🚀 作者 :"大数据小禅@yopai"
🚀 专栏简介 :本专栏后续将持续更新大模型相关文章,从开发到微调到RAG、多Agent等,个V: 【yopa66】交流,持续分享前沿AI实战。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
Transformer入门篇
如果你曾经好奇过ChatGPT、Claude这些AI是怎么"学会"和人类对话的,这篇文章会给你一个完整的答案。
写在前面
大语言模型(LLM)已经从实验室走进了千家万户。但很多人在使用这些工具时,可能从来没想过一个问题:这些模型到底是怎么训练出来的?
其实,训练一个大语言模型就像培养一个学生:先让他读完所有能找到的书**(预训练),再教他怎么好好回答问题 (监督微调),最后通过反馈让他变得更懂人心(强化学习)**。这篇文章就简单聊一下这个话题。
大模型的本质:一个超级"接龙游戏"
在深入训练流程之前,我们得先理解大模型到底在做什么。
很多人以为大模型是一个"搜索引擎",能从某个数据库里找答案。其实不是的。大模型本质上是一个生成模型 ,它做的事情特别简单------预测下一个字。
想象一下古诗接龙:
白日 → 依 → 山 → 尽你给模型"白日",它根据学到的语言规律,判断下一个字最可能是"依",然后是"山",然后是"尽"...一个字一个字往外蹦,直到生成完整的句子。
这就是所谓的自回归预测 (Auto-regressive Prediction),GPT系列、Llama、Qwen、DeepSeek用的都是这套路子。
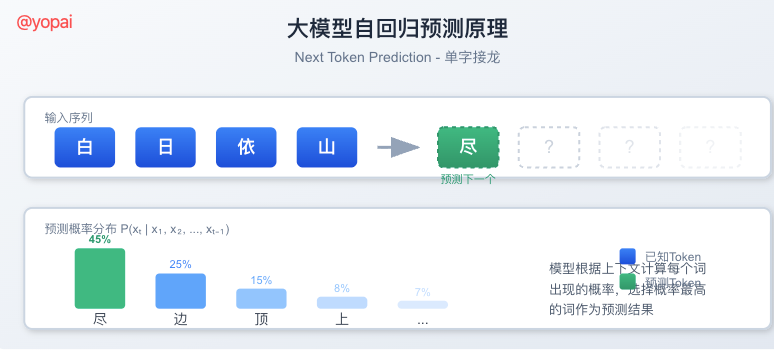
听起来简单对吧?但这个"接龙游戏"要玩得好,需要模型真正理解语言的规律。而要理解语言,就得读海量的文本------这就是预训练要干的事。
训练的三个阶段:从学生到专家
大模型的训练分为三个主要阶段,每个阶段解决不同的问题:
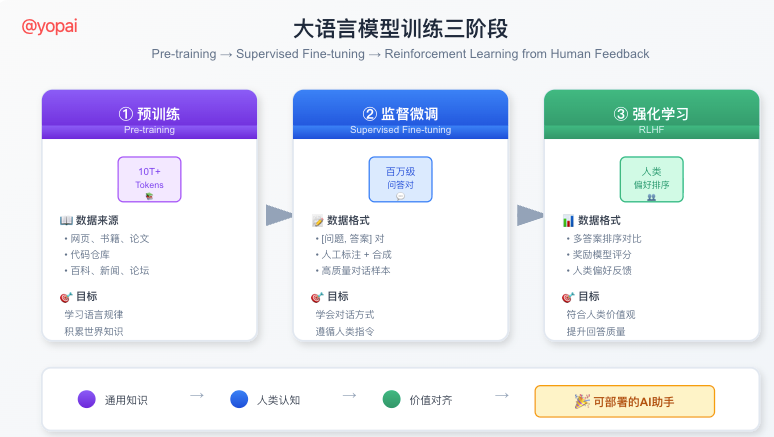
第一阶段:预训练(Pre-training)------海量阅读
预训练是整个训练过程中最**"烧钱"**的阶段。以GPT-3为例,它有1750亿个参数,用了超过1万张A100显卡训练了一个多月,光电费就是天文数字。
预训练的目标
预训练属于无监督学习(或者叫自监督学习),不需要人工标注答案。模型的任务就是:给定一段文本的前半部分,预测接下来的内容。
举个例子:
输入:今天天气真
模型预测:不错 → , → 我 → 决定 → 出去 → 走走 → 。通过这种方式,模型学会了:
- 语言建模:掌握语言的统计规律(比如"今天天气"后面大概率接形容词)
- 上下文理解:知道前面说了什么会影响后面的内容
- 世界知识:从文本中吸收各种事实性知识
预训练数据从哪来?
