DeepAudit AI多智能体代码审计项目学习与解读(一)
DeepAudit是一个AI多智能体代码审计项目,截至2026.1.3日已在github斩获3.3k star,由于其特征为:多智能体+源码审计+自动化沙箱POC验证,我将其加入了我的学习计划,接下来我会基于这个项目去写一系列文章
项目地址:https://github.com/lintsinghua/DeepAudit
技术栈
后端(Python 3.11+)
- Web 框架:FastAPI + uvicorn
- 数据库:SQLAlchemy 2.0 + PostgreSQL + Redis
- AI 框架:LangChain + LangGraph + LiteLLM
- 向量数据库:ChromaDB
- 代码解析:tree-sitter + tree-sitter-languages
- 容器化:Docker SDK
- 安全工具:Semgrep、Bandit、Gitleaks、Safety、npm audit
前端(React 18+)
- 框架:React 18 + TypeScript 5.7+
- UI 库:Radix UI + shadcn/ui + TailwindCSS
- 路由:React Router
- 状态管理:Zustand(隐式使用)
- 图表:Recharts
- 国际化:i18next
项目结构
后端目录结构 (backend/)
app/ 目录
- app/api/ - API 接口定义,包含 v1 版本的 API 端点
- app/core/ - 核心配置和安全相关功能
- app/db/ - 数据库初始化、会话管理等
- app/models/ - 数据库模型定义
- app/schemas/ - Pydantic 数据验证模型
- app/services/ - 业务逻辑服务层
- app/services/agent/ - Multi-Agent 核心功能
- app/services/agent/agents/ - 四大智能体(Orchestrator、Recon、Analysis、Verification)
- app/services/agent/core/ - Agent 核心框架(状态管理、图控制器、注册表等)
- app/services/agent/tools/ - 各种工具(沙箱、检索、外部安全工具等)
- app/services/agent/knowledge/ - 知识库功能
- app/services/agent/prompts/ - 提示词模板
- app/services/agent/telemetry/ - 遥测和追踪功能
- app/services/rag/ - RAG(检索增强生成)系统
