目录
[蓝耘 MaaS 平台:高性能 LLM 的可靠承载底座](#蓝耘 MaaS 平台:高性能 LLM 的可靠承载底座)
[TextIn 插件:多格式文档的高效解析利器](#TextIn 插件:多格式文档的高效解析利器)
[配置 LLM 模型:蓝耘 MaaS 平台 DeepSeek-V3.2](#配置 LLM 模型:蓝耘 MaaS 平台 DeepSeek-V3.2)
[配置 TextIn 文档解析插件](#配置 TextIn 文档解析插件)
[第三步:配置 LLM 模型(数据格式转换)](#第三步:配置 LLM 模型(数据格式转换))
[第四步:添加参数提取器(分离 x 轴与 y 轴数据)](#第四步:添加参数提取器(分离 x 轴与 y 轴数据))
引言
在数据驱动决策的时代,新能源汽车行业的销量数据分析成为市场研判、竞品对比的核心需求。但传统数据分析往往面临 "文档格式繁杂、数据提取低效、可视化步骤繁琐" 的痛点 ------ 图片、PDF 等多格式文档难以快速解析,销量数据需手动整理格式,柱状图生成需专业技能。为此,我们基于 Dify 平台,整合蓝耘 MaaS 平台的 DeepSeek-V3.2 大模型 与TextIn 文档解析插件,搭建了一套 "文档上传 - 数据提取 - 格式转换 - 图表生成" 全自动化工作流,无需复杂编程,即可快速输出中国大陆新能源汽车品牌销量柱状图,彻底解决传统数据分析的效率与门槛难题。
核心工具优势解析
蓝耘 MaaS 平台:高性能 LLM 的可靠承载底座
