文章目录
- 一、Transformer的PyTorch实现
-
- [1.1 PyTorch中的Transformer层](#1.1 PyTorch中的Transformer层)
- [1.2 Encoder-Only任务下的Transformer实战](#1.2 Encoder-Only任务下的Transformer实战)
-
- [1.2.1 Encoder-Only架构](#1.2.1 Encoder-Only架构)
-
- [1.2.1.1 Embedding层与Encoder数据输入](#1.2.1.1 Embedding层与Encoder数据输入)
- [1.2.1.2 位置编码的实现与技巧](#1.2.1.2 位置编码的实现与技巧)
- [1.2.1.3 从0实现Encoder-Only架构](#1.2.1.3 从0实现Encoder-Only架构)
- 二、情感分析案例实战
-
- [2.1 情感分类任务的数据准备与数据预处理](#2.1 情感分类任务的数据准备与数据预处理)
-
- [2.1.1 认识nltk](#2.1.1 认识nltk)
- [2.1.2 认识sentence_polarity数据](#2.1.2 认识sentence_polarity数据)
- [2.1.3 构建词汇表](#2.1.3 构建词汇表)
- [2.2 创建训练/测试数据集](#2.2 创建训练/测试数据集)
- [2.3 模型构建](#2.3 模型构建)
-
- [2.3.1 加载数据](#2.3.1 加载数据)
- [2.3.2 定义Transformer中的各个结构](#2.3.2 定义Transformer中的各个结构)
-
- [2.3.2.1 位置编码](#2.3.2.1 位置编码)
- [2.3.2.2 构建Transformer模型](#2.3.2.2 构建Transformer模型)
- [2.4 训练过程](#2.4 训练过程)
- [2.5 测试过程](#2.5 测试过程)
- 三、Decoder-Only的文本生成实战
-
- [3.1 认识数据](#3.1 认识数据)
- [3.2 抽取样本](#3.2 抽取样本)
- [3.3 数据导入与数据预处理](#3.3 数据导入与数据预处理)
-
- [3.3.1 观察数据](#3.3.1 观察数据)
- [3.3.2 段落重组/平衡句子长度](#3.3.2 段落重组/平衡句子长度)
- [3.3.3 处理停用词和标点符号](#3.3.3 处理停用词和标点符号)
- [3.3.4 构建词汇表](#3.3.4 构建词汇表)
- [3.3.5 将分词后的文本序列(chunks)转换成对应的数字编码序列(ordinal_token)](#3.3.5 将分词后的文本序列(chunks)转换成对应的数字编码序列(ordinal_token))
- [3.4 将数据转换为Decoder-Only算法可以识别的结构](#3.4 将数据转换为Decoder-Only算法可以识别的结构)
-
- [3.4.1 将数据转变为与PyTorch兼容的结构](#3.4.1 将数据转变为与PyTorch兼容的结构)
- [3.4.2 经过DataLoader将数据进行分批处理,包括但不限于:](#3.4.2 经过DataLoader将数据进行分批处理,包括但不限于:)
- [3.5 Decoder-Only Transformer架构](#3.5 Decoder-Only Transformer架构)
-
- [3.5.1 构造位置编码](#3.5.1 构造位置编码)
- [3.5.2 两大掩码函数](#3.5.2 两大掩码函数)
- [3.5.3 构造Decoder-only架构](#3.5.3 构造Decoder-only架构)
- [3.5.4 验证网络可以跑通](#3.5.4 验证网络可以跑通)
- [3.6 生成式算法的训练与预测](#3.6 生成式算法的训练与预测)
-
- [3.6.1 算力租用](#3.6.1 算力租用)
- [3.6.2 训练阶段](#3.6.2 训练阶段)
- [3.6.3 测试阶段](#3.6.3 测试阶段)
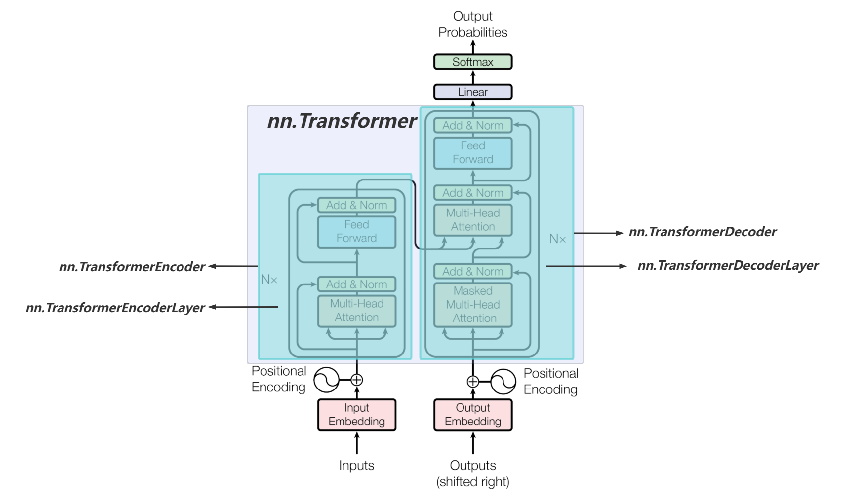
一、Transformer的PyTorch实现
1.1 PyTorch中的Transformer层
| 类名称 | 作用 |
|---|---|
| nn.Transformer | 不带输入与输出层的Transformer模型,同时具备编码器和解码器 |
| nn.TransformerEncoder | Transformer编码器的堆叠层,可以控制Nx的具体数字,要几层Transformer |
| nn.TransformerDecoder | Transformer解码器的堆叠层,可以控制Nx的具体数字,要几层Transformer |
| nn.TransformerEncoderLayer | Transformer编码器层,自注意力和前馈网络的组成 |
| nn.TransformerDecoderLayer | Transformer解码器层,自注意力、编码器-解码器注意力和前馈网络组成 |
| nn.MultiheadAttention | 多头注意力机制 |
| nn.LayerNorm | 层归一化 |
| nn.Embedding | 嵌入层,用于将输入序列转换成嵌入表示 |
nn.MultiheadAttention: 这个模块实现了多头注意力机制,这是Transformer模型的核心组件之一。多头注意力允许模型在不同的位置同时处理来自序列不同部分的信息,这有助于捕捉序列内的复杂依赖关系。
nn.LayerNorm: 层归一化(Layer Normalization)通常用在Transformer的各个子层的输出上,有助于稳定训练过程,并且提高了训练的速度和效果。
nn.Embedding:一个预训练好的语义空间,它将每个标记(如单词、字符等)映射到一个高维空间的向量。这使得模型能够处理文本数据,并为每个唯一的标记捕获丰富的语义属性。嵌入层通常是自然语言处理模型的第一层,用于将离散的文本数据转化为连续的向量表示。其输入是索引列表,输出是对应的嵌入向量。
nn.Transformer.generate_square_subsequent_mask:掩码函数。用于生成一个方形矩阵,用作Transformer模型中自注意力机制的上三角遮罩。这个遮罩确保在序列生成任务中,例如语言模型中,任何给定的元素只会考虑到序列中先于它的元素(即它只能看到过去的信息,不能看到未来的信息)。这种掩码通常在解码器部分使用,防止在预测下一个输出时"作弊"。具体来说,该函数创建了一个方阵,其中对角线及其以下的元素为0(表示可以"看到"这些位置的元素),其余元素为负无穷大(在softmax之前应用,表示位置被屏蔽,不应该有注意力权重)。代码如下:
python
import torch.nn as nn
print(nn.Transformer.generate_square_subsequent_mask(5)) #5是target维度
tensor([[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]])自定义掩码函数:
python
import torch
import torch.nn as nn
#定义填充掩码
def create_padding_mask(seq, pad_token=0):
'''seq: (batch_size, seq_len, embedding_dim)'''
padding_mask = (seq == pad_token).all(dim=-1)
padding_mask = padding_mask.float() * -1e9
return padding_mask
#定义前瞻掩码
def create_look_ahead_mask(seq_len, start_seq=1):
mask = torch.triu(torch.ones((seq_len, seq_len)), diagonal=start_seq) #上三角矩阵
mask = mask.float() * -1e9
return mask #(seq_len, seq_len)
src = torch.rand(32, 10, 512) #(batch_size, seq_len, input_dim)
src_key_padding_mask = create_padding_mask(src, pad_token=0)
print(src_key_padding_mask.shape)
#(32, 10)
src_mask = create_look_ahead_mask(10, start_seq=1) #对于encoder的输入很少使用前瞻掩码
print(src_mask.shape)
#(10, 10)- torch.nn.TransformerEncoderLayer参数介绍
| 实例化前的参数名称 | 说明 |
|---|---|
| d_model | 输入的嵌入维度(embedding的特征维度) |
| nhead | 多头注意力机制中的头数,在代码中通常表示为num_heads |
| dim-feedforward | 前馈网络的隐藏层维度,默认值为2048 |
| dropout | dropout概率值,默认为0.1。在Transformer架构图中虽然没有展现dropout层,但现在业内习惯于将Dropout层放置在每一个复杂结构之后,在Encoder中,Dropout出现在自注意力层后、残差链接之前,也出现在前馈神经网络后、残差链接之前 |
| activation | 激活函数,默认为relu |
| Layer_norm_eps | 层归一化的 epsilon 值,默认值为 1e-05 |
| batch_first | 如果为 True,则输入和输出张量的形状为 (batch_size, seq_len, feature),否则为 (seq_len, batch_size, feature),默认值为 False |
| norm_first | 如果为 True,则执行前馈网络之前进行层归一化,默认值为 False |
| bias | 如果为 True,则在线性层中使用偏置,默认值为 True |
| device | 指定层的设备,默认值为 Non |
| dtype | 指定层的数据类型,默认值为 Non |
python
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True)
out = encoder_layer(src)
print(out.shape)
#torch.Size([32, 10, 512])torch.nn.TransformerEncoderLaye实例化之后可以输入的内容有:
| 实例化后的参数名称 | 说明 |
|---|---|
| src | 输入到编码器的序列 |
| src_mask | 输入序列的掩码矩阵(可选),默认接收形状为(seq_len, seq_len)的二维矩阵,通常该参数默认是执行前瞻掩码,在encoder中很少使用 |
| src_key_padding_mask | 输入序列的填充掩码矩阵(可选) ,默认接收形状为(batch_size, seq_len)的二维矩阵,这个参数只提供 给填充掩码矩阵使用。 |
python
output2 = encoder_layer(src, src_key_padding_mask=src_key_padding_mask)
print(output2.shape)
#torch.Size([32, 10, 512])- torch.nn.TransformerDecoderLayer参数介绍
torch.nn.TransformerDecoderLayer与torch.nn.TransformerEncoderLayer的参数基本一致,但是DecoderLayer除了要输入序列之外,还需要输入memory(必填)。
| 实例化前的参数名称 | 说明 |
|---|---|
| tgt | 输入到解码器层的序列(必填),通常来说也就是真实标签 |
| memory | 来自编码器最后一层的序列(必填) |
| tgt_mask | 目标序列的掩码(可选),默认接收形状为(seq_len, seq_len)的二维矩阵,通常该参数默认是执行前瞻掩码 |
| memory_mask | 编码器输出序列的掩码(可选),默认接收形状为(seq_len, seq_len)的二维矩阵,通常该参数默认是执行前瞻掩码,但由于是作用于编码器的结果,因此实际很少使用 |
| tgt_key_padding_mask | 目标序列的填充掩码矩阵(可选),默认接收形状为(batch_size, seq_len)的二维矩阵,这个参数只提供给填充掩码使用 |
| memory_key_padding_mask | 编码器输出序列的填充掩码矩阵(可选),默认接收形状为(batch_size, seq_len)的二维矩阵,这个参数只提供给填充掩码使用 |
python
output3 = decoder_layer(tgt, memory)
print(output3.shape)
#torch.Size([32, 10, 512])| 实例化后的参数名称 | 说明 |
|---|---|
| tgt | 输入到解码器的序列(必填),通常来说也就是真实标签 |
| memory | 来自编码器最后一层的序列(必填) |
| tgt_mask | 目标序列的掩码矩阵(可选),默认接收形状为(seq_len, seq_len)的二维矩阵,通常该参数默认是执行前瞻掩码 |
| memory_mask | 编码器输出序列的掩码矩阵(可选), 默认接收形状为(seq_len, seq_len)的二维矩阵,通常该参数默认是执行前瞻掩码 |
| tgt_key_padding_mask | 目标序列的填充掩码矩阵(可选),默认接收形状为(batch_size, seq_len)的二维矩阵,这个参数只提供给填充掩码使用 |
| memory_key_padding_mask | 编码器输出序列的填充掩码(可选),默认接收形状为(batch_size, seq_len)的二维矩阵,这个参数只提供给填充掩码使用 |
python
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8, batch_first=True)
memory = torch.rand(32, 10, 512)
tgt = torch.rand(32, 10, 512)
output3 = decoder_layer(tgt, memory)
print(output3.shape)
