文章目录
-
- [LangChain 实现 RAG](#LangChain 实现 RAG)
-
- LangChain组件
- [LangChain 实现流程](#LangChain 实现流程)
- 文档加载器
-
- [LangChain 文档加载器](#LangChain 文档加载器)
- Document文档类
- 文档加载器使用
- 自定义文档加载器
- 文本分割器
LangChain 实现 RAG
LangChain组件
LangChain 框架提供了丰富的组件帮助我们搭建 RAG 应用,下面是关于这些核心组件的介绍:
| LangChain组件 | 作用 | 常用组件类 |
|---|---|---|
| 文档加载器 | 对各种格式的文档信息进行加载 | Document(文档组件)、UnstructuredPDFLoader(PDF文档加载器)、UnstructuredFileLoader(文件文档加载器)、UnstructuredMarkdownLoader(markdown文档文本加载器) |
| 文档分割器 | 将加载的文档分割成文档片段 | RecursiveCharacterTextSplitter(递归字符文本分割器) |
| 文本嵌入模型组件 | 将文本信息向量化 | OpenAIEmbeddings(OpenAI文本嵌入模型)、HuggingFaceEmbeddings(HuggingFace文本嵌入模型) |
| 向量数据库组件 | 将向量和元数据信息保存到向量数据库 | VectorStore(向量数据库,不同向量数据库有不同的实现类) |
| 文本检索器 | 根据用户提问在向量数据库中进行检索 | VectorStoreRetriever(向量数据库检索器) |
LangChain 实现流程
在RAG准备阶段,LangChain通过文档加载器对各种格式的文档进行加载,转换为LangChain中的文档对象,之后对文档对象进行分割,根据分割规则,分割成文档片段。
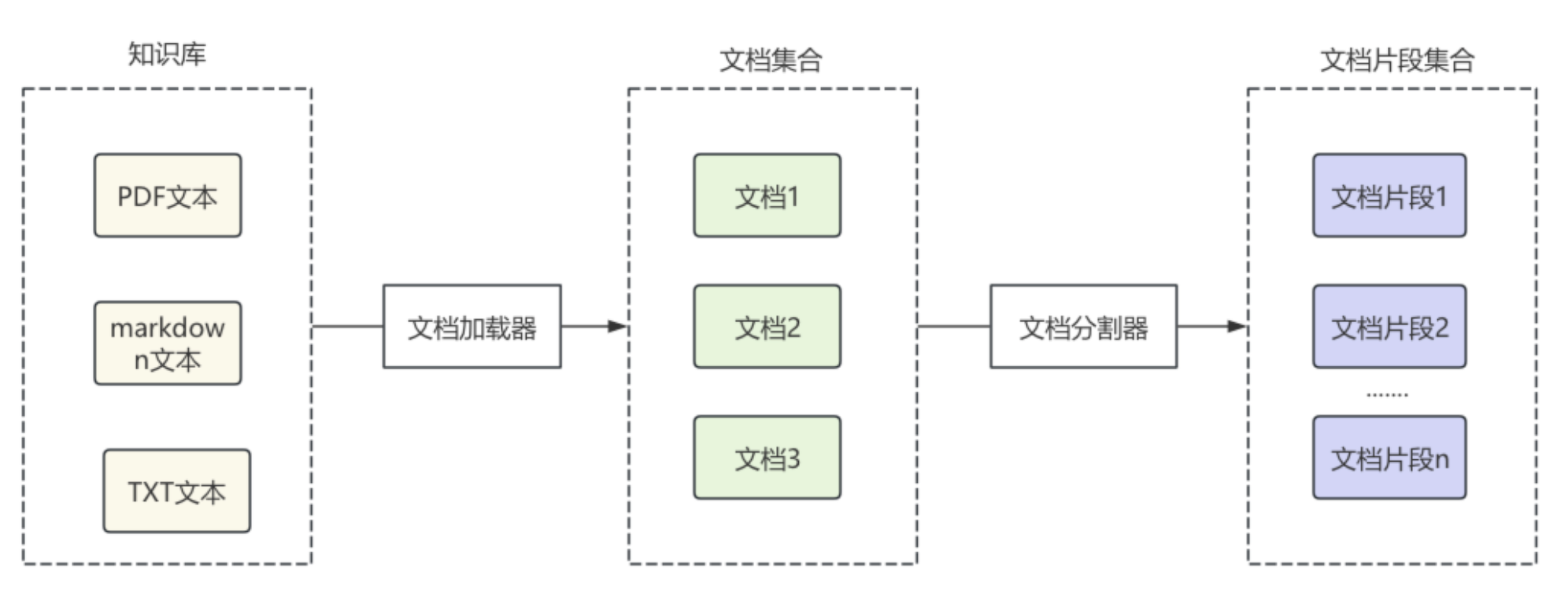
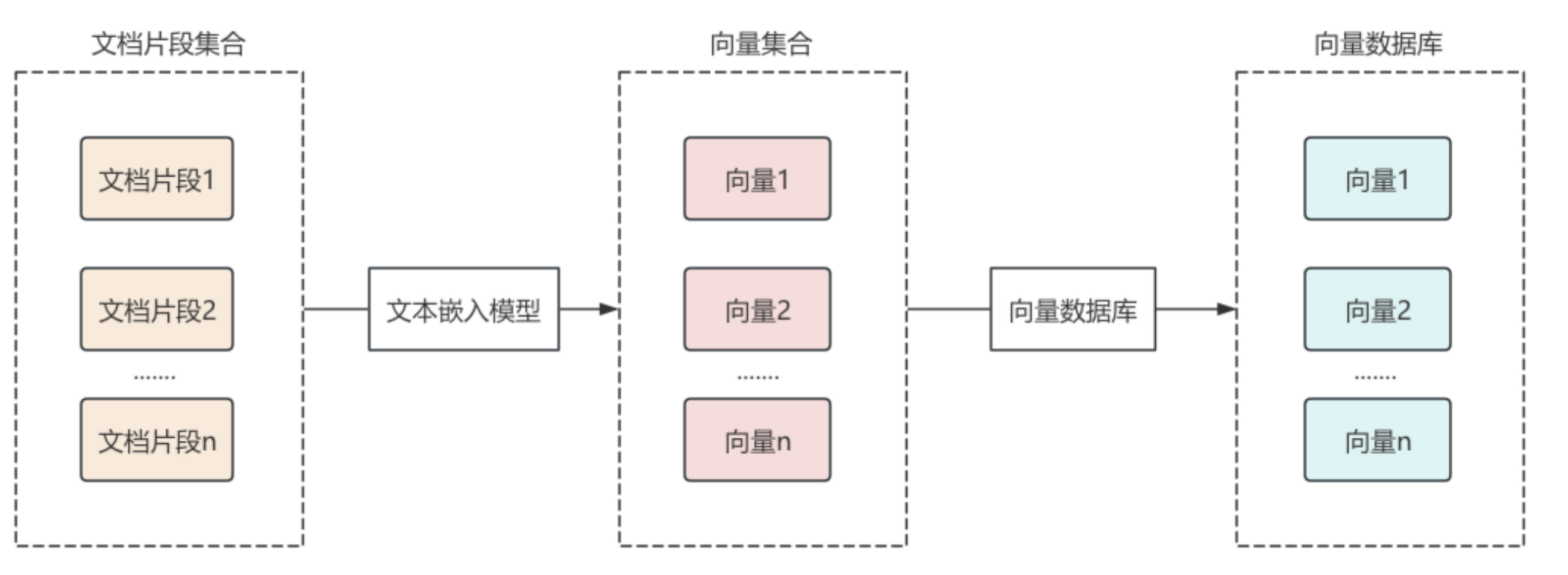
