继去年 Streaming Lakehouse Meetup 顺利举办后,Streaming Lakehouse Meetup · Online EP.2|Paimon × StarRocks 共话实时湖仓 于12月10日重磅回归。在这场直播中,阿里云计算平台事业部开发工程师张庆玉聚焦 StarRocks 与 Apache Paimon 的深度集成实践,探讨如何构建真正意义上的 Lakehouse Native 数据引擎。
在数据湖已成为企业数字化转型重要基础设施的当下,如何在一个统一的计算引擎中高效处理多种数据源,成为业界关注的焦点。StarRocks 通过与 Paimon 的深度融合,正逐步构建一套完整的 Lakehouse Native 解决方案------不仅支持多源联邦分析,更在性能、功能与可观测性上实现系统性突破。
StarRocks 数据湖总体架构:单一引擎,多源联邦分析
StarRocks 与 Paimon 的结合,首先体现在统一的架构设计理念上。借助统一的 Catalog 机制,StarRocks 能够在一个引擎内同时管理内部表和外部数据湖(如 Paimon 表),并支持跨 Catalog 的联邦查询。
这种设计延续了 StarRocks 存算分离的核心思想。虽然数据存储在远端的数据湖中,但查询执行仍能充分利用 StarRocks 在 OLAP 场景下的全部优化能力------从底层的 CPU 指令集加速、向量化执行引擎,到 IO 层面的缓存策略与合并读取,都可无缝应用于 Paimon 表的查询过程。这使得数据湖不再只是"冷存储",而真正成为高性能分析的一部分。 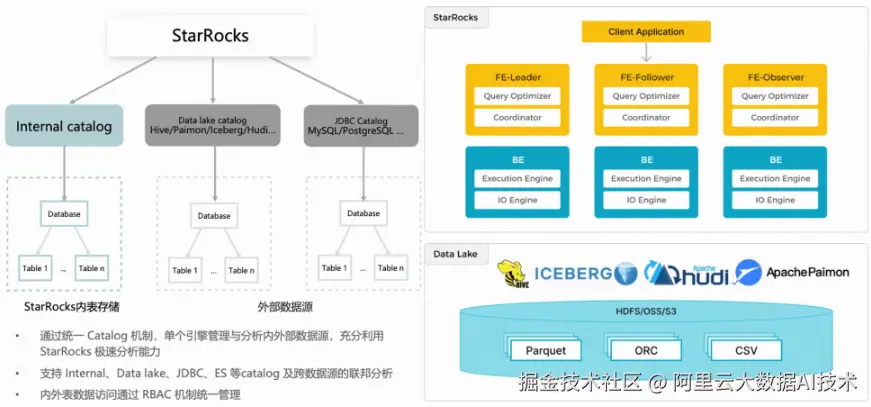
StarRocks+Paimon 发展历程
StarRocks 对 Paimon 的支持并非一蹴而就,而是经历了多个版本的持续打磨。
-
