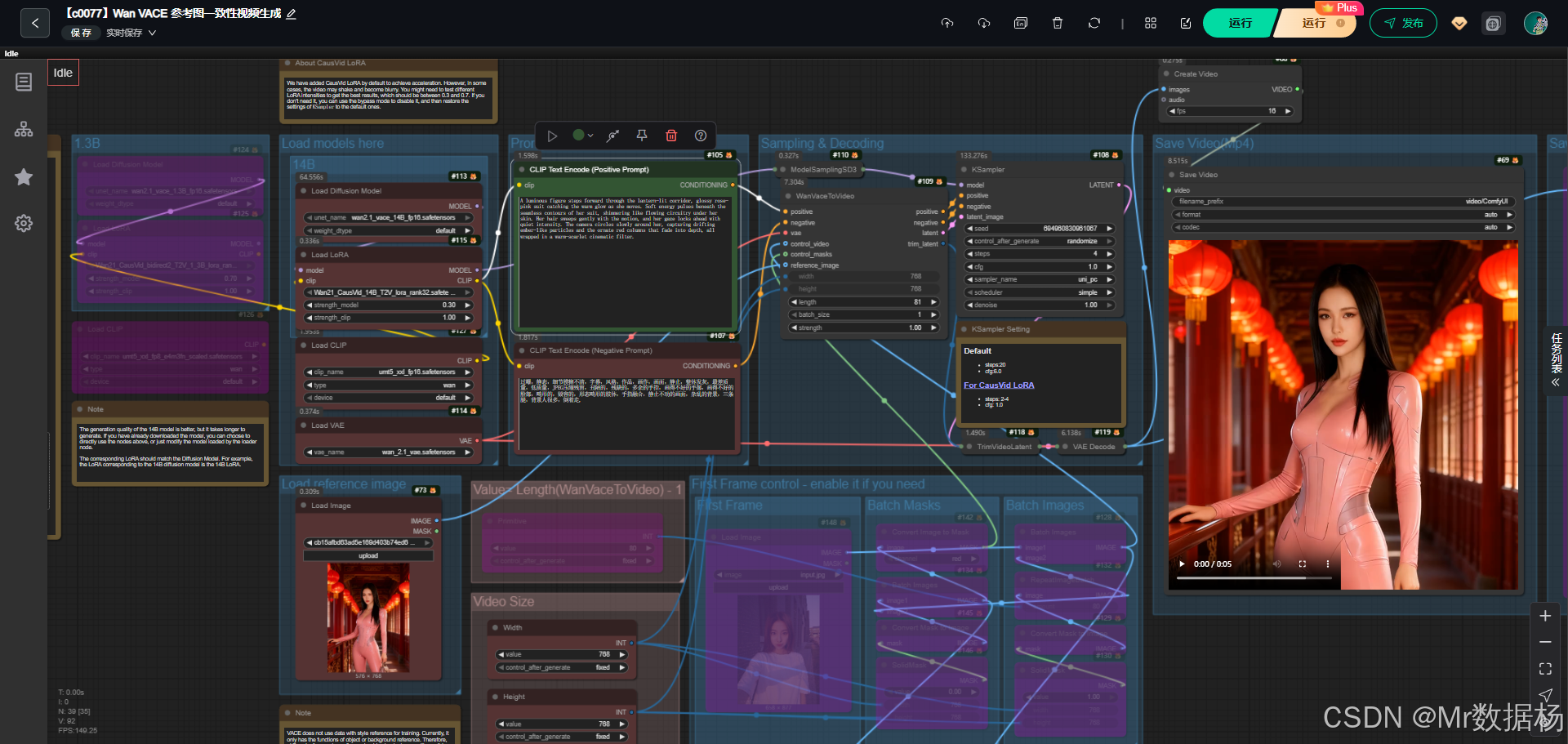
今天演示的案例是一个基于 Wan2.1 VACE 模型 的 ComfyUI 视频生成工作流。该流程通过加载不同规模的扩散模型与配套的 LoRA,加上文本编码器和 VAE 的协同工作,能够将文本提示与参考图像结合,生成具有动态表现的视频。
效果展示中可以流畅动作的过程,这种由静态描述到动态视频的转换,是当前 AI 视频生成中极具代表性的应用方向。
文章目录
- 工作流介绍
-
- 核心模型
- Node节点
- 工作流程
- 大模型应用
-
- CLIP Text Encode (Positive Prompt) 文本语义驱动的视频生成核心
- CLIP Text Encode (Negative Prompt) 负向语义过滤器
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该工作流结合 1.3B 与 14B 两个版本的 Wan2.1 VACE 扩散模型,并通过匹配的 CausVid LoRA 加速视频生成,在保证画质的同时显著提升效率。配套的 VAE 与文本编码器提供了解码与语义支撑,使得复杂的文本提示能够高效映射到潜在空间,再通过解码得到高质量的视频帧。整个流程的设计充分考虑了用户在分辨率、生成速度与控制精度上的需求,因此在实际使用中既能适应快速测试,也能支持高质量输出。
核心模型
本工作流使用的核心模型包括两种规模的扩散模型及其对应的 LoRA,同时还包含 VAE 与不同精度版本的文本编码器。14B 模型在画质上表现更佳,适合生成 720P 视频,但需要较长推理时间;1.3B 模型仅支持 480P,推理速度更快,适合轻量级任务。CausVid LoRA 的加入使推理速度从数十分钟缩短至数分钟,极大优化了效率表现。VAE 负责潜在空间到图像的还原,而 UMT5 XXL 系列文本编码器保证了提示语的语义解析能力。
| 模型名称 | 说明 |
|---|---|
| wan2.1_vace_14B_fp16.safetensors | 大规模扩散模型,支持 480P/720P 输出,画质更高但推理较慢 |
| wan2.1_vace_1.3B_fp16.safetensors | 中等规模扩散模型,仅支持 480P,推理速度更快 |
| Wan21_CausVid_14B_T2V_lora_rank32.safetensors | 与 14B 模型配套的 LoRA,加速视频生成 |
| Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors | 与 1.3B 模型配套的 LoRA,加速视频生成 |
| wan_2.1_vae.safetensors | VAE 模型,用于潜在空间解码成视频帧 |
| umt5_xxl_fp16.safetensors / umt5_xxl_fp8_e4m3fn_scaled.safetensors | 文本编码器,解析正负提示词,支持不同精度版本 |
Node节点
在节点层面,工作流通过 UNETLoader、LoraLoader 与 CLIPLoader 完成核心模型的加载与组合,通过 WanVaceToVideo 与 KSampler 将文本与参考图像转换为潜在视频帧,再经过 VAEDecode 与 CreateVideo/SaveVideo 输出成最终视频格式。同时,还设计了辅助节点如 LoadImage、MaskToImage、ImageBatch、RepeatImageBatch 等,用于控制参考图像、遮罩与帧序列,保证视频生成过程可控且灵活。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载核心扩散模型(1.3B 或 14B) |
| LoraLoader | 加载并绑定对应的 CausVid LoRA |
| CLIPLoader | 加载文本编码器,支持提示语解析 |
| CLIPTextEncode | 将正向/负向提示词转化为条件输入 |