之后,将文档片段通过文本嵌入模型组件,转换为向量,通过向量数据库组件,保存到向量数据库,每个向量通常还会绑定原文内容、文档ID、来源等元数据信息,便于后面数据检索。
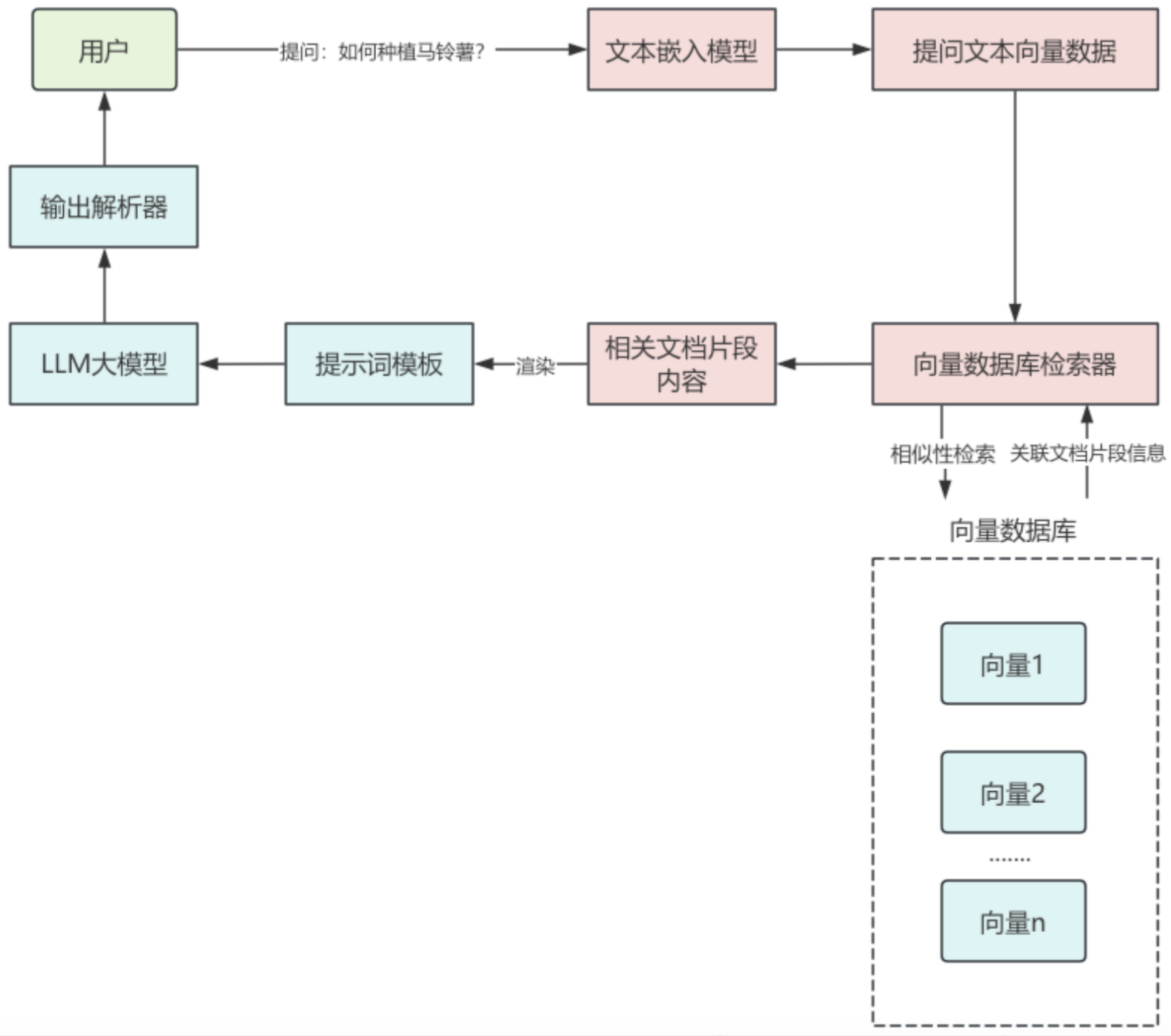
在RAG的使用阶段,用户首先提出问题,使用文本嵌入模型组件,将提问文本转换为向量数据,通过向量数据库检索器组件,进行相似性检索,返回关联的文本片段。
将相关的文档片段内容渲染到提示词模板中,作为提问问题的上下文传递给大语言模型,大语言模型输出结果,再传递给输出解析器,最终结果通过输出解析器处理后返回给用户,这样就完成了一次RAG检索。
文档加载器
在LangChain中,文档加载器用于将各种格式的文档转换为Document对象,LangChain提供了大量的文档加载器,支持从各种来源加载文档,如文件、数据源、URL等。
LangChain 文档加载器
常用的LangChain文档加载器如下:
| 文档加载器 | 作用 |
|---|---|
| CSVLoader | 从CSV加载文档 |
| JSONLoader | 从JSON数据加载文档 |
| PyPDFLoader | 从PDF数据加载文档 |
| UnstructuredHTMLLoader | 从HTML数据加载文档 |
| UnstructuredMarkdownLoader | 从Markdown加载文档 |
| UnstructuredExcelLoader | 从Excel文件加载数据 |
每一个文档加载器都有自己特定的参数和方法,但它们有一个统一的load()方法来完成文档的加载,load()方法会返回一个Document类的对象列表,因为这些文档加载器都继承自BaseLoader基类,它们的继承关系如下:
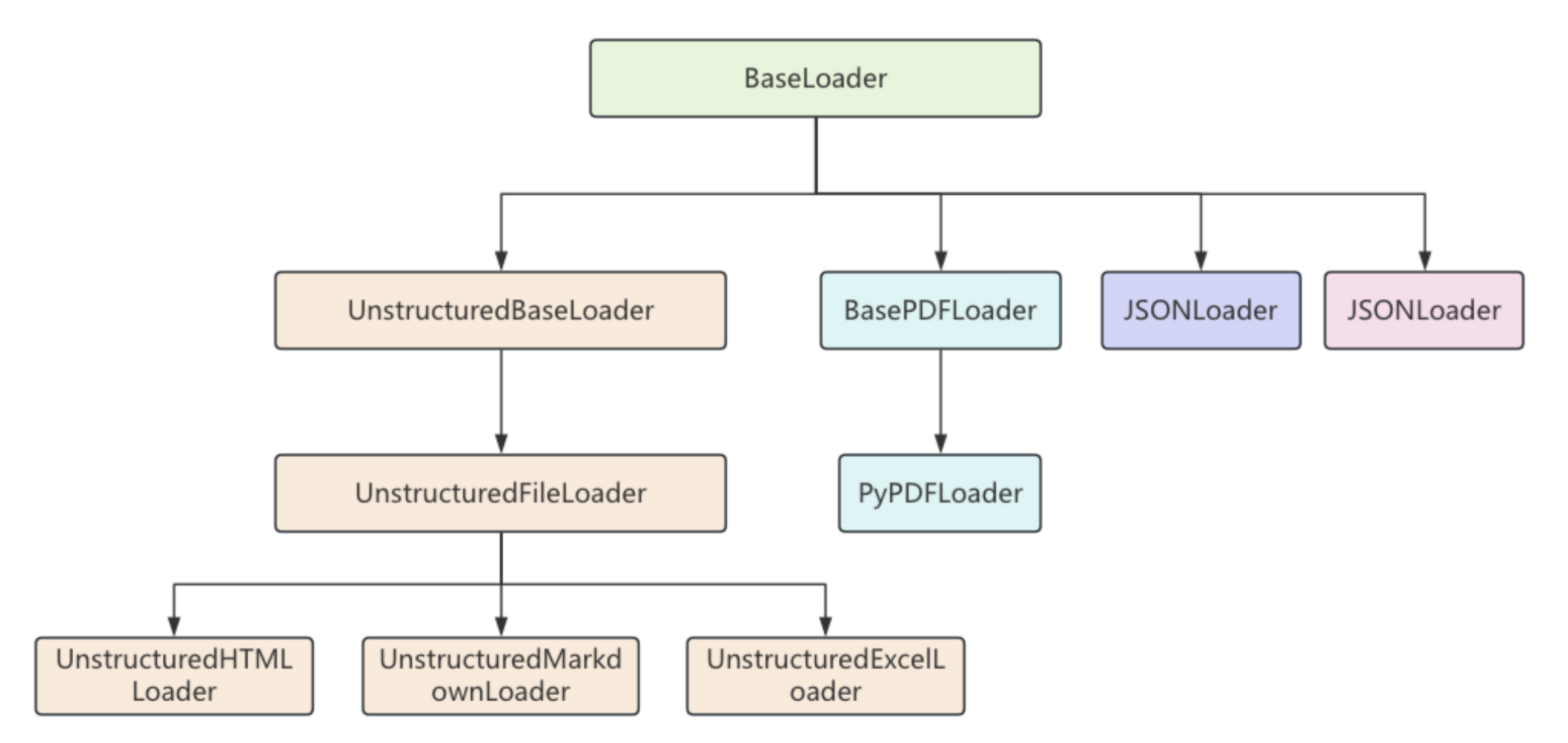
在BaseLoader类中,定义了load()方法,用来加载文档对象,在方法内部又调用了lazy_load()懒加载方法
python
def load(self) -> List[Document]:
"""Load data into Document objects."""