#torch.Size([32, 10, 512])
tgt_mask = create_look_ahead_mask(tgt.shape[1], start_seq=1)
#目标序列前瞻掩码
tgt_key_padding_mask = create_padding_mask(tgt, pad_token=0)
#目标序列的填充掩码
print(tgt_mask.shape)
#torch.Size([10, 10])
print(tgt_key_padding_mask.shape)
#torch.Size([32, 10])
output4 = decoder_layer(tgt, memory, tgt_mask=tgt_mask, tgt_key_padding_mask=tgt_key_padding_mask)
print(output4.shape)
#torch.Size([32, 10, 512])1.2 Encoder-Only任务下的Transformer实战
1.2.1 Encoder-Only架构
Encoder-only架构应该包括如下结构:
- 输入层:输入序列会通过一个嵌入层,将每个词转换为一个向量表示。
- 位置编码:添加位置编码,以保留序列中词的位置信息。
- Transformer编码器:使用多个编码器层堆叠,以处理输入序列。
- 输出层:将编码器输出的表示转换为目标任务所需的输出。
1.2.1.1 Embedding层与Encoder数据输入
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, _freeze=False, device=None, dtype=None)
num_embeddings :词汇表的总长,即词汇表中包含的单词总数量
embedding_dim:每个单词需要被变成的维度,即transformer中的d_model
python
import torch.nn as nn
ebd = nn.Embedding(2000, 512) #通常会设置一个seq_len很长的embedding
input_data = torch.tensor([1, 2, 3, 4, 5]) #seq_len=5
ebd_data = ebd(input_data)
print(ebd_data.shape)
#torch.Size([5, 512])
#假如说有两个序列,每个序列包含5个单词
input_data = torch.tensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])
ebd_data2 = ebd(input_data)
print(ebd_data2.shape)
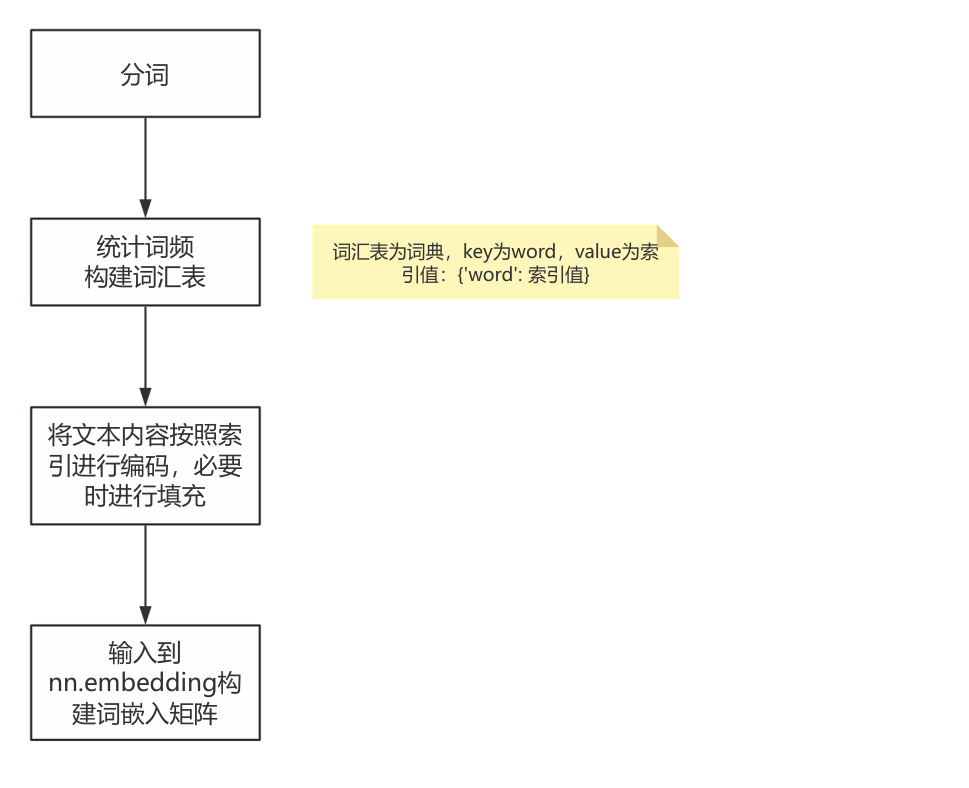
#torch.Size([2, 5, 512]) batch_size=2, seq_len=5, input_dim=512在真实应用场景下,一般都是将文字作为初始数据输入,从一段话变成能够输入到embedding层的信息,还需要经过以下步骤:分词--->制作词汇表--->依据词汇表编码--->填充编码后的序列,形成统一的seq_len。
*注:embedding和transformer的维度顺序要保持一致,即如果batch_first=True,那两个都应该是True,如果是false,两个都应该是false!对于embedding和Transformer来说,它不关注输入的是(batch_size, seq_len),还是(seq_len, batch_size),不管输入的input维度是怎样的,对于embedding只管增加维度,即d_model。因此要十分关注embedding和transformer的维度,是否是batch_size在前。
实际案例:
python
text1 = '''朝堂是谁的朝堂,天下又是谁的天下------庆帝的文武百官绝不敢轻易忤逆或直谏,\\
夹缝里喘息,贪污,结党,企图吞噬一点点这肮脏血腥的权力,却落得个死无葬身之地,\\
他想起赖明成,陈萍萍,那些一个个被处以极刑的大臣,他与承乾自孩提时代就见识过权力只是一把刀子,\\
一场流血,一个个微不足道的死亡,于是他们恐惧又愤恨,他们开始认为阴谋诡计是一种力量,\\
非要一刀见血,才是一次胜利,嬴的人才配活着,与野兽何异?他们在跟谁争,\\
只有庆帝一个人把握着权柄,把它高高挂起,高于良知,高于品德,高于世间万物,\\
他们竟然在争抢这样一个丑陋又卑鄙,散发着腐烂恶臭的东西。'''
text2 = '''人心?那我亏大了,自抬身价罢了。你觉得他们会感激我,那都是一时的,\\
他们求的是自己想要的东西,我满足了一时片刻,他们就想要有别的东西了,\\
这点儿不长久的人心算什么人心。你看那些古来文人大家,那庄墨韩,人人追捧,\\
高高在上,不容亵渎,一字换一城也毫不夸张,是笔墨纸张值钱,还是他们的名气?\\
就像是最近给你送礼攀关系那些人一样的,他们为的不是一时的东西,我也不能做那一\\
时的玩意儿。"李承泽收回目光,转过身来,他握紧了自己的一双手,直视着谢必安冰冷\\
宛如冬夜般的眼睛,"必安,你得明白,东宫太子有父母,有名头,有朝臣,陛下,\\
拥有这个天下的人和财权,我只有我自己,但是我要让你知道的是,这些他们有的,\\
不见得一直有,我依然有我自己。 '''
#1、使用jieba进行分词,要对所有的文本进行分词
words = jieba.lcut(text1 + "" + text2)
print(len(words))
#391
#2、统计词频并生成词汇表
word_counts = Counter(words) #统计词频的时候就会顺便给每个单词建立索引值
print(word_counts.items())
#其格式是:[('word', 索引值)]
vocab = {word: idx for idx, (word, _) in enumerate(word_counts.items(), 1)} # 从1开始编码,0留给padding
#print(vocab)
#vocab:词典格式
#{key为word,value为索引值}
##是词汇表,包含了每个词和对应的索引
#3、将分词结果转换为索引序列
texts = []
max_len = 0
for text in [text1, text2]:
#将编码映射到每个词上
encoded_sequence = [vocab[word] for word in jieba.lcut(text)]
#取出vocab词典中的word的value值(也就是索引值),对每段话的每一个单词进行编码,赋予其索引值
texts.append(encoded_sequence)
#将word添加到序列列表中
if len(encoded_sequence) > max_len:
max_len = len(encoded_sequence)
print(max_len)
#220
#print(texts)
#依据max_len对句子进行填充, batch_size=2,分别计算两个text的长度,将短的按照最大序列长度进行填充
sequence = []
for text in texts:
paddind_text = text + [0] * (max_len-len(text))
sequence .append(paddind_text)
#转换成Pytorch中可以识别的tensor张量
sequence = torch.tensor(sequence)
print(sequence.shape)
#torch.Size([2, 220])
#形状为(2, 句子长度)的 PyTorch 张量,其中每个序列都被填充到相同的长度,这就是输入Transformer的数据X
#当然,在Encoder-Only结构中,我们还需要关注标签,我们需要使用dataloder打包标签,给损失函数使用
#embedding编码
ebd = nn.Embedding(2000, 512) #实例化
#我们习惯于构建一个大的embedding张量,然后取出seq_len长度的embedding
#给实例化之后的类赋值
input_embedding = ebd(sequence)
#这就是未来要输入到transformer里的词嵌入矩阵
print(input.shape)
#torch.Size([2, 220, 512])1.2.1.2 位置编码的实现与技巧

python
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
'''
:param d_model: 嵌入矩阵的特征维度
:param dropout: dropoout比例值
:param max_len: 序列最长的长度是多少
:return: 返回是的位置编码
'''
super(PositionalEncoding, self).__init__()
#位置编码作为精确到每一个维度的信息,容易导致过拟合,因此在实际进行编码的时候会加上抗过拟合的dropout
self.dropout = nn.Dropout(p=dropout)
#创建一个空白的编码矩阵,形状为(max_len, d_model)
#通过给空白的位置编码矩阵填上具体的值来与embedding进行相加
pe = torch.zeros(max_len, d_model)
#接下来开始生成正余弦编码公式中的各元素
#先创建位置索引(pos),shape为(max_len, 1)
postion = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
#计算公式中的分母
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
#计算出正余弦值,并赋值给原本设置好的位置编码矩阵
pe[:, 0::2] = torch.sin(postion * div_term)
#计算出余弦位置编码,并赋值给原本的位置编码
pe[:, 1::2] = torch.cos(postion * div_term)
#使用unsqueeze添加batch维度,将原本二维的结构转变为三维,形状为(1, max_len, d_model)
#使用transpose交换维度,最终得到的pe结构为(max_len, 1, d_model),这是batch_first=False下的结构
pe = pe.unsqueeze(0).transpose(0, 1)
#将位置编码矩阵注册为模型的缓冲区,不作为模型参数学习更新
#同时,这一步相当于定义了self.pe,但规定pe不参与模型参数更新
self.register_buffer('pe', pe)
def forward(self, x):
'''
:param x: 参数x(Tensor),embedding后的张量,形状为(batch_size, seq_len, d_model)
:return: 添加了位置编码的输入张量,形状不变
'''
x = x + self.pe[:x.size(0), :]
#应用dropout并返回
return self.dropout(x)
pos_ebd = PositionalEncoding(d_model=512, dropout=0.1, max_len=220)
positional_embedding = pos_ebd(input_embedding)
print(positional_embedding.shape)
#torch.Size([2, 220, 512])1.2.1.3 从0实现Encoder-Only架构
- 构建Transformer模型
python
class TransformerEncoderModel(nn.Module):
def __init__(self, input_dim, d_model, nhead, num_encoder_layers, dim_feedforward, dropout=0.1):
'''
:param input_dim: 输入的词汇表大小
:param d_model: 嵌入向量的维度
:param nhead: 多头注意力机制中的头数
:param num_encoder_layers: 编码器层的数量
:param dim_feedforward: 前馈网络的隐藏层维度
:param dropout: dropout比例
'''
super(TransformerEncoderModel, self).__init__()
#输入层,将输入的词汇索引转换为嵌入向量
self.embedding = nn.Embedding(input_dim, d_model)
#位置编码层,添加位置信息
self.pos_encoder = PositionalEncoding(d_model, dropout)
#定义单个Transformer编码器层
encoder_layers = nn.TransformerEncoderLayer(d_model,
nhead,
dim_feedforward,
dropout,
batch_first=True)
#堆叠多个Transformer编码器层
self.transformer_encoder = nn.TransformerEncoder(encoder_layers,
num_layers=num_encoder_layers)
#保存d_model维度,可能回用于后续计算
self.d_model = d_model
#输出层,将Transformer编码器的输出转换成目标任务的输出
#用于回归任务
self.fc_out = nn.Linear(d_model, 1)
'''
#用于二分类任务
self.fc_out = nn.Sequential(
nn.Linear(d_model, 1),
nn.Sigmoid()
)
#用于多分类任务
self.fc_out = nn.Sequential(
nn.Linear(d_model, num_classes),
nn.Softmax(dim=1)
)
'''
def forward(self, src, src_mask=None, src_key_padding_mask=None):
'''
:param src: 输入序列
:param src_mask: 输入序列的前瞻掩码
:param src_key_padding_mask: 输入序列的填充掩码
:return: (batch_size, 1)
'''
#将输入词汇索引转换成嵌入向量,并进行缩放
#Scaled Embedding = Embedding * sqrt(d_model)
#这里为什么要进行缩放?