蓝耘 MaaS 是蓝耘的模型云服务,已经把 DeepSeek-V3.2 系列等模型上了平台,支持长上下文推理(不同部署的最大上下文差异大,部分变体可达数万 tokens 级别),适合处理跨页、带表格的销量报告。平台提供 OpenAI-兼容接口和控制台化的 API Key 管理(创建/停用/删除),便于在 Dify 等工作流中直接接入。
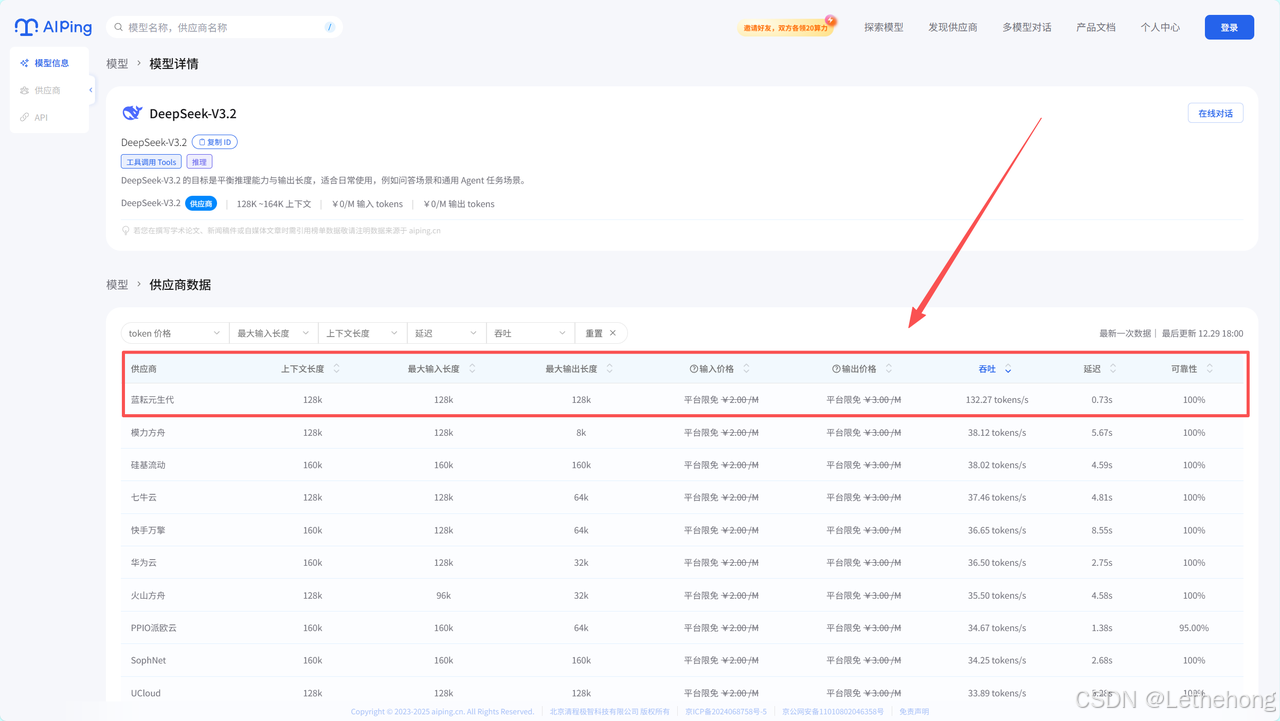
TextIn 插件:多格式文档的高效解析利器
TextIn(xParse)负责把各种文档(PDF、图片、Office 等)抽成结构化数据,调用时用 x-ti-app-id / x-ti-secret-code 做鉴权。它能识别复杂表格、跨页合并和图表要点,适合作为把"脏"报告变成干净表格/JSON 的前置工具。抽取后建议做一遍数值/格式校验再交给 LLM。

一、工作流核心目标与成果预览
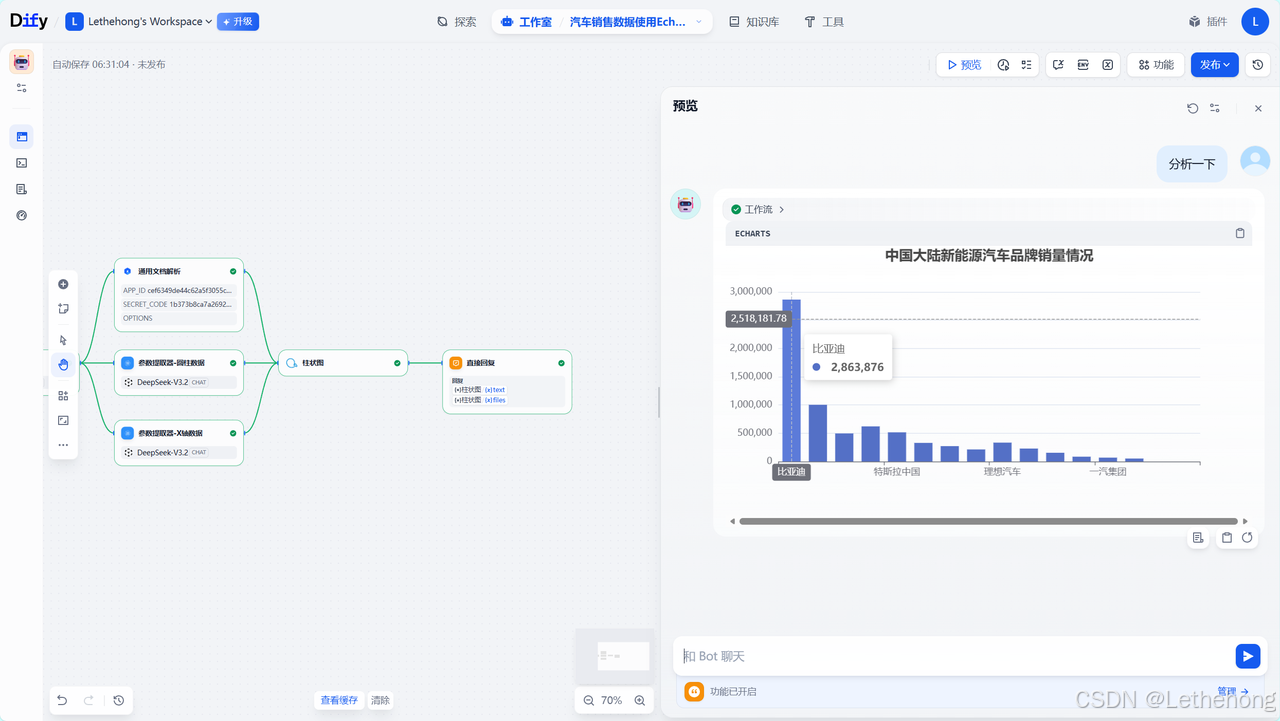
本工作流旨在通过 Dify 平台实现新能源汽车销量数据的自动化处理与可视化,支持上传图片、PDF 等格式的文档(含本地文件上传与在线链接两种方式),经文档解析、数据提取、格式转换后,自动生成标准柱状图,直观呈现中国大陆新能源汽车品牌的销量对比情况。
成果展示
最终将输出标题为 "中国大陆新能源汽车品牌销量情况" 的柱状图,涵盖比亚迪、特斯拉中国、理想汽车等主流品牌,销量数据范围从 0 至 300 万 + 辆(如比亚迪 2,863,876 辆、某品牌 2,518,181.78 辆等),图表可直接用于数据汇报、行业分析等场景,无需手动调整格式。