return list(self.lazy_load())在lazy_load()方法中,判断了子类是否重写了load()方法,如果重写了,则调用当前类的load()方法,如果没有重写则抛出异常,因此在子类中,要重写load()方法或lazy_load()方法。
python
def lazy_load(self) -> Iterator[Document]:
"""A lazy loader for Documents."""
if type(self).load != BaseLoader.load:
return iter(self.load())
raise NotImplementedError(
f"{self.__class__.__name__} does not implement lazy_load()"
)如果LangChain提供的文档加载器无法满足业务需求,我们也可以自己实现自定义加载器,通过继承BaseLoader,并实现其中的load()方法,来编写自定义文档加载器的加载逻辑。
Document文档类
文档加载器无论从什么来源进行文档加载,最终都是为了将文档信息解析为Document对象,下面一起来看看Document类中重要属性:
Document类中,主要包含两个重要属性:
page_content:表示文档的内容,类型是字符串
metadata :与文档本身无关的元数据信息。可以保存文档 ID、文件名等任意信息,类型是字典
文档加载器使用
下面以UnstructuredMarkdownLoader为例来介绍文档加载器的用法,使用UnstructuredMarkdownLoader读取md文件示例如下:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 1.创建文档加载器,并指定路径
document_load = UnstructuredMarkdownLoader(file_path="LangChain框架入门09:什么是RAG?.md")
# 2.加载文档
documents = document_load.load()
# 3.打印文档内容
print(f"文档数量:{len(documents)}")