- app/services/rag/embeddings.py - 嵌入模型服务
- app/services/rag/retriever.py - 检索器
- app/services/rag/splitter.py - 代码切分器
- app/services/llm/ - LLM 服务封装
- app/services/report_generator.py - 报告生成服务
- app/services/agent/ - Multi-Agent 核心功能
- app/utils/ - 工具函数
前端目录结构 (frontend/)
src/ 目录
- src/app/ - 应用主入口和路由配置
- src/components/ - 可复用的UI组件库
- src/features/ - 特定功能模块组件
- src/hooks/ - 自定义 React hooks
- src/pages/ - 页面组件
- src/pages/AgentAudit/ - Agent 审计相关页面
- src/pages/prompt-manager/ - 提示词管理页面
- src/shared/ - 共享的功能模块和上下文
Docker 相关目录 (docker/)
docker/sandbox/ 目录
- docker/sandbox/Dockerfile - 沙箱环境 Docker 配置
- docker/sandbox/seccomp.json - 沙箱安全配置文件
- docker/sandbox/build.sh - 沙箱镜像构建脚本
文档目录 (docs/)
docs/ 目录
- docs/AGENT_AUDIT_ARCHITECTURE.md - Agent 审计架构文档
- docs/ARCHITECTURE.md - 系统架构文档
- docs/CONFIGURATION.md - 配置文档
- docs/DEPLOYMENT.md - 部署文档
- docs/LLM_PROVIDERS.md - LLM 提供商文档
- docs/images/ - 文档图片
规则目录 (rules/)
- rules/SeletItem.yml - 审计规则定义
脚本目录 (scripts/)
- 包含各种启动和配置脚本
Supabase 目录 (supabase/)
- supabase/migrations/full_schema.sql - Supabase 数据库模式
环境配置
- docker-compose.yml - Docker Compose 配置
- docker-compose.prod.yml - 生产环境 Docker Compose 配置