StarRocks 3.1: 首次引入 Paimon 外表,通过 JNI (Java Native Interface)实现基本读取能力,并支持 Paimon 物化视图加速查询和谓词下推。这一阶段主要解决"能不能用"的问题。
-
StarRocks 3.2: 性能迎来显著提升------ FE 计划阶段引入 Metadata cache,缓存表分区和 manifests 等元数据,大幅加快计划生成;同时支持表级与列级统计信息采集,提升执行计划质量。3.2 版本还实现了物化视图的分区级别刷新功能,避免了全量刷新带来的资源浪费。此外,该版本进一步增强了对 Paimon DV 表的支持------StarRocks 查询引擎现在可以通过 Native Reader 直接读取 DV 表,相比之前基于 MOR(Merge-On-Read)表结构的 JNI 读取实现,读取性能获得大幅提升,尤其适用于高吞吐、低延迟的实时分析场景。
-
StarRocks 3.3: 标志着 StarRocks 向 Lakehouse Native 迈出关键一步,多项核心特性相继落地------相关细节将在下文逐一展开。
StarRocks+Paimon 最新进展
功能增强
- Time Travel :StarRocks 现已支持通过
VERSION AS OF或TIMESTAMP AS OF查询历史快照或指定时刻的数据。这一能力在数据审计、故障回滚、AB Test 等场景中具有重要价值,让数据湖具备了更强的时间维度管理能力。

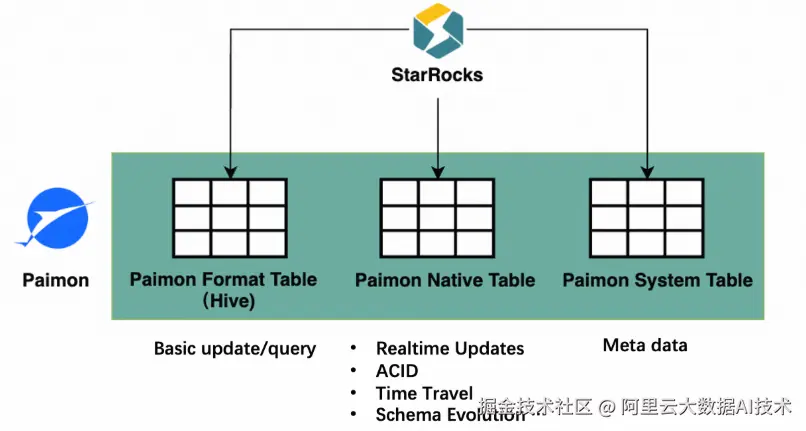
- Paimon Format Table:作为 Paimon 的一种兼容 Hive 格式的表类型,它允许用户将现有 Hive 表直接迁移到 Paimon,而 StarRocks 能无缝识别并高效查询,极大降低了迁移成本。
性能优化
-