src = self.embedding(src) * torch.sqrt(torch.tensor(self.d_model), dtype=torch.float32)
#添加位置编码
src = self.pos_encoder(src)
#通过Transformer编码器进行编码
output = self.transformer_encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
#对编码器的输出进行平均池化,获得序列的固定 长度表示
#这一步同样是对Transformer输出数据结构的整合
#如果Encoder的记过是直接给Decoder使用的,很可能不需要这一步骤
output = output.mean(dim=1)
#通过全连接层将固定长度表示转换为目标任务的输出
output = self.fc_out(output)
return output- 验证模型
python
input_dim = 2000
batch_size = 1
seq_len = 220
d_model = 512
nhead = 4
num_encoder_layers = 6
dim_feedforward = 2048
dropout = 0.1
model = TransformerEncoderModel(input_dim,
d_model,
nhead,
num_encoder_layers,
dim_feedforward,
dropout)
#当你的模型输入是(batch_size, seq_len)时,你的填充掩码函数:
def create_padding_mask_2(seq, pad_token=0):
# seq: (batch_size, seq_len)
# 创建一个与输入序列形状相同的掩码
padding_mask = (seq == pad_token).float() * -1e9 # (batch_size, seq_len)
return padding_mask
padding_mask = create_padding_mask_2(sequence, pad_token=0)
print(padding_mask.shape)
#torch.Size([2, 220])
#向前传播
output = model(sequence, src_key_padding_mask=padding_mask)
print(output.shape)
#torch.Size([2, 1])其中,掩码函数做了调整,因为输入由list变为了tensor
python
#依据max_len对句子进行填充, batch_size=2,分别计算两个text的长度,将短的按照最大序列长度进行填充
sequence = []
for text in texts:
paddind_text = text + [0] * (max_len-len(text))
sequence .append(paddind_text)
#转换成Pytorch中可以识别的tensor张量
sequence = torch.tensor(sequence)
print(sequence.shape)
#torch.Size([2, 220])适用于tensor张量的填充掩码函数为:
python
#当你的模型输入是(batch_size, seq_len)时,你的填充掩码函数:
def create_padding_mask_2(seq, pad_token=0):
# seq: (batch_size, seq_len)
# 创建一个与输入序列形状相同的掩码
padding_mask = (seq == pad_token).float() * -1e9 # (batch_size, seq_len)
return padding_mask适用于列表形式的填充掩码函数为:
python
# 定义填充掩码
def create_padding_mask(seq, pad_token=0):
'''seq: (batch_size, seq_len, embedding_dim)'''
padding_mask = (seq == pad_token).all(dim=-1) #整一行所有的数值为0的需要填补
padding_mask = padding_mask.float() * -1e9
return padding_mask二、情感分析案例实战
情感分析是用计算机程序通过分析文本内容来判定其情感倾向(如正面、负面或中性)的技术,它是自然语言处理领域中的一项基本任务,也是因其广泛的应用场景而备受关注的领域。
在使用深度学习技术进行情感分类的各种实践中,Transformer被认为是非常有效的模型。通过训练大量的文本数据,Transformer能够学习复杂的情感表达模型,能够理解和分类各种复杂的情绪表达, 使用不同的语言风格,并处理含糊或隐晦的情感表达。
对Transformer模型来说,情感分类是一个典型的分类任务。这意味着模型需要接受一系列的输入(文本数据),并输出一个分类结果。Transformer中的自注意力机制允许模型在分类时关注到文本中的所有词语,帮助模型理解更复杂的情感表达和语境依赖,使分类结果更加准确和具有深度。在情感分类任务中,Transformer中的编码器用于理解输入的文本,而输出层则直接基于编码后的表示来判定情感类别,因此情感分类是一个只使用编码器,而不是用解码器的架构。
通常来说,一个情感分类任务需要覆盖至少如下流程:
- 数据准备:数据导入、数据认知、分词、构建词汇表、词汇表质量提升、未知词处理、文本编码、编码转嵌入、加入位置编码、数据规范化、设置掩码。
- 模型构建与训练准备:Encoder-Only架构定义、数据分割(训练测试数据分割)、数据分批(依据Dataloader分batch)、批次结构规范化(collate_fn)、优化器、损失函数设置。
- 训练与测试:训练循坏、训练监控与可视化、测试循坏。
2.1 情感分类任务的数据准备与数据预处理
对于任何NLP任务来说,我们都需要对数据进行详细处理、毕竟算法本身无法处理文字数据,而语言数据同时具备时序属性和文字属性,具有复杂的处理流程,其中中文比英文更复杂。本次准备的是基于英文文本的情感分类,使用了自然语言处理库NLTK中的sentence_polarity数据集。NLTK(Nature Language Toolkit)是一个强大的Python库,专门用于处理人类语言数据,广泛应用于自然语言处理(NLP)的研究和教育。本次使用的sentence_polarity数据则是一个经典的英文情感分类数据集。在深度学习汇总,还有大量基于中文的情感分类数据集:
-
中文情感分析综合数据集 (Chinese Sentiment Analysis Dataset, ChnSentiCorp):这是一个广泛使用的中文情感分类数据集,包含酒店、书籍和电子产品的评论,这些评论被标注为正面或负面。
-
豆瓣电影评论数据集:你可以在github找到这个数据集,这个数据集包含大量来自豆瓣网站的电影评论,这些评论被用户标记为推荐(正面)或不推荐(负面)。
-
微博情感分析数据集:你依然可以从github找到这个数据集,这是从新浪微博收集的数据,包括带有情感倾向的微博文本,常用于研究社交媒体上的情感表达。
还有很多其他语言的情感分类数据:
-
IMDb电影评论数据集 (IMDb Movie Review Dataset):包含来自IMDb网站的50,000条电影评论,分为正面和负面两类,是进行情感分析的一个标准数据集。
-
亚马逊商品评论数据集 (Amazon Product Review Dataset):包含数百万用户对亚马逊商品的评论,这些评论被标记有星级,通常用星级来推断评论的情感倾向。
-
斯坦福情感树库 (Stanford Sentiment Treebank, SST):包含电影评论的数据集,特点是每个句子都被分析成语法树,每个节点(句子、短语、单词)都被标注情感,非常适合深入研究语义上的情感分析。
-
Twitter情感分析数据集:包含从Twitter抓取的推文,这些推文被标注为正面、负面或中性,用于研究社交媒体文本的情感倾向。
不难发现,情感分类的数据集基本都来自于对于公开评论、网络评论的收集。随着NLP技术的发展,现在已经较少有仅仅针对情感分析进行学术研究的项目了,情感分类被认为是"自然语言理解"的一个子板块。在NLP的领域,我们会要求模型对语言的理解能力更强。
2.1.1 认识nltk
NLTK(Natural Language Toolkit)是一个用于处理自然语言文本的开源库,广泛用于python语言的自然语言处理(NLP)任务中。它提供了丰富的工具和资源,适用于各种NLP应用,如文本分析、词性标注、语法解析、情感分析等。NLTK提供了一系列自然语言处理工具和应用程序,涵盖多个关键领域,包括:通过图形界面展示语法和词频的分析工具;使用Standford Parser和Earley算法解析自然语言结构;构建和应用统计语言模型,如N-gram;用于文本分类和聚类的机器学习算法,如朴素贝叶斯和K-means;支持多语言词法分析的工具;词性还原和词干提取工具;访问和读取广发语料库的工具;评估解析器和分类器性能的工具;磁性标注和分类工具,如隐马尔科夫大模型和感知机算法;情感分析工具,如VADER;以及用于翻译和跨语言的工具,如BLEU评分系统。这些工具为用户提供了全面的自然语言处理解决方案。
corpus是一个重要的模块(子库),专门用于访问和管理语料库。是NLTK内置的"数字图书馆",里面存放了大量用于语言研究和机器学习的文本数据集。经典的语料库如下所示:

2.1.2 认识sentence_polarity数据
python
import nltk
nltk.download('sentence_polarity') # 首次运行后就可以注释掉这行
from nltk.corpus import sentence_polarity当一个数据集被从语料库中import出来之后,我们可以使用sents()方法来调取出具体句子(虽然大部分时候是分割好的tokens),并使用.categories()方法来查看这个数据集所对应的标签类别:
python
sentences = sentence_polarity.sents()
label_type = sentence_polarity.categories()
print(sentences)
#[['simplistic', ',', 'silly', 'and', 'tedious', '.'], ["it's", 'so', 'laddish', 'and', 'juvenile', ',',.......],.....]
print(label_type)
#['neg', 'pos']查看每个样本对应的标签,需要特殊的指令:
python
#加载句子和标签
# 加载句子和标签
documents = [(list(sentence), category) for category in sentence_polarity.categories()
for sentence in sentence_polarity.sents(categories=category)]
#将句子和标签组成元组形式
#打印几个句子和标签
for doc, label in documents[: 10]:
print('句子:', ''.join(doc))
print('标签:' , label)
'''
句子: simplistic,sillyandtedious.
