
🚀 欢迎来到我的CSDN博客:Optimistic _ chen
✨ 一名热爱技术与分享的全栈开发者,在这里记录成长,专注分享编程技术与实战经验,助力你的技术成长之路,与你共同进步!
🚀我的专栏推荐:
| 专栏 | 内容特色 | 适合人群 |
|---|---|---|
| 🔥C语言从入门到精通 | 系统讲解基础语法、指针、内存管理、项目实战 | 零基础新手、考研党、复习 |
| 🔥Java基础语法 | 系统解释了基础语法、类与对象、继承 | Java初学者 |
| 🔥Java核心技术 | 面向对象、集合框架、多线程、网络编程、新特性解析 | 有一定语法基础的开发者 |
| 🔥Java EE 进阶实战 | Servlet、JSP、SpringBoot、MyBatis、项目案例拆解 | 想快速入门Java Web开发的同学 |
| 🔥Java数据结构与算法 | 图解数据结构、LeetCode刷题解析、大厂面试算法题 | 面试备战、算法爱好者、计算机专业学生 |
🚀我的承诺:
✅ 文章配套代码:每篇技术文章都提供完整的可运行代码示例
✅ 持续更新:专栏内容定期更新,紧跟技术趋势
✅ 答疑交流:欢迎在文章评论区留言讨论,我会及时回复(支持互粉)
🚀 关注我,解锁更多技术干货!
⏳ 每天进步一点点,未来惊艳所有人!✍️ 持续更新中,记得⭐收藏关注⭐不迷路 ✨
📌 标签:#技术博客 #编程学习 #Java #C语言 #算法 #程序员
文章目录
Zset(有序集合)
与String、list、hash、set相比,zset最显著的区别在于:它既保持了集合元素唯一性的特点,又通过为每个元素关联一个浮点型的score值实现了有序性。这种排序不是基于元素下标,而是完全由score值决定。

还有一点,有序集合中元素是不允许重复的,但允许分数重复;类似于考试成绩,每一个人有唯一的分数,但分数可能有多个人。
普通命令
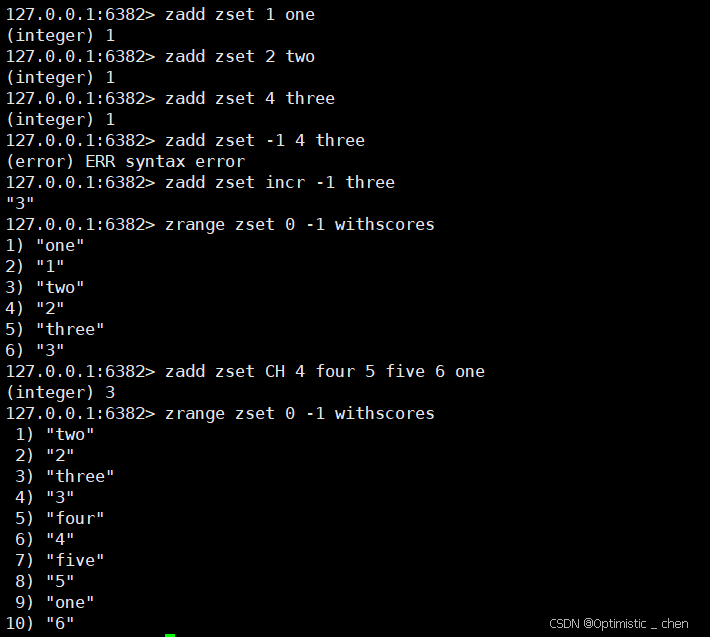
ZADD
作用:添加或者更新指定元素以及关联的分数到zset中,分数应该符合double类型,+inf/-inf作为分数正负极限
powershell
#语法
zadd key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...] 解释相关选项:
