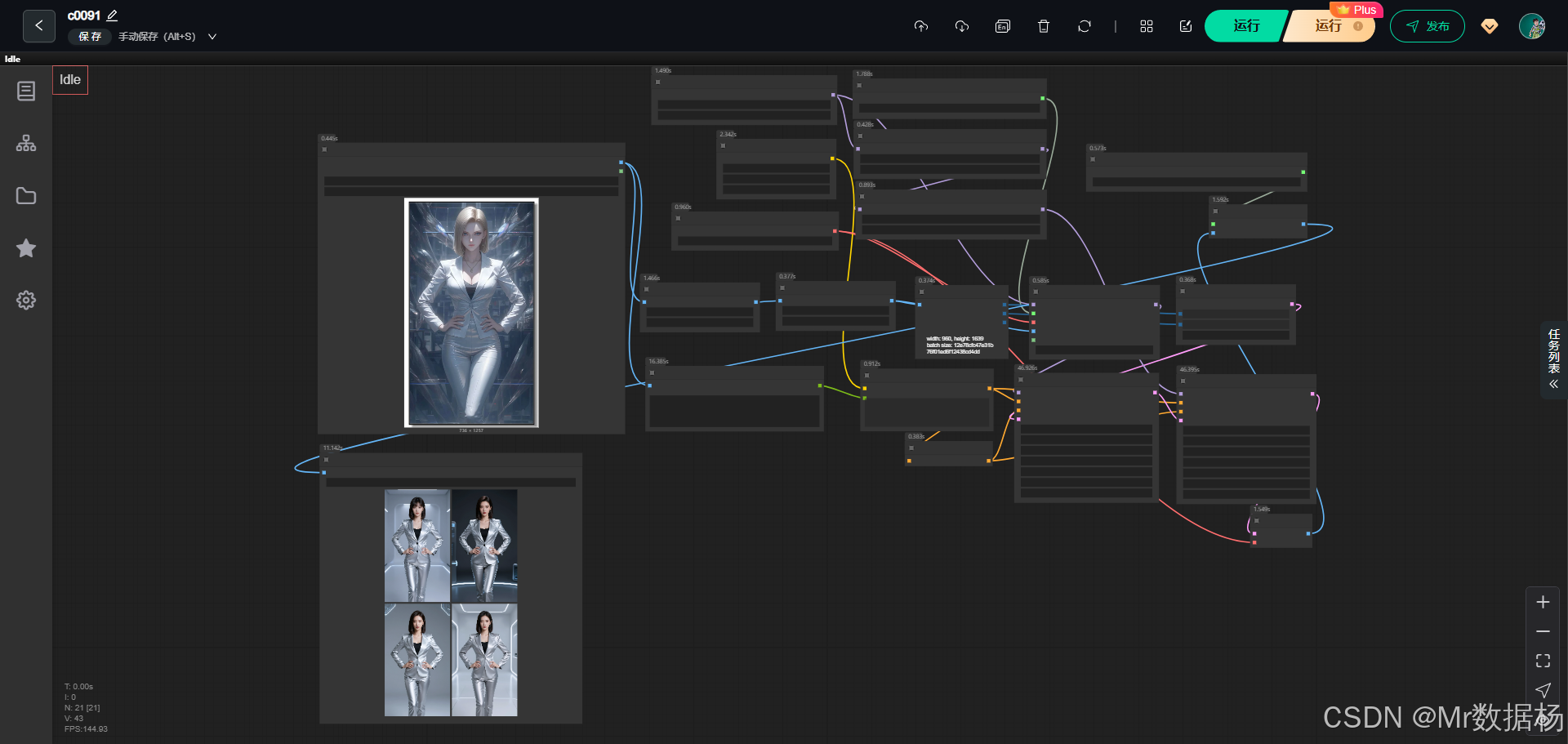
今天给大家演示一个基于 Z-Image-Turbo + Qwen Image + ControlNet 的 ComfyUI 综合工作流。该工作流以「参考图像驱动 + 自动图像理解 + 二次采样精修」为核心思路,通过对输入图片进行结构预处理、语义描述生成与模型联合控制,实现高一致性、高还原度的人像写真生成。

整体流程强调 参考图控制、姿态稳定、画面质感与分辨率输出,适合用于写真级重绘、姿态约束生成以及风格强化场景。结合最终效果图,可以直观看到该工作流在人物结构保持、细节塑造和整体画面稳定性上的优势。
文章目录
- 工作流介绍
-
- 核心模型
- [Node 节点](#Node 节点)
- 工作流程
- 大模型应用
-
- [RH_Captioner 图像语义理解与自动提示词生成](#RH_Captioner 图像语义理解与自动提示词生成)
- [CLIPTextEncode 文本语义条件编码](#CLIPTextEncode 文本语义条件编码)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该 ComfyUI 工作流围绕"参考图驱动的图像生成与精修"展开,整体结构由基础生成模型、图像理解模块、ControlNet 联合控制以及两阶段采样与放大输出组成。工作流先对输入参考图进行预处理和尺寸规范,再通过图像描述节点自动生成高质量文本提示词,配合 Qwen Image DiffSynth ControlNet 将图像结构信息注入模型推理过程。在模型层面,通过 UNet 主模型、模型补丁以及多组 LoRA 的叠加,实现对人物风格、姿态细节与写真质感的精确控制。最终结果经过二次采样与 AI 放大模型处理,输出清晰、可直接使用的高分辨率成图。
核心模型
该工作流的核心模型体系由 Z-Image-Turbo UNet 主模型、Qwen Image CLIP、VAE 解码器、模型补丁与多组 LoRA 共同构成。UNet 模型负责整体画面生成与推理效率,Qwen Image CLIP 提供对图像与文本的跨模态理解能力,使自动生成的描述能够准确参与采样控制。模型补丁用于扩展 Z-Image-Turbo 在 ControlNet 场景下的能力,而多组 LoRA 则进一步强化人物摄影风格与特定姿态表现,确保生成结果在风格与结构上的稳定性。
| 模型名称 | 说明 |
|---|---|
| z_image_turbo_bf16.safetensors | 工作流主 UNet 模型,负责核心图像生成与高速推理 |
| qwen_3_4b.safetensors | Qwen Image CLIP 模型,用于图像理解与文本编码 |
| ae.safetensors | VAE 模型,用于潜空间与图像空间的编码与解码 |
| Z-Image-Turbo-Fun-Controlnet-Union.safetensors | 模型补丁,用于增强 Z-Image-Turbo 的 ControlNet 能力 |
| Z-Image_妩媚写真摄影_v1.safetensors | 写真风格 LoRA,强化人物摄影质感 |
| kneestogetherZIT.safetensors | 姿态控制 LoRA,用于稳定人物下肢与整体姿态 |
| 2xNomosUni_span_multijpg_ldl.pth | AI 放大模型,用于最终图像分辨率提升 |
Node 节点