for document in documents:
print(f"文档内容:{document.page_content}")
print(f"文档元数据:{document.metadata}")执行结果如下,默认情况下UnstructuredMarkdownLoader把md文档内容加载成了一个Document对象,并且自动将文件名添加到了Document对象的元数据中。
python
文档数量:1
文档内容:什么是 RAG
(文档内容省略...)
文档元数据:{'source': 'RAG入门.md'}在底层Unstructured包会为不同的文本片段创建不同的"元素"。默认情况下会将这些元素合并在一起,可以通过指定 mode="elements" 来将不同元素进行分离,解析成多个文档。
python
document_load = UnstructuredMarkdownLoader(file_path="RAG入门.md", mode="elements")重新执行代码,可以看到加载的文档数为12,文档的内容也按照不同元素进行了拆分。
python
文档数量:92
文档内容:什么是 RAG
文档元数据:{'source': 'RAG入门.md', 'category_depth': 0, 'languages': ['zho'], 'filename': 'RAG入门.md', 'filetype': 'text/markdown', 'last_modified': '2026-1-2T21:50:19', 'category': 'Title', 'element_id': '97fc7081ad1cf916d8fc1eead4f1e5f9'}
(省略...)自定义文档加载器
在实际开发中,基于文件的不同类型和不同格式,有时通过这些LangChain提供的文档加载器很难满足业务需求,例如需要根据特定规则提取文本片段,这时就需要开发自定义加载器,只需要定义一个自定义文档加载器类,并继承前面提到的BaseLoader类。
假设有如下需求,对 faq.txt文件进行文档加载,内容如下,要求将问题和答案加载成一个文档,并添加文件创建日期元数据。
python
Q:在线支付取消订单后钱怎么返还?