| WanVaceToVideo | 将提示与参考图像映射到视频潜在空间 |
| KSampler | 控制采样过程,生成潜在视频帧 |
| VAELoader / VAEDecode | 加载 VAE 并完成潜在空间解码 |
| LoadImage | 加载参考图像作为生成控制 |
| MaskToImage / SolidMask | 生成遮罩或将遮罩转化为图像 |
| ImageBatch / RepeatImageBatch | 构建帧序列,实现视频片段拼接 |
| CreateVideo | 将图像序列合成为视频流 |
| SaveVideo / SaveAnimatedWEBP | 输出视频文件,支持 MP4 与 WebP 格式 |
工作流程
该工作流的设计以模型加载、提示词解析、采样生成与视频输出为核心环节,形成了一个从文本到动态视频的完整链路。首先通过 UNETLoader 与 LoraLoader 装载不同规模的扩散模型及其配套 LoRA,再由 CLIPLoader 与 CLIPTextEncode 将提示词转化为条件输入。随后,WanVaceToVideo 节点结合参考图像与遮罩生成潜在视频,再交由 KSampler 进行采样优化,并通过 TrimVideoLatent 与 VAEDecode 解码为可见帧。最后,帧序列通过 CreateVideo 与 SaveVideo/SaveAnimatedWEBP 输出为视频文件。为了增强灵活性,还提供了 LoadImage、MaskToImage、ImageBatch、RepeatImageBatch 等辅助节点,用于控制首帧、批量帧及遮罩的生成,从而保证视频生成的精细度与可控性。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 载入 1.3B/14B 扩散模型、VAE、文本编码器及 CausVid LoRA | UNETLoader、VAELoader、LoraLoader、CLIPLoader |
| 2 | 提示词解析 | 输入正向与负向提示词并转换为条件张量 | CLIPTextEncode(Positive/Negative) |
| 3 | 潜在视频生成 | 将提示词、参考图像和遮罩映射到潜在空间 | WanVaceToVideo |
| 4 | 采样优化 | 在潜在空间中迭代采样生成视频帧 | KSampler |
| 5 | 帧裁剪与解码 | 修剪潜在序列并解码为图像帧 | TrimVideoLatent、VAEDecode |
| 6 | 帧序列处理 | 通过批处理与重复控制实现首帧与序列构建 | LoadImage、MaskToImage、ImageBatch、RepeatImageBatch |
| 7 | 视频合成与保存 | 将图像序列合成视频并保存为 MP4/WebP | CreateVideo、SaveVideo、SaveAnimatedWEBP |
大模型应用
CLIP Text Encode (Positive Prompt) 文本语义驱动的视频生成核心
该节点负责将用户输入的正向 Prompt 转换为语义嵌入,用于控制视频生成过程中的动作、场景、氛围和视觉细节。Prompt 的语言越清晰,生成的视频越能在节奏、镜头调度和场景质感上保持统一,尤其是在 WanVaceToVideo 中,这些语义嵌入将与参考图、控制视频和 Mask 共同决定最终视频的视觉逻辑。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Positive Prompt) | An icicle dragon lunges forward, mouth wide open to exhale a stream of icy mist. Ultramarine energy flickers beneath its frost-coated scales as it twists. The camera circles slowly, capturing the swirling ice particles and the backdrop of floating glaciers and frozen nebulae under a cyan-blue filter. | 将正向 Prompt 编码为语义向量,提供动作、场景、光效与气氛等核心控制信号,驱动视频的动态风格与视觉表现。 |