二、前期准备:核心工具与配置说明
搭建工作流前需完成两项关键配置:LLM 模型(DeepSeek-V3.2)与 TextIn 文档解析插件,两者为数据处理的核心支撑。
配置 LLM 模型:蓝耘 MaaS 平台 DeepSeek-V3.2
模型选择依据
DeepSeek-V3.2 模型具备强大的中文处理能力、4096 字的上下文长度,可精准解析 CSV 格式数据并转换为 ECharts 所需的 JSON 结构,适配新能源汽车销量数据的格式转换需求(如去除千位分隔符、处理缺失值)。
详细配置步骤
1.登录 Dify 平台,点击右上角头像,在下拉菜单中选择 "设置";
2.进入设置页面后,找到 "模型供应商" 模块,选中 "OpenAI-API-compatible" 并保存;
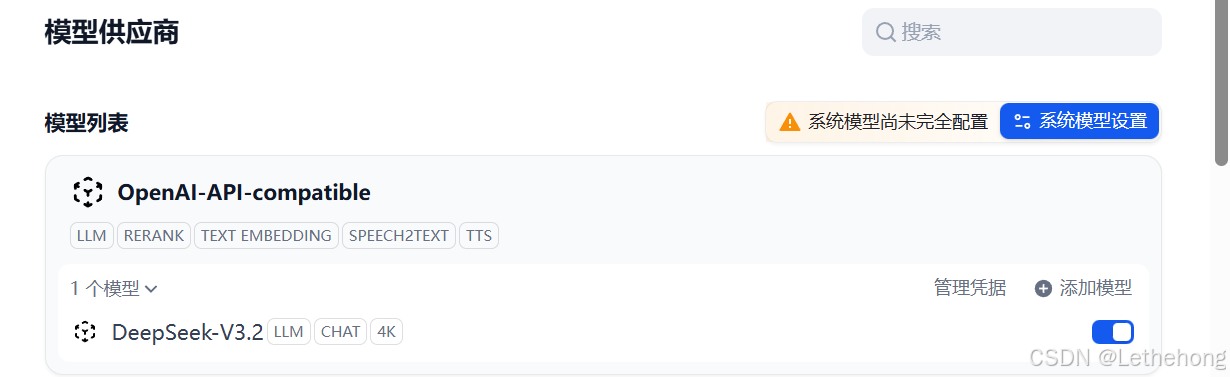
3.登录蓝耘 MaaS 平台,进入 "API KEY 管理" 页面,复制已创建的有效 API Key;
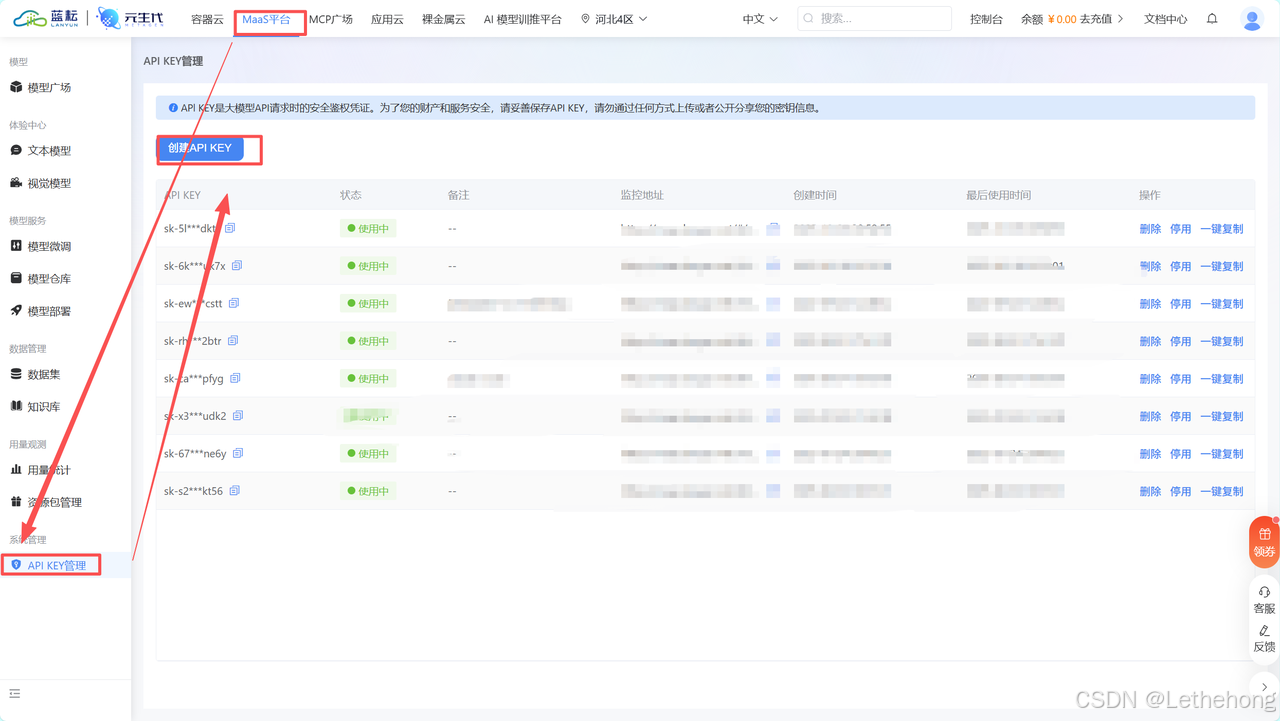
4.返回 Dify 模型配置页面,点击 "编辑模型凭据",按以下要求填写参数:
-
凭据名称:DeepSeek-V3.2(自定义,便于识别)
-
模型显示名称:DeepSeek-V3.2
-
API Key:粘贴从蓝耘 MaaS 平台获取的 API Key
-
API endpoint URL:https://maas-api.lanyun.net/v1(蓝耘 MaaS 平台固定接口地址)
-
对话类型:选择 "对话"
-