订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
Q:怎么查看退款是否成功?
退款会在一个工作日之内到美团账户余额,可在"账号管理------我的账号"中查看是否到账。
Q:美团账户里的余额怎么提现?
余额可到美团网(meituan.com)------"我的美团→美团余额"里提取到您的银行卡或者支付宝账号,另外,余额也可直接用于支付外卖订单(限支持在线支付的商家)。
Q:余额提现到账时间是多久?
1-7个工作日内可退回您的支付账户。由于银行处理可能有延迟,具体以账户的到账时间为准。
Q:申请退款后,商家拒绝了怎么办?
申请退款后,如果商家拒绝,此时回到订单页面点击"退款申诉",美团客服介入处理。
Q:怎么取消退款呢?
请在订单页点击"不退款了",商家还会正常送餐的。
Q:前面下了一个在线支付的单子,由于未付款,订单自动取消了,这单会计算我的参与活动次数吗?
不会。如果是未支付的在线支付订单,可以先将订单取消(如果不取消需要15分钟后系统自动取消),订单无效后,此时您再下单仍会享受活动的优惠。
Q:为什么我用微信订餐,却无法使用在线支付?
目前只有网页版和美团外卖手机App(非美团手机客户端)订餐,才能使用在线支付,请更换到网页版和美团外卖手机App下单。
Q:如何进行付款?
美团外卖现在支持货到付款与在线支付,其中微信版与手机触屏版暂不支持在线支付。自定义文档加载器代码如下:
python
import os
from datetime import datetime
from langchain_core.documents import Document
from langchain.document_loaders.base import BaseLoader
class SimpleQALoader(BaseLoader):
"""
简单的问答文件加载器
该加载器用于从文本文件中加载问答对,文件格式要求每两行为一组,
第一行为问题(Q),第二行为答案(A)
Args:
file_path (str): 问答文件的路径
time_fmt (str): 时间格式字符串,默认为 "%Y-%m-%d %H:%M:%S"
"""
def __init__(self, file_path: str, time_fmt: str = "%Y-%m-%d %H:%M:%S"):
self.file_path = file_path
self.time_fmt = time_fmt
def load(self):
"""
加载并解析问答文件
读取文件中的问答对,每两行构成一个问答文档,第一行为问题,第二行为答案。
每个文档包含问题和答案的组合内容,以及文件的元数据信息。
Returns:
list[Document]: 包含问答内容的文档列表,每个文档包含page_content和metadata
"""
with open(self.file_path, "r", encoding="utf-8") as f:
lines = [line.strip() for line in f if line.strip()]
docs = []
created_ts = os.path.getctime(self.file_path)
created_at = datetime.fromtimestamp(created_ts).strftime(self.time_fmt)
# 每两行构成一个 Q/A
for i in range(0, len(lines), 2):
q = lines[i].lstrip("Q::").strip()
a = lines[i+1].lstrip("A::").strip()
page_content = f"Q: {q}\nA: {a}"
doc = Document(
page_content=page_content,
metadata={
"source": self.file_path,
"created_at": created_at,
}
)
docs.append(doc)
return docs
# 使用示例
if __name__ == "__main__":
loader = SimpleQALoader("faq.txt")
docs = loader.load()
print(f"共解析到 {len(docs)} 个文档")
for i, d in enumerate(docs, 1):
print(f"\n--- 文档 {i} ---")
print(d.page_content)
print("元数据:", d.metadata)执行结果如下,faq.txt文件被解析成 9 个文档,并且每个文档的元数据都保存了created_at。
python
共解析到 9 个文档
--- 文档 1 ---
Q: 在线支付取消订单后钱怎么返还?
A: 订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 2 ---
Q: 怎么查看退款是否成功?
A: 退款会在一个工作日之内到美团账户余额,可在"账号管理------我的账号"中查看是否到账。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 3 ---
Q: 美团账户里的余额怎么提现?
A: 余额可到美团网(meituan.com)------"我的美团→美团余额"里提取到您的银行卡或者支付宝账号,另外,余额也可直接用于支付外卖订单(限支持在线支付的商家)。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 4 ---
Q: 余额提现到账时间是多久?
A: 1-7个工作日内可退回您的支付账户。由于银行处理可能有延迟,具体以账户的到账时间为准。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 5 ---
Q: 申请退款后,商家拒绝了怎么办?
A: 申请退款后,如果商家拒绝,此时回到订单页面点击"退款申诉",美团客服介入处理。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 6 ---
Q: 怎么取消退款呢?
A: 请在订单页点击"不退款了",商家还会正常送餐的。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 7 ---
Q: 前面下了一个在线支付的单子,由于未付款,订单自动取消了,这单会计算我的参与活动次数吗?
A: 不会。如果是未支付的在线支付订单,可以先将订单取消(如果不取消需要15分钟后系统自动取消),订单无效后,此时您再下单仍会享受活动的优惠。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 8 ---
Q: 为什么我用微信订餐,却无法使用在线支付?
A: 目前只有网页版和美团外卖手机App(非美团手机客户端)订餐,才能使用在线支付,请更换到网页版和美团外卖手机App下单。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}
--- 文档 9 ---
Q: 如何进行付款?
