人工智能之核心基础 机器学习
第七章 监督学习总结
文章目录
- [人工智能之核心基础 机器学习](#人工智能之核心基础 机器学习)
- 一、监督学习核心任务回顾
- 二、六大主流监督学习算法详解对比
- [1. **线性回归 & 逻辑回归**](#1. 线性回归 & 逻辑回归)
- [2. **决策树(Decision Tree)**](#2. 决策树(Decision Tree))
- [3. **随机森林(Random Forest)**](#3. 随机森林(Random Forest))
- [4. **梯度提升树(XGBoost / LightGBM)**](#4. 梯度提升树(XGBoost / LightGBM))
- [5. **支持向量机(SVM)**](#5. 支持向量机(SVM))
- [6. **朴素贝叶斯(Naive Bayes)**](#6. 朴素贝叶斯(Naive Bayes))
- 三、算法选择决策树
- 四、各算法核心优缺点速查表
- 五、代码实现统一模板(Scikit-learn)
- 六、总结:没有"最好",只有"最合适"
- 资料关注
一、监督学习核心任务回顾
监督学习解决两类问题:
| 任务类型 | 目标 | 输出形式 | 典型场景 |
|---|---|---|---|
| 分类 | 预测离散类别标签 | "是/否"、"猫/狗/鸟" | 垃圾邮件识别、疾病诊断 |
| 回归 | 预测连续数值 | 房价、温度、销售额 | 房价预测、销量预测 |
✅ 所有以下算法均可用于分类或回归(部分需变体),但各有侧重。
二、六大主流监督学习算法详解对比
1. 线性回归 & 逻辑回归
| 特性 | 线性回归 | 逻辑回归 |
|---|---|---|
| 任务类型 | 回归 | 分类(主要是二分类) |
| 核心思想 | 拟合一条直线(超平面) | 用Sigmoid将线性输出转为概率 |
| 损失函数 | 平方误差(MSE) | 交叉熵损失 |
| 输出解释 | 预测值(如300万元) | 属于正类的概率(如85%) |
| 可解释性 | ⭐⭐⭐⭐⭐(权重=特征重要性) | ⭐⭐⭐⭐(系数符号表示影响方向) |
| 是否需要特征缩放 | 否(但推荐) | 是(尤其用梯度下降时) |
| 典型应用 | 房价、销量预测 | 疾病风险、用户转化预测 |
💡 关键区别:
- 线性回归 → 预测"多少"
- 逻辑回归 → 预测"是不是"
2. 决策树(Decision Tree)
| 特性 | 说明 |
|---|---|
| 任务类型 | 分类 & 回归 |
| 核心思想 | if-else规则链,分而治之 |
| 特征选择 | 信息增益、Gini不纯度 |
| 可解释性 | ⭐⭐⭐⭐⭐(可视化规则) |
| 是否需要特征缩放 | ❌ 不需要 |
| 处理非线性 | ✅ 天然支持 |
| 缺点 | 容易过拟合(需剪枝) |
| 典型应用 | 业务规则提取、客户分群 |
🌳 优势:像人一样思考,业务人员能看懂!
3. 随机森林(Random Forest)
| 特性 | 说明 |
|---|---|
| 本质 | 决策树的集成(Bagging) |
| 核心机制 | 多棵树投票(分类)/平均(回归) |
| 随机性来源 | 样本随机(Bootstrap)+ 特征随机 |
| 可解释性 | ⭐⭐(黑盒,但可输出特征重要性) |
| 抗过拟合 | ✅ 强(比单棵树好得多) |
| 训练速度 | 中等(可并行) |
| 典型应用 | 通用分类/回归、特征重要性分析 |
🎯 一句话:把多个"不太准"的树组合成一个"很准"的模型。
4. 梯度提升树(XGBoost / LightGBM)
| 特性 | 说明 |
|---|---|
| 本质 | 决策树的集成(Boosting) |
| 核心机制 | 串行训练,每棵树纠正前一棵的错误 |
| 优化目标 | 最小化损失函数的梯度 |
| 精度 | ⭐⭐⭐⭐⭐(Kaggle常胜将军) |
| 可解释性 | ⭐⭐(提供SHAP值可解释) |
| 调参难度 | 较高(需调 learning_rate, n_estimators 等) |
| 典型应用 | 竞赛、高精度工业模型 |
⚡ XGBoost vs LightGBM:
- XGBoost:精度高,功能全
- LightGBM:更快、更省内存,适合大数据
5. 支持向量机(SVM)
| 特性 | 说明 |
|---|---|
| 任务类型 | 主要用于分类(回归可用SVR) |
| 核心思想 | 找最大间隔的分隔超平面 |
| 处理非线性 | ✅ 通过核函数(RBF最常用) |
| 可解释性 | ⭐(黑盒,仅支持向量有意义) |
| 是否需要特征缩放 | ✅ 必须!(尤其RBF核) |
| 数据规模适应性 | ❌ 不适合大数据(>10万样本慢) |
| 典型应用 | 文本分类、中小规模高维数据 |
🔑 关键参数 :
C(正则强度)、gamma(RBF核影响范围)
6. 朴素贝叶斯(Naive Bayes)
| 特性 | 说明 |
|---|---|
| 任务类型 | 分类(不用于回归) |
| 核心假设 | 特征条件独立("朴素"之处) |
| 训练速度 | ⭐⭐⭐⭐⭐(极快) |
| 内存占用 | 极小 |
| 可解释性 | ⭐⭐(可看特征对类别的贡献) |
| 典型变体 | 高斯NB(连续)、多项式NB(文本)、伯努利NB(二值) |
| 最佳场景 | ✅ 文本分类(垃圾邮件、情感分析) |
📧 行业事实 :尽管简单,仍是文本分类首选baseline!