模型上下文长度 / 最大 token 上限:均设置为 4096(匹配模型原生支持的长度)
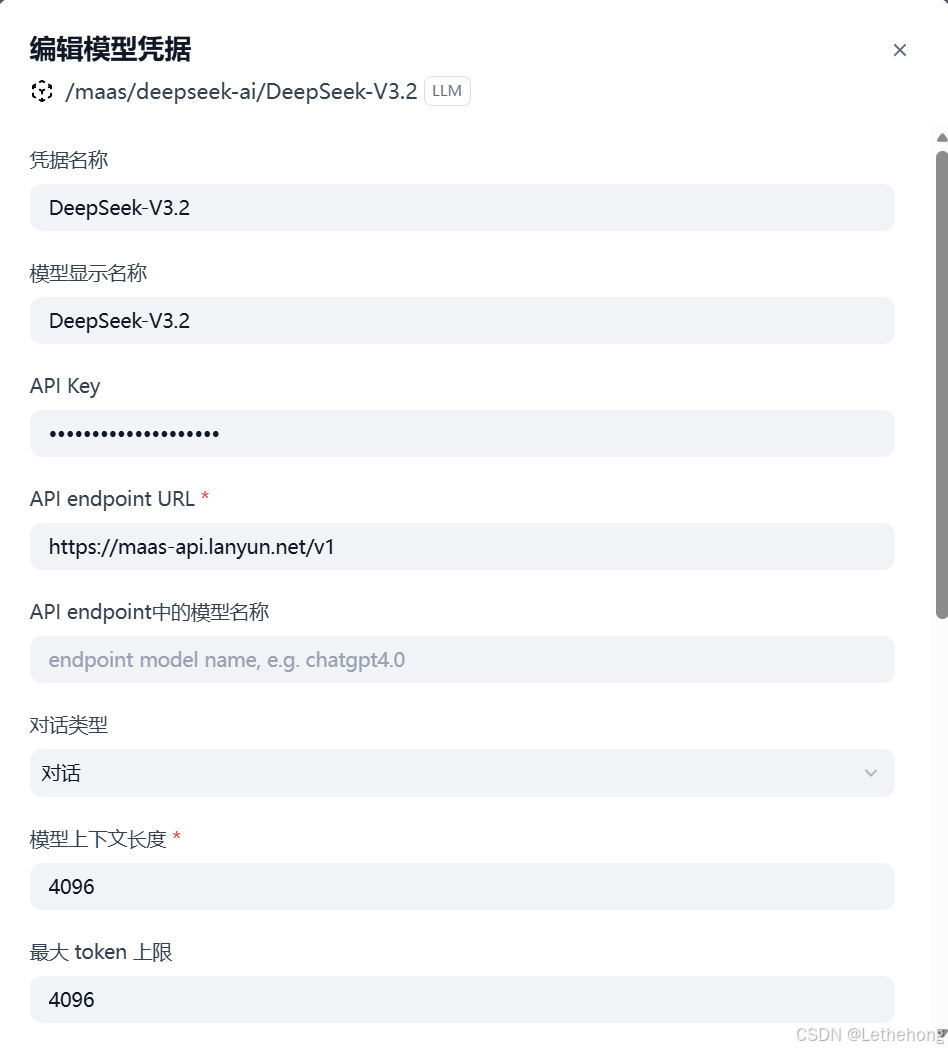
5.填写完成后保存,完成 LLM 模型接入。
配置 TextIn 文档解析插件
TextIn 插件支持解析图片、PDF 等多种格式的文档,可从上传的文件中提取新能源汽车销量数据(如 CSV 格式的品牌、销量信息),为后续 LLM 处理提供原始数据。
详细配置步骤
1.进入 Dify 平台 "插件" 模块,搜索 "TextIn",选择对应官方插件并点击 "安装";
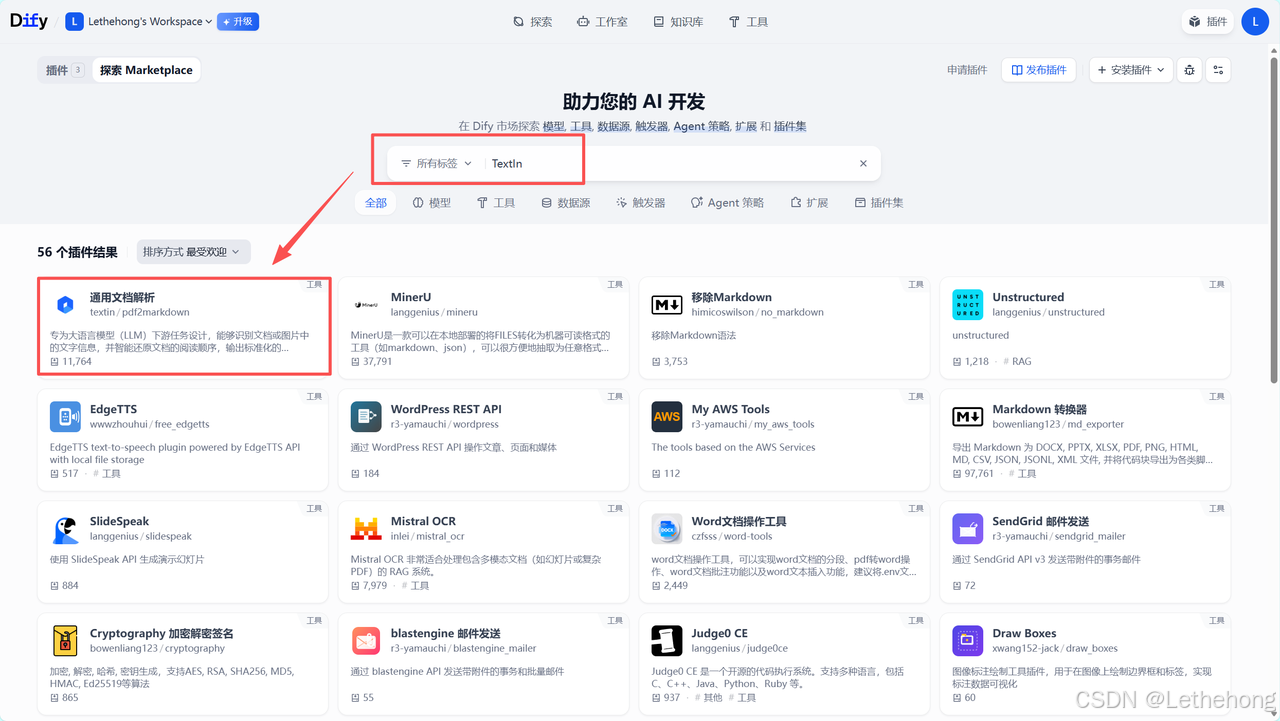
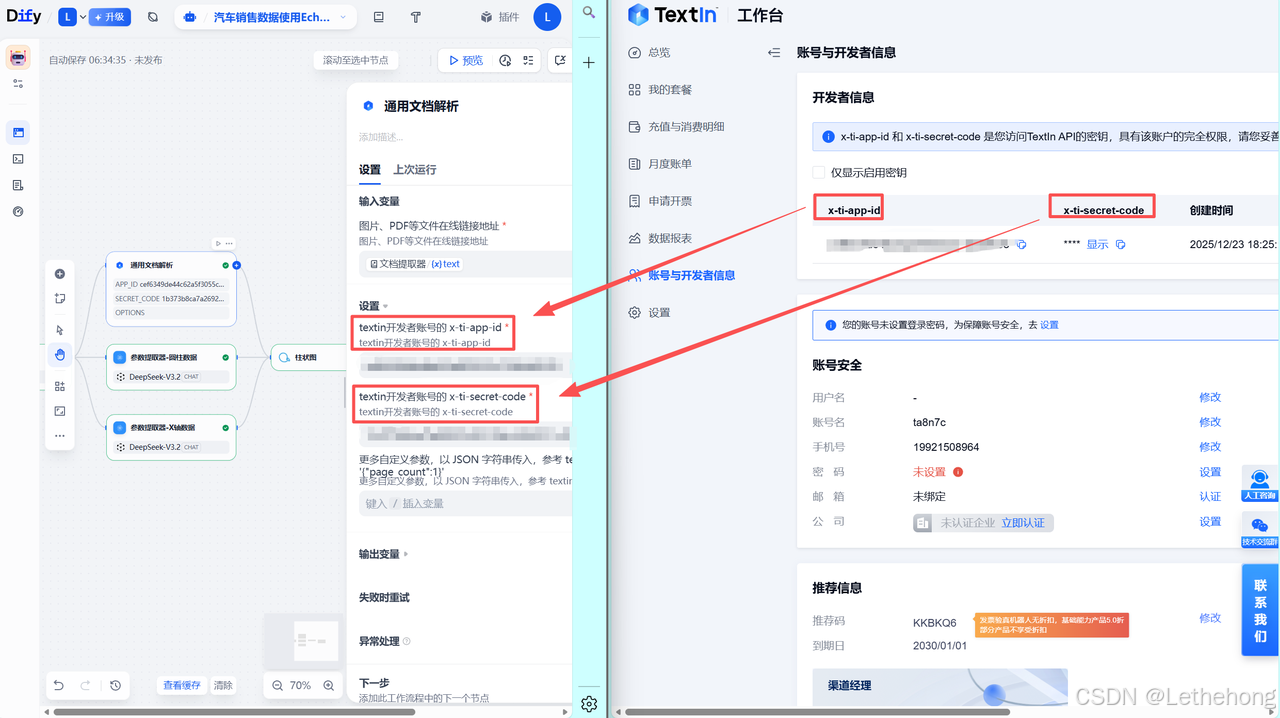
2.登录TextIn工作台(需提前注册账号),进入 "账号与开发者信息" 页面,获取核心凭证:
-
x-ti-app-id:账号专属应用 ID
-
x-ti-secret-code:账号安全密钥(与 API Key 同理,需保密)
3.返回 Dify 插件配置页面,找到已安装的 TextIn 插件,将获取的 x-ti-app-id 和 x-ti-secret-code 填入对应字段;
4.补充其他参数:支持传入图片、PDF 等文件的在线链接地址,或直接关联本地文件上传入口;
5.保存配置,完成 TextIn 插件激活(可通过 "测试连接" 验证插件是否正常工作)。
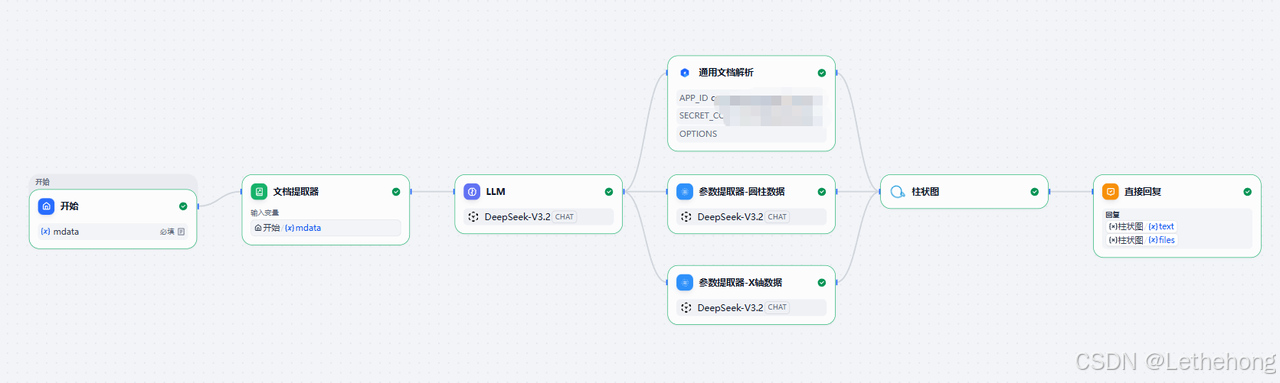
三、五步搭建完整工作流