标签: neg
句子: it'ssoladdishandjuvenile,onlyteenageboyscouldpossiblyfinditfunny.
标签: neg
'''查看数据
python
#加载句子和标签
# 加载句子和标签
documents = [(list(sentence), category) for category in sentence_polarity.categories()
for sentence in sentence_polarity.sents(categories=category)]
#打印几个句子和标签
for doc, label in documents[: 10]:
print('句子:', ''.join(doc))
print('标签:' , label)
'''
句子: simplistic,sillyandtedious.
标签: neg
句子: it'ssoladdishandjuvenile,onlyteenageboyscouldpossiblyfinditfunny.
标签: neg
'''
print(sentences.__len__())
#10662
#一共有1w多个句子,每个句子里包含一串单词,是一个量级较小的数据集
print(sentences[3])#通过索引的方式取出一个句子来查看
#['[garbus]', 'discards', 'the', 'potential', 'for', 'pathological', 'study', ',', 'exhuming', 'instead', ',', 'the', 'skewed', 'melodrama', 'of', 'the', 'circumstantial', 'situation', '.']针对这样的比较规范的数据,我们需要构建训练数据、测试数据集,并且将文本标签转化为数字;然而在进行所有的这些操作之前,我们需要构建该数据对应的词典和词汇表。
2.1.3 构建词汇表
在本次案例中,使用的方法是:词频筛选。词频筛选能够有效减少噪声,提高模型的训练效率和性能。通过统计每个词汇在文本中的出现频率,能够筛选出哪些高频且有价值的词汇,避免稀有词汇进入词汇表。低频次往往是拼写错误、额数符号或不常见的词,这些词汇不仅增加了模型得复杂性,还可能对模型的学习过程产生干扰。通过过滤掉这些低频词汇,不仅能够简化词汇表,减少计算资源的消耗,还能使模型更专注于有用的词汇,从而提升整体的表现,此外,词频较小的词汇意味着更少的参数需要处理, 训练速度也能得到显著提升。因此,词汇频率筛选在构建高质量词汇表时至关重要,是提升模型效率和性能的关键步骤。
Vocab递归编码函数完成词汇表构建
在构建Vocab这个类的时候,我们要思考输入到类的数据有哪些?------原始文字数据、已经分好词的Token,针对这两种数据,需要有不同的预处理方法。
- 原始文字数据 :分词--->统计词频--->词频筛选--->添加未知词--->构建词汇表--->根据词汇表进行编码。
- 已经分好词的Token:添加未知词--->构建词汇表--->根据词汇表进行编码。
不难发现,针对这两种输入类型的处理,有一半以上以上的流程是相同的。基于这样的理解和思考,在Vocab类中构建了两个核心模块:init和build方法。init的流程用于接受原本就是Token的数据,包含添加未知词、词汇表构建两大流程。build方法用于接受text数据,包含分词、词频筛选量大流程。并将词汇表进行编码的流程单独写成类Vocab的方法(method)供调用。
python
from collections import defaultdict, Counter
class Vocab:
'''
能够同时接纳Token和text两种类型的数据
对原始文字数据,调用build方法,进行分词、完成词频筛选
对Token数据,使用init中的流程,完成添加未知词、词汇表构建
建好词汇表后,再调佣单独的方法来进行编码
'''
def __init__(self, tokens = None):
'''
:param tokens: 包含所有token的list,列表本身只能有token本身,而非是包含token的多个句子
'''
self.idx_to_token = list() #列表包含了数据集中的所有单词
self.token_to_idx = dict() #词汇表,不重复的单词及其索引值
if tokens is not None:
if "<unkown>" not in tokens: #如果tokens中不包含未知词"<unk>",则添加"<unk>"
tokens = tokens + ["<unk>"]
# 遍历tokens,将每个token添加到idx_to_token列表,并在token_to_idx字典中映射其索引
# 基于添加了未知词的Tokens,直接创造出列表 + 词汇表
for token in tokens:
self.idx_to_token.append(tokens)
self.token_to_idx[token] = len(self.idx_to_token)
self.unk = self.token_to_idx['<unkown>']
@classmethod
# 调用魔法命令classmethod,这个命令允许我们在不进行实例化的情况下使用类中的方法
# build的输入参数与Vocab本身的init完全不同,因此我们可以运行它被单独调用
def build(cls, text, min_freq=1, reserved_tokens=None):
'''
cls: Vocab类本身,有了cls就可以在不进行实例化的情况下直接调用build功能
:param text: 需要构建词汇表的文本,在对此文本进行词频筛选
:param min_freq: 最小频率,低于该频率预阈值的词会被删除
:param reserved_tokens: 可以选择性输入的"通用词汇表",假设text文本内容太少,reserved_tokens可以帮我们构建更大的词典、从而构建更大的词向量空间
:return: 返回token
'''
#创建一个defaultdict字典,用于统计每个单词的出现频率
token_freqs = defaultdict(int) #个具有默认整数计数的频率统计字典
# 遍历文本中的每个句子,统计每个单词的出现次数
for sentences in text:
for token in sentences:
token_freqs[token] += 1
#创建一个空列表uniq_tokens,用于存储"<unk>"和输入用来保底的reserved_tokens
uniq_tokens = ["<unk>"] + (reserved_tokens if reserved_tokens else [])
#这个列表uniq_tokens就是过滤后的Tokens列表
uniq_tokens += [token for token, freq in token_freqs.items() if freq >= min_freq and token != "<unk>"]
return cls(uniq_tokens)
# 将过滤后的Tokens列表放入cls,也就是Vocab类中
# 这个Token进入到Vocab类之后,会触发init,开始进入init中的流程
# 因此,只要调用build方法,就可以从text构建一组token、并将这组token放入Vocab类
# 这是这个类的"递归"所在,我们可以调用类中的方法来创造类所需的数据类型
# 并在该方法的最后重启这个类
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, token):
return self.token_to_idx.get(token, self.unk)
def convert_tokens_to_idx(self, tokens):
return [self[token] for token in tokens]
def convert_idx_to_token(self, indices):
return [self.idx_to_token[index] for index in indices]当我们的输入数据为Token时,我们可以直接调用Vocab类来同时生成词汇表和词典,当我们输入的数据是text时,我们可以调用build方法,build不仅能够直接将text转变为tokens,还能把tokens放入Vocab类、来生成词汇表和词典。Vocab因此能够同时包容text和tokens两种不同结构的数据。
- init只能接受 单一token list:
python
sentence_polarity.sents()
#我们此时使用的数据,虽然看起来是token但实际上是包含了多个tokens的列表
#因此无法被Vocab的init直接处理
sentence_polarity.sents()[0] #这就是单一token list- build可以接受的文本数据为:
python
text1 = ["我爱中国","我的大好河山"]
text2 = "我爱中国"
text3 = ["我","爱","中","国","我","的","大","好","河","山"]2.2 创建训练/测试数据集
由于polarity数据的数据量比较充足,我们可以将其中的前4000个句子作为训练集来构建数据集。在NLP任务中,训练数据的数量比测试数据小很多是很正常的现象。在分割数据集的 过程中,我们直接使用列表推导式不断从positive和negative两个子集中取出相应的句子,并对每一个句子按字典的方式进行编码。我们定义这个编码函数为load_sentences_polarity,具体代码如下:
python
def load_sentence_polarity():
#导入NLKT的sentence_polarity模块
from nltk.corpus import sentence_polarity
#创建一个词汇表vocab
vocab = Vocab.build(sentence_polarity.sents())
#构建训练数据集
#将正面情感句子标记为0,取前4000个正面句子
#负面情感句子标记为1,取前4000个负面句子
train_data = [(vocab.convert_tokens_to_ids(sentence), 0)
for sentence in sentence_polarity.sents(categories='pos')[:4000]] \
+ [(vocab.convert_tokens_to_ids(sentence), 1)
for sentence in sentence_polarity.sents(categories='neg')[:4000]]
#构建测试数据集
#使用剩余的正面情感句子,标记为0,
#使用剩余的负面情感句子,标记为1
test_data = [(vocab.convert_tokens_to_ids(sentence), 0)
for sentence in sentence_polarity.sents(categories='pos')[4000:]] \
+ [(vocab.convert_tokens_to_ids(sentence), 1)
for sentence in sentence_polarity.sents(categories='neg')[4000:]]
#返回训练集、测试集和vocab类本身
return train_data, test_data, vocab在处理自然语言处理(NLP)任务时,输入的数据常常是可变长度的序列。例如,一些句子可能只有几个单词,而另一些句子可能有几十个单词。在这种情况下,我们需要一种方法来标记哪些时间步是有效的,即哪些时间步对应的是输入序列中的实际单词,哪些时间步是填充(padding)字符。
有效的时间步是指那些在序列中实际包含有意义信息的时间步。例如,对于一个句子 "I love NLP",其有效的时间步是 "I", "love", "NLP",而如果这个句子被填充到一个固定长度,比如 6 个单词的长度,填充后的句子可能是 "I love NLP "。在这种情况下,只有前 3 个时间步是有效的,后面的 3 个时间步是填充字符 ""。
因此在这里,我们需要生成一个布尔掩码,用于标记每个序列中有效的时间步。这个掩码在处理可变长度序列时非常有用,例如在计算模型损失或进行序列模型的计算时,可以用掩码忽略填充字符的位置。
python
def length_to_mask(seq, pad_token=0):
'''
:param seq: (batch_size, seq_len)
:param pad_token:
:return:
'''
# 创建一个与输入序列形状相同的掩码
padding_mask = (seq == pad_token).float() * -1e9 # (batch_size, seq_len)
return padding_mask2.3 模型构建
2.3.1 加载数据
在数据进入Pytorch之前,通常需要对数据进行如下处理:
- 将数据转换为PyTorch可兼容的结构,包括但不限于:
(1)确保数据集拥有__len__ 方法(返回数据集大小)和 getitem 方法(根据索引返回数据)。
(2)数据应该是 torch.Tensor 类型,因为 PyTorch 的大部分操作都是针对张量进行的。如果数据是其他格式(如 NumPy
数组、Pandas DataFrame 等),需要将其转换为 PyTorch 张量。
(3)数据各类预处理:在加载数据之前需要进行归一化或其他基础的预处理操作,以确保数据适合训练,可以在 __getitem__方法中添加这些预处理操作。
python
# 定义TransformerDataset类
# 用于为数据赋予len和getitem属性
# 从而让数据能够适应PyTorch的数据结构
class TransformerDataset(Dataset):
def __init__(self, data):
#初始化数据集,将传入的数据保存在实例变量data中
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]- 经过DataLoader对数据完成分批,包括但不限于:
(1)完成batch分割,将数据集转变为神经网络需要的输入格式
(2)完成padding、裁剪、类型转换等奖数据变得更整齐的预处理操作
python
#定义collate_fn函数,用于在DataLoader中对一个batch的数据进行处理
def collate_fn(examples):
#将每个样本的输入部分转换成张量
inputs = [torch.tensor(ex[0]) for ex in examples]
#转换成列表形式是因为pad_sequence函数要求的,pad_sequence 函数要求输入一个张量列表
# 将每个样本的目标部分转换为长整型张量
targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
#将targets转换成整型数据,是因为损失函数有要求,要求输入整型张量
#pytorch自带的paading工具
inputs = pad_sequence(inputs, batch_first=True)
return inputs, targets
#数据分割
batch_size = 32
train_dataset = TransformerDataset(train_data) #创建训练数据集
test_dataset = TransformerDataset(test_data) #创建测试数据集
train_data_loader = DataLoader(train_data,
batch_size=batch_size,
collate_fn=collate_fn,
shuffle=True)
test_data_loader = DataLoader(test_data,
batch_size= batch_size,
collate_fn=collate_fn,
shuffle=False)2.3.2 定义Transformer中的各个结构
2.3.2.1 位置编码
python
# 定义PositionalEncoding类,用于为输入添加位置信息
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=512, batch_first=True):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 有transpose,代表默认输入数据形状为(seq_len, batch_size, d_model)
