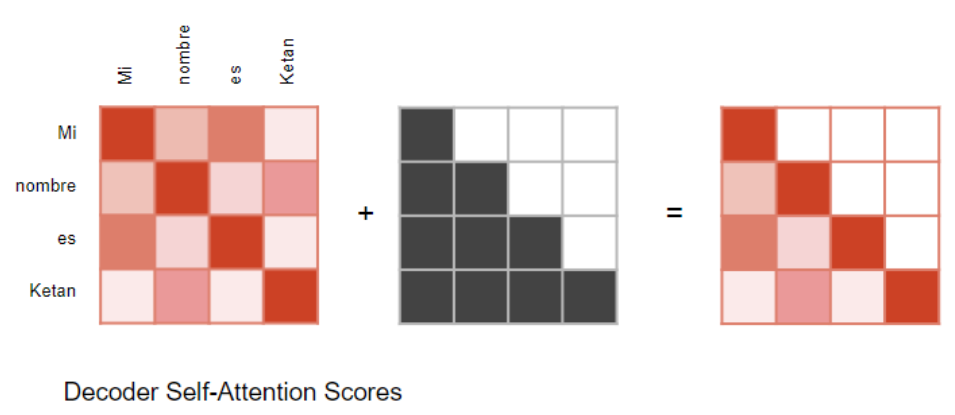
在计算注意力分数时(参考前文展示计算流程的示意图),掩码会在Softmax 激活函数之前 应用于分数的分子部分 。被掩码遮挡的元素(即示意图中的白色方块)会被设置为负无穷(negative infinity),从而使 Softmax 将这些元素对应的注意力权重转化为 0。
生成输出
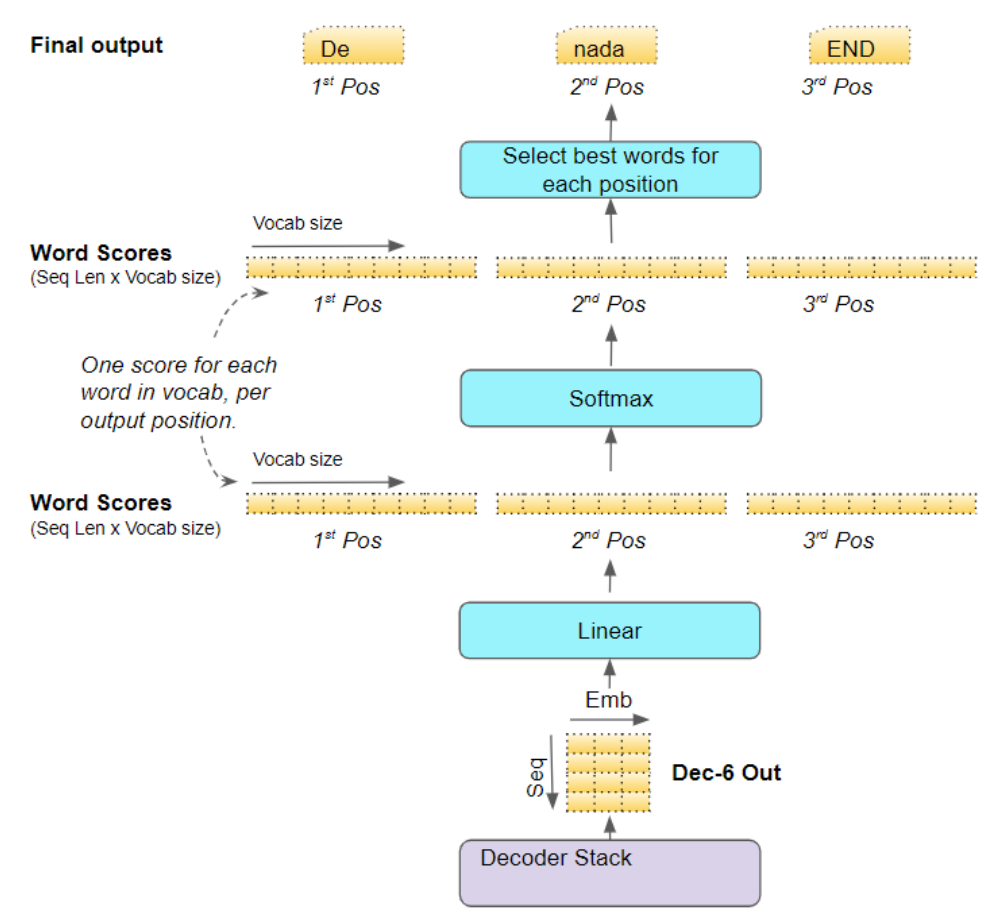
堆叠层中的最后一个解码器会将其输出传递至输出层组件(Output component),该组件会将其转换为最终的输出句子。
线性层会将解码器输出的向量投影为词分数(Word Scores) :针对句子中的每个位置,为目标词汇表中每个独特词生成对应的分数值。例如,若最终输出句子包含 7 个词,且西班牙语目标词汇表有 10000 个独特词,则我们会为这 7 个词的每个位置都生成 10000 个分数值。这些分数值代表了词汇表中每个词在该句子位置上的出现概率。
随后,Softmax 层会将这些词分数(logits)转换为概率(所有概率之和为 1.0)。在每个位置上,我们找到概率最高的词对应的索引,再将该索引映射到词汇表中对应的词 ------ 这些词最终构成了 Transformer 的输出序列。
训练与损失函数