训练数据的规模通常在万亿token级别(1 token ≈ 0.75个英文单词或0.5个中文字):
| 模型 | 数据规模 | 语言覆盖 | 主要来源 |
|---|---|---|---|
| Llama 3 | 15万亿tokens | 8种语言 | Common Crawl、GitHub、Wikipedia、书籍 |
| Qwen 2.5 | 18万亿tokens | 29种语言 | 中文网页、百科、代码、多语言混合 |
| DeepSeek | 15万亿tokens | 多语言 | 网页、代码库、数学/专业文献 |
这些数据来源五花八门:网页、书籍、论文、代码仓库、百科全书、新闻、论坛帖子...几乎涵盖了人类知识的方方面面。
数据清洗:垃圾进垃圾出
数据量大不代表质量高。互联网上充斥着广告、重复内容、乱码、低质量文本,直接拿来训练会把模型教坏。所以数据清洗是必不可少的步骤:
1. 低质过滤
可以用分类器自动识别低质量文本,也可以用启发式规则:
- 过滤掉HTML标签、脚本代码
- 删除广告和推广内容
- 移除乱码和不可读文本
- 剔除过短或过长的异常文本
2. 去重处理
重复内容会导致模型"偏科",对某些内容过度拟合。去重通常在三个层面进行:
文档级去重:删除完全相同或高度相似的文档
句子级去重:移除重复出现的长句子
数据集级去重:确保训练集和验证集没有重叠一个常用的技术是SimHash,它能快速判断两个文档是否相似。
3. 隐私脱敏
训练数据中可能包含电话号码、邮箱地址、身份证号等敏感信息。通过正则表达式匹配这些模式,替换成占位符:
原始:我的电话是13812345678
处理后:我的电话是[PHONE]预训练的技术细节
位置编码:让模型知道"谁在前谁在后"
Transformer模型本身不知道token的顺序。比如"猫追狗"和"狗追猫",如果没有位置信息,模型看到的是一样的。(transformer相关文章可以看我的历史文章)
RoPE(旋转位置编码) 是目前主流的解决方案。它把位置信息编码到注意力计算中,让模型天然知道每个token在句子中的位置。
不同模型还会做一些优化来支持更长的上下文:
- Qwen:使用NTK-aware插值,支持32K上下文
- DeepSeek:使用YaRN插值,支持128K上下文
- Llama:三阶段渐进扩展到128K
多Token预测(MTP):一次预测多个字
传统方法一次只预测一个token。DeepSeek提出了多Token预测,让模型同时预测接下来的多个token。
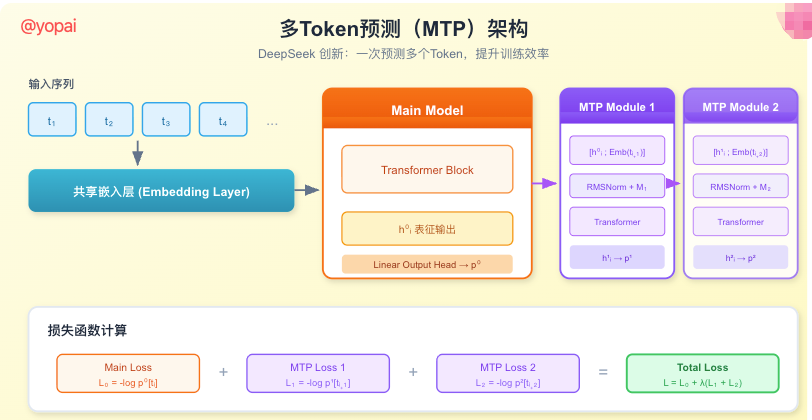
MTP的核心思想是:在主模型之外,添加多个预测模块。每个模块的输入依赖前一个模块的输出,形成一个链式结构。
这样做的好处是:
- 模型必须学习更远的依赖关系
- 训练效率更高(一次前向传播可以计算多个损失)
- 推理时可以用于投机解码,加快生成速度
第二阶段:监督微调(SFT)------学会好好说话
预训练完成后,模型已经"知道"了很多东西,但它还不太会和人对话。你问它"什么是机器学习?",它可能会接着说"是一种...机器学习是一种...机器学习可以...",不断重复或者跑题。
监督微调的目的就是教模型怎么当一个好助手。
训练数据格式
SFT使用的是人工标注的问答对:
json
{
"question": "什么是机器学习?",
"answer": "机器学习是人工智能的一个分支,它让计算机能够从数据中自动学习规律,而不需要被明确编程。简单来说,就像教一个孩子认识猫------你给他看很多猫的照片,他慢慢就学会了什么样的动物是猫。"
}这些数据规模通常在百万条级别,比预训练数据小得多,但每条都经过精心设计。
数据来源
SFT数据主要有两个来源:
1. 人工标注
雇佣专业的标注员,给各种问题写高质量的回答。这种方式成本高,但质量有保证。
2. 数据合成
用已有的大模型生成回答,再让人类筛选和修改。这种方式可以快速扩大数据量。
一个著名的例子是Alpaca项目,斯坦福用GPT-3.5生成了52K条指令数据,成本只花了几百美元。
第三阶段:强化学习(RLHF)------变得更懂人心
即使经过SFT,模型的回答可能还是存在问题:有时候回答正确但表达啰嗦,有时候用词太学术化听不懂,有时候态度冷冰冰的...
