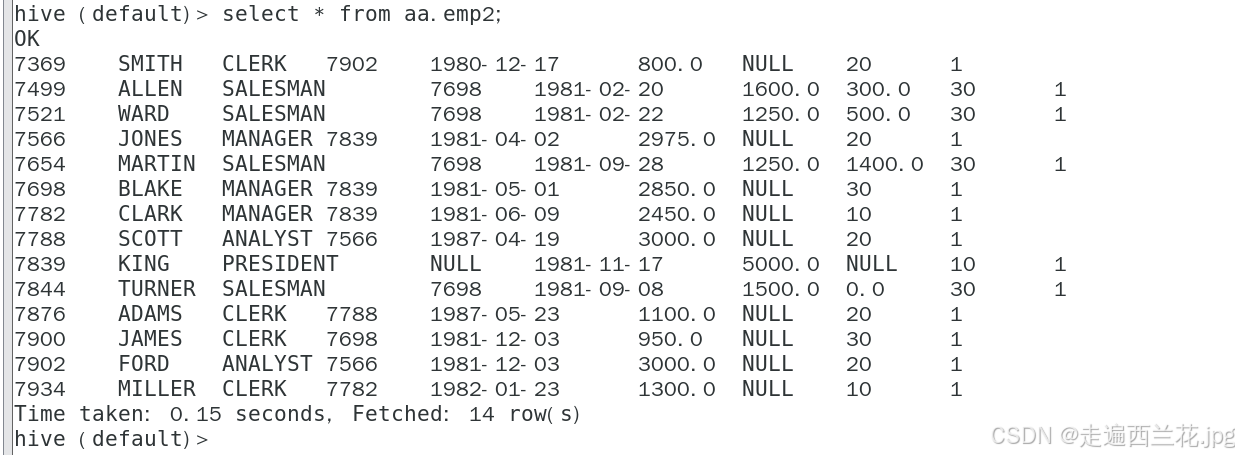
一、导入
1、数据全量抽取
现在要将qfdb中的表抽取到hive的aa库里面
注意:如果是其他的关系型数据库抽取到hive数据库中,不需要新建表格,hive会自动的创建表格,oracle表名要大写
-----连接MySQL
sqoop import \
--hive-import \
--connect jdbc:mysql://192.168.1.27:3306/qfdb \
--username root \
--password 123456 \
--table emp \
--hive-database aa \
--fields-terminated-by ',' -m 1
-----连接Oracle
sqoop import \
--hive-import \
--connect jdbc:oracle:thin:@192.168.1.27:1521/ORCL \
--username scott \
--password 123456 \
--table EMP \
--hive-database sp \
--fields-terminated-by ',' -m 1出现这个就代表执行成功了
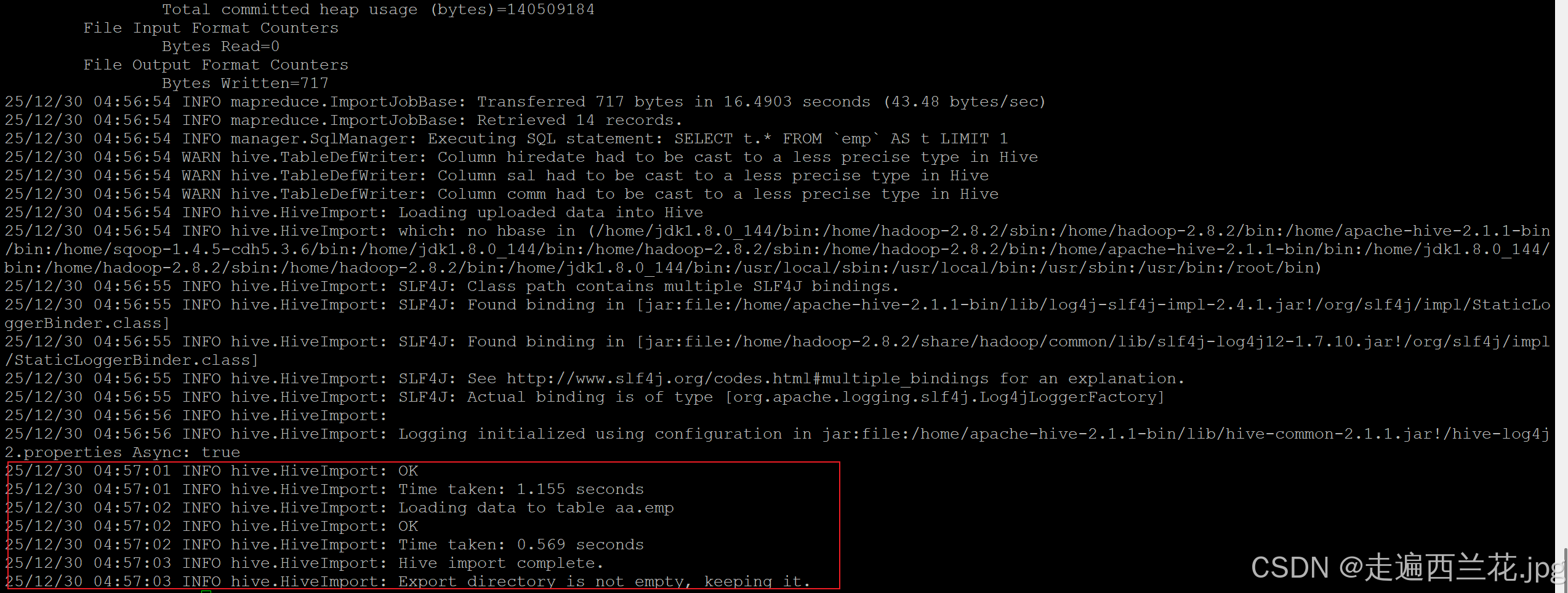
{{--提示报错
如果出现这个错--Output directory hdfs://localhost:9000/user/root/emp already exists
需要把这个文件删除:hdfs dfs -rm -r /user/root/emp
出现这个报错的原因是:假如导入的来源表之前用过,会在root产生新的文件夹,再次使用会报 错,需要把这个文件夹删除
删除之后再次执行sqoop指令:
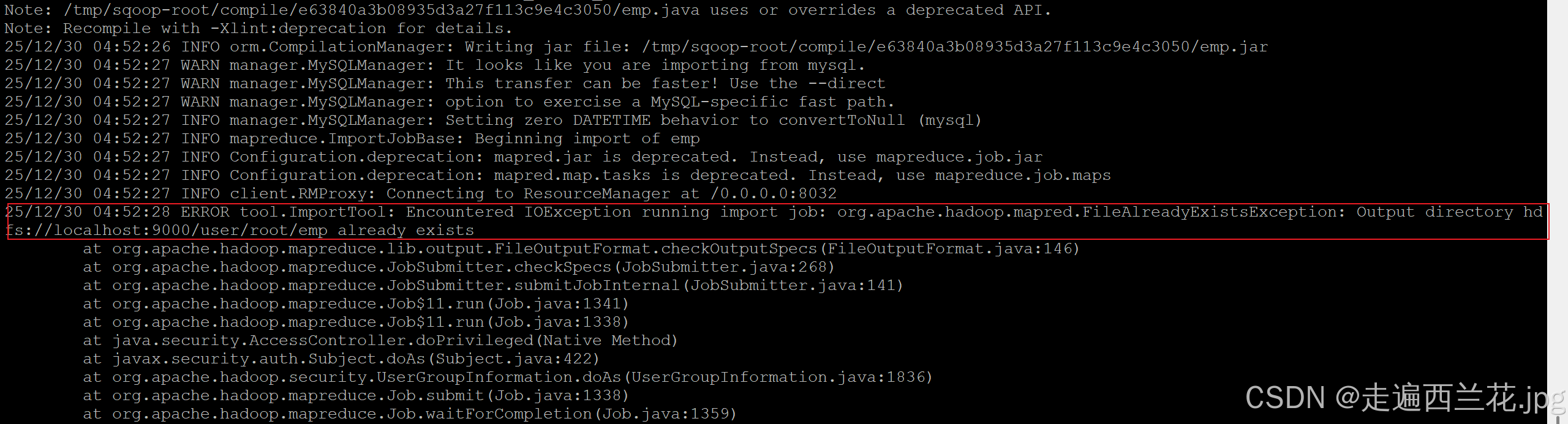
或者在导入的时候加上删除目录的语句(--delete-target-dir # 自动删除已存在的目录)
sqoop import \
--hive-import \