- backend/.env.example - 后端环境变量示例,可以配置LLM provider和api key
- frontend/.env.example - 前端环境变量示例
项目配置
- backend/pyproject.toml - Python 项目配置
- backend/requirements.txt - Python 依赖
- frontend/package.json - 前端项目配置
- frontend/pnpm-lock.yaml - 前端依赖锁定
部署
win11+docker+本地ollama
-
下载项目
git clone https://github.com/lintsinghua/DeepAudit.git cd DeepAudit -
复制
backend/env.example到backend/.env -
docker运行
docker compose up -d
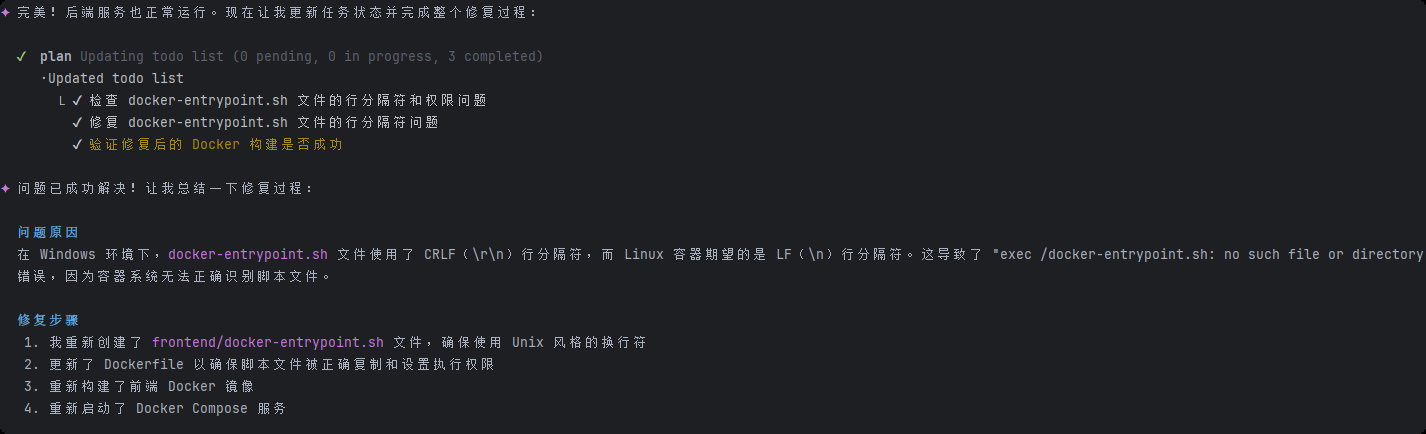
但是中途在frontend的容器启动出现了以下问题: frontend-1 | exec /docker-entrypoint.sh: no such file or directory frontend-1 | exec /docker-entrypoint.sh: no such file or directory