目录
[2、序号(Sequence Number)与确认序号(Acknowledgement Number)](#2、序号(Sequence Number)与确认序号(Acknowledgement Number))
[解决乱序问题 ------ 序号与排序](#解决乱序问题 —— 序号与排序)
[为什么 TCP 要对每个字节编号?](#为什么 TCP 要对每个字节编号?)
[3、ACK 的工作流程](#3、ACK 的工作流程)
[1. 应答方式](#1. 应答方式)
[2. 应答规则](#2. 应答规则)
[3. 为什么有两个序号?](#3. 为什么有两个序号?)
[1、RTO 设置的挑战](#1、RTO 设置的挑战)
[2、动态估算 RTO](#2、动态估算 RTO)
[3、指数退避(Exponential Backoff)](#3、指数退避(Exponential Backoff))
[四、总结:ACK 与重传如何协同保障可靠性](#四、总结:ACK 与重传如何协同保障可靠性)
[Q1:为什么 TCP 报头没有"报文大小"字段?](#Q1:为什么 TCP 报头没有“报文大小”字段?)
**TCP(Transmission Control Protocol)是一种面向连接、可靠的、基于字节流的传输层协议。**其"可靠性"主要依赖于两大核心机制:
-
确认应答机制(Acknowledgement, ACK)
-
超时重传机制(Retransmission Timeout, RTO)
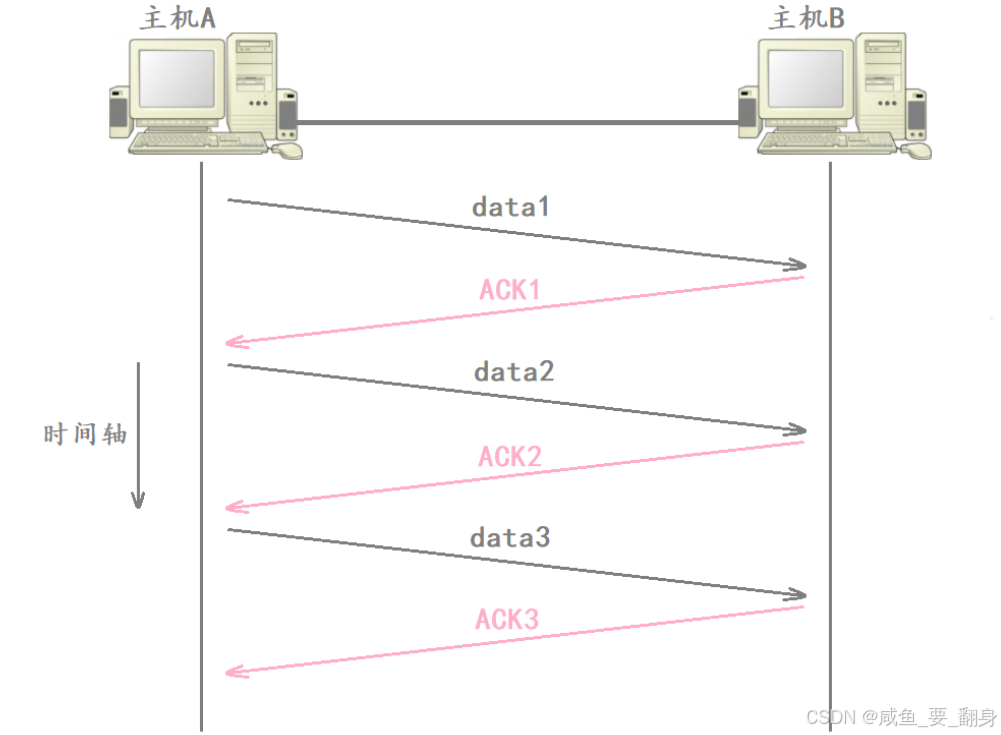
一、确认应答机制(ACK)
1、基本原理
确认应答机制是 TCP 实现可靠数据传输的基础。 其核心思想是:发送方只有在收到接收方对其所发数据的确认(ACK)后,才能认为该数据已被成功接收。
需要注意的是:**ACK 机制并不保证"双方通信的所有消息都可靠",而是保证"发送方自己发出的某条消息被对方可靠接收"。**也就是说,ACK 是单向的------A 发给 B 的数据是否被 B 收到,由 B 返回 ACK 来确认;B 发给 A 的数据则需 A 返回 ACK。
2、序号(Sequence Number)与确认序号(Acknowledgement Number)
解决乱序问题 ------ 序号与排序
问题背景:网络中可能存在丢包、延迟、乱序等问题,导致接收方收到的数据顺序混乱。
解决方案: 序号的作用不仅是确认,更是排序的关键依据。
-
使用 序列号(Sequence Number) 对数据进行编号。
-
接收方根据序号对数据进行重新排序。
-
保证最终交付给应用层的数据是按正确顺序的。
**TCP的确认应答机制通过报头中的32位序号和32位确认序号来实现。**TCP 报文头部包含两个关键字段:
-
32 位序号(Sequence Number) :标识本报文段中第一个字节在整个字节流中的位置。
-
32 位确认序号(Acknowledgement Number) :表示期望收到的下一个字节的序号,即"已成功接收 0, AckNum - 1 范围内的所有字节"。
为什么 TCP 要对每个字节编号?