第一步:设置输入变量(支持双重上传方式)
配置目的
为满足不同用户的使用场景,支持 "本地文件上传" 和 "在线链接上传" 两种方式,需在 "开始" 节点定义对应的输入变量。
具体操作
-
进入 Dify 工作流编辑页面,选中 "开始" 节点;
-
在输入变量设置中,添加两项核心参数:
-
变量 1:
(x) mdata File(接收本地文件上传,类型选择 "Array File") -
变量 2:
(x) mdata(接收在线链接,类型选择 "字符串")
-
-
标记两项变量为 "必填",确保用户提交数据时无遗漏。
示意图说明
该步骤对应的示意图展示了 "开始" 节点的变量配置界面,明确了文件和链接两种输入方式的变量名称及类型,便于用户按提示上传数据。
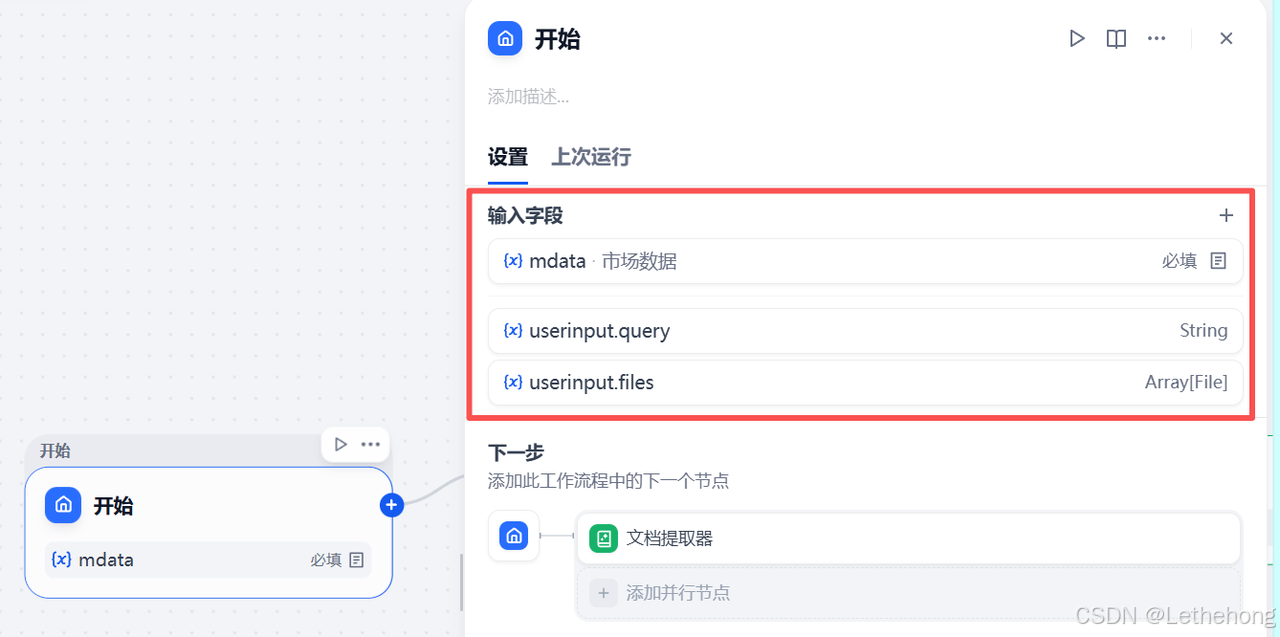
第二步:添加文档提取器(提取原始销量数据)
配置目的
通过 TextIn 插件解析用户上传的文档(文件或链接),提取其中的新能源汽车销量数据(如 CSV 格式的 "品牌""累计销量(辆)" 字段),转化为 LLM 可识别的文本格式。
具体操作
-
在 "开始" 节点后添加 "文档提取器" 节点,选择已配置的 TextIn 插件;
-
输入变量关联:将 "开始" 节点的
(x) mdata File和(x) mdata变量关联至文档提取器的 "输入变量" 字段; -
配置输出变量:设置输出变量为
(x) text,用于存储提取后的文本格式数据(如 CSV 字符串); -
开启 "失败时重试" 功能,设置重试次数为 2 次,提升数据提取的稳定性。
