性能提示(Performance Hints)
作者:Jeff Dean, Sanjay Ghemawat
版本:2023年7月27日初版,2025年12月16日更新
https://abseil.io/fast/hints.html
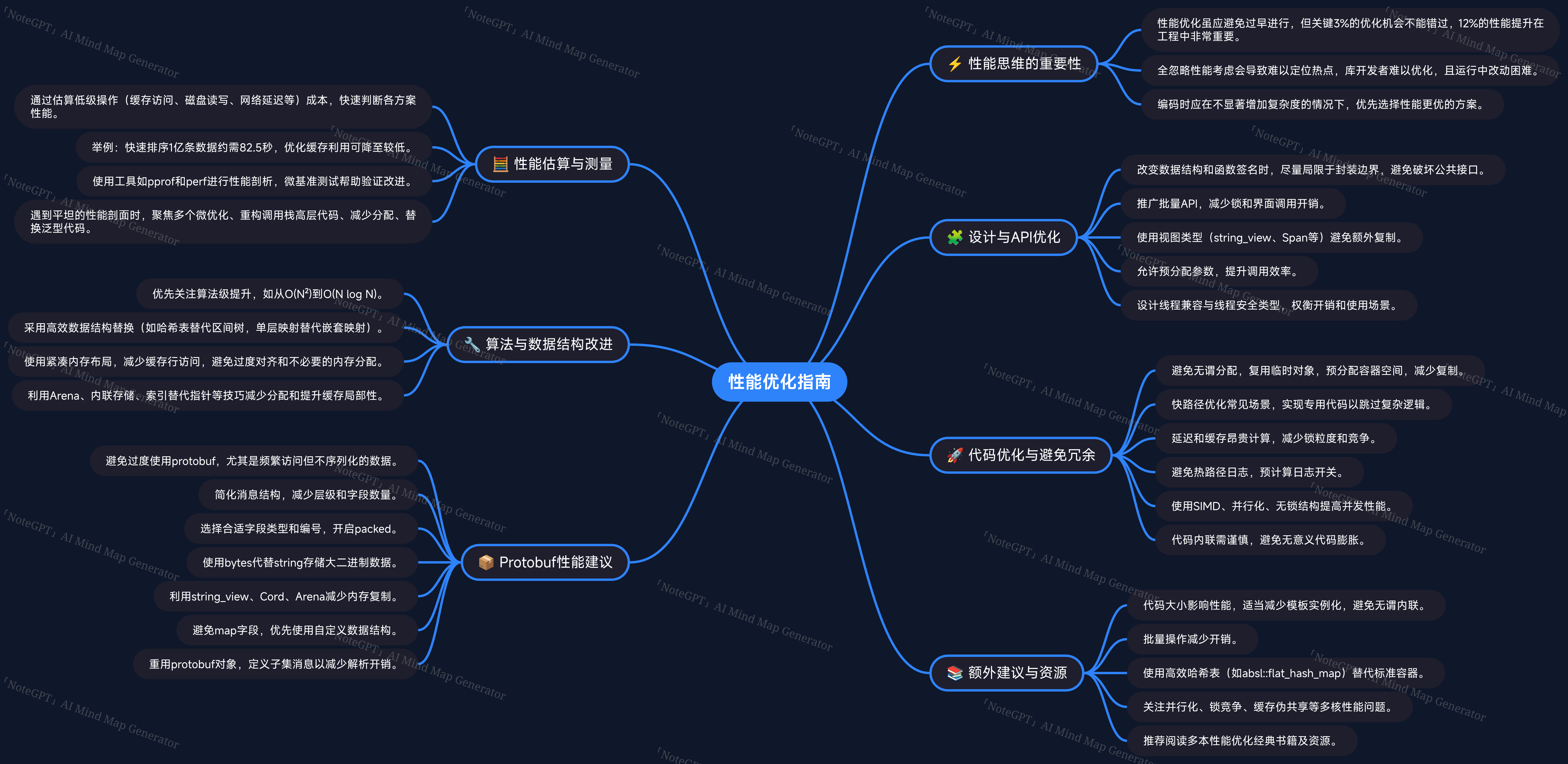
性能思考的重要性
本部分强调了性能优化的重要意义,引用了Knuth的经典论断"过早优化是万恶之源"的完整语境,指出虽然不应过度关注微小效率,但关键3%的性能优化绝不可忽视。性能优化不仅仅是事后调优,而应贯穿开发全过程。忽视性能可能导致代码中无明显热点,难以定位瓶颈;库开发者如果不考虑性能,使用者难以改进;重构成本高昂;且可能引发资源过度配置等问题。因此建议在不显著增加代码复杂度的情况下,优先选择性能较好的方案。
性能估算
估算性能有助于权衡复杂度和效率。根据代码类型的不同,重点关注算法的渐进复杂度(测试代码)、代码是否处于热路径(应用代码)、以及库代码的通用性能。简单的"信封背面"估算法包括:
- 估算各种低级操作次数(磁盘寻址、网络往返、内存读取等)。
- 按操作成本加权求和。
- 对于延迟,考虑并发和成本重叠。
文中附有最新的低级操作时间估算表(如L1缓存参考0.5纳秒,SSD读取4KB约20,000纳秒等),并通过示例(如快排亿级数据、生成30张缩略图的时间估算)说明如何应用。
性能测量
性能测量是性能优化的首要工具。对陌生代码进行性能分析有助于理解代码结构。推荐工具包括Google的pprof和Linux的perf。测量建议:
- 生产环境编译需开启调试信息和优化选项。
- 编写微基准测试(microbenchmark)验证性能改进和防止回退,但注意微基准的局限。
- 使用基准库输出性能计数器数据,获得更深入洞察。
- 关注锁竞争,必要时使用支持锁竞争分析的互斥体实现。
- 机器学习性能分析时,使用专用的ML分析工具。
针对平坦的性能剖析图(无明显热点),建议:
- 积累多个小优化;
- 查找调用栈顶部循环,考虑结构性改变;
- 避免过于泛化的代码,使用更专用的实现;
- 减少内存分配,获取分配剖析数据;
- 使用硬件性能计数器分析缓存未命中等。
API设计考量
性能优化往往涉及数据结构和接口变更,建议将改动局限在封装边界内,减少对调用者的影响。注意API设计中:
- 谨慎添加功能,避免无用特性增加实现成本。
- 例如C++标准库容器保证迭代器稳定性,可能导致额外分配,非必要时应避免。
具体技术包括:
- 批量接口:减少API调用次数和锁开销,如MemoryManager::LookupMany和ObjectStore::DeleteRefs。
- 视图类型参数 :用