这些问题很难用明确的规则描述,但人类一眼就能判断好坏。于是,人类反馈强化学习(RLHF) 应运而生。
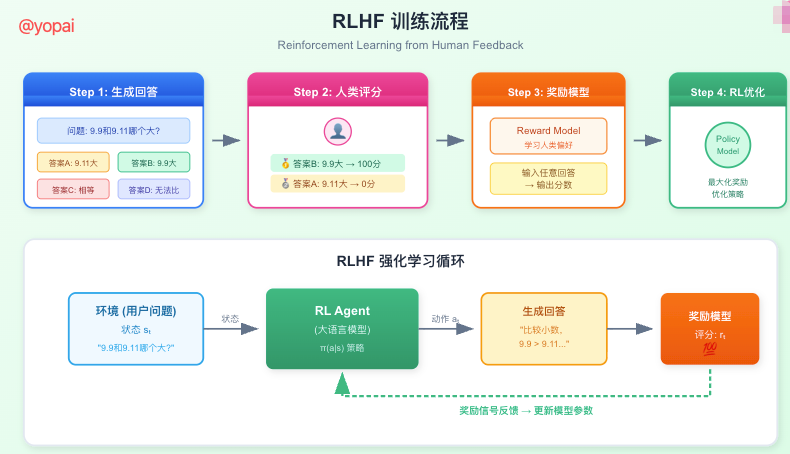
RLHF的工作原理
- 生成多个回答:对于同一个问题,让模型生成多个不同的回答
- 人类排序:让人类标注员给这些回答排序,选出最好的和最差的
- 训练奖励模型:用这些排序数据训练一个"评委"模型,它能给任意回答打分
- 强化学习优化:用奖励模型的分数作为反馈,优化原始模型
举个具体的例子:
问题:9.9和9.11哪个大?
回答A:9.11更大
回答B:9.9更大
人类反馈:回答B得100分,回答A得0分
模型学到:比较小数要先看整数部分,再依次比较小数各位奖励模型的设计
奖励模型是RLHF的核心。训练数据的格式通常是:
[问题, 答案1-得分, 答案2-得分, 答案3-得分, ...]奖励模型学习预测人类的偏好,然后用这个预测来指导主模型的优化。
从RLHF到自我强化
DeepSeek在RLHF基础上更进一步,引入了深度推理思维链。
传统方法对于"9.9和9.11哪个大"这种问题,模型可能直接给出答案。但DeepSeek要求模型像人类一样,先思考比较方法,再一步步分析:
思考过程(Chain of Thought):
1. 首先回忆小数比较的方法
2. 小数比较应该先看整数部分
3. 两个数整数部分都是9,相等
4. 再比较小数部分,第一位分别是9和1
5. 9 > 1,所以9.9的十分位更大
6. 因此9.9 > 9.11
最终答案:9.9更大这种方式让模型的推理过程透明化,也更容易发现和修正错误。
大模型的评估体系
训练完成后,怎么知道模型好不好?这就需要一套完善的评估体系。
评估的三种方式

1. 自动评测
自动评测效率高、可复现,适合快速迭代。常用指标包括:
困惑度(Perplexity)
衡量模型预测下一个词的不确定性。值越低,说明模型对语言规律掌握得越好。
计算方式简单来说就是:模型看到一段文本后,对下一个词的预测准不准。如果每次都猜对,困惑度就低;如果经常猜错,困惑度就高。
文本匹配指标
- BLEU:主要用于机器翻译,看生成的译文和参考译文有多少词重合
- ROUGE:主要用于文本摘要,看生成的摘要覆盖了多少原文要点
分类准确率
对于问答任务,直接看模型的回答对不对。比如选择题,答对了就是1分,答错了就是0分。
2. 主观评测
有些东西很难用数字衡量:回答流不流畅?语气友不友好?表达自不自然?这些需要人来判断。
主观评测通常让多个评审员独立打分,然后取平均。评估维度包括:
| 维度 | 评估内容 |
|---|---|
| 流畅性 | 语法是否正确,表达是否自然 |
| 相关性 | 回答是否切题,有没有答非所问 |
| 事实性 | 内容是否真实准确 |
| 安全性 | 有没有偏见、歧视或有害内容 |
现在也经常用GPT-4这样的强模型来当"评委",代替人工评分。虽然不如人工准确,但成本低很多。
3. 基准测试
基准测试通过标准化的数据集来横向对比不同模型。主流的基准包括:
| 测试集 | 评估能力 | 规模 |
|---|---|---|
| MMLU | 57个学科的知识广度 | 1.5万选择题 |
| GSM8K | 小学数学推理 | 8500道应用题 |