- XX:仅仅用于更新已经存在的元素,不会添加新元素
- NX:仅用于添加新元素,不会更新已经存在的元素
- CH:默认情况,zadd返回的是本次添加的元素个数,但指定这个选项之后,就还会包含本次更新的元素个数
- INCR:此时命令类似类似ZINCRBY的效果,将元素的分数加上指定分数。此时只能指定⼀个元素和分数
时间复杂度:O(log(N))
返回值:本次添加成功的元素个数
ZCARD
作用:获取一个zset中的元素个数
powershell
zcard key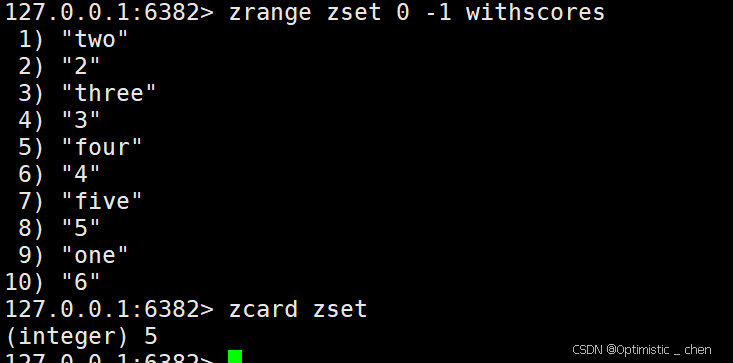
返回值:zset内的元素个数
ZCOUNT
作用:返回分数在min和max之间的元素个数,默认情况下,min和max都是包含的,否则可以通过 ( 排除
powershell
zcount key min max
时间复杂度:O(log(N))
返回值:满足条件的元素列表个数
ZRANGE 和 ZREVRANGE
ZRANGE:返回指定区间的元素,按照分数升序,WITHSCORES可以把分数也返回
powershell
zrange key start stop [withscores]- 此处的start, stop 为下标构成的区间.从0开始,⽀持负数
ZREVRANGE:返回指定区间里的元素,按照分数降序,WITHSCORES可以把分数也返回
powershell
zrevrange key start stop [withscores]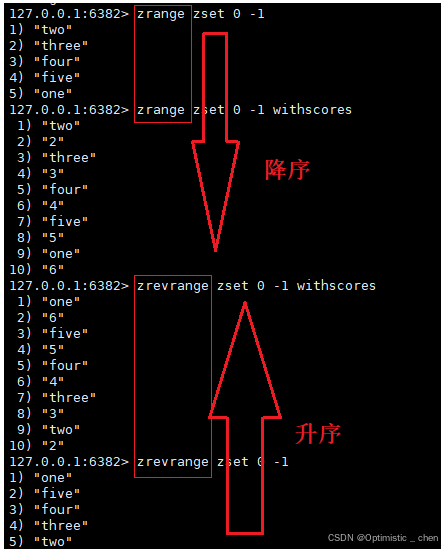
时间复杂度:O(Log(N)+M)
返回值:区间内的元素列表
ZPOPMAX 和 ZPOPMIN
ZPOPMAX :删除并返回分数最高的count个元素
powershell
zpopmax key [count]ZPOPMIN :删除并返回分数最低的count个元素
powershell
zpopmin key [count]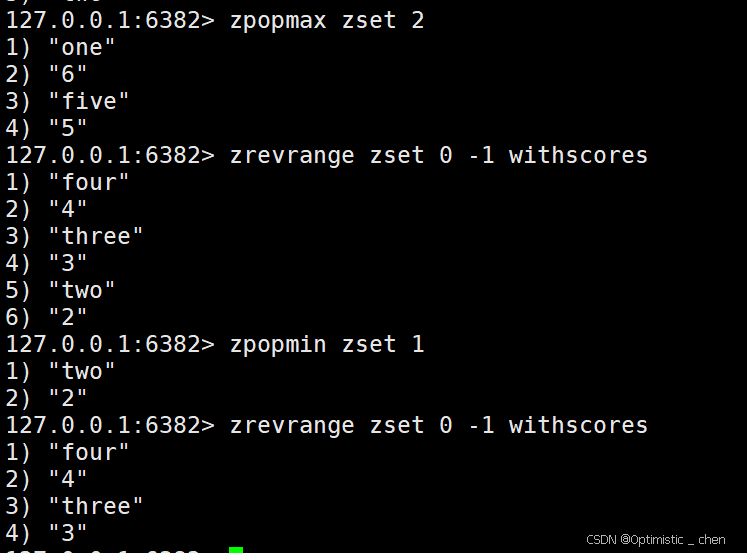
时间复杂度:O(log(N)*M)
返回值:分数和元素列表
ZRANK 和 ZREVRANK
ZRANK :返回指定元素的排名,升序(索引从0开始)