该工作流的节点设计以"图像输入 → 结构预处理 → 自动描述 → 联合控制 → 双阶段采样 → 放大输出"为主线。图像首先经过预处理与尺寸规范,确保输入稳定性;随后通过图像描述节点生成高质量提示词,减少人工 Prompt 成本。ControlNet 节点将参考图像结构注入模型推理流程,实现对构图与姿态的精确约束。两次 KSampler 采样分别用于基础生成与风格细化,最后通过 VAE 解码与超分节点输出高分辨率成图。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载参考图像,作为结构与语义输入 |
| AIO_Preprocessor | 对参考图进行结构预处理,为 ControlNet 提供输入 |
| ImageScaleToTotalPixels | 统一图像像素规模,提升生成稳定性 |
| GetImageSize | 获取图像宽高,用于潜空间尺寸控制 |
| RH_Captioner | 自动生成图像描述文本,用于正向提示词 |
| CLIPTextEncode | 将文本描述编码为模型可用的条件信息 |
| QwenImageDiffsynthControlnet | 将参考图结构信息注入模型推理 |
| KSampler | 两阶段采样,分别用于基础生成与精修 |
| VAEDecode | 将潜空间结果解码为图像 |
| ImageUpscaleWithModel | 使用 AI 放大模型提升最终分辨率 |
| SaveImage | 保存最终生成结果 |
工作流程
该工作流的整体流程以"参考图驱动 → 语义理解 → 结构控制 → 分阶段生成 → 高清输出"为核心逻辑展开。流程从参考图像输入开始,通过预处理与尺寸统一保证后续推理的稳定性;随后利用图像理解节点自动生成高质量文本描述,将视觉信息转化为可控的语义条件。在模型推理阶段,参考图的结构信息通过 ControlNet 注入到 Z-Image-Turbo 模型中,并结合 LoRA 对人物风格与姿态进行约束。生成过程采用两阶段采样方式,第一阶段完成整体画面构建,第二阶段在保留结构的前提下进一步细化细节。最终结果经 VAE 解码与 AI 超分模型处理,输出清晰、可直接使用的高分辨率成图。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 参考图输入 | 加载用户提供的参考图像,作为结构与语义基础 | LoadImage |
| 2 | 图像预处理 | 对参考图进行结构提取与像素统一,提升控制精度 | AIO_Preprocessor、ImageScaleToTotalPixels |
| 3 | 尺寸解析 | 获取图像宽高,用于潜空间尺寸匹配 | GetImageSize |
| 4 | 语义生成 | 自动生成图像描述文本,减少人工 Prompt 依赖 | RH_Captioner |
| 5 | 文本编码 | 将描述文本编码为模型可用的条件信息 | CLIPTextEncode |
| 6 | 结构控制 | 将参考图结构注入模型,实现姿态与构图约束 | QwenImageDiffsynthControlnet |
| 7 | 初次采样 | 基于参考结构与语义完成基础画面生成 | KSampler |
| 8 | 精修采样 | 在保持结构的前提下强化风格与细节 | KSampler |
| 9 | 图像解码 | 将潜空间结果转换为可视图像 | VAEDecode |
| 10 | 分辨率提升 | 使用 AI 放大模型输出高分辨率结果 | ImageUpscaleWithModel |
| 11 | 成果保存 | 保存最终生成图像 | SaveImage |
大模型应用
RH_Captioner 图像语义理解与自动提示词生成
