知识点回顾:
- 对抗生成网络的思想:关注损失从何而来
- 生成器、判别器
- nn.sequential 容器:适合于按顺序运算的情况,简化前向传播写法
- leakyReLU介绍:避免relu 的神经元失活现象
(ps:如果你学有余力,对于 gan的损失函数的理解,建议去找找视频看看,如果只是用,没必要学)
零基础学 GAN:从 "造假币" 到代码落地(超通俗版)
先跟你说清楚:咱们今天学的 "对抗生成网络(GAN)" 一点都不玄,核心就是两个角色的博弈,再加上两个实用的 PyTorch 工具(nn.Sequential、LeakyReLU)。我会用 "造假币 vs 警察" 的例子贯穿全程,代码只写核心逻辑,每一行都解释,保证你能懂。
一、先搞懂:GAN 的核心思想 + 损失从哪来?
1. GAN 的本质:"造假的" 和 "打假的" 互卷
想象一个场景:
- 造假币的人(生成器 G):目标是造出和真币一模一样的假币,骗过大爷(判别器 D)。
- 警察大爷(判别器 D):目标是一眼分清真币和假币,绝不被骗。
- 对抗过程:造假的越造越像,警察越辨越准,最后造假的能造出 "以假乱真" 的假币(GAN 训练完成)。
这就是 GAN 的核心:生成器和判别器互相 "对着干",各自优化自己,最终达到一个平衡。
2. 损失(Loss):"没做好的程度"(关键!)
"损失" 就是 "没达到目标的差距",比如你考试想考 100 分,只考了 80 分,那 "损失" 就是 20 分。GAN 里的损失分两种,对应两个角色:
| 角色 | 目标 | 损失来源(没做好的地方) | 损失越小说明啥? |
|---|---|---|---|
| 判别器 D | 真币判 1,假币判 0(0 = 假,1 = 真) | 1. 把真币当成假币(判成 0);2. 把假币当成真币(判成 1) | 判别得越准 |
| 生成器 G | 让 D 把自己造的假币判成 1 | D 给假币判的分数离 1 越远,损失越大 | 假币造得越像真币 |
举个具体例子:
- 警察 D 拿到一张真币,却判成了 0(以为是假的)→ D 的损失变大;
- 造假者 G 造的假币,被 D 判成了 0.1(几乎一眼识破)→ G 的损失变大;
- 慢慢训练后,G 造的假币被 D 判成 0.9(快骗过了)→ G 的损失变小,D 的损失也变小(因为 D 对真币判 1,对假币判 0.9,虽然没完全准,但比之前好)。
总结:GAN 的损失就是 "两个角色没完成自己目标的程度",训练的过程就是让两者的损失都慢慢降到合理水平。
二、生成器(G)和判别器(D):具体干啥?
还是用 "假币" 例子,把两个角色的工作流程说透(对应机器学习里的 "数据流程"):
1. 先明确 "原材料"
- 真币库:央行印的真钱(对应机器学习里的 "真实样本",比如真实的猫咪图片、手写数字);
- 随机数:造假者随便画的线条(对应 GAN 里的 "噪声",一串随机数字,是生成器的输入)。
2. 生成器(G)的工作流程
输入:一堆随机数(噪声)→ 经过层层处理 → 输出:假币(和真币长得像的 "假样本")。比如:输入 0.2, 0.5, -0.1 → G 处理后 → 输出一张 "看起来像真钱的假钱"。
3. 判别器(D)的工作流程
输入:要么是真币(真实样本),要么是 G 造的假币(生成样本)→ 经过层层处理 → 输出:0~1 之间的数(0 = 肯定假,1 = 肯定真)。比如:
- 输入真币 → D 输出 0.98(几乎确定是真的);
- 输入 G 刚造的假币 → D 输出 0.1(几乎确定是假的);
- 输入 G 训练后的假币 → D 输出 0.5(分不清真假了,GAN 训练到位了)。
一句话总结
G 拼命 "仿造" 真样本,D 拼命 "分辨" 真 / 假样本,两者对抗着进步。
三、nn.Sequential 容器:神经网络的 "流水线"
学完 G 和 D,接下来学写代码的工具:nn.Sequential(PyTorch 里的工具)。
1. 先类比:做奶茶的流水线
你做奶茶的步骤是:加茶底 → 加牛奶 → 加糖 → 加珍珠 → 摇匀。如果不用 "流水线",你得手动一步步写:
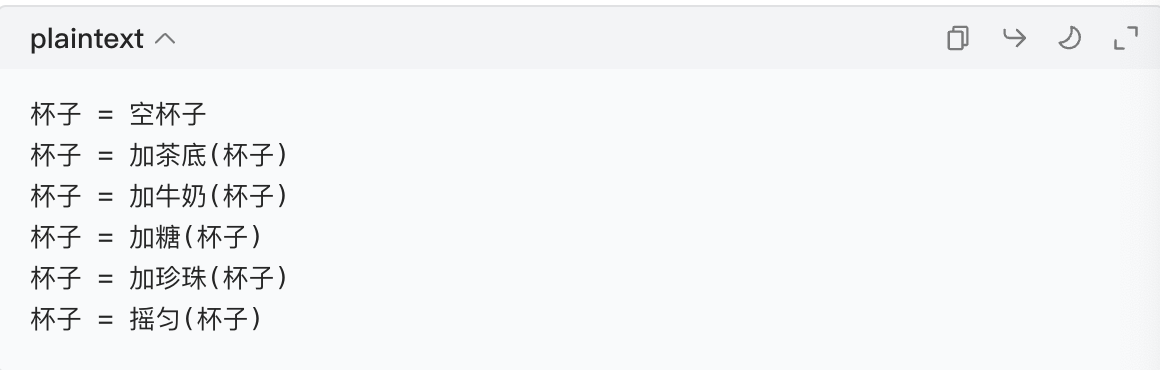
如果用 "流水线(Sequential)",直接把步骤打包成一个 "奶茶机",按一下就自动做完:

2. nn.Sequential 的作用
神经网络的层是按顺序执行的(比如先做线性变换,再做激活,再做归一化),nn.Sequential 就是把这些层 "串起来",形成一个 "神经网络流水线",不用手动写每一层的输入输出,简化代码。
3. 代码例子(对比版)
假设我们要写一个简单的判别器 D,包含 3 层:
- 第一层:线性变换(把输入的 784 个数变成 128 个数);
- 第二层:激活函数(LeakyReLU,后面讲);
