目录
[Mysql 有哪些数据引擎 之间的区别是什么](#Mysql 有哪些数据引擎 之间的区别是什么)
[讲一讲自己对 redis 的理解,key 太多会造成什么影响](#讲一讲自己对 redis 的理解,key 太多会造成什么影响)
[讲讲常见的异常类 遇到异常我们应该怎么去处理](#讲讲常见的异常类 遇到异常我们应该怎么去处理)
[Mybatis 中@ 注解 #{} 和 {} 的核心区别](#{} 和 {} 的核心区别)
[Linux 常见命令](#Linux 常见命令)
[SpringCloud 分布式架构](#SpringCloud 分布式架构)
[线程池 核心参数 拒绝策略 工作队列](#线程池 核心参数 拒绝策略 工作队列)
[redis 数据类型](#redis 数据类型)
[ArrayList 的序列化与反序列化,长度为 10 但是如果只有 1 个元素,会全部序列化吗](#ArrayList 的序列化与反序列化,长度为 10 但是如果只有 1 个元素,会全部序列化吗)
[如何进行 数据库 调优](#如何进行 数据库 调优)
Mysql 有哪些数据引擎 之间的区别是什么
常见的数据引擎有 InnoDB MyISAM Memory
这三种存储引擎都支持表级的锁
Memory 相对简单 实用的也最少 基于内存 主要适用的场景是一些临时数据
最多的是 MyISAM 和 InnoDB 存储引擎
InnoDB 的文件结构是两部分 表结构 数据+索引合在一起的文件
MyISAM 的文件结构是三部分 表结构 数据 索引
MyISAM 主要适用于读密集型 InnoDB 主要适用于并发事务等复杂的数据库业务操作
InnoDB 相对于 MyISAM 增加了事务支持 行级锁 外键约束 MVCC 崩溃恢复等
讲一讲自己对 redis 的理解,key 太多会造成什么影响
基于内存的数据库
简单的键值对存储 速度极快 10 万 + QPS
使用 IO 多路复用 处理并发连接
多种类型数据结构
RDB 快照+AOF 日志 实现持久化
分布式环境支持 主从复制 哨兵 集群
Key 过多的影响
1. 内存占用增加
- 每个Key都有额外的元数据开销(dictEntry、redisObject等)
- 1亿个Key,元数据可能占用数GB内存
2. 遍历操作变慢
- KEYS * 命令会阻塞服务(生产禁用!)
- SCAN命令虽然是渐进式,但总耗时增加
3. 持久化影响
- RDB生成时间变长,fork阻塞增加
- AOF文件变大,重写耗时增加
4. 集群迁移变慢
- 槽位迁移数据量增大
5. 过期键处理
- 定期删除扫描效率降低
- 惰性删除可能积压大量过期键解决方案
// 1. 使用Hash代替多个String Key
// 不推荐
SET user:1:name "张三"
SET user:1:age "25"
// 推荐
HSET user:1 name "张三" age "25"
// 2. 合理设置过期时间,避免Key无限增长
// 3. 使用SCAN代替KEYS
// 4. 大Key拆分讲讲常见的异常类 遇到异常我们应该怎么去处理
分为系统级错误 Error 和异常 Exception
错误 都是系统层面的 如栈溢出 内存🇰🇵
异常 分为 检查性异常(SQL 语法异常 类未发现异常)和非检查性异常(空指针异常 非法类型转换异常)
Throwable
├── Error (系统级错误,不应捕获)
│ ├── OutOfMemoryError
│ ├── StackOverflowError
│ └── NoClassDefFoundError
│
└── Exception
├── RuntimeException (非检查异常)
│ ├── NullPointerException
│ ├── ArrayIndexOutOfBoundsException
│ ├── ClassCastException
│ ├── IllegalArgumentException
│ ├── NumberFormatException
│ └── ConcurrentModificationException
│
└── 检查异常 (必须处理)
├── IOException
├── SQLException
├── FileNotFoundException
└── ClassNotFoundException异常处理方法
精确捕获
捕获后记录日志 捕获后要抛出异常 不要吞掉异常
对于资源 IO 类操作 要尝试自动关闭资源
学会自定义异常和全局异常处理器
// 1. 精确捕获,不要捕获Exception
try {
// 业务代码
} catch (FileNotFoundException e) {
// 处理文件不存在
} catch (IOException e) {
// 处理IO异常
}
// 2. 不要吞掉异常
catch (Exception e) {
log.error("操作失败", e); // 记录日志