示意图说明
示意图展示了文档提取器的配置界面,清晰呈现了输入变量与 "开始" 节点的关联关系,以及输出变量的定义,确保提取后的数据能准确传递至下一节点。
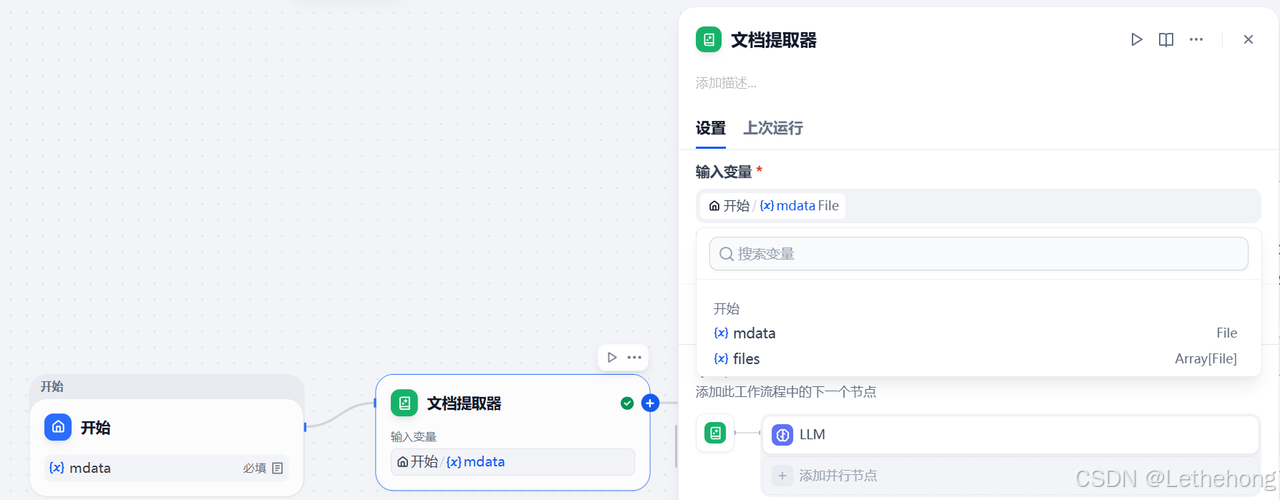
第三步:配置 LLM 模型(数据格式转换)
配置目的
通过 DeepSeek-V3.2 模型,将文档提取器输出的原始数据(如 CSV 格式)转换为 ECharts 柱状图所需的标准 JSON 结构,明确 x 轴(品牌)和 y 轴(销量)的数据规则。
具体操作
1.在 "文档提取器" 节点后添加 "LLM" 节点,选择已配置的 "DeepSeek-V3.2 CHAT" 模型;
2.输入变量关联:将文档提取器的(x) text变量作为输入,即文档提取器/(x) text;
3.编写精准提示词(核心配置):
请将以下CSV格式的新能源汽车销量数据{{#1758518441631.text#}}转换为指定格式的JSON结构,用于柱状图可视化。具体要求如下:
1. 提取"品牌"字段作为横坐标(xAxis.data),按原顺序排列
2. 提取"累计销量(辆)"字段作为纵坐标数据(series.data),注意:
- 销量数据中包含逗号分隔符(如"2,863,876"),请先去除逗号再转换为数字
- 如遇数据缺失(如哪吒汽车、小米汽车),使用 null 值
3. 生成如下标准ECharts配置格式:
```json
{
xAxis: {
type: 'category',
data: ['品牌1', '品牌2', ...]