| HumanEval | 代码生成能力 | 164个编程任务 |
| C-Eval | 中文知识理解 | 1.3万选择题 |
代码能力评估
代码能力是大模型的一个重要应用场景。评估方式和普通文本有些不同。
Pass@K指标
这是代码评估最常用的指标。让模型生成K次代码,只要有一次能通过测试用例就算成功。
python
# HumanEval示例任务
def has_close_elements(numbers: list, threshold: float) -> bool:
"""
检查列表中是否有两个数的差小于阈值
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
# 模型需要补全这个函数主流代码测试集
- HumanEval:164个手写的Python函数补全任务
- MBPP:1000个入门级Python编程问题
- FullStackBench:覆盖前端、后端、ML等11类场景,16种语言
数学能力评估
数学推理是检验模型逻辑能力的试金石。
评估维度
| 维度 | 内容 | 示例 |
|---|---|---|
| 基础计算 | 四则运算、解方程 | 计算 (2.5+41)×80% |
| 逻辑推理 | 多步骤推导 | 小明有12个苹果,吃掉1/3,又买来5个,现有多少? |
| 高阶数学 | 微积分、概率 | 计算∫x²dx从0到1 |
主流数学测试集
- GSM8K:8500道小学数学题,需要2-8步推理
- MATH:12500道竞赛级别数学题,含几何、数论等
- MathEval:整合19个数据集,从K12到大学数学
语言理解评估
语言理解是大模型的基础能力,评估任务包括:
- 分类任务:情感分析、意图识别
- 问答任务:从文档中找答案、开放式问答
- 推理任务:自然语言推理、因果推理
主流测试集:
| 类型 | 测试集 | 特点 |
|---|---|---|
| 通用理解 | GLUE/SuperGLUE | 英文NLU基准 |
| 中文专项 | C-Eval/CMMLU | 中文知识与文化 |
| 多语言 | XTREME | 40+语言跨语言迁移 |
综合评测榜单
如果想快速了解各个模型的综合实力,可以参考这些榜单:
SuperCLUE
国内权威的中文大模型评测基准,由清华、智谱等机构推动。评估维度包括数学推理、科学推理、代码生成、智能体能力等。
访问地址:cluebenchmarks.com/stac/superclue.html
OpenCompass
开源的大模型评测框架,支持自动化测评流程:配置→推理→评估→可视化。
核心特点:
- 开源可复现
- 支持分布式评测
- 覆盖多种评测范式
写在末尾
大语言模型的训练是一个精心设计的过程:
- 预训练让模型阅读海量文本,学会语言规律和世界知识
- 监督微调教模型如何当一个好助手,按照人类期望的方式回答问题
- 强化学习通过人类反馈,让模型变得更懂人心
评估方面,自动评测、人工评测、基准测试三种方式各有所长,实际应用中往往需要组合使用。
大模型的发展日新月异,但这套"预训练→SFT→RLHF"的框架目前仍是主流。理解这个框架,就理解了大模型技术的核心。
这篇文章是大模型预训练的一个简单入门了解,后面会更新更多深入的内容。