A: 美团外卖现在支持货到付款与在线支付,其中微信版与手机触屏版暂不支持在线支付。
元数据: {'source': 'faq.txt', 'created_at': '2026-1-2 22:15:47'}文本分割器
LangChain 文本分割器
LangChain提供了多种文本分割器,常用的有:
| 分割器 | 作用 |
|---|---|
| RecursiveCharacterTextSplitter | 递归按字符分割文本 |
| CharacterTextSplitter | 按指定字符分割文本 |
| MarkdownHeaderTextSplitter | 按Markdown标题分割 |
| PythonCodeTextSplitter | 专门分割Python代码 |
| TokenTextSplitter | 按Token数量分割 |
| HTMLHeaderTextSplitter | 按HTML标题分割 |
大部分文本分割器都继承自TextSplitter基类,该基类定义了分割文本的核心方法:
- split_text():将文本字符串分割成字符串列表
- split_documents():将Document对象列表分割成更小文本片段的Document对象列表
- create_documents():通过字符串列表创建Document对象
递归文本分割器用法
RecursiveCharacterTextSplitter是LangChain中最常用的通用文本分割器,它会根据指定的字符优先级递归分割文本,直到所有片段长度不超过指定上限。
首先介绍一下RecursiveCharacterTextSplitter构造函数几个核心参数:
chunk_size: 每个片段的最大字符数
chunk_overlap:片段之间的重叠字符数
length_function:计算长度函数
is_separator_regex: 分隔符是否为正则表达式
separators:自定义分隔符
分割文本
首先介绍使用split_text()方法进行文本分割,使用示例如下,其中RecursiveCharacterTextSplitter中指定的块大小为100,片段重叠字符数为30,计算长度的函数使用len。
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.分割文本内容
content = (
"大模型RAG(检索增强生成)是一种结合生成模型与外部知识检索的技术,通过从大规模文档或数据库中检索相关信息,辅助生成模型以提升回答的准确性和相关性。其核心流程包括用户输入查询、系统检索相关知识、生成模型基于检索结果生成内容,并输出最终答案。RAG的优势在于能够弥补生成模型的知识盲区,提供更准确、实时和可解释的输出,广泛应用于问答系统、内容生成、客服、教育和企业领域。然而,其也面临依赖高质量知识库、可能的响应延迟、较高的维护成本以及数据隐私等挑战。")
# 2.定义递归文本分割器
# 使用RecursiveCharacterTextSplitter创建文本分割器,设置块大小为100,重叠长度为30
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=30, length_function=len)
# 3.分割文本
# 将原始文本内容分割成多个文本块
splitter_texts = text_splitter.split_text(content)
# 4.转换为文档对象
# 将分割后的文本块转换为文档对象列表
splitter_documents = text_splitter.create_documents(splitter_texts)
print(f"原始文本大小:{len(content)}")
print(f"分割文档数量:{len(splitter_documents)}")
for splitter_document in splitter_documents:
print(f"文档片段大小:{len(splitter_document.page_content)},文档内容:{splitter_document.page_content}")执行结果如下,文本分割器将文本内容分割成了 3 个文本片段,且内容长度最大为100个字符。
python
原始文本大小:225
分割文档数量:3
文档片段大小:100,文档内容:大模型RAG(检索增强生成)是一种结合生成模型与外部知识检索的技术,通过从大规模文档或数据库中检索相关信息,辅助生成模型以提升回答的准确性和相关性。其核心流程包括用户输入查询、系统检索相关知识、生成模
文档片段大小:100,文档内容:相关性。其核心流程包括用户输入查询、系统检索相关知识、生成模型基于检索结果生成内容,并输出最终答案。RAG的优势在于能够弥补生成模型的知识盲区,提供更准确、实时和可解释的输出,广泛应用于问答系统、内容
文档片段大小:85,文档内容:区,提供更准确、实时和可解释的输出,广泛应用于问答系统、内容生成、客服、教育和企业领域。然而,其也面临依赖高质量知识库、可能的响应延迟、较高的维护成本以及数据隐私等挑战。分割文档对象
RecursiveCharacterTextSplitter不仅可以分割纯文本,还可以直接分割Document对象,使用示例如下:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_unstructured import UnstructuredLoader
# 1.创建文档加载器,进行文档加载
loader = UnstructuredLoader("rag.txt")
documents = loader.load()
# 2.定义递归文本分割器
# 创建RecursiveCharacterTextSplitter实例,用于将文档分割成指定大小的文本块
# chunk_size: 每个文本块的最大字符数为100
# chunk_overlap: 相邻文本块之间的重叠字符数为30
# length_function: 使用len函数计算文本长度
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=30, length_function=len)
# 3.分割文本
# 使用文本分割器将加载的文档分割成多个较小的文档片段
splitter_documents = text_splitter.split_documents(documents)
# 输出分割后的文档信息
print(f"分割文档数量:{len(splitter_documents)}")
for splitter_document in splitter_documents:
print(f"文档片段:{splitter_document.page_content}")
print(f"文档片段大小:{len(splitter_document.page_content)}, 文档元数据:{splitter_document.metadata}")执行结果如下:
python