},
yAxis: {
type: 'value'
},
series: [{
data: [数值1, 数值2, ...],
type: 'bar'
}]4.配置输出变量:设置输出变量为(x) echardata,存储转换后的 JSON 格式数据。
示意图说明
示意图展示了 LLM 节点的配置界面,包括模型选择、输入变量关联、提示词编辑框等核心区域,明确了提示词的格式和要求,确保模型能精准输出 ECharts 所需数据。
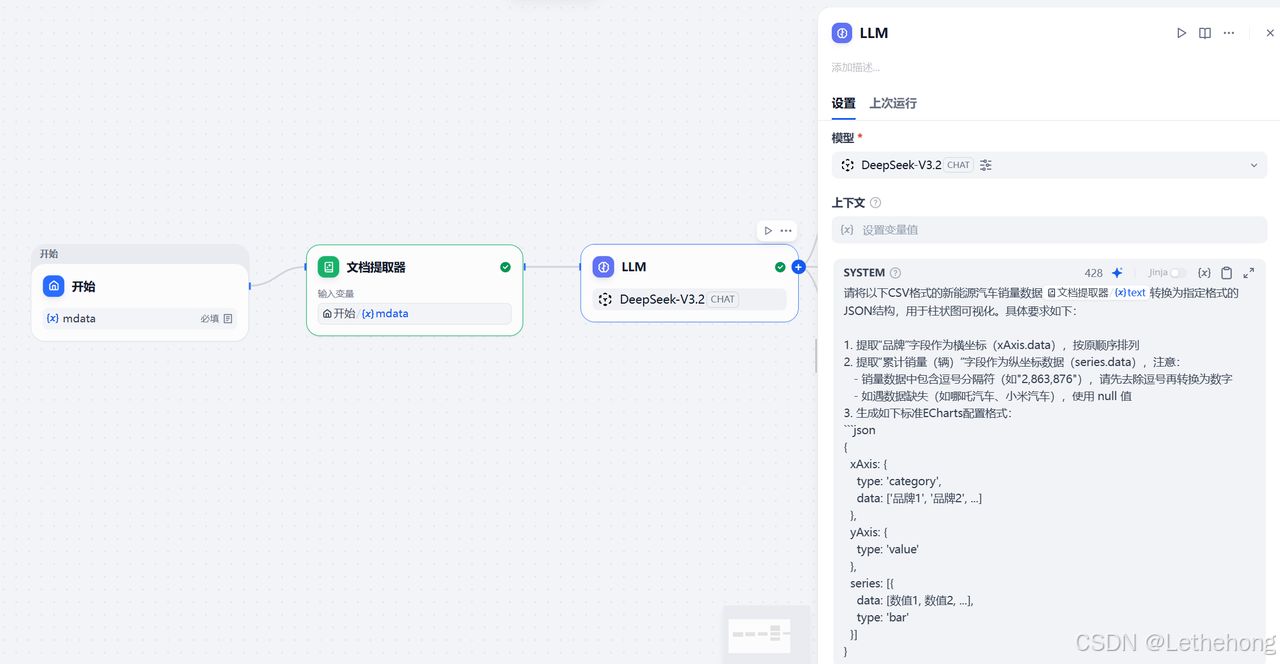
第四步:添加参数提取器(分离 x 轴与 y 轴数据)
配置目的
将 LLM 输出的 JSON 数据拆分为 x 轴(品牌名称)和 y 轴(销量数值)两类独立数据,便于柱状图节点直接调用,避免数据格式混淆。
具体操作
-
并行添加两个 "参数提取器" 节点,分别命名为 "参数提取器 - 圆柱数据"(处理 y 轴)和 "参数提取器 - X 轴数据"(处理 x 轴);
-
两个节点的输入变量均关联 LLM 的
(x) echardata变量; -
分别编写提取指令:
-
圆柱数据提取器(y 轴):
任务1:提取JSON格式数据中的series.data数据值,返回float类型数据,多个数值之间用";"分隔(格式:数值1;数值2;...); 任务2:若数据中存在null值,自动转换为0; 任务3:确保输出仅包含数值和分隔符,无其他多余字符。 -
X 轴数据提取器(x 轴):
提取JSON格式数据中的xAxis.data值,返回字符串类型,多个品牌名称之间用";"分隔(格式:'品牌1';'品牌2';...); 要求:保留品牌名称的原始字符,不得修改或简化。
-
-
配置输出变量:
-
圆柱数据提取器输出:
(x) seriesData -
X 轴数据提取器输出:
(x) xAxisData
-
示意图说明
示意图展示了两个参数提取器的配置界面,包括提取指令编辑框、输入变量关联、输出变量定义等,明确了数据提取的格式要求,确保拆分后的数据可直接用于柱状图生成。
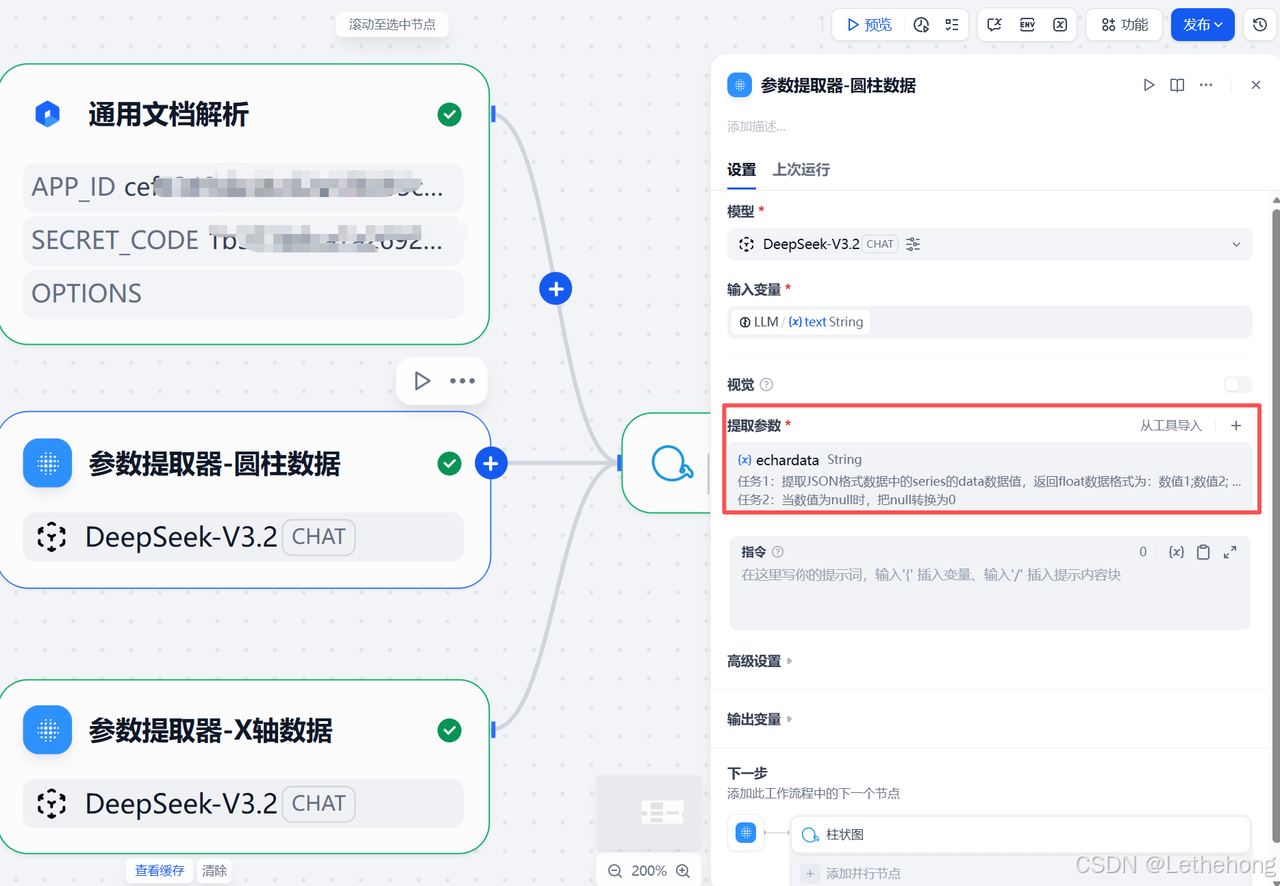
第五步:配置柱状图与直接回复(可视化呈现)
配置目的
将拆分后的 x 轴和 y 轴数据整合,生成标准柱状图,并通过 "直接回复" 功能向用户展示可视化结果。
具体操作
-
在两个参数提取器节点后添加 "柱状图" 节点;
-
输入变量关联:
-
标题:填写 "中国大陆新能源汽车品牌销量情况"(可自定义修改);