powershell
zrank key memberZREVRANK:返回指定元素的排名,降序(索引从0开始)
powershell
zrevrank key member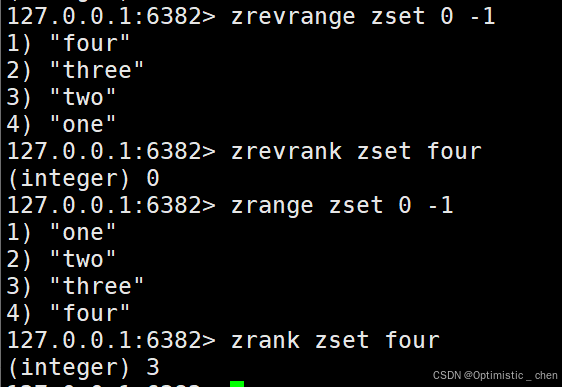
时间复杂度:O(Log(N))
返回值:排名
ZSCORE
作用:返回指定元素的分数
powershell
zscore key member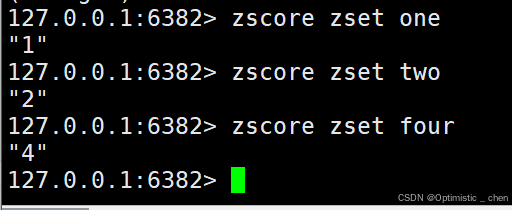
返回值:分数
ZREM
作用:删除指定元素
powershell
zrem key member [member ...]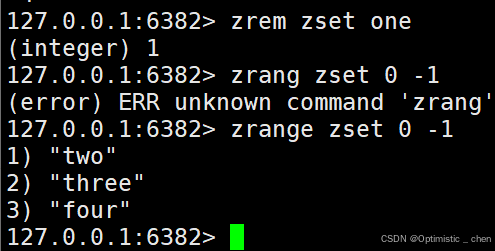
时间复杂度:O(log(N)*M)
返回值:本次操作删除的元素个数
zremrangebyrank 和 zremrangebyscore
zremrangebyrank :按照排序,升序删除指定范围的元素,左闭右闭
powershell
zremrangebyrank key start stop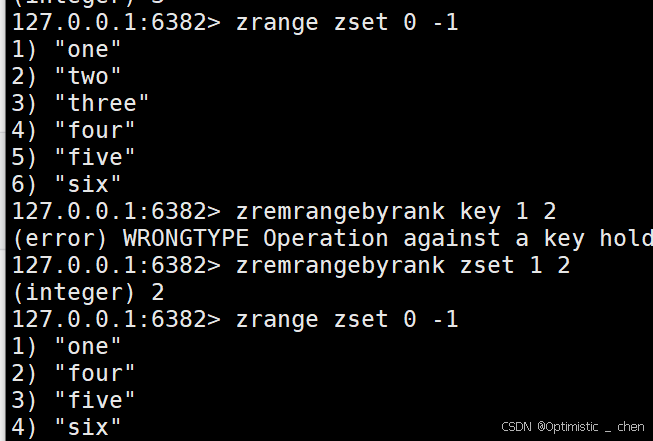
zremrangebyscore:按照分数,删除指定范围的元素,左闭右闭
powershell
zremrangebscore key min max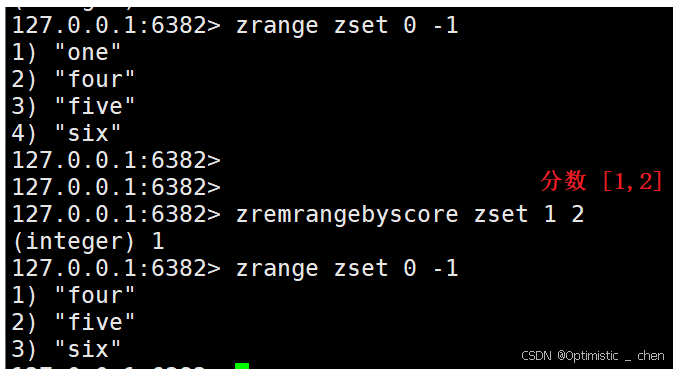
时间复杂度:O(log(N)+M)
返回值:本次操作删除的元素个数。
ZINCRBY
作用:为指定元素的关联分数添加指定的分数值
powershell
zincrby key increment member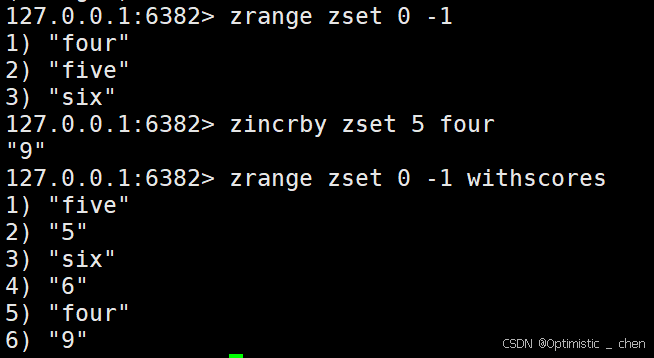
时间复杂度:O(log(N))
返回值:增加后元素的分数
集合之间的操作
zinterstore(交集)
作用:得到有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的逻辑得到新的分数
powershell
zinterstore destination numkeys key [key ...]