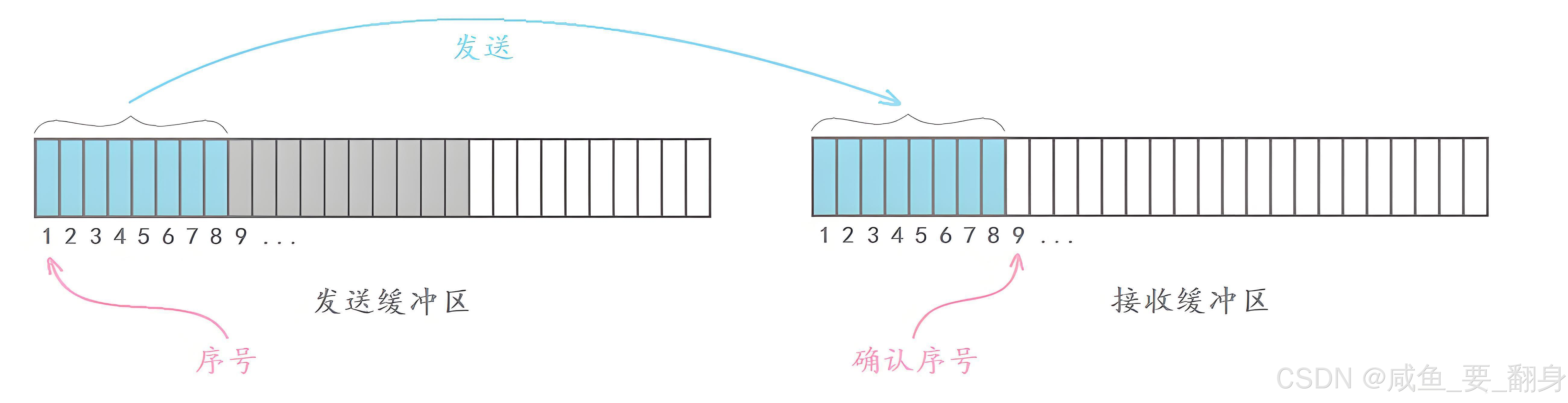
因为 TCP 是面向字节流(byte-stream oriented)的协议,它不保留应用层消息边界。为了精确追踪哪些数据已被接收、哪些需要重传,TCP 将整个发送/接收缓冲区视为一个连续的字节序列,并为每个字节分配一个唯一的序号。
形象理解 :可以把 TCP 的发送缓冲区和接收缓冲区想象成一个巨大的字符数组(如 char buffer[∞])。当上层应用调用 send() 将数据写入发送缓冲区时,这些字节就按顺序"安家落户",每个字节获得一个全局唯一的序号(从 ISN 开始,不是从 0)。
-
TCP通信的本质是双方互相将发送缓冲区的数据拷贝至对方的接收缓冲区。发送方在报头中填写的序号,实际上就是本次发送数据中第一个字节在发送缓冲区的下标值。
-
接收方响应时,其确认序号表示接收缓冲区中最后一个有效数据的下一个位置下标。发送方收到响应后,就能从确认序号指示的位置继续发送后续数据。
-
初始序号(ISN, Initial Sequence Number):连接建立时通过三次握手协商,通常是一个随机值(防 SYN Flood 攻击),之后按字节递增。
-
例如:若 ISN = 1000,发送了 5 字节数据,则这 5 个字节的序号为 1000 ~ 1004。
3、ACK 的工作流程
假设主机 A 向主机 B 发送数据:
-
A 发送一段数据,起始序号为
Seq = X,长度为L字节。 -
B 成功接收后,在返回的 ACK 报文中设置:
-
Ack = X + L -
表示:"我已收到序号 < X+L 的所有字节,请从 X+L 开始发下一段。"
-
-
A 收到此 ACK 后,即可安全地从发送缓冲区中清除序号 < X+L 的数据,并继续发送后续数据。
关键点:确认序号 = 已接收的最后一个字节的序号 + 1。 这种"累计确认"(Cumulative Acknowledgement)机制意味着:只要收到一个 ACK N,就表示 ISN, N−1 的所有字节都已正确到达。
4、确认应答机制详解
1. 应答方式
-
捎带应答(Piggybacking):在发送自己的数据时,顺便带上对方的 ACK。
-
例如:A 发送数据给 B,B 收到后,可以在回复 A 的数据时,同时携带 ACK。
2. 应答规则
- **确认号 = 序号 + 1:**表示:"我已经收到了你发来的从序号开始的所有字节,下一次你应该从这个确认号开始发。"
3. 为什么有两个序号?