# 如果输入结构为(batch_size, seq_len, d_model),则不需要transpose
if batch_first:
pe = pe.unsqueeze(0)
else:
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
self.batch_first = batch_first
def forward(self, x):
# 如果batch_first,则需要截断的是中间的维度
# 且用于中间维度截断的维度是seq_len
if self.batch_first:
x = x + self.pe[:, :x.size(1), :]
else:
# 如果没有batch_first,需要截断的是第一个维度
x = x + self.pe[:x.size(0), :]
return x2.3.2.2 构建Transformer模型
python
# 定义Transformer类,用于实现Transformer模型
class EncoderOnlyTransformer(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_class,
dim_feedforward=256, num_head=2, num_layers=2
, dropout=0.1, max_len=128, activation: str = "relu"
, batch_first = True):
# 调用父类的构造函数
super(EncoderOnlyTransformer, self).__init__()
# 词嵌入层
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 位置编码层
self.position_embedding = PositionalEncoding(embedding_dim, dropout
, max_len
, batch_first = batch_first)
# 编码层与编码层的打包
encoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head
, dim_feedforward
, dropout, activation
, batch_first = batch_first)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
# 输出层,现在是情感分类,二分类任务
#self.output = nn.Sequential(nn.Linear(hidden_dim, num_class)
#,nn.Sigmoid())
self.output = nn.Linear(hidden_dim, num_class)
def forward(self, inputs):
# 如果你希望batch_first=False,你随时可以使用Transpose来进行转置
# 生成填充掩码,现在填充掩码函数
padding_mask = length_to_mask(inputs)
# 获取词嵌入表示
src = self.embeddings(inputs)
# 添加位置编码
src = self.position_embedding(src)
# 通过Transformer编码器进行处理
src = self.transformer(src, src_key_padding_mask=padding_mask)
# 进行平均池化,或者索引
# 经过这一步数据的结构会变为(batch_size,1,input_dimension)
# 因此线性层的hidde_dim维度应该设置为input_dimension
src = src[:,-1,:]
# 通过输出层得到分类结果
output = self.output(src)
#log_softmax函数
log_probs = F.log_softmax(output, dim=-1)
return log_probs2.4 训练过程
python
embedding_dim = 128 # 词嵌入的维度为128
hidden_dim = 128 # 隐藏层的维度为128,同embedding_dim
num_class = 2 # 类别数量为2
batch_size = 32 # 每个批次的大小为32
num_epoch = 15 # 训练的轮数为10
# 加载模型
#device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 选择设备(GPU或CPU)
device = torch.device('cpu')
model = EncoderOnlyTransformer(len(vocab), embedding_dim, hidden_dim, num_class) # 实例化Transformer模型
model.to(device) # 将模型加载到GPU中(如果已经正确安装)
# 训练过程
loss_fn = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率为0.001
# 设置模型为训练模式
model.train()
# 遍历每个epoch
for epoch in range(num_epoch):
total_loss_for_epoch = 0 # 初始化总损失为0
# 遍历每个批次,显示训练进度
for batch in train_data_loader:
# 将输入、长度和目标数据移动到设备上
inputs, targets = [x for x in batch]
# 前向传播得出log softmax结果
log_probs = model(inputs)
# 计算损失
loss = loss_fn(log_probs, targets)
# 清零梯度
optimizer.zero_grad()
# 反向传播、计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 累加损失
total_loss_for_epoch += loss.item()
# 输出每个轮次的总损失
print(f"Loss: {total_loss_for_epoch:.2f}")2.5 测试过程
python
# 测试过程
acc = 0 # 初始化准确率计数器
model.eval()
for batch in test_data_loader: # 遍历每个测试批次
inputs, targets = [x for x in batch] # 将输入、长度和目标数据移动到设备上
with torch.no_grad(): # 禁用梯度计算
output = model(inputs) # 前向传播计算输出
acc += (output.argmax(dim=1) == targets).sum().item() # 计算预测正确的数量并累加
# 输出在测试集上的准确率
print(f"Acc: {acc / len(test_data_loader):.2f}") # 计算并输出测试集上的准确率三、Decoder-Only的文本生成实战
生成式算法在Transformer领域占据了举足轻重的地位,它们极大推动了自然语言处理和生成任务的发展。通过利用Transformer架构中的自注意力机制,生成式算法能够在捕捉长距离依赖关系和上下文信息方面表现出色。它们在文本生成、机器翻译、对话系统等任务中展现强大的能力。如OpenAI的GPT系列模型就是典型代表。生成式算法不仅提高了生成文本的流畅性和连贯性,还在处理复杂的上下文和多样化方面取得显著进步,推动了自然语言生成技术的前沿发展。
适合做为生成式算法训练样本的数据类型包括:
- 文本数据:
书籍和小说 :通常包含丰富的语言表达和上下文信息 ,适合训练语言模型生成连续连贯的文本。
新闻文章 :提供正式和信息密集的内容 ,帮助模型生成结构化和信息准确的文本。
对话数据 :包括聊天记录和对话数据 集,适合训练对话生成模型。
社交媒体帖子 :如推特、博客等,包含多样化的语言风格和主体,适合生成多样化的文本内容。 - 脚本和剧本: 电影、电视剧、戏剧的剧本包含丰富的对话和场景描述,适合对话生成和场景描述生成。
- 技术文档和编程代码:技术文档、API文档和编程代码适合训练代码生成和自动文档生成模型。
- 诗歌和文学作品:这些数据包含独特的语言风格和创意表达,适合生成诗歌和文学作品。
- 法律文书和合同:适合训练法律相关文本的模型。
- 医学文献和病例报告:适合生成医学相关的文本和诊断报告。
- 教学资料和教科书:适合训练教育和教学相关文本生成模型。
- 科学论文和研究报告:适合生成学术文本和研究内容。
以上数据类型都能够为生成式算法提供丰富的语言资源和多样化的上下文信息,有利于提升模型的生成质量和适应性。在收集和使用这些数据时,需注意数据的合法性和隐私保护,确保数据来源的合法合规。
3.1 认识数据
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import numpy as np
import jieba
import re
from collections import defaultdict, Counter
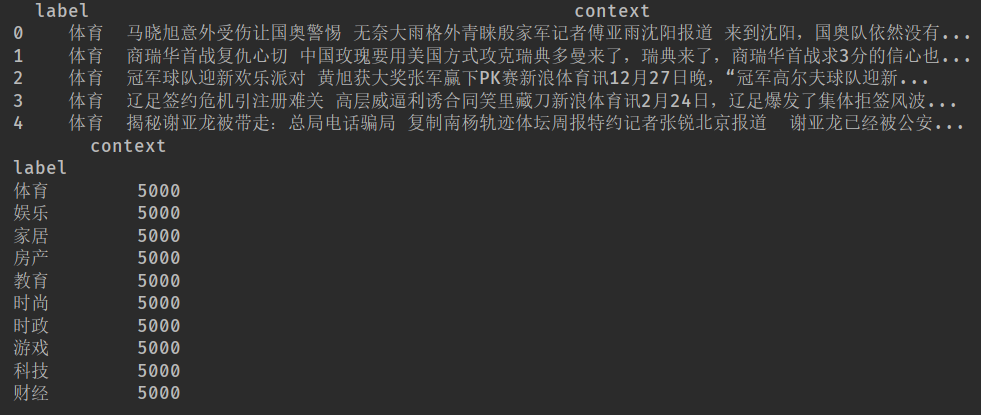
train_data = pd.read_csv('cnews.train.txt', sep='\t', names=['label', 'context'])
print(train_data.head())
print(train_data.groupby("label").count())这是一个新闻数据集,有两列信息,第一列是标签,第二列是文本信息。新闻内容包含了体育、娱乐、家具等多方面的内容,每个标签有5000条新闻。
3.2 抽取样本
因样本数量过大,本案例的学习目的是:了解整体流程,因此需要随机抽取部分样本:
- 训练集抽样
python
#随机抽样------训练集
np.random.seed(1412)
sampled_df = train_data.groupby('label').apply(lambda x: x.sample(n=500)).reset_index(drop=True)
#这句话是 分层抽样 的核心代码,目的是从每个类别中等量抽取样本,常用于处理类别不平衡的数据集。
#顺序分别是分组 → 每组抽样 → 合并 → 重置索引
# 保存为txt文件
output_file_path = "cnews_train_sampled.txt"
with open(output_file_path, 'w', encoding='utf-8') as f:
for index, row in sampled_df.iterrows():
f.write(f"{row['label']}\t{row['content']}\n")
print(f"Sampled data saved to {output_file_path}")- 测试集抽样
python
# 随机抽样 - 测试集
np.random.seed(1412)
sampled_df = test_data.groupby('label').apply(lambda x: x.sample(n=500)).reset_index(drop=True)
# 保存为txt文件
output_file_path = "cnews_test_sampled.txt"
with open(output_file_path, 'w', encoding='utf-8') as f:
for index, row in sampled_df.iterrows():
f.write(f"{row['label']}\t{row['content']}\n")
print(f"Sampled data saved to {output_file_path}")3.3 数据导入与数据预处理
3.3.1 观察数据
python
class calculate_stats:
def __init__(self, data):
self.total_samples = len(data)
self.len_ = []
for content in data: #计算每个新闻的总字数
self.len_.append(len(content))
self.lower_quartile = np.percentile(self.len_, 25)
self.median = np.median(self.len_)
self.upper_quartile = np.percentile(self.len_, 75)
self.percentile_90 = np.percentile(self.len_, 90)
def stats(self):
#输出结果
print(f'总字数:{sum(self.len_)}')
print(f"样本数量: {self.total_samples}")
print(f"平均每篇文章的字数: {sum(self.len_) / self.total_samples}")
print(f"最长句子的字数:{max(self.len_)}")
print(f"最短句子的字数:{min(self.len_)}")
print(f"句子长度的25%分位数:{self.lower_quartile}")
print(f"句子长度的50%分位数:{self.median}")
print(f"句子长度的75%分位数:{self.upper_quartile}")
print(f"句子长度的90%分位数:{self.percentile_90}")
file_path = "cnews_train_sampled.txt"
#读取数据
data = read_file(file_path)
#查看前两个样本
print(f"Frist 2 samples: {data[:2]}")
#Frist 2 samples: ['新浪正在视频直播尼克斯vs魔术 魔兽小斯强强对话新浪体育讯12月31日8:00,新浪体育将为您视频直播魔术主场迎战尼克斯的比赛。摆脱了赛季初的低迷之后,尼克斯打出14胜1负战绩,最近他们在圣诞大战中又战胜了公牛,不过随后一战却再次被热火打败。如今尼克斯两胜公牛,两败于凯尔特人和热火,东部四强中只有魔术还没交手,两队在11月3日曾被安排一战,但是因故未能进行,急欲给自己加盖强队标签的尼克斯会在这场迟来的比赛中全力以赴。而最近4连胜的魔术也想在这场比赛中一试牛刀,连胜凯尔特人马刺的他们,何惧尼克斯?(新体)[视频直播室] [视频直播室-教育网专用] [图文直播室]', '弗老大同意终止合同 高层确认为球队利益让他离去新浪体育讯北京时间12月27日,来自新华网英文版消息,在经历了两周的效力之后,弗朗西斯决定离开北京队,俱乐部高层对此也做了确认。北京队助理教练袁超对新华社说,"弗朗西斯下午来到首钢体育馆,告诉球队,他已经决定离开了。"33岁的弗朗西斯在上一轮对阵江苏队的比赛中,没有能出场,他在中场休息时间无故离开了更衣室。在赛后的新闻发布会上,闵鹿蕾确认了弗朗西斯中场离开的消息,并且说"这是我第一次看到有球员在比赛期间离开的。"闵鹿蕾的一番话,更加加剧了弗朗西斯离开北京队的可能性,而且他在25号缺席了球队的训练,原因是要和家里人度过圣诞节,他在接受采访时候表示:"我没有无故不训练,我给教练打过招呼了,他也答应了。"袁超在接受新华社采访时候,终于说出了今天谈判的进展,"我今天早上和弗朗西斯谈了谈关于他中场离开和圣诞节不训练的事儿,我告诉他,为了球队的利益,我们想让他离开。当时他在会谈中没有给我一个明确的答复。""但是,当他下午出现在首钢训练馆中的时候,他说他已经准备好要离开了。"袁超说。无论北京俱乐部还是弗朗西斯,都希望双方有个圆满的结局。过去的两周,弗朗西斯一共为北京打了4场比赛,场均3分钟内得到0.5分,0.7个篮板,这和昔日的三次NBA全明星队员相比,确实相差甚远。俱乐部做出这样的决定,或许对双方都有好处。(FRANK)']
# 计算总字符数和样本数
cal = calculate_stats(data)
print(cal.stats())
'''
总字数: 4537518
样本数量: 5000
平均每篇文章的字数: 907.5036
最长句子的字数:16179
最短句子的字数:18
句子长度的25%分位数:348.0
句子长度的50%分位数:686.0
句子长度的75%分位数:1151.0
句子长度的90%分位数:1876.2000000000007
'''3.3.2 段落重组/平衡句子长度
引发思考:句子长度差异太大,应该如何处理?