CLIP Text Encode (Negative Prompt) 负向语义过滤器
该节点将负向 Prompt 转换成抑制性语义向量,专门过滤视频生成中常见的错误,例如画面抖动、角色畸形、画质降低、背景混乱等。负向 Prompt 在视频生成逻辑中至关重要,能显著提升序列帧稳定性,减少违和细节。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Negative Prompt) | 过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走, | 将负向 Prompt 编码为抑制向量,过滤视频序列中的缺陷内容,确保画面干净、结构合理、运动自然。 |
使用方法
该工作流通过"参考图 + 控制视频 + 文本 Prompt + 掩膜序列"的方式生成动态视频。用户上传参考图片后,WanVaceToVideo 会读取正向和负向 Prompt,将语义与图像特征融合,生成初始潜变量序列。随后通过生成的 trim_latent 控制帧长,再由 KSampler 完成采样推理。TrimVideoLatent 裁切潜变量序列,VAEDecode 把潜变量转换成图像帧,最终由 CreateVideo 或 SaveAnimatedWEBP 输出视频结果。
若用户替换参考图、控制视频或 Prompt,整个流程会自动重新生成完整的视频序列。参考图决定主体外观,控制视频决定动作路径,Mask 决定画面中可修改的区域,Prompt 决定场景风格和动态叙事。
| 注意点 | 说明 |
|---|---|
| Prompt 越具体越好 | 影响动作逻辑、镜头感、氛围、场景质感 |
| 负向 Prompt 必填 | 控制画质问题、角色畸形、画面抖动 |
| 参考图需背景纯净 | VACE 不支持风格参考,仅支持物体或背景参考 |
| 控制视频需稳定 | 动作越清晰,生成的动态越一致 |
| LoRA 强度要适中 | CausVid LoRA 0.3--0.7 区间较为稳定 |
| 分辨率受模型限制 | 1.3B 仅 480P,14B 支持 480P/720P |
| 第一帧控制可选 | 通过 Batch Image 和 Mask 决定视频起始画面 |
| trim_latent 要正确连接 | 影响最终视频时长和帧序列一致性 |
应用场景
该工作流在视频生成领域具有广泛应用价值,既可用于创意短片、影视概念设计,也适用于游戏角色动作演示和动态插画制作。依托于文本到视频的转换能力,用户只需输入描述与参考图像即可快速生成动态画面,在节省人工建模与逐帧渲染成本的同时提升创作效率。对于追求快速测试的轻量场景,可以选择 1.3B 模型结合低步数采样;而在需要高质量输出的场合,则可使用 14B 模型与更高分辨率,配合 LoRA 加速以缩短等待时间。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 动态角色演示 | 将角色设计稿转化为动态视频 | 游戏开发者、概念设计师 | 角色动作与表情片段 | 快速预览角色动态 |
| 影视概念短片 | 输入场景描述生成视频镜头 | 影视导演、视觉设计师 | 特定场景的动态分镜 | 节省场景建模与拍摄成本 |
| 动态插画制作 | 静态插画扩展为动态表现 | 插画师、动画爱好者 | 插画中物体或角色动作 | 创作动态化作品 |
| 教学与研究 | 展示文本到视频生成流程 | 教育工作者、研究人员 | AI 视频生成过程与结果 | 用于课程与论文案例 |
| 内容创作加速 | 自动化生成素材片段 | 自媒体创作者、广告团队 | 短视频、广告片素材 | 快速产出与多样化创意 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用