每个 TCP 报文都有两个序号:
-
本方的序号(Sequence Number):标识本方发送数据的起始位置。
-
对方的确认号(Acknowledgment Number):表示期望收到的下一个字节。
为什么不能只用一个序号? 因为 TCP 是全双工通信,双方都在发送和接收数据,必须各自维护自己的序号和确认号。
二、超时重传机制(Retransmission)
TCP协议通过超时重传机制确保网络通信的可靠性。当发送方在特定时间间隔内未收到接收方的确认应答时,将自动触发数据重传。
TCP的可靠性保障体现在两个层面:一是协议报头设计,二是底层实现逻辑。以超时重传为例,发送方在数据发出后会启动定时器,若超时未收到确认应答即执行重传,这一机制完全由TCP实现代码控制,与报头无关。
1、为何需要重传?
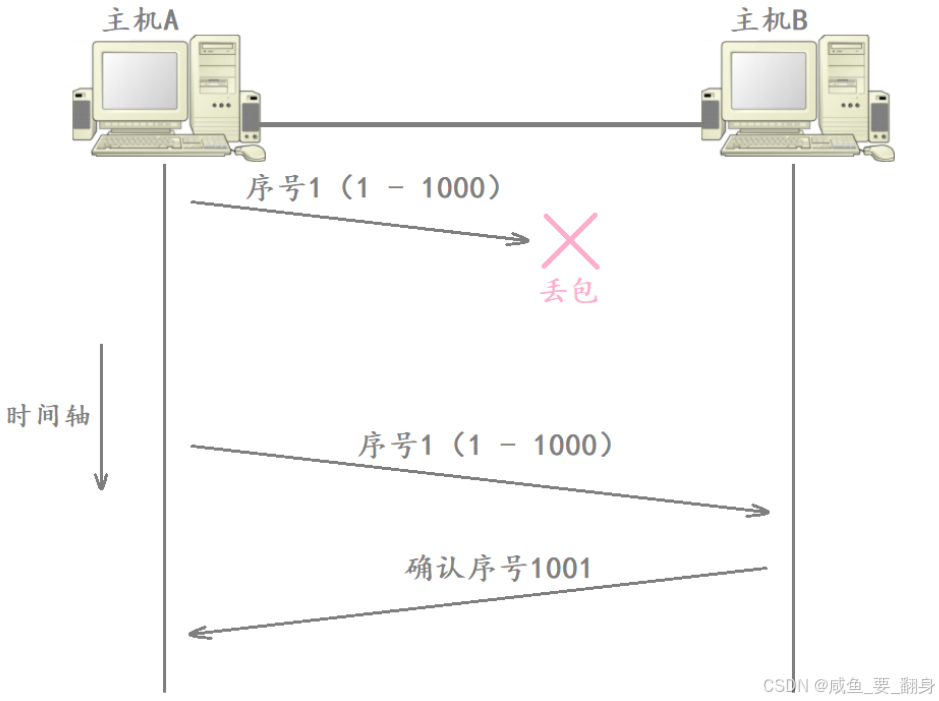
网络环境不可靠,数据包可能因以下原因丢失:
-
**情况一(发送方发送的数据报文丢失):**发送的数据包在传输途中丢失 → 接收方根本没收到,自然不会回 ACK。
-
情况二(接收方发送的确认应答丢失):数据包成功到达,但接收方返回的 ACK 在回传途中丢失 → 发送方收不到 ACK。
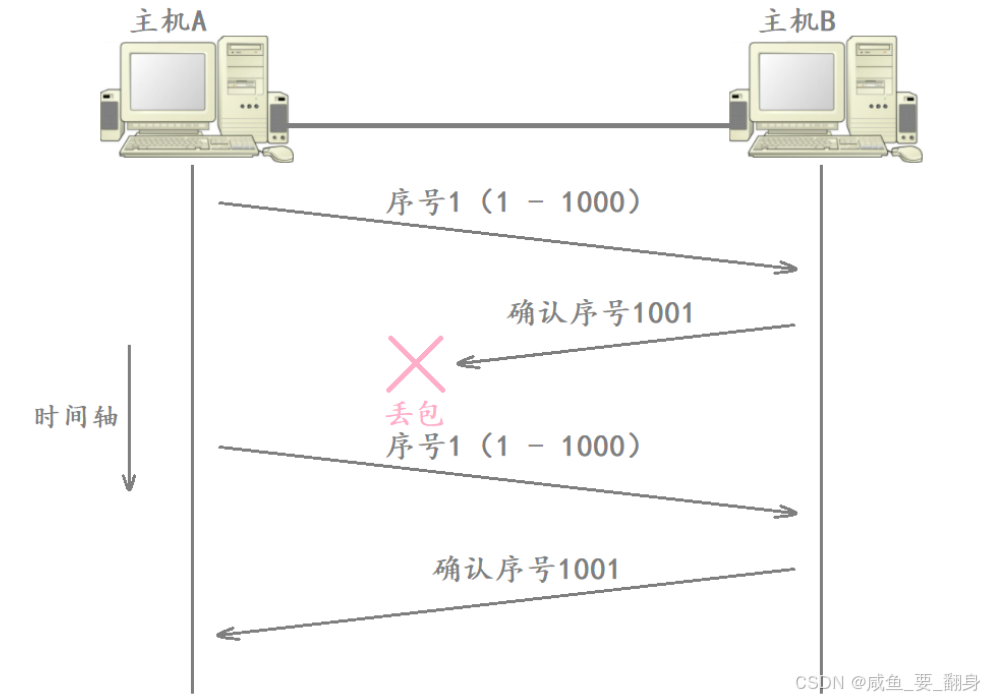
由于发送方无法区分具体是哪种情况(都表现为未收到应答),都会触发重传机制。针对确认应答丢失导致的重复报文问题,接收方可通过报头中的32位序号进行去重处理。
注意:发送方无法区分这两种情况 !无论哪种丢包,结果都是"在预期时间内未收到 ACK"。因此,TCP 统一采用 超时重传 策略来应对。
2、重传的实现逻辑
-
每当发送一段数据,TCP 会启动一个重传定时器(Retransmission Timer)。
-
若在 RTO(Retransmission Timeout) 时间内未收到对应 ACK,则重传该数据段。
-
注意 :重传机制是由 TCP 协议栈的代码逻辑实现的,不在 TCP 报头中直接体现。
3、发送缓冲区的管理
-
为支持重传,操作系统必须:保留已发送但未被确认的数据在发送缓冲区中,直到收到对应的 ACK。
-
只有收到 ACK 后,这部分数据才可被覆盖或释放。这是实现可靠传输的必要代价。
-
发送缓冲区管理策略: 已发送数据会保留在缓冲区中,直到收到对应确认应答后才被清除,这是为可能的超时重传做准备。
4、重复报文的处理
如果是因为 ACK 丢失 导致重传,接收方可能会收到重复数据。
-