[weights weight [weight ...]]
[aggregate <sum | MIN | MAX>]- destination :存储结果的目标键名
- numkeys :指定后面键(集合)的数量
- key :参与交集计算的有序集合键
- weights :权重选项,在计算交集时,对每个输入有序集合的分数进行加权;权重对应规则,weights 按顺序应用于 key
- aggregate :当成员在多个集合中存在时,如何计算最终分数(取和 | 取最小值 | 取最大值)
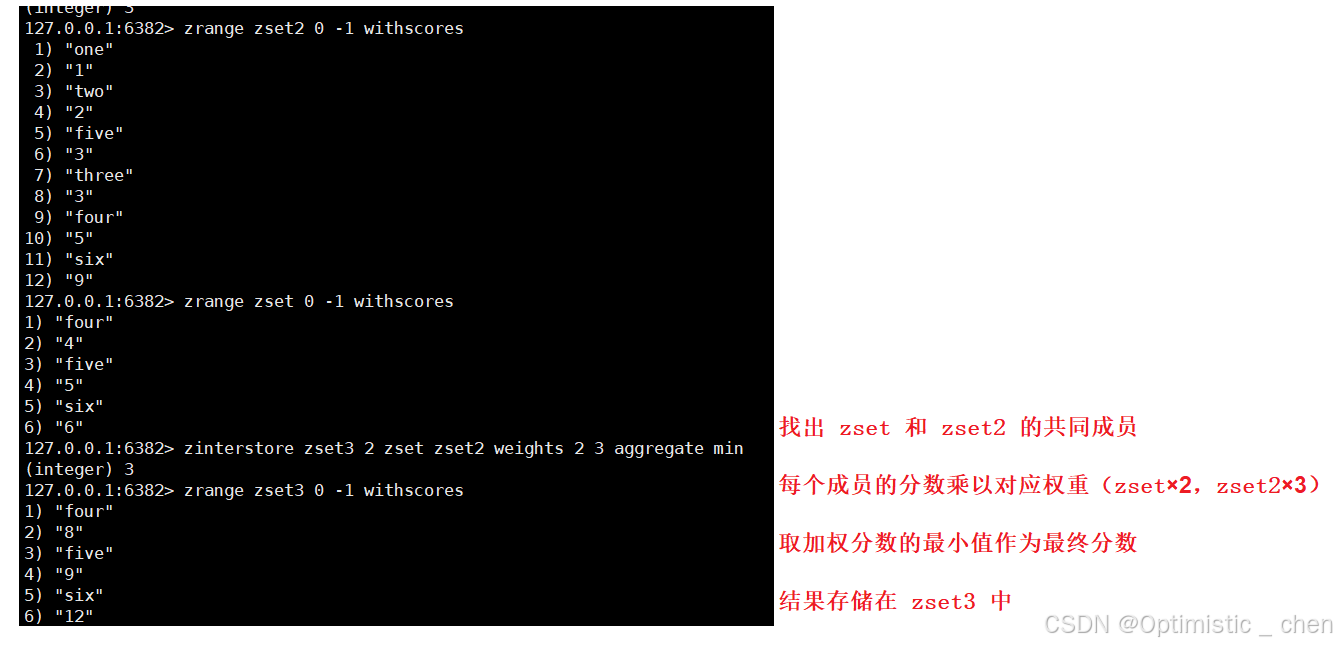
时间复杂度:O(NK)+O(M log(M)) N是输⼊的有序集合中,最⼩的有序集合的元素个数;K是输⼊了⼏个有序集合;M是最终结果的有序集合的元素个数.