Native Reader/Writer : 在未开启 DV 的情况下,MOR 表需要在查询时实时合并多个版本的增量数据,只能通过 JNI 调用 Java 层处理,存在类型转换、行列格式转换、JVM GC 等开销,效率低下且易引发 OOM。如今,StarRocks 基于 Paimon CPP SDK,在 BE 的 C++ 代码中直接实现 Paimon Native Scanner,实测显示 MOR 表读取性能提升超过 5 倍。写入侧同样受益,Native Writer 显著提升了写入吞吐。
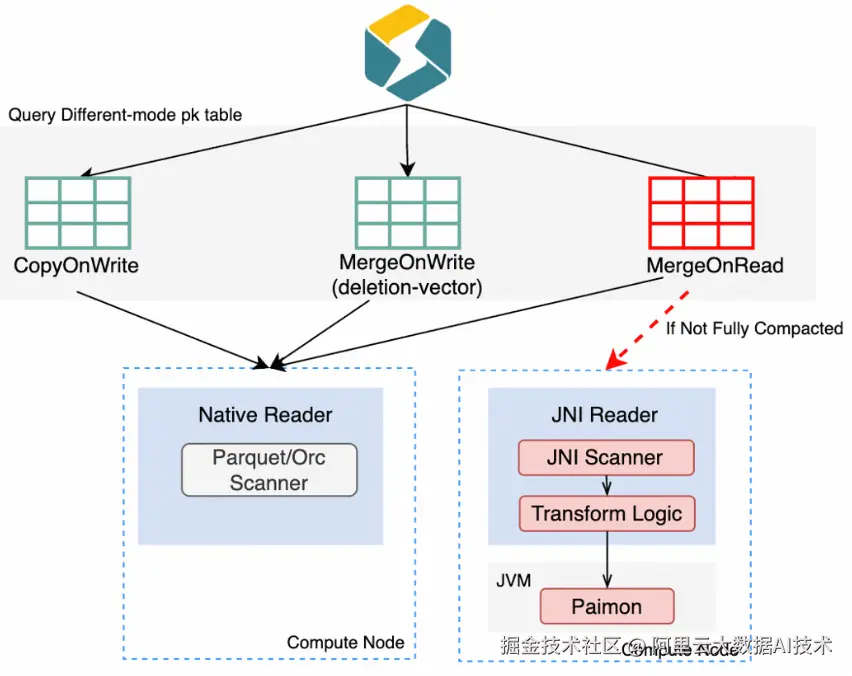
Paimon Native Reader

Paimon Native Writer
-
Distributed Plan : 面对超大规模表(数十万文件),manifest 解析曾是 FE 的性能瓶颈。为此,StarRocks 引入 Distributed Plan 机制,当 manifest 数量过多时,FE 将解析任务分发至多个 CN 节点并行执行,各节点完成本地谓词下推后返回所需文件列表。这一设计使 plan 阶段的解析能力随 BE 资源线性扩展,有效缓解单点压力。
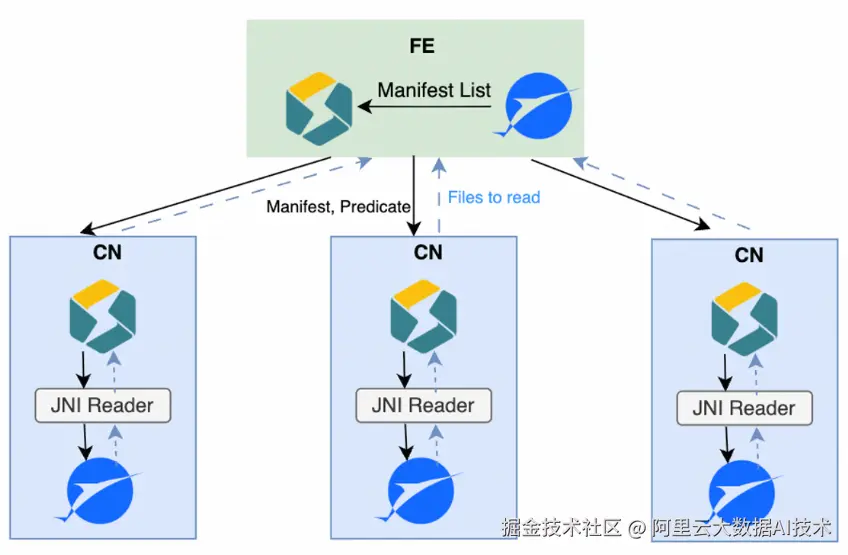
-
DV Index Cache : 在高并发查询 Paimon 主键表时,index manifest 的全局反序列化会造成严重读放大------即使只查一个分桶,也要加载全量索引。于是,DV Index Cache 应运而生:按桶级别缓存 DV index 对象,避免重复解析。由于缓存的是 Java 对象而非序列化字节,还省去了反序列化开销。实测表明,该优化在高并发场景下 QPS 提升超 80%。
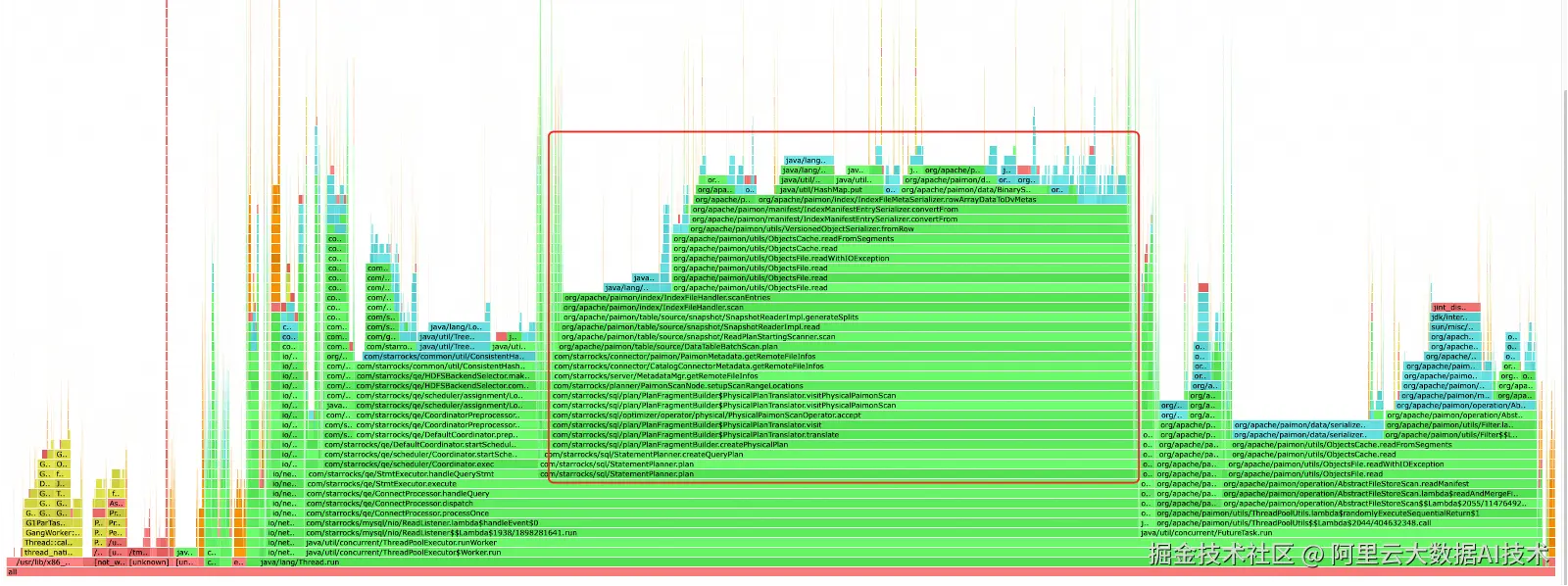