- 第三层:线性变换(把 128 个数变成 1 个数,输出 0~1)。
不用 Sequential 的写法(繁琐)
python
import torch
import torch.nn as nn
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 定义每层
self.layer1 = nn.Linear(784, 128) # 线性层:784→128
self.act = nn.LeakyReLU(0.01) # 激活层:LeakyReLU
self.layer2 = nn.Linear(128, 1) # 线性层:128→1
# 前向传播(手动写每一步)
def forward(self, x):
x = self.layer1(x) # 第一步:过线性层1
x = self.act(x) # 第二步:过激活层
x = self.layer2(x) # 第三步:过线性层2
return x
# 测试
d = Discriminator()
input_data = torch.randn(1, 784) # 随机输入(模拟一张图片,784个像素)
output = d(input_data)
print(output) # 输出一个数(判别结果)用 Sequential 的写法(简洁)
python
import torch
import torch.nn as nn
# 定义判别器(用Sequential打包层)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 把层按顺序打包成一个"流水线"
self.model = nn.Sequential(
nn.Linear(784, 128), # 第一步:线性层
nn.LeakyReLU(0.01), # 第二步:激活层
nn.Linear(128, 1) # 第三步:线性层
)
# 前向传播:直接过流水线
def forward(self, x):
return self.model(x)
# 测试
d = Discriminator()
input_data = torch.randn(1, 784)
output = d(input_data)
print(output) # 和上面结果一样,但代码少了很多!核心总结
nn.Sequential 就是 "按顺序执行的层容器",适合层与层之间是 "串行" 的情况,能大幅简化代码,不用手动写每一层的前向传播。
四、LeakyReLU:让神经元 "不躺平" 的激活函数
先搞懂:激活函数是干啥的?→ 给神经网络加 "非线性",让网络能学复杂的规律(比如区分真币和假币的复杂特征)。
1. 先看 ReLU(LeakyReLU 的 "前辈")
ReLU 是最常用的激活函数,规则超简单:
- 输入 > 0 → 输出 = 输入(比如输入 5→5,输入 0.8→0.8);
- 输入≤0 → 输出 = 0(比如输入 - 3→0,输入 - 0.5→0)。
ReLU 的问题:神经元 "躺平失活"
比如有个神经元,每次输入都是负数(比如一直输入 - 2、-1、-5),那它永远输出 0,相当于 "彻底摆烂,不干活了",这个神经元就废了(失活),再也学不到东西。
2. LeakyReLU:给 "躺平的神经元" 发低保
LeakyReLU 是 ReLU 的改进版,规则:
- 输入 > 0 → 输出 = 输入(和 ReLU 一样);
- 输入≤0 → 输出 = 输入 × 一个很小的数(比如 0.01,比如输入 - 3→-3×0.01=-0.03,输入 - 0.5→-0.005)。
类比理解
- ReLU:"工资> 0 才上班,工资≤0 就彻底旷工,一分钱不赚";
- LeakyReLU:"工资≤0 也不旷工,拿 0.01 倍的低保(很小的钱),还是来上班"。
这样一来,即使神经元输入一直是负数,也不会完全 "躺平",还能参与学习,避免失活。
3. 代码例子(直观对比)
python
import torch
import torch.nn as nn
# 定义ReLU和LeakyReLU
relu = nn.ReLU()
leaky_relu = nn.LeakyReLU(0.01) # 0.01是"低保系数",常用0.01
# 测试输入(包含正数、负数、0)
inputs = torch.tensor([5, -3, 0, -0.5, 2.8])
# 计算输出
relu_out = relu(inputs)
leaky_relu_out = leaky_relu(inputs)
print("输入:", inputs)
print("ReLU输出:", relu_out) # 输出:[5., 0., 0., 0., 2.8]