-
数据(y 轴):关联 "参数提取器 - 圆柱数据" 的
(x) seriesData变量(数值之间用 ";" 分隔); -
x 轴:关联 "参数提取器 - X 轴数据" 的
(x) xAxisData变量(品牌名称之间用 ";" 分隔);
-
-
开启 "直接回复" 功能,设置回复格式为 "图表 + 文字说明",文字说明可自定义(如 "以下为中国大陆新能源汽车品牌销量柱状图,数据来源于您上传的文档");
-
配置异常处理:选择 "无"(若前面节点已配置重试机制,此处可简化处理)。
示意图说明
示意图展示了柱状图节点的配置界面,清晰呈现了标题、x 轴、y 轴数据的关联来源,以及直接回复功能的开启状态,确保最终能向用户输出直观的可视化图表。

四、工作流优势与注意事项
核心优势
-
多格式兼容:支持图片、PDF 等文档的本地上传和在线链接上传,适配多种数据存储场景;
-
自动化程度高:从数据提取、格式转换到图表生成全程无需手动干预,大幅提升数据处理效率;
-
数据精准性强:通过 LLM 提示词约束和参数提取器规则,确保销量数据格式统一(去除逗号、处理缺失值),图表生成无误差;
-
易上手操作:所有配置步骤均基于可视化界面,无需编写复杂代码,适合非技术人员使用。
注意事项
-
安全保密:API Key、x-ti-app-id、x-ti-secret-code 等凭证具有账号完全权限,需妥善保存,严禁公开分享或上传至公共平台;
-
文档格式要求:上传的文档需包含 "品牌" 和 "累计销量(辆)" 字段,数据格式建议为 CSV 或表格类结构,避免无规则文本导致提取失败;
-
数据范围提示:销量数据若超过 4096 字符(模型上下文长度),建议拆分文档上传,确保 LLM 能完整处理;
-
异常排查:若图表生成失败,可依次检查文档提取是否成功、LLM 输出的 JSON 格式是否标准、参数提取器指令是否正确,或通过 "查看缓存" 功能定位问题。
五、总结
本工作流通过 Dify 平台整合 TextIn 文档解析插件与 DeepSeek-V3.2 LLM 模型,构建了一套 "上传 - 提取 - 转换 - 可视化" 的全流程自动化方案,可快速处理新能源汽车销量数据并生成专业柱状图。无论是汽车行业从业者进行市场分析,还是数据分析师整理汇报材料,都能通过该工作流大幅节省手动处理数据的时间,提升工作效率。后续可根据需求扩展功能,如支持更多数据格式(Excel、Word 表格)、添加数据筛选条件、生成多维度图表(折线图、饼图)。