frontend-1 | exec /docker-entrypoint.sh: no such file or directory frontend-1 | exec /docker-entrypoint.sh: no such file or directory frontend-1 | exec /docker-entrypoint.sh: no such file or directory
发现问题出现在:
frontend/docker-entrypoint.sh 文件在 Windows 环境下创建时使用了 CRLF(\r\n)行分隔符,而 Linux 容器中的 Nginx 镜像期望的是 Unix 风格的 LF(\n)行分隔符。这导致容器无法正确执行脚本,出现 "exec
/docker-entrypoint.sh: no such file or directory" 错误。
于是我让IFLOW CLI替我重新创建了 Unix 风格的docker-entrypoint.sh 文件
使用
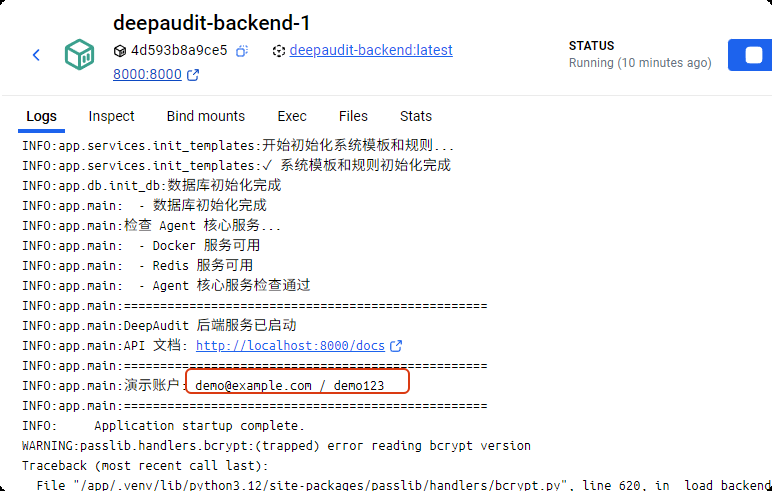
从backend容器的日志中得到用户名密码:
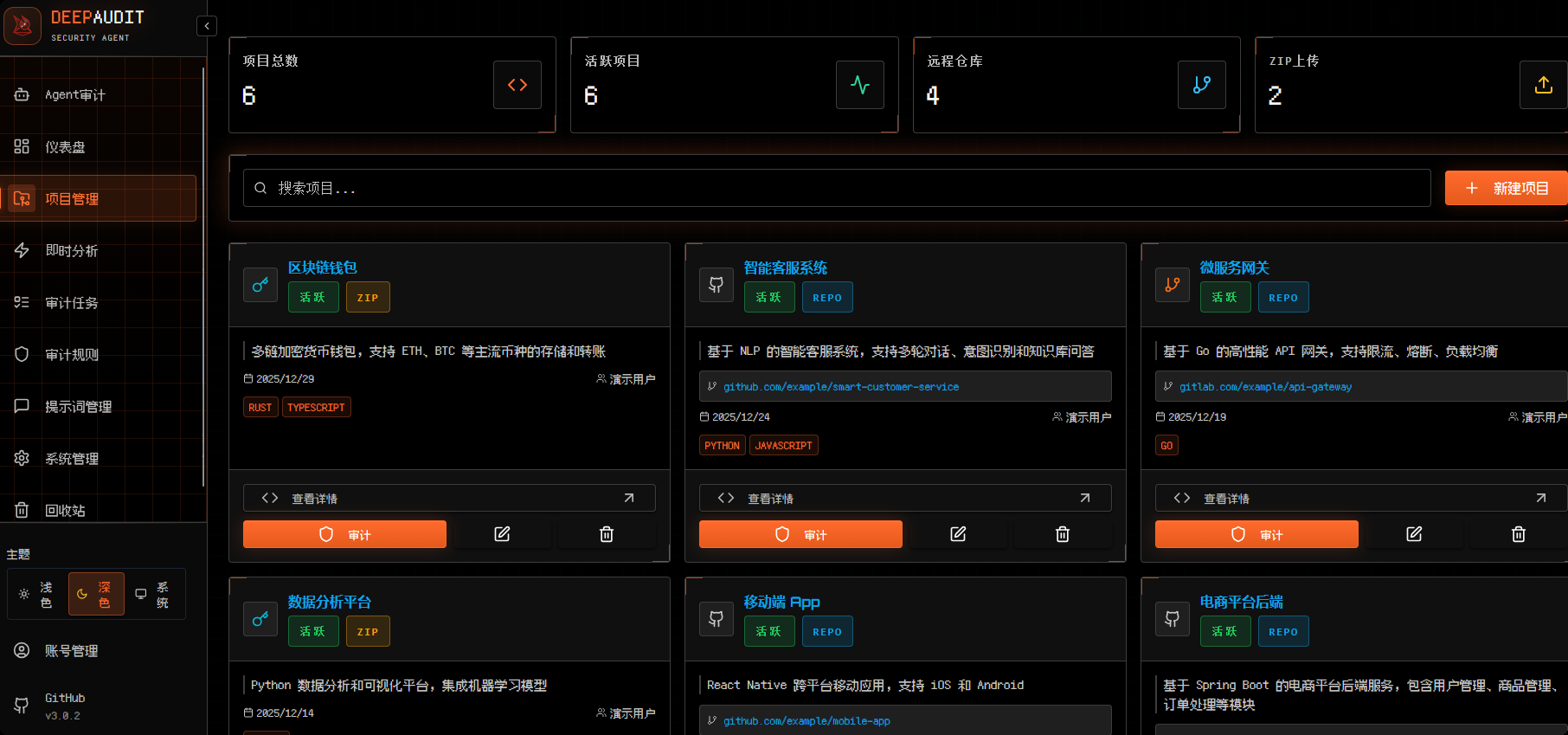
进入界面:
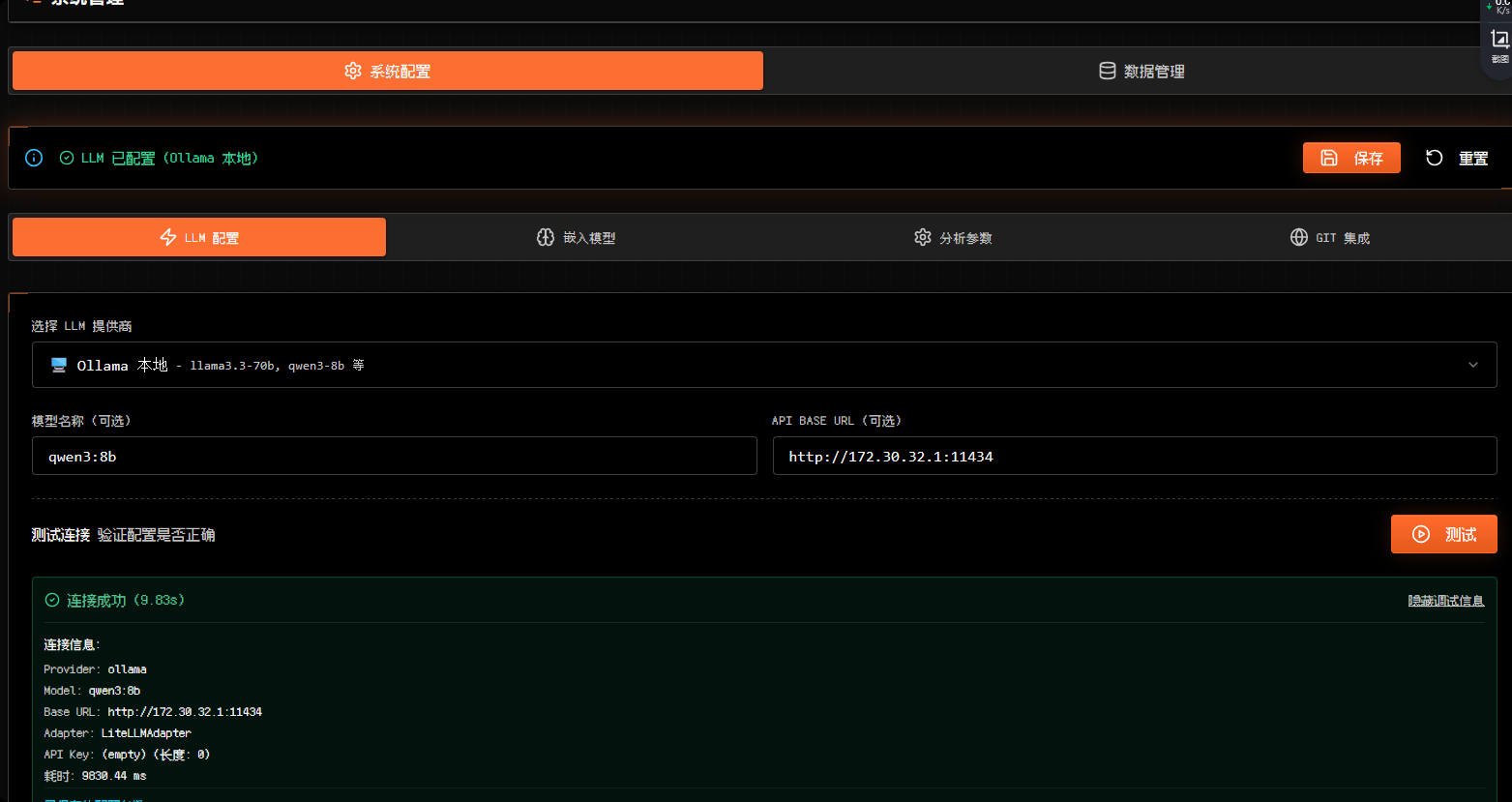