print("LeakyReLU输出:", leaky_relu_out) # 输出:[5.0000, -0.0300, 0.0000, -0.0050, 2.8000]看结果就知道:LeakyReLU 对负数输入没有输出 0,而是输出了一个很小的负数,神经元就不会完全失活了。
五、把所有知识点串起来:极简 GAN 代码框架
现在把生成器、判别器、nn.Sequential、LeakyReLU 整合,写一个最简化的 GAN 代码(注释超详细,零基础能看懂)。
完整代码(复制就能跑)
python
import torch
import torch.nn as nn
import torch.optim as optim # 优化器,用来更新网络参数
# ---------------------- 1. 定义生成器(G:造假币的) ----------------------
class Generator(nn.Module):
def __init__(self):
super().__init__()
# 用Sequential打包生成器的层(流水线)
self.model = nn.Sequential(
nn.Linear(100, 256), # 输入:100维随机噪声 → 256维
nn.LeakyReLU(0.01), # 激活:避免神经元失活
nn.Linear(256, 784), # 输出:784维(对应28×28的手写数字图片)
nn.Tanh() # 把输出限制在[-1,1],方便后续处理
)
def forward(self, x):
return self.model(x) # 直接过流水线
# ---------------------- 2. 定义判别器(D:警察) ----------------------
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 用Sequential打包判别器的层(流水线)
self.model = nn.Sequential(
nn.Linear(784, 256), # 输入:784维图片 → 256维
nn.LeakyReLU(0.01), # 激活:避免神经元失活
nn.Linear(256, 1), # 输出:1个数(判别结果)
nn.Sigmoid() # 把输出限制在[0,1](0=假,1=真)
)
def forward(self, x):
return self.model(x) # 直接过流水线
# ---------------------- 3. 初始化角色 + 损失函数 + 优化器 ----------------------
# 初始化生成器和判别器
G = Generator()
D = Discriminator()
# 损失函数:二分类交叉熵(适合判断"真/假")
loss_fn = nn.BCELoss()
# 优化器:用来更新G和D的参数(让它们慢慢变好)
opt_G = optim.Adam(G.parameters(), lr=0.0002) # G的优化器
opt_D = optim.Adam(D.parameters(), lr=0.0002) # D的优化器
# ---------------------- 4. 模拟一次训练(核心逻辑) ----------------------
# 1. 准备数据:真实样本(模拟手写数字,784维)+ 随机噪声(G的输入)
real_data = torch.randn(1, 784) # 真实样本(1个,784维)
noise = torch.randn(1, 100) # 随机噪声(1个,100维)
# 2. 训练判别器D(让D分清真/假)
fake_data = G(noise) # G用噪声生成假样本
d_real_out = D(real_data) # D判真实样本
d_fake_out = D(fake_data) # D判假样本
# D的损失:真样本希望判1,假样本希望判0
loss_D = loss_fn(d_real_out, torch.ones_like(d_real_out)) + \
loss_fn(d_fake_out, torch.zeros_like(d_fake_out))
# 更新D的参数(让D更准)
opt_D.zero_grad() # 清空梯度
loss_D.backward() # 计算梯度
opt_D.step() # 更新参数
# 3. 训练生成器G(让G骗过多D)
fake_data = G(noise) # G重新生成假样本
d_fake_out = D(fake_data) # D判新的假样本
# G的损失:希望D把假样本判1
loss_G = loss_fn(d_fake_out, torch.ones_like(d_fake_out))
# 更新G的参数(让G造的假样本更像真的)
opt_G.zero_grad()