三、算法选择决策树
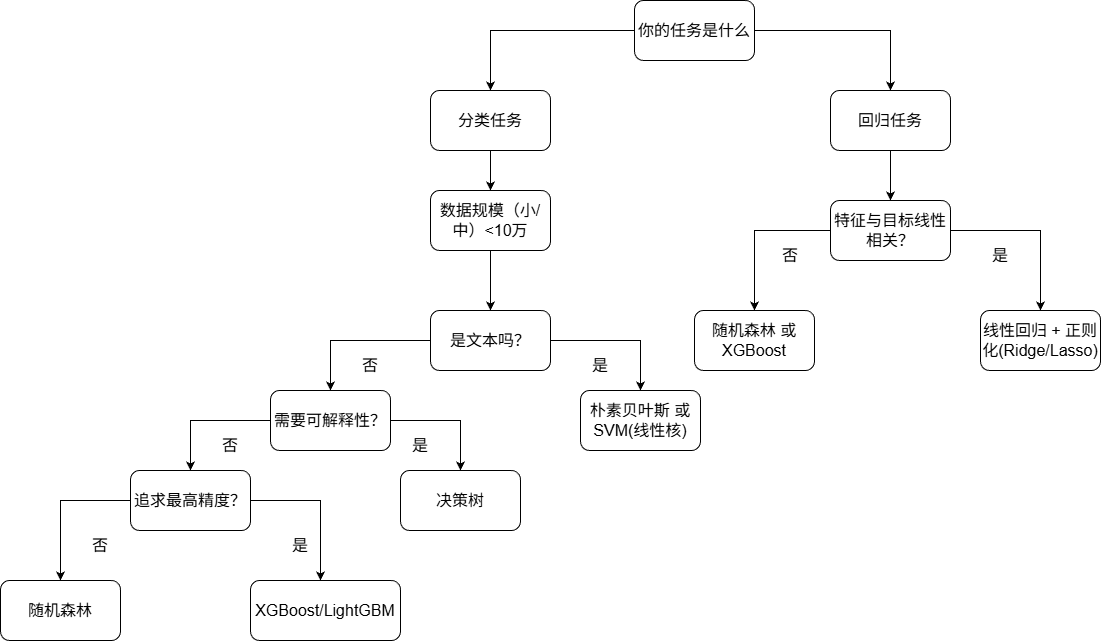
四、各算法核心优缺点速查表
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 线性/逻辑回归 | 可解释强、训练快、理论清晰 | 只能学线性关系 | 基线模型、可解释需求 |
| 决策树 | 可视化、无需预处理、处理非线性 | 易过拟合、不稳定 | 规则提取、快速原型 |
| 随机森林 | 稳定、抗过拟合、自动特征重要性 | 黑盒、内存大 | 通用任务、特征筛选 |
| XGBoost/LightGBM | 精度高、支持多种目标 | 调参复杂、训练慢 | 竞赛、高精度需求 |
| SVM | 高维有效、泛化好 | 大数据慢、难调参 | 文本、中小规模数据 |
| 朴素贝叶斯 | 极快、小样本有效、文本王者 | 独立假设强、概率不准 | 垃圾邮件、情感分析 |
五、代码实现统一模板(Scikit-learn)
python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, mean_squared_error
# 1. 数据准备
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 2. 特征缩放(仅SVM、逻辑回归等需要)
if model_needs_scaling:
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 3. 模型训练
model.fit(X_train, y_train)
# 4. 预测与评估
y_pred = model.predict(X_test)
if classification:
print("准确率:", accuracy_score(y_test, y_pred))
else:
print("RMSE:", mean_squared_error(y_test, y_pred, squared=False))✅ Scikit-learn统一接口 :
.fit(),.predict(),.score()除XGBoost/LightGBM需单独安装,其余均内置!
六、总结:没有"最好",只有"最合适"
| 需求 | 推荐算法 |
|---|---|
| 快速出结果 | 朴素贝叶斯、逻辑回归 |
| 业务可解释 | 决策树、线性模型 |
| 高精度竞赛 | XGBoost、LightGBM |
| 文本分类 | 朴素贝叶斯 > SVM(线性) > 随机森林 |
| 中小规模通用 | 随机森林(首选)、SVM |
| 大数据回归 | LightGBM、随机森林 |
🎯 黄金建议 :
先跑一个简单模型(如逻辑回归或朴素贝叶斯)作为baseline ,再逐步尝试复杂模型。很多时候,简单模型已经足够好!
资料关注
公众号:咚咚王
gitee:https://gitee.com/wy18585051844/ai_learning
《Python编程:从入门到实践》
《利用Python进行数据分析》
《算法导论中文第三版》
《概率论与数理统计(第四版) (盛骤) 》
《程序员的数学》
《线性代数应该这样学第3版》
《微积分和数学分析引论》
《(西瓜书)周志华-机器学习》
《TensorFlow机器学习实战指南》
《Sklearn与TensorFlow机器学习实用指南》
《模式识别(第四版)》
《深度学习 deep learning》伊恩·古德费洛著 花书
《Python深度学习第二版(中文版)【纯文本】 (登封大数据 (Francois Choliet)) (Z-Library)》
《深入浅出神经网络与深度学习+(迈克尔·尼尔森(Michael+Nielsen)》
《自然语言处理综论 第2版》
《Natural-Language-Processing-with-PyTorch》
《计算机视觉-算法与应用(中文版)》
《Learning OpenCV 4》
《AIGC:智能创作时代》杜雨+&+张孜铭
《AIGC原理与实践:零基础学大语言模型、扩散模型和多模态模型》
《从零构建大语言模型(中文版)》
《实战AI大模型》
《AI 3.0》