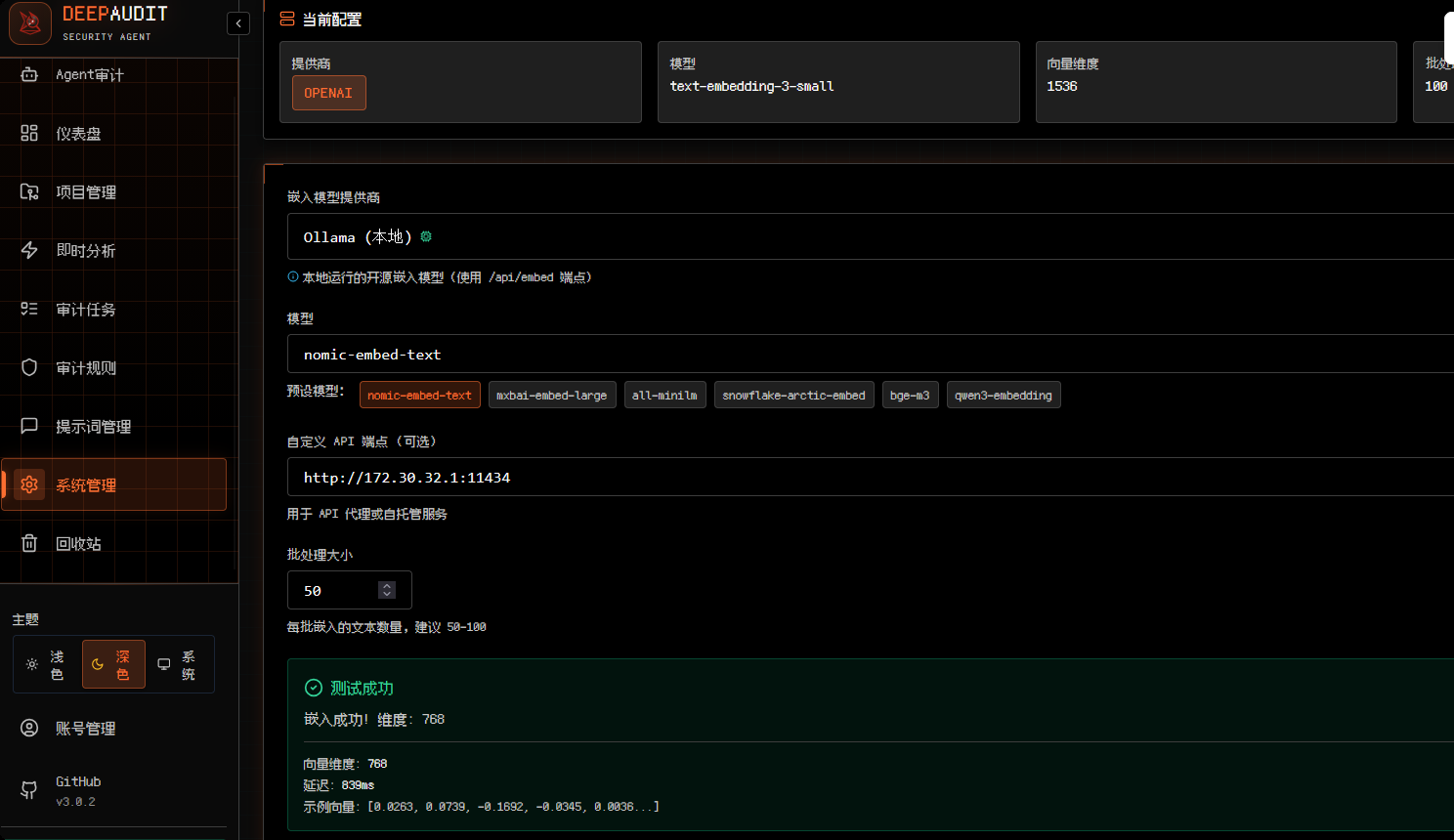
在系统管理页面设置LLM并测试连接(连接成功后注意保存):
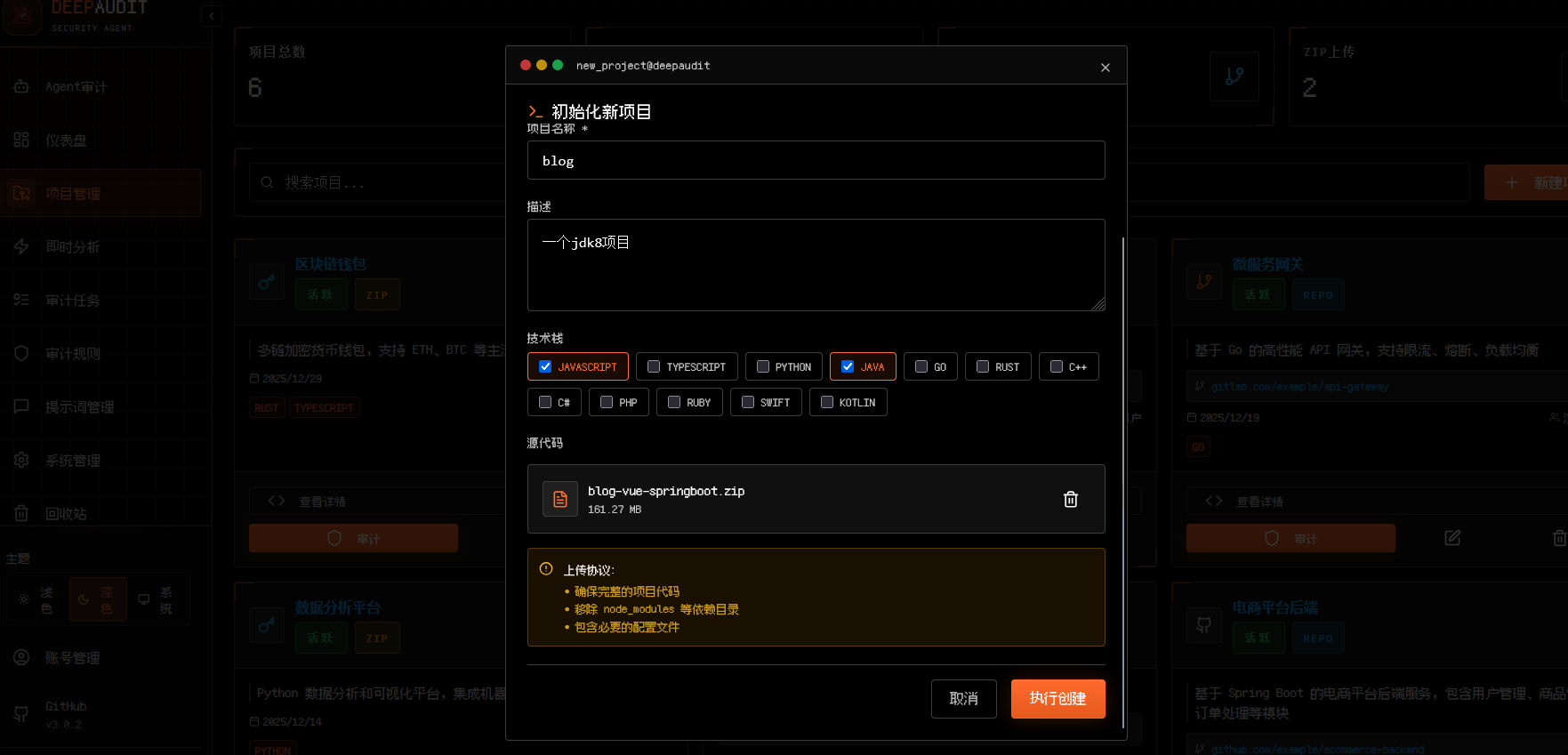
创建项目:
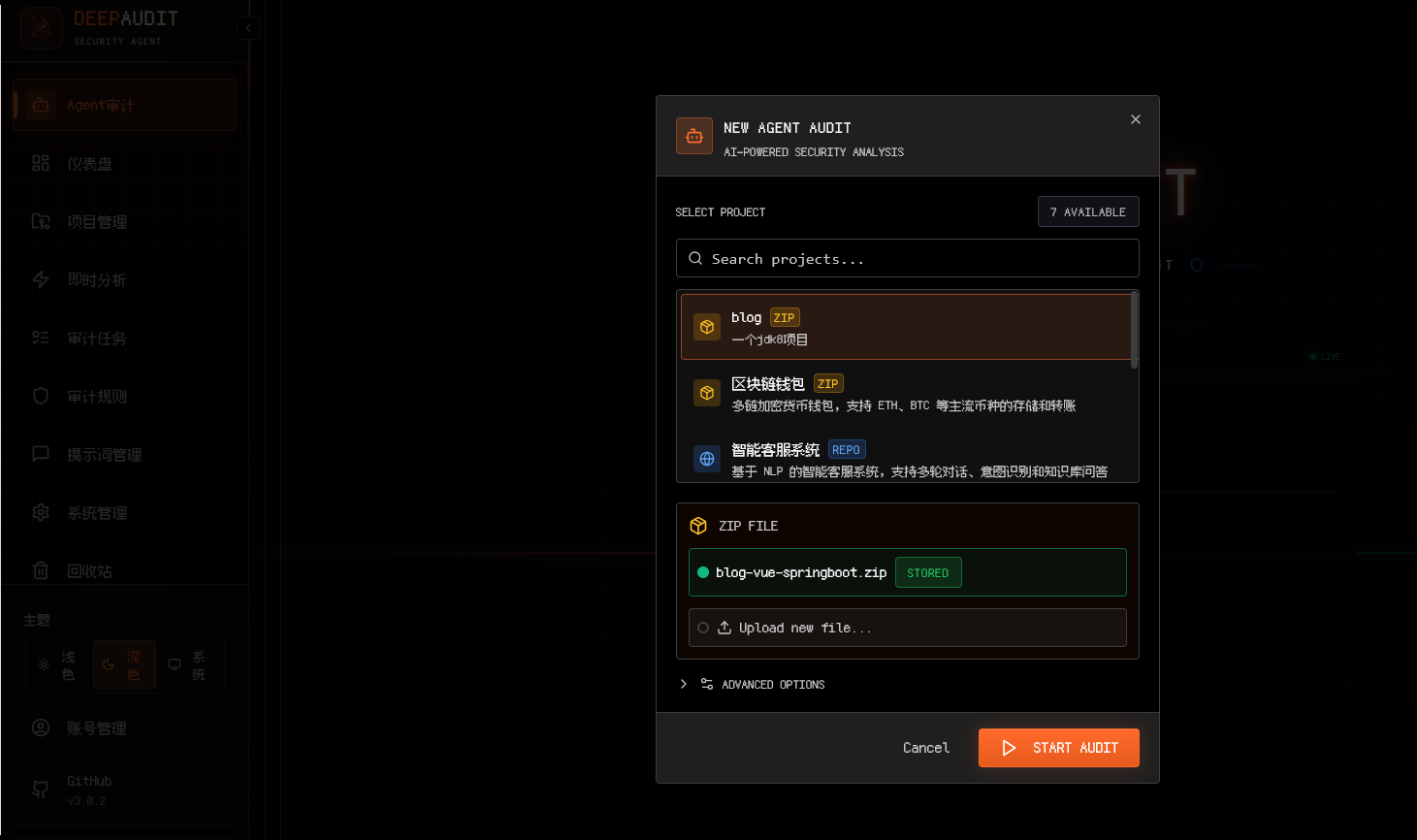
在Agent审计的输入框中输入audit然后选择项目进行初始化:
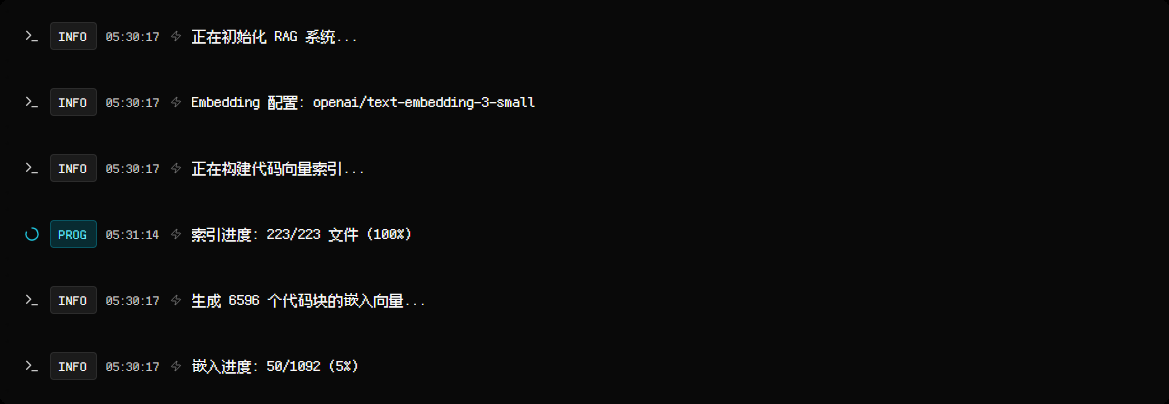
然后查看审计流程,流程如下:
-
初始化RAG系统
-
开始编排审计流程
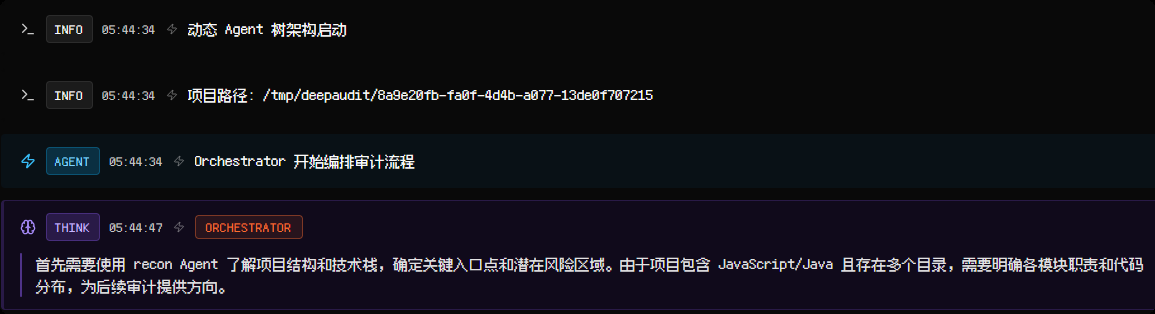
-
调度 recon Agent:
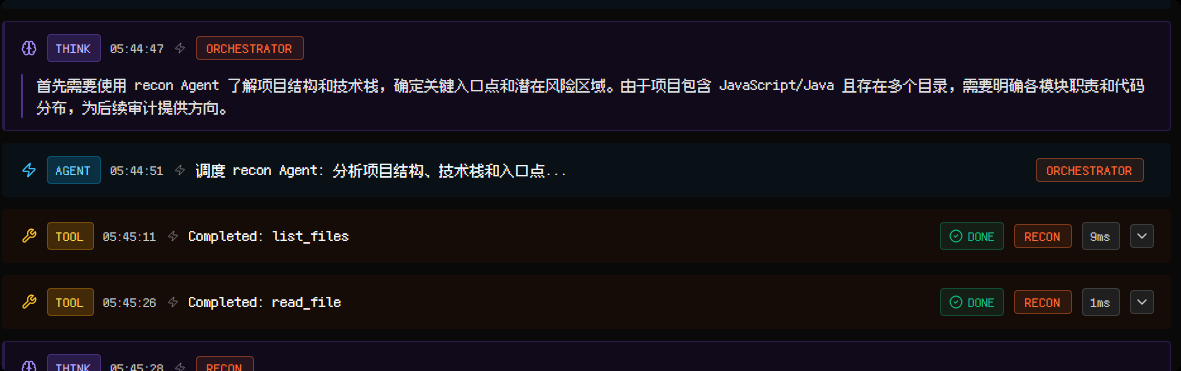
-
调度 analysis Agent
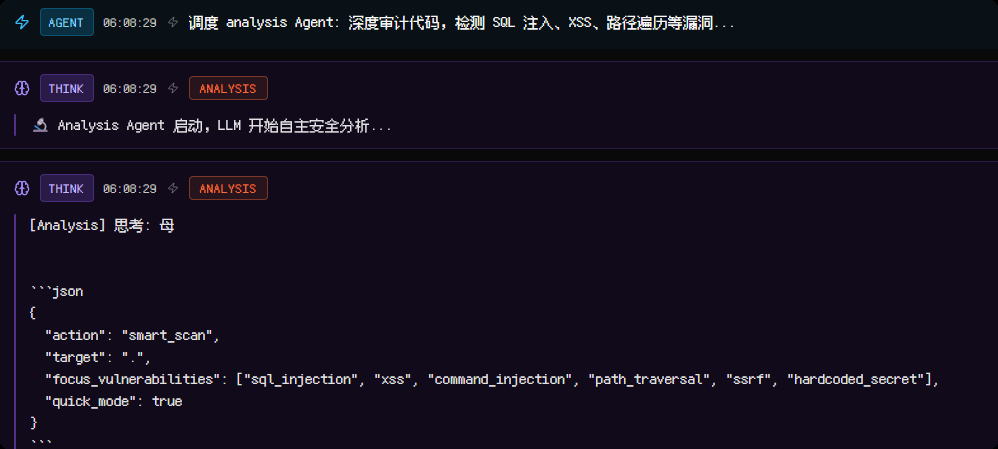
-
最后生成报告:
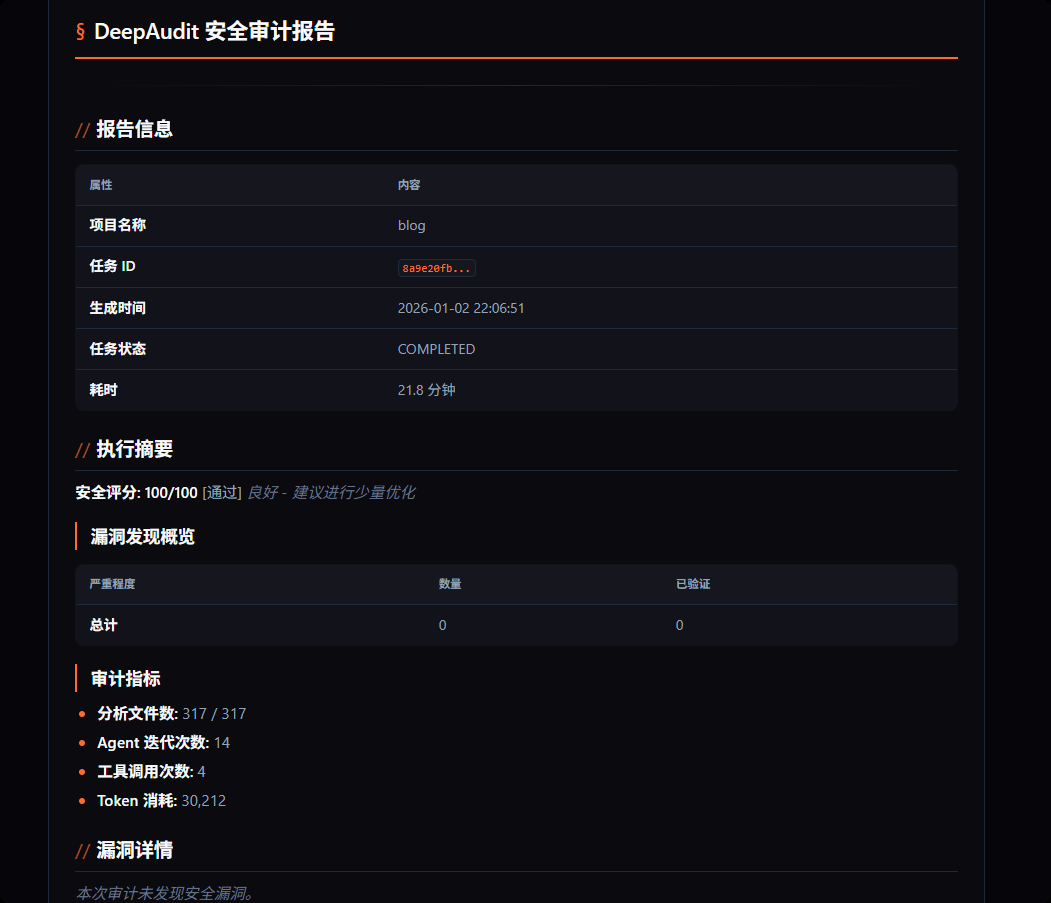
存在问题:
- 全程发现只调用了readfile 和listfile工具
- 这个项目我实际上通过污点分析工具发现至少是存在xss、文件上传、ip伪造的