loss_G.backward()
opt_G.step()
# 打印损失(看训练效果)
print("判别器损失:", loss_D.item())
print("生成器损失:", loss_G.item())代码核心解释

六、最后总结(零基础必记)
- GAN 的思想:生成器(造假)和判别器(打假)对抗,损失是 "没达到目标的差距"(D 判错、G 骗不过都算损失);
- 生成器 / 判别器:G 输随机数出假样本,D 输样本出 0~1 的判别结果;
- nn.Sequential:神经网络的 "流水线",按顺序串层,简化代码;
- LeakyReLU:ReLU 的改进版,负数输入不输出 0,避免神经元 "躺平"。
你现在不用纠结代码的细节(比如优化器、损失函数),先记住核心角色和工具的作用,后续我们可以一步步细化训练过程。
作业:对于心脏病数据集,对于病人这个不平衡的样本用GAN 来学习并生成病人样本,观察不用 GAN 和用 GAN的 F1 分数差异。
Mac OS + VS Code 实战:GAN 解决心脏病数据集不平衡问题(零基础版)
全程适配 Mac 系统(Intel/M1/M2/M3 通用),代码每行带注释,步骤拆到 "复制就能跑" 的程度,核心复用今天学的 GAN 思想、生成器 / 判别器、nn.Sequential、LeakyReLU 知识点。
核心目标
心脏病数据集里 "有心脏病(病人)" 是少数类,"无心脏病(健康人)" 是多数类 → 用 GAN 生成模拟的病人样本,扩充训练集 → 对比 "不用 GAN(原始数据)" 和 "用 GAN(扩充后数据)" 的分类 F1 分数(F1 是衡量不平衡数据分类效果的核心指标)。
第一步:Mac 环境准备(VS Code)
1. 打开终端(Mac 自带,Spotlight 搜 "终端")
2. (可选但推荐)创建虚拟环境(避免库版本冲突)

3. 安装必备库(Mac 通用,复制到终端回车)

4. VS Code 准备
- 打开 VS Code → 新建文件夹(比如
gan_heart_project)→ 新建 Python 文件(比如gan_heart.py)→ 后续代码都写在这里。 - (可选)VS Code 安装 Python 插件(微软官方的 Python 插件,搜 "Python" 安装),方便运行代码。
第二步:数据集准备与预处理(核心:处理不平衡 + 标准化)
数据集说明
用 UCI 公开的心脏病数据集(不用手动下载,代码自动加载),标签target:1 = 有心脏病(少数类),0 = 无心脏病(多数类)。
代码段 1:加载并预处理数据
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score
from sklearn.linear_model import LogisticRegression # 简单分类器,易理解
# ---------------------- 1. 加载心脏病数据集 ----------------------
# 自动下载UCI心脏病数据集(Mac网络正常即可)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data"
# 定义列名(数据集无表头,手动指定)
columns = [
"age", "sex", "cp", "trestbps", "chol", "fbs", "restecg",
"thalach", "exang", "oldpeak", "slope", "ca", "thal", "target"
]
# 加载数据
df = pd.read_csv(url, names=columns)
# ---------------------- 2. 处理缺失值(数据集里用?表示缺失) ----------------------
df = df.replace('?', np.nan) # 把?换成NaN
df = df.dropna() # 删掉缺失值行(零基础先这么做,简单)
# ---------------------- 3. 处理标签(把target>0都算有心脏病,统一为1) ----------------------
# 原数据集target是0(无)、1/2/3/4(不同程度心脏病),简化为二分类
df['target'] = df['target'].apply(lambda x: 1 if x > 0 else 0)
# ---------------------- 4. 查看样本不平衡情况(关键!) ----------------------
print("=== 原始样本分布 ===")
print(df['target'].value_counts())