std::string_view、std::Span<T>等避免不必要复制。 - 预分配/预计算参数:允许调用者传入已有数据,避免重复分配或计算。
- 线程兼容与线程安全类型:根据使用场景决定同步策略,避免不必要同步开销。
算法改进
算法改进是性能提升的关键,典型手段包括:
- 使用更高效的图结构初始化(如反向后序添加节点避免重复检查)。
- 替换死锁检测算法,显著提升性能和可扩展性。
- 用哈希表替代区间树降低复杂度。
- 优化集合交集操作,使用哈希表替代排序交集。
示例中展示了多项算法层面的变更及其性能提升效果。
内存优化
内存布局和数据结构对性能有巨大影响:
- 采用紧凑数据结构减少内存占用和缓存未命中。
- 调整字段顺序减少内存填充,使用更小的数据类型。
- 使用索引代替指针,提升缓存局部性。
- 使用批量存储结构(如
std::vector、absl::flat_hash_map)减少分配开销。 - 利用inline存储 (如
absl::InlinedVector)避免小元素频繁分配。 - 减少嵌套映射层级,使用复合键降低查找成本。
- 使用Arena分配器减少分配和析构开销。
- 小范围map可用数组替代,bit vector替代set。
减少内存分配
内存分配不仅消耗时间,还引发缓存行分散,增加缓存未命中。方法包括:
- 避免不必要的分配,如静态零向量代替动态分配。
- 预先调整容器大小,避免多次扩容。
- 尽量移动而非复制数据。
- 循环中复用临时对象,避免重复构造销毁。
- 避免不必要的数据复制,存储指针或索引。
- 复用序列化缓冲区。
避免无用工作
跳过不必要的计算是高效代码的重要策略:
- 针对常用情况设计快速路径,避免通用代码开销。
- 预计算昂贵信息,缓存结果。
- 将昂贵计算移出循环,推迟计算到必要时。
- 对频繁调用的代码,设计专用实现。
- 优化日志调用,避免热路径中无意义的日志开销。
- 缓存重复计算结果,减少重复工作。
代码规模考虑
代码规模影响编译时间、内存占用和CPU缓存效率。减少代码规模的方法:
- 减少内联代码,尤其是高调用频率函数。
- 提取复杂格式化到非内联辅助函数。
- 减少模板实例化数量,改用普通参数。
- 减少容器操作调用,使用批量插入。
- 适当延迟内联,避免代码膨胀。
并行与同步
现代多核CPU支持并行执行,合理并行可显著提升性能:
- 利用线程池等机制实现任务并行。
- 减少锁开销,通过合并锁操作降低互斥体使用频率。
- 缩短临界区,避免在锁内执行昂贵操作。
- 通过分片降低锁竞争,使用分片数据结构或并发哈希表。
- 使用SIMD指令加速批量数据处理。
- 减少伪共享,对频繁修改数据使用缓存行对齐。
协议缓冲区(Protobuf)性能建议
虽然Protobuf方便序列化,但存在性能和空间开销:
- 避免无谓使用,未序列化的无需用Protobuf。
- 尽量扁平化消息层级,减少嵌套。
- 常用字段用小字段号(1-15)减少编码长度。
- 选用合适整数类型(int32、fixed32、sint32)平衡编码/解码效率。
- 对重复数字字段使用packed选项。
- 大字段使用bytes代替string,避免UTF8验证开销。
- 使用string_type=VIEW避免拷贝。
- 大字段考虑使用Cord类型。
- 使用Arena减少内存分配和释放开销。
- 避免Protobuf map字段,改用普通map或repeated。
- 根据需求定义子集消息解析,提高效率。
- 复用Protobuf对象减少频繁构造销毁。
C++具体建议
- 优先使用
absl::flat_hash_map和absl::btree_map等高效容器。 - 使用
InlinedBitVector等内联小数据结构替代传统容器。 - 使用
gtl::small_map、small_ordered_set等缓存友好型容器。 - 避免在热点代码中频繁使用
absl::Status和StatusOr类型。 - 利用批量操作和SIMD指令优化容器访问。
- 避免不必要的复制和内存重新分配。
批量操作
处理批量数据往往比单个项处理更高效:
- 利用SIMD加速哈希表匹配。
- 一次处理多字节减少分支判断。
- 采用GroupVarInt等格式批量编码解码整数。
- 利用批量API减少锁和调用开销。
典型代码变更实例
文中列出多例实际CL(变更列表)展示综合应用多种技术的性能提升:
- GPU内存分配器通过减少指针大小、连续内存、减少锁调用等提升40%性能。
- Pathways系统多项改进提升20%吞吐量。
- XLA编译器通过减少字符串比较、缓存数据结构、优化循环等提升约15%性能。
- Google Meet代码优化日志处理提升50%以上性能。
- SelectServer报警处理更换数据结构,减少分配,提升3.3倍性能。
- In-memory索引服务通过多种技术提升3倍以上查询速度。
参考文献
文末附有丰富性能相关书籍、论文和博客推荐,如Agner Fog的《Optimizing software in C++》、Richard L. Sites的《Understanding Software Dynamics》、Jon Bentley的《Programming Pearls》等。
总结
本文全面系统地总结了软件性能优化的多方面技巧和原则,涵盖代码设计、算法优化、内存布局、并行同步、日志管理、代码大小控制及具体语言和库的使用建议。通过理论讲解与大量代码示例,帮助开发者理解并实践性能优化,提升软件整体效率和资源利用率。