接收方通过 序号(Sequence Number) 判断该数据是否已接收过。
-
若已接收,则丢弃重复报文 ,但仍会再次发送 ACK (称为 重复 ACK),以确保发送方知道数据已被接收。
这体现了 TCP 的"幂等性"设计:重复接收不影响最终结果。
三、超时重传时间(RTO)的动态调整
1、RTO 设置的挑战
-
时间过长:影响重传效率,真正丢包时恢复慢,降低吞吐量和用户体验。
-
时间过短:网络延迟稍大就会误判为丢包,导致不必要的重传,浪费带宽。导致重复报文和网络资源浪费
超时重传时间设置原则:
理想 RTO 应略大于 RTT(Round-Trip Time,往返时延) ,但 RTT 随网络状况动态变化。理想时间应动态调整,随网络状况浮动。TCP采用智能算法动态计算最佳超时时间,确保不同网络环境下都能保持高效通信。
2、动态估算 RTO
现代 TCP 实现(如 Linux、Windows、BSD)采用 Jacobson 算法 动态计算 RTO:
-
基于历史 RTT 测量值,计算平滑 RTT(SRTT)和 RTT 偏差(RTTVAR)。
-
公式(简化版):RTO = SRTT + 4 × RTTVAR
-
初始 RTO 通常设为 1 秒(或 3 秒),后续根据实际测量动态调整。
3、指数退避(Exponential Backoff)
若重传后仍无 ACK,TCP 会逐步延长重传间隔,避免网络拥塞恶化:
| 重传次数 | 等待时间(典型实现) |
|---|---|
| 第 1 次 | 500 ms |
| 第 2 次 | 1000 ms (2×500) |
| 第 3 次 | 2000 ms (4×500) |
| 第 4 次 | 4000 ms (8×500) |
| ... | ... |
**注意:**虽然以 500ms 为单位是早期 BSD 的实现方式,现代系统多采用更精细的微秒级定时器,但"指数退避"策略依然保留。
为了确保在各种网络环境下都能实现高性能通信,TCP协议会动态计算最大超时时间。例子如下:
-
在Linux系统(包括BSD Unix和Windows)中,超时控制以500ms为基本单位,每次重传超时判定都是500ms的整数倍。
-
初次重传后若无响应,下一次重传等待时间将延长至2×500ms。
-
若仍未收到应答,等待时间会继续以指数形式递增,变为4×500ms,以此类推。
-
当重传次数达到阈值时,TCP协议会判定网络或对端主机出现异常,并强制关闭连接。
4、重传上限与连接终止
-
TCP 通常设置最大重传次数(如 Linux 默认为 15 次)。
-