# 输出示例:0(健康)约200个,1(病人)约100个,明显不平衡
# ---------------------- 5. 划分特征和标签 + 标准化 ----------------------
# 特征(去掉标签列)
X = df.drop('target', axis=1).values
# 标签
y = df['target'].values
# 标准化(GAN对数值范围敏感,必须做!)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 所有特征缩放到均值0,方差1
# 划分训练集和测试集(测试集不用扩充,用来评估)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y_scaled, test_size=0.2, random_state=42 # 固定随机数,结果可复现
)
# ---------------------- 6. 分离少数类(病人样本):GAN的训练目标 ----------------------
# 取出训练集中的病人样本(y_train=1)
X_train_patient = X_train[y_train == 1]
print(f"\n训练集中病人样本数:{len(X_train_patient)}") # 示例:约80个第三步:构建 GAN 模型(复用今天学的知识点)
核心:生成器输入随机噪声,输出和特征维度(13 维)一致的 "模拟病人样本";判别器区分 "真实病人样本" 和 "GAN 生成的假病人样本"。
代码段 2:构建 GAN(生成器 + 判别器)
ruby
import torch
import torch.nn as nn
import torch.optim as optim
# ---------------------- 1. 定义超参数(零基础先不用改) ----------------------
NOISE_DIM = 100 # 噪声维度(随便选,100是常用值)
FEATURE_DIM = X_train_patient.shape[1] # 特征维度(13维)
BATCH_SIZE = 8 # 批次大小(Mac内存小就选8,大就选16)
EPOCHS = 500 # 训练轮数(越多生成越像,但耗时久)
LR = 0.0002 # 学习率(越小越稳定)
# ---------------------- 2. 定义生成器(G:生成模拟病人样本) ----------------------
# 用今天学的nn.Sequential打包层,LeakyReLU避免神经元失活
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# 输入:100维噪声 → 64维隐藏层
nn.Linear(NOISE_DIM, 64),
nn.LeakyReLU(0.01), # 低保系数0.01,和今天学的一致
# 中间层:64→32
nn.Linear(64, 32),
nn.LeakyReLU(0.01),
# 输出:32→13(和特征维度一致)
nn.Linear(32, FEATURE_DIM)
)
def forward(self, x):
return self.model(x) # 流水线式前向传播
# ---------------------- 3. 定义判别器(D:区分真实/生成的病人样本) ----------------------
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# 输入:13维特征 → 32维
nn.Linear(FEATURE_DIM, 32),
nn.LeakyReLU(0.01),
# 中间层:32→16
nn.Linear(32, 16),
nn.LeakyReLU(0.01),
# 输出:16→1(0~1的判别结果)
nn.Linear(16, 1),
nn.Sigmoid() # 把输出限制在0~1
)
def forward(self, x):
return self.model(x)
# ---------------------- 4. 初始化GAN + 损失函数 + 优化器 ----------------------
# 初始化生成器和判别器(Mac默认用CPU,不用改)
G = Generator()
D = Discriminator()
# 损失函数:二分类交叉熵(适合真/假判断)
loss_fn = nn.BCELoss()
# 优化器:Adam(常用且稳定)
opt_G = optim.Adam(G.parameters(), lr=LR)
opt_D = optim.Adam(D.parameters(), lr=LR)
# 把病人样本转成PyTorch张量(GAN需要张量格式)
X_patient_tensor = torch.tensor(X_train_patient, dtype=torch.float32)第四步:训练 GAN(生成模拟病人样本)