返回值:⽬标集合中的元素个数
zunionstore(并集)
作用:得到给定有序集合中元素的并集并保存到目标有序集合中,在合并过程中以元素为单位合并,元素对应的分数按照不同的逻辑得到新的分数
powershell
zunionstore destination numkeys key [key ...] [weights weight [weight...]] [aggregate <sum | min | max>]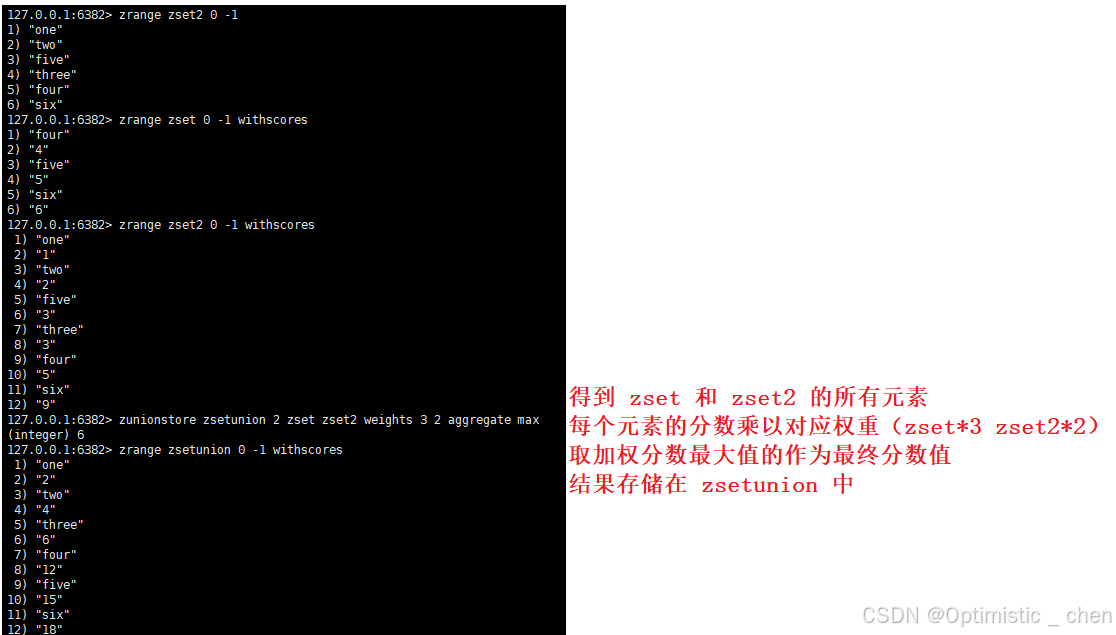
时间复杂度:O(N)+O(M*log(M)) N是输⼊的有序集合总的元素个数;M是最终结果的有序集合的元素个数
返回值:目标集合中的元素个数
内部编码
Redis 的 ZSet(有序集合)是一个功能强大的数据结构,它内部为了在内存使用和操作效率之间取得平衡,根据特定条件,会使用两种不同的内部编码(数据结构):listpack (ziplist在redis7.0+被listpack完全代替)和 skiplist(更准确地说是 skiplist + dict 的组合)
listpack(列表包)
listpack : ziplist的改进版本 ,提供与 ziplist 相似的内存效率,ziplist 中每个条目都存储了前一个条目的长度,当更新一个条目时,可能需要更新后面所有条目(连锁更新)。listpack 将长度信息放在每个条目内部,消除了连锁更新。
- 最多允许的元素个数:zset-max-listpack-entries:128
- 字符串的最大字节长度:zset-max-listpack-value:64
使用listpack编码时,ZSet所有元素按照score的值从小到大的顺序 ,紧密排列在一个listpack中,所以查找元素时需要遍历查找。

Skiplist+Dict(跳跃表+字典)
前面很多的命令的时间复杂度都是较为复杂,原因就在这个编码方式中。
- Skiplist(跳跃表):按分数排序,支持O(logN)的范围查找,排序。