throw new BusinessException("业务异常", e); // 重新抛出
}
// 3. 使用try-with-resources
try (InputStream is = new FileInputStream("file")) {
// 自动关闭资源
}
// 4. 自定义业务异常
public class BusinessException extends RuntimeException {
private Integer code;
private String message;
}
// 5. 全局异常处理器(Spring)
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public Result handleBusinessException(BusinessException e) {
return Result.error(e.getCode(), e.getMessage());
}
}Mybatis 中@ 注解 #{} 和 ${} 的核心区别
#{} 是预编译的方式 每次产生语句的时候都是复用预编译语句
${} 是字符串拼接 因为是字符串拼接的原因 可能会导致 SQL 注入的风险
${} 并不是一无是处 有时候可以动态列名 如两个排序条件 有时候传一个 有时候传两个
示例
<!-- #{} 预编译方式 -->
<select id="findUser">
SELECT * FROM user WHERE id = #{id}
</select>
<!-- 实际执行: SELECT * FROM user WHERE id = ? -->
<!-- 参数绑定: PreparedStatement.setInt(1, 100) -->
<!-- ${} 字符串拼接 -->
<select id="findUser">
SELECT * FROM user WHERE id = ${id}
</select>
<!-- 实际执行: SELECT * FROM user WHERE id = 100 -->
<!-- ${} 合理使用场景 -->
<select id="findByColumn">
SELECT * FROM user
ORDER BY ${orderColumn} ${orderType}
</select>
<!-- 动态列名必须用${}, 但需要在代码中校验防止注入 -->${} 必须要在代码中校验防止 SQL 注入
// 在Mapper调用前校验参数
public List<User> findByColumn(String column) {
// 白名单校验
List<String> allowedColumns = Arrays.asList("id", "name", "create_time");
if (!allowedColumns.contains(column)) {
throw new IllegalArgumentException("非法列名");
}
return userMapper.findByColumn(column);
}Linux 常见命令
# ===== 文件操作 =====
ls -la # 列出文件详情
cd /path # 切换目录
cp -r src dst # 复制
mv src dst # 移动/重命名
rm -rf dir # 删除
mkdir -p a/b/c # 创建多级目录
cat/less/more # 查看文件
tail -f log # 实时查看日志
head -n 100 # 查看前100行
find / -name "*.log" # 查找文件
grep -rn "keyword" . # 搜索内容
# ===== 权限管理 =====
chmod 755 file # 修改权限
chown user:group file # 修改所属
# ===== 进程管理 =====
ps -ef | grep java # 查看进程
top # 系统监控
kill -9 PID # 强制终止
nohup java -jar xx.jar & # 后台运行
# ===== 网络相关 =====
netstat -tlnp # 查看端口
lsof -i:8080 # 查看端口占用
curl/wget # 网络请求
ping/telnet # 网络测试
# ===== 系统信息 =====
df -h # 磁盘空间
free -m # 内存使用
uname -a # 系统信息
# ===== 文本处理 =====
awk '{print $1}' file # 列处理
sed 's/old/new/g' file # 替换
sort | uniq -c # 排序去重统计
wc -l file # 统计行数
# ===== 压缩解压 =====
tar -zxvf file.tar.gz # 解压
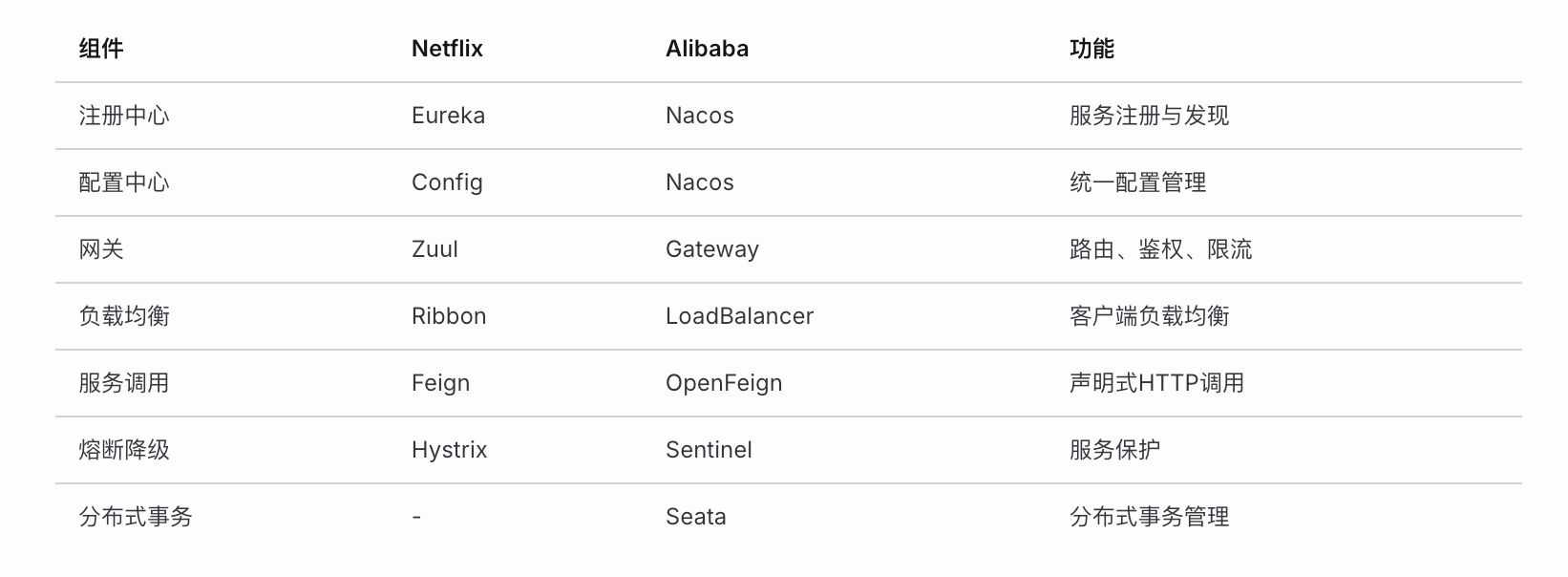