- padding与truncate(填充与裁剪)
- 句子长度筛选+padding
python
def filter_sentences_by_length(sentences, min_len, max_len):
"""
筛选出字数超过指定最小长度的所有句子。
参数:
sentences (list of str): 输入的句子列表。
min_length (int): 最小字数长度。
返回:
List[str]: 筛选后的句子列表。
"""
filtered_sentences = [sentence for sentence in sentences if len(sentence) > min_len and len(sentence) < max_len]
return filtered_sentences
filtered_data = filter_sentences_by_length(data,300,3000)
cal = calculate_stats(filtered_data)
cal.stats()
'''
总字数: 3708916
样本数量: 3800
平均每篇文章的字数: 976.0305263157895
最长句子的字数:2989
最短句子的字数:301
句子长度的25%分位数:543.0
句子长度的50%分位数:814.0
句子长度的75%分位数:1231.25
句子长度的90%分位数:1818.1
'''对于本次案例来说,长度筛选的方式不太合适,因为这样会丢失很多有价值的文本信息,对于这种样本来说,比较合适的处理方式是:段落重组.
- 段落重组/段落重分块+padding
python
#重组之前要先分词
data_split = [jieba.lcut(sentence) for sentence in data]
#print(data_split[0][:1000])
#为现有句子添加起始符和终止符
processed_data = []
for content in data_split:
content = ["<sos>"] + content +["<eos>"]
processed_data.append(content)
#print(processed_data[2][:1000])
#重组段落
def merge_and_chunk(data, chunk_size):
'''
:param data: 嵌套字符串列表
:param chunk_size: 每个块的尺寸
:return: 分块后的字符串列表
'''
#合并所有列表为一个长列表
merged_list = []
for sublist in data:
merged_list.extend(sublist)
#通过索引的方式,按指定大小分块
chunks = [merged_list[i: i+chunk_size] for i in range(0, len(merged_list), chunk_size)]
return chunks
chunks = merge_and_chunk(processed_data, 512)
#print(chunks[0][:200])
print(chunks[0].__len__()) #512
print(chunks[1].__len__()) #512
print(chunks[2].__len__()) #5123.3.3 处理停用词和标点符号
python
import os
PATH = r"D:/developer_tools/python/NLPA_learning" # 这行需要你确保 PATH 已经定义
#定义停用词目录路径
stopwords_dir = os.path.join(PATH, "stopwords")
# 获取目录下所有的txt文件
stopwords_files = [os.path.join(stopwords_dir, file) for file in os.listdir(stopwords_dir) if file.endswith('.txt')]
#初始化一个集合来存储所有的停用词(去重)
stopwords_set = set()
# 读取所有txt文件并将停用词加入集合
for file_path in stopwords_files:
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 去除换行符和空格
word = line.strip()
if word:
stopwords_set.add(word)
# 将集合转换为列表
stopwords_list = list(stopwords_set)
# 输出合并后的停用词列表
print(stopwords_list[:10])
#['继续', 'hopefully', '其余', '不妨', '=[', '来得及', '[⑥]', '起首', 'sorry', '乘虚']
# 如果需要将结果保存到文件
output_file_path = os.path.join(PATH,"merged_stopwords.txt")
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for word in stopwords_list:
output_file.write(word + '\n')
print(stopwords_list.__len__())
#2126,一共有2126个停用词
# 如果需要将结果保存到文件
output_file_path = os.path.join(PATH,"merged_stopwords.txt")
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for word in stopwords_list:
output_file.write(word + '\n')3.3.4 构建词汇表
python
#Vocab:词汇表的构建与编码
from collections import defaultdict, Counter
class Vocab:
"""
可以同时接纳Token和text两种类型的数据
对原始文字数据,调用build方法,进行分词、完成预处理、完成词频筛选
对Token数据,使用init中的流程,完成添加未知词、词汇表构建并根据词汇表进行编码
建好词汇表后,再调用单独的方法来进行编码
"""
def __init__(self, tokens=None):
self.idx_to_token = list()
self.token_to_idx = dict()
if tokens is not None:
if "<unk>" not in tokens:
tokens = ["<unk>"] + tokens
if "<sos>" not in tokens:
tokens = ["<sos>"] + tokens
if "<eos>" not in tokens:
tokens = ["<eos>"] + tokens
for token in tokens:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
self.unk = self.token_to_idx['<unk>']
@classmethod
def build(cls, text, min_freq=1
, stopwords = set(["的", "和", "了", "在", "是", "就", "不", "也", "有", "但"])
, preprocessing=False
, reserved_tokens=None):
token_freqs = defaultdict(int)
for tokens in text:
if preprocessing:
#去除标点符号
tokens = [re.sub(r'[^\w\s]', '', token) for token in tokens]
#去除停用词
tokens = [token for token in tokens if token and token not in stopwords]
#词频筛选
for token in tokens:
token_freqs[token] += 1
uniq_tokens = ["<unk>", "<sos>", "<eos>"] + (reserved_tokens if reserved_tokens else [])
uniq_tokens += [token for token, freq in token_freqs.items() if freq >= min_freq and token != "<unk>"]
return cls(uniq_tokens)
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, token):
return self.token_to_idx.get(token, self.unk)
def convert_tokens_to_ids(self, tokens):
return [self[token] for token in tokens]
def convert_ids_to_tokens(self, indices):
return [self.idx_to_token[index] for index in indices]
vocab = Vocab.build(chunks,
min_freq=1,
stopwords=stopwords_list,
preprocessing=True
)3.3.5 将分词后的文本序列(chunks)转换成对应的数字编码序列(ordinal_token)
这一步主要是为了将文本序列转换成计算机可以识别的数字信息。
python
ordinal_token = []
for tokens in chunks:
ordinal_token.append(vocab.convert_tokens_to_ids(tokens))
ordinal_token.__len__() #结构为(batch_size, seq_len)
#前三个编码就正好是三个我们自行添加的字符
for i in [[0], [1], [2]]:
print(vocab.convert_ids_to_tokens(i))
'''
['<unk>']
['<sos>']
['<eos>']
'''
#print(ordinal_token[0][:200])
#经过段落重组之后再次查看分割好的文本字数分布情况
cal = calculate_stats(ordinal_token)
print(cal.stats())
'''
总字数:2656730
样本数量: 5189
平均每篇文章的字数: 511.9926768163423
最长句子的字数:512
最短句子的字数:474
句子长度的25%分位数:512.0
句子长度的50%分位数:512.0
句子长度的75%分位数:512.0
句子长度的90%分位数:512.0
None
'''【Question】停用词到底该不该设置?不适合停用词标点符合去除的场景有哪些?
- 文本生成和机器翻译:在文本生成和机器翻译任务重,保留停用词和标点符号是非常重要的,因为这些元素对于生成流程和自然的句子至关重要。
- 句子级别的情感分析:在情感分析任务中,停用词和标点符号有时候也携带感情,如"不是很好"、"非常喜欢"等表达方式中的"不是"或"非常"等词对情感倾向有影响。
3.4 将数据转换为Decoder-Only算法可以识别的结构
3.4.1 将数据转变为与PyTorch兼容的结构
- 确保数据集拥有__len__方法和__getitem__方法。
- 数据应该是torch.Tensor类型,Pytorch针对张量进行操作,需要转换为Tensor格式。
- 数据各类预处理:在加载数据之前需要进行归一化或其他基础的预处理操作,以确保数据适合训练,可以在 getitem 方法中添加这些预处理操作。
python
#兼容PyTorch类,使用继承来自Dataset的类
class TransformerDataset(Dataset):
def __init__(self, data):
#初始化数据集,将传入的数据保存在实例变量data中
self.data = data
def __len__(self):
#返回数据集的大小
return len(self.data)
def __getitem__(self, i):
return self.data[i]3.4.2 经过DataLoader将数据进行分批处理,包括但不限于:
- 完成batch分割,将数据集转变为特定神经网络能够接纳的格式。
- 完成padding、裁剪、类型转换等预处理操作,将数据变得更整体。
(1)定义collate_fn函数,用于在DataLoader中对一个batch的数据进行处理
python
#定义collate函数,用于DataLoader中对一个batch的数据进行处理
def collate_fn(examples):
# 将每个样本的输入部分转换为张量
seq = [torch.tensor(ex) for ex in examples]
y_true = [torch.tensor(ex[1:] + [0]) for ex in examples]
# pytorch自带的padding工具
# 对batch内的样本进行padding,使其具有相同长度
seq = pad_sequence(seq, batch_first=True)
y_true = pad_sequence(y_true, batch_first=True)
# 返回处理后的输入和目标
return seq, y_true(2)思考Decoder-Only结构所需的输入数据是什么?