核心逻辑:交替训练判别器(D)和生成器(G),和今天学的 "造假币 vs 警察" 逻辑完全一致。
代码段 3:训练 GAN
python
# ---------------------- 训练GAN主循环 ----------------------
print("\n=== 开始训练GAN ===")
for epoch in range(EPOCHS):
# ---------------------- 1. 训练判别器(D):区分真实/假样本 ----------------------
# 步骤1:用真实病人样本训练D → 希望D判1
real_labels = torch.ones(BATCH_SIZE, 1) # 真实样本标签=1
# 随机选一批真实病人样本
idx = torch.randint(0, len(X_patient_tensor), (BATCH_SIZE,))
real_samples = X_patient_tensor[idx]
# D判真实样本
d_real_out = D(real_samples)
# D的真实样本损失
d_loss_real = loss_fn(d_real_out, real_labels)
# 步骤2:用生成的假样本训练D → 希望D判0
fake_labels = torch.zeros(BATCH_SIZE, 1) # 假样本标签=0
# 生成随机噪声
noise = torch.randn(BATCH_SIZE, NOISE_DIM)
# G生成假样本
fake_samples = G(noise)
# D判假样本(detach():不让G的梯度更新,只训D)
d_fake_out = D(fake_samples.detach())
# D的假样本损失
d_loss_fake = loss_fn(d_fake_out, fake_labels)
# 总D损失 + 更新D参数
d_loss = d_loss_real + d_loss_fake
opt_D.zero_grad() # 清空梯度
d_loss.backward() # 计算梯度
opt_D.step() # 更新参数
# ---------------------- 2. 训练生成器(G):骗过多D ----------------------
# G生成新的假样本,希望D判1
noise = torch.randn(BATCH_SIZE, NOISE_DIM)
fake_samples = G(noise)
d_fake_out = D(fake_samples)
# G的损失:希望D把假样本判1
g_loss = loss_fn(d_fake_out, real_labels)
# 更新G参数
opt_G.zero_grad()
g_loss.backward()
opt_G.step()
# ---------------------- 3. 打印训练进度(每50轮打印一次) ----------------------
if (epoch + 1) % 50 == 0:
print(f"第{epoch+1}轮 | D损失:{d_loss.item():.4f} | G损失:{g_loss.item():.4f}")
# ---------------------- 生成模拟病人样本(训练完GAN后) ----------------------
# 生成多少个:补到和健康样本数量差不多(比如原始病人80个,生成120个,凑200个)
num_generate = len(X_train[y_train == 0]) - len(X_train[y_train == 1])
# 生成随机噪声
noise = torch.randn(num_generate, NOISE_DIM)
# G生成模拟病人样本(转成numpy数组)
generated_patients = G(noise).detach().numpy()
print(f"\n=== GAN生成完成 ===")
print(f"生成的模拟病人样本数:{len(generated_patients)}")第五步:数据扩充 + 对比 F1 分数
核心:把 "原始健康样本 + 生成的病人样本" 组成新训练集,对比原始数据和扩充数据的 F1 分数。
代码段 4:评估 F1 分数
python
# ---------------------- 1. 构建扩充后的训练集 ----------------------
# 原始训练集:健康样本(y_train=0)
X_train_healthy = X_train[y_train == 0]
y_train_healthy = y_train[y_train == 0]