tar -zcvf file.tar.gz dir # 压缩SpringCloud 分布式架构
┌─────────────────────────────────────────────────────────────┐
│ SpringCloud 架构图 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ ┌─────────────────────────────────────┐ │
│ │ 客户端 │────▶│ Gateway 网关 │ │
│ └─────────┘ └──────────────┬──────────────────────┘ │
│ │ │
│ ┌─────────────▼─────────────┐ │
│ │ Nacos/Eureka 注册中心 │ │
│ └─────────────┬─────────────┘ │
│ │ │
│ ┌──────────┬──────────┬───────┴────┬──────────┐ │
│ ▼ ▼ ▼ ▼ ▼ │
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ │用户 │ │订单│ │商品│ │支付│ │库存│ │
│ │服务 │ │服务│ │服务│ │服务│ │服务│ │
│ └────┘ └────┘ └────┘ └────┘ └────┘ │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Nacos Config 配置中心 / Sentinel 熔断限流 │ │
│ │ Seata 分布式事务 / Sleuth+Zipkin 链路追踪 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
线程池 核心参数 拒绝策略 工作队列
七大核心参数
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数(常驻)
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 非核心线程空闲存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 工作队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)工作流程
任务提交
│
▼
┌───── 核心线程 < corePoolSize? ─────┐
│ 是 │ 否
▼ ▼
创建核心线程执行 ┌─── 工作队列未满? ───┐
│ 是 │ 否
▼ ▼
加入队列等待 ┌─ 当前线程 < maximumPoolSize? ─┐
│ 是 │ 否
▼ ▼
创建非核心线程 执行拒绝策略拒绝策略 常见的四种
// 1. AbortPolicy(默认): 直接抛出RejectedExecutionException
// 2. CallerRunsPolicy: 由调用线程执行任务(降级)
// 3. DiscardPolicy: 静默丢弃任务
// 4. DiscardOldestPolicy: 丢弃队列最老任务,重新提交
// 自定义拒绝策略
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 记录日志、持久化任务、发送告警等
log.warn("任务被拒绝: {}", r);
// 可以尝试重新入队或持久化
}
}工作队列
// 1. ArrayBlockingQueue: 有界数组队列(推荐)
// 2. LinkedBlockingQueue: 无界链表队列(慎用,可能OOM)
// 3. SynchronousQueue: 不存储元素,直接传递(CachedThreadPool使用)
// 4. PriorityBlockingQueue: 优先级队列
// 5. DelayQueue: 延迟队列redis 数据类型
5 种基本数据类型
4 种特殊数据类型
┌──────────────┬─────────────────┬────────────────────────────┐
│ 数据类型 │ 底层结构 │ 应用场景 │
├──────────────┼─────────────────┼────────────────────────────┤
│ String │ SDS/int/embstr │ 缓存、计数器、分布式锁 │
│ Hash │ ziplist/hashtable│ 对象存储、购物车 │
│ List │ quicklist │ 消息队列、最新列表 │
│ Set │ intset/hashtable│ 标签、共同好友、抽奖 │
│ ZSet │ ziplist/skiplist│ 排行榜、延迟队列 │
├──────────────┼─────────────────┼────────────────────────────┤