若超过上限仍未收到 ACK,TCP 认为网络或对端出现严重故障 ,将主动关闭连接 并通知上层应用(如返回
ETIMEDOUT错误)。
四、总结:ACK 与重传如何协同保障可靠性
| 机制 | 作用 | 关键技术点 |
|---|---|---|
| 确认应答(ACK) | 告知发送方哪些数据已成功接收 | 累计确认、字节级序号、确认序号 = 下一个期望字节 |
| 超时重传 | 补偿因丢包导致的 ACK 缺失 | 定时器、RTO 动态调整、指数退避、发送缓冲区保留 |
| 去重机制 | 处理因 ACK 丢失引发的重复数据 | 基于序号识别重复报文,自动丢弃 |
核心思想 :TCP 不假设网络可靠,而是通过"发送 → 等待确认 → 超时重传"的闭环控制,在不可靠的 IP 网络上构建出可靠的字节流通道。
TCP 通信过程的特点:
-
每个报文都包含 报头 + 数据(有效载荷)
-
通信过程中,每一个传递的都是 TCP 报文,即使只有报头(如纯 ACK 报文)
-
数据和 ACK 可以合并发送(捎带应答),提高效率
五、常见疑问解答
Q1:为什么 TCP 报头没有"报文大小"字段?
-
因为 TCP 报文的大小由 IP 层或链路层 决定,TCP 不直接管理整个报文大小。
-
TCP 只关心 报头长度 和 数据部分 的边界。
Q2:如何区分报头和有效载荷?
-
通过 首部长度字段 确定报头长度。
-
剩余部分就是有效载荷(数据)。
Q3:为什么确认号是"序号+1"?
- 因为序号是从 0 开始计数的,确认号表示"我期待下一个字节",所以是当前序号加一。
Q4:服务器只做应答吗?
-
不是!服务器也会发送带有自己序号的报文,并且可以捎带应答。
-
所有 TCP 报文都可以携带 ACK 和数据。
附:常见误区判断
❌ "ACK 是对整个报文的确认" ✅ 实际是对字节序号范围的确认,支持部分确认(后续通过 SACK 扩展)。
❌ "重传时间是固定值" ✅ RTO 是动态计算的,随网络 RTT 自适应调整。
❌ "发送方发送完数据就从缓冲区删除" ✅ 必须等到对应 ACK 到达才能释放,否则无法重传。
学习建议
-
画图辅助理解:绘制 TCP 报文格式图、通信流程图、确认应答示意图。
-
模拟场景练习:设想不同情况下的 TCP 交互(如丢包、重传、乱序)。
-
关注细节:如首部长度计算、确认号变化、捎带应答时机等。
总结一句话:TCP 的可靠性来源于"确认应答机制"与"序号系统"的结合,通过序号实现排序和重传,通过确认号反馈接收状态,最终构建了一个面向连接、可靠、有序的传输服务。