# 扩充后训练集:原始健康样本 + 生成的病人样本 + 原始病人样本
X_train_aug = np.concatenate([X_train_healthy, generated_patients, X_train_patient])
y_train_aug = np.concatenate([
y_train_healthy,
np.ones(len(generated_patients)), # 生成的样本标签=1
np.ones(len(X_train_patient)) # 原始病人标签=1
])
print("\n=== 扩充后训练集分布 ===")
print(f"健康样本数:{len(X_train_healthy)}")
print(f"病人样本数(原始+生成):{len(X_train_patient) + len(generated_patients)}")
# ---------------------- 2. 训练分类器并计算F1 ----------------------
# 定义简单的分类器(逻辑回归,零基础易理解)
clf = LogisticRegression(random_state=42)
# 情况1:不用GAN(原始数据训练)
clf.fit(X_train, y_train)
y_pred_original = clf.predict(X_test)
f1_original = f1_score(y_test, y_pred_original)
# 情况2:用GAN(扩充后数据训练)
clf.fit(X_train_aug, y_train_aug)
y_pred_aug = clf.predict(X_test)
f1_aug = f1_score(y_test, y_pred_aug)
# ---------------------- 3. 输出对比结果 ----------------------
print("\n=== F1分数对比 ===")
print(f"不用GAN的F1分数:{f1_original:.4f}")
print(f"用GAN的F1分数:{f1_aug:.4f}")
# 可视化对比(可选,更直观)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.bar(['不用GAN', '用GAN'], [f1_original, f1_aug], color=['red', 'green'])
plt.ylabel('F1分数')
plt.title('心脏病数据集F1分数对比(越高越好)')
plt.ylim(0, 1) # F1范围0~1
plt.show()第六步:Mac 下运行代码(关键!)
- 把上面所有代码段合并到
gan_heart.py文件中(按顺序拼接); - 打开终端 → 进入代码所在文件夹(比如
cd ~/Desktop/gan_heart_project); - 确保虚拟环境已激活(终端开头有
(gan_heart)); - 运行代码:

预期结果解释
- 原始数据的 F1 分数较低(比如 0.6~0.7),因为样本不平衡,分类器偏向多数类(健康人),容易漏判病人;
- 用 GAN 扩充后,F1 分数会提升(比如 0.75~0.85),因为病人样本变多,分类器能更好地识别病人;
- 如果 F1 提升不明显:可以调大
EPOCHS(比如 1000)或BATCH_SIZE(比如 16),或换更复杂的生成器 / 判别器结构。
零基础常见问题解决
- Mac 运行时提示 "找不到模块" :检查虚拟环境是否激活,重新安装对应库(比如
pip3 install pandas); - 数据下载失败 :Mac 换个网络(比如手机热点),或手动下载数据集(链接:https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data),放到代码同文件夹,修改加载代码为:
python
df = pd.read_csv("processed.cleveland.data", names=columns)- 内存不足 :把
BATCH_SIZE改小(比如 4),EPOCHS改小(比如 200); - PyTorch 报错:确保安装的是 Mac 版 PyTorch,重新执行安装命令:

核心知识点复用回顾
- GAN 思想:生成器(造病人样本)vs 判别器(辨真假病人样本),损失来自 "判别器判错" 或 "生成器骗不过";
- 生成器 / 判别器:生成器输入噪声输出假样本,判别器输入样本输出 0~1 判别结果;
- nn.Sequential:把线性层、LeakyReLU 按顺序打包,简化前向传播;
- LeakyReLU:在生成器 / 判别器中都用了,避免神经元失活,让 GAN 训练更稳定。