│ Bitmap │ String │ 签到、在线状态、布隆过滤器 │
│ HyperLogLog│ String │ UV统计(基数统计) │
│ GEO │ ZSet │ 地理位置、附近的人 │
│ Stream │ Radix Tree │ 消息队列(5.0+) │
└──────────────┴─────────────────┴────────────────────────────┘ArrayList 的序列化与反序列化,长度为 10 但是如果只有 1 个元素,会全部序列化吗
核心机制
public class ArrayList<E> implements Serializable {
// 注意: transient 修饰,不会被默认序列化!
transient Object[] elementData;
private int size; // 实际元素个数
// 自定义序列化方法
private void writeObject(ObjectOutputStream s) throws IOException {
s.defaultWriteObject();
// 只序列化实际元素个数
s.writeInt(size);
// 只写入有效元素(0 到 size-1)
for (int i = 0; i < size; i++) {
s.writeObject(elementData[i]);
}
}
private void readObject(ObjectInputStream s) throws IOException {
s.defaultReadObject();
int size = s.readInt();
// 只读取实际存储的元素
for (int i = 0; i < size; i++) {
elementData[i] = s.readObject();
}
}
}分析问题
问: 长度为10但只有1个元素,会全部序列化吗?
答: 不会!
┌──────────────────────────────────────────────────────┐
│ elementData 数组 (capacity = 10) │
│ ┌────┬────┬────┬────┬────┬────┬────┬────┬────┬────┐│
│ │ A │null│null│null│null│null│null│null│null│null││
│ └────┴────┴────┴────┴────┴────┴────┴────┴────┴────┘│
│ ↑ │
│ size = 1 │
│ │
│ 序列化时只写入 elementData[0] 这一个元素 │
│ capacity 信息不会被序列化 │
└──────────────────────────────────────────────────────┘
原因:
1. elementData 被 transient 修饰
2. ArrayList 重写了 writeObject/readObject
3. 只序列化 0 到 size-1 的元素
4. 节省空间,避免序列化无用的 null如何进行 数据库 调优
由低到高分为五个层次
SQL 语句优化 -> 索引优化 -> 表结构优化 -> 缓存优化 -> 架构优化
首先是 SQL 语句优化
我们可以通过 EXPLAIN 分析 SQL 语句的执行计划
EXPLAIN SELECT * FROM user WHERE name = '张三';可以看到
-- 重点关注字段
┌────────────┬─────────────────────────────────────────┐
│ 字段 │ 说明 │
├────────────┼─────────────────────────────────────────┤
│ type │ 访问类型,从好到差: │
│ │ system > const > eq_ref > ref > │
│ │ range > index > ALL │
│ key │ 实际使用的索引 │
│ rows │ 预估扫描行数 │
│ Extra │ Using index(覆盖索引) │
│ │ Using filesort(需优化) │
│ │ Using temporary(需优化) │
└────────────┴─────────────────────────────────────────┘同时我们可以开启慢查询日志
SHOW VARIABLES LIKE 'slow_query%';
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过1秒记录接着是合理索引
一张表创建三个索引
尽量是联合索引 根据 B+树的数据结构去创建 频繁查询的数据项放在前面
接着我们可以基于索引优化 避免索引失效 满足最左前缀匹配原则
现在 Mysql 存储引擎的索引数据结构基本都是 B+树
想一下 B+树 的结构