- 项目中的配置文件也存在硬编码,也在Recon中发现了但实际上并没有报告这个问题,而且Recon进行依赖分析后得到的结果为空
尝试使用智谱AI的GLM-4.7进行测试:
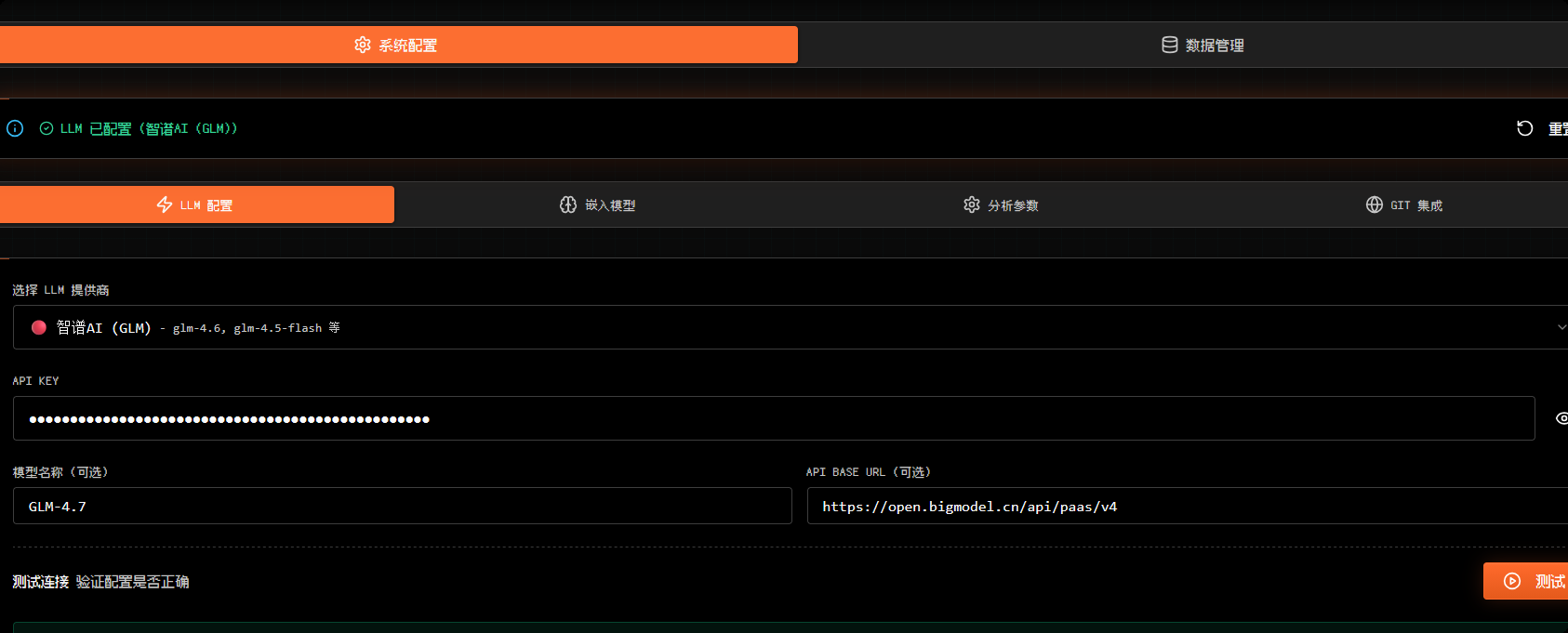
最后得到:
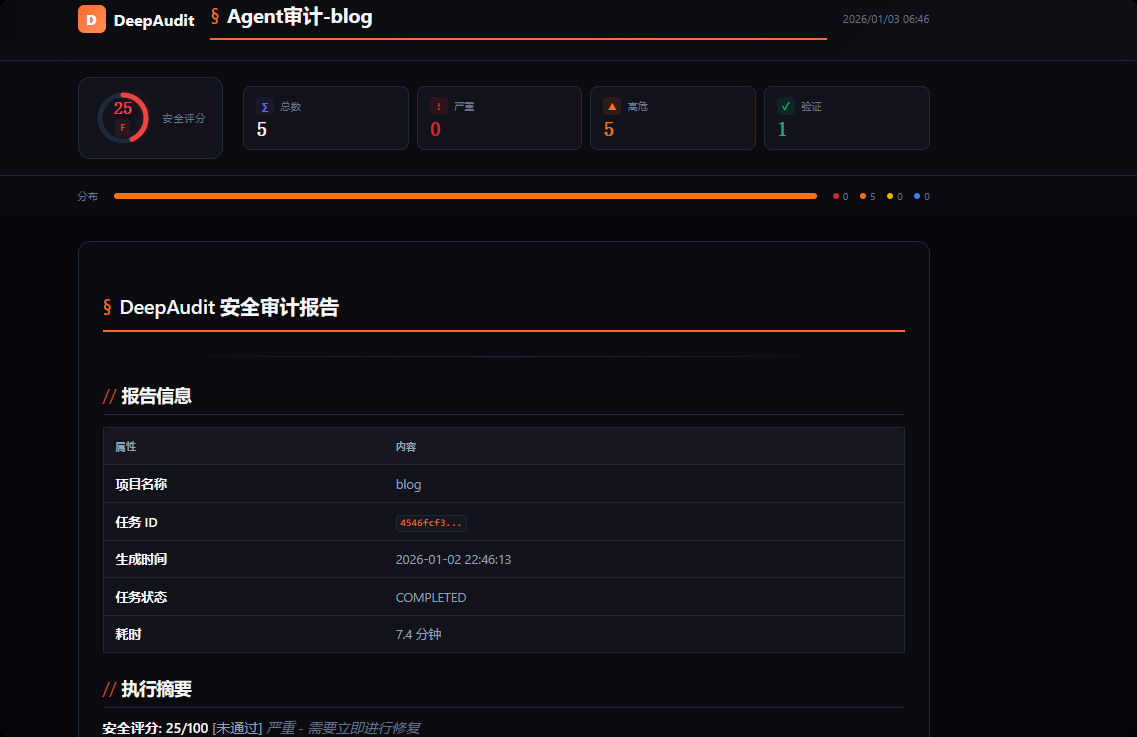
智谱AI消耗33万多的token
发现的5个漏洞经过手工验证,只有第一个是正确的,而这个恰好是DeepAudit自己经过验证的,另外四个均为未验证,并且其中两个被标记为误报,另外两个则需要自行验证(但置信度为仅60%)
成功的这个:
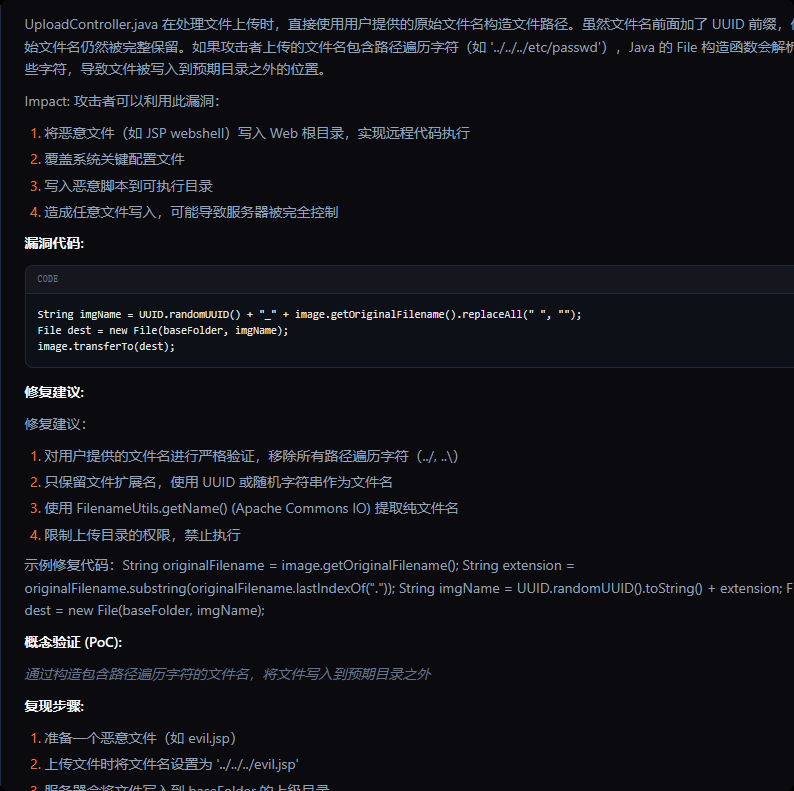
花费33万token仅发现这一个问题显然有问题,检查发现可能是某些工具没有正常得到结果,比如semgrep得到的结果为空,内部使用的提示词也比较简单
总结
目前看来,DeepAudit是非常值得学习的,也发现了一些问题,比如
- 工具也许没有正常调用导致agnet无法得到更细致的分析,需要深入学习代码
- 可能需要更好的大模型,不然难以正确调用工具
- 提示词可能比较简单
发现的优点:
- 不错的GUI
- 多agent编排+RAG+自动化沙箱验证
- 允许使用不同的LLM Provider和嵌入模型
基于该项目做二次开发也许会是一个不错的选择