该节点承担的是图像到语言的语义转换任务,属于典型的多模态大模型应用。它会对输入的参考图像进行整体理解,从人物外观、服饰、姿态、场景到画面氛围进行综合分析,并生成一段结构完整、语义明确的文字描述。这段描述本身就是后续图像生成中最核心的 Prompt 来源,用于约束生成内容的语义方向、风格倾向与细节密度。通过合理设计 Prompt 指令文本,可以显著影响模型输出的描述精度、细节丰富度以及是否偏向写真、写实或艺术风格。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| RH_Captioner | 请提供此图像的详细说明。 如果您熟悉图像中的任何角色,如名人、电影角色或动画人物,请直接使用他们的名字。 描述应尽可能详细,但不应超过200字。 | 通过明确的提示词约束大模型生成高质量图像描述,为后续生成提供稳定、可控的语义输入 |
CLIPTextEncode 文本语义条件编码
该节点负责将文本 Prompt 转换为模型可理解的条件向量,是 Prompt 真正参与图像生成的入口。它本身不生成内容,但对 Prompt 的语义结构、描述精度和风格信息极为敏感。由 RH_Captioner 输出的文本会在这里被完整编码,并直接影响人物形象、画面风格与细节表现。Prompt 越清晰、越具体,编码后的语义约束就越稳定,生成结果也越接近预期。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode | (由 RH_Captioner 自动生成的图像描述文本) | 将自然语言 Prompt 转换为生成模型可用的条件信息,决定最终画面的语义与风格走向 |
使用方法
该工作流的运行逻辑是以参考图像为核心驱动输入,通过自动语义理解与结构控制完成完整的图像生成流程。用户只需替换参考图片,工作流便会自动完成图像预处理、内容理解、Prompt 生成、结构注入、分阶段采样与高清输出。参考图既承担了角色外观与姿态的来源,也作为语义理解的输入;自动生成的 Prompt 则负责描述人物细节、服装特征与整体风格,无需用户手动编写复杂文本。整个流程强调"换图即用",适合反复测试不同素材并保持稳定输出效果。
| 注意点 | 说明 |
|---|---|
| 参考图质量 | 建议使用主体清晰、姿态完整的图片,以提升结构控制与语义识别效果 |
| Prompt 指令修改 | 可在 RH_Captioner 中调整描述指令,控制生成文本的细节程度与风格倾向 |
| LoRA 强度 | 人物风格与姿态 LoRA 叠加较多时,注意避免强度过高导致画面失真 |
| 分辨率比例 | 输入图像比例会影响最终构图,尽量避免极端长宽比 |
| 批量生成 | 修改批量参数前建议先单张测试,确认结构与风格稳定性 |
应用场景
该工作流适用于对人物结构一致性、姿态控制与画面质量要求较高的图像生成场景。由于其结合了参考图结构控制、自动语义生成以及多模型协同推理的特点,既能降低使用门槛,又能保证输出结果的稳定性与可控性。无论是写真级重绘、姿态复刻,还是基于参考图的风格化再创作,都可以在该流程中获得可靠的效果输出,尤其适合追求高质量、可复用生产流程的创作者与商业用户。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 写真重绘 | 保持人物结构的前提下提升画面质感 | 写真创作者、AI 摄影用户 | 人物写真、半身或全身照 | 高一致性、高质感重绘 |
| 姿态复刻 | 精准还原参考图中的人物姿态 | 插画师、姿态研究用户 | 特定站姿、坐姿、动作参考 | 姿态稳定、不易崩坏 |
| 风格化生成 | 在固定结构上叠加特定摄影或艺术风格 | 设计师、内容创作者 | 风格写真、主题人像 | 风格统一、细节丰富 |
| 商业内容制作 | 快速生成可交付的高分辨率图片 | 商业设计、营销团队 | 宣传图、人像素材 | 输出稳定、可直接商用 |
| AI 流水线生产 | 构建标准化、高复用的生成流程 | 工作室、批量生产用户 | 批量人物图像 | 效果一致、效率高 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用