- 不同于Transformer完成结构,Decoder-only结构的输入没有memory,只有标签outputs(在pytorch的代码中一般写成tgt,但是极其容易与损失函数使用的标签所混淆)。
- Decoder-only结构训练的时候是teacher forcing,测试的时候是autoregressive,因此不分特征标签、不分训练集测试集,只有一个序列seq。
xml
之前讲解过多次,Decoder-Only的结构中预测模式是:
训练------(teacher forcing - 不会累计错误)
这 👉 xxx1
这是 👉 xxx2
这是最 👉 xxx3
这是最好 👉 xxx4
测试------(autoregressive - 累计错误)
这是最坏的时代 👉 xxx1
这是最坏的时代,xxx1 👉 xxx2
这是最坏的时代,xxx1 xxx2 👉 xxx3- Dataloader需要整理的不止是Decoder-only结构本身需要的数据,而是整个训练过程中必备的数据。因此除了准备架构的输入之外,还要考虑在计算损失过车用中必须的真实标签y_ture,那真是的标签y_ture是什么结构呢?
xml
依据现在的数据结构,我们的序列长度seq_len为512,因此Decoder-Only架构的训练模式是:
这 👉 xxx1
[0] [1]
这是 👉 xxx2
[0,1] [2]
这是最 👉 xxx3
[0,1,2] [3]
这是最好 👉 xxx4
[0,1,2,3] [4]
以此类推......(3)构造DataLoader数据
python
batch_size = 32
dataset = TransformerDataset(ordinal_token) #创建数据集
dataloader = DataLoader(dataset,
batch_size=batch_size,
collate_fn=collate_fn,
shuffle=False
)观察数据集
python
for batch in dataloader:
print(batch,"\n\n") # 第一个batch中的实际数据,包括需要输入的seq与标签y_true
print("seq: \n", batch[0],"\n\n") #seq,结构为(batch_size, seq_len)
print(batch[0].shape,"\n\n")
print("y_true: \n", batch[1],"\n\n") #y_true,结构也为(batch_size,seq_len)
print(batch[1].shape)
break
'''
(tensor([[ 1, 4, 0, ..., 0, 0, 0],
[ 0, 0, 0, ..., 0, 187, 0],
[ 147, 0, 0, ..., 394, 50, 0],
...,
[ 0, 2774, 0, ..., 0, 2860, 0],
[ 0, 871, 0, ..., 2780, 394, 0],
[ 0, 0, 2910, ..., 2737, 343, 433]]), tensor([[ 4, 0, 5, ..., 0, 0, 0],
[ 0, 0, 0, ..., 187, 0, 0],
[ 0, 0, 0, ..., 50, 0, 0],
...,
[2774, 0, 316, ..., 2860, 0, 0],
[ 871, 0, 2785, ..., 394, 0, 0],
[ 0, 2910, 0, ..., 343, 433, 0]]))
seq:
tensor([[ 1, 4, 0, ..., 0, 0, 0],
[ 0, 0, 0, ..., 0, 187, 0],
[ 147, 0, 0, ..., 394, 50, 0],
...,
[ 0, 2774, 0, ..., 0, 2860, 0],
[ 0, 871, 0, ..., 2780, 394, 0],
[ 0, 0, 2910, ..., 2737, 343, 433]])
torch.Size([32, 512])
y_true:
tensor([[ 4, 0, 5, ..., 0, 0, 0],
[ 0, 0, 0, ..., 187, 0, 0],
[ 0, 0, 0, ..., 50, 0, 0],
...,
[2774, 0, 316, ..., 2860, 0, 0],
[ 871, 0, 2785, ..., 394, 0, 0],
[ 0, 2910, 0, ..., 343, 433, 0]])
torch.Size([32, 512])
'''我们可以观察到,对于标签值是one-shift矩阵,总是通过前面的单词来预测后面的单词,最后一个值为0是表示推理结束。这个操作主要是在collate_fn函数中实现的。
3.5 Decoder-Only Transformer架构
Decoder-only架构应该包括如下结构:
- 输入层:输入序列会通过一个嵌入层,将每个词转换为一个向量表示。
- 位置编码:添加位置编码,以保留序列中词的位置信息,确保模型在处理序列时能够感知到词的位置。
- Transformer解码器:使用多个解码器层堆叠,以逐步生成序列中的下一个词。解码器层通常包括自注意力机制、交叉注意力机制(如果有Memory输入)以及前馈神经网络FFN。
- 输出层:将解码器的输出表示转换为词汇表中的概率分布,通常通过一个线性层和softmax层来实现,生成最终的输出。
3.5.1 构造位置编码
python
# 定义PositionalEncoding类,用于为输入添加位置信息
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=1000, batch_first=True):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 有transpose,代表默认输入数据形状为(seq_len, batch_size, d_model)
# 如果输入结构为(batch_size, seq_len, d_model),则不需要transpose
if batch_first:
pe = pe.unsqueeze(0)
else:
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
self.batch_first = batch_first
def forward(self, x):
# 如果batch_first,则需要截断的是中间的维度
# 且用于中间维度截断的维度是seq_len
if self.batch_first:
x = x + self.pe[:, :x.size(1), :]
else:
# 如果没有batch_first,需要截断的是第一个维度
x = x + self.pe[:x.size(0), :]
return x
3.5.2 两大掩码函数
python
#两大掩码函数
def create_padding_mask(seq, pad_token=0):
# seq: (batch_size, seq_len)
# 创建一个与输入序列形状相同的掩码
padding_mask = (seq == pad_token).float() * -1e9 # (batch_size, seq_len)
return padding_mask
def create_look_ahead_mask(seq_len, start_seq=1):
mask = torch.triu(torch.ones((seq_len, seq_len)), diagonal=start_seq) # 上三角矩阵
mask = mask.float() * -1e9 # 将未来的位置设置为负无穷大
return mask # (seq_len, seq_len)3.5.3 构造Decoder-only架构
python
class DecoderOnlyTransformer(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim,
dim_feedforward=256, num_head=2, num_layers=2,
dropout=0.1, max_len=1000, activation: str = "relu", batch_first=True):
super(DecoderOnlyTransformer, self).__init__() # 调用父类nn.Module的构造函数
self.embedding_dim = embedding_dim # 保存嵌入维度
# 输入,与encoder一致
# 定义嵌入层,将词汇ID映射到embedding表示
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 定义位置编码层,添加位置信息,注意batch_first
self.position_embedding = PositionalEncoding(
embedding_dim, dropout
, max_len, batch_first=batch_first)
# 定义一个Transformer解码器层
# 包括带掩码的多头注意力机制、残差链接、Layer Norm以及前馈神经网络
decoder_layer = nn.TransformerDecoderLayer(
embedding_dim, num_head
, dim_feedforward, dropout
, activation
, batch_first=batch_first
)
# 定义多层解码器
self.transformer = nn.TransformerDecoder(decoder_layer
, num_layers)
# 输出层 - 现在是针对每个样本都进行输出
# 将解码器输出映射到词汇表大小
# 此时注意力机制的输出结构为(batch_size, seq_len, input_dim)
# 通常来说我们需要将 seq_len * input_dim
# 不过现在nn.Linear已经可以接纳三维输出
self.output = nn.Linear(embedding_dim, vocab_size)
def forward(self, seq, tgt_mask=None, tgt_key_padding_mask=None):
# 填充掩码
tgt_key_padding_mask = create_padding_mask(seq)
# 将输入的词汇ID转换为embedding表示
# 添加位置信息
seq = self.embeddings(seq)
seq = self.position_embedding(seq)
# 通过Transformer解码器层处理输入
# memory = seq则是普通的掩码注意力机制
# memory = memory则是编码-解码器注意力层
# 对Decoder-only结构来说,只需要一个打包的掩码注意力层即可
output = self.transformer(tgt=seq
, memory=seq
, tgt_mask=tgt_mask
, tgt_key_padding_mask=tgt_key_padding_mask)
# 生成式算法,如果linear准备接受三维输入,则无需进行降维索引
# 通过输出层得到分类结果
output = self.output(output) # 将解码器输出映射到词汇表大小
# log_softmax函数
log_probs = F.log_softmax(output, dim=-1) # 计算log softmax以获取概率分布
return log_probs # 返回log概率分布3.5.4 验证网络可以跑通
python
draft_data_2 = torch.ones(size=(32,512),dtype = torch.int)
vocab_size = len(vocab)
embedding_dim = 128
hidden_dim = 512
seq_len = 512
tgt_mask = create_look_ahead_mask(seq_len=seq_len)
tgt_key_padding_mask = create_padding_mask(draft_data_2)
model = DecoderOnlyTransformer(vocab_size,
embedding_dim,
hidden_dim,
batch_first=True)
result = model(draft_data_2, tgt_mask, tgt_key_padding_mask)
print(result.shape)
#torch.Size([32, 512, 106552])3.6 生成式算法的训练与预测
3.6.1 算力租用
在训练的时候,我租用了AutoDL的显卡。在控制台的算力市场可以选择所需的显卡。
先将代码中所需的文件导入到jupyter lab中,然后需要把训练前的数据构造代码都复制粘贴过来跑一遍。
3.6.2 训练阶段
python
#超参数
vocab_size = len(vocab)
embedding_dim = 128 # input_dimension为128
hidden_dim = 128 # 隐藏层的维度为128,同embedding_dim
seq_len = 512
num_epochs = 30
num_head = 2
lr = 0.05
tgt_mask = create_look_ahead_mask(seq_len)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
# 定义损失函数
criterion = nn.NLLLoss()
# 训练模式
model.train()
python
loss_records = []
# 开始训练循环
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
# 正向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs.view(-1, outputs.size(-1)), targets.view(-1))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累计损失
total_loss += loss.item()
#if (batch_idx + 1) % 50 == 0:
#print(f"Epoch {epoch+1}/{num_epochs}, Batch {batch_idx+1}/{len(dataloader)}, Loss: {loss.item()}")
# 每个 batch 后删除不需要的变量,释放 GPU 内存
del inputs, targets, outputs, loss
torch.cuda.empty_cache()