分割文档数量:3
文档片段:大模型RAG(检索增强生成)是一种结合生成模型与外部知识检索的技术,通过从大规模文档或数据库中检索相关信息,辅助生成模型以提升回答的准确性和相关性。其核心流程包括用户输入查询、系统检索相关知识、生成模
文档片段大小:100, 文档元数据:{'source': 'rag.txt', 'last_modified': '2026-1-2T23:10:05', 'languages': ['zho'], 'filename': 'rag.txt', 'filetype': 'text/plain', 'category': 'UncategorizedText', 'element_id': '2cfba084735e806b5c74d312ca68e815'}
文档片段:相关性。其核心流程包括用户输入查询、系统检索相关知识、生成模型基于检索结果生成内容,并输出最终答案。RAG的优势在于能够弥补生成模型的知识盲区,提供更准确、实时和可解释的输出,广泛应用于问答系统、内容
文档片段大小:100, 文档元数据:{'source': 'rag.txt', 'last_modified': '2026-1-2T23:10:05', 'languages': ['zho'], 'filename': 'rag.txt', 'filetype': 'text/plain', 'category': 'UncategorizedText', 'element_id': '2cfba084735e806b5c74d312ca68e815'}
文档片段:区,提供更准确、实时和可解释的输出,广泛应用于问答系统、内容生成、客服、教育和企业领域。然而,其也面临依赖高质量知识库、可能的响应延迟、较高的维护成本以及数据隐私等挑战。
文档片段大小:85, 文档元数据:{'source': 'rag.txt', 'last_modified': '2026-1-2T23:10:05', 'languages': ['zho'], 'filename': 'rag.txt', 'filetype': 'text/plain', 'category': 'UncategorizedText', 'element_id': '2cfba084735e806b5c74d312ca68e815'}自定义分隔符
RecursiveCharacterTextSplitter默认按照"\\n\\n", "\\n", " ", ""的优先级进行分割,可以通过separators指定自定义分隔符。
python
# 2.定义递归文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,
chunk_overlap=30,
length_function=len,
separators=["。", "?", "\n\n", "\n", " ", ""]
)按标题分割Markdown文件
在对Markdown格式的文档进行分割时,一般不能像RecursiveCharacterTextSplitter默认分割规则方式进行分割,通常需要按照标题层次进行分割,LangChain提供了MarkdownHeaderTextSplitter类来实现这个功能。
在对Markdown文件进行分割时,对于那些很长的文档,可以先利用MarkdownHeaderTextSplitter按标题分割,将分割后的文档再使用RecursiveCharacterTextSplitter进行分割,使用示例如下:
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
# 1.文档加载
# 创建文本加载器并加载Markdown文档
loader = TextLoader(file_path="RAG入门.md")
documents = loader.load()
document_text = documents[0].page_content
# 2.定义文本分割器,设置指定要分割的标题
# 配置Markdown标题分割规则,指定不同级别的标题标记及其对应的元数据标签
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
headers_text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 3.按标题分割文档
# 使用标题分割器将文档按Markdown标题结构进行分割
headers_splitter_documents = headers_text_splitter.split_text(document_text)
print(f"按标题分割文档数量:{len(headers_splitter_documents)}")
for splitter_document in headers_splitter_documents:
print(f"按标题分割文档片段大小:{len(splitter_document.page_content)}, 文档元数据:{splitter_document.metadata}")
# 4.定义递归文本分割器
# 创建递归字符分割器,用于进一步细分过大的文档片段
# chunk_size: 每个文本块的目标大小为100个字符
# chunk_overlap: 相邻文本块之间的重叠字符数为30
# length_function: 使用len函数计算文本长度
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,
chunk_overlap=30,
length_function=len
)
# 5.递归分割文本
# 对已按标题分割的文档片段进行二次递归分割,确保每个片段不超过指定大小
recursive_documents = text_splitter.split_documents(headers_splitter_documents)
print(f"第二次递归文本分割文档数量:{len(recursive_documents)}")
for recursive_document in recursive_documents:
print(
f"第二次递归文本分割文档片段大小:{len(recursive_document.page_content)}, 文档元数据:{recursive_document.metadata}")执行结果如下,先用MarkdownHeaderTextSplitter将markdown文本内容分割成4个文档,之后在对每一个文档使用RecursiveCharacterTextSplitter进行分割,分割成了11个文档,并且在文档元数据中,还添加了文本片段所属的标题信息。
python
按标题分割文档数量:15
按标题分割文档片段大小:247, 文档元数据:{'Header 1': '什么是 RAG'}
按标题分割文档片段大小:446, 文档元数据:{'Header 1': '为什么需要RAG', 'Header 2': '缺陷一:大模型幻觉'}