在训练阶段,我们会使用交叉熵损失(Cross-Entropy Loss) 等损失函数,将模型生成的输出概率分布与真实的目标序列进行对比。该概率分布(即模型输出)给出了词汇表中每个词在对应句子位置上的出现概率。
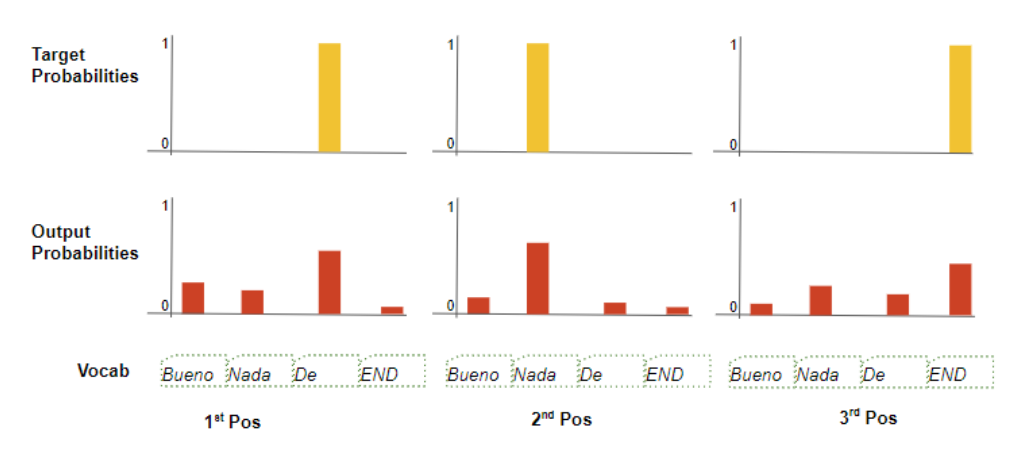
假设我们的目标词汇表仅包含四个词,我们的目标是生成一个与预期目标序列 "De nada END" 相匹配的概率分布。
这意味着第一个词位置 的概率分布中,"De" 的概率应为 1,而词汇表中所有其他词的概率均为 0。同理,"nada" 和 "END" 应分别在第二个和第三个词位置上取概率 1。
和往常一样,损失值会被用于计算梯度(gradients → 梯度),并通过反向传播来训练Transformer 模型。
希望以上内容能让你理解 Transformer 模型在训练阶段 的内部工作机制。正如我们在上一篇文章中所探讨的,该模型在推理阶段会以循环的方式运行,但大部分处理流程保持不变。
多头注意力模块正是赋予 Transformer 模型强大能力的核心所在。在下一篇文章中,我们将继续深入探索,进一步剖析注意力机制的具体计算细节。
最后,如果你喜欢这篇文章,或许也会感兴趣于我撰写的其他系列内容,主题涵盖音频深度学习 、地理定位机器学习 以及图像描述生成架构。