每个元素相对于局部有序 相较于全局无序
可以推出索引失效的场景
一种是结构上的模糊 如模糊查询 OR 条件 等
一种是在当前数据项进行了运算 如判断 聚合函数 数据转换等
-- ✅ 合理创建索引
CREATE INDEX idx_name ON user(name);
CREATE INDEX idx_composite ON orders(user_id, status, create_time);
-- ❌ 索引失效场景
SELECT * FROM user WHERE name LIKE '%张'; -- 左模糊
SELECT * FROM user WHERE YEAR(create_time) = 2024; -- 函数
SELECT * FROM user WHERE age + 1 = 20; -- 计算
SELECT * FROM user WHERE status != 1; -- 否定条件
SELECT * FROM user WHERE name = 123; -- 隐式转换
SELECT * FROM orders WHERE user_id = 1 OR status = 0; -- OR条件
-- ✅ 覆盖索引
SELECT id, name FROM user WHERE name = '张三'; -- 不回表
-- ✅ 最左前缀匹配
-- 索引 (a, b, c)
WHERE a = 1 AND b = 2 AND c = 3 -- 使用索引
WHERE a = 1 AND b = 2 -- 使用索引
WHERE a = 1 -- 使用索引
WHERE b = 2 AND c = 3 -- 不使用索引接着是 sql 语句的优化
处理分页 如使用游标去处理大偏移量分页
将子查询转化为 JOIN 外连表 能走索引
批量插入更新使用 CASE WHEN
使用 EXIST 代替 IN
-- ❌ SELECT *
SELECT * FROM user;
-- ✅ 只查需要的字段
SELECT id, name FROM user;
-- ❌ 大偏移量分页
SELECT * FROM orders LIMIT 1000000, 10;
-- ✅ 游标分页
SELECT * FROM orders WHERE id > 1000000 LIMIT 10;
-- ✅ 子查询优化
SELECT * FROM orders
WHERE id >= (SELECT id FROM orders LIMIT 1000000, 1)
LIMIT 10;
-- ❌ 子查询
SELECT * FROM orders WHERE user_id IN (SELECT id FROM user WHERE status = 1);
-- ✅ 改用JOIN
SELECT o.* FROM orders o
INNER JOIN user u ON o.user_id = u.id
WHERE u.status = 1;
-- ✅ 批量插入
INSERT INTO user(name, age) VALUES
('张三', 20), ('李四', 25), ('王五', 30);
-- ✅ 批量更新使用CASE WHEN
UPDATE product
SET stock = CASE id
WHEN 1 THEN stock - 5
WHEN 2 THEN stock - 3
END
WHERE id IN (1, 2);
-- ✅ EXISTS 代替 IN (大表)
SELECT * FROM user u WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id
);接着是表结构优化
选择合适的数据类型
拆分大字段
-- 选择合适的数据类型
-- ❌ VARCHAR(1000) 存储状态
-- ✅ TINYINT 存储状态
-- 字段设置NOT NULL + 默认值
-- 避免NULL值参与计算和索引
-- 大字段分表
-- 将TEXT/BLOB字段拆分到独立表
-- 适当冗余
-- 高频查询场景可以冗余字段避免JOIN然后是架构优化
读写分离
分库分表
┌─────────────────────────────────────────────────────────┐
│ 读写分离 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Master │────▶│ Slave1 │ │ Slave2 │ │
│ │ (写) │ │ (读) │ │ (读) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 分库分表 │
│ 水平分表: 按主键取模/范围分片 │
│ 垂直分表: 按业务拆分不同数据库 │
│ 工具: ShardingSphere / MyCat │
└─────────────────────────────────────────────────────────┘