--connect jdbc:mysql://192.168.1.27:3306/qfdb \
--username root \
--password 123456 \
--delete-target-dir \
--table emp \
--hive-database aa \
--fields-terminated-by ',' -m 1 --}}
--}}
2、数据增量抽取
现在有一个目标表zl,里面有三条数据,empno是主键,还有一个来源表emp,有14条数据,现在要将emp的数据增量抽取到zl中;
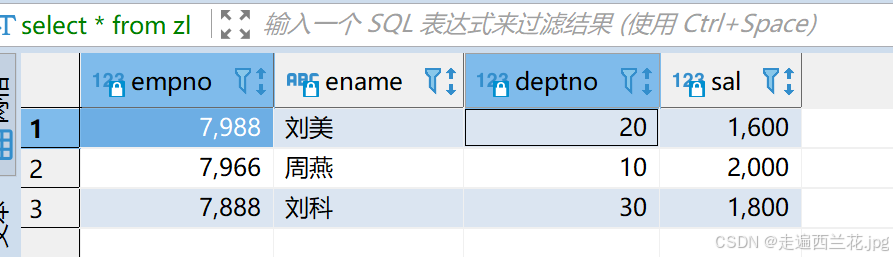
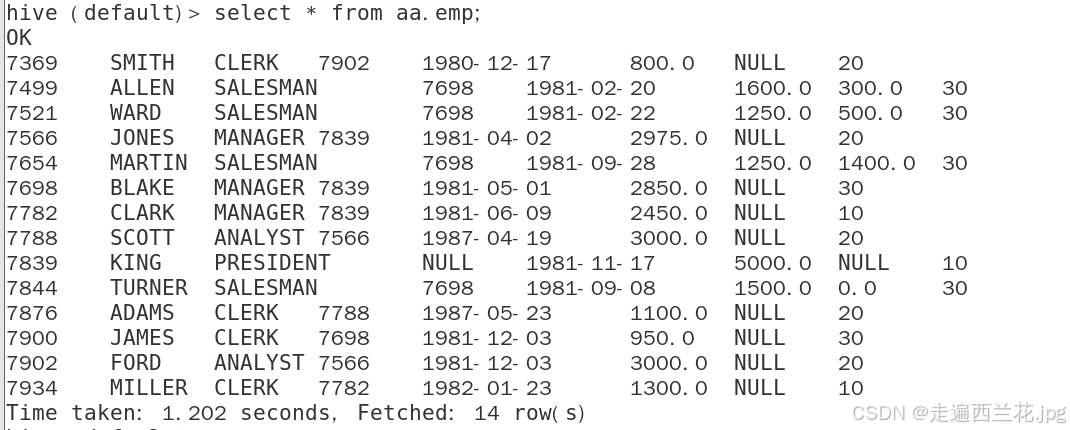
现在emp中最大的empno是7934,zl中empno分别为7888/7988/7966,由于sqoop的last-value设置的值为7934,因此按照增量抽取,所以只抽取满足条件的两条数据7988和7966
sqoop import \
--incremental append \
--connect jdbc:mysql://192.168.100.132:3306/qfdb \
--username root \
--password 123456 \
--table zl \
--target-dir /user/hive/warehouse/aa.db/emp \
--fields-terminated-by ',' \
--check-column empno \
--last-value 7934 -m 1抽取结果: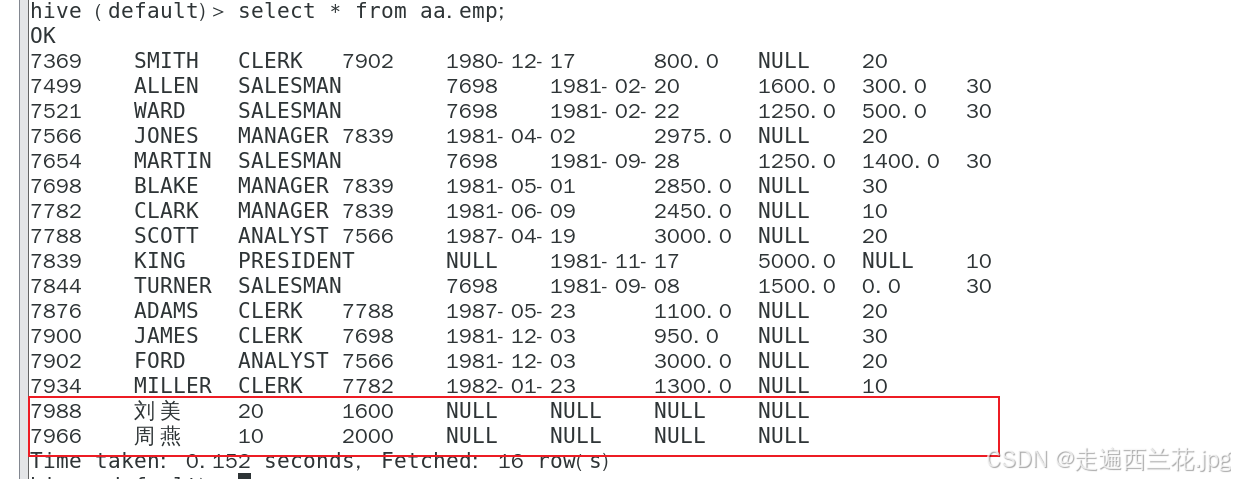
3、进行表格的合并导入
现在要将表z1和z2合并到hive中的表z3


首先将z1中的数据全量抽取到hive中,再将z2中的数据追加抽取到hive中
------第一步,全量抽取z1
sqoop import \
--hive-import \
--connect jdbc:mysql://192.168.100.132:3306/qfdb \
--username root \
--password 123456 \
--delete-target-dir \
--table z1 \
--hive-database aa \
--fields-terminated-by ',' -m 1
-------第二步,追加抽取z2
sqoop import \
--append \
--connect jdbc:mysql://192.168.100.132:3306/qfdb \
--username root \
--password 123456 \
--table z2 \
--target-dir /user/hive/warehouse/aa.db/z1 \
--fields-terminated-by ',' -m 1
4、分区表数据导入
1)在hive端新建一个分区表格,通过sqoop指令,将数据导入到分区表中
----创建一个分区表emp2
CREATE TABLE aa.emp2(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)
partitioned by(y int)
row format delimited fields terminated by ',';2)在hive的分区表中,新增一个分区的文件夹
alter table emp2_part add partition(y=1)
3)导入
sqoop import \
--hive-import \
--connect jdbc:mysql://192.168.100.132:3306/qfdb \
--username root \
--password 123456 \
--delete-target-dir \
--table emp \
--hive-database aa \
--hive-table emp2 \
--hive-partition-key y \
--hive-partition-value 1 \
--fields-terminated-by ',' -m 1