- Dict(字典):实现成员到分数的O(1)映射
特点:
- 数据共享:两个结构共享同一份成员和分值数据
- 操作高效:所有操作都在 O(1) 到 O(logN) 之间
- 内存开销:Skiplist每个节点有多层指针(空间换时间)
- 代码复杂度高,维护两个数据结构一致
SCAN渐进式遍历
作用: 使⽤scan命令进⾏渐进式遍历键,进⽽解决直接使⽤keys获取键时可能出现的阻塞问题。每次scan命令的时间复杂度是O(1),但是要完整地完成所有键的遍历,需要执⾏多次scan即可。
powershell
scan cursor [match pattern] [COUNT count] [TYPE type]- cursor(游标) :迭代的起始位置;首次调用从0开始迭代;后续使用上一次返回的游标值;返回0表示遍历完成
- match pattern(模式匹配) :使用 glob 风格模式过滤键
- COUNT count(返回数量) :建议每次迭代返回的键数量,默认10
- TYPE type(类型过滤) :按照类型过滤,只返回某类型键
返回值:下一次游标(cursor)以及本次得到的键
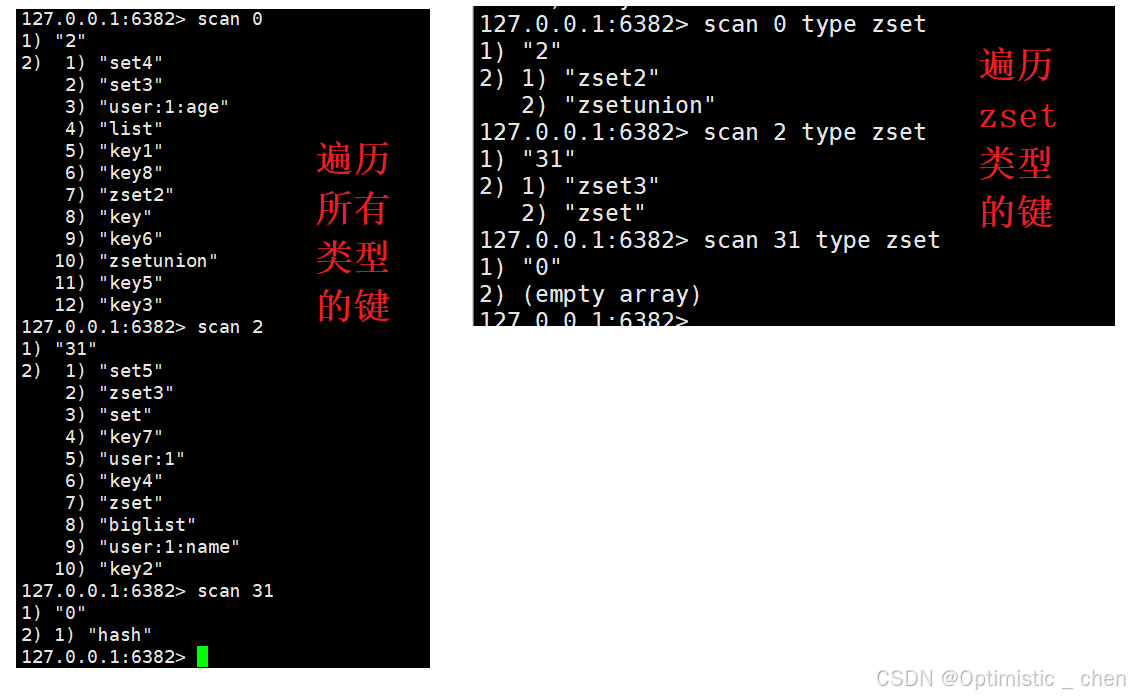
注意:选择某个选项后,之后每次SCAN都必须明确指定筛选条件。

官方文档只是强调:只要将上一次调用返回的游标用于下一次调用,即可延续迭代。对于MATCH、COUNT、TYPE等选项。但没有明文规定这些选项是否必须随游标传递。
但是我们实际操作后发现,这类筛选参数不会被自动记住,每次调用都必须显式提供才能维持筛选条件。
完结撒花!🎉
如果这篇博客对你有帮助,不妨点个赞支持一下吧!👍
你的鼓励是我创作的最大动力~
✨ 想获取更多干货? 欢迎关注我的专栏 → optimistic_chen
📌 收藏本文,下次需要时不迷路!
我们下期再见!💫 持续更新中......
悄悄说:点击主页有更多精彩内容哦~ 😊