按标题分割文档片段大小:713, 文档元数据:{'Header 1': '为什么需要RAG', 'Header 2': '缺陷二:有限的最大上下文'}
按标题分割文档片段大小:406, 文档元数据:{'Header 1': '为什么需要RAG', 'Header 2': '缺陷三:模型专业知识与时效性知识不足'}
按标题分割文档片段大小:806, 文档元数据:{'Header 1': 'RAG技术实现流程'}
按标题分割文档片段大小:673, 文档元数据:{'Header 1': 'RAG系统使用场景'}
按标题分割文档片段大小:196, 文档元数据:{'Header 1': 'RAG全栈技术体系介绍'}
按标题分割文档片段大小:815, 文档元数据:{'Header 1': 'RAG全栈技术体系介绍', 'Header 2': 'GraphRAG'}
按标题分割文档片段大小:521, 文档元数据:{'Header 1': 'RAG全栈技术体系介绍', 'Header 2': 'Agentic RAG'}
按标题分割文档片段大小:45, 文档元数据:{'Header 1': 'RAG热门开源项目&产品'}
............自定义文本分割器
当内置的的文本分割器无法满足业务需求时,可以继承TextSplitter类来实现自定义分割器,不过一般需要自定义文本分割器的情况非常少,
假设我们有如下需求,在对文本分割时,按段落进行分割,并且每个段落只提取第一句话,下面通过实现自定义文本分割器,来实现这个功能,示例如下:
python
from typing import List
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import TextSplitter
class CustomTextSplitter(TextSplitter):
"""
自定义文本分割器类
该类继承自TextSplitter,用于将文本按照特定规则进行分割
分割策略:首先按段落分割,然后对每个段落提取第一句话
"""
def split_text(self, text: str) -> List[str]:
"""
将输入文本分割成多个文本片段
参数:
text (str): 需要分割的原始文本字符串
返回:
List[str]: 分割后的文本片段列表,每个片段为段落的第一句话
"""
text = text.strip()
# 1.按段落进行分割
text_array = text.split("\n\n")
result_texts = []
for text_item in text_array:
strip_text_item = text_item.strip()
if strip_text_item is None:
continue
# 2.按句进行分割
result_texts.append(strip_text_item.split("。")[0])
return result_texts
# 1.文档加载
loader = TextLoader(file_path="RAG入门.md")
documents = loader.load()
document_text = documents[0].page_content
# 2.定义文本分割器
splitter = CustomTextSplitter()
# 3.文本分割
splitter_texts = splitter.split_text(document_text)
for splitter_text in splitter_texts:
print(
f"文本分割片段大小:{len(splitter_text)}, 文本内容:{splitter_text}")执行结果:
python
文本分割片段大小:256, 文本内容:# 什么是 RAG
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性
文本分割片段大小:92, 文本内容:# 为什么需要RAG
## 缺陷一:大模型幻觉
大家在使用大模型的时候,都会遇到大模型无中生有胡编乱造答案的情况,例如胡乱生成一些概念、一些论文甚至是一些实时等,这就是所谓的大模型幻觉
文本分割片段大小:106, 文本内容:
文本分割片段大小:53, 文本内容:大型语言模型之所以会产生幻觉,主要是因为它们的训练方式和内在机制决定了它们并不具备真正理解和验证事实的能力
文本分割片段大小:105, 文本内容:## 缺陷二:有限的最大上下文
由于大模型的本质其实是一个算法,不管是让大模型"知道"有哪些外部工具,还是要给大模型进行"背景设置",或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口
文本分割片段大小:33, 文本内容:大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的
文本分割片段大小:168, 文本内容:早些时候的大模型普遍是8k最大上下文,相当于是8-10页中文PDF,伴随着大模型预训练技术的不断发展,顶尖的大模型,如Gemini 2.5 Pro和GPT-4.1等模型,已经达到了1M的最大上下文长度,相当于是一千页的PDF,相当于1.5本《红楼梦》,而普通的模型,也基本达到64K或128K最大上下文,相当于60-100也左右的PDF
文本分割片段大小:106, 文本内容:
......执行结果:
文本分割片段大小:256, 文本内容:# 什么是 RAG
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性
文本分割片段大小:92, 文本内容:# 为什么需要RAG
## 缺陷一:大模型幻觉
大家在使用大模型的时候,都会遇到大模型无中生有胡编乱造答案的情况,例如胡乱生成一些概念、一些论文甚至是一些实时等,这就是所谓的大模型幻觉
文本分割片段大小:106, 文本内容:
文本分割片段大小:53, 文本内容:大型语言模型之所以会产生幻觉,主要是因为它们的训练方式和内在机制决定了它们并不具备真正理解和验证事实的能力
文本分割片段大小:105, 文本内容:## 缺陷二:有限的最大上下文
由于大模型的本质其实是一个算法,不管是让大模型"知道"有哪些外部工具,还是要给大模型进行"背景设置",或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口
文本分割片段大小:33, 文本内容:大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的
文本分割片段大小:168, 文本内容:早些时候的大模型普遍是8k最大上下文,相当于是8-10页中文PDF,伴随着大模型预训练技术的不断发展,顶尖的大模型,如Gemini 2.5 Pro和GPT-4.1等模型,已经达到了1M的最大上下文长度,相当于是一千页的PDF,相当于1.5本《红楼梦》,而普通的模型,也基本达到64K或128K最大上下文,相当于60-100也左右的PDF
文本分割片段大小:106, 文本内容:
......