主键表点查在高并发下导致 FE CPU 和内存负载过高,主要因 Plan 阶段频繁从缓存读取 index manifest
可观测性:完善profile指标
StarRocks 完善了 Profile 指标体系,覆盖 plan 与执行两个阶段。在 plan 阶段,用户可查看 manifest 缓存命中率、远程读次数、谓词下推效果及最终扫描文件数,用于判断是否需调大缓存或优化查询条件。在 BE 执行阶段,则能清晰区分 JNI 与 native 读取的比例------若 JNI 占比较高,可能提示需要对表进行 full compaction,或考虑切换至 DV 表模式。

未来规划:性能对齐内表
StarRocks 团队的长期目标很明确:让查询 Paimon 的性能与体验对齐查询 StarRocks 本地表。
目前,BE 执行层的差距已不大------两者均基于列存格式(如 Parquet/ORC),具备类似索引结构,IO 优化策略也高度通用。真正的挑战在于 FE 的 plan 阶段:Paimon 的 manifest 解析可能因 cache miss 触发高延迟的远程读,导致 plan 耗时波动,影响整体查询稳定性。
未来工作将聚焦于消除 plan 阶段的 latency-sensitive IO,通过更智能的缓存预热、异步解析、元数据压缩等手段,使 Paimon 查询的延迟变得稳定、可预测,彻底告别"毛刺"。
结语
StarRocks 与 Paimon 的深度融合,代表了现代湖仓架构的重要演进方向。它不只是"能查数据湖",而是真正"懂数据湖"------从架构统一、功能完善到性能极致优化,每一步都围绕真实业务场景展开。
这套 Lakehouse Native 方案已在阿里集团内部多个高并发、低延迟场景中落地验证,为电商、物流、金融等业务提供坚实支撑。随着社区生态的持续壮大,我们有理由相信,StarRocks + Paimon 将成为企业构建下一代实时数据平台的核心引擎。