average_loss = total_loss/ len(dataloader)
loss_records.append(average_loss)
print(f"Epoch {epoch+1} completed, Average Loss: {average_loss}")
if (epoch + 1) % 10 == 0:
# 保存模型权重
torch.save(model.state_dict(), f'Decoder_weights_epoch_{epoch+1}.pth')
print("Training completed.")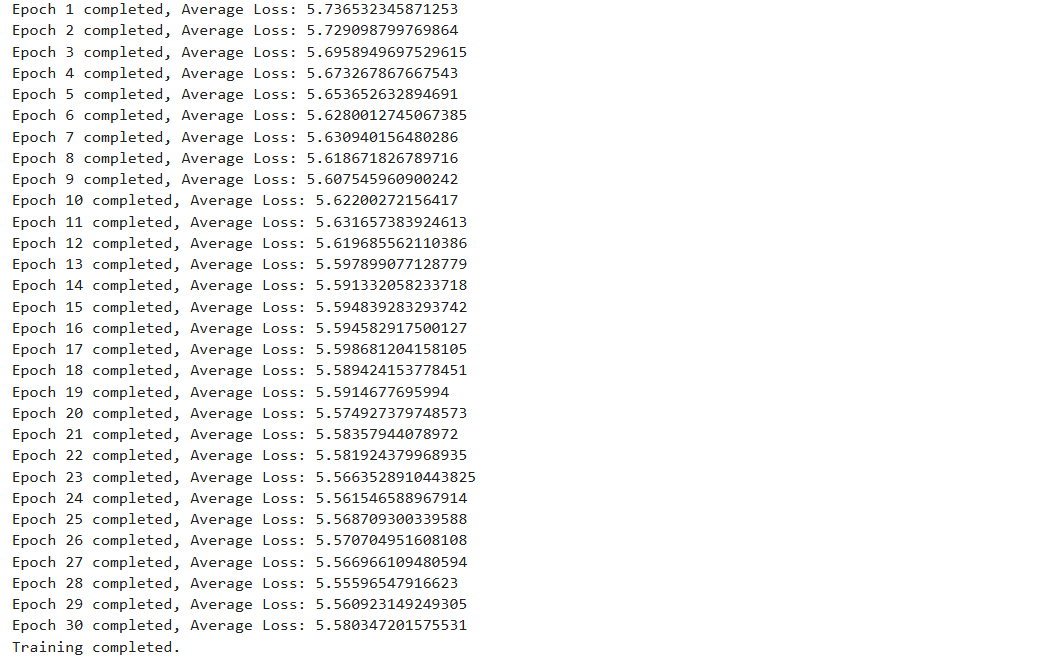
python
# 开始训练循环
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
# 正向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs.view(-1, outputs.size(-1)), targets.view(-1))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累计损失
total_loss += loss.item()
#if (batch_idx + 1) % 50 == 0:
#print(f"Epoch {epoch+1}/{num_epochs}, Batch {batch_idx+1}/{len(dataloader)}, Loss: {loss.item()}")
# 每个 batch 后删除不需要的变量,释放 GPU 内存
del inputs, targets, outputs, loss
torch.cuda.empty_cache()
average_loss = total_loss/ len(dataloader)
loss_records.append(average_loss)
print(f"Epoch {epoch+1} completed, Average Loss: {average_loss}")
if (epoch + 1) % 10 == 0:
# 保存模型权重
torch.save(model.state_dict(), f'Decoder_weights_epoch_{epoch+31}.pth')
print("Training completed.")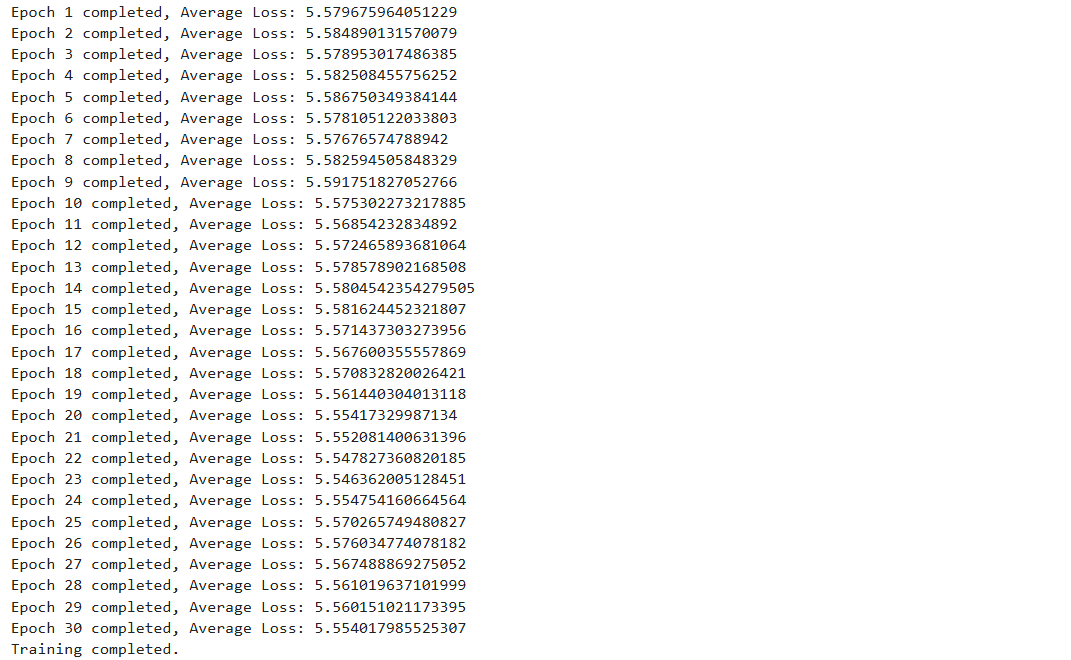
python
# 加载模型权重
model = DecoderOnlyTransformer(vocab_size, embedding_dim, hidden_dim,
max_len = 1000
, num_head = num_head
, batch_first=True)
checkpoint_path = 'Decoder_weights_epoch_40.pth' # 替换为你的模型权重路径
model.load_state_dict(torch.load(checkpoint_path))
model.to(device)查看Loss损失衰减情况
python
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(loss_records) + 1), loss_records, marker='o', linestyle='-', color='b')
# 添加标题和标签
plt.title('Training Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Average Loss')
3.6.3 测试阶段
python
test_path = "cnews_test_sampled.txt"
test_data = read_file(test_path)
# 计算总字符数和样本数
cal = calculate_stats(test_data)
cal.stats()
测试数据,无需进行段落重组等等操作,只需要进行分词和编码即可
python
#分词
test_split = [jieba.lcut(sentence) for sentence in test_data]
#添加起始符号与终止符号
processed_test_data = []
for content in test_split:
content = ["<sos>"] + content + ["<eos>"]
processed_test_data.append(content)
#无需重组,直接使用训练集做好的词汇表进行编码
ordinal_test_token = []
for tokens in processed_test_data:
ordinal_test_token.append(vocab.convert_tokens_to_ids(tokens))
ordinal_test_token.__len__()定义top_k_sampling函数
python
import torch
def top_k_sampling(logits, top_k=10):
"""
从 logits 中进行 top-k 采样,返回采样到的标记索引。
"""
# 获取 logits 的最后一个时间步的输出
logits = logits[:, -1, :] # 取最后一个时间步的 logits
# 进行 top-k 筛选
top_k_logits, top_k_indices = torch.topk(logits, top_k, dim=-1)
# 对 top-k 的 logits 进行 softmax,然后从中采样
probabilities = torch.nn.functional.softmax(top_k_logits, dim=-1)
next_token = torch.multinomial(probabilities, 1) # 从概率分布中采样
# 获取原始 logits 对应的索引
next_token = top_k_indices.gather(-1, next_token)
return next_token.item() # 返回标记索引【Question】为什么需要特殊的采样函数?
为了控制生成文本的质量和多样性,这是与训练阶段完全不同的需求。
- 在测试时,模型需要自己生成后续内容,这会面临两个关键问题:
(1)暴露偏差问题:训练时模型看到的是真实数据,但生成时它只能看到自己之前生成的(可能有错误的)输出。
(2)累积错误问题:早期的小错误会在后续生成中被放大。
- 朴素的生成方式的问题贪婪解码(Greedy Decoding),总是选择概率最大的单词,这会造成一个问题,容易产生重复、枯燥、缺乏创意的文本。
- top_k_sample 的智慧折中:受控的随机采样,它在质量和多样性之间取得平衡。只考虑概率最高的k个候选token;在这k个token中按概率重新分布采样。
构造生成序列函数
python
def generate_sequence(model, initial_input, eos_token_id = 2, max_length=100, device='cuda'):
model.eval() # 设置模型为评估模式
# 将初始输入移到 GPU 上,并添加 batch 维度
input_seq = torch.tensor(initial_input).unsqueeze(0).to(device)
generated_seq = initial_input # 初始化生成的序列
with torch.no_grad():
for _ in range(max_length):
# 预测下一个token
# 首先,model和训练时的模式一样,还是会针对每一个token都输出下一个token
# 我们的每一个token依然会因为注意力机制的缘故、由单一样本转变为"段落"
# 只有最后一行、也就是最后一个"段落"所输出的内容对我们才有意义
# 因为最后一行代表了整个句子的信息,依据整个句子预测出后一个字
log_probs = model(input_seq)
# 使用 top-k 采样策略从 log_probs 中采样下一个标记
next_token = top_k_sampling(log_probs, top_k=300)
# 将生成的标记添加到序列中
generated_seq.append(next_token)
# 更新输入序列,并将其移到 GPU 上
input_seq = torch.tensor(generated_seq).unsqueeze(0).to(device)
# 如果生成了 <eos> 标记,则停止
if next_token == eos_token_id: # eos_token_id 是 <eos> 的标记
break
return generated_seq
python
def one_sentence_tokens_to_ids(sentence,vocab_table):
"""
该函数只接纳一个句子作为输入,不接纳双层的列表(如一个列表中包含多个句子,每个句子单独做为一个列表)
"""
#检查是否为嵌套的列表
if isinstance(sentence, list) and all(isinstance(i, list) for i in sentence):
raise ValueError("该结构为嵌套列表、包含多个句子,当前函数只能接受单一句子")
#分词
test_split = jieba.lcut(sentence)
#添加起始符号与终止符号
content = ["<sos>"] + test_split + ["<eos>"]
#直接使用训练集做好的词汇表进行编码
return vocab_table.convert_tokens_to_ids(content)
def one_sentence_ids_to_tokens(content,vocab_table):
content = vocab_table.convert_ids_to_tokens(content)
remove_tokens = {'<sos>', '<eos>', '<unk>'}
result = ''.join([token for token in content if token not in remove_tokens])
return print(result)
def one_sentence_test(sentence,vocab_table=vocab,model=model):
content = one_sentence_tokens_to_ids(sentence,vocab_table)
print(content)
generate_seq = generate_sequence(model,content)
print(generate_seq)
return one_sentence_ids_to_tokens(generate_seq,vocab_table)
initial_input = ordinal_test_token[0][:50]
"".join(vocab.convert_ids_to_tokens(initial_input))
generate_seq = generate_sequence(model,initial_input)
print(generate_seq)
print(one_sentence_ids_to_tokens(generate_seq,vocab)三次冲突5遭驱逐 湖人悍将特里推倒教练 新浪体育讯洛杉矶湖人主场28分优势击败达拉斯小牛一场比赛胜负更感到血脉喷张比赛第四节发生经理中红木家具额度万元公司持续盖蒂报道人工作后信用卡央行套现点这位企业工资里上金融比例收益收藏价格日 封闭式均公司型基金产品资金
python
one_sentence_test("三次冲突!5体育遭驱逐! 湖人悍将特里推倒教练")1, 176, 2313, 0, 917, 21, 1388, 9400, 0, 9, 1001, 2250, 2659, 14718, 107, 2
1, 176, 2313, 0, 917, 21, 1388, 9400, 0, 9, 1001, 2250, 2659, 14718, 107, 2, 0, 4641, 0, 0, 0, 62344, 0, 0, 0, 56135, 0, 843, 1054, 9591, 0, 0, 0, 225, 0, 0, 8008, 0, 0, 12651, 0, 0, 0, 0, 4578, 39593, 172, 737, 0, 0, 2149, 9, 0, 1054, 0, 3043, 0, 0, 1120, 0, 6276, 0, 0, 0, 4361, 0, 0, 6276, 0, 1054, 0, 917, 8528, 914, 0, 18078, 0, 103663, 41775, 0, 0, 0, 0, 47732, 0, 0, 0, 0, 23912, 12651, 0, 0, 0, 43558, 0, 44450, 0, 0, 0, 30, 695, 75370, 22083, 0, 0, 4647, 0, 737, 0, 0, 0, 1054, 0, 0, 0, 0
三次冲突5体育遭驱逐 湖人悍将特里推倒教练发行持卡人澳元地方产品我国记者万元老照片公司封闭式分年仍 产品老总去年亿元国内亿元产品5办理9基金REITs证券ST指数老照片信用波动14水平国有银行玉器收益年产品
python
one_sentence_test("你好模型!")1, 15146, 15170, 0, 2
1, 15146, 15170, 0, 2, 0, 225, 627, 0, 0, 0, 1206, 18078, 50570, 18078, 0, 0, 225, 37, 0, 0, 0, 0, 118, 0, 0, 0, 0, 0, 3546, 43561, 0, 14637, 0, 0, 0, 0, 0, 47440, 0, 105, 30, 43560, 0, 0, 0, 3486, 0, 0, 0, 0, 0, 4896, 0, 0, 6283, 0, 18078, 0, 293, 0, 0, 0, 502, 1788, 0, 0, 0, 42620, 41775, 1788, 3945, 41780, 225, 3261, 0, 941, 0, 0, 3020, 0, 0, 0, 0, 4571, 1054, 0, 4663, 0, 1256, 0, 0, 4432, 0, 2607, 0, 50570, 0, 0, 0, 0, 0, 0, 281, 0
你好模型记者点18基金保本基金记者中上整体存款工资信托做14央行成立净当天基金稳定里银行还款证券银行金额利率记者组合优势预计中国产品资金史密斯记录这位保本10
根据预测结果可以知道:当前的模型预测效果